

You've seen the headlines: a single misfired AI agent derails a customer journey, and the bill lands on the company’s balance sheet. Benchmarks now show autonomous agents still finish barely half the tasks you give them, clocking in at a 50% success rate across common workflows, hardly production-grade reliability for revenue-bearing systems.
Microsoft's taxonomy of failure modes underscores why: security lapses, hallucinations, memory poisoning, and planning loops lurk inside every complex chain of thought.
When an agent can book flights, move money, or push code without pausing for human approval, each hidden flaw scales instantly. You need guardrails that translate policy into verifiable controls, surface failures before customers notice, and adapt as threats evolve.
If you want reliable AI agents, the following eight steps lay out a framework for deploying live AI agents in production, so you can implement autonomy without betting the business on chance.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
Guardrailing AI agent step #1: Translate policies into verifiable guardrails
You probably already track model accuracy, yet the first failures often stem from something less obvious: vague corporate policies. "Maintain privacy" sounds clear to executives, but your agent can't enforce a concept it can't parse.
This policy-to-practice gap creates compliance risk when AI systems can't interpret abstract guidelines.
Closing this gap requires converting every paragraph of your privacy, security, and brand guidelines into machine-verifiable decision nodes. Deterministic guardrails that fire consistently provide the predictability that regulators expect.
The most effective approach uses a two-stage conversion process:
POLICY-TREE-GEN breaks long prose into explicit conditional rules
POLICY-AS-PROMPT transforms each rule into a lightweight classifier prompt
Galileo automates this entire workflow in production, creating classifiers that run in line with every agent action. Galileo flag violations, log context, and block problematic outputs before they reach your users.

