
Nov 10, 2025
The AI Agent Behavioral Validation Testing Playbook

Scripts built for deterministic code simply ask, "Did this function run?"—never, "Was it the right function to run right now?"
AI agent outputs don't follow strict rules. The same prompt can trigger multiple valid—or disastrously invalid—responses. Non-determinism, continuous learning, and hidden data biases create behaviors that only appear once they hit production, a risk highlighted across the industry.
This requires switching from execution checks to behavioral validation: testing decision quality, context awareness, and safety across changing scenarios.
Without this shift, you're just shipping uncertainty dressed up as code quality.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What is behavioral validation for AI agents?
Behavioral validation refers to the comprehensive assessment of an AI agent's decision-making quality and appropriateness across diverse scenarios.
Unlike traditional testing, which focuses on code execution, behavioral validation examines whether an agent makes contextually appropriate choices, maintains safety guardrails, and achieves user goals through sensible reasoning.
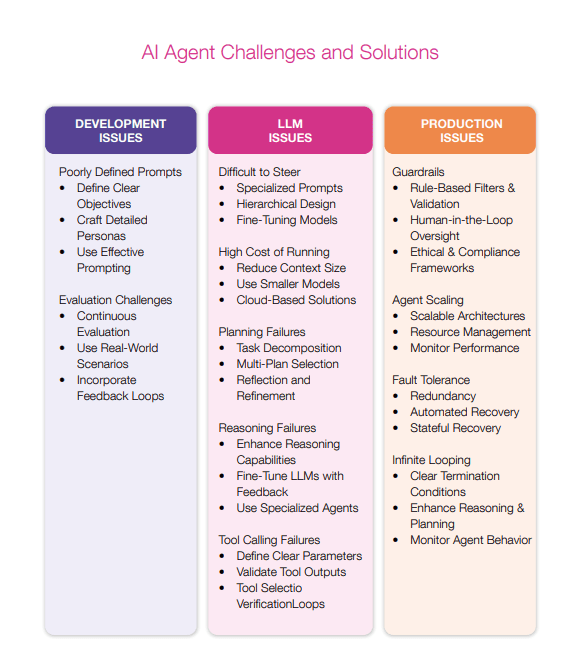
Agent behavior breaks down into five testable dimensions:
Memory: Does the agent accurately retain and retrieve information from previous interactions?
Reflection: Can the agent correctly assess its own progress and interpret outcomes?
Planning: Does the agent generate logically sound and feasible strategies?
Action: Are the agent's actions properly formatted and aligned with its intentions?
System reliability: How does the agent handle external constraints and environmental factors?
This validation approach picks up where classic quality assurance ends, asking not just "did the code run?" but "did the agent make the right call for the right reasons?" To understand this shift, we need to examine why traditional methods fail and how behavioral assessment builds more reliable systems.
Why does traditional QA fail for AI agents?
Traditional test suites assume determinism—identical inputs should always produce identical outputs. AI systems play by different rules. The exact same prompt can generate several plausible responses because the underlying model uses probabilistic sampling and evolving weights.
Assertion-based tests that work for conventional software break down under this variability, leaving you with brittle pass/fail checks that miss real-world risks.
Classic QA only reviews a tiny sample of interactions; human teams typically spot-check 1–5% of cases, allowing rare but catastrophic failures to slip through unnoticed.
The problem goes deeper than sampling rates. Traditional methods assume specifications cover all relevant data and context, but intelligent systems work in open-ended environments where context constantly shifts.
Technical execution can be perfect while the system's judgment remains unsafe, biased, or completely off-base.
The failure cascade problem makes this worse. Research analyzing 500+ agent trajectories reveals that agent errors rarely stay isolated; they propagate through subsequent decisions.
A memory error in step 2 (misremembering user context) corrupts the planning in step 3, triggering incorrect tool selection in step 4, which results in the final output failing. Traditional QA treats each failure independently. Agent behavioral validation tracks how early mistakes cascade through the entire decision chain.
Behavioral validation focuses on agent decision-making, not just execution
Think about how you evaluate human performance—technical ability is just the baseline, but judgment quality separates adequate from exceptional.
By focusing on decision appropriateness instead of binary outcomes, you create space to evaluate multiple valid responses and catch subtle alignment issues that traditional methods miss. This approach recognizes that excellent systems might take different valid paths to reach appropriate solutions.
When your system juggles multiple tools during complex tasks, you care less about each API call succeeding and more about whether those calls made strategic sense. Smart validation traces the entire reasoning chain—from initial prompt interpretation through intermediate thoughts, tool choices, and final synthesis.
Take a customer service system handling a billing dispute.
Technical success means database queries ran and the response formatted correctly. Decision quality means the system gathered relevant context, chose appropriate escalation thresholds, and communicated with empathy while following policy.
Good validation checks for sensible escalation patterns—does the system hand off to humans when confidence drops too low? It examines reasoning efficiency, making sure systems avoid needless loops while staying thorough.
Metrics like tool-usage accuracy and hallucination rates show whether reasoning aligns with intended behavior. The goal isn't perfect determinism but consistent appropriateness across varied scenarios.

Core testing methodologies for AI agent behavior
Beyond theoretical validation principles, you need structured methodologies that stress every part of the decision-making process—from the first prompt token to the final API call—under conditions that mirror production chaos.
These four approaches cover the most critical failure modes.
End-to-end task flow validation
Systems fail mysteriously in production because isolated function tests miss the complexity of real workflows. Most teams test individual API calls but ignore the messy reality of multi-step coordination.
Instead of checking calls in isolation, map an entire workflow—like "find a mutual free slot for three people, book a room, and email invites." Give the system a natural-language request, then trace every decision, intermediate output, and tool choice until the calendar event appears.
DataGrid's non-deterministic test harnesses capture each reasoning step so you can spot loops, unnecessary tool calls, or missing safeguards. Define success beyond "no exceptions"—require the right participants, correct timezone handling, and a confirmation message matching user intent.
Evaluation platforms like Galileo visualize execution paths, making it obvious where context got lost or goals drifted. Once an end-to-end test passes, save that trace as a regression artifact and run it again with every model or prompt change.
Scenario-based testing and synthetic edge cases
What happens when your system faces contradictory instructions, malformed payloads, or sneaky prompts designed to extract sensitive information?
Traditional QA rarely covers these paths, leaving critical vulnerabilities hidden until production. Start with a normal conversation, then systematically change it: add typos, reorder context, or include prompts that try to override system instructions.
Simulation frameworks can automate this fuzzing so you explore the full combinatorial space without endless manual work. Track how often the system degrades gracefully—asking clarifying questions or providing safe fallbacks—versus hallucinating or crashing.
Feeding these synthetic edge cases into continuous integration reveals brittle logic long before users encounter it, building a library of "known challenges" you can reuse as models evolve.
Multi-agent and human-agent interaction testing
Production environments show that autonomous systems can deadlock while waiting for each other, trigger endless escalation loops, or lose vital context during human handoffs. These coordination failures stay invisible in single-system testing.
Modern ecosystems need distributed tests that mirror real collaboration patterns.
Try injecting a human override mid-flow to verify the system hands off complete context—incomplete transfers destroy user trust. Measure shared memory consistency, message passing speed, and adherence to escalation thresholds.
Once these metrics meet your SLAs, vary one parameter—network delay, role capability, or tool availability—to test robustness. Purpose-built observability tools capture distributed traces so you can debug cross-system problems instead of guessing which component failed.
Validating agent outputs
System failures rarely announce themselves with error messages—they show up as plausible-sounding hallucinations, inefficient tool choices, or logical gaps in reasoning.
This requires layered output evaluation. First, run automated factuality checks—link verification, numerical consistency, and contradiction detection—to catch obvious hallucinations. Next, compare the tools the system chose against an "optimal path" based on domain knowledge; unnecessary calls show inefficient reasoning and possible cost issues.
