Best Practices for AI Model Validation in Machine Learning

Your team just shipped an LLM-powered autonomous agent. Logs show successful completions. Latency looks good. Then customer complaints start piling up: the system hallucinated a policy that does not exist, selected the wrong tool for a routine request, and confidently contradicted your own documentation.
Your model passed every offline benchmark. In production, it still fails in ways your validation process never tested for.
That gap defines modern AI model validation. You need continuous, production-aware validation across the full lifecycle, from development experiments to live monitoring, with evals that catch how your autonomous agents actually fail.
TLDR:
Holdout testing misses many production failures in agentic systems
Validation should span development, release gates, and live monitoring
LLM apps need behavioral metrics, not just accuracy scores
Automated eval pipelines catch regressions before release
Runtime guardrails add a final production safety layer
What Is AI Model Validation?
AI model validation is the process of confirming that your model performs reliably on data and scenarios it was not trained on. It helps you verify accuracy, safety, and business fit before and after deployment.
If you work on traditional machine learning, your validation process likely focuses on statistical generalization. You trained on one split, tested on another, and checked whether metrics like accuracy, precision, recall, and F1 held up. That approach works when outputs are deterministic, and the correct answer is clear.
If you ship agentic systems, validation has to go further. LLM applications and autonomous agents produce variable outputs, make multi-step decisions, and interact with tools in non-deterministic ways. Your model can score well on a benchmark and still hallucinate, ignore instructions, or misuse a tool in production. Modern validation measures behavior across quality, safety, and compliance, not just prediction accuracy.
Why Traditional Validation Falls Short for Agentic Systems
The validation methods that worked for classical ML break down once your workflow starts generating open-ended responses, planning across steps, and calling tools. You are no longer validating only prediction quality. You are validating behavior under changing prompts, changing context, and changing production conditions.
The next two sections show where legacy validation misses important failure modes and why agent observability now belongs in your validation stack.
Static Benchmarks Miss Production Behavior
Static benchmarks assume a stable input-output mapping. Given input X, the correct output is Y. That assumption weakens quickly for agentic systems, where multiple responses may be acceptable and where tool use changes the path entirely.
A benchmark score cannot tell you whether your autonomous agents followed instructions, selected the right tool, or stayed grounded in the retrieved context. Here is what those benchmarks usually miss:
Hallucinated facts that sound plausible
Wrong tool choices during multi-step flows
Instruction drift across long conversations
Unsafe outputs that violate policy
Suppose your support assistant answers 95% of product questions correctly in offline testing. In production, it may still call the refund workflow for a billing question because the prompt phrasing changed.
That single behavior matters more than the average benchmark score because it creates real support costs and customer frustration. If you rely on static benchmarks alone, you validate general competence instead of production behavior.
One-Time Validation Cannot Catch Drift and Degradation
Even if your workflow validates well before release, production behavior changes. Retrieval quality shifts as documents change. Tool contracts evolve. Upstream model updates alter responses without warning. A one-time checkpoint cannot cover those moving parts.
You need post-deployment measurement to confirm reliable behavior in real-world conditions and to detect drift, degradation, and unexpected consequences early. That matters even more when your production agents operate in narrow domains, where small failures carry outsized risk.
A common pattern emerges when your workflow looks stable at launch and degrades quietly afterward. You see more retries, longer conversations, and subtle changes in tool usage before anyone files a complaint. Continuous validation and agent observability help you catch that earlier, shorten root-cause analysis, and avoid learning about failures from your customers first.
Choosing the Right Validation Metrics for Your AI System
Your metric set determines what you can catch. If you validate an autonomous workflow with the wrong metrics, you create false confidence and ship with blind spots. For agentic systems, you need to measure decision quality, safety, efficiency, and consistency under changing conditions, which requires agentic performance metrics alongside classical ones.
Classical ML Metrics Still Matter for Deterministic Tasks
Accuracy, precision, recall, F1, and ROC-AUC still matter when your task has a clear right answer. If you are validating fraud detection, churn prediction, or document classification, these metrics remain your baseline.
