
What You Should Know About Agentic AI Workflows Before Deployment

Your AI systems are about to get a lot more autonomous—and a lot riskier. Half of all companies experimenting with generative AI will pilot agentic workflows by 2027, while 33% of enterprise AI will embed agentic capabilities the following year.
However, the shift from supervised AI to autonomous agents is fundamentally changing what can go wrong.
Consider what happens when you remove human oversight from decision-making loops. A misfired API call can reorder inventory, expose customer data, or trigger regulatory violations at machine speed—all while you're still figuring out what happened.
You need more than traditional monitoring to manage autonomous AI systems. You need agentic workflows: the framework for designing, governing, and operating AI that makes real-world decisions without asking permission first.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What are agentic AI workflows?
Agentic AI workflows are AI agents that make autonomous decisions to complete tasks. Designed to operate independently, they adapt to dynamic environments and interact seamlessly with surrounding systems.
Agentic workflows represent the next evolution in AI-driven processes, where autonomous agents plan, act, and learn toward goals with minimal human intervention.
Unlike rigid automation scripts, these intelligent systems perceive context, decompose complex tasks into manageable subtasks, select appropriate tools, and refine their approach through continuous feedback loops—steadily improving performance over time.

Benefits of agentic AI workflows
You probably already automate repetitive steps, yet bottlenecks persist whenever processes demand judgment calls. Autonomous agent systems erase that gap entirely, delivering measurable improvements across operations:
Near-instant task resolution: When agents decompose problems and act independently, ticket backlogs and manual hand-offs disappear—giving you immediate resolution for tasks like software installations or account unlocks
Self-updating decision systems: Continuous sensing and reflection mean decisions adapt to live data without your intervention, keeping forecasts, compliance checks, and policy recommendations current without manual retraining cycles that drain engineering resources
Effortless scaling through API coordination: Agents coordinate through APIs rather than queued emails, allowing a single implementation to handle thousands of parallel requests without proportional headcount growth
Proven performance gains: Multi-agent collaboration lifts task performance on benchmark suites, freeing your teams from routine firefighting to redirect talent toward strategy and innovation that actually moves business objectives forward
Use cases of agentic AI workflows
Modern enterprises across industries already leverage agentic workflows to transform reactive processes into proactive systems. From IT service desks to financial operations, autonomous agents demonstrate their value through tangible operational improvements:
IT service management: Agents verify permissions, trigger installers, and close tickets before you notice the alert—transforming help desk operations from reactive to predictive while eliminating queue times
Supply chain optimization: Systems reroute shipments, check real-time inventory levels, and raise procurement orders the moment shortages surface, preventing stockouts without human intervention
Financial operations and compliance: Intelligent systems scan transactions for anomalies, file regulatory reports, and update fraud models mid-stream without human oversight, maintaining continuous compliance
Customer service enhancement: Agents learn from every interaction, steadily trimming average handle times while escalating only true edge cases that require human expertise, improving both efficiency and satisfaction
HR operations automation: Departments deploy these systems for time-off approvals, password resets, and personalized policy guidance delivered in plain language, reducing administrative burden
Healthcare workflow coordination: Organizations use similar architectures for appointment scheduling, clinical note summarization, and high-risk patient alerts, improving both operational efficiency and patient outcomes
Retail pricing and inventory: Dynamic pricing and inventory placement systems respond to market conditions in real-time, optimizing revenue without constant manual adjustment
Telecommunications network management: Providers orchestrate network diagnostics and remedial actions without operator intervention, maintaining service quality at scale
Components of agentic AI workflows and how they work
When you break an autonomous workflow into its parts, you'll find a layered architecture rather than a single "black box." Each layer handles a distinct cognitive function—planning, acting, remembering, evaluating, guarding, and coordinating.
A weakness in one tier can undermine the entire system. Understanding these roles helps you design agents that stay reliable as scale and complexity grow.