Finally, examine the thinking process itself. Galileo can help score each reasoning step for logical coherence and redundancy, helping you spot where context leaked or goals shifted. Combine these automated scores with human reviews to catch subtle issues—tone, regulatory compliance, sensitive content—that metrics miss.
When an update pushes any of these signals beyond acceptable limits, you have evidence to justify a rollback or retraining before reputation damage occurs.
Root Cause vs. Surface-Level Diagnosis
Finding the root cause, not just counting failures
Most failed agent traces show multiple errors, but not all errors matter equally. An agent might fail a task with five visible problems, yet fixing just one early decision would have prevented everything else.
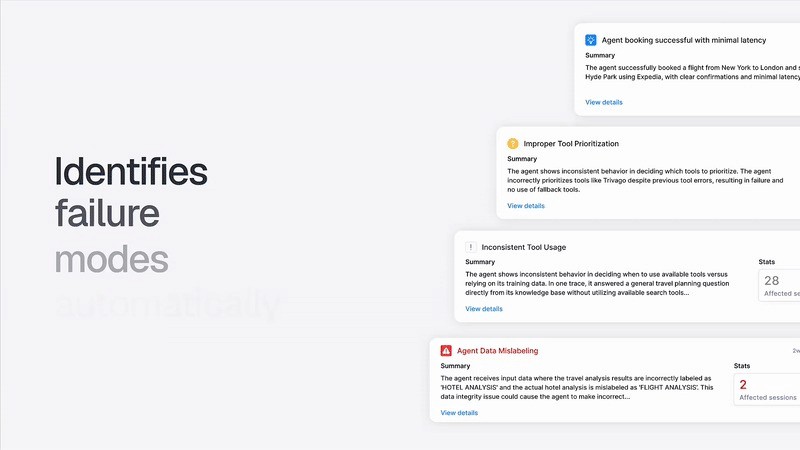
Recent research on agent debugging identifies "root cause errors", the first failure in the chain that triggers everything else. Fix the root cause, and the downstream shortcomings disappear.
Example: An agent fails a booking task showing:
Step 3: Wrong date retrieved (memory error)
Step 5: Invalid hotel selected (planning error)
Step 7: Confirmation failed (action error)
The root cause is Step 3. Fix the memory retrieval, and steps 5 and 7 never happen. Traditional QA reports all three as separate bugs. Behavioral validation identifies which one actually caused the cascade.
Tools like Galileo's Insights Engine automatically detect these causal failure patterns, helping teams fix root causes instead of chasing downstream effects.
AI agent metrics that matter
Knowing which testing methods to apply only gets you halfway there. You also need concrete metrics that show how consistently your system achieves objectives, selects tools, and handles messy real-world inputs. These three dimensions create your behavioral scorecard, warning you when performance drifts before users notice problems.
Task completion rate and success criteria
Did your system actually solve the user's problem? Task completion rate shows the percentage of sessions ending with correct, satisfying outcomes.
Don't settle for simple HTTP 200 responses. Define detailed success signals—accurate data entry, confirmation messages, proper escalation paths.
Record specific failure types: wrong tool selection, flawed reasoning, timeouts. This shows exactly where runs go off track. Establish baselines for each task type and watch for trends.
You'll create a living benchmark that catches regressions before customers complain. Business-level KPIs connect these rates directly to revenue or support costs, making performance improvements clear to stakeholders.
Tool usage accuracy and reasoning efficiency
Precise tool selection separates helpful systems from expensive, slow ones. Tool usage accuracy measures how often your system picks the right API, database, or function on the first try. Pair this with reasoning efficiency—the ratio between steps taken and the optimal path.

Dashboards that analyze reasoning patterns highlight redundant loops, unnecessary calls, and oversized parameters. Cutting this waste improves speed and reduces compute costs without sacrificing quality.
With tools like Galileo, you can track improvement with each model or prompt update to show concrete optimization gains.
Response quality and robustness under edge cases
Output quality remains paramount. Track factual accuracy, coherence, and relevance with automated text metrics. Monitor hallucination rates for generative systems. To test robustness, replay synthetic edge cases—malformed inputs, contradictory instructions—and record pass rates.
Continuous evaluation through specialized AI evaluation platforms highlights problems across diverse inputs. This helps you address ambiguity handling and uncertainty expression.
Consistently high scores show your system maintains composure when real users stray from the script, behaving professionally even under stress.
Module-level failure tracking
Your dashboard shows an 80% success rate. Great news, right? Not quite—you still don't know why the other 20% failed or where to fix it.
Generic error counts won't help. You need to see what actually broke in the decision-making process. Research on agent failure patterns identifies four critical areas where agents commonly fail:
Memory failures: The agent invents facts that never appeared in your conversation, or completely forgets something you mentioned two minutes ago.
Reflection failures: It declares victory while half the task remains unfinished, or treats an error message as confirmation that everything worked.
Planning failures: It maps out steps that physically can't execute, or ignores the constraints you explicitly spelled out.
Action failures: It knows what to do but fumbles the execution—wrong parameter values, malformed API calls, or actions that contradict its own stated plan.
Here's why this matters: That 80% success rate might actually mean 90% memory accuracy but only 40% planning reliability. Now you know exactly where to focus instead of guessing which component needs work.
Galileo's Luna-2 models classify failures across these categories at 87-96% accuracy, so you get these diagnostics automatically instead of manually combing through thousands of traces.
Implementing agent behavioral testing in practice
These implementation strategies address the practical aspects of integrating behavioral testing into development workflows, from selecting frameworks to monitoring production behavior.
Choose the right testing frameworks and build custom harnesses
Most systems don't fit neatly into standard test runners. You're probably dealing with unpredictable outputs, tool calls, and multi-step reasoning chains that traditional QA scripts ignore.
Frameworks for non-deterministic systems offer replayable simulations, adversarial input generators, and decision-path tracers—crucial when you need to understand if a system "could" act before judging if it "should."
Platform breadth becomes a limitation once domain-specific issues arise. Financial advisors, medical triage bots, and autonomous drones each need specialized data setups, compliance mocks, or hardware loops.
Custom harnesses excel here: they can simulate regulated APIs, introduce domain-specific edge cases, and capture richer data than generic frameworks allow. Consider starting with a core library, then adding custom fixtures that match real production constraints.
Align this approach with your system architecture to avoid false confidence from test dashboards disconnected from reality.
Test agent prompts and logic early (shift-left)
Treating prompts like code catches hallucinations before they reach users. Traditional teams wait for full system integration, wasting time on bugs that mask prompt failures.
Smart validation begins with lightweight prompt testing that covers common intents, security challenges, and ambiguous requests. AI test plugins can run these checks on every pull request, while scenario-based testing helps you create cases that test reasoning limits.
A single prompt change can affect tool selection, context retrieval, and safety filters. By testing prompts separately, you can pinpoint failures to the prompt or instruction layer—no more searching through massive logs for a misplaced word.
Automated metrics like answer correctness and tool-usage accuracy provide direct feedback to prompt engineers. This closed loop builds a culture where behavioral quality gets addressed alongside syntax errors, preventing expensive fixes later.
Run continuous validation in staging environments
Testing reveals an uncomfortable truth: yesterday's passing tests mean nothing after a model update. Most teams learn this through production incidents that flood Slack at the worst times.
Rather than learning the hard way, continuous validation in staging environments prevents this pain.
Non-deterministic AI frameworks route synthetic and real traffic through test environments, recording decision paths, speed, and success metrics in real time. Every model retrain or prompt change triggers a full behavioral regression, with any significant drift blocking the release.
Treat behavioral tests as core components: version them with your code and display pass/fail status directly in your pipeline. Since staging mirrors production data patterns, you'll find problems—wrong tool choices, infinite reasoning loops, context leaks—while there's still time to fix them.
