Galileo vs. LangSmith
Learn why AI teams choose Galileo over LangSmith for agent observability. Real-time guardrails, 97% cost savings, framework flexibility, and the ability to stop failures before they ship.
Trusted by enterprises, loved by developers
Trusted by enterprises, loved by developers
Debug with confidence
Why Companies Choose Galileo
LangSmith offers LangChain tracing and debugging, but Galileo goes much further as an end-to-end observability platform that not only logs failures, it prevents them.
While LangSmith excels at moving fast and logging everything, Galileo is purpose-built for shipping safely at scale with framework-agnostic observability, sub-200ms inline protection, and no external tools required to fill gaps.
Debug with confidence
Why Companies Choose Galileo
LangSmith offers LangChain tracing and debugging, but Galileo goes much further as an end-to-end observability platform that not only logs failures, it prevents them.
While LangSmith excels at moving fast and logging everything, Galileo is purpose-built for shipping safely at scale with framework-agnostic observability, sub-200ms inline protection, and no external tools required to fill gaps.
Debug with confidence
Why Companies Choose Galileo
LangSmith offers LangChain tracing and debugging, but Galileo goes much further as an end-to-end observability platform that not only logs failures, it prevents them.
While LangSmith excels at moving fast and logging everything, Galileo is purpose-built for shipping safely at scale with framework-agnostic observability, sub-200ms inline protection, and no external tools required to fill gaps.
Synthetic Data Generation & Pre-Production Testing
LangSmith's dataset philosophy creates a dangerous catch-22: you need production logs to build evaluations, but you need evaluations to ship safely. This forces teams into an endless loop of testing in production by default, essentially using your early users as QA.
Galileo breaks this cycle by generating synthetic datasets with behavior profiles before day one, including prompt injection attempts, off-topic queries, toxic content, and adversarial scenarios that your users will encounter, but you can catch first.
Real Impact:
BAM Elevate tested 1,000 agentic workflows across 13 concurrent projects using synthetic data
Evaluated 5 different LLMs without risking production
Shipped with confidence instead of hoping
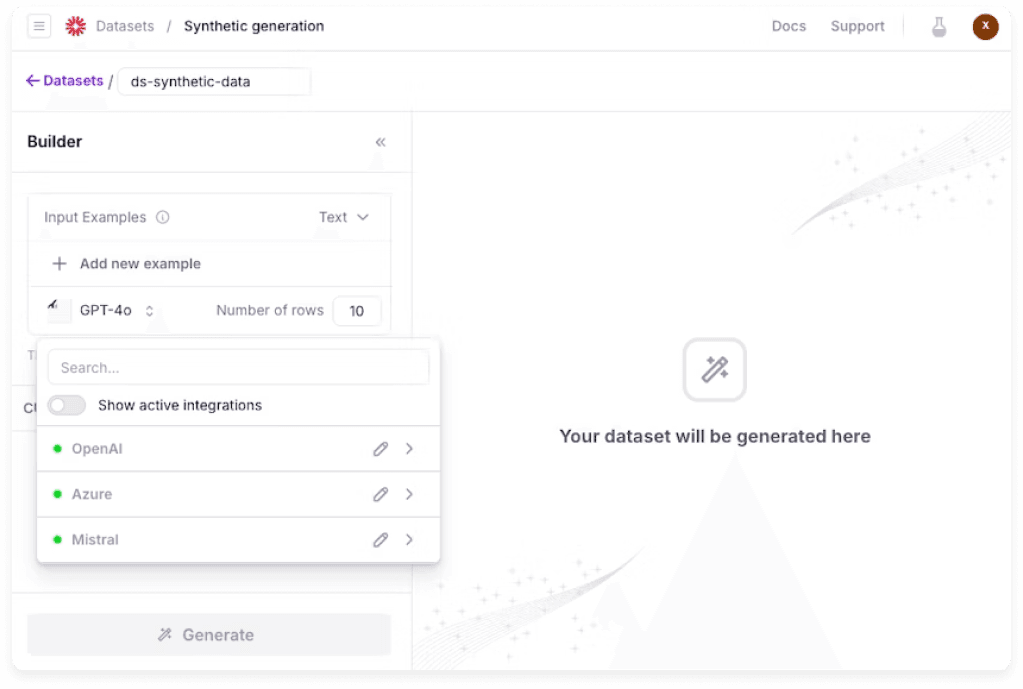
Synthetic Data Generation & Pre-Production Testing
LangSmith's dataset philosophy creates a dangerous catch-22: you need production logs to build evaluations, but you need evaluations to ship safely. This forces teams into an endless loop of testing in production by default, essentially using your early users as QA.