Planning and reasoning engine
Your agent's planning engine works like a prefrontal cortex, decomposing abstract goals into executable steps before firing a single API call. Rather than following rigid scripts, it weighs constraints, sketches execution paths, and adapts based on live context.
For instance, converting "resolve a payroll ticket" into concrete subtasks prevents brittle automations that break at the first unexpected input.
The reasoning loop continuously compares context against the plan, selecting optimal branches as conditions change. This adaptive approach explains why iterative wrapper methods transform basic language models into sophisticated problem-solvers.
You control autonomy through parameter tuning—search depth, risk thresholds, fallback rules—so agents explore possibilities without wandering into chaos. The planning engine transforms reactive systems into proactive ones that anticipate challenges before they surface.
Tool use and integrations
Language models can't change passwords or book freight shipments alone. Your agent accomplishes real work by calling tools—databases, CRMs, ERPs, specialized services—through well-defined APIs.
The critical loop runs "think → act → observe," where agents choose tools based on task context, execute calls, then reason over responses before the next move.

This tight integration enables workflows to verify permissions, trigger installations, and update logs without human intervention. Security becomes non-negotiable: scope each function, restrict credentials, and log every external interaction.
Proper guardrails transform models from chatty advisors into reliable doers. When integration points are secure and well-defined, your agents gain the hands they need to execute decisions in the real world.
Memory and context management
Agents without memory greet repeat customers like strangers every time. Short-term buffers maintain conversation flow while long-term vectors store persistent facts—employee IDs, contract terms, resolution history.
Efficient retrieval layers, typically backed by embeddings, surface relevant information without bloating prompts with unnecessary context.
Solid memory management eliminates the "can you repeat that?" cycle and enables true personalization at scale. When building a solid agentic AI workflow, you need to balance retention with relevance: keep what improves future decisions, purge what doesn't to meet privacy requirements.
When memory systems work correctly, users feel your agent actually knows them rather than starting fresh each interaction. This continuity becomes the foundation for building meaningful relationships between users and AI systems.
Feedback and evaluation loops
Autonomous systems drift without continuous feedback. After every action, effective agents record outcomes and score themselves against accuracy, safety, and business KPIs. Reflection patterns—mini post-mortems built into the workflow—update strategies on the fly, creating the improvement cycles that drive measurable performance gains.
Human reviewers handle edge cases while automated evaluators process the bulk, flagging anomalies across thousands of traces. This approach enables rapid iteration without expanding headcount: your agents learn, adapt, and deploy fixes faster than traditional release cycles permit.
The feedback loop transforms static automations into learning systems that improve with every interaction, building institutional knowledge that compounds over time.
Security and governance controls
Power without guardrails creates liability. Governance layers convert policy into runtime constraints: input filtering blocks hostile prompts, output moderation scrubs sensitive data, and action authorization prevents system-level damage.
Fine-grained permissions, audit trails, and deterministic overrides align with enterprise safeguards.
Embed these controls at design time rather than retrofitting them later—attackers exploit the gaps left by bolted-on security. Done correctly, agents operate freely inside sandboxes you define, keeping regulators, security teams, and customers confident.
The governance layer becomes invisible to users while providing the foundation that makes autonomous operation possible in regulated environments.
Orchestration and collaboration layer
Complex missions rarely match a single agent's capabilities. Orchestration assigns specialized agents to subtasks—data retrieval, analysis, drafting—then weaves outputs into unified results.
Supervisor agents track dependencies, retry failed steps, and reallocate work when conditions shift, delivering the collaboration gains that push performance beyond what individual systems achieve.
This layer coordinates AI components, RPA bots, and human operators, preventing cascade failures when individual pieces falter. With clear interfaces and shared context, the collective system behaves like a well-run project team—only faster and tireless.
Orchestration transforms individual agents into collaborative networks that tackle enterprise-scale challenges no single system could handle alone.