Continuous staging validation turns unpredictable systems into predictable releases.
Monitor agent behavior in production
Production systems make thousands of decisions daily, far beyond what humans can review manually. Best practices for monitoring suggest tracking inputs, outputs, tool usage, and confidence scores for every request.
Add anomaly detection to flag increases in hallucination rates or unexpected cost spikes; observability guides show how sliding-window baselines catch subtle behavioral changes days before users notice.
Security can't be an afterthought. Identity platforms can connect each action to verifiable credentials, creating audit trails that satisfy compliance requirements. When anomalies appear, human-in-the-loop dashboards let product owners assess risk and decide whether to throttle, retrain, or roll back.
This approach converts raw data into actionable insights, keeping systems aligned with user needs long after deployment.
Build regression test suites and A/B test configurations
Most teams hope nothing breaks rather than documenting expectations in regression test suites. Capture previously failing scenarios—escalation mistakes, tool misuse, context drops—and verify future versions never reintroduce them.
Then move from fear to experimentation with controlled A/B tests. Modern evaluation platforms let you direct traffic percentages to candidate configurations, comparing task completion, speed, and hallucination rates side by side.
Agent performance testing in dynamic environments demonstrates how this approach reveals trade-offs that static tests miss. Rollouts become gradual: start at 5%, watch real-time dashboards, expand only when metrics improve across the board.
By combining regression tests with data-driven A/B testing, you can confidently make improvements without sacrificing the stability your users depend on.
Achieving reliable AI agents with Galileo behavioral validation
Behavioral validation becomes actionable when powered by purpose-built observability tools that understand agent decision processes. Galileo's platform specifically addresses the unique challenges of validating non-deterministic agent behavior across the entire development lifecycle.
Here’s how Galileo wraps evaluation, tracing, and guardrailing into a single cohesive workflow:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 Small Language models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agents' development and achieve reliable AI agents that users trust.
Scripts built for deterministic code simply ask, "Did this function run?"—never, "Was it the right function to run right now?"
AI agent outputs don't follow strict rules. The same prompt can trigger multiple valid—or disastrously invalid—responses. Non-determinism, continuous learning, and hidden data biases create behaviors that only appear once they hit production, a risk highlighted across the industry.
This requires switching from execution checks to behavioral validation: testing decision quality, context awareness, and safety across changing scenarios.
Without this shift, you're just shipping uncertainty dressed up as code quality.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What is behavioral validation for AI agents?
Behavioral validation refers to the comprehensive assessment of an AI agent's decision-making quality and appropriateness across diverse scenarios.
Unlike traditional testing, which focuses on code execution, behavioral validation examines whether an agent makes contextually appropriate choices, maintains safety guardrails, and achieves user goals through sensible reasoning.
Agent behavior breaks down into five testable dimensions:
Memory: Does the agent accurately retain and retrieve information from previous interactions?
Reflection: Can the agent correctly assess its own progress and interpret outcomes?
Planning: Does the agent generate logically sound and feasible strategies?
Action: Are the agent's actions properly formatted and aligned with its intentions?
System reliability: How does the agent handle external constraints and environmental factors?
This validation approach picks up where classic quality assurance ends, asking not just "did the code run?" but "did the agent make the right call for the right reasons?" To understand this shift, we need to examine why traditional methods fail and how behavioral assessment builds more reliable systems.
Why does traditional QA fail for AI agents?
Traditional test suites assume determinism—identical inputs should always produce identical outputs. AI systems play by different rules. The exact same prompt can generate several plausible responses because the underlying model uses probabilistic sampling and evolving weights.
Assertion-based tests that work for conventional software break down under this variability, leaving you with brittle pass/fail checks that miss real-world risks.
Classic QA only reviews a tiny sample of interactions; human teams typically spot-check 1–5% of cases, allowing rare but catastrophic failures to slip through unnoticed.
The problem goes deeper than sampling rates. Traditional methods assume specifications cover all relevant data and context, but intelligent systems work in open-ended environments where context constantly shifts.
Technical execution can be perfect while the system's judgment remains unsafe, biased, or completely off-base.
The failure cascade problem makes this worse. Research analyzing 500+ agent trajectories reveals that agent errors rarely stay isolated; they propagate through subsequent decisions.
A memory error in step 2 (misremembering user context) corrupts the planning in step 3, triggering incorrect tool selection in step 4, which results in the final output failing. Traditional QA treats each failure independently. Agent behavioral validation tracks how early mistakes cascade through the entire decision chain.
Behavioral validation focuses on agent decision-making, not just execution
Think about how you evaluate human performance—technical ability is just the baseline, but judgment quality separates adequate from exceptional.
By focusing on decision appropriateness instead of binary outcomes, you create space to evaluate multiple valid responses and catch subtle alignment issues that traditional methods miss. This approach recognizes that excellent systems might take different valid paths to reach appropriate solutions.
When your system juggles multiple tools during complex tasks, you care less about each API call succeeding and more about whether those calls made strategic sense. Smart validation traces the entire reasoning chain—from initial prompt interpretation through intermediate thoughts, tool choices, and final synthesis.
Take a customer service system handling a billing dispute.
Technical success means database queries ran and the response formatted correctly. Decision quality means the system gathered relevant context, chose appropriate escalation thresholds, and communicated with empathy while following policy.
Good validation checks for sensible escalation patterns—does the system hand off to humans when confidence drops too low? It examines reasoning efficiency, making sure systems avoid needless loops while staying thorough.
Metrics like tool-usage accuracy and hallucination rates show whether reasoning aligns with intended behavior. The goal isn't perfect determinism but consistent appropriateness across varied scenarios.
Core testing methodologies for AI agent behavior
Beyond theoretical validation principles, you need structured methodologies that stress every part of the decision-making process—from the first prompt token to the final API call—under conditions that mirror production chaos.
These four approaches cover the most critical failure modes.
End-to-end task flow validation
Systems fail mysteriously in production because isolated function tests miss the complexity of real workflows. Most teams test individual API calls but ignore the messy reality of multi-step coordination.
Instead of checking calls in isolation, map an entire workflow—like "find a mutual free slot for three people, book a room, and email invites." Give the system a natural-language request, then trace every decision, intermediate output, and tool choice until the calendar event appears.
DataGrid's non-deterministic test harnesses capture each reasoning step so you can spot loops, unnecessary tool calls, or missing safeguards. Define success beyond "no exceptions"—require the right participants, correct timezone handling, and a confirmation message matching user intent.
Evaluation platforms like Galileo visualize execution paths, making it obvious where context got lost or goals drifted. Once an end-to-end test passes, save that trace as a regression artifact and run it again with every model or prompt change.
Scenario-based testing and synthetic edge cases
What happens when your system faces contradictory instructions, malformed payloads, or sneaky prompts designed to extract sensitive information?
Traditional QA rarely covers these paths, leaving critical vulnerabilities hidden until production. Start with a normal conversation, then systematically change it: add typos, reorder context, or include prompts that try to override system instructions.
Simulation frameworks can automate this fuzzing so you explore the full combinatorial space without endless manual work. Track how often the system degrades gracefully—asking clarifying questions or providing safe fallbacks—versus hallucinating or crashing.
Feeding these synthetic edge cases into continuous integration reveals brittle logic long before users encounter it, building a library of "known challenges" you can reuse as models evolve.
Multi-agent and human-agent interaction testing
Production environments show that autonomous systems can deadlock while waiting for each other, trigger endless escalation loops, or lose vital context during human handoffs. These coordination failures stay invisible in single-system testing.
Modern ecosystems need distributed tests that mirror real collaboration patterns.
Try injecting a human override mid-flow to verify the system hands off complete context—incomplete transfers destroy user trust. Measure shared memory consistency, message passing speed, and adherence to escalation thresholds.