Galileo breaks this cycle by generating synthetic datasets with behavior profiles before day one, including prompt injection attempts, off-topic queries, toxic content, and adversarial scenarios that your users will encounter, but you can catch first.
Real Impact:
BAM Elevate tested 1,000 agentic workflows across 13 concurrent projects using synthetic data
Evaluated 5 different LLMs without risking production
Shipped with confidence instead of hoping
Synthetic Data Generation & Pre-Production Testing
LangSmith's dataset philosophy creates a dangerous catch-22: you need production logs to build evaluations, but you need evaluations to ship safely. This forces teams into an endless loop of testing in production by default, essentially using your early users as QA.
Galileo breaks this cycle by generating synthetic datasets with behavior profiles before day one, including prompt injection attempts, off-topic queries, toxic content, and adversarial scenarios that your users will encounter, but you can catch first.
Real Impact:
BAM Elevate tested 1,000 agentic workflows across 13 concurrent projects using synthetic data
Evaluated 5 different LLMs without risking production
Shipped with confidence instead of hoping
Runtime Guardrails (Block Failures, Don't Just Watch Them)
LangSmith logs failures after they happen. A user jailbreaks your agent? Logged. PII leaks into a prompt? Traced. Toxic output ships? Recorded. You get detailed forensics but zero prevention. You're watching failures occur, not stopping them.
Galileo Protect scans every prompt and response in under 200ms, blocking policy violations before they reach users or databases. Luna-2 SLMs deliver this evaluation speed at 97% lower cost than GPT-4 judges, making 100% production sampling economically viable.
Real Impact:
Fortune 50 telco: 50,000+ live agents monitored
Sub-200ms inline blocking of policy violations
Prevention vs. forensics—the difference between stopped incidents and detailed post-mortems
Cost Comparison: At 20M daily traces:
LangSmith (GPT-4): $200K/month in evaluation costs
Galileo (Luna-2): $6K/month—same accuracy, millisecond latency
Annual savings: $2.3M
Runtime Guardrails (Block Failures, Don't Just Watch Them)
LangSmith logs failures after they happen. A user jailbreaks your agent? Logged. PII leaks into a prompt? Traced. Toxic output ships? Recorded. You get detailed forensics but zero prevention. You're watching failures occur, not stopping them.
Galileo Protect scans every prompt and response in under 200ms, blocking policy violations before they reach users or databases. Luna-2 SLMs deliver this evaluation speed at 97% lower cost than GPT-4 judges, making 100% production sampling economically viable.
Real Impact:
Fortune 50 telco: 50,000+ live agents monitored
Sub-200ms inline blocking of policy violations
Prevention vs. forensics—the difference between stopped incidents and detailed post-mortems
Cost Comparison: At 20M daily traces:
LangSmith (GPT-4): $200K/month in evaluation costs
Galileo (Luna-2): $6K/month—same accuracy, millisecond latency
Annual savings: $2.3M
Runtime Guardrails (Block Failures, Don't Just Watch Them)
LangSmith logs failures after they happen. A user jailbreaks your agent? Logged. PII leaks into a prompt? Traced. Toxic output ships? Recorded. You get detailed forensics but zero prevention. You're watching failures occur, not stopping them.
Galileo Protect scans every prompt and response in under 200ms, blocking policy violations before they reach users or databases. Luna-2 SLMs deliver this evaluation speed at 97% lower cost than GPT-4 judges, making 100% production sampling economically viable.