Guardrailing AI agent step #2: Deploy comprehensive agent metrics for full-spectrum monitoring
Traditional latency dashboards miss the nuanced ways AI agents fail. Picture this: Your metrics show green across the board, yet an autonomous travel agent quietly picks the wrong API, loops endlessly, then delivers half-finished itineraries.
These silent failures slip past conventional monitoring built for deterministic software, leaving you blind until customers complain.
In your agent monitoring, you can expose these hidden cracks through five complementary dimensions:
Agentic performance metrics: Measure how well your AI agents perform complex, multi-step tasks—especially when those agents need to use tools, make decisions, or interact with external systems.
Expression and readability metrics: Evaluate how well your AI agent communicates, not just what it says, but how it says it. These metrics are essential when you want your AI to produce content that is clear, on-brand, and easy for users to understand.
Model confidence metrics: Gauge the certainty of your AI agent's answers. These metrics are useful for flagging uncertain responses, improving reliability, and knowing when to involve a human in the loop.
Response quality metrics: Measure how well your AI agent answers user questions, follows instructions, and provides useful information. These metrics are key for building reliable, helpful, and user-friendly AI applications.
Safety and compliance metrics: Ensure your AI agents are safe, fair, and meet regulatory requirements. These metrics are essential for protecting users, avoiding harmful outputs, and building trust in your AI applications.
Modern platforms like Galileo wire these signals into real-time alerts and trend reports. For instance, when prompt perplexity suddenly spikes, you know hallucination risk is climbing. A dip in action completion flags broken tool chains.
You trade reactive firefighting for proactive tuning, catching anomalies hours before they reach production.
Guardrailing AI agent step #3: Enforce role-based tool access controls
Permission creep isn't theoretical; it enabled an agent to wipe a production database once it gained unrestricted terminal access. Agents start with harmless read-only API keys, then quietly accumulate privileges until they can issue shell commands.
Failures like memory poisoning, where malicious instructions linger in long-term storage, amplify the danger because agents can resurrect those instructions later without supervision.
Real-time monitoring stops that escalation cold. Instrument every tool call to track invocation patterns and scope boundaries. The moment an agent reaches for a capability it never needed, you'll know.
Runtime policy engines with role-based access control (RBAC) make this straightforward: define allowlists once, and the system enforces them continually.
To avoid building from the ground up, Galileo's platform-level RBAC maps your existing org roles to agent capabilities without code changes, even at token granularity. Each request carries a signed token specifying which APIs, files, and third-party tools the agent can access.
Audit logs capture every access decision, proving compliance while eliminating the silent privilege creep that turns minor oversights into catastrophic outages.
Guardrailing AI agent step #4: Cluster similar failures for faster root cause analysis
Production agents generate thousands of observations every hour, making manual analysis impossible. You've probably tried skimming trace logs after an incident, only to realize the real problem hid dozens of steps earlier. Human eyes can't keep up with the volume or complexity of modern AI agents' failures.
Purpose-built observability tools like Galileo's Insights Engine automatically cluster these anomalies: hallucinated citations, tool selection dead-ends, planning loops, and even the subtler memory poisoning paths.
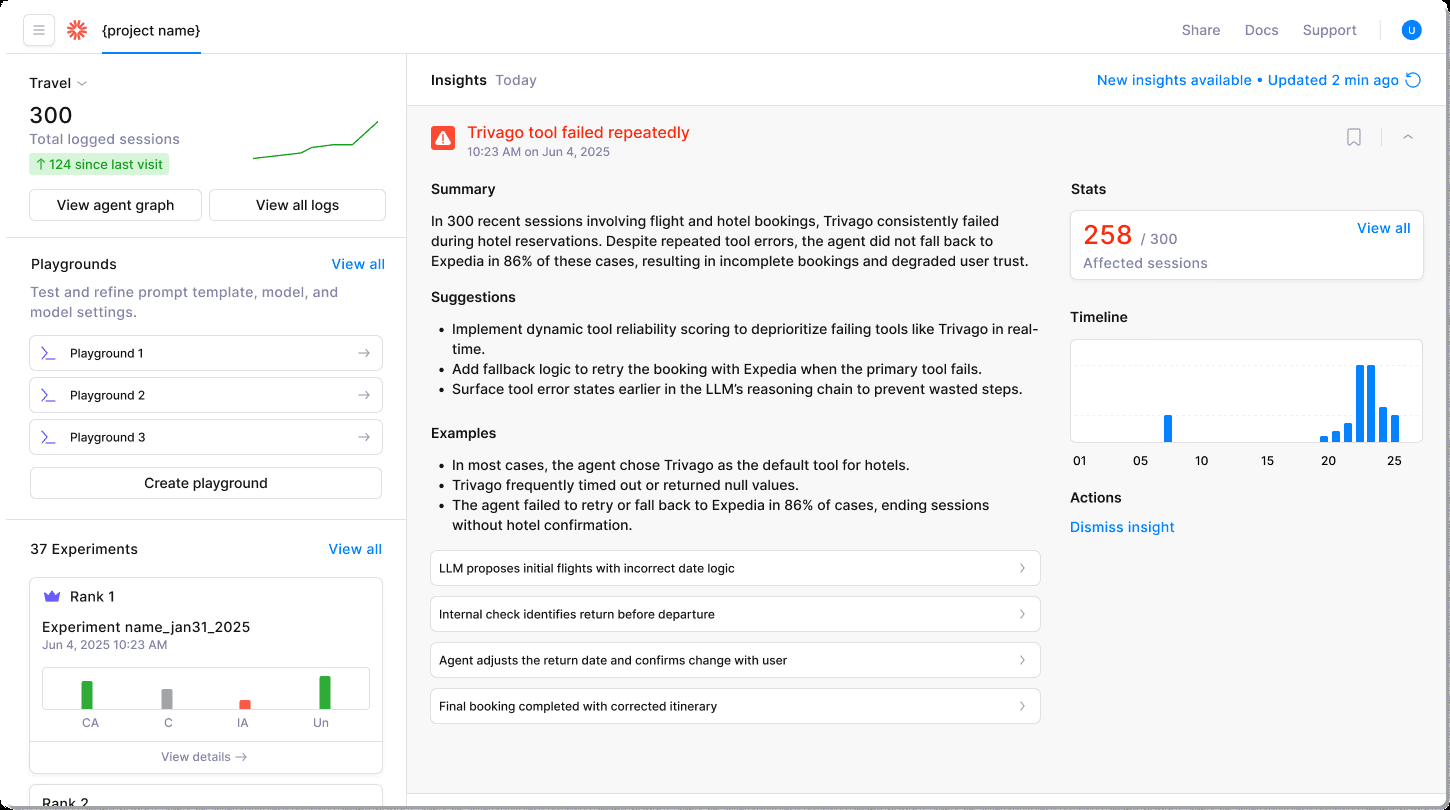
Because traces with similar signatures converge in the same cluster, you jump straight to root causes instead of replaying entire sessions.
Galileo also pairs every cluster with live metrics—frequency, severity, and recency—so you can set precision thresholds that trigger real-time alerts when risk crosses your tolerance. One click on the alert pivots you into a drill-down view that surfaces the offending prompt, decision chain, and downstream impact.
Hours of log-hunting collapse into minutes of targeted investigation, freeing you to focus on fixes instead of forensic guesswork.
Guardrailing AI agent step #5: Intercept harmful responses before user exposure
When agents fail, they often spiral into errors or risky behavior that reaches your users. One developer watched an LLM-generated script erase a production database after a single misguided prompt. These moments expose how thin the margin is between impressive automation and catastrophic loss.
Runtime guardrails work like highway crash barriers: always present, invisible until needed, and utterly predictable in response. By scanning every token before it leaves the model, deterministic systems ensure identical safety actions for identical inputs—the predictability enterprises need for trust.
Galileo's Agent Protect further sits inline, inspecting each response against your security and compliance policies in under 0.3 ms. Even at 5 million calls per day, it either passes content through, rewrites it, or overrides it completely.