Once these metrics meet your SLAs, vary one parameter—network delay, role capability, or tool availability—to test robustness. Purpose-built observability tools capture distributed traces so you can debug cross-system problems instead of guessing which component failed.
Validating agent outputs
System failures rarely announce themselves with error messages—they show up as plausible-sounding hallucinations, inefficient tool choices, or logical gaps in reasoning.
This requires layered output evaluation. First, run automated factuality checks—link verification, numerical consistency, and contradiction detection—to catch obvious hallucinations. Next, compare the tools the system chose against an "optimal path" based on domain knowledge; unnecessary calls show inefficient reasoning and possible cost issues.
Finally, examine the thinking process itself. Galileo can help score each reasoning step for logical coherence and redundancy, helping you spot where context leaked or goals shifted. Combine these automated scores with human reviews to catch subtle issues—tone, regulatory compliance, sensitive content—that metrics miss.
When an update pushes any of these signals beyond acceptable limits, you have evidence to justify a rollback or retraining before reputation damage occurs.
Root Cause vs. Surface-Level Diagnosis
Finding the root cause, not just counting failures
Most failed agent traces show multiple errors, but not all errors matter equally. An agent might fail a task with five visible problems, yet fixing just one early decision would have prevented everything else.
Recent research on agent debugging identifies "root cause errors", the first failure in the chain that triggers everything else. Fix the root cause, and the downstream shortcomings disappear.
Example: An agent fails a booking task showing:
Step 3: Wrong date retrieved (memory error)
Step 5: Invalid hotel selected (planning error)
Step 7: Confirmation failed (action error)
The root cause is Step 3. Fix the memory retrieval, and steps 5 and 7 never happen. Traditional QA reports all three as separate bugs. Behavioral validation identifies which one actually caused the cascade.
Tools like Galileo's Insights Engine automatically detect these causal failure patterns, helping teams fix root causes instead of chasing downstream effects.
AI agent metrics that matter
Knowing which testing methods to apply only gets you halfway there. You also need concrete metrics that show how consistently your system achieves objectives, selects tools, and handles messy real-world inputs. These three dimensions create your behavioral scorecard, warning you when performance drifts before users notice problems.
Task completion rate and success criteria
Did your system actually solve the user's problem? Task completion rate shows the percentage of sessions ending with correct, satisfying outcomes.
Don't settle for simple HTTP 200 responses. Define detailed success signals—accurate data entry, confirmation messages, proper escalation paths.
Record specific failure types: wrong tool selection, flawed reasoning, timeouts. This shows exactly where runs go off track. Establish baselines for each task type and watch for trends.
You'll create a living benchmark that catches regressions before customers complain. Business-level KPIs connect these rates directly to revenue or support costs, making performance improvements clear to stakeholders.
Tool usage accuracy and reasoning efficiency
Precise tool selection separates helpful systems from expensive, slow ones. Tool usage accuracy measures how often your system picks the right API, database, or function on the first try. Pair this with reasoning efficiency—the ratio between steps taken and the optimal path.
Dashboards that analyze reasoning patterns highlight redundant loops, unnecessary calls, and oversized parameters. Cutting this waste improves speed and reduces compute costs without sacrificing quality.
With tools like Galileo, you can track improvement with each model or prompt update to show concrete optimization gains.
Response quality and robustness under edge cases
Output quality remains paramount. Track factual accuracy, coherence, and relevance with automated text metrics. Monitor hallucination rates for generative systems. To test robustness, replay synthetic edge cases—malformed inputs, contradictory instructions—and record pass rates.
Continuous evaluation through specialized AI evaluation platforms highlights problems across diverse inputs. This helps you address ambiguity handling and uncertainty expression.
Consistently high scores show your system maintains composure when real users stray from the script, behaving professionally even under stress.
Module-level failure tracking
Your dashboard shows an 80% success rate. Great news, right? Not quite—you still don't know why the other 20% failed or where to fix it.
Generic error counts won't help. You need to see what actually broke in the decision-making process. Research on agent failure patterns identifies four critical areas where agents commonly fail:
Memory failures: The agent invents facts that never appeared in your conversation, or completely forgets something you mentioned two minutes ago.
Reflection failures: It declares victory while half the task remains unfinished, or treats an error message as confirmation that everything worked.
Planning failures: It maps out steps that physically can't execute, or ignores the constraints you explicitly spelled out.
Action failures: It knows what to do but fumbles the execution—wrong parameter values, malformed API calls, or actions that contradict its own stated plan.
Here's why this matters: That 80% success rate might actually mean 90% memory accuracy but only 40% planning reliability. Now you know exactly where to focus instead of guessing which component needs work.
Galileo's Luna-2 models classify failures across these categories at 87-96% accuracy, so you get these diagnostics automatically instead of manually combing through thousands of traces.
Implementing agent behavioral testing in practice
These implementation strategies address the practical aspects of integrating behavioral testing into development workflows, from selecting frameworks to monitoring production behavior.
Choose the right testing frameworks and build custom harnesses
Most systems don't fit neatly into standard test runners. You're probably dealing with unpredictable outputs, tool calls, and multi-step reasoning chains that traditional QA scripts ignore.
Frameworks for non-deterministic systems offer replayable simulations, adversarial input generators, and decision-path tracers—crucial when you need to understand if a system "could" act before judging if it "should."
Platform breadth becomes a limitation once domain-specific issues arise. Financial advisors, medical triage bots, and autonomous drones each need specialized data setups, compliance mocks, or hardware loops.
Custom harnesses excel here: they can simulate regulated APIs, introduce domain-specific edge cases, and capture richer data than generic frameworks allow. Consider starting with a core library, then adding custom fixtures that match real production constraints.
Align this approach with your system architecture to avoid false confidence from test dashboards disconnected from reality.
Test agent prompts and logic early (shift-left)
Treating prompts like code catches hallucinations before they reach users. Traditional teams wait for full system integration, wasting time on bugs that mask prompt failures.
Smart validation begins with lightweight prompt testing that covers common intents, security challenges, and ambiguous requests. AI test plugins can run these checks on every pull request, while scenario-based testing helps you create cases that test reasoning limits.
A single prompt change can affect tool selection, context retrieval, and safety filters. By testing prompts separately, you can pinpoint failures to the prompt or instruction layer—no more searching through massive logs for a misplaced word.
Automated metrics like answer correctness and tool-usage accuracy provide direct feedback to prompt engineers. This closed loop builds a culture where behavioral quality gets addressed alongside syntax errors, preventing expensive fixes later.
Run continuous validation in staging environments
Testing reveals an uncomfortable truth: yesterday's passing tests mean nothing after a model update. Most teams learn this through production incidents that flood Slack at the worst times.
Rather than learning the hard way, continuous validation in staging environments prevents this pain.
Non-deterministic AI frameworks route synthetic and real traffic through test environments, recording decision paths, speed, and success metrics in real time. Every model retrain or prompt change triggers a full behavioral regression, with any significant drift blocking the release.
Treat behavioral tests as core components: version them with your code and display pass/fail status directly in your pipeline. Since staging mirrors production data patterns, you'll find problems—wrong tool choices, infinite reasoning loops, context leaks—while there's still time to fix them.
Continuous staging validation turns unpredictable systems into predictable releases.
Monitor agent behavior in production
Production systems make thousands of decisions daily, far beyond what humans can review manually. Best practices for monitoring suggest tracking inputs, outputs, tool usage, and confidence scores for every request.
Add anomaly detection to flag increases in hallucination rates or unexpected cost spikes; observability guides show how sliding-window baselines catch subtle behavioral changes days before users notice.
Security can't be an afterthought. Identity platforms can connect each action to verifiable credentials, creating audit trails that satisfy compliance requirements. When anomalies appear, human-in-the-loop dashboards let product owners assess risk and decide whether to throttle, retrain, or roll back.
