

Between 70 to 85% of generative AI deployments stall before reaching production. Some analyses even push enterprise failure rates to 95%, with 42% of companies simply abandoning their AI projects rather than fighting their reality. These numbers reveal how often promising agent pilots die, squandering months of work and budget.
When an AI agent misfires in production, you feel the cost immediately—broken workflows, compliance headaches, frustrated customers, and diverted engineering hours. Unlike traditional software, AI agents reason across non-deterministic paths, manage long context windows, and call external tools autonomously.
A single error ripples through multiple systems before anyone notices.
That doesn’t have to be your reality. What follows addresses these issues directly. You'll explore ten common AI agent failure modes, learn how to detect each one in production, and walk away with practical debugging and prevention tactics that protect your operations.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies
AI agent failure mode #1: Hallucination cascade
You probably remember the courtroom fiasco where lawyers cited six non-existent precedents generated by a language model. The judge imposed sanctions, and headlines spread worldwide. That episode captures a hallucination cascade: one confident lie snowballing into legal, financial, and brand damage.
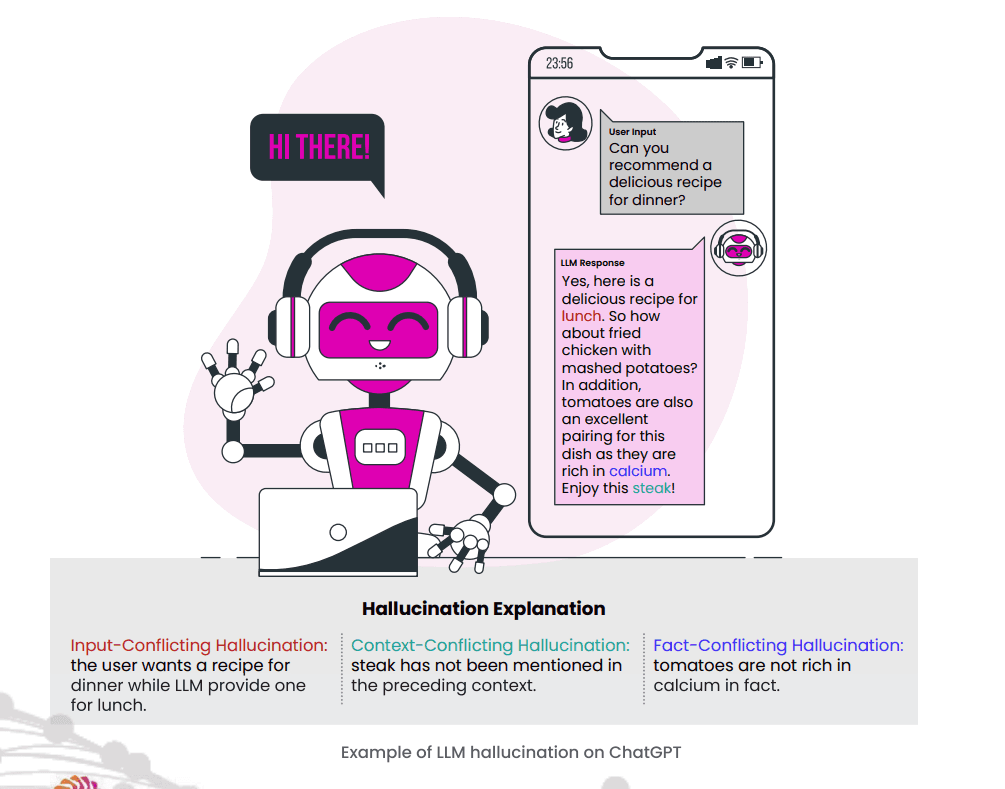
In your production agents, the same risk lurks behind every response. These cascades erode trust and invite compliance scrutiny, contributing to why so many enterprise AI projects stumble before delivering value.
The spiral begins predictably. Missing retrieval hits leave the model to invent facts, aggressive decoding settings amplify creativity, and multi-step reasoning compounds each slip until fiction poses as fact.