They just do not tell the whole story for generative systems. A strong classifier metric says nothing about latency, cost, instruction following, or whether your production agents completed the right workflow safely. Use classical metrics when you have deterministic outputs, but widen the lens when production risk grows. A practical validation stack includes classical metrics for prediction quality, behavioral metrics for LLM outputs, operational metrics such as latency and cost, and safety metrics for risky or regulated flows.
Think about a fintech onboarding flow. Your model might classify document types accurately while still failing to escalate edge cases that need human review. That combination of classical and behavioral metrics gives your team a more realistic release signal than any single score.
Behavioral Metrics Matter More for Autonomous Agents
If you ship autonomous agents, you need metrics built for open-ended, multi-step behavior. For LLM applications, that often includes context adherence, instruction adherence, correctness, and completeness.
For production agents, the list expands to tool selection quality, action completion, reasoning coherence, and efficiency. Safety metrics add another layer; PII detection, prompt injection resistance, toxicity screening, and bias checks often catch the failures that traditional validation misses entirely.
Here is where these metrics become operationally useful:
Context adherence catches unsupported answers in RAG flows
Tool selection quality reveals wrong API or workflow choices
Action completion shows whether the task was actually finished
Agent efficiency exposes wasteful loops and redundant steps
Say you are running an e-commerce shopping guide. The most expensive failure may not be a bad answer. It may be the wrong action, like applying the wrong inventory lookup or skipping a required escalation. Measuring those behaviors directly gives you a better release signal than a generic accuracy number and helps your team connect model behavior to customer impact and cost.
Building a Validation Pipeline From Development to Production
Validation works best as a pipeline, not a single gate. You need one layer for fast iteration in development, one for automated release decisions, and one for live production feedback. Development sets expectations, CI/CD enforces them, and production validation confirms they still hold under real traffic.