This approach converts raw data into actionable insights, keeping systems aligned with user needs long after deployment.
Build regression test suites and A/B test configurations
Most teams hope nothing breaks rather than documenting expectations in regression test suites. Capture previously failing scenarios—escalation mistakes, tool misuse, context drops—and verify future versions never reintroduce them.
Then move from fear to experimentation with controlled A/B tests. Modern evaluation platforms let you direct traffic percentages to candidate configurations, comparing task completion, speed, and hallucination rates side by side.
Agent performance testing in dynamic environments demonstrates how this approach reveals trade-offs that static tests miss. Rollouts become gradual: start at 5%, watch real-time dashboards, expand only when metrics improve across the board.
By combining regression tests with data-driven A/B testing, you can confidently make improvements without sacrificing the stability your users depend on.
Achieving reliable AI agents with Galileo behavioral validation
Behavioral validation becomes actionable when powered by purpose-built observability tools that understand agent decision processes. Galileo's platform specifically addresses the unique challenges of validating non-deterministic agent behavior across the entire development lifecycle.
Here’s how Galileo wraps evaluation, tracing, and guardrailing into a single cohesive workflow:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 Small Language models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agents' development and achieve reliable AI agents that users trust.
Scripts built for deterministic code simply ask, "Did this function run?"—never, "Was it the right function to run right now?"
AI agent outputs don't follow strict rules. The same prompt can trigger multiple valid—or disastrously invalid—responses. Non-determinism, continuous learning, and hidden data biases create behaviors that only appear once they hit production, a risk highlighted across the industry.
This requires switching from execution checks to behavioral validation: testing decision quality, context awareness, and safety across changing scenarios.
Without this shift, you're just shipping uncertainty dressed up as code quality.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What is behavioral validation for AI agents?
Behavioral validation refers to the comprehensive assessment of an AI agent's decision-making quality and appropriateness across diverse scenarios.
Unlike traditional testing, which focuses on code execution, behavioral validation examines whether an agent makes contextually appropriate choices, maintains safety guardrails, and achieves user goals through sensible reasoning.
Agent behavior breaks down into five testable dimensions:
Memory: Does the agent accurately retain and retrieve information from previous interactions?
Reflection: Can the agent correctly assess its own progress and interpret outcomes?
Planning: Does the agent generate logically sound and feasible strategies?
Action: Are the agent's actions properly formatted and aligned with its intentions?
System reliability: How does the agent handle external constraints and environmental factors?
This validation approach picks up where classic quality assurance ends, asking not just "did the code run?" but "did the agent make the right call for the right reasons?" To understand this shift, we need to examine why traditional methods fail and how behavioral assessment builds more reliable systems.
Why does traditional QA fail for AI agents?
Traditional test suites assume determinism—identical inputs should always produce identical outputs. AI systems play by different rules. The exact same prompt can generate several plausible responses because the underlying model uses probabilistic sampling and evolving weights.
Assertion-based tests that work for conventional software break down under this variability, leaving you with brittle pass/fail checks that miss real-world risks.
Classic QA only reviews a tiny sample of interactions; human teams typically spot-check 1–5% of cases, allowing rare but catastrophic failures to slip through unnoticed.
The problem goes deeper than sampling rates. Traditional methods assume specifications cover all relevant data and context, but intelligent systems work in open-ended environments where context constantly shifts.
Technical execution can be perfect while the system's judgment remains unsafe, biased, or completely off-base.
The failure cascade problem makes this worse. Research analyzing 500+ agent trajectories reveals that agent errors rarely stay isolated; they propagate through subsequent decisions.
A memory error in step 2 (misremembering user context) corrupts the planning in step 3, triggering incorrect tool selection in step 4, which results in the final output failing. Traditional QA treats each failure independently. Agent behavioral validation tracks how early mistakes cascade through the entire decision chain.
Behavioral validation focuses on agent decision-making, not just execution
Think about how you evaluate human performance—technical ability is just the baseline, but judgment quality separates adequate from exceptional.
By focusing on decision appropriateness instead of binary outcomes, you create space to evaluate multiple valid responses and catch subtle alignment issues that traditional methods miss. This approach recognizes that excellent systems might take different valid paths to reach appropriate solutions.
When your system juggles multiple tools during complex tasks, you care less about each API call succeeding and more about whether those calls made strategic sense. Smart validation traces the entire reasoning chain—from initial prompt interpretation through intermediate thoughts, tool choices, and final synthesis.
Take a customer service system handling a billing dispute.
Technical success means database queries ran and the response formatted correctly. Decision quality means the system gathered relevant context, chose appropriate escalation thresholds, and communicated with empathy while following policy.
Good validation checks for sensible escalation patterns—does the system hand off to humans when confidence drops too low? It examines reasoning efficiency, making sure systems avoid needless loops while staying thorough.
Metrics like tool-usage accuracy and hallucination rates show whether reasoning aligns with intended behavior. The goal isn't perfect determinism but consistent appropriateness across varied scenarios.
Core testing methodologies for AI agent behavior
Beyond theoretical validation principles, you need structured methodologies that stress every part of the decision-making process—from the first prompt token to the final API call—under conditions that mirror production chaos.
These four approaches cover the most critical failure modes.
End-to-end task flow validation
Systems fail mysteriously in production because isolated function tests miss the complexity of real workflows. Most teams test individual API calls but ignore the messy reality of multi-step coordination.
Instead of checking calls in isolation, map an entire workflow—like "find a mutual free slot for three people, book a room, and email invites." Give the system a natural-language request, then trace every decision, intermediate output, and tool choice until the calendar event appears.
DataGrid's non-deterministic test harnesses capture each reasoning step so you can spot loops, unnecessary tool calls, or missing safeguards. Define success beyond "no exceptions"—require the right participants, correct timezone handling, and a confirmation message matching user intent.
Evaluation platforms like Galileo visualize execution paths, making it obvious where context got lost or goals drifted. Once an end-to-end test passes, save that trace as a regression artifact and run it again with every model or prompt change.
Scenario-based testing and synthetic edge cases
What happens when your system faces contradictory instructions, malformed payloads, or sneaky prompts designed to extract sensitive information?
Traditional QA rarely covers these paths, leaving critical vulnerabilities hidden until production. Start with a normal conversation, then systematically change it: add typos, reorder context, or include prompts that try to override system instructions.
Simulation frameworks can automate this fuzzing so you explore the full combinatorial space without endless manual work. Track how often the system degrades gracefully—asking clarifying questions or providing safe fallbacks—versus hallucinating or crashing.
Feeding these synthetic edge cases into continuous integration reveals brittle logic long before users encounter it, building a library of "known challenges" you can reuse as models evolve.
Multi-agent and human-agent interaction testing
Production environments show that autonomous systems can deadlock while waiting for each other, trigger endless escalation loops, or lose vital context during human handoffs. These coordination failures stay invisible in single-system testing.
Modern ecosystems need distributed tests that mirror real collaboration patterns.
Try injecting a human override mid-flow to verify the system hands off complete context—incomplete transfers destroy user trust. Measure shared memory consistency, message passing speed, and adherence to escalation thresholds.
Once these metrics meet your SLAs, vary one parameter—network delay, role capability, or tool availability—to test robustness. Purpose-built observability tools capture distributed traces so you can debug cross-system problems instead of guessing which component failed.
Validating agent outputs
System failures rarely announce themselves with error messages—they show up as plausible-sounding hallucinations, inefficient tool choices, or logical gaps in reasoning.
This requires layered output evaluation. First, run automated factuality checks—link verification, numerical consistency, and contradiction detection—to catch obvious hallucinations. Next, compare the tools the system chose against an "optimal path" based on domain knowledge; unnecessary calls show inefficient reasoning and possible cost issues.