Precision thresholds and allow-lists give you surgical control over PII leaks, rogue commands, and toxic language before they ever reach production logs or customer screens.
Guardrailing AI agent step #6: Scale evaluation without budget constraints
Most teams can't afford to evaluate every agent decision because GPT-4 evaluation costs quickly exceed actual model inference spend. When scoring becomes more expensive than running the agent, coverage drops and failures slip through undetected.
This creates an impossible choice: comprehensive evaluation that destroys budgets, or affordable spot-checking that misses critical failures. Teams rationing their evaluation budget face the exact blind spots that cause production incidents.
Small language models like Galileo's Luna-2 solve this economic constraint. Purpose-built for evaluation tasks, Luna-2 delivers assessment scores in under 200 milliseconds at roughly 3% of GPT-4's cost.

You can now evaluate every tool call, planning step, and agent response without budget concerns. The lightweight architecture integrates directly into your agent stack without additional infrastructure complexity.
Connect Luna-2 to your deployment pipelines and production monitoring systems. Set automated thresholds for hallucination detection, context drift, and safety violations. Reserve human reviewers only for borderline cases that require nuanced judgment.
With this, you can achieve 97% evaluation cost reduction while getting 100% traffic coverage, complete visibility without the traditional cost penalty.
Guardrailing AI agent step #7: Adapt guardrails with Continuous Learning via Human Feedback (CLHF)
Static guardrails age quickly. As your agents take on new tasks and encounter novel prompts, yesterday's "safe" rules start firing false positives while genuine threats slip through unnoticed. You feel the pain when support tickets spike because an over-zealous filter blocks harmless queries—or worse, when a toxic response sneaks past a stale policy.
You can spot this guardrail drift by tracking precision and recall over time. Rising false-positive rates flag over-blocking; climbing false negatives reveal eroding coverage. Once drift appears, the fix isn't another brittle regex.
Instead, capture the offending traces and feed them into a Continuous Learning via Human Feedback loop. Platforms like Galileo let you customize your metrics, flag a handful of misclassifications directly in the UI, then auto-fine-tune the underlying evaluator.
Each weekly CLHF cycle lifts accuracy with as few as five expert annotations, so you course-correct before small errors snowball.
The workflow feels familiar if you've experimented with RLHF in model tuning. The key difference is speed: because the evaluator is lightweight, retraining completes in minutes and ships straight into production. Continuous, human-in-the-loop adaptation keeps your safeguards sharp without slowing release velocity.
Guardrailing AI agent step #8: Embed guardrails into CI/CD pipelines
Imagine your sprint ends on Friday, and a last-minute prompt tweak slips through because the test suite is unaware of hallucinations. In staging, the agent happily recommends flights that don't exist—an invisible regression with real cost.
Most CI pipelines still stop at unit tests and API contracts, leaving a dangerous gap in quality assurance.
Guardrails need to gate code, not just monitor it after deployment. Wire your evaluator suite into Jenkins or GitHub Actions, and every pull request becomes an instant red-team run. Prompts, tool calls, and outputs are scored for context drift, PII leaks, and toxicity using the checker, a pattern typical of enterprise guardrails.
Failing traces block the merge and leave developers a pinpoint diff showing exactly what went wrong.
Synthetic edge-case suites with deterministic seeds run in under a minute, so velocity never suffers. You ship faster because safe code merges automatically, unsafe code never reaches staging, and auditors already have the compliance trail.
With guardrail gates in CI/CD, zero-error delivery transforms from aspiration to routine.
Achieve reliable AI agents with Galileo
Working through each of the steps creates a safety net strong enough to turn brittle autonomous agents into reliable agents. This framework synchronizes policy, evaluation, runtime controls, and continuous learning so every deployment makes your agents sharper, without the budget headaches of traditional evaluation.
Here’s how Galileo wraps evaluation, tracing, and guardrailing into a single cohesive workflow:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 Small Language models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agents' development and achieve reliable AI agents that users trust.

Conor Bronsdon