Ship Reliable Agents with Agentic Evaluations
“Launching AI agents without proper measurement is risky for any organization. This important work Galileo has done gives developers the tools to measure agent behavior, optimize performance, and ensure reliable operations - helping teams move to production faster and with more confidence”

Vijoy Pandey
SVP/GP of Outshift
“Developers know that AI agents need to be tested and refined over time.
Galileo makes that easier and faster with end-to-end visibility and agent-specific evaluation metrics”

Surojit Chatterjee
Co-founder and CEO of Ema
“Launching AI agents without proper measurement is risky for any organization. This important work Galileo has done gives developers the tools to measure agent behavior, optimize performance, and ensure reliable operations - helping teams move to production faster and with more confidence”
Vijoy Pandey
SVP/GP of Outshift
“Developers know that AI agents need to be tested and refined over time.
Galileo makes that easier and faster with end-to-end visibility and agent-specific evaluation metrics”
Surojit Chatterjee
Co-founder and CEO of Ema


End-to-end observability
Catch every step under the hood, from LLM plan generation to tool calling and final actions.
Learn More →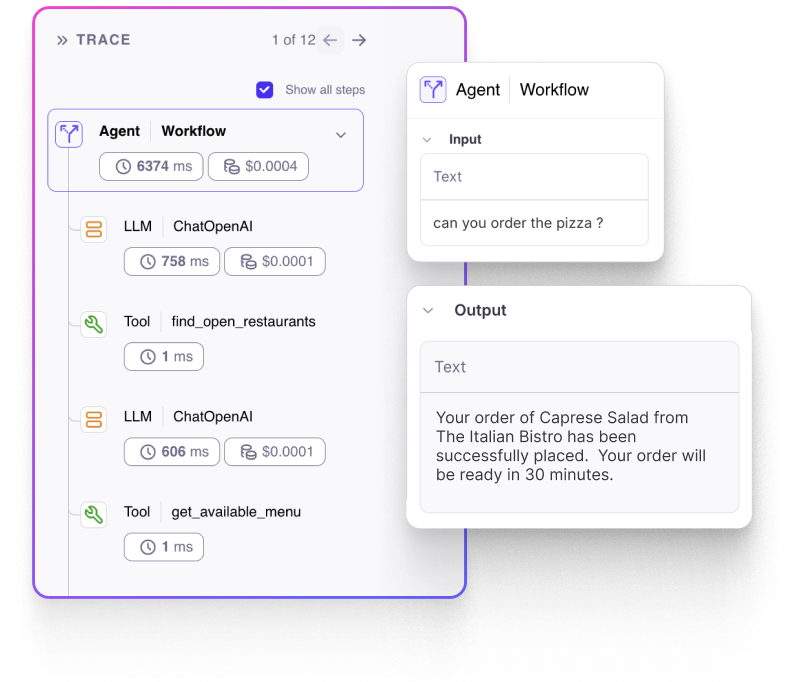
Metrics built for a world of agents
Measure and debug everything from tool selection and instruction, individual tool errors, and overall session success.
Learn More →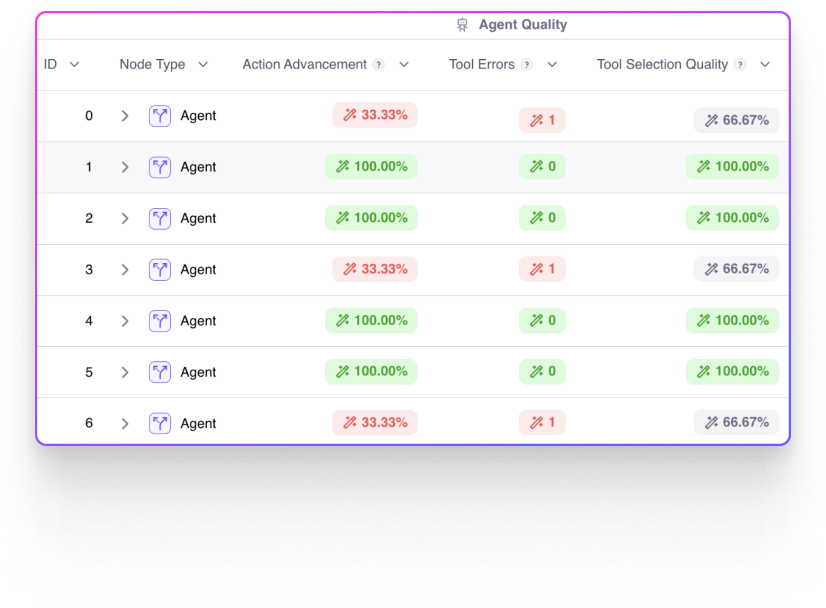
Granular cost and latency tracking
Build cost-effective agentic apps by optimizing for cost and latency at every step with side-by-side run comparisons and granular insights.
Learn More →