Real Impact:
Fortune 50 telco: 50,000+ live agents monitored
Sub-200ms inline blocking of policy violations
Prevention vs. forensics—the difference between stopped incidents and detailed post-mortems
Cost Comparison: At 20M daily traces:
LangSmith (GPT-4): $200K/month in evaluation costs
Galileo (Luna-2): $6K/month—same accuracy, millisecond latency
Annual savings: $2.3M
Evaluator Reusability & Metric Store (Build Once, Deploy Everywhere)
LangSmith treats every evaluation as a bespoke prompt engineering task. Building a "factual accuracy" checker for Project A? You rebuild it from scratch for Project B. And C. And D. No evaluator library. No version control. No reusability. Weeks of manual prompt engineering per metric.
Galileo's Metric Store with CLHF (Continuous Learning from Human Feedback) enables you to build once, refine with human feedback, and deploy across all your projects. One team's "hallucination detector" becomes the entire organization's standard, with version control and refinement built in.
Real Impact:
Service Titan: Single dashboard for 3 distinct AI systems using shared metric library
BAM Elevate: Created custom "tool selection quality" metric using 5 labeled examples, CLHF fine-tuned to 92% accuracy in 10 minutes, reused across 13 research projects and 60+ evaluation runs
Metric creation time: Minutes (2-5 examples via CLHF) vs. Weeks (manual prompt engineering)

Evaluator Reusability & Metric Store (Build Once, Deploy Everywhere)
LangSmith treats every evaluation as a bespoke prompt engineering task. Building a "factual accuracy" checker for Project A? You rebuild it from scratch for Project B. And C. And D. No evaluator library. No version control. No reusability. Weeks of manual prompt engineering per metric.
Galileo's Metric Store with CLHF (Continuous Learning from Human Feedback) enables you to build once, refine with human feedback, and deploy across all your projects. One team's "hallucination detector" becomes the entire organization's standard, with version control and refinement built in.
Real Impact:
Service Titan: Single dashboard for 3 distinct AI systems using shared metric library
BAM Elevate: Created custom "tool selection quality" metric using 5 labeled examples, CLHF fine-tuned to 92% accuracy in 10 minutes, reused across 13 research projects and 60+ evaluation runs
Metric creation time: Minutes (2-5 examples via CLHF) vs. Weeks (manual prompt engineering)
Evaluator Reusability & Metric Store (Build Once, Deploy Everywhere)
LangSmith treats every evaluation as a bespoke prompt engineering task. Building a "factual accuracy" checker for Project A? You rebuild it from scratch for Project B. And C. And D. No evaluator library. No version control. No reusability. Weeks of manual prompt engineering per metric.
Galileo's Metric Store with CLHF (Continuous Learning from Human Feedback) enables you to build once, refine with human feedback, and deploy across all your projects. One team's "hallucination detector" becomes the entire organization's standard, with version control and refinement built in.
