
Launching Agent Leaderboard v2: The Enterprise-Grade Benchmark for AI Agents

TL;DR: What's New in v2

Klarna’s decision to replace 700 customer-service reps with AI backfired so much that they’re now rehiring humans to patch the gaps. They saved money, but customer experience degraded. What if there were a way to catch those failures before flipping the switch?
That’s precisely the problem Agent Leaderboard v2 is built to solve. Rather than simply testing whether an agent can call the right tools, we put AIs through real enterprise scenarios spanning five industries with multi-turn dialogues and complex decision-making.
Key Results as of July 17, 2025:
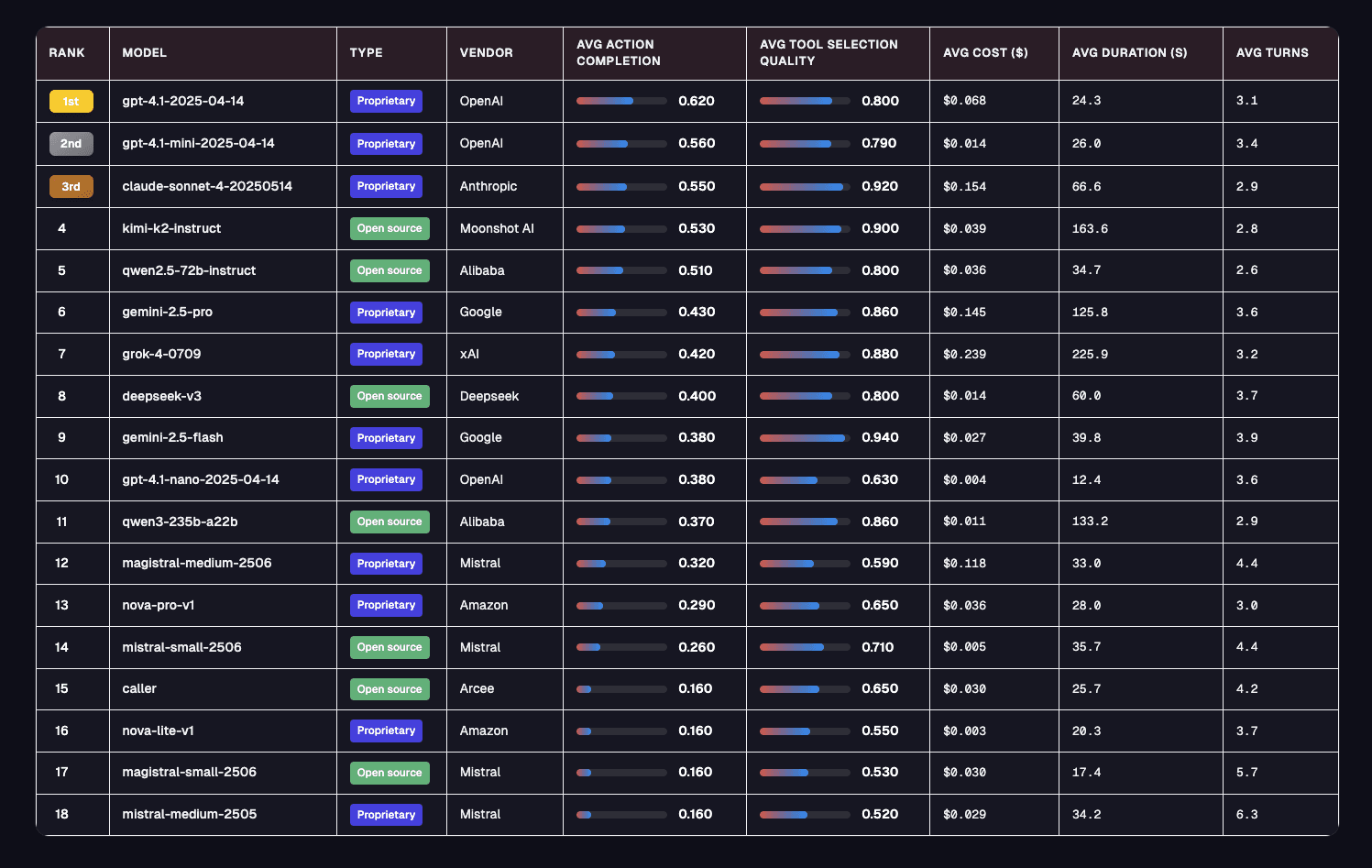
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
→ Explore the Live Leaderboard
What we measure shapes AI. With our Agent Leaderboard initiative, we’re bringing focus back to the ground where real work happens. The Humanity’s Last Exam benchmark is cool, but we must still cover the basics.
A New Benchmark Was Needed
Agent Leaderboard v1 established our foundation for evaluating AI agents, with over 30 LLMs tested across 14 datasets. But as model quality improved, high performance in basic tool-calling became the norm, and several challenges emerged:
Score saturation: Models clustered above 90% made differentiation on performance difficult
Potential benchmark leakage: Public benchmarks may have been incorporated into model training, blurring the lines between genuine generalization and memorization.
Insufficient scenario complexity: While v1 covered a range of domains, most scenarios were static, with little context carry-over, few ambiguous cases, and limited reflection of the messiness of real enterprise deployments.
Limitations of static datasets: Real-world tasks are dynamic and multi-turn. Static, one-shot evaluations miss the complexity of extended, evolving interactions.
No domain isolation: The absence of truly domain-specific datasets made it difficult for enterprises to understand model strengths for their specific agent use cases.
Here is my interview with Latent Space where I talk about the limitations of v1 and my learnings.
These limitations meant the v1 leaderboard was no longer enough to guide enterprises that need agents capable of navigating true complexity of the real world. When hundreds of models score above 80% on simple API-call tests, how do you know which one will handle your real-world customer conversations? How can we get realistic, multi-turn, domain-specific evaluation?
Enter Agent Leaderboard v2: Built for the Enterprise
https://galileo.ai/agent-leaderboard
Agent Leaderboard v2 is a leap forward, simulating realistic support agents across five critical industries at launch: banking, healthcare, investment, telecom, and insurance.
Each domain features 100 synthetic scenarios crafted to reflect the ambiguity, context-dependence, and unpredictability of real-world conversations. Every scenario includes prior chat context, changing user requirements, missing or irrelevant tools, and conditional requests, all driven by synthetic personas representing realistic user types. Agents must coordinate actions over multi-turn dialogues, plan ahead, adapt to new information, and use a suite of domain-specific tools, just like in a real enterprise deployment.
Each scenario features:
Real-world complexity
5-8 interconnected user goals per conversation
Multi-turn dialogues with context dependencies
Dynamic user personas with varying communication styles
Domain-specific tools reflecting actual enterprise APIs
Edge cases and ambiguity that mirror production challenges
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
Where v1 was about checking if the model calls the API with the correct arguments, v2 is about real-world effectiveness: Can the agent actually get the job done for the user, every time, across a wide range of realistic situations?
This is our ranking based on Action Completion. GPT-4.1 comes out at the top.