Finally, examine the thinking process itself. Galileo can help score each reasoning step for logical coherence and redundancy, helping you spot where context leaked or goals shifted. Combine these automated scores with human reviews to catch subtle issues—tone, regulatory compliance, sensitive content—that metrics miss.
When an update pushes any of these signals beyond acceptable limits, you have evidence to justify a rollback or retraining before reputation damage occurs.
Root Cause vs. Surface-Level Diagnosis
Finding the root cause, not just counting failures
Most failed agent traces show multiple errors, but not all errors matter equally. An agent might fail a task with five visible problems, yet fixing just one early decision would have prevented everything else.
Recent research on agent debugging identifies "root cause errors", the first failure in the chain that triggers everything else. Fix the root cause, and the downstream shortcomings disappear.
Example: An agent fails a booking task showing:
Step 3: Wrong date retrieved (memory error)
Step 5: Invalid hotel selected (planning error)
Step 7: Confirmation failed (action error)
The root cause is Step 3. Fix the memory retrieval, and steps 5 and 7 never happen. Traditional QA reports all three as separate bugs. Behavioral validation identifies which one actually caused the cascade.
Tools like Galileo's Insights Engine automatically detect these causal failure patterns, helping teams fix root causes instead of chasing downstream effects.
AI agent metrics that matter
Knowing which testing methods to apply only gets you halfway there. You also need concrete metrics that show how consistently your system achieves objectives, selects tools, and handles messy real-world inputs. These three dimensions create your behavioral scorecard, warning you when performance drifts before users notice problems.
Task completion rate and success criteria
Did your system actually solve the user's problem? Task completion rate shows the percentage of sessions ending with correct, satisfying outcomes.
Don't settle for simple HTTP 200 responses. Define detailed success signals—accurate data entry, confirmation messages, proper escalation paths.
Record specific failure types: wrong tool selection, flawed reasoning, timeouts. This shows exactly where runs go off track. Establish baselines for each task type and watch for trends.
You'll create a living benchmark that catches regressions before customers complain. Business-level KPIs connect these rates directly to revenue or support costs, making performance improvements clear to stakeholders.
Tool usage accuracy and reasoning efficiency
Precise tool selection separates helpful systems from expensive, slow ones. Tool usage accuracy measures how often your system picks the right API, database, or function on the first try. Pair this with reasoning efficiency—the ratio between steps taken and the optimal path.
Dashboards that analyze reasoning patterns highlight redundant loops, unnecessary calls, and oversized parameters. Cutting this waste improves speed and reduces compute costs without sacrificing quality.
With tools like Galileo, you can track improvement with each model or prompt update to show concrete optimization gains.
Response quality and robustness under edge cases
Output quality remains paramount. Track factual accuracy, coherence, and relevance with automated text metrics. Monitor hallucination rates for generative systems. To test robustness, replay synthetic edge cases—malformed inputs, contradictory instructions—and record pass rates.
Continuous evaluation through specialized AI evaluation platforms highlights problems across diverse inputs. This helps you address ambiguity handling and uncertainty expression.
Consistently high scores show your system maintains composure when real users stray from the script, behaving professionally even under stress.
Module-level failure tracking
Your dashboard shows an 80% success rate. Great news, right? Not quite—you still don't know why the other 20% failed or where to fix it.
Generic error counts won't help. You need to see what actually broke in the decision-making process. Research on agent failure patterns identifies four critical areas where agents commonly fail:
Memory failures: The agent invents facts that never appeared in your conversation, or completely forgets something you mentioned two minutes ago.
Reflection failures: It declares victory while half the task remains unfinished, or treats an error message as confirmation that everything worked.
Planning failures: It maps out steps that physically can't execute, or ignores the constraints you explicitly spelled out.
Action failures: It knows what to do but fumbles the execution—wrong parameter values, malformed API calls, or actions that contradict its own stated plan.
Here's why this matters: That 80% success rate might actually mean 90% memory accuracy but only 40% planning reliability. Now you know exactly where to focus instead of guessing which component needs work.
Galileo's Luna-2 models classify failures across these categories at 87-96% accuracy, so you get these diagnostics automatically instead of manually combing through thousands of traces.
Implementing agent behavioral testing in practice
These implementation strategies address the practical aspects of integrating behavioral testing into development workflows, from selecting frameworks to monitoring production behavior.
Choose the right testing frameworks and build custom harnesses
Most systems don't fit neatly into standard test runners. You're probably dealing with unpredictable outputs, tool calls, and multi-step reasoning chains that traditional QA scripts ignore.
Frameworks for non-deterministic systems offer replayable simulations, adversarial input generators, and decision-path tracers—crucial when you need to understand if a system "could" act before judging if it "should."
Platform breadth becomes a limitation once domain-specific issues arise. Financial advisors, medical triage bots, and autonomous drones each need specialized data setups, compliance mocks, or hardware loops.
Custom harnesses excel here: they can simulate regulated APIs, introduce domain-specific edge cases, and capture richer data than generic frameworks allow. Consider starting with a core library, then adding custom fixtures that match real production constraints.
Align this approach with your system architecture to avoid false confidence from test dashboards disconnected from reality.
Test agent prompts and logic early (shift-left)
Treating prompts like code catches hallucinations before they reach users. Traditional teams wait for full system integration, wasting time on bugs that mask prompt failures.
Smart validation begins with lightweight prompt testing that covers common intents, security challenges, and ambiguous requests. AI test plugins can run these checks on every pull request, while scenario-based testing helps you create cases that test reasoning limits.
A single prompt change can affect tool selection, context retrieval, and safety filters. By testing prompts separately, you can pinpoint failures to the prompt or instruction layer—no more searching through massive logs for a misplaced word.
Automated metrics like answer correctness and tool-usage accuracy provide direct feedback to prompt engineers. This closed loop builds a culture where behavioral quality gets addressed alongside syntax errors, preventing expensive fixes later.
Run continuous validation in staging environments
Testing reveals an uncomfortable truth: yesterday's passing tests mean nothing after a model update. Most teams learn this through production incidents that flood Slack at the worst times.
Rather than learning the hard way, continuous validation in staging environments prevents this pain.
Non-deterministic AI frameworks route synthetic and real traffic through test environments, recording decision paths, speed, and success metrics in real time. Every model retrain or prompt change triggers a full behavioral regression, with any significant drift blocking the release.
Treat behavioral tests as core components: version them with your code and display pass/fail status directly in your pipeline. Since staging mirrors production data patterns, you'll find problems—wrong tool choices, infinite reasoning loops, context leaks—while there's still time to fix them.
Continuous staging validation turns unpredictable systems into predictable releases.
Monitor agent behavior in production
Production systems make thousands of decisions daily, far beyond what humans can review manually. Best practices for monitoring suggest tracking inputs, outputs, tool usage, and confidence scores for every request.
Add anomaly detection to flag increases in hallucination rates or unexpected cost spikes; observability guides show how sliding-window baselines catch subtle behavioral changes days before users notice.
Security can't be an afterthought. Identity platforms can connect each action to verifiable credentials, creating audit trails that satisfy compliance requirements. When anomalies appear, human-in-the-loop dashboards let product owners assess risk and decide whether to throttle, retrain, or roll back.
This approach converts raw data into actionable insights, keeping systems aligned with user needs long after deployment.
Build regression test suites and A/B test configurations
Most teams hope nothing breaks rather than documenting expectations in regression test suites. Capture previously failing scenarios—escalation mistakes, tool misuse, context drops—and verify future versions never reintroduce them.
Then move from fear to experimentation with controlled A/B tests. Modern evaluation platforms let you direct traffic percentages to candidate configurations, comparing task completion, speed, and hallucination rates side by side.
Agent performance testing in dynamic environments demonstrates how this approach reveals trade-offs that static tests miss. Rollouts become gradual: start at 5%, watch real-time dashboards, expand only when metrics improve across the board.