Four biggest challenges that break agentic AI workflows
Autonomous agents promise massive productivity gains, yet every new layer of independence multiplies risk. You suddenly juggle opaque decision trees, ballooning evaluation bills, runaway outputs, and auditors demanding answers you can't provide.
Tackling these intertwined technical and governance gaps is the only way to move from thrilling demos to trustworthy production.
Observability gap and debugging complexity
You probably spend hours scrolling through raw traces, hoping to pinpoint why an agent took a bizarre detour. Most teams lean on traditional APM dashboards, but those tools capture CPU spikes—not the chain-of-thought driving an LLM.
Without visibility, failures look random, and you ship patches in the dark, inflating mean-time-to-repair.
Purpose-built observability from modern platforms flips that script. Galileo's Graph Engine reconstructs every reasoning hop, tool call, and response so you can watch an entire decision path unfold like a network diagram.
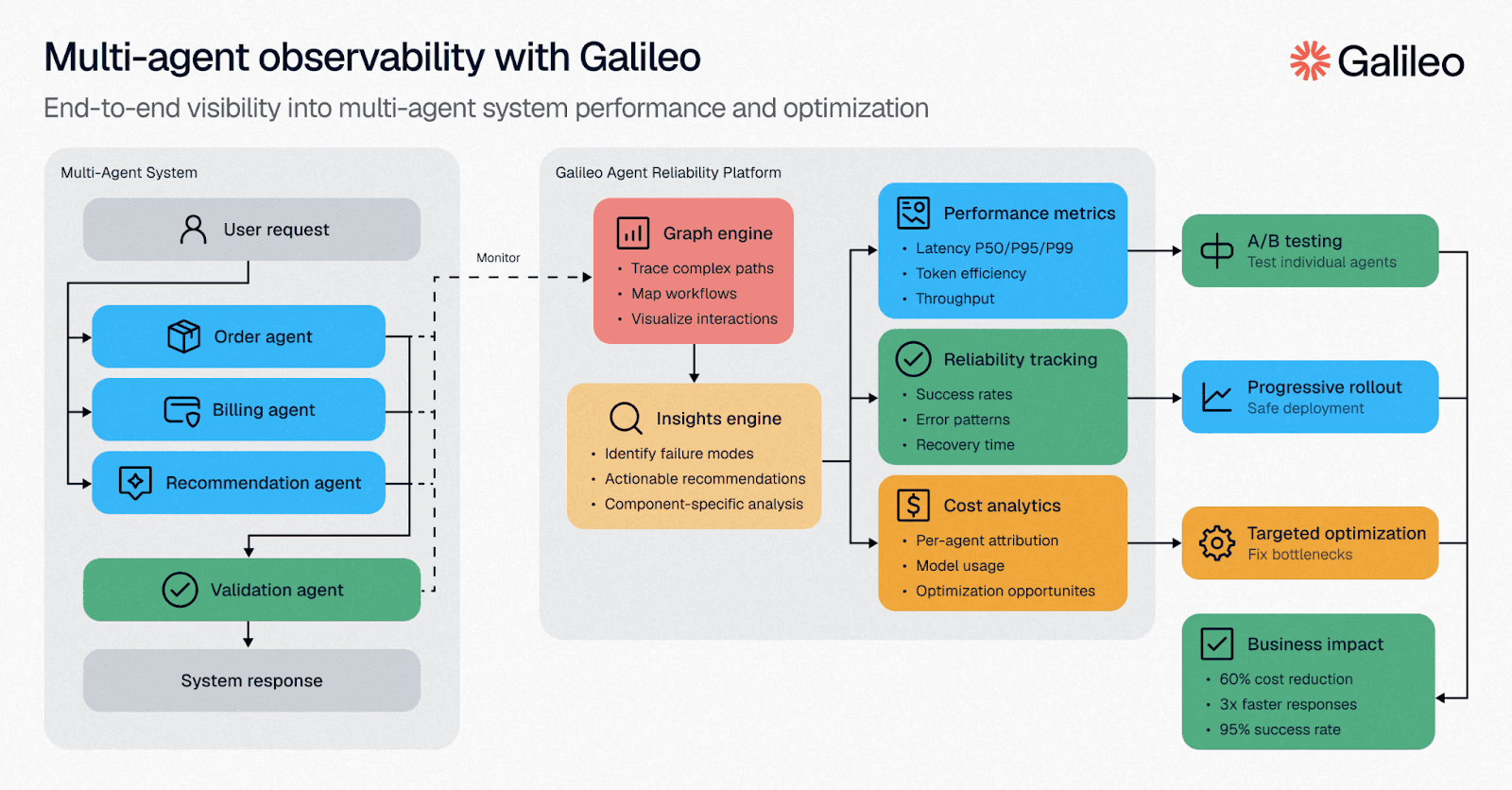
To take observability a step further, Galileo’s Insights Engine clusters similar failure patterns, surfacing root causes you might never suspect. Multi-turn session tracking keeps context intact, revealing when a forgotten variable from message three torpedoes outcome seven.