Spotting the spiral early is crucial. Watch for spikes in semantic-divergence scores or proprietary hallucination metrics. When users flag confusing answers, jump into Galileo's Graph Engine: it aligns every turn, letting you trace the first divergence and run an embed-based diff between the prompt and the suspect output.

Once the culprit turn is isolated, tighten the loop. Add fact-checking unit tests, lower sampling temperature, and insert retrieval filters. Deploy guardrail metrics in production—they block or quarantine content that drifts beyond verified context, stopping a single hallucination from metastasizing into a full-scale incident.

AI agent failure mode #2: Tool invocation misfires
Imagine your finance agent misconfigures a payment transfer, sending negative amounts that lock customer accounts and trigger compliance incidents. These tool invocation failures drive much of the project failure rate in those enterprise surveys.
They occur when an agent's planner sends ambiguous instructions to an API, relies on outdated schemas, or omits required parameters.
You typically notice the damage first: p95 latency spikes, HTTP 4xx/5xx response floods, or workflows that abort mid-execution. Traditional logs bury the initiating decision under layers of downstream errors.
However, purpose-built observability platforms like Galileo surface tool error metric and tool-selection quality scores in real time, pinpointing the exact decision that generated the malformed payload.
Debugging becomes forensic analysis once you identify the source. Inspect structured traces to compare expected schemas with actual dispatched parameters. Modern span-level visualization highlights mismatched fields, while diff views reveal whether the fault originated from prompt drift or broken integrations.
Prevention requires systematic safeguards. Enforce strict API contracts and version every schema. Simulate tool usage during CI and embed graceful fallbacks so null returns don't cascade into system failures.
With these guardrails and live metrics monitoring for misfires, you keep workflows operational instead of cleaning up after them.
AI agent failure mode #3: Context window truncation
Long Slack tickets, sprawling support chats—before you know it, your agent has quietly dropped the most critical instructions. Users get responses that feel random: missing references, half-finished steps, or explanations that directly contradict earlier turns. The model's reasoning stays sharp, but it never saw the complete picture.
Truncation strikes when multi-turn histories or verbose attachments consume tokens faster than your summarizer can compress them. Poorly pruned memories compound the problem alongside verbose system prompts and inefficient encoding, often sacrificing the tail end—typically the latest user request—first.
Spotting this silent failure requires watching for sudden accuracy drops on lengthy threads, unexplained logic jumps, or frustrated users asking more follow-up questions.
Once your agent experiences context loss, two approaches restore stability. Tighten token budgets through dynamic pruning, hierarchical memories, and auto-summaries that preserve intent without excess detail.
Then, instrument your traces—span-level comparison shows precisely which sentences vanished, letting you redesign prompts or add compression before your agents lose track of what matters most.
AI agent failure mode #4: Planner infinite loops
Nothing shreds your cloud budget faster than an agent that can't decide it's finished. When a planner loops endlessly—writing the same checklist, calling the same sub-task, or re-asking the same clarifying question—you pay for every wasted token while users stare at a spinning cursor.
These runaway cycles trigger downstream rate limits, starving other workloads and eroding trust just as badly as an outright crash.
Ambiguous success criteria usually sit at the root of the problem. Without clear "done" criteria, the planner circles forever, especially when two steps produce nearly identical confidence scores.
Symptoms surface quickly: identical planner traces repeating in logs, sudden token-usage spikes, and p95 latency marching upward. Leverage modern observability metrics like Agent Efficiency score to flag these patterns automatically, letting you spot a loop minutes after it appears instead of after the month-end bill.
Breaking the cycle starts with visibility. Galileo's Insights Engine groups repeated spans so you can inspect one representative loop rather than hundreds, then you can implement tighter exit conditions or cost caps.
Once you confirm the fix, guardrails enforce deterministic termination rules, back-off strategies, and hard timeouts—ensuring a single misconfigured prompt never spirals into uncontrolled compute or a stalled user experience.