Real Impact:
Service Titan: Single dashboard for 3 distinct AI systems using shared metric library
BAM Elevate: Created custom "tool selection quality" metric using 5 labeled examples, CLHF fine-tuned to 92% accuracy in 10 minutes, reused across 13 research projects and 60+ evaluation runs
Metric creation time: Minutes (2-5 examples via CLHF) vs. Weeks (manual prompt engineering)
Comprehensive Comparison Table
Capability
Galileo
LangSmith
Core Focus
Agent observability + runtime protection
LLM tracing & debugging
Evaluation Engine
Luna-2 SLMs, sub-200ms, 97% cheaper
Generic LLM-as-judge (GPT-4)
Synthetic Data Generation
Behavior profiles (injection, toxic, off-topic)
Production logs only
Evaluator Reusability
Metric Store with versioning & CLHF
Recreate prompt per project
Runtime Intervention
Inline blocking & guardrails
Logs only, no prevention
Framework Support
Framework-agnostic (CrewAI, LangGraph, custom)
LangChain-first, others need custom work
Agent-Specific Metrics
8 out-of-the-box (tool selection, flow, efficiency)
2 basic metrics
Span-Level Evaluation
Every step measured independently
Run-level only
Session-Level Analysis
Multi-turn conversation tracking
No session grouping
Scale Proven
20M+ traces/day, 50K+ live agents
1B+ stored trace logs
Deployment Options
SaaS, hybrid, on-prem; SOC 2, ISO 27001
Primarily SaaS; SOC 2
P0 Incident SLA
4 hours
Not publicly disclosed
Metric Creation Time
Minutes (2-5 examples via CLHF)
Weeks (manual prompt engineering)
PII Detection & Redaction
Automatic before storage
Separate tooling needed
Insights Engine
Auto-clusters failures, recommends fixes
Manual analysis required
Data During Outages
Queued and processed
Dropped (May 2025 SSL incident: 28min data loss)
Comprehensive Comparison Table
Capability
Galileo
LangSmith
Core Focus
Agent observability + runtime protection
LLM tracing & debugging
Evaluation Engine
Luna-2 SLMs, sub-200ms, 97% cheaper
Generic LLM-as-judge (GPT-4)
Synthetic Data Generation
Behavior profiles (injection, toxic, off-topic)
Production logs only
Evaluator Reusability
Metric Store with versioning & CLHF
Recreate prompt per project
Runtime Intervention
Inline blocking & guardrails
Logs only, no prevention
Framework Support
Framework-agnostic (CrewAI, LangGraph, custom)
LangChain-first, others need custom work
Agent-Specific Metrics
8 out-of-the-box (tool selection, flow, efficiency)
2 basic metrics
Span-Level Evaluation
Every step measured independently
Run-level only
Session-Level Analysis
Multi-turn conversation tracking
No session grouping
Scale Proven
20M+ traces/day, 50K+ live agents
1B+ stored trace logs
Deployment Options
SaaS, hybrid, on-prem; SOC 2, ISO 27001
Primarily SaaS; SOC 2
P0 Incident SLA
4 hours
Not publicly disclosed
Metric Creation Time
Minutes (2-5 examples via CLHF)
Weeks (manual prompt engineering)
PII Detection & Redaction
Automatic before storage
Separate tooling needed
Insights Engine
Auto-clusters failures, recommends fixes
Manual analysis required
Data During Outages
Queued and processed
Dropped (May 2025 SSL incident: 28min data loss)
Comprehensive Comparison Table
Capability
Galileo
LangSmith
Core Focus
Agent observability + runtime protection
LLM tracing & debugging
Evaluation Engine
Luna-2 SLMs, sub-200ms, 97% cheaper
Generic LLM-as-judge (GPT-4)
Synthetic Data Generation
Behavior profiles (injection, toxic, off-topic)
Production logs only
Evaluator Reusability
Metric Store with versioning & CLHF
Recreate prompt per project
Runtime Intervention
Inline blocking & guardrails
Logs only, no prevention
Framework Support
Framework-agnostic (CrewAI, LangGraph, custom)
LangChain-first, others need custom work
Agent-Specific Metrics
8 out-of-the-box (tool selection, flow, efficiency)
2 basic metrics
Span-Level Evaluation
Every step measured independently
Run-level only
Session-Level Analysis
Multi-turn conversation tracking
No session grouping
Scale Proven
20M+ traces/day, 50K+ live agents
1B+ stored trace logs
Deployment Options
SaaS, hybrid, on-prem; SOC 2, ISO 27001
Primarily SaaS; SOC 2
P0 Incident SLA
4 hours
Not publicly disclosed
Metric Creation Time
Minutes (2-5 examples via CLHF)
Weeks (manual prompt engineering)
PII Detection & Redaction
Automatic before storage
Separate tooling needed
Insights Engine
Auto-clusters failures, recommends fixes
Manual analysis required
Data During Outages
Queued and processed
Dropped (May 2025 SSL incident: 28min data loss)
Trusted by enterprises, loved by developers

"Before Galileo, we could go three days before knowing if something bad is happening. With Galileo, we can know in minutes. Galileo fills in the gaps we had in instrumentation and observability."