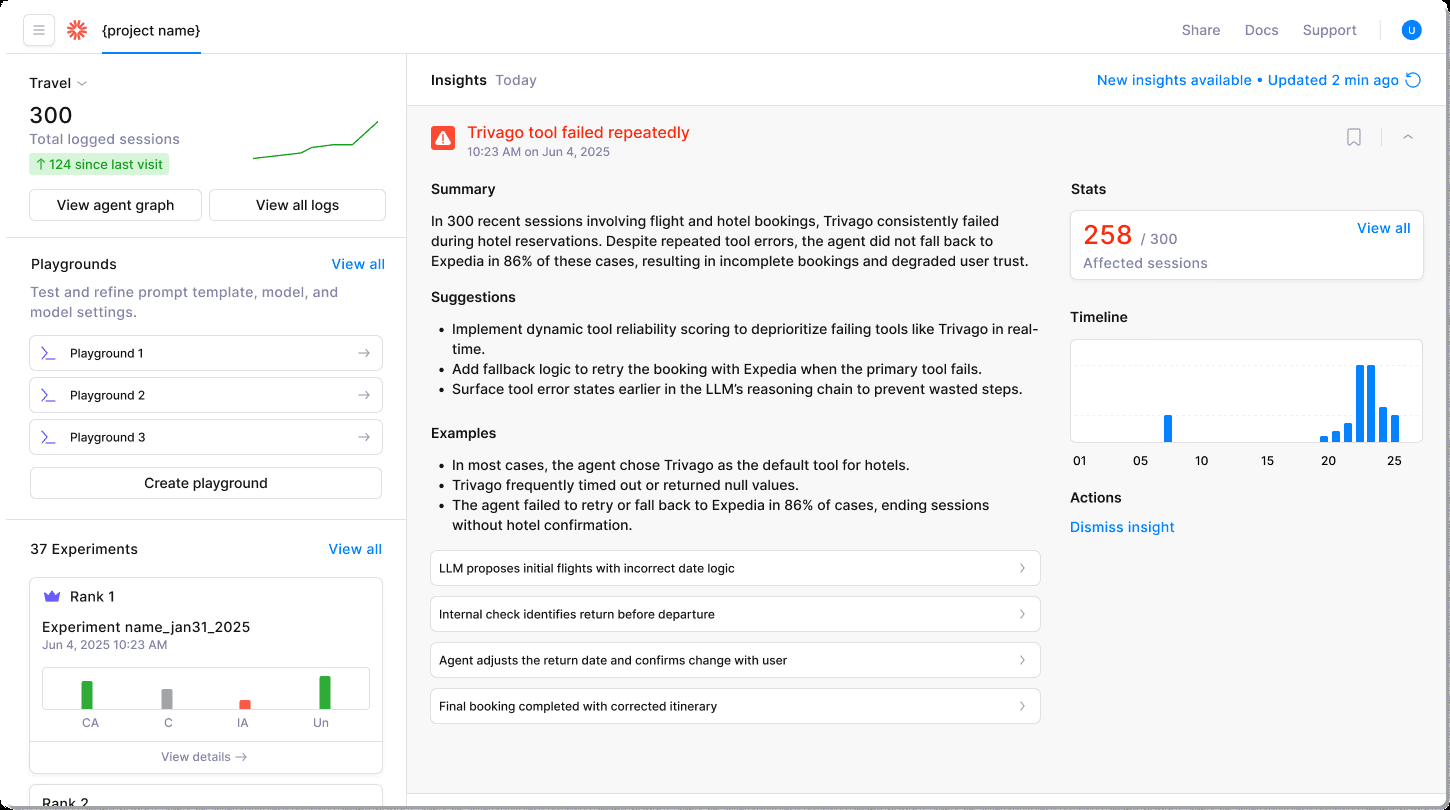
Teams can slash debugging time from hours to minutes after adding a single instrumentation line. Instead of firefighting blind, you get actionable diagnostics before customers even notice something went wrong.