By combining regression tests with data-driven A/B testing, you can confidently make improvements without sacrificing the stability your users depend on.
Achieving reliable AI agents with Galileo behavioral validation
Behavioral validation becomes actionable when powered by purpose-built observability tools that understand agent decision processes. Galileo's platform specifically addresses the unique challenges of validating non-deterministic agent behavior across the entire development lifecycle.
Here’s how Galileo wraps evaluation, tracing, and guardrailing into a single cohesive workflow:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 Small Language models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agents' development and achieve reliable AI agents that users trust.
Scripts built for deterministic code simply ask, "Did this function run?"—never, "Was it the right function to run right now?"
AI agent outputs don't follow strict rules. The same prompt can trigger multiple valid—or disastrously invalid—responses. Non-determinism, continuous learning, and hidden data biases create behaviors that only appear once they hit production, a risk highlighted across the industry.
This requires switching from execution checks to behavioral validation: testing decision quality, context awareness, and safety across changing scenarios.
Without this shift, you're just shipping uncertainty dressed up as code quality.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What is behavioral validation for AI agents?
Behavioral validation refers to the comprehensive assessment of an AI agent's decision-making quality and appropriateness across diverse scenarios.
Unlike traditional testing, which focuses on code execution, behavioral validation examines whether an agent makes contextually appropriate choices, maintains safety guardrails, and achieves user goals through sensible reasoning.
Agent behavior breaks down into five testable dimensions:
Memory: Does the agent accurately retain and retrieve information from previous interactions?
Reflection: Can the agent correctly assess its own progress and interpret outcomes?
Planning: Does the agent generate logically sound and feasible strategies?
Action: Are the agent's actions properly formatted and aligned with its intentions?
System reliability: How does the agent handle external constraints and environmental factors?
This validation approach picks up where classic quality assurance ends, asking not just "did the code run?" but "did the agent make the right call for the right reasons?" To understand this shift, we need to examine why traditional methods fail and how behavioral assessment builds more reliable systems.
Why does traditional QA fail for AI agents?
Traditional test suites assume determinism—identical inputs should always produce identical outputs. AI systems play by different rules. The exact same prompt can generate several plausible responses because the underlying model uses probabilistic sampling and evolving weights.
Assertion-based tests that work for conventional software break down under this variability, leaving you with brittle pass/fail checks that miss real-world risks.
Classic QA only reviews a tiny sample of interactions; human teams typically spot-check 1–5% of cases, allowing rare but catastrophic failures to slip through unnoticed.
The problem goes deeper than sampling rates. Traditional methods assume specifications cover all relevant data and context, but intelligent systems work in open-ended environments where context constantly shifts.
Technical execution can be perfect while the system's judgment remains unsafe, biased, or completely off-base.
The failure cascade problem makes this worse. Research analyzing 500+ agent trajectories reveals that agent errors rarely stay isolated; they propagate through subsequent decisions.
A memory error in step 2 (misremembering user context) corrupts the planning in step 3, triggering incorrect tool selection in step 4, which results in the final output failing. Traditional QA treats each failure independently. Agent behavioral validation tracks how early mistakes cascade through the entire decision chain.
Behavioral validation focuses on agent decision-making, not just execution
Think about how you evaluate human performance—technical ability is just the baseline, but judgment quality separates adequate from exceptional.
By focusing on decision appropriateness instead of binary outcomes, you create space to evaluate multiple valid responses and catch subtle alignment issues that traditional methods miss. This approach recognizes that excellent systems might take different valid paths to reach appropriate solutions.
When your system juggles multiple tools during complex tasks, you care less about each API call succeeding and more about whether those calls made strategic sense. Smart validation traces the entire reasoning chain—from initial prompt interpretation through intermediate thoughts, tool choices, and final synthesis.
Take a customer service system handling a billing dispute.
Technical success means database queries ran and the response formatted correctly. Decision quality means the system gathered relevant context, chose appropriate escalation thresholds, and communicated with empathy while following policy.
Good validation checks for sensible escalation patterns—does the system hand off to humans when confidence drops too low? It examines reasoning efficiency, making sure systems avoid needless loops while staying thorough.
Metrics like tool-usage accuracy and hallucination rates show whether reasoning aligns with intended behavior. The goal isn't perfect determinism but consistent appropriateness across varied scenarios.
Core testing methodologies for AI agent behavior
Beyond theoretical validation principles, you need structured methodologies that stress every part of the decision-making process—from the first prompt token to the final API call—under conditions that mirror production chaos.
These four approaches cover the most critical failure modes.
End-to-end task flow validation
Systems fail mysteriously in production because isolated function tests miss the complexity of real workflows. Most teams test individual API calls but ignore the messy reality of multi-step coordination.
Instead of checking calls in isolation, map an entire workflow—like "find a mutual free slot for three people, book a room, and email invites." Give the system a natural-language request, then trace every decision, intermediate output, and tool choice until the calendar event appears.
DataGrid's non-deterministic test harnesses capture each reasoning step so you can spot loops, unnecessary tool calls, or missing safeguards. Define success beyond "no exceptions"—require the right participants, correct timezone handling, and a confirmation message matching user intent.
Evaluation platforms like Galileo visualize execution paths, making it obvious where context got lost or goals drifted. Once an end-to-end test passes, save that trace as a regression artifact and run it again with every model or prompt change.
Scenario-based testing and synthetic edge cases
What happens when your system faces contradictory instructions, malformed payloads, or sneaky prompts designed to extract sensitive information?
Traditional QA rarely covers these paths, leaving critical vulnerabilities hidden until production. Start with a normal conversation, then systematically change it: add typos, reorder context, or include prompts that try to override system instructions.
Simulation frameworks can automate this fuzzing so you explore the full combinatorial space without endless manual work. Track how often the system degrades gracefully—asking clarifying questions or providing safe fallbacks—versus hallucinating or crashing.
Feeding these synthetic edge cases into continuous integration reveals brittle logic long before users encounter it, building a library of "known challenges" you can reuse as models evolve.
Multi-agent and human-agent interaction testing
Production environments show that autonomous systems can deadlock while waiting for each other, trigger endless escalation loops, or lose vital context during human handoffs. These coordination failures stay invisible in single-system testing.
Modern ecosystems need distributed tests that mirror real collaboration patterns.
Try injecting a human override mid-flow to verify the system hands off complete context—incomplete transfers destroy user trust. Measure shared memory consistency, message passing speed, and adherence to escalation thresholds.
Once these metrics meet your SLAs, vary one parameter—network delay, role capability, or tool availability—to test robustness. Purpose-built observability tools capture distributed traces so you can debug cross-system problems instead of guessing which component failed.
Validating agent outputs
System failures rarely announce themselves with error messages—they show up as plausible-sounding hallucinations, inefficient tool choices, or logical gaps in reasoning.
This requires layered output evaluation. First, run automated factuality checks—link verification, numerical consistency, and contradiction detection—to catch obvious hallucinations. Next, compare the tools the system chose against an "optimal path" based on domain knowledge; unnecessary calls show inefficient reasoning and possible cost issues.
Finally, examine the thinking process itself. Galileo can help score each reasoning step for logical coherence and redundancy, helping you spot where context leaked or goals shifted. Combine these automated scores with human reviews to catch subtle issues—tone, regulatory compliance, sensitive content—that metrics miss.
When an update pushes any of these signals beyond acceptable limits, you have evidence to justify a rollback or retraining before reputation damage occurs.
Root Cause vs. Surface-Level Diagnosis
Finding the root cause, not just counting failures
Most failed agent traces show multiple errors, but not all errors matter equally. An agent might fail a task with five visible problems, yet fixing just one early decision would have prevented everything else.