AI agent failure mode #5: Data leakage & PII exposure
Imagine your agent just exposed a customer's social security number in a chat log. Privacy breaches often derail enterprise AI projects because safeguards arrive too late in the build cycle. When regulators step in, fines and remediation costs dwarf any projected ROI.
Why does leakage happen? Over-broad retrieval pipelines drag sensitive rows into prompts, prompt injections slip through naive sanitizers, and output filters rely on brittle regex patterns. Traditional monitoring flags HTTP errors, not subtle privacy breaches, leaving you blind until customers complain.
Modern detection starts with lightweight regex screens paired with LLM-based scanners tuned for names, addresses, and account numbers. Platforms like Galileo take this further through Luna-2 metrics—a small language model can help you evaluate every agent response in sub-200 ms, catching exposures your handcrafted rules miss.

When a leak surfaces, trace history lets you walk the retrieval path step by step, validating whether the source document should have been accessible.
Prevention requires architectural discipline. Limit retrieval scopes to least-privilege indices, enforce schema version checks, and mask sensitive fields before they reach the model. Real-time guardrails powered by Luna-2 can redact or block risky outputs on the fly, maintaining continuous compliance even as prompts evolve.
AI agent failure mode #6: Non-deterministic output drift
You can spend days tuning a prompt, only to discover that the same request suddenly produces three different answers in production. This silent drift—outputs changing even when inputs and context remain stable—undercuts test reliability and leaves users doubting your agent's competence.
As seen earlier, industry surveys show up to 85% of generative-AI deployments miss their objectives due to quality issues. Drift is more than an annoyance; it's a leading reason projects stall or get abandoned entirely.
Why does it happen? Temperature settings creep upward during rapid experiments, a seemingly minor model upgrade tweaks token sampling, embeddings shift after a retrain, or latent context mutates across sessions.
Each change seeds randomness that cascades into conflicting answers and brittle integrations.
Spotting the pattern early is crucial. Variance spikes on p95 dashboards, flurries of regression test failures, or frustrated support tickets signal trouble.
Modern observability platforms such as Galileo can help you surface these anomalies: the experimentation framework can help you run A/B comparisons, while trace-comparison tools diff seeds, prompts, and context windows to pinpoint the exact divergence.
Once you identify the root cause, lock down the entropy. Drop temperatures for deterministic paths, pin seeds in critical journeys, enforce canonical prompts through version control, and ship upgrades behind shadow deployments.
Combined with continuous variance monitoring, these guardrails keep your agent's voice—and your credibility—consistent.
AI agent failure mode #7: Memory bloat & state drift
You've probably watched an otherwise well-behaved agent grind to a halt after dredging up week-old scraps of conversation. That slowdown isn't your infrastructure—it's memory bloat. As the vector store swells with every partial thought, retrieval calls return irrelevant facts, responses grow incoherent, and p95 latency spikes.
Most enterprise AI projects falter because hidden issues like this derail production rollouts—few teams anticipate how an unbounded memory layer compounds cost and confusion over time.
You need session monitoring to spotlight the problem early. You can watch store size climb in real time, see which writes triggered needless recalls, and trace a sluggish turn back to a single bloated span. That visibility beats scrolling through raw embeddings or guessing which chat history line poisoned the context window.
Once you isolate the culprit, pruning becomes mechanical: delete stale keys, replay the trace with a trimmed memory set, then compare latency and output coherence. Multi-span visualization makes the before-and-after delta obvious, so it fixes land with confidence rather than hope.
To keep the issue from resurfacing, adopt strict hygiene practices. TTL policies expire entries after a defined horizon, while relevance-scored retention writes only context likely to help future turns.
Automatic resets trigger on session boundaries or when store size breaches a safe threshold. With guardrails like these in place, your agent recalls what matters, forgets what doesn't, and stays fast enough for production traffic.
AI agent failure mode #8: Latency spikes & resource starvation
You probably know the feeling: response times suddenly triple, queues back up, and anxious pings start rolling in because the agent missed its SLO. Latency spikes rarely stay isolated—left unchecked, they snowball into user frustration, breached contracts, and budget blowouts that contribute to the high failure rate seen across generative AI deployments.