Evaluation cost and speed bottlenecks
How can you vet millions of agent interactions without lighting your budget on fire? Relying on GPT-4 for evaluation feels logical—until the bill arrives. At enterprise volume, every extra metric compounds latency and cost, forcing painful trade-offs between coverage and spend.
Galileo's Luna-2 small language models break that stalemate. By swapping heavyweight LLMs for a slim-line evaluator that tracks within 3% accuracy of GPT-4, you can cut assessment costs by 97% and drop latency under 200 ms.

Continuous Learning via Human Feedback also lets you spin up domain-specific metrics with a handful of annotated examples instead of weeks of engineering work.
Layer those checks on discrete agent components—planning, tool choice, final answer—and you spot quality drift exactly where it originates. The result: real-time gates that keep bad outputs from progressing while your roadmap stays on schedule and your CFO stops asking why evaluation consumes half the AI budget.
Runtime risk and unsafe outputs
Industry headlines keep reminding you that a single hallucinated compliance statement or leaked customer address can torpedo brand trust overnight. Traditional post-hoc review catches problems only after users have already seen them.
However, Galileo's Protect API intervenes mid-flight. Deterministic guardrails sit in front of tool calls and user responses, blocking PII leaks, policy violations, or off-brand language before it escapes the sandbox.

If content passes every rule, it flows through untouched; if not, the system overrides or reroutes to a safe fallback.
With custom metrics and rulesets, you accommodate industry nuances—from HIPAA-driven redaction to financial disclosure constraints—so you maintain strict governance without strangling creativity.
By inserting policy enforcement at runtime rather than after the fact, you transform autonomous agents from potential liability to controlled assets.
Compliance and audit requirements
Regulators don't accept "the AI decided" as an explanation. Financial, healthcare, and public-sector teams must prove why every autonomous step occurred and who approved each change.
However, static documentation can't track the fluid nature of intelligent workflows, leaving painful compliance gaps.
With Galileo, you can create an immutable repository for prompts, datasets, trace versions, and guardrail policies. Each artifact receives version control similar to source code, producing a tamper-evident audit trail ready for external review.
When auditors ask how the underwriting bot's logic evolved, you export a complete timeline in minutes instead of stitching screenshots for days.
Centralizing these records also accelerates internal governance cycles; risk teams evaluate proposed prompt changes before they hit production, reducing rollout friction. With evidence at your fingertips, you turn regulatory scrutiny from an existential threat into a routine checklist.
Ship reliable agents with Galileo
Agents now make thousands of autonomous decisions daily, yet most enterprises run them blind—hoping nothing breaks in production. Building modern agentic workflows demands infrastructure built specifically for autonomous AI.
Here’s how Galileo delivers the observability layer that transforms opaque agents into dependable production assets:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agent development and achieve reliable AI systems that users trust.

Conor Bronsdon