Recent research on agent debugging identifies "root cause errors", the first failure in the chain that triggers everything else. Fix the root cause, and the downstream shortcomings disappear.
Example: An agent fails a booking task showing:
Step 3: Wrong date retrieved (memory error)
Step 5: Invalid hotel selected (planning error)
Step 7: Confirmation failed (action error)
The root cause is Step 3. Fix the memory retrieval, and steps 5 and 7 never happen. Traditional QA reports all three as separate bugs. Behavioral validation identifies which one actually caused the cascade.
Tools like Galileo's Insights Engine automatically detect these causal failure patterns, helping teams fix root causes instead of chasing downstream effects.
AI agent metrics that matter
Knowing which testing methods to apply only gets you halfway there. You also need concrete metrics that show how consistently your system achieves objectives, selects tools, and handles messy real-world inputs. These three dimensions create your behavioral scorecard, warning you when performance drifts before users notice problems.
Task completion rate and success criteria
Did your system actually solve the user's problem? Task completion rate shows the percentage of sessions ending with correct, satisfying outcomes.
Don't settle for simple HTTP 200 responses. Define detailed success signals—accurate data entry, confirmation messages, proper escalation paths.
Record specific failure types: wrong tool selection, flawed reasoning, timeouts. This shows exactly where runs go off track. Establish baselines for each task type and watch for trends.
You'll create a living benchmark that catches regressions before customers complain. Business-level KPIs connect these rates directly to revenue or support costs, making performance improvements clear to stakeholders.
Tool usage accuracy and reasoning efficiency
Precise tool selection separates helpful systems from expensive, slow ones. Tool usage accuracy measures how often your system picks the right API, database, or function on the first try. Pair this with reasoning efficiency—the ratio between steps taken and the optimal path.
Dashboards that analyze reasoning patterns highlight redundant loops, unnecessary calls, and oversized parameters. Cutting this waste improves speed and reduces compute costs without sacrificing quality.
With tools like Galileo, you can track improvement with each model or prompt update to show concrete optimization gains.
Response quality and robustness under edge cases
Output quality remains paramount. Track factual accuracy, coherence, and relevance with automated text metrics. Monitor hallucination rates for generative systems. To test robustness, replay synthetic edge cases—malformed inputs, contradictory instructions—and record pass rates.
Continuous evaluation through specialized AI evaluation platforms highlights problems across diverse inputs. This helps you address ambiguity handling and uncertainty expression.
Consistently high scores show your system maintains composure when real users stray from the script, behaving professionally even under stress.
Module-level failure tracking
Your dashboard shows an 80% success rate. Great news, right? Not quite—you still don't know why the other 20% failed or where to fix it.
Generic error counts won't help. You need to see what actually broke in the decision-making process. Research on agent failure patterns identifies four critical areas where agents commonly fail:
Memory failures: The agent invents facts that never appeared in your conversation, or completely forgets something you mentioned two minutes ago.
Reflection failures: It declares victory while half the task remains unfinished, or treats an error message as confirmation that everything worked.
Planning failures: It maps out steps that physically can't execute, or ignores the constraints you explicitly spelled out.
Action failures: It knows what to do but fumbles the execution—wrong parameter values, malformed API calls, or actions that contradict its own stated plan.
Here's why this matters: That 80% success rate might actually mean 90% memory accuracy but only 40% planning reliability. Now you know exactly where to focus instead of guessing which component needs work.
Galileo's Luna-2 models classify failures across these categories at 87-96% accuracy, so you get these diagnostics automatically instead of manually combing through thousands of traces.
Implementing agent behavioral testing in practice
These implementation strategies address the practical aspects of integrating behavioral testing into development workflows, from selecting frameworks to monitoring production behavior.
Choose the right testing frameworks and build custom harnesses
Most systems don't fit neatly into standard test runners. You're probably dealing with unpredictable outputs, tool calls, and multi-step reasoning chains that traditional QA scripts ignore.
Frameworks for non-deterministic systems offer replayable simulations, adversarial input generators, and decision-path tracers—crucial when you need to understand if a system "could" act before judging if it "should."
Platform breadth becomes a limitation once domain-specific issues arise. Financial advisors, medical triage bots, and autonomous drones each need specialized data setups, compliance mocks, or hardware loops.
Custom harnesses excel here: they can simulate regulated APIs, introduce domain-specific edge cases, and capture richer data than generic frameworks allow. Consider starting with a core library, then adding custom fixtures that match real production constraints.
Align this approach with your system architecture to avoid false confidence from test dashboards disconnected from reality.
Test agent prompts and logic early (shift-left)
Treating prompts like code catches hallucinations before they reach users. Traditional teams wait for full system integration, wasting time on bugs that mask prompt failures.
Smart validation begins with lightweight prompt testing that covers common intents, security challenges, and ambiguous requests. AI test plugins can run these checks on every pull request, while scenario-based testing helps you create cases that test reasoning limits.
A single prompt change can affect tool selection, context retrieval, and safety filters. By testing prompts separately, you can pinpoint failures to the prompt or instruction layer—no more searching through massive logs for a misplaced word.
Automated metrics like answer correctness and tool-usage accuracy provide direct feedback to prompt engineers. This closed loop builds a culture where behavioral quality gets addressed alongside syntax errors, preventing expensive fixes later.
Run continuous validation in staging environments
Testing reveals an uncomfortable truth: yesterday's passing tests mean nothing after a model update. Most teams learn this through production incidents that flood Slack at the worst times.
Rather than learning the hard way, continuous validation in staging environments prevents this pain.
Non-deterministic AI frameworks route synthetic and real traffic through test environments, recording decision paths, speed, and success metrics in real time. Every model retrain or prompt change triggers a full behavioral regression, with any significant drift blocking the release.
Treat behavioral tests as core components: version them with your code and display pass/fail status directly in your pipeline. Since staging mirrors production data patterns, you'll find problems—wrong tool choices, infinite reasoning loops, context leaks—while there's still time to fix them.
Continuous staging validation turns unpredictable systems into predictable releases.
Monitor agent behavior in production
Production systems make thousands of decisions daily, far beyond what humans can review manually. Best practices for monitoring suggest tracking inputs, outputs, tool usage, and confidence scores for every request.
Add anomaly detection to flag increases in hallucination rates or unexpected cost spikes; observability guides show how sliding-window baselines catch subtle behavioral changes days before users notice.
Security can't be an afterthought. Identity platforms can connect each action to verifiable credentials, creating audit trails that satisfy compliance requirements. When anomalies appear, human-in-the-loop dashboards let product owners assess risk and decide whether to throttle, retrain, or roll back.
This approach converts raw data into actionable insights, keeping systems aligned with user needs long after deployment.
Build regression test suites and A/B test configurations
Most teams hope nothing breaks rather than documenting expectations in regression test suites. Capture previously failing scenarios—escalation mistakes, tool misuse, context drops—and verify future versions never reintroduce them.
Then move from fear to experimentation with controlled A/B tests. Modern evaluation platforms let you direct traffic percentages to candidate configurations, comparing task completion, speed, and hallucination rates side by side.
Agent performance testing in dynamic environments demonstrates how this approach reveals trade-offs that static tests miss. Rollouts become gradual: start at 5%, watch real-time dashboards, expand only when metrics improve across the board.
By combining regression tests with data-driven A/B testing, you can confidently make improvements without sacrificing the stability your users depend on.
Achieving reliable AI agents with Galileo behavioral validation
Behavioral validation becomes actionable when powered by purpose-built observability tools that understand agent decision processes. Galileo's platform specifically addresses the unique challenges of validating non-deterministic agent behavior across the entire development lifecycle.
Here’s how Galileo wraps evaluation, tracing, and guardrailing into a single cohesive workflow:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 Small Language models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agents' development and achieve reliable AI agents that users trust.
If you find this helpful and interesting,

Conor Bronsdon