
Optimizing retrieval results in a RAG system requires various modules to work together in unison. A crucial component of this process is the reranker, a module that improves the order of documents within the retrieved set to prioritize the most relevant items. Let’s dive into the intricacies of selecting an optimal reranker for RAG systems, including the significance of rerankers, scenarios demanding their use, potential drawbacks, and the diverse types available.
What is a Reranker?
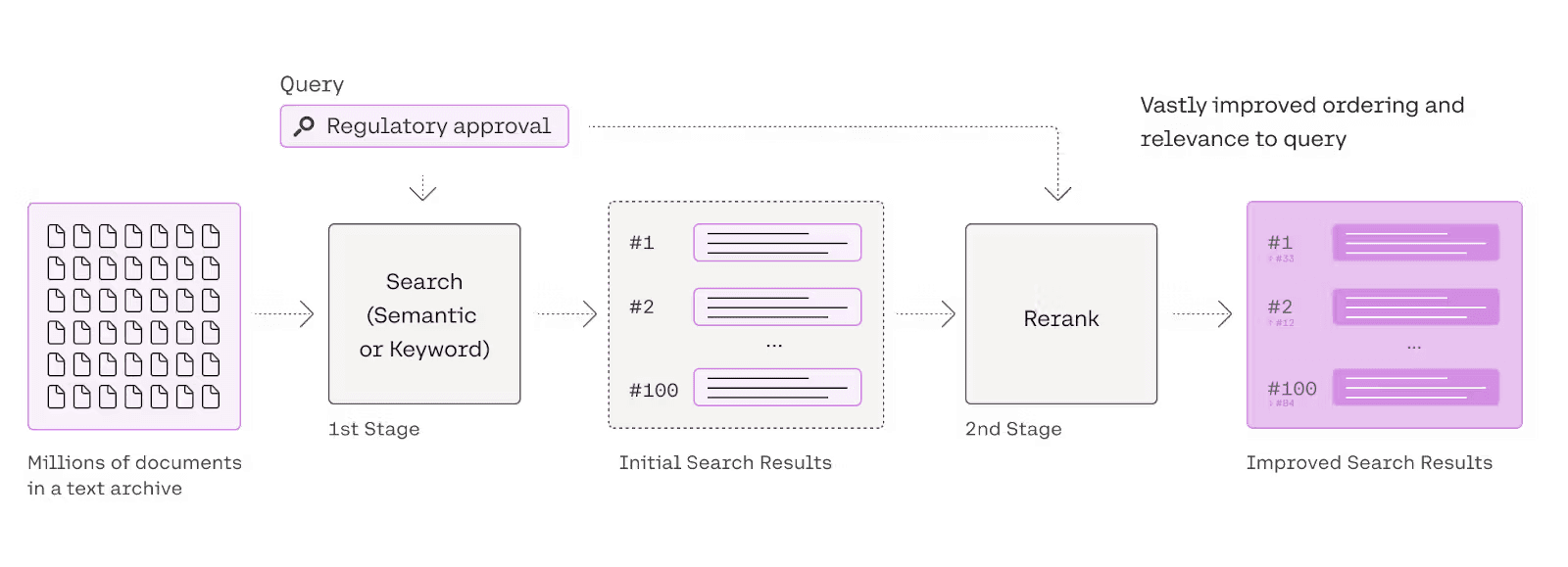
A reranker, functioning as the second-pass document filter in information retrieval(IR) systems, focuses on reordering documents retrieved by the initial retriever (semantic search, keyword search, etc.). This reordering is based on the query-document relevance, emphasizing the quality of document ranking. Balancing efficiency with effectiveness, rerankers prioritize the enhancement of search result quality, often involving more complex matching methods than traditional vector inner products.
Why We Need Rerankers

We know that hallucinations happen when unrelated retrieved docs are included in output context. This is exactly where rerankers can be helpful! They rearrange document records to prioritize the most relevant ones. This not only helps address hallucinations but also saves money during the RAG process. Let’s explore this need in more detail and why rerankers are necessary.
Limitations of Embeddings
Let's examine why embeddings fail to adequately address retrieval challenges. Their generalization issues present significant obstacles in real-world applications.
Limited Semantic Understanding
While embeddings capture semantic information, they often lack contrastive information. For example, embeddings may struggle to distinguish between "I love apples" and "I used to love apples" since both convey a similar semantic meaning.
Dimensionality Constraints
Embeddings represent documents or sentences in a relatively low-dimensional space, typically with a fixed number of dimensions (e.g., 1024). This limited space makes it challenging to encode all relevant information accurately, especially for longer documents or queries.
Generalization Issues
Embeddings must generalize well to unseen documents and queries, which is crucial for real-world search applications. However, due to their dimensionality constraints and training data limitations, embeddings-based models may struggle to generalize effectively beyond the training data.

How Rerankers Work
Rerankers fundamentally surpass the limitations of embeddings, rendering them valuable for retrieval applications.
Bag-of-Embeddings Approach
Early interaction models like cross encoders and late-interaction models like ColBERT adopt a bag-of-embeddings approach. Instead of representing documents as single vectors, they break documents into smaller, contextualized units of information.
Semantic Keyword Matching
Reranker models combine the power of strong encoder models, such as BERT, with keyword-based matching. This allows them to capture semantic meaning at a finer granularity while retaining the simplicity and efficiency of keyword matching.
Improved Generalization
They alleviate generalization issues faced by traditional embeddings by focusing on smaller contextualized units. They can better handle unseen documents and queries, leading to improved retrieval performance in real-world scenarios.
Types of Rerankers
Rerankers have been used for years, but the field is rapidly evolving. Let's examine current options and how they differ.
Model | Type | Performance | Cost | Example |
Cross encoder | Open source | Great | Medium | BGE, sentence, transformers, Mixedbread |
Multi-vector | Open source | Good | Low | ColBERT |
LLM | Open source | Great | High | RankZephyr, RankT5 |
LLM API | Private | Best | Very High | GPT, Claude |
Rerank API | Private | Great | Medium | Cohere, Mixedbread, Jina |
Cross-Encoders
Cross-encoder models redefine the conventional approach by employing a classification mechanism for pairs of data. The model takes a pair of data, such as two sentences, as input, and produces an output value between 0 and 1, indicating the similarity between the two items. This departure from vector embeddings allows for a more nuanced understanding of the relationships between data points.