Darrel Cherry
Distinguished Engineer, Clearwater Analytics
"Before Galileo, we could go three days before knowing if something bad is happening. With Galileo, we can know in minutes. Galileo fills in the gaps we had in instrumentation and observability."
Darrel Cherry
Distinguished Engineer, Clearwater Analytics
Trusted by enterprises, loved by developers
"Before Galileo, we could go three days before knowing if something bad is happening. With Galileo, we can know in minutes. Galileo fills in the gaps we had in instrumentation and observability."
Darrel Cherry
Distinguished Engineer, Clearwater Analytics
Trusted by enterprises, loved by developers
"Before Galileo, we could go three days before knowing if something bad is happening. With Galileo, we can know in minutes. Galileo fills in the gaps we had in instrumentation and observability."
Darrel Cherry
Distinguished Engineer, Clearwater Analytics
Visual Cost Comparison
Traditional Approach (LangSmith):
Galileo Approach:
GPT-4 evaluations: $10 per 1M tokens
Luna-2 evaluations: $0.20 per 1M tokens
20M daily traces: $200K/month
20M daily traces: $6K/month
Annual cost: $2.4M
Annual cost: $72K
Plus: External guardrails, synthetic data tools, metric versioning infrastructure
Includes: Built-in guardrails, synthetic data generation, metric store with CLHF
Total Savings: $2.3M+ annually
Visual Cost Comparison
Traditional Approach (LangSmith):
Galileo Approach:
GPT-4 evaluations: $10 per 1M tokens
Luna-2 evaluations: $0.20 per 1M tokens
20M daily traces: $200K/month
20M daily traces: $6K/month
Annual cost: $2.4M
Annual cost: $72K
Plus: External guardrails, synthetic data tools, metric versioning infrastructure
Includes: Built-in guardrails, synthetic data generation, metric store with CLHF
Total Savings: $2.3M+ annually
Visual Cost Comparison
Traditional Approach (LangSmith):
Galileo Approach:
GPT-4 evaluations: $10 per 1M tokens
Luna-2 evaluations: $0.20 per 1M tokens
20M daily traces: $200K/month
20M daily traces: $6K/month
Annual cost: $2.4M
Annual cost: $72K
Plus: External guardrails, synthetic data tools, metric versioning infrastructure
Includes: Built-in guardrails, synthetic data generation, metric store with CLHF
Total Savings: $2.3M+ annually
Observability Platform Evaluation Questions
Before choosing an observability platform, ask these questions to separate production-ready platforms from prototyping tools:
1
“How do you generate test data before production?”
“How do you generate test data before production?”
1
“How do you generate test data before production?”
“How do you generate test data before production?”
2
“Can I reuse evaluators across projects?”
2
“Can I reuse evaluators across projects?”
3
“Can you block bad outputs at runtime?”
3
“Can you block bad outputs at runtime?”
4
“What happens if I outgrow my current framework?”
4
“What happens if I outgrow my current framework?”
5
“How much time will my team spend recreating evaluators?”
5
“How much time will my team spend recreating evaluators?”
6
“What's your operational maturity and incident history?”
6
“What's your operational maturity and incident history?”
Observability Platform Evaluation Questions
Before choosing an observability platform, ask these questions to separate production-ready platforms from prototyping tools:
1
“How do you generate test data before production?”
“How do you generate test data before production?”
2
“Can I reuse evaluators across projects?”
3
“Can you block bad outputs at runtime?”
4
“What happens if I outgrow my current framework?”
5
“How much time will my team spend recreating evaluators?”
6
“What's your operational maturity and incident history?”
Observability Platform Evaluation Questions
Before choosing an observability platform, ask these questions to separate production-ready platforms from prototyping tools:
1
“How do you generate test data before production?”
“How do you generate test data before production?”
2
“Can I reuse evaluators across projects?”
3
“Can you block bad outputs at runtime?”
4
“What happens if I outgrow my current framework?”
5
“How much time will my team spend recreating evaluators?”
6
“What's your operational maturity and incident history?”