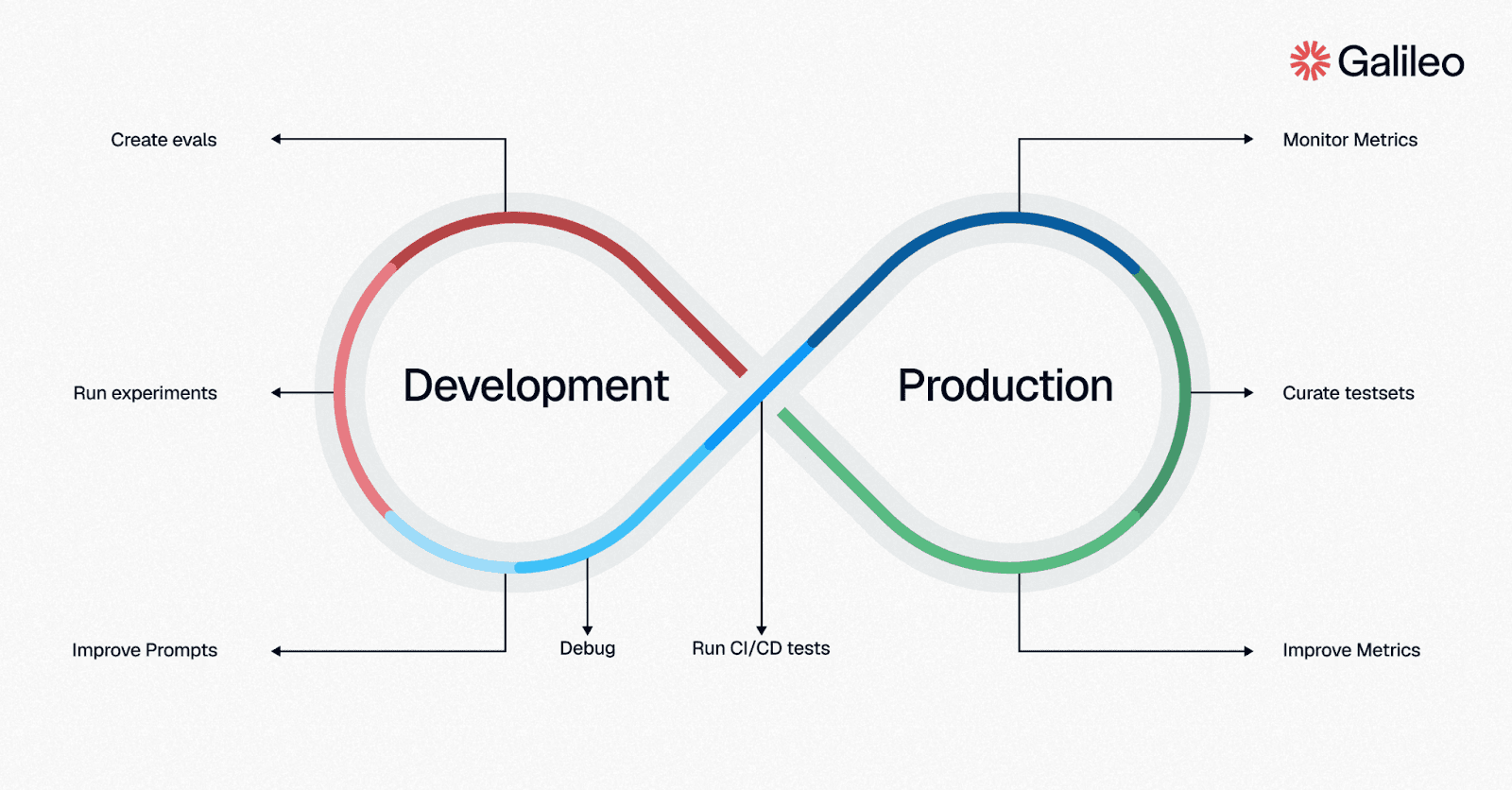
Start With Experiment-Driven Evals in Development
Your first job is to create controlled experiments that compare prompts, models, and configurations against versioned datasets. That gives you a repeatable way to decide what actually improved.
Keep your datasets separated by purpose. Synthetic examples help you stress edge cases. Development sets support fast iteration. Production-sampled sets reveal what your live traffic really looks like.
Here is a simple development workflow:
Compare multiple prompts or models side by side
Score them on quality, safety, and tool behavior
Save datasets and results with version control
Re-test after each prompt, model, or tool change
The goal is test-driven evals. Define expected behavior first, then iterate until your workflow meets it consistently. Picture this in a SaaS support flow: a prompt tweak improves answer quality but reduces tool selection quality.
Without side-by-side evals, you might ship a regression that looks like progress during manual testing. A disciplined experiment loop keeps your team from confusing anecdotal improvement with real reliability gains.
Add Automated Evals to CI/CD Gates
Your development evals should become deployment gates. If a change fails quality thresholds, your pipeline should block the release automatically.
Manual vibe checks do not scale when your prompts, retrieval logic, and tool schemas change every week. You need automated checks that run the same way every time, especially when your team is moving fast.
A good CI/CD gate mixes several test types:
Golden dataset checks for known outcomes
LLM-as-judge scoring for subjective quality
Programmatic tests for repeatable failure modes
Adversarial tests for malicious inputs
This plays out in production as fewer bad releases and faster shipping confidence. If your developer copilot suddenly starts selecting file-editing tools when it should only retrieve context, a CI gate can catch the regression before you create customer-facing damage and rollback work. The release process becomes less dependent on intuition and more grounded in repeatable evidence.
Monitor Production Continuously for Drift and Failure Patterns
Post-deployment validation means scoring real production traces, not just curated test cases. That is where you see drift, emerging failure modes, and shifts in cost or latency.