Slowdowns trace back to predictable culprits. For instance, a planner chains three heavyweight models instead of one, concurrent tool calls overwhelm shared GPUs, or an over-generous context window forces unnecessary token processing.
Each misstep can starve upstream resources and trigger cascading failures across services.
Early warning lives in your telemetry. Monitor p95 latency charts, async work-queue depth, and memory pressure. Custom dashboards overlay these signals with agent-specific metrics—tool selection counts, context window size—pinpointing exactly where latency spiked.

When incidents hit, traces reveal the story metrics can't tell. Expand each planner step, tool invocation, and model hop, exposing hotspots that traditional APM traces miss. You'll see that the summarization subroutine ballooned from 200 ms to 1.8 s after a silent model upgrade.
Prevention beats firefighting. Adopt asynchronous orchestration, cache repeat model calls, cap concurrency per agent, and reserve lightweight fallback models for peak traffic. Proactive alerts combined with these tactics keep resource starvation from derailing production agents.
AI agent failure mode #9: Emergent multi-agent conflict
Imagine your discount bot just slashed prices while your revenue optimizer simultaneously raised them. This exact chaos—autonomous agents issuing conflicting actions—drives the sobering reality that most generative AI deployment efforts falter.
The real culprit isn't model quality but the absence of shared state and coordination. Agents pursuing isolated goals overwrite databases, trigger duplicate API calls, and undo each other's work, leaving customers confused and systems unstable.
Early detection saves you from cascading failures. Watch for divergent audit logs, repeated rollbacks, and unusual spikes in compensating transactions—these patterns signal agent conflicts before they explode.
Purpose-built observability platforms dig deeper: multi-agent tracing maps every decision path, exposing where objectives clash and identifying which agent triggered the first conflicting action. Agent Flow lets you inspect each justification and pinpoint the exact step that initiated the contradiction.
Prevention starts with governance, not clever code. Establish a central coordinator where agents must publish intent before acting. Add arbitration rules for contested resources and require explicit locks before high-risk operations.
Layer in automatic rollbacks so one bad decision doesn't cascade. When conflicts surface despite your safeguards, the same tracing data that alerted you becomes your roadmap for rapid, surgical fixes.
AI agent failure mode #10: Evaluation blind spots & unknown unknowns
You probably assume your test suite covers every danger zone, yet reality proves otherwise. Most enterprise AI initiatives falter at deployment because hidden edge cases escape lab-grade evaluations and surface only after users complain or metrics dive unexpectedly.
Most teams make the same mistake: treating agent evaluation like a checkpoint rather than an ongoing investigation. They build comprehensive test suites, validate against golden datasets, and ship with confidence—only to discover their agents crumble when users phrase requests differently or mention entities that weren't in training data.
Static benchmarks also freeze yesterday's worldview while your model learns and mislearns in production.
The breakthrough comes from turning production interactions into evaluation opportunities. Modern observability requires capturing every user interaction and piping it into Continuous Learning via Human Feedback (CLHF), which promotes anomalies to first-class training data. When an unexpected spike in latency or accuracy appears, CLHF automatically flags the blind spot and guides retraining.
Once an issue surfaces, you mine production traces to reconstruct the offending path, then clone it into a new test scenario using dataset management tools. Comparing fresh and historical runs reveals whether the bug stems from context drift, model upgrades, or unforeseen user intent.
This approach transforms unknown unknowns into monitored, fixable problems. You synthesize edge-case prompts, diversify evaluation datasets, and loop CLHF back into the pipeline. Your guardrails evolve as fast as your users, catching issues before they become support tickets.
Ship reliable AI agents with Galileo
Encountering blind spots when AI agents interact with customers isn't a luxury enterprises can afford. Such gaps not only mean missed opportunities but also potential losses in customer trust and operational efficiency. You can't afford blind spots when agents interact with real customers.
Here’s how Galileo unifies observability, evaluation, and runtime protection, setting a new standard in AI agent reliability:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Discover how Galileo can empower you to build reliable agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.

Conor Bronsdon