Framework Flexibility Matters
Your observability layer shouldn't lock you in
LangSmith's deep LangChain integration becomes a constraint when you need to migrate. Custom orchestrators, CrewAI, LlamaIndex, and Amazon Bedrock Agents all require instrumentation workarounds.
Galileo provides framework-agnostic SDKs via OpenTelemetry:
LangGraph
LangChain
LlamaIndex
CrewAI
AutoGen
Custom proprietary engines
Amazon Bedrock Agents
Same telemetry layer. Zero migration pain.
Framework Flexibility Matters
Your observability layer shouldn't lock you in
LangSmith's deep LangChain integration becomes a constraint when you need to migrate. Custom orchestrators, CrewAI, LlamaIndex, and Amazon Bedrock Agents all require instrumentation workarounds.
Galileo provides framework-agnostic SDKs via OpenTelemetry:
LangGraph
LangChain
LlamaIndex
CrewAI
AutoGen
Custom proprietary engines
Amazon Bedrock Agents
Same telemetry layer. Zero migration pain.
Framework Flexibility Matters
Your observability layer shouldn't lock you in
LangSmith's deep LangChain integration becomes a constraint when you need to migrate. Custom orchestrators, CrewAI, LlamaIndex, and Amazon Bedrock Agents all require instrumentation workarounds.
Galileo provides framework-agnostic SDKs via OpenTelemetry:
LangGraph
LangChain
LlamaIndex
CrewAI
AutoGen
Custom proprietary engines
Amazon Bedrock Agents
Same telemetry layer. Zero migration pain.
Galileo: Compliance Infrastructure Standard
SOC 2 Type II and ISO 27001 certifications
Real-time guardrails block policy violations in under 200ms
PII detection and redaction automatic before storage
Immutable audit trails for every agent decision
Data residency controls keep records in specified regions
On-prem deployment for air-gapped environments
Result: Finance and healthcare teams run regulated AI without inviting auditors back every sprint.
LangSmith: External Tools Required
SOC 2 certified for security baseline
No inline blocking—external guardrails required
No PII redaction—separate tooling needed
Primarily SaaS—limited on-prem options
Reality: For end-to-end compliance, you're building a complete defense layer separately.
When LangSmith Makes Sense
We believe in transparent comparisons. LangSmith excels in specific scenarios:
Pure LangChain shops:
If 90%+ of your stack is LangChain and staying that way, the auto-instrumentation saves time
Early prototyping:
Pre-production teams iterating on prompts benefit from instant trace visualization
Small scale:
Under 1M traces monthly, LangSmith's SaaS model is plug-and-play
Where teams outgrow LangSmith:
Where teams outgrow LangSmith:
No runtime blocking (requires external guardrails)
No synthetic test data (testing in prod becomes default)
Framework lock-in (custom orchestrators require heavy lifting)
Evaluator recreation (no metric reusability across projects)
Cost at scale (GPT-4 evals compound past 10M traces/month)
Galileo: Compliance Infrastructure Standard
SOC 2 Type II and ISO 27001 certifications
Real-time guardrails block policy violations in under 200ms
PII detection and redaction automatic before storage
Immutable audit trails for every agent decision
Data residency controls keep records in specified regions
On-prem deployment for air-gapped environments
Result: Finance and healthcare teams run regulated AI without inviting auditors back every sprint.
LangSmith: External Tools Required
SOC 2 certified for security baseline
No inline blocking—external guardrails required
No PII redaction—separate tooling needed
Primarily SaaS—limited on-prem options
Reality: For end-to-end compliance, you're building a complete defense layer separately.
When LangSmith Makes Sense
We believe in transparent comparisons. LangSmith excels in specific scenarios:
Pure LangChain shops:
If 90%+ of your stack is LangChain and staying that way, the auto-instrumentation saves time
Early prototyping:
Pre-production teams iterating on prompts benefit from instant trace visualization
Small scale:
Under 1M traces monthly, LangSmith's SaaS model is plug-and-play
Where teams outgrow LangSmith:
No runtime blocking (requires external guardrails)
No synthetic test data (testing in prod becomes default)
Framework lock-in (custom orchestrators require heavy lifting)
Evaluator recreation (no metric reusability across projects)
Cost at scale (GPT-4 evals compound past 10M traces/month)
Galileo: Compliance Infrastructure Standard
SOC 2 Type II and ISO 27001 certifications
Real-time guardrails block policy violations in under 200ms
PII detection and redaction automatic before storage
Immutable audit trails for every agent decision
Data residency controls keep records in specified regions
On-prem deployment for air-gapped environments
Result: Finance and healthcare teams run regulated AI without inviting auditors back every sprint.