Track both technical and business-facing signals. Your list does not need to be huge, but it does need to reflect your workflow:
Cost per successful task
Latency at p50, p90, and p99
Error rates by failure category
Tool invocation success and failure rates
Action completion and reasoning quality
Consider a healthcare triage flow. If action completion stays flat but latency spikes and tool failures rise, your workflow may still be technically finishing tasks while creating operational risk and poor user experience.
Continuous monitoring plus agent observability gives you session-level visibility into where things went wrong, whether in retrieval, planning, tool use, or policy handling. Automated failure detection, such as Signals, can also surface recurring failure clusters that manual log review often misses.
Preventing Validation Failures Before They Reach Your Users
Even strong eval pipelines leave gaps. You cannot anticipate every production scenario, so you also need protections that act at runtime.
That matters most when a bad answer or tool call could create immediate harm. In those cases, detection after the fact is helpful, but prevention is better.
Turn Offline Evals Into Runtime Guardrails
The most useful validation insight is the one that prevents harm before a response is shown or a tool call executes. That is the eval-to-guardrail pattern: use the same standards from development as live enforcement rules.
In practice, that means you can block hallucinated answers, redact PII, or intercept prompt injections in real time. The operational value is straightforward. You reduce legal exposure, lower review load, and keep more incidents from reaching your customers.
Here is what that looks like in practice:
Score a response against a safety or quality threshold
Trigger a deterministic action when it fails
Override, redact, or route before user impact
Say your team ships production agents in healthcare, retail, or developer tooling. A runtime layer gives you more control when static testing cannot cover every case. It also closes the gap between what you measured offline and what you enforce in production, which is what turns validation from reporting into prevention.
Surface Unknown Failure Patterns in Production Traces
Some production failures are impossible to predefine. You may know to test for hallucinations and tool errors, but not for a new multi-turn policy drift pattern that appears only after a provider update or tool interaction change.
That is why automated pattern detection matters. Instead of searching logs manually, you want systems that cluster recurring issues, rank them by severity, and point you toward the traces worth reviewing first.
Your VP of Engineering just asked why agent quality dipped last week. No single trace looks dramatic. Across hundreds of sessions, though, the pattern is clear: your autonomous agents started leaking internal policy language after a retrieval update.
When you find a new pattern, turn it into a new eval. That closes the loop from unknown issue to repeatable prevention, which is how validation becomes a reliability system instead of a QA checklist. Your team learns from production in a structured way instead of treating every incident as a one-off surprise.
Common AI Model Validation Mistakes and How to Avoid Them
Most validation failures come from false confidence. A benchmark passed, a test suite ran, and the release looked fine. Production usually exposes the shortcuts, and these mistakes show up across SaaS, e-commerce, developer tooling, fintech, and healthcare.
The failure mode changes by workflow, but incomplete validation creates avoidable incidents that erode executive confidence in your AI strategy.
Validating Only at Deployment Time
Treating validation as a one-time launch gate is the most common mistake. You test, you ship, and then behavior changes quietly over the next week.
This happens because your production environment does not stay still. Documents change. Retrieval quality shifts. Tool schemas evolve. Provider updates alter outputs. Prompts from real customers become longer and messier than anything in your test set.
Here is where things break down most often:
Policy or knowledge sources change after launch
Retrieval returns stale or conflicting context
Tool behavior shifts without model retraining
Real prompts become more adversarial over time
Three sprints ago, your team noticed your customer support autonomous agents started giving outdated refund exceptions after a policy update. Nothing appeared broken in a narrow system sense, but support volume rose, and trust dropped.
To avoid that trap, validate before deployment and after deployment with production-sampled evals and drift checks. If your team waits for complaints, you are already too late.
Relying on One Metric or Generic Benchmarks
A single metric can hide the exact failures that matter most. You may see strong overall accuracy while critical workflows underperform.
That is especially dangerous in agentic systems because business risk often sits in a thin slice of traffic. Your e-commerce assistant may answer product questions well, but mishandle the discount policy. Your developer copilot may write valid code, but choose unsafe tools. Your fintech workflow may complete most tasks but fail on the minority that trigger compliance review.