It's important to note that cross-encoders require a pair of "items" for every input, making them unsuitable for handling individual sentences independently. In the context of search, a cross-encoder is employed with each data item and the search query to calculate the similarity between the query and the data object.
Here is a snippet of how to use state-of-the-art rerankers like BGE.
from FlagEmbedding import FlagReranker reranker = FlagReranker('BAAI/bge-reranker-base, use_fp16=True) score = reranker.compute_score(['query', 'passage']) print(score) scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
Multi-Vector Rerankers
Cross encoders perform very well, but what about alternative options that require less compute?
Multi-vector embedding models like ColBERT feature late interaction, where the interaction between query and document representations occurs late in the process, after both have been independently encoded. This approach contrasts with early interaction models like cross-encoder, where query and document embeddings interact at earlier stages, potentially leading to increased computational complexity. While in case of cosine similarity of embeddings for retrieval, there is no interaction!
The late interaction design allows for the pre-computation of document representations, contributing to faster retrieval times and reduced computational demands, making it suitable for processing large document collections.
ColBERT offers the best of both worlds, so let's see how it is implemented. Below is a code snippet of from Jina’s blog.
import torch def compute_relevance_scores(query_embeddings, document_embeddings, k): """Compute relevance scores for top-k documents given a query.""" scores = torch.matmul(query_embeddings.unsqueeze(0), document_embeddings.transpose(1, 2)) max_scores_per_query_term = scores.max(dim=2).values total_scores = max_scores_per_query_term.sum(dim=1) sorted_indices = total_scores.argsort(descending=True) return sorted_indices
How the score is calculated using late interaction:
Dot Product: It computes the dot product between the query embeddings and document embeddings. This operation is performed using torch.matmul(), which calculates the matrix multiplication between query_embeddings.unsqueeze(0) (unsqueeze is used to add a batch dimension) and document_embeddings.transpose(1, 2) (transposed to align dimensions for multiplication). The result is a tensor with shape [k, num_query_terms, max_doc_length], where each element represents the similarity score between a query term and a document term.
Max pooling: Max-pooling operation is applied across document terms (dimension 2) to find the maximum similarity score per query term. This is done using scores.max(dim=2).values. The resulting tensor has shape [k, num_query_terms], where each row represents the maximum similarity scores for each query term across all documents.
Total scoring: The maximum scores per query term are summed up to get the total score for each document. This is done using .sum(dim=1), resulting in a tensor with shape [k] containing the total relevance score for each document.
Sorting: The documents are sorted based on their total scores in descending order using .argsort(descending=True).
Here is a code snippet using Jina-ColBERT - a ColBERT-style model but based on JinaBERT so it can support 8k context with better retrieval. The extra context length can help reduce the reliance on chunking techniques.
from colbert.modeling.checkpoint import Checkpoint from colbert.infra import ColBERTConfig query = ["How to use ColBERT for indexing long documents?"] documents = [ "ColBERT is an efficient and effective passage retrieval model.", "Jina-ColBERT is a ColBERT-style model but based on JinaBERT so it can support both 8k context length.", "JinaBERT is a BERT architecture that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.", "Jina-ColBERT model is trained on MSMARCO passage ranking dataset, following a very similar training procedure with ColBERTv2.", ] config = ColBERTConfig(query_maxlen=32, doc_maxlen=512) ckpt = Checkpoint(args.reranker, colbert_config=colbert_config) Q_emb = ckpt.queryFromText([all_queries[i]]) D_emb = ckpt.docFromText(all_passages, bsize=32)[0] D_mask = torch.ones(D.shape[:2], dtype=torch.long) scores = colbert_score(Q_emb, D_emb, D_mask).flatten().cpu().numpy().tolist() ranking = numpy.argsort(scores)[::-1]
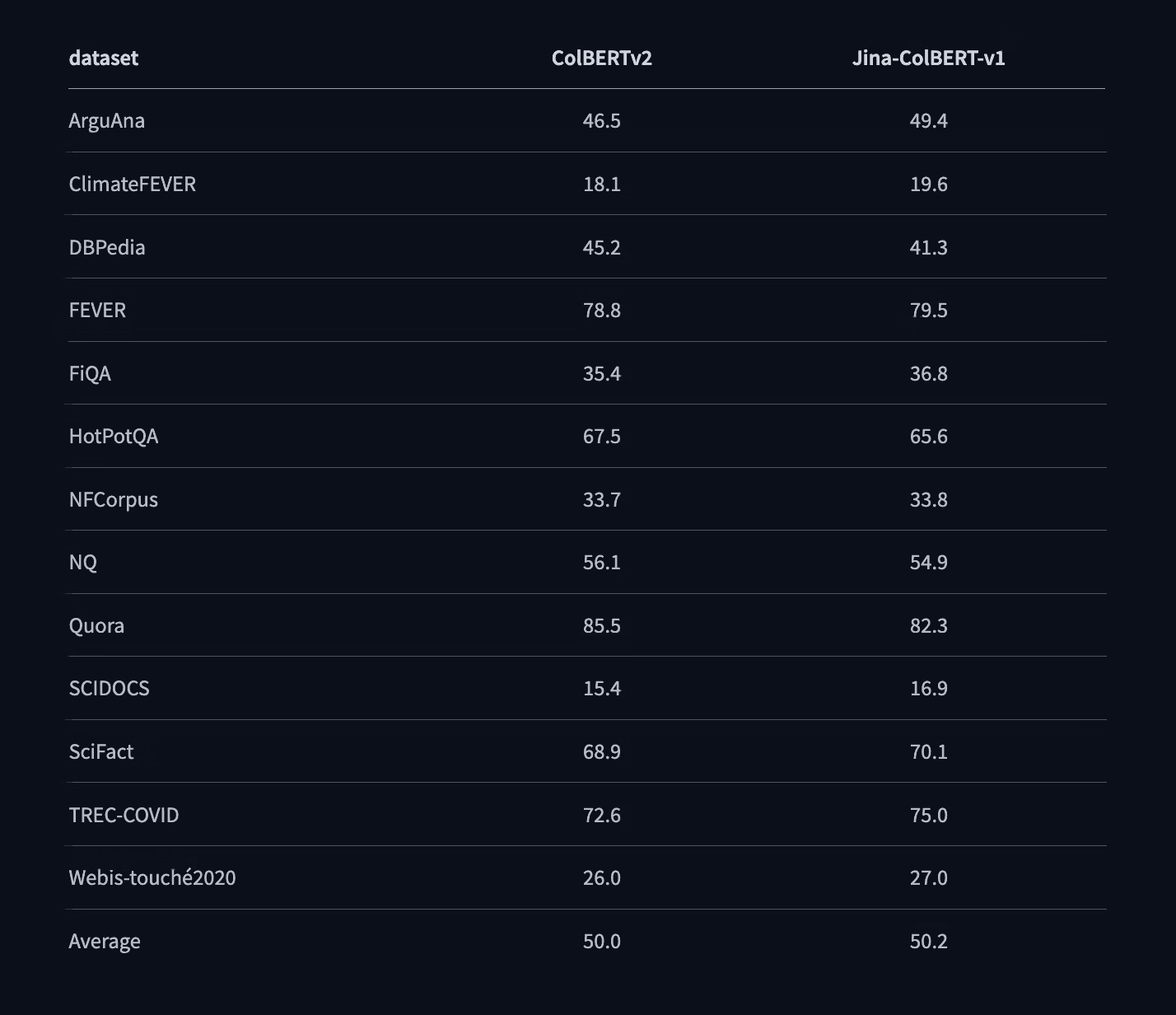
Below is the comparison between Jina-ColBERT-v1-en and state-of-the-art late interaction model ColBERT-v2. Both show nearly similar zero-shot performance on 13 public BEIR datasets, rendering it a worthy candidate for reranking.
LLMs for Reranking
As LLMs grow in size, surpassing 10 billion parameters, fine-tuning the reranking model becomes progressively more challenging. Recent endeavors have aimed to tackle this issue by prompting LLMs to improve document reranking autonomously. Broadly, these prompting strategies fall into three categories: pointwise, listwise, and pairwise methods.
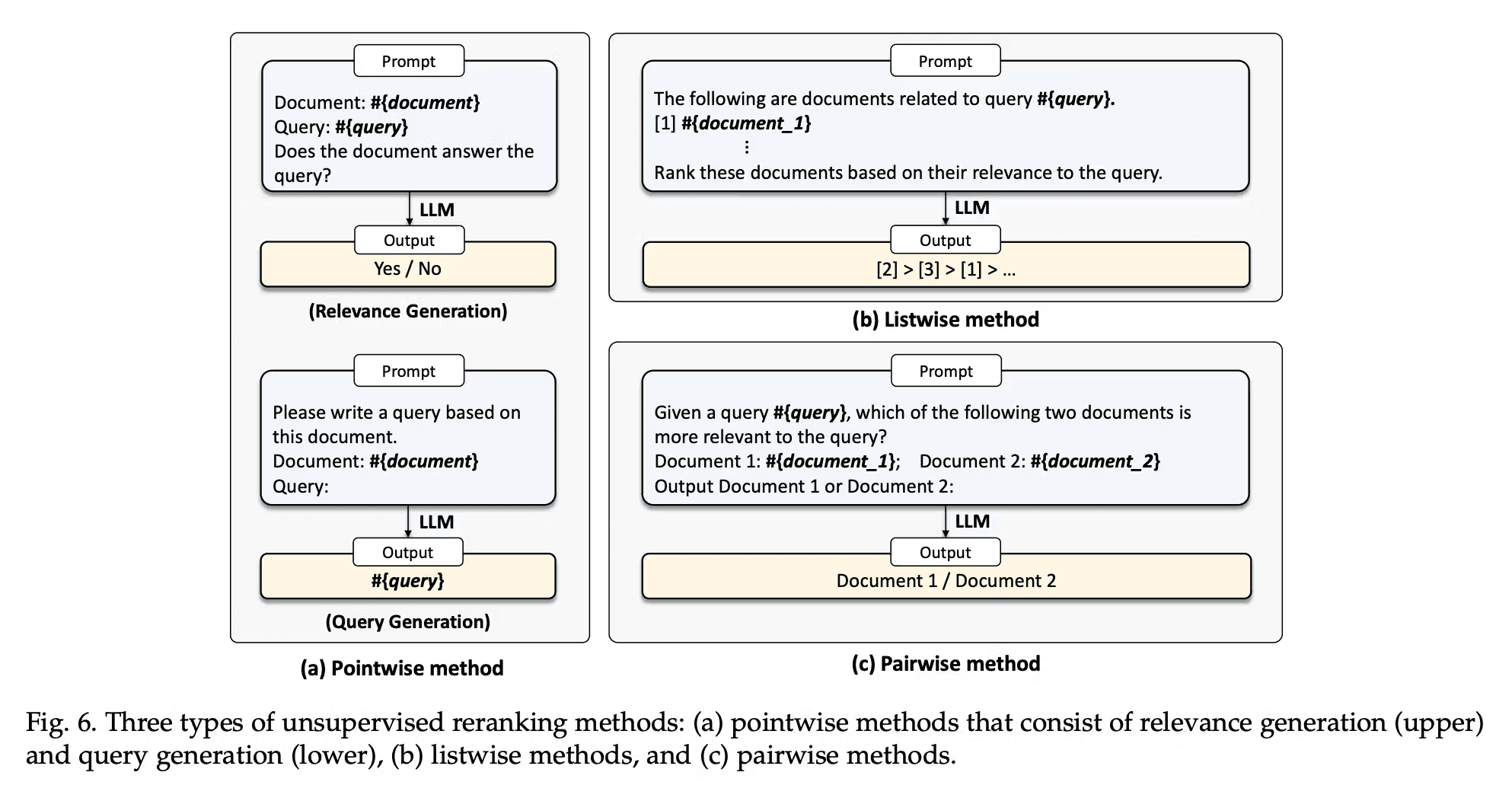
Pointwise Methods
Pointwise methods measure relevance between a query and a single document. Subcategories include relevance generation and query generation, both effective in zero-shot document reranking.
Listwise Methods
Listwise methods directly rank a list of documents by inserting the query and a document list into the prompt and instructing the LLMs to output the reranked document identifiers. Due to the limited input length of LLMs, inserting all candidate documents into the prompt is not feasible. To address this issue, these methods employ a sliding window strategy to rerank a subset of candidate documents each time. This involves ranking from back to front using a sliding window and re-ranking only the documents within the window at a time.
Pairwise Methods
In pairwise methods, LLMs receive a prompt containing a query and a document pair. They are then directed to generate the identifier of the document deemed more relevant. Aggregation methods like AllPairs are employed to rerank all candidate documents. AllPairs initially generates all potential document pairs and consolidates a final relevance score for each document. Efficient sorting algorithms like heap sort and bubble sort are typically utilized to expedite the ranking process.
This can be accomplished with the help of GPT-3.5, GPT4 and GPT4-Turbo, where the last one offers the best tradeoff between cost and performance.
Supervised LLMs Rerankers
Supervised fine-tuning is a critical step when applying pre-trained LLMs to reranking tasks. Due to the lack of ranking awareness during pre-training, LLMs cannot accurately measure query-document relevance. Fine-tuning on task-specific ranking datasets, such as MS MARCO passage ranking dataset, allow LLMs to adjust parameters for improved reranking performance. Supervised rerankers can be categorized based on the backbone model structure into two types.
Encoder-Decoder
Studies in this category mainly formulate document ranking as a generation task, optimizing an encoder-decoder-based reranking model. For example, the RankT5 model is fine-tuned to generate classification tokens for relevant or irrelevant query-document pairs.
Decoder-only
Recent attempts involve reranking documents by fine-tuning decoder-only models, such as LLaMA. Different approaches, including RankZephyr and RankGPT, propose various methods for relevance calculation.
Private Reranking APIs
Hosting and improving rerankers is often challenging. Private reranking APIs offer a convenient solution for organizations seeking to enhance their search systems with semantic relevance without making an infrastructure investment. Below, we look into three notable private reranking APIs: Cohere, Jina, and Mixedbread.
Cohere
Cohere's rerank API offers rerank models tailored for English and multilingual documents, each optimized for specific language processing tasks. Cohere automatically breaks down lengthy documents into manageable chunks for efficient processing. The API delivers relevance scores normalized between 0 and 1, facilitating result interpretation and threshold determination.
Jina
Jina's reranking API, exemplified by jina-colbert-v1-en, specializes in enhancing search results with semantic understanding with longer context lengths.
Mixedbread

Mixedbread offers a family of reranking models with an open-source Apache 2.0 license, empowering organizations to integrate semantic relevance into their existing search infrastructure seamlessly.
How to Select a Reranker
Several key factors need to be carefully considered when selecting a reranker to ensure optimal performance and compatibility with system requirements.
Relevance Improvement
The primary objective of adding a reranker is to enhance the relevance of search results. Evaluate the reranker's ability to improve the ranking in terms of retrieval metrics like NDCG or generation metrics like attribution.
Latency Considerations
Assess the additional latency introduced by the reranker to the search system. Measure the time required for reranking documents and ensure that it remains within acceptable limits for real-time or near-real-time search applications.
Contextual Understanding
Determine the reranker's ability to handle varying lengths of context in queries and documents. Some rerankers may be optimized for short text inputs, while others may be capable of processing longer sequences with rich contextual information.
Generalization Ability
Evaluate the reranker's ability to generalize across different domains and datasets. Ensure that the reranker performs well not only on training data but also on unseen or out-of-domain data to prevent overfitting and ensure robust performance in diverse search scenarios.

Latest Research on Comparison of Rerankers
How should you go about all these options? Recent research, highlighted in the paper A Thorough Comparison of Cross-Encoders and LLMs for Reranking SPLADE, sheds light on the effectiveness and efficiency of different reranking methods, especially when coupled with strong retrievers like SPLADEv3. Here are the key conclusions drawn from this research.
In-Domain vs. Out-of-Domain Performance
In the in-domain setting, differences between evaluated rerankers are not as pronounced. However, in out-of-domain scenarios, the gap between approaches widens, suggesting that the choice of reranker can significantly impact performance, especially across different domains.
Impact of Reranked Document Count
Increasing the number of documents to rerank has a positive impact on the final effectiveness of the reranking process. This highlights the importance of considering the trade-off between computational resources and performance gains when determining the optimal number of reranked documents.
Cross-Encoders vs. LLMs
Effective cross-encoders, when paired with strong retrievers, have shown the ability to outperform most LLMs in reranking tasks, except for GPT-4 on some datasets. Notably, cross-encoders offer this improved performance while being more efficient, making them an attractive option for reranking tasks.
Evaluation of LLM-based Rerankers
Zero-shot LLM-based rerankers, including those based on OpenAI and open models, exhibit competitive effectiveness, with some even matching the performance of GPT3.5 Turbo. However, the inefficiency and high cost associated with these models currently limit their practical use in retrieval systems, despite their promising performance.
Overall, the research highlights the significance of reranking methods in enhancing retrieval, with cross-encoders emerging as a particularly promising and efficient option. While LLM-based rerankers show competitive effectiveness, their practical deployment is hindered by inefficiency and high costs.
How to Evaluate Your Reranker
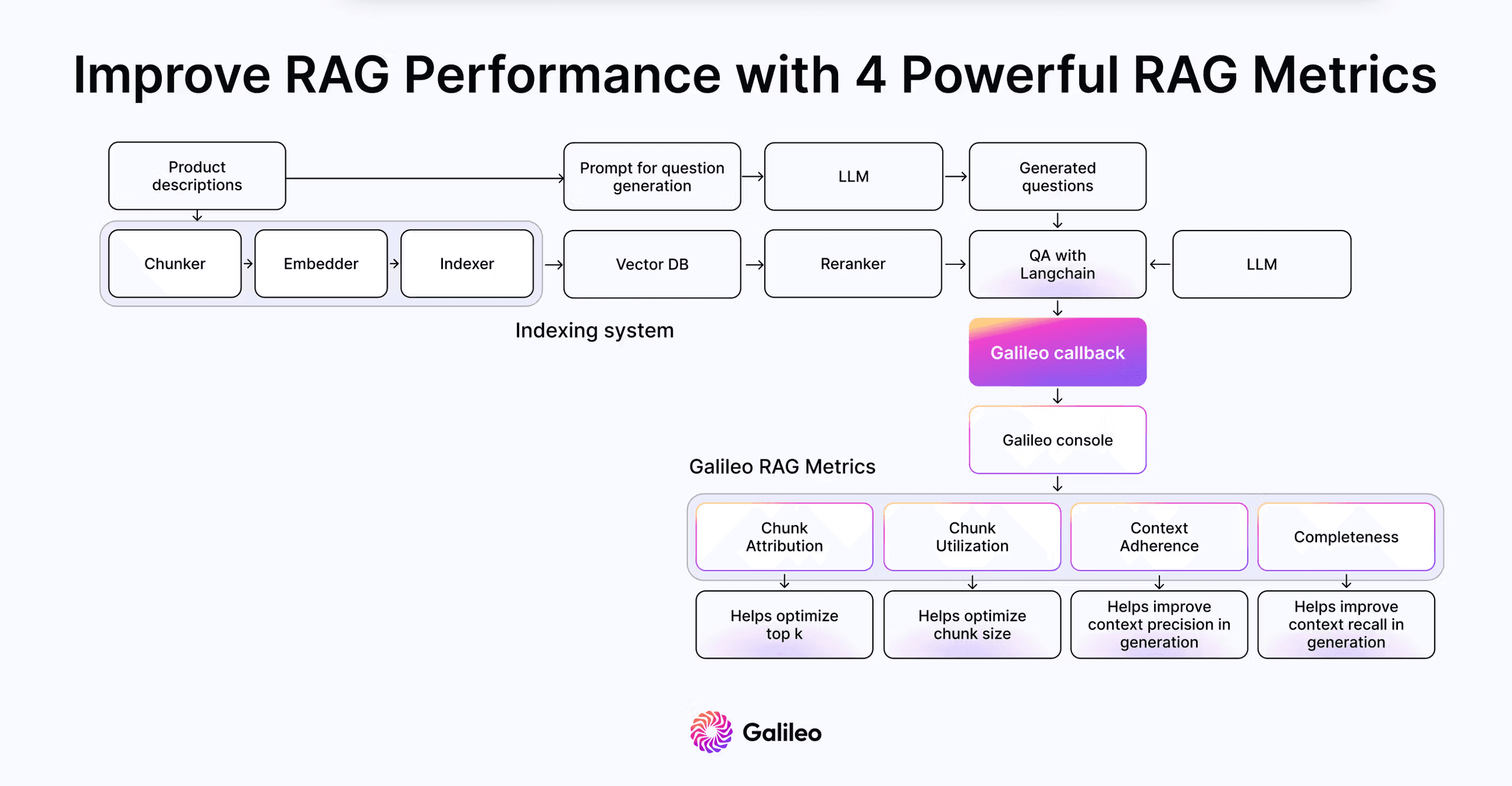
Let's continue with our last RAG example, where we built a Q&A system on Nvidia’s 10-k filings. At the time our goal was to evaluate embedding models. This time we want to see how we can evaluate a reranker.
We leverage the same data and introduce Cohere reranker in the RAG chain as shown below.
import os from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema.runnable import RunnablePassthrough from langchain.schema import StrOutputParser from langchain_community.vectorstores import Pinecone as langchain_pinecone from langchain.retrievers.contextual_compression import ContextualCompressionRetriever from langchain.retrievers.document_compressors import CohereRerank from pinecone import Pinecone def get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature): # setup retriever pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY")) index = pc.Index(index_name) vectorstore = langchain_pinecone(index, embeddings.embed_query, "text") compressor = CohereRerank(top_n=rerank_k) retriever = vectorstore.as_retriever(search_kwargs={"k": emb_k}) # https://github.com/langchain-ai/langchain/blob/master/libs/core/langchain_core/vectorstores.py#L553 # rerank retriever compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) # setup prompt rag_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the question based only on the provided context." ), ("human", "Context: '{context}' \n\n Question: '{question}'"), ] ) # setup llm llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature, tiktoken_model_name="cl100k_base") # helper function to format docs def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) # setup chain rag_chain = ( {"context": compression_retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser() ) return rag_chain
We modify our rag_chain_executor function to include emb_k and rerank_k which are the number of retrieved docs we want from OpenAI’s text-embedding-3-small retrieval and Cohere’s rerank-english-v2.0 reranker.
def rag_chain_executor(emb_model_name: str, dimensions: int, llm_model_name: str, emb_k: int, rerank_k: int) -> None: # initialise embedding model if "text-embedding-3" in emb_model_name: embeddings = OpenAIEmbeddings(model=emb_model_name, dimensions=dimensions) else: embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True}) index_name = f"{emb_model_name}-{dimensions}".lower() # First, check if our index already exists and delete stale index if index_name in [index_info['name'] for index_info in pc.list_indexes()]: pc.delete_index(index_name) # create a new index pc.create_index(name=index_name, metric="cosine", dimension=dimensions, spec=ServerlessSpec( cloud="aws", region="us-west-2" ) ) time.sleep(10) # index the documents _ = langchain_pinecone.from_documents(documents, embeddings, index_name=index_name) time.sleep(10) # load qa chain qa = get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature) # tags to be kept in galileo run run_name = f"{index_name}-emb-k-{emb_k}-rerank-k-{rerank_k}" index_name_tag = pq.RunTag(key="Index config", value=index_name, tag_type=pq.TagType.RAG) encoder_model_name_tag = pq.RunTag(key="Encoder", value=emb_model_name, tag_type=pq.TagType.RAG) llm_model_name_tag = pq.RunTag(key="LLM", value=llm_model_name, tag_type=pq.TagType.RAG) dimension_tag = pq.RunTag(key="Dimension", value=str(dimensions), tag_type=pq.TagType.RAG) emb_k_tag = pq.RunTag(key="Emb k", value=str(emb_k), tag_type=pq.TagType.RAG) rerank_k_tag = pq.RunTag(key="Rerank k", value=str(rerank_k), tag_type=pq.TagType.RAG) evaluate_handler = pq.GalileoPromptCallback(project_name=project_name, run_name=run_name, scorers=all_metrics, run_tags=[encoder_model_name_tag, llm_model_name_tag, index_name_tag, dimension_tag, emb_k_tag, rerank_k_tag]) # run chain with questions to generate the answers print("Ready to ask!") for i, q in enumerate(tqdm(questions)): print(f"Question {i}: ", q) print(qa.invoke(q, config=dict(callbacks=[evaluate_handler]))) print("\n\n") evaluate_handler.finish() pq.login("console.demo.rungalileo.io")
Now we can go ahead and run the same sweep with the required parameters.
pq.sweep( rag_chain_executor, { "emb_model_name": ["text-embedding-3-small"], "dimensions": [384], "llm_model_name": ["gpt-3.5-turbo-0125"], "emb_k": [10], "rerank_k": [3] }, )
The outcome isn't surprising! We get a 10% increase in attribution, indicating we now possess more relevant chunks necessary to address the question. Additionally, there's 5% improvement in Context Adherence, suggesting a reduction in hallucinations.
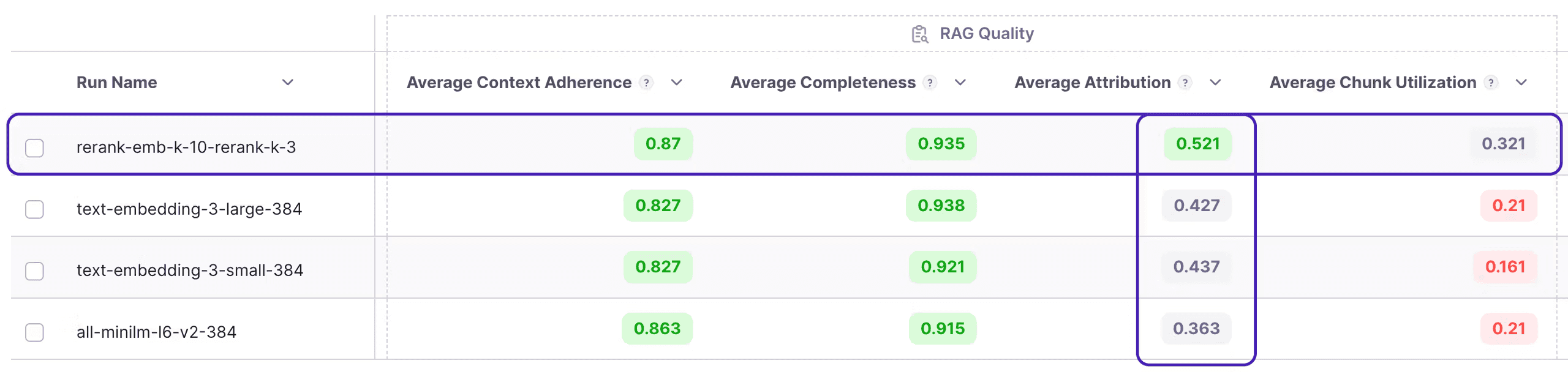
In most cases, we continue to seek further improvements rather than stopping at this point. Galileo Evaluate facilitates error analysis by examining individual runs and inspecting attributed chunks. The following illustrates the specific chunk attributed from the retrieved chunks in the vector DB.
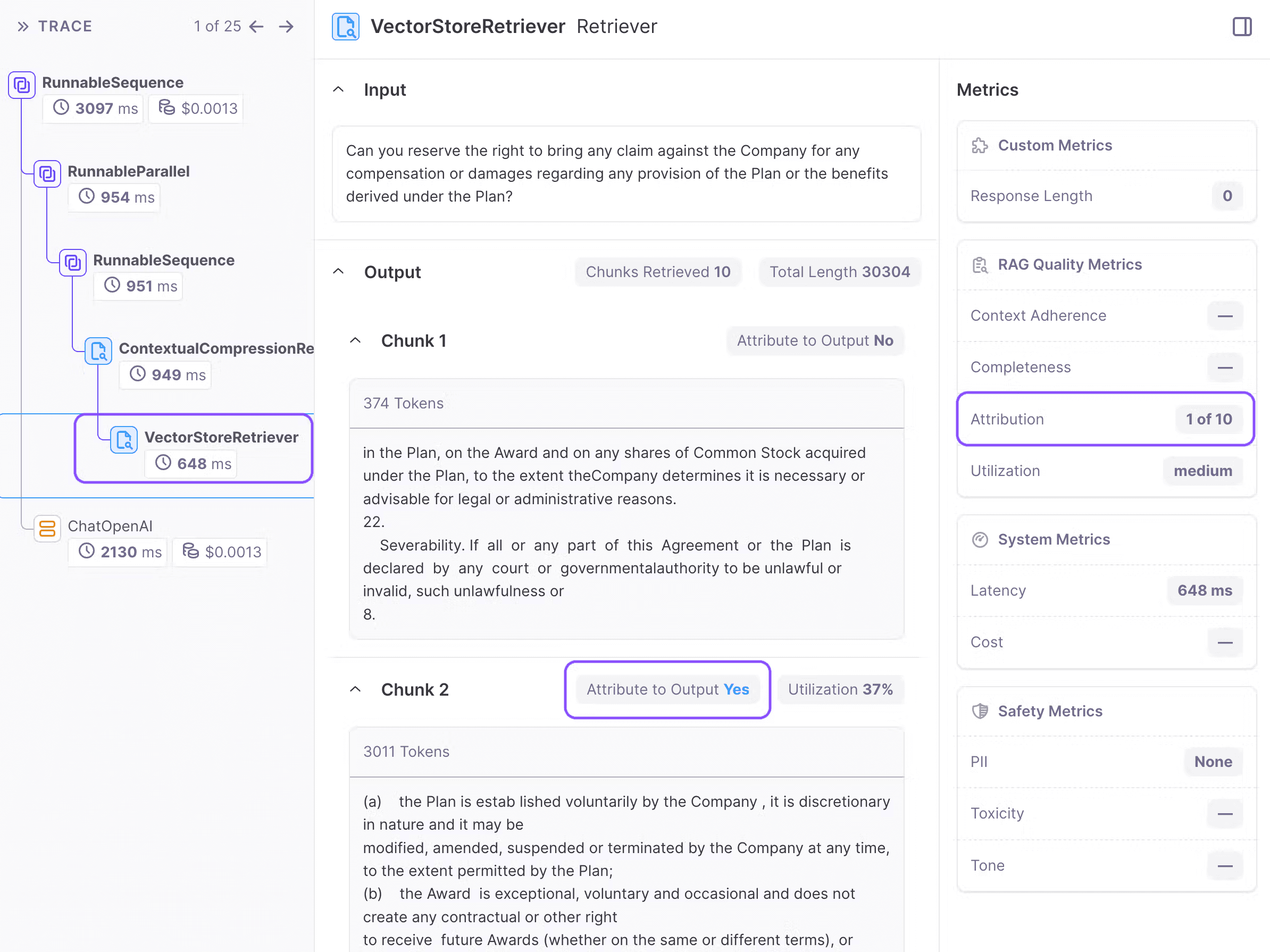
When we click the rerank node, we can see the total attributed chunks from the reranker and each chunk’s attribution(yes/no).
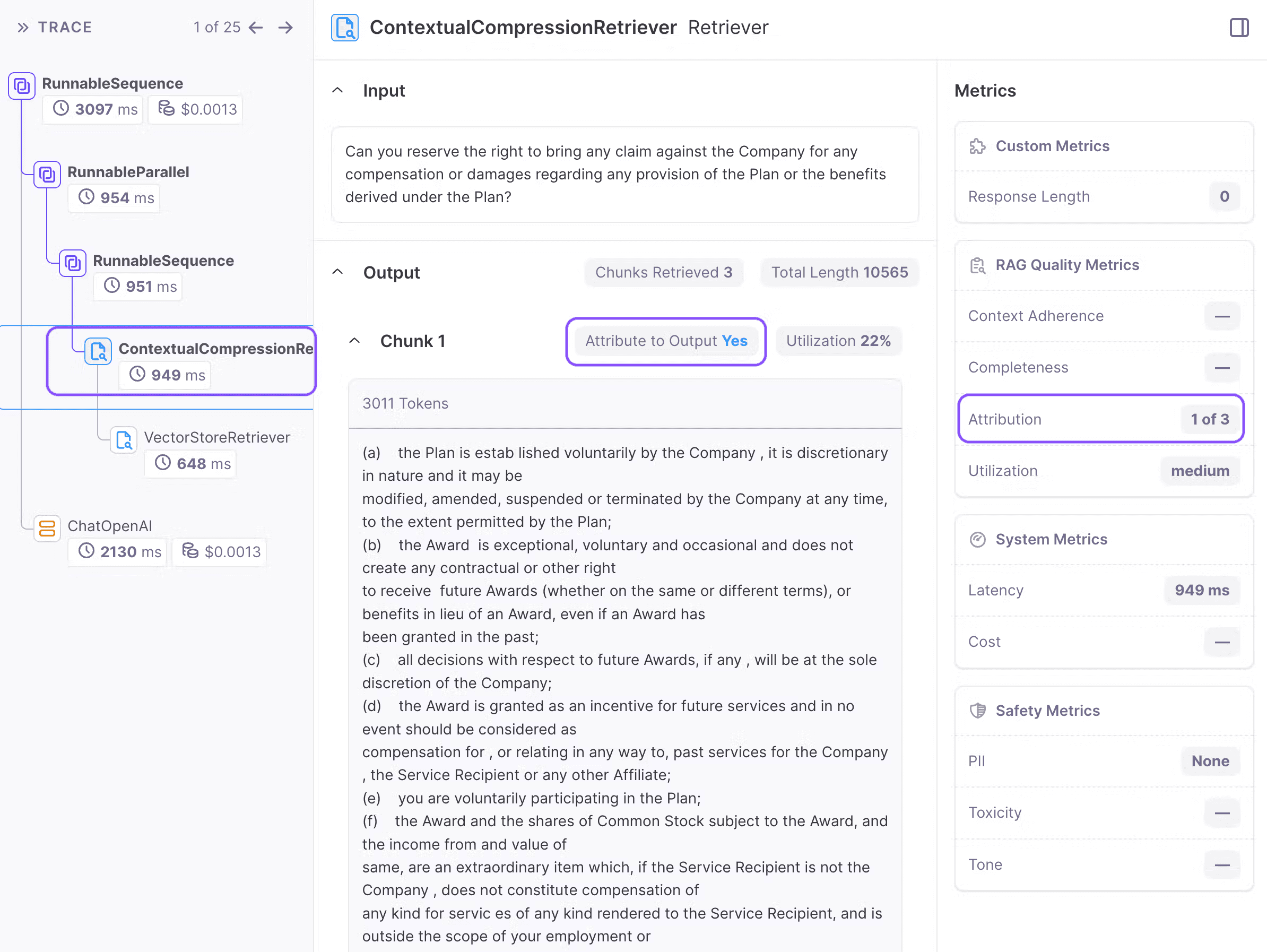
This approach enables us to swiftly conduct experiments with various rerankers to determine the most effective one for our needs.
Conclusion
The importance of selecting the appropriate reranker cannot be overstated in optimizing RAG systems and ensuring dependable search outcomes by mitigating hallucinations. A nuanced understanding of various reranker types, including cross-encoders and multi-vector models, underscores their pivotal role in augmenting search precision.
However, as the RAG pipeline matures, debugging complexities can hinder system improvements. By leveraging comprehensive observability across the entire pipeline, AI teams can build production-ready systems.
Get started with Galileo today for free, or download our free comprehensive guide for building enterprise-grade RAG systems to take the next step in your journey.
Optimizing retrieval results in a RAG system requires various modules to work together in unison. A crucial component of this process is the reranker, a module that improves the order of documents within the retrieved set to prioritize the most relevant items. Let’s dive into the intricacies of selecting an optimal reranker for RAG systems, including the significance of rerankers, scenarios demanding their use, potential drawbacks, and the diverse types available.
What is a Reranker?
A reranker, functioning as the second-pass document filter in information retrieval(IR) systems, focuses on reordering documents retrieved by the initial retriever (semantic search, keyword search, etc.). This reordering is based on the query-document relevance, emphasizing the quality of document ranking. Balancing efficiency with effectiveness, rerankers prioritize the enhancement of search result quality, often involving more complex matching methods than traditional vector inner products.
Why We Need Rerankers
We know that hallucinations happen when unrelated retrieved docs are included in output context. This is exactly where rerankers can be helpful! They rearrange document records to prioritize the most relevant ones. This not only helps address hallucinations but also saves money during the RAG process. Let’s explore this need in more detail and why rerankers are necessary.
Limitations of Embeddings
Let's examine why embeddings fail to adequately address retrieval challenges. Their generalization issues present significant obstacles in real-world applications.
Limited Semantic Understanding
While embeddings capture semantic information, they often lack contrastive information. For example, embeddings may struggle to distinguish between "I love apples" and "I used to love apples" since both convey a similar semantic meaning.
Dimensionality Constraints
Embeddings represent documents or sentences in a relatively low-dimensional space, typically with a fixed number of dimensions (e.g., 1024). This limited space makes it challenging to encode all relevant information accurately, especially for longer documents or queries.
Generalization Issues
Embeddings must generalize well to unseen documents and queries, which is crucial for real-world search applications. However, due to their dimensionality constraints and training data limitations, embeddings-based models may struggle to generalize effectively beyond the training data.
How Rerankers Work
Rerankers fundamentally surpass the limitations of embeddings, rendering them valuable for retrieval applications.
Bag-of-Embeddings Approach
Early interaction models like cross encoders and late-interaction models like ColBERT adopt a bag-of-embeddings approach. Instead of representing documents as single vectors, they break documents into smaller, contextualized units of information.
Semantic Keyword Matching
Reranker models combine the power of strong encoder models, such as BERT, with keyword-based matching. This allows them to capture semantic meaning at a finer granularity while retaining the simplicity and efficiency of keyword matching.
Improved Generalization
They alleviate generalization issues faced by traditional embeddings by focusing on smaller contextualized units. They can better handle unseen documents and queries, leading to improved retrieval performance in real-world scenarios.
Types of Rerankers
Rerankers have been used for years, but the field is rapidly evolving. Let's examine current options and how they differ.
Model | Type | Performance | Cost | Example |
Cross encoder | Open source | Great | Medium | BGE, sentence, transformers, Mixedbread |
Multi-vector | Open source | Good | Low | ColBERT |
LLM | Open source | Great | High | RankZephyr, RankT5 |
LLM API | Private | Best | Very High | GPT, Claude |
Rerank API | Private | Great | Medium | Cohere, Mixedbread, Jina |
Cross-Encoders
Cross-encoder models redefine the conventional approach by employing a classification mechanism for pairs of data. The model takes a pair of data, such as two sentences, as input, and produces an output value between 0 and 1, indicating the similarity between the two items. This departure from vector embeddings allows for a more nuanced understanding of the relationships between data points.
It's important to note that cross-encoders require a pair of "items" for every input, making them unsuitable for handling individual sentences independently. In the context of search, a cross-encoder is employed with each data item and the search query to calculate the similarity between the query and the data object.
Here is a snippet of how to use state-of-the-art rerankers like BGE.
from FlagEmbedding import FlagReranker reranker = FlagReranker('BAAI/bge-reranker-base, use_fp16=True) score = reranker.compute_score(['query', 'passage']) print(score) scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
Multi-Vector Rerankers
Cross encoders perform very well, but what about alternative options that require less compute?
Multi-vector embedding models like ColBERT feature late interaction, where the interaction between query and document representations occurs late in the process, after both have been independently encoded. This approach contrasts with early interaction models like cross-encoder, where query and document embeddings interact at earlier stages, potentially leading to increased computational complexity. While in case of cosine similarity of embeddings for retrieval, there is no interaction!
The late interaction design allows for the pre-computation of document representations, contributing to faster retrieval times and reduced computational demands, making it suitable for processing large document collections.
ColBERT offers the best of both worlds, so let's see how it is implemented. Below is a code snippet of from Jina’s blog.
import torch def compute_relevance_scores(query_embeddings, document_embeddings, k): """Compute relevance scores for top-k documents given a query.""" scores = torch.matmul(query_embeddings.unsqueeze(0), document_embeddings.transpose(1, 2)) max_scores_per_query_term = scores.max(dim=2).values total_scores = max_scores_per_query_term.sum(dim=1) sorted_indices = total_scores.argsort(descending=True) return sorted_indices
How the score is calculated using late interaction:
Dot Product: It computes the dot product between the query embeddings and document embeddings. This operation is performed using torch.matmul(), which calculates the matrix multiplication between query_embeddings.unsqueeze(0) (unsqueeze is used to add a batch dimension) and document_embeddings.transpose(1, 2) (transposed to align dimensions for multiplication). The result is a tensor with shape [k, num_query_terms, max_doc_length], where each element represents the similarity score between a query term and a document term.
Max pooling: Max-pooling operation is applied across document terms (dimension 2) to find the