LangSmith: External Tools Required
SOC 2 certified for security baseline
No inline blocking—external guardrails required
No PII redaction—separate tooling needed
Primarily SaaS—limited on-prem options
Reality: For end-to-end compliance, you're building a complete defense layer separately.
When LangSmith Makes Sense
We believe in transparent comparisons. LangSmith excels in specific scenarios:
Pure LangChain shops:
If 90%+ of your stack is LangChain and staying that way, the auto-instrumentation saves time
Early prototyping:
Pre-production teams iterating on prompts benefit from instant trace visualization
Small scale:
Under 1M traces monthly, LangSmith's SaaS model is plug-and-play
Where teams outgrow LangSmith:
No runtime blocking (requires external guardrails)
No synthetic test data (testing in prod becomes default)
Framework lock-in (custom orchestrators require heavy lifting)
Evaluator recreation (no metric reusability across projects)
Cost at scale (GPT-4 evals compound past 10M traces/month)
Choose Galileo When You Need:
Production-Ready Capabilities:
Real-time protection for regulated workloads (financial services, healthcare, PII-sensitive)
Framework flexibility to avoid orchestration lock-in
Cost-efficient scale with 20M+ traces daily
Metric reusability across teams and projects
Sub-200ms guardrails that block failures inline
Agent-specific observability with session-level tracking
Deployment Flexibility:
SaaS, hybrid, or on-prem options
Data residency controls
SOC 2 Type II + ISO 27001 compliance
Economic Viability:
97% cost reduction vs. GPT-4 evaluations
No external guardrail subscriptions needed
No synthetic data tooling costs
No metric versioning infrastructure to build
Choose Galileo When You Need:
Production-Ready Capabilities:
Real-time protection for regulated workloads (financial services, healthcare, PII-sensitive)
Framework flexibility to avoid orchestration lock-in
Cost-efficient scale with 20M+ traces daily
Metric reusability across teams and projects
Sub-200ms guardrails that block failures inline
Agent-specific observability with session-level tracking
Deployment Flexibility:
SaaS, hybrid, or on-prem options
Data residency controls
SOC 2 Type II + ISO 27001 compliance
Economic Viability:
97% cost reduction vs. GPT-4 evaluations
No external guardrail subscriptions needed
No synthetic data tooling costs
No metric versioning infrastructure to build
Choose Galileo When You Need:
Production-Ready Capabilities:
Real-time protection for regulated workloads (financial services, healthcare, PII-sensitive)
Framework flexibility to avoid orchestration lock-in
Cost-efficient scale with 20M+ traces daily
Metric reusability across teams and projects
Sub-200ms guardrails that block failures inline
Agent-specific observability with session-level tracking
Deployment Flexibility:
SaaS, hybrid, or on-prem options
Data residency controls
SOC 2 Type II + ISO 27001 compliance
Economic Viability:
97% cost reduction vs. GPT-4 evaluations
No external guardrail subscriptions needed
No synthetic data tooling costs
No metric versioning infrastructure to build
Start Building Reliable AI Agents
Moving from reactive debugging to proactive quality assurance requires a platform built for production complexity.
Automated CI/CD guardrails:
Block releases failing quality thresholds
Multi-dimensional evaluation:
Luna-2 models assess correctness, toxicity, bias, and adherence at 97% lower cost
Real-time runtime protection:
Scan every prompt/response, block harmful outputs before users see them
Intelligent failure detection:
Insights Engine clusters failures, surfaces root causes, and recommends fixes
CLHF optimization:
Transform expert reviews into reusable evaluators in minutes