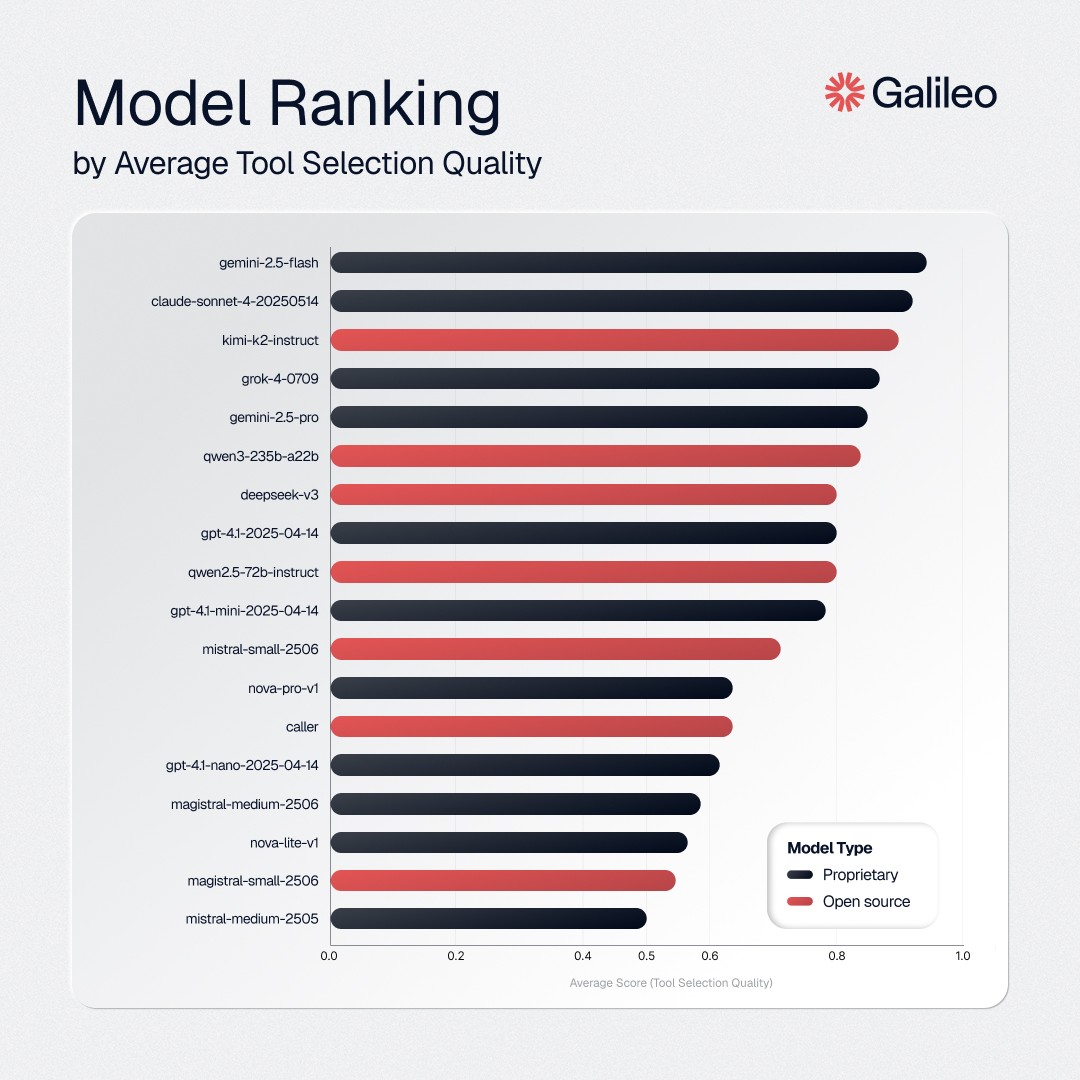
This is our ranking based on Tool Selection Quality. Gemini 2.5 Flash comes out at the top.
Key Insights
Here are our top model and overall insights as of July 17, 2025:
Model insights:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.

Measuring an Agent’s Performance
We center on two complementary pillars—Action Completion and Tool Selection Quality—that together capture what the agent achieves and how it achieves it.
Action Completion
Our Action Completion metric is at the heart of v2: Did the agent fully accomplish every user goal, providing clear answers or confirmations for every ask? This isn’t just about checking off tool calls. Agents must track context across up to eight interdependent user requests.

Action Completion reflects the agent’s ability to fulfill all aspects of a user’s request, not just make the right tool calls or provide partial answers. A high Action Completion score means the assistant provided clear, complete, and accurate outcomes, whether answering questions, confirming task success, or summarizing tool results.
In short, did the agent actually solve the user’s problem?
Tool Selection Quality
The complexity of tool calling extends far beyond simple API invocations. When an agent encounters a query, it must first determine if tool usage is warranted. Information may already exist in the conversation history, making tool calls redundant. Alternatively, available tools might be insufficient or irrelevant to the task, requiring the agent to acknowledge limitations rather than force inappropriate tool usage.
Various scenarios challenge AI agents' ability to make appropriate decisions about tool usage. Tool Selection Quality (TSQ) measures how accurately an AI agent chooses and uses external tools to fulfill a user’s request. A perfect TSQ score means the agent not only picks the right tool but also supplies every required parameter correctly, while avoiding unnecessary or erroneous calls. In agentic systems, subtle mistakes like invoking the wrong API or passing a bad argument can lead to incorrect or harmful outcomes, so TSQ surfaces exactly where and how tool use goes off track.
We compute TSQ by sending each tool call through a dedicated LLM evaluator (Anthropic’s Claude) with a reasoning prompt.

Tool Selection Dynamics
Tool selection involves both precision and recall. An agent might correctly identify one necessary tool while missing others (recall issue) or select appropriate tools alongside unnecessary ones (precision issue). While suboptimal, these scenarios represent different severity levels of selection errors.
Parameter Handling
Even with correct tool selection, argument handling introduces additional complexity. Agents must:
Provide all required parameters with the correct naming
Handle optional parameters appropriately
Maintain parameter value accuracy
Format arguments according to tool specifications
Sequential Decision Making
Multi-step tasks require agents to:
Determine the optimal tool calling sequence
Handle interdependencies between tool calls
Maintain context across multiple operations
Adapt to partial results or failures

The diagram above illustrates the logical flow of how a tool call is processed within an LLM’s internal reasoning. These complexities illustrate why Tool Selection Quality should not be regarded as a simple metric but rather as a multifaceted evaluation of an agent’s decision-making capabilities in real-world scenarios.
Let's understand how we built the dataset to run the simulation to evaluate the LLMs.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
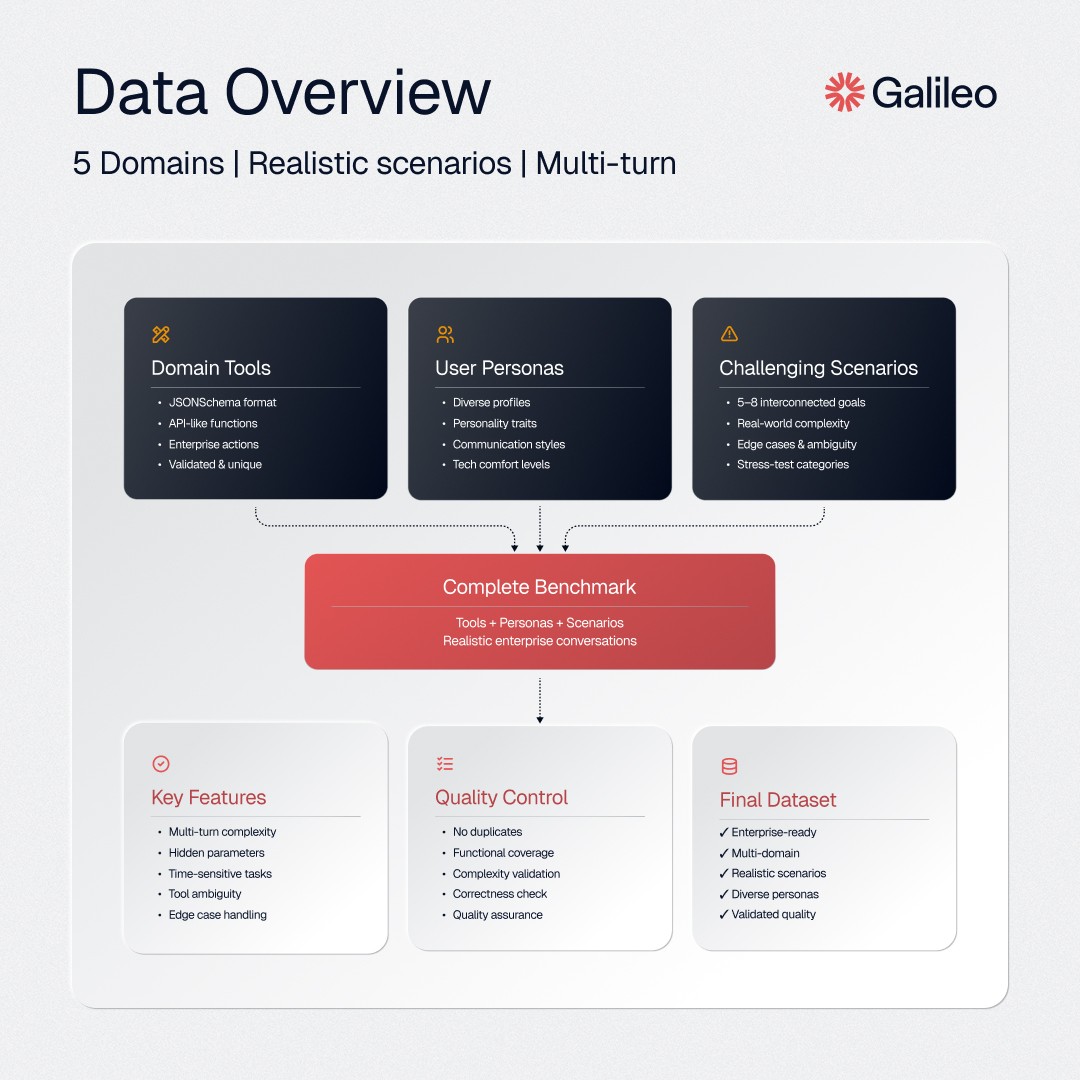
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and to guarantee functional coverage for each domain. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Response schema for the tool
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "persona_index": 0, "first_message": "Hello, I need to handle several banking matters before I leave for Europe next Thursday. I've been saving for this trip for years through my Premium Savings account. First, I need to report my Platinum credit card as lost yesterday - I think I left it at a restaurant. Also, I'd like to verify my upcoming mortgage payment on the 15th and set up automatic payments for my utility bills from my checking account. Could you also help me find a branch near my hotel in Paris to exchange some currency? I need to know today's euro exchange rate. Oh, and I should probably set up fraud alerts since I'll be traveling abroad for 3 weeks.", "user_goals": [ "Report Platinum credit card as lost and request replacement before international travel", "Verify mortgage payment details for upcoming payment on the 15th", "Set up automatic bill payments for utilities from checking account", "Find information about bank branches near a specific Paris hotel location", "Get current USD to EUR exchange rates for travel planning", "Configure account alerts for international travel to prevent fraud detection issues" ] }, { "persona_index": 1, "first_message": "Hey, I need some major help sorting out my banking situation. I'm traveling to Tokyo next month on the 23rd for a tech conference, but I just realized my credit card expires on the 15th! I also need to make sure my business loan application from last week got processed, set up automatic payments for my AWS hosting bill ($249.99 monthly), check if I can open a high-yield CD for some startup funds I'm not using yet, and update my phone number since I'm switching carriers tomorrow. Oh, and my last card transaction at TechHub for $892.50 was supposed to be only $289.25 - they double-charged me!", "user_goals": [ "Get a replacement credit card before international travel to Japan on the 23rd of next month", "Check status of recently submitted business loan application from approximately 7 days ago", "Set up recurring automatic bill payment for AWS hosting service at $249.99 per month", "Find a high-yield Certificate of Deposit option for temporary startup capital investment (minimum $25,000)", "Update contact information with new phone number before carrier switch tomorrow", "Dispute an incorrect charge of $892.50 at TechHub that should have been $289.25" ] } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.

Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed not just on accuracy but also on their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Here is a very high-level pseudocode for the simulation.
class AgentSimulation: def __init__(self, model, domain, category): # Load data self.tools = load_tools(domain) self.personas = load_personas(domain) self.scenarios = load_scenarios(domain, category) # Init LLMs self.agent_llm = get_llm(model) self.user_sim_llm = get_llm(USER_SIM_MODEL) self.tool_sim_llm = get_llm(TOOL_SIM_MODEL) # Init components self.tool_simulator = ToolSimulator(self.tool_sim_llm, self.tools) self.agent = LLMAgent(self.agent_llm, self.tool_simulator) self.user_simulator = UserSimulator(self.user_sim_llm) self.history_manager = ConversationHistoryManager() def run(self, scenario_idx): scenario = self.scenarios[scenario_idx] persona = self.personas[scenario['persona_index']] # Init history system_prompt = create_system_prompt(self.tools) history = initialize_history(system_prompt) initial_msg = scenario['first_message'] add_message(history, 'user', initial_msg) tool_outputs = [] for turn in range(1, MAX_TURNS + 1): user_msg = history[-1]['content'] agent_resp, tools_used = self.agent.run(user_msg, history, tool_outputs) add_message(history, 'assistant', agent_resp) tool_outputs.extend(tools_used) user_resp = self.user_simulator.simulate(persona, scenario, history, tool_outputs) add_message(history, 'user', user_resp) if 'COMPLETE' in user_resp: break # Compute metrics metrics = calculate_metrics(tokens, duration, success=True if turn > 0 else False) return metrics def runner(input_data, model, domain, category, results_collector=None): scenario_idx = input_data['scenario_idx'] simulation = AgentSimulation(model, domain, category) results = simulation.run(scenario_idx) results['scenario_idx'] = scenario_idx if results_collector: results_collector.append(results) return json.dumps(results) def run_experiment(experiment_name, project, dataset, function, metrics): # Create or get experiment in Galileo exp = create_or_get_experiment(experiment_name, project) # Initialize results list all_results = [] # Process each dataset item (scenario) for data in dataset: # Apply the provided function (runner) to the data raw_result = function(data) # Parse the JSON result result_dict = json.loads(raw_result) # Log individual run to Galileo with input/output log_run_to_galileo( exp_id=exp.id, input_data=data, output=result_dict, metrics=compute_metrics(result_dict, metrics) ) all_results.append(result_dict) # Compute aggregate metrics aggregate = compute_aggregate_metrics(all_results, metrics) # Update experiment with aggregates update_experiment(exp.id, aggregate) # Return experiment details return { "experiment": exp, "link": generate_view_link(exp.id), "message": "Experiment completed successfully" } def run_experiments(models, domains, categories): for model in models: for domain in domains: for category in categories: if experiment_exists(model, domain, category): continue create_project(model) experiment_name = f"{domain}-{category}" dataset = get_dataset_from_scenarios(domain, category) results_collector = [] run_experiment( experiment_name=experiment_name, project=model, dataset=dataset, function=lambda data: runner(data, model, domain, category, results_collector), metrics=METRICS ) save_results_to_parquet(experiment_name, results_collector)
You can check out the full code in our GitHub repository.
Why Domain-Specific Evaluation Matters
Enterprise applications are rarely about “general” AI. Companies want AI agents tuned to their domain's specific needs, regulations, and workflows. Each sector brings unique challenges: specialized terminology, domain-specific tasks, intricate multi-step workflows, sensitive data, and edge cases that rarely appear in generic benchmarks.
In v1, the lack of isolated domain evaluation meant enterprises couldn’t truly know how a model would perform in their environment. Would an agent excel at healthcare scheduling but struggle with insurance claims? Can it handle financial compliance or telecom troubleshooting with equal reliability? Without targeted benchmarks, such questions went unanswered.
Our evaluation directly addresses this gap. By building datasets that mirror the real challenges of specific domains with domain-specific tools, tasks, and personas, we can now offer organizations actionable insight into model suitability for their use case.
Learnings from The Illusion of Leaderboards
The recent study The Leaderboard Illusion highlights how lax submission rules, hidden tests, and uneven sampling can distort public rankings such as Chatbot Arena.¹ Private “shadow” evaluations let some providers tune dozens of variants before a single public reveal, proprietary models harvest far more evaluation data than open-source peers, and retractions quietly erase poor results. The paper’s core warning is simple: when a leaderboard becomes the metric, it stops measuring real progress.
Agent Leaderboard v2 was designed with these pitfalls in mind.

Practical Implications for AI Engineers
Our evaluation reveals several key considerations for creating robust and efficient systems when developing AI agents. Let's break down the essential aspects.

Build Your Agent Evaluation Engine
After launching this leaderboard, I have learned a lot about agents, and I recently talked to the DAIR.AI community about building the evaluation engine for reliable agents.
Future Work
As Agent Leaderboard continues to evolve, we’re focused on three key initiatives:
Monthly Model Updates
We’ll refresh the benchmark every month to include the latest open- and closed-source models. This cadence ensures you always have up-to-date comparisons as new architectures and fine-tuned variants arrive.Multiagent Evaluation
Real-world workflows often involve chains of specialized agents collaborating to solve complex tasks. We plan to extend our framework to simulate and score multi-agent pipelines for measuring not only individual tool selection but also how well agents coordinate, hand off context, and recover from partial failures in a collective setting.Domain Expansion on Demand
While v2 covers healthcare, finance, telecom, banking, and insurance, we recognize that every organization has unique needs. Going forward, we’ll add new verticals based on user requests and partnership projects. If you would like to collaborate, you can email us with your proposal.
See You In The Comments
We hope you found this helpful and would love to hear from you on LinkedIn, Twitter and GitHub.
Connect with us via these channels for any inquiries.
Email: info@galileo.ai
Twitter: https://x.com/rungalileo
LinkedIn: https://linkedin.com/company/galileo-ai
Contact: research@galileo.ai
You can cite the leaderboard with:
@misc{agent-leaderboard, author = {Pratik Bhavsar}, title = {Agent Leaderboard}, year = {2025}, publisher = {Galileo.ai}, howpublished = "\url{https://huggingface.co/spaces/galileo-ai/agent-leaderboard}" }
Acknowledgements
We extend our sincere gratitude to the creators of the benchmark datasets that made this evaluation framework possible:
BFCL: Thanks to the Berkeley AI Research team for their comprehensive dataset evaluating function calling capabilities.
τ-bench: Thanks to the Sierra Research team for developing this benchmark focusing on real-world tool use scenarios.
xLAM: Thanks to the Salesforce AI Research team for their extensive Large Action Model dataset covering 21 domains.
ToolACE: Thanks to the team for their comprehensive API interaction dataset spanning 390 domains.

TL;DR: What's New in v2
Klarna’s decision to replace 700 customer-service reps with AI backfired so much that they’re now rehiring humans to patch the gaps. They saved money, but customer experience degraded. What if there were a way to catch those failures before flipping the switch?
That’s precisely the problem Agent Leaderboard v2 is built to solve. Rather than simply testing whether an agent can call the right tools, we put AIs through real enterprise scenarios spanning five industries with multi-turn dialogues and complex decision-making.
