AI Reliability Platform
AI apps don't always do what you want. Galileo is the end-to-end platform for AI evaluation, observability, and real-time protection, so you can ship with confidence.


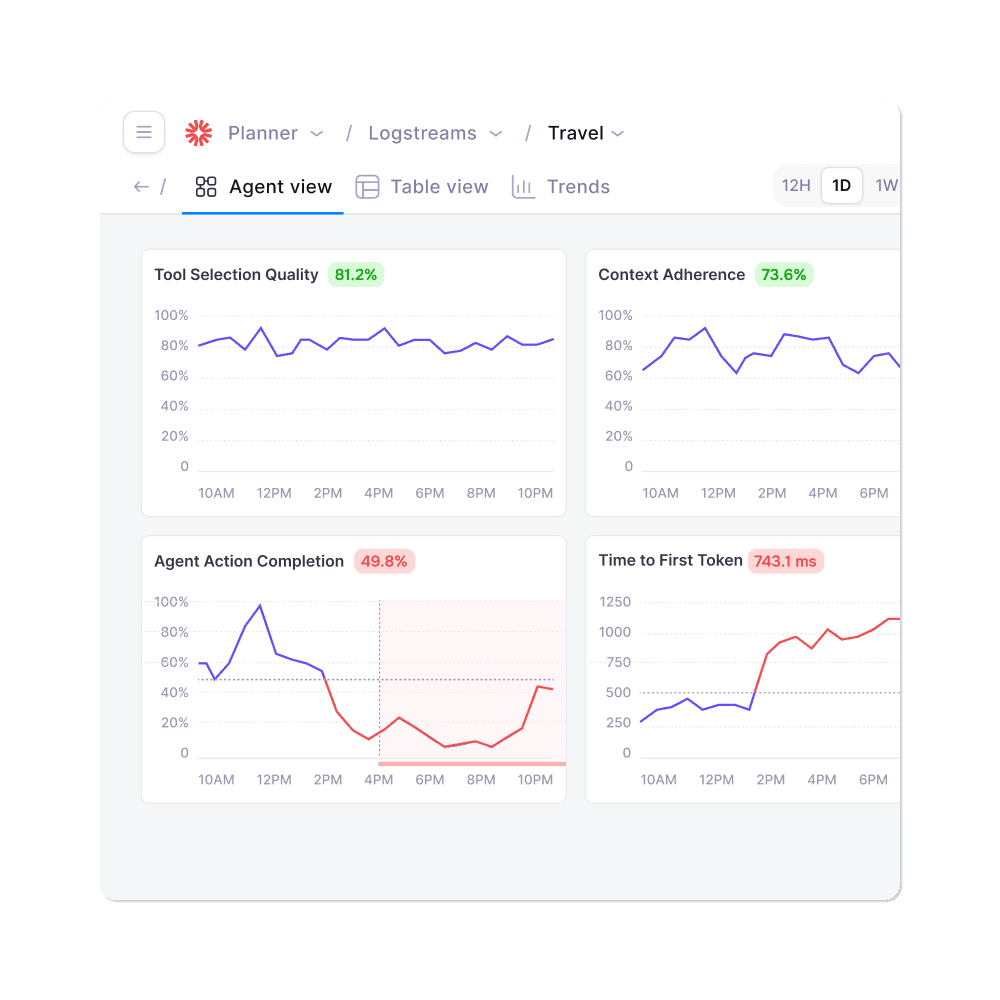
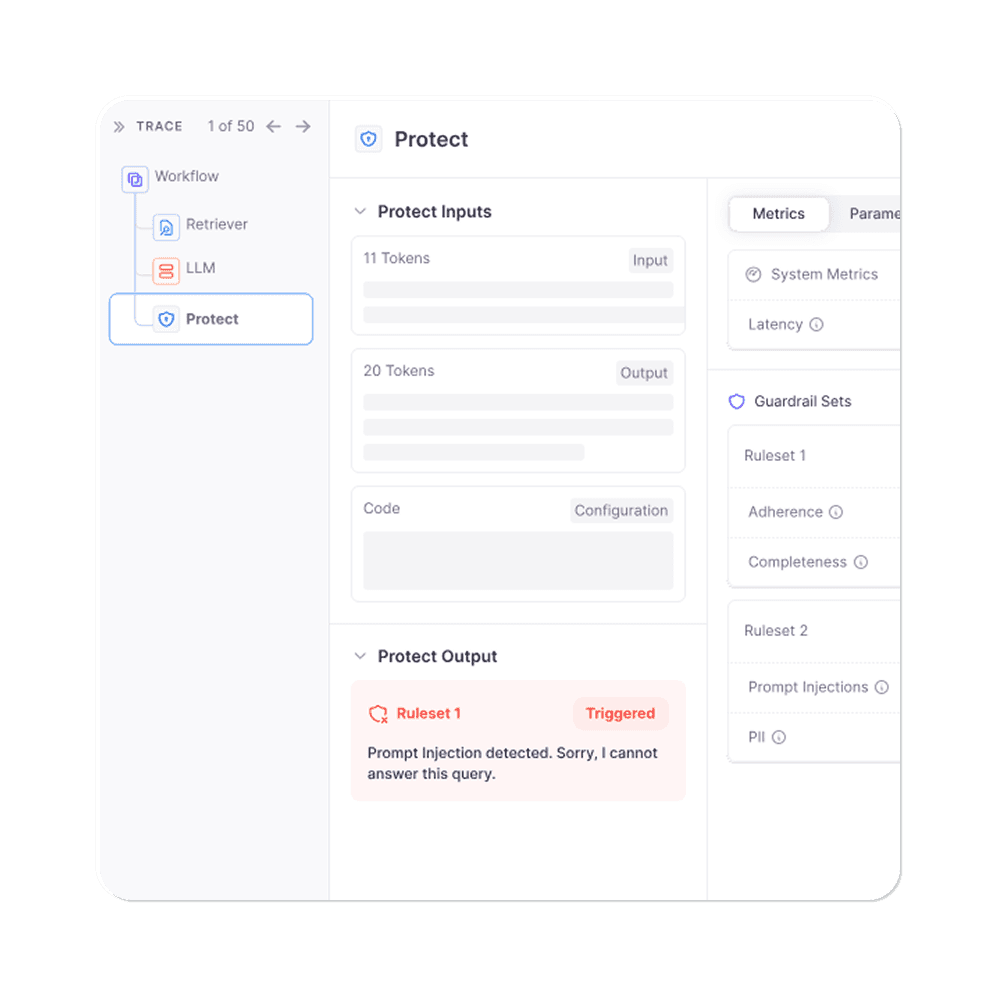
Adaptive
Powered by the Evaluation Engine
Prebuilt metrics
Get started with over 20 out-of-the-box evaluators that are tested and accurate.
Custom metrics
Add code-based evaluators or automatically generate accurate LLM-as-judge evaluators just by typing a description.
Auto-tune
Improve evaluators with CLHF (Continuous Learning with Human Feedback) which optimizes prompts by adding few-shot examples.
Inference
Monitor AI in production with low-latency evaluators hosted on our purpose-built inference server.
Scalable
Proprietary models for fast evaluation
Azure AI Content Safety
$1.52
0.62
Cost per 1M tokens
Accuracy
312ms
3k
Latency (Avg)
Max tokens
Online and offline
Easy to integrate










SDKs
APIs


Your App


Models

Orchestration
Incident Response
OnCall

Retrieval
Cloud / Data Platforms
Ready to start?
Get started in minutes with our free developer tier, or explore our enterprise features in a guided demo.
Flexible pricing
Start for free and upgrade when you're ready to customize your evaluations and scale your AI applications to production.
Learn more
See how companies like Twilio and Comcast are achieving reliable AI with Galieo - and explore the platform’s capabilities for yourself.