Use a multi-dimensional scorecard instead. Include quality, safety, and operational metrics, then slice them by workflow or risk level.
That means tracking correctness and context adherence alongside PII and injection detection, latency and cost per task, and segment-level breakdowns by intent or workflow type. This approach helps you prioritize what actually affects revenue, support burden, and trust instead of optimizing for a single average score.
Ignoring Domain Rules and Safety Requirements
Generic evals rarely capture the rules that matter most in your product. If you do not encode domain requirements into validation, your workflow can look strong overall while failing in the exact moments your stakeholders care about.
The differences across workflows illustrate this clearly. Your healthcare assistant may need to separate education from advice. Your SaaS admin copilot may need explicit confirmation before destructive actions. Your fintech onboarding flow may need escalation rules for identity checks.
Your validation process should reflect those realities with domain-specific criteria, auditability, and human review where needed.
In practice, that usually means building custom evals tied to product or policy rules, incorporating domain expert review for ambiguous edge cases, maintaining audit trails for high-risk workflows, and defining human escalation paths for asymmetric downside.
When your governance standards become part of product quality, you reduce cleanup later and make expansion into new workflows easier. Domain-specific validation is how you scale safely without relearning the same lesson in every release.
Making Validation a Reliable Part of Your AI Stack
AI model validation works best as an ongoing reliability practice, not a one-time gate. You need development evals to compare changes, CI/CD gates to block regressions, production validation to catch drift, and runtime controls to prevent the highest-risk failures from reaching your customers.
When you build those layers together, you ship faster without giving up trust, safety, or operational visibility.
Galileo is the agent observability and guardrails platform built for teams shipping reliable production agents, connecting evals, observability, and guardrails in one workflow:
Metrics Engine: Measure quality, safety, and agentic behavior with 20+ out-of-the-box and custom metrics
Experiments: Compare prompts, models, and configurations against versioned datasets before release
Signals: Surface recurring failure patterns across production traces so your team can investigate faster
Runtime Protection: Block unsafe outputs, redact sensitive data, and enforce policies in real time
CLHF: Improve metric accuracy by 20-30% over time with as few as 2-5 targeted human feedback examples
Book a demo to see how continuous validation can help you ship more reliable production agents.
FAQs
What Is AI Model Validation in Machine Learning?
AI model validation is the process of checking whether your model performs reliably on new data and scenarios outside training. In traditional ML, that usually means holdout testing and cross-validation. In agentic systems, it also includes behavioral checks like instruction following, tool use, groundedness, and safety.
How Do You Validate LLMs and Autonomous Agents Differently From Traditional ML Models?
Traditional ML validation relies on fixed test sets and metrics like accuracy or F1. If you ship LLM applications and autonomous agents, you need broader evals, including context adherence, tool selection quality, action completion, and safety checks. You also need production validation because behavior changes over time.
What Metrics Should You Use for AI Model Validation?
Use accuracy, precision, recall, F1, and ROC-AUC for deterministic tasks. For LLM systems, add context adherence, instruction adherence, correctness, and completeness. For autonomous agents, add action completion, reasoning coherence, agent efficiency, and safety checks like PII detection and prompt injection resistance.
Do You Need Both Pre-Deployment and Production Validation?
Yes. Pre-deployment validation catches issues before release and helps you block regressions in CI/CD. Production validation catches drift, changing prompt patterns, upstream dependency shifts, and new failure modes that only appear under live traffic. The combination is what separates reactive debugging from proactive reliability.
How Does Galileo Support AI Model Validation Across the Full Lifecycle?
Galileo supports development experiments, agent observability, automated evals, failure detection, and runtime guardrails in one workflow. That lets you compare configurations before release, inspect live production behavior after launch, and turn offline eval standards into real-time protections with the eval-to-guardrail lifecycle. For AI teams shipping production agents, that reduces debugging time and improves reliability at scale.

Pratik Bhavsar