Key Results as of July 17, 2025:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
→ Explore the Live Leaderboard
What we measure shapes AI. With our Agent Leaderboard initiative, we’re bringing focus back to the ground where real work happens. The Humanity’s Last Exam benchmark is cool, but we must still cover the basics.
A New Benchmark Was Needed
Agent Leaderboard v1 established our foundation for evaluating AI agents, with over 30 LLMs tested across 14 datasets. But as model quality improved, high performance in basic tool-calling became the norm, and several challenges emerged:
Score saturation: Models clustered above 90% made differentiation on performance difficult
Potential benchmark leakage: Public benchmarks may have been incorporated into model training, blurring the lines between genuine generalization and memorization.
Insufficient scenario complexity: While v1 covered a range of domains, most scenarios were static, with little context carry-over, few ambiguous cases, and limited reflection of the messiness of real enterprise deployments.
Limitations of static datasets: Real-world tasks are dynamic and multi-turn. Static, one-shot evaluations miss the complexity of extended, evolving interactions.
No domain isolation: The absence of truly domain-specific datasets made it difficult for enterprises to understand model strengths for their specific agent use cases.
Here is my interview with Latent Space where I talk about the limitations of v1 and my learnings.
These limitations meant the v1 leaderboard was no longer enough to guide enterprises that need agents capable of navigating true complexity of the real world. When hundreds of models score above 80% on simple API-call tests, how do you know which one will handle your real-world customer conversations? How can we get realistic, multi-turn, domain-specific evaluation?
Enter Agent Leaderboard v2: Built for the Enterprise
https://galileo.ai/agent-leaderboard
Agent Leaderboard v2 is a leap forward, simulating realistic support agents across five critical industries at launch: banking, healthcare, investment, telecom, and insurance.
Each domain features 100 synthetic scenarios crafted to reflect the ambiguity, context-dependence, and unpredictability of real-world conversations. Every scenario includes prior chat context, changing user requirements, missing or irrelevant tools, and conditional requests, all driven by synthetic personas representing realistic user types. Agents must coordinate actions over multi-turn dialogues, plan ahead, adapt to new information, and use a suite of domain-specific tools, just like in a real enterprise deployment.
Each scenario features:
Real-world complexity
5-8 interconnected user goals per conversation
Multi-turn dialogues with context dependencies
Dynamic user personas with varying communication styles
Domain-specific tools reflecting actual enterprise APIs
Edge cases and ambiguity that mirror production challenges
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
Where v1 was about checking if the model calls the API with the correct arguments, v2 is about real-world effectiveness: Can the agent actually get the job done for the user, every time, across a wide range of realistic situations?
This is our ranking based on Action Completion. GPT-4.1 comes out at the top.
This is our ranking based on Tool Selection Quality. Gemini 2.5 Flash comes out at the top.
Key Insights
Here are our top model and overall insights as of July 17, 2025:
Model insights:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
Measuring an Agent’s Performance
We center on two complementary pillars—Action Completion and Tool Selection Quality—that together capture what the agent achieves and how it achieves it.
Action Completion
Our Action Completion metric is at the heart of v2: Did the agent fully accomplish every user goal, providing clear answers or confirmations for every ask? This isn’t just about checking off tool calls. Agents must track context across up to eight interdependent user requests.
Action Completion reflects the agent’s ability to fulfill all aspects of a user’s request, not just make the right tool calls or provide partial answers. A high Action Completion score means the assistant provided clear, complete, and accurate outcomes, whether answering questions, confirming task success, or summarizing tool results.
In short, did the agent actually solve the user’s problem?
Tool Selection Quality
The complexity of tool calling extends far beyond simple API invocations. When an agent encounters a query, it must first determine if tool usage is warranted. Information may already exist in the conversation history, making tool calls redundant. Alternatively, available tools might be insufficient or irrelevant to the task, requiring the agent to acknowledge limitations rather than force inappropriate tool usage.
Various scenarios challenge AI agents' ability to make appropriate decisions about tool usage. Tool Selection Quality (TSQ) measures how accurately an AI agent chooses and uses external tools to fulfill a user’s request. A perfect TSQ score means the agent not only picks the right tool but also supplies every required parameter correctly, while avoiding unnecessary or erroneous calls. In agentic systems, subtle mistakes like invoking the wrong API or passing a bad argument can lead to incorrect or harmful outcomes, so TSQ surfaces exactly where and how tool use goes off track.
We compute TSQ by sending each tool call through a dedicated LLM evaluator (Anthropic’s Claude) with a reasoning prompt.
Tool Selection Dynamics
Tool selection involves both precision and recall. An agent might correctly identify one necessary tool while missing others (recall issue) or select appropriate tools alongside unnecessary ones (precision issue). While suboptimal, these scenarios represent different severity levels of selection errors.
Parameter Handling
Even with correct tool selection, argument handling introduces additional complexity. Agents must:
Provide all required parameters with the correct naming
Handle optional parameters appropriately
Maintain parameter value accuracy
Format arguments according to tool specifications
Sequential Decision Making
Multi-step tasks require agents to:
Determine the optimal tool calling sequence
Handle interdependencies between tool calls
Maintain context across multiple operations
Adapt to partial results or failures
The diagram above illustrates the logical flow of how a tool call is processed within an LLM’s internal reasoning. These complexities illustrate why Tool Selection Quality should not be regarded as a simple metric but rather as a multifaceted evaluation of an agent’s decision-making capabilities in real-world scenarios.
Let's understand how we built the dataset to run the simulation to evaluate the LLMs.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and to guarantee functional coverage for each domain. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Response schema for the tool
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "persona_index": 0, "first_message": "Hello, I need to handle several banking matters before I leave for Europe next Thursday. I've been saving for this trip for years through my Premium Savings account. First, I need to report my Platinum credit card as lost yesterday - I think I left it at a restaurant. Also, I'd like to verify my upcoming mortgage payment on the 15th and set up automatic payments for my utility bills from my checking account. Could you also help me find a branch near my hotel in Paris to exchange some currency? I need to know today's euro exchange rate. Oh, and I should probably set up fraud alerts since I'll be traveling abroad for 3 weeks.", "user_goals": [ "Report Platinum credit card as lost and request replacement before international travel", "Verify mortgage payment details for upcoming payment on the 15th", "Set up automatic bill payments for utilities from checking account", "Find information about bank branches near a specific Paris hotel location", "Get current USD to EUR exchange rates for travel planning", "Configure account alerts for international travel to prevent fraud detection issues" ] }, { "persona_index": 1, "first_message": "Hey, I need some major help sorting out my banking situation. I'm traveling to Tokyo next month on the 23rd for a tech conference, but I just realized my credit card expires on the 15th! I also need to make sure my business loan application from last week got processed, set up automatic payments for my AWS hosting bill ($249.99 monthly), check if I can open a high-yield CD for some startup funds I'm not using yet, and update my phone number since I'm switching carriers tomorrow. Oh, and my last card transaction at TechHub for $892.50 was supposed to be only $289.25 - they double-charged me!", "user_goals": [ "Get a replacement credit card before international travel to Japan on the 23rd of next month", "Check status of recently submitted business loan application from approximately 7 days ago", "Set up recurring automatic bill payment for AWS hosting service at $249.99 per month", "Find a high-yield Certificate of Deposit option for temporary startup capital investment (minimum $25,000)", "Update contact information with new phone number before carrier switch tomorrow", "Dispute an incorrect charge of $892.50 at TechHub that should have been $289.25" ] } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed not just on accuracy but also on their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Here is a very high-level pseudocode for the simulation.
class AgentSimulation: def __init__(self, model, domain, category): # Load data self.tools = load_tools(domain) self.personas = load_personas(domain) self.scenarios = load_scenarios(domain, category) # Init LLMs self.agent_llm = get_llm(model) self.user_sim_llm = get_llm(USER_SIM_MODEL) self.tool_sim_llm = get_llm(TOOL_SIM_MODEL) # Init components self.tool_simulator = ToolSimulator(self.tool_sim_llm, self.tools) self.agent = LLMAgent(self.agent_llm, self.tool_simulator) self.user_simulator = UserSimulator(self.user_sim_llm) self.history_manager = ConversationHistoryManager() def run(self, scenario_idx): scenario = self.scenarios[scenario_idx] persona = self.personas[scenario['persona_index']] # Init history system_prompt = create_system_prompt(self.tools) history = initialize_history(system_prompt) initial_msg = scenario['first_message'] add_message(history, 'user', initial_msg) tool_outputs = [] for turn in range(1, MAX_TURNS + 1): user_msg = history[-1]['content'] agent_resp, tools_used = self.agent.run(user_msg, history, tool_outputs) add_message(history, 'assistant', agent_resp) tool_outputs.extend(tools_used) user_resp = self.user_simulator.simulate(persona, scenario, history, tool_outputs) add_message(history, 'user', user_resp) if 'COMPLETE' in user_resp: break # Compute metrics metrics = calculate_metrics(tokens, duration, success=True if turn > 0 else False) return metrics def runner(input_data, model, domain, category, results_collector=None): scenario_idx = input_data['scenario_idx'] simulation = AgentSimulation(model, domain, category) results = simulation.run(scenario_idx) results['scenario_idx'] = scenario_idx if results_collector: results_collector.append(results) return json.dumps(results) def run_experiment(experiment_name, project, dataset, function, metrics): # Create or get experiment in Galileo exp = create_or_get_experiment(experiment_name, project) # Initialize results list all_results = [] # Process each dataset item (scenario) for data in dataset: # Apply the provided function (runner) to the data raw_result = function(data) # Parse the JSON result result_dict = json.loads(raw_result) # Log individual run to Galileo with input/output log_run_to_galileo( exp_id=exp.id, input_data=data, output=result_dict, metrics=compute_metrics(result_dict, metrics) ) all_results.append(result_dict) # Compute aggregate metrics aggregate = compute_aggregate_metrics(all_results, metrics) # Update experiment with aggregates update_experiment(exp.id, aggregate) # Return experiment details return { "experiment": exp, "link": generate_view_link(exp.id), "message": "Experiment completed successfully" } def run_experiments(models, domains, categories): for model in models: for domain in domains: for category in categories: if experiment_exists(model, domain, category): continue create_project(model) experiment_name = f"{domain}-{category}" dataset = get_dataset_from_scenarios(domain, category) results_collector = [] run_experiment( experiment_name=experiment_name, project=model, dataset=dataset, function=lambda data: runner(data, model, domain, category, results_collector), metrics=METRICS ) save_results_to_parquet(experiment_name, results_collector)
You can check out the full code in our GitHub repository.
Why Domain-Specific Evaluation Matters
Enterprise applications are rarely about “general” AI. Companies want AI agents tuned to their domain's specific needs, regulations, and workflows. Each sector brings unique challenges: specialized terminology, domain-specific tasks, intricate multi-step workflows, sensitive data, and edge cases that rarely appear in generic benchmarks.
In v1, the lack of isolated domain evaluation meant enterprises couldn’t truly know how a model would perform in their environment. Would an agent excel at healthcare scheduling but struggle with insurance claims? Can it handle financial compliance or telecom troubleshooting with equal reliability? Without targeted benchmarks, such questions went unanswered.
Our evaluation directly addresses this gap. By building datasets that mirror the real challenges of specific domains with domain-specific tools, tasks, and personas, we can now offer organizations actionable insight into model suitability for their use case.
Learnings from The Illusion of Leaderboards
The recent study The Leaderboard Illusion highlights how lax submission rules, hidden tests, and uneven sampling can distort public rankings such as Chatbot Arena.¹ Private “shadow” evaluations let some providers tune dozens of variants before a single public reveal, proprietary models harvest far more evaluation data than open-source peers, and retractions quietly erase poor results. The paper’s core warning is simple: when a leaderboard becomes the metric, it stops measuring real progress.
Agent Leaderboard v2 was designed with these pitfalls in mind.
Practical Implications for AI Engineers
Our evaluation reveals several key considerations for creating robust and efficient systems when developing AI agents. Let's break down the essential aspects.
Build Your Agent Evaluation Engine
After launching this leaderboard, I have learned a lot about agents, and I recently talked to the DAIR.AI community about building the evaluation engine for reliable agents.
Future Work
As Agent Leaderboard continues to evolve, we’re focused on three key initiatives:
Monthly Model Updates
We’ll refresh the benchmark every month to include the latest open- and closed-source models. This cadence ensures you always have up-to-date comparisons as new architectures and fine-tuned variants arrive.Multiagent Evaluation
Real-world workflows often involve chains of specialized agents collaborating to solve complex tasks. We plan to extend our framework to simulate and score multi-agent pipelines for measuring not only individual tool selection but also how well agents coordinate, hand off context, and recover from partial failures in a collective setting.Domain Expansion on Demand
While v2 covers healthcare, finance, telecom, banking, and insurance, we recognize that every organization has unique needs. Going forward, we’ll add new verticals based on user requests and partnership projects. If you would like to collaborate, you can email us with your proposal.
See You In The Comments
We hope you found this helpful and would love to hear from you on LinkedIn, Twitter and GitHub.
Connect with us via these channels for any inquiries.
Email: info@galileo.ai
Twitter: https://x.com/rungalileo
LinkedIn: https://linkedin.com/company/galileo-ai
Contact: research@galileo.ai
You can cite the leaderboard with:
@misc{agent-leaderboard, author = {Pratik Bhavsar}, title = {Agent Leaderboard}, year = {2025}, publisher = {Galileo.ai}, howpublished = "\url{https://huggingface.co/spaces/galileo-ai/agent-leaderboard}" }
Acknowledgements
We extend our sincere gratitude to the creators of the benchmark datasets that made this evaluation framework possible:
BFCL: Thanks to the Berkeley AI Research team for their comprehensive dataset evaluating function calling capabilities.
τ-bench: Thanks to the Sierra Research team for developing this benchmark focusing on real-world tool use scenarios.
xLAM: Thanks to the Salesforce AI Research team for their extensive Large Action Model dataset covering 21 domains.
ToolACE: Thanks to the team for their comprehensive API interaction dataset spanning 390 domains.
TL;DR: What's New in v2
Klarna’s decision to replace 700 customer-service reps with AI backfired so much that they’re now rehiring humans to patch the gaps. They saved money, but customer experience degraded. What if there were a way to catch those failures before flipping the switch?
That’s precisely the problem Agent Leaderboard v2 is built to solve. Rather than simply testing whether an agent can call the right tools, we put AIs through real enterprise scenarios spanning five industries with multi-turn dialogues and complex decision-making.
Key Results as of July 17, 2025:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
→ Explore the Live Leaderboard
What we measure shapes AI. With our Agent Leaderboard initiative, we’re bringing focus back to the ground where real work happens. The Humanity’s Last Exam benchmark is cool, but we must still cover the basics.
A New Benchmark Was Needed
Agent Leaderboard v1 established our foundation for evaluating AI agents, with over 30 LLMs tested across 14 datasets. But as model quality improved, high performance in basic tool-calling became the norm, and several challenges emerged:
Score saturation: Models clustered above 90% made differentiation on performance difficult
Potential benchmark leakage: Public benchmarks may have been incorporated into model training, blurring the lines between genuine generalization and memorization.
Insufficient scenario complexity: While v1 covered a range of domains, most scenarios were static, with little context carry-over, few ambiguous cases, and limited reflection of the messiness of real enterprise deployments.
Limitations of static datasets: Real-world tasks are dynamic and multi-turn. Static, one-shot evaluations miss the complexity of extended, evolving interactions.
No domain isolation: The absence of truly domain-specific datasets made it difficult for enterprises to understand model strengths for their specific agent use cases.
Here is my interview with Latent Space where I talk about the limitations of v1 and my learnings.
These limitations meant the v1 leaderboard was no longer enough to guide enterprises that need agents capable of navigating true complexity of the real world. When hundreds of models score above 80% on simple API-call tests, how do you know which one will handle your real-world customer conversations? How can we get realistic, multi-turn, domain-specific evaluation?
Enter Agent Leaderboard v2: Built for the Enterprise
https://galileo.ai/agent-leaderboard
Agent Leaderboard v2 is a leap forward, simulating realistic support agents across five critical industries at launch: banking, healthcare, investment, telecom, and insurance.
Each domain features 100 synthetic scenarios crafted to reflect the ambiguity, context-dependence, and unpredictability of real-world conversations. Every scenario includes prior chat context, changing user requirements, missing or irrelevant tools, and conditional requests, all driven by synthetic personas representing realistic user types. Agents must coordinate actions over multi-turn dialogues, plan ahead, adapt to new information, and use a suite of domain-specific tools, just like in a real enterprise deployment.
Each scenario features:
Real-world complexity
5-8 interconnected user goals per conversation
Multi-turn dialogues with context dependencies
Dynamic user personas with varying communication styles
Domain-specific tools reflecting actual enterprise APIs
Edge cases and ambiguity that mirror production challenges
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
Where v1 was about checking if the model calls the API with the correct arguments, v2 is about real-world effectiveness: Can the agent actually get the job done for the user, every time, across a wide range of realistic situations?
This is our ranking based on Action Completion. GPT-4.1 comes out at the top.
This is our ranking based on Tool Selection Quality. Gemini 2.5 Flash comes out at the top.
Key Insights
Here are our top model and overall insights as of July 17, 2025:
Model insights:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
Measuring an Agent’s Performance
We center on two complementary pillars—Action Completion and Tool Selection Quality—that together capture what the agent achieves and how it achieves it.
Action Completion
Our Action Completion metric is at the heart of v2: Did the agent fully accomplish every user goal, providing clear answers or confirmations for every ask? This isn’t just about checking off tool calls. Agents must track context across up to eight interdependent user requests.
Action Completion reflects the agent’s ability to fulfill all aspects of a user’s request, not just make the right tool calls or provide partial answers. A high Action Completion score means the assistant provided clear, complete, and accurate outcomes, whether answering questions, confirming task success, or summarizing tool results.
In short, did the agent actually solve the user’s problem?
Tool Selection Quality
The complexity of tool calling extends far beyond simple API invocations. When an agent encounters a query, it must first determine if tool usage is warranted. Information may already exist in the conversation history, making tool calls redundant. Alternatively, available tools might be insufficient or irrelevant to the task, requiring the agent to acknowledge limitations rather than force inappropriate tool usage.
Various scenarios challenge AI agents' ability to make appropriate decisions about tool usage. Tool Selection Quality (TSQ) measures how accurately an AI agent chooses and uses external tools to fulfill a user’s request. A perfect TSQ score means the agent not only picks the right tool but also supplies every required parameter correctly, while avoiding unnecessary or erroneous calls. In agentic systems, subtle mistakes like invoking the wrong API or passing a bad argument can lead to incorrect or harmful outcomes, so TSQ surfaces exactly where and how tool use goes off track.
We compute TSQ by sending each tool call through a dedicated LLM evaluator (Anthropic’s Claude) with a reasoning prompt.
Tool Selection Dynamics
Tool selection involves both precision and recall. An agent might correctly identify one necessary tool while missing others (recall issue) or select appropriate tools alongside unnecessary ones (precision issue). While suboptimal, these scenarios represent different severity levels of selection errors.
Parameter Handling
Even with correct tool selection, argument handling introduces additional complexity. Agents must:
Provide all required parameters with the correct naming
Handle optional parameters appropriately
Maintain parameter value accuracy
Format arguments according to tool specifications
Sequential Decision Making
Multi-step tasks require agents to:
Determine the optimal tool calling sequence
Handle interdependencies between tool calls
Maintain context across multiple operations
Adapt to partial results or failures
The diagram above illustrates the logical flow of how a tool call is processed within an LLM’s internal reasoning. These complexities illustrate why Tool Selection Quality should not be regarded as a simple metric but rather as a multifaceted evaluation of an agent’s decision-making capabilities in real-world scenarios.
Let's understand how we built the dataset to run the simulation to evaluate the LLMs.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and to guarantee functional coverage for each domain. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Response schema for the tool
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "persona_index": 0, "first_message": "Hello, I need to handle several banking matters before I leave for Europe next Thursday. I've been saving for this trip for years through my Premium Savings account. First, I need to report my Platinum credit card as lost yesterday - I think I left it at a restaurant. Also, I'd like to verify my upcoming mortgage payment on the 15th and set up automatic payments for my utility bills from my checking account. Could you also help me find a branch near my hotel in Paris to exchange some currency? I need to know today's euro exchange rate. Oh, and I should probably set up fraud alerts since I'll be traveling abroad for 3 weeks.", "user_goals": [ "Report Platinum credit card as lost and request replacement before international travel", "Verify mortgage payment details for upcoming payment on the 15th", "Set up automatic bill payments for utilities from checking account", "Find information about bank branches near a specific Paris hotel location", "Get current USD to EUR exchange rates for travel planning", "Configure account alerts for international travel to prevent fraud detection issues" ] }, { "persona_index": 1, "first_message": "Hey, I need some major help sorting out my banking situation. I'm traveling to Tokyo next month on the 23rd for a tech conference, but I just realized my credit card expires on the 15th! I also need to make sure my business loan application from last week got processed, set up automatic payments for my AWS hosting bill ($249.99 monthly), check if I can open a high-yield CD for some startup funds I'm not using yet, and update my phone number since I'm switching carriers tomorrow. Oh, and my last card transaction at TechHub for $892.50 was supposed to be only $289.25 - they double-charged me!", "user_goals": [ "Get a replacement credit card before international travel to Japan on the 23rd of next month", "Check status of recently submitted business loan application from approximately 7 days ago", "Set up recurring automatic bill payment for AWS hosting service at $249.99 per month", "Find a high-yield Certificate of Deposit option for temporary startup capital investment (minimum $25,000)", "Update contact information with new phone number before carrier switch tomorrow", "Dispute an incorrect charge of $892.50 at TechHub that should have been $289.25" ] } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed not just on accuracy but also on their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Here is a very high-level pseudocode for the simulation.
class AgentSimulation: def __init__(self, model, domain, category): # Load data self.tools = load_tools(domain) self.personas = load_personas(domain) self.scenarios = load_scenarios(domain, category) # Init LLMs self.agent_llm = get_llm(model) self.user_sim_llm = get_llm(USER_SIM_MODEL) self.tool_sim_llm = get_llm(TOOL_SIM_MODEL) # Init components self.tool_simulator = ToolSimulator(self.tool_sim_llm, self.tools) self.agent = LLMAgent(self.agent_llm, self.tool_simulator) self.user_simulator = UserSimulator(self.user_sim_llm) self.history_manager = ConversationHistoryManager() def run(self, scenario_idx): scenario = self.scenarios[scenario_idx] persona = self.personas[scenario['persona_index']] # Init history system_prompt = create_system_prompt(self.tools) history = initialize_history(system_prompt) initial_msg = scenario['first_message'] add_message(history, 'user', initial_msg) tool_outputs = [] for turn in range(1, MAX_TURNS + 1): user_msg = history[-1]['content'] agent_resp, tools_used = self.agent.run(user_msg, history, tool_outputs) add_message(history, 'assistant', agent_resp) tool_outputs.extend(tools_used) user_resp = self.user_simulator.simulate(persona, scenario, history, tool_outputs) add_message(history, 'user', user_resp) if 'COMPLETE' in user_resp: break # Compute metrics metrics = calculate_metrics(tokens, duration, success=True if turn > 0 else False) return metrics def runner(input_data, model, domain, category, results_collector=None): scenario_idx = input_data['scenario_idx'] simulation = AgentSimulation(model, domain, category) results = simulation.run(scenario_idx) results['scenario_idx'] = scenario_idx if results_collector: results_collector.append(results) return json.dumps(results) def run_experiment(experiment_name, project, dataset, function, metrics): # Create or get experiment in Galileo exp = create_or_get_experiment(experiment_name, project) # Initialize results list all_results = [] # Process each dataset item (scenario) for data in dataset: # Apply the provided function (runner) to the data raw_result = function(data) # Parse the JSON result result_dict = json.loads(raw_result) # Log individual run to Galileo with input/output log_run_to_galileo( exp_id=exp.id, input_data=data, output=result_dict, metrics=compute_metrics(result_dict, metrics) ) all_results.append(result_dict) # Compute aggregate metrics aggregate = compute_aggregate_metrics(all_results, metrics) # Update experiment with aggregates update_experiment(exp.id, aggregate) # Return experiment details return { "experiment": exp, "link": generate_view_link(exp.id), "message": "Experiment completed successfully" } def run_experiments(models, domains, categories): for model in models: for domain in domains: for category in categories: if experiment_exists(model, domain, category): continue create_project(model) experiment_name = f"{domain}-{category}" dataset = get_dataset_from_scenarios(domain, category) results_collector = [] run_experiment( experiment_name=experiment_name, project=model, dataset=dataset, function=lambda data: runner(data, model, domain, category, results_collector), metrics=METRICS ) save_results_to_parquet(experiment_name, results_collector)
You can check out the full code in our GitHub repository.
Why Domain-Specific Evaluation Matters
Enterprise applications are rarely about “general” AI. Companies want AI agents tuned to their domain's specific needs, regulations, and workflows. Each sector brings unique challenges: specialized terminology, domain-specific tasks, intricate multi-step workflows, sensitive data, and edge cases that rarely appear in generic benchmarks.
In v1, the lack of isolated domain evaluation meant enterprises couldn’t truly know how a model would perform in their environment. Would an agent excel at healthcare scheduling but struggle with insurance claims? Can it handle financial compliance or telecom troubleshooting with equal reliability? Without targeted benchmarks, such questions went unanswered.
Our evaluation directly addresses this gap. By building datasets that mirror the real challenges of specific domains with domain-specific tools, tasks, and personas, we can now offer organizations actionable insight into model suitability for their use case.
Learnings from The Illusion of Leaderboards
The recent study The Leaderboard Illusion highlights how lax submission rules, hidden tests, and uneven sampling can distort public rankings such as Chatbot Arena.¹ Private “shadow” evaluations let some providers tune dozens of variants before a single public reveal, proprietary models harvest far more evaluation data than open-source peers, and retractions quietly erase poor results. The paper’s core warning is simple: when a leaderboard becomes the metric, it stops measuring real progress.
Agent Leaderboard v2 was designed with these pitfalls in mind.
Practical Implications for AI Engineers
Our evaluation reveals several key considerations for creating robust and efficient systems when developing AI agents. Let's break down the essential aspects.
Build Your Agent Evaluation Engine
After launching this leaderboard, I have learned a lot about agents, and I recently talked to the DAIR.AI community about building the evaluation engine for reliable agents.
Future Work
As Agent Leaderboard continues to evolve, we’re focused on three key initiatives:
Monthly Model Updates
We’ll refresh the benchmark every month to include the latest open- and closed-source models. This cadence ensures you always have up-to-date comparisons as new architectures and fine-tuned variants arrive.Multiagent Evaluation
Real-world workflows often involve chains of specialized agents collaborating to solve complex tasks. We plan to extend our framework to simulate and score multi-agent pipelines for measuring not only individual tool selection but also how well agents coordinate, hand off context, and recover from partial failures in a collective setting.Domain Expansion on Demand
While v2 covers healthcare, finance, telecom, banking, and insurance, we recognize that every organization has unique needs. Going forward, we’ll add new verticals based on user requests and partnership projects. If you would like to collaborate, you can email us with your proposal.
See You In The Comments
We hope you found this helpful and would love to hear from you on LinkedIn, Twitter and GitHub.
Connect with us via these channels for any inquiries.
Email: info@galileo.ai
Twitter: https://x.com/rungalileo
LinkedIn: https://linkedin.com/company/galileo-ai
Contact: research@galileo.ai
You can cite the leaderboard with:
@misc{agent-leaderboard, author = {Pratik Bhavsar}, title = {Agent Leaderboard}, year = {2025}, publisher = {Galileo.ai}, howpublished = "\url{https://huggingface.co/spaces/galileo-ai/agent-leaderboard}" }
Acknowledgements
We extend our sincere gratitude to the creators of the benchmark datasets that made this evaluation framework possible:
BFCL: Thanks to the Berkeley AI Research team for their comprehensive dataset evaluating function calling capabilities.
τ-bench: Thanks to the Sierra Research team for developing this benchmark focusing on real-world tool use scenarios.
xLAM: Thanks to the Salesforce AI Research team for their extensive Large Action Model dataset covering 21 domains.
ToolACE: Thanks to the team for their comprehensive API interaction dataset spanning 390 domains.
TL;DR: What's New in v2
Klarna’s decision to replace 700 customer-service reps with AI backfired so much that they’re now rehiring humans to patch the gaps. They saved money, but customer experience degraded. What if there were a way to catch those failures before flipping the switch?
That’s precisely the problem Agent Leaderboard v2 is built to solve. Rather than simply testing whether an agent can call the right tools, we put AIs through real enterprise scenarios spanning five industries with multi-turn dialogues and complex decision-making.
Key Results as of July 17, 2025:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
→ Explore the Live Leaderboard
What we measure shapes AI. With our Agent Leaderboard initiative, we’re bringing focus back to the ground where real work happens. The Humanity’s Last Exam benchmark is cool, but we must still cover the basics.
A New Benchmark Was Needed
Agent Leaderboard v1 established our foundation for evaluating AI agents, with over 30 LLMs tested across 14 datasets. But as model quality improved, high performance in basic tool-calling became the norm, and several challenges emerged:
Score saturation: Models clustered above 90% made differentiation on performance difficult
Potential benchmark leakage: Public benchmarks may have been incorporated into model training, blurring the lines between genuine generalization and memorization.
Insufficient scenario complexity: While v1 covered a range of domains, most scenarios were static, with little context carry-over, few ambiguous cases, and limited reflection of the messiness of real enterprise deployments.
Limitations of static datasets: Real-world tasks are dynamic and multi-turn. Static, one-shot evaluations miss the complexity of extended, evolving interactions.
No domain isolation: The absence of truly domain-specific datasets made it difficult for enterprises to understand model strengths for their specific agent use cases.
Here is my interview with Latent Space where I talk about the limitations of v1 and my learnings.
These limitations meant the v1 leaderboard was no longer enough to guide enterprises that need agents capable of navigating true complexity of the real world. When hundreds of models score above 80% on simple API-call tests, how do you know which one will handle your real-world customer conversations? How can we get realistic, multi-turn, domain-specific evaluation?
Enter Agent Leaderboard v2: Built for the Enterprise
https://galileo.ai/agent-leaderboard
Agent Leaderboard v2 is a leap forward, simulating realistic support agents across five critical industries at launch: banking, healthcare, investment, telecom, and insurance.
Each domain features 100 synthetic scenarios crafted to reflect the ambiguity, context-dependence, and unpredictability of real-world conversations. Every scenario includes prior chat context, changing user requirements, missing or irrelevant tools, and conditional requests, all driven by synthetic personas representing realistic user types. Agents must coordinate actions over multi-turn dialogues, plan ahead, adapt to new information, and use a suite of domain-specific tools, just like in a real enterprise deployment.
Each scenario features:
Real-world complexity
5-8 interconnected user goals per conversation
Multi-turn dialogues with context dependencies
Dynamic user personas with varying communication styles
Domain-specific tools reflecting actual enterprise APIs
Edge cases and ambiguity that mirror production challenges
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
Where v1 was about checking if the model calls the API with the correct arguments, v2 is about real-world effectiveness: Can the agent actually get the job done for the user, every time, across a wide range of realistic situations?
This is our ranking based on Action Completion. GPT-4.1 comes out at the top.
This is our ranking based on Tool Selection Quality. Gemini 2.5 Flash comes out at the top.
Key Insights
Here are our top model and overall insights as of July 17, 2025:
Model insights:
GPT-4.1 leads with an average Action Completion (AC) score of 62% across all domains.
Gemini-2.5-flash excels at tool selection (94% TSQ) but struggles with task completion (38% AC).
GPT-4.1-mini delivers exceptional value at $0.014 per session versus $0.068 for GPT-4.1.
Performance varies dramatically by industry—no single model dominates all domains.
Grok 4 did not capture the top spot in any domain or metric.
Reasoning models generally lag behind non-reasoning models in overall Action Completion.
Kimi’s K2 (new open-source entrant) leads open-source models with a 0.53 AC score and 0.90 TSQ at an affordable $0.039 per session.
Measuring an Agent’s Performance
We center on two complementary pillars—Action Completion and Tool Selection Quality—that together capture what the agent achieves and how it achieves it.
Action Completion
Our Action Completion metric is at the heart of v2: Did the agent fully accomplish every user goal, providing clear answers or confirmations for every ask? This isn’t just about checking off tool calls. Agents must track context across up to eight interdependent user requests.
Action Completion reflects the agent’s ability to fulfill all aspects of a user’s request, not just make the right tool calls or provide partial answers. A high Action Completion score means the assistant provided clear, complete, and accurate outcomes, whether answering questions, confirming task success, or summarizing tool results.
In short, did the agent actually solve the user’s problem?
Tool Selection Quality
The complexity of tool calling extends far beyond simple API invocations. When an agent encounters a query, it must first determine if tool usage is warranted. Information may already exist in the conversation history, making tool calls redundant. Alternatively, available tools might be insufficient or irrelevant to the task, requiring the agent to acknowledge limitations rather than force inappropriate tool usage.
Various scenarios challenge AI agents' ability to make appropriate decisions about tool usage. Tool Selection Quality (TSQ) measures how accurately an AI agent chooses and uses external tools to fulfill a user’s request. A perfect TSQ score means the agent not only picks the right tool but also supplies every required parameter correctly, while avoiding unnecessary or erroneous calls. In agentic systems, subtle mistakes like invoking the wrong API or passing a bad argument can lead to incorrect or harmful outcomes, so TSQ surfaces exactly where and how tool use goes off track.
We compute TSQ by sending each tool call through a dedicated LLM evaluator (Anthropic’s Claude) with a reasoning prompt.
Tool Selection Dynamics
Tool selection involves both precision and recall. An agent might correctly identify one necessary tool while missing others (recall issue) or select appropriate tools alongside unnecessary ones (precision issue). While suboptimal, these scenarios represent different severity levels of selection errors.
Parameter Handling
Even with correct tool selection, argument handling introduces additional complexity. Agents must:
Provide all required parameters with the correct naming
Handle optional parameters appropriately
Maintain parameter value accuracy
Format arguments according to tool specifications
Sequential Decision Making
Multi-step tasks require agents to:
Determine the optimal tool calling sequence
Handle interdependencies between tool calls
Maintain context across multiple operations
Adapt to partial results or failures
The diagram above illustrates the logical flow of how a tool call is processed within an LLM’s internal reasoning. These complexities illustrate why Tool Selection Quality should not be regarded as a simple metric but rather as a multifaceted evaluation of an agent’s decision-making capabilities in real-world scenarios.
Let's understand how we built the dataset to run the simulation to evaluate the LLMs.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and to guarantee functional coverage for each domain. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Response schema for the tool
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "persona_index": 0, "first_message": "Hello, I need to handle several banking matters before I leave for Europe next Thursday. I've been saving for this trip for years through my Premium Savings account. First, I need to report my Platinum credit card as lost yesterday - I think I left it at a restaurant. Also, I'd like to verify my upcoming mortgage payment on the 15th and set up automatic payments for my utility bills from my checking account. Could you also help me find a branch near my hotel in Paris to exchange some currency? I need to know today's euro exchange rate. Oh, and I should probably set up fraud alerts since I'll be traveling abroad for 3 weeks.", "user_goals": [ "Report Platinum credit card as lost and request replacement before international travel", "Verify mortgage payment details for upcoming payment on the 15th", "Set up automatic bill payments for utilities from checking account", "Find information about bank branches near a specific Paris hotel location", "Get current USD to EUR exchange rates for travel planning", "Configure account alerts for international travel to prevent fraud detection issues" ] }, { "persona_index": 1, "first_message": "Hey, I need some major help sorting out my banking situation. I'm traveling to Tokyo next month on the 23rd for a tech conference, but I just realized my credit card expires on the 15th! I also need to make sure my business loan application from last week got processed, set up automatic payments for my AWS hosting bill ($249.99 monthly), check if I can open a high-yield CD for some startup funds I'm not using yet, and update my phone number since I'm switching carriers tomorrow. Oh, and my last card transaction at TechHub for $892.50 was supposed to be only $289.25 - they double-charged me!", "user_goals": [ "Get a replacement credit card before international travel to Japan on the 23rd of next month", "Check status of recently submitted business loan application from approximately 7 days ago", "Set up recurring automatic bill payment for AWS hosting service at $249.99 per month", "Find a high-yield Certificate of Deposit option for temporary startup capital investment (minimum $25,000)", "Update contact information with new phone number before carrier switch tomorrow", "Dispute an incorrect charge of $892.50 at TechHub that should have been $289.25" ] } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed not just on accuracy but also on their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Here is a very high-level pseudocode for the simulation.
class AgentSimulation: def __init__(self, model, domain, category): # Load data self.tools = load_tools(domain) self.personas = load_personas(domain) self.scenarios = load_scenarios(domain, category) # Init LLMs self.agent_llm = get_llm(model) self.user_sim_llm = get_llm(USER_SIM_MODEL) self.tool_sim_llm = get_llm(TOOL_SIM_MODEL) # Init components self.tool_simulator = ToolSimulator(self.tool_sim_llm, self.tools) self.agent = LLMAgent(self.agent_llm, self.tool_simulator) self.user_simulator = UserSimulator(self.user_sim_llm) self.history_manager = ConversationHistoryManager() def run(self, scenario_idx): scenario = self.scenarios[scenario_idx] persona = self.personas[scenario['persona_index']] # Init history system_prompt = create_system_prompt(self.tools) history = initialize_history(system_prompt) initial_msg = scenario['first_message'] add_message(history, 'user', initial_msg) tool_outputs = [] for turn in range(1, MAX_TURNS + 1): user_msg = history[-1]['content'] agent_resp, tools_used = self.agent.run(user_msg, history, tool_outputs) add_message(history, 'assistant', agent_resp) tool_outputs.extend(tools_used) user_resp = self.user_simulator.simulate(persona, scenario, history, tool_outputs) add_message(history, 'user', user_resp) if 'COMPLETE' in user_resp: break # Compute metrics metrics = calculate_metrics(tokens, duration, success=True if turn > 0 else False) return metrics def runner(input_data, model, domain, category, results_collector=None): scenario_idx = input_data['scenario_idx'] simulation = AgentSimulation(model, domain, category) results = simulation.run(scenario_idx) results['scenario_idx'] = scenario_idx if results_collector: results_collector.append(results) return json.dumps(results) def run_experiment(experiment_name, project, dataset, function, metrics): # Create or get experiment in Galileo exp = create_or_get_experiment(experiment_name, project) # Initialize results list all_results = [] # Process each dataset item (scenario) for data in dataset: # Apply the provided function (runner) to the data raw_result = function(data) # Parse the JSON result result_dict = json.loads(raw_result) # Log individual run to Galileo with input/output log_run_to_galileo( exp_id=exp.id, input_data=data, output=result_dict, metrics=compute_metrics(result_dict, metrics) ) all_results.append(result_dict) # Compute aggregate metrics aggregate = compute_aggregate_metrics(all_results, metrics) # Update experiment with aggregates update_experiment(exp.id, aggregate) # Return experiment details return { "experiment": exp, "link": generate_view_link(exp.id), "message": "Experiment completed successfully" } def run_experiments(models, domains, categories): for model in models: for domain in domains: for category in categories: if experiment_exists(model, domain, category): continue create_project(model) experiment_name = f"{domain}-{category}" dataset = get_dataset_from_scenarios(domain, category) results_collector = [] run_experiment( experiment_name=experiment_name, project=model, dataset=dataset, function=lambda data: runner(data, model, domain, category, results_collector), metrics=METRICS ) save_results_to_parquet(experiment_name, results_collector)
You can check out the full code in our GitHub repository.
Why Domain-Specific Evaluation Matters
Enterprise applications are rarely about “general” AI. Companies want AI agents tuned to their domain's specific needs, regulations, and workflows. Each sector brings unique challenges: specialized terminology, domain-specific tasks, intricate multi-step workflows, sensitive data, and edge cases that rarely appear in generic benchmarks.
In v1, the lack of isolated domain evaluation meant enterprises couldn’t truly know how a model would perform in their environment. Would an agent excel at healthcare scheduling but struggle with insurance claims? Can it handle financial compliance or telecom troubleshooting with equal reliability? Without targeted benchmarks, such questions went unanswered.
Our evaluation directly addresses this gap. By building datasets that mirror the real challenges of specific domains with domain-specific tools, tasks, and personas, we can now offer organizations actionable insight into model suitability for their use case.
Learnings from The Illusion of Leaderboards
The recent study The Leaderboard Illusion highlights how lax submission rules, hidden tests, and uneven sampling can distort public rankings such as Chatbot Arena.¹ Private “shadow” evaluations let some providers tune dozens of variants before a single public reveal, proprietary models harvest far more evaluation data than open-source peers, and retractions quietly erase poor results. The paper’s core warning is simple: when a leaderboard becomes the metric, it stops measuring real progress.
Agent Leaderboard v2 was designed with these pitfalls in mind.
Practical Implications for AI Engineers
Our evaluation reveals several key considerations for creating robust and efficient systems when developing AI agents. Let's break down the essential aspects.
Build Your Agent Evaluation Engine
After launching this leaderboard, I have learned a lot about agents, and I recently talked to the DAIR.AI community about building the evaluation engine for reliable agents.
Future Work
As Agent Leaderboard continues to evolve, we’re focused on three key initiatives:
Monthly Model Updates
We’ll refresh the benchmark every month to include the latest open- and closed-source models. This cadence ensures you always have up-to-date comparisons as new architectures and fine-tuned variants arrive.Multiagent Evaluation
Real-world workflows often involve chains of specialized agents collaborating to solve complex tasks. We plan to extend our framework to simulate and score multi-agent pipelines for measuring not only individual tool selection but also how well agents coordinate, hand off context, and recover from partial failures in a collective setting.Domain Expansion on Demand
While v2 covers healthcare, finance, telecom, banking, and insurance, we recognize that every organization has unique needs. Going forward, we’ll add new verticals based on user requests and partnership projects. If you would like to collaborate, you can email us with your proposal.
See You In The Comments
We hope you found this helpful and would love to hear from you on LinkedIn, Twitter and GitHub.
Connect with us via these channels for any inquiries.
Email: info@galileo.ai
Twitter: https://x.com/rungalileo
LinkedIn: https://linkedin.com/company/galileo-ai
Contact: research@galileo.ai
You can cite the leaderboard with:
@misc{agent-leaderboard, author = {Pratik Bhavsar}, title = {Agent Leaderboard}, year = {2025}, publisher = {Galileo.ai}, howpublished = "\url{https://huggingface.co/spaces/galileo-ai/agent-leaderboard}" }
Acknowledgements
We extend our sincere gratitude to the creators of the benchmark datasets that made this evaluation framework possible:
BFCL: Thanks to the Berkeley AI Research team for their comprehensive dataset evaluating function calling capabilities.
τ-bench: Thanks to the Sierra Research team for developing this benchmark focusing on real-world tool use scenarios.
xLAM: Thanks to the Salesforce AI Research team for their extensive Large Action Model dataset covering 21 domains.
ToolACE: Thanks to the team for their comprehensive API interaction dataset spanning 390 domains.

Pratik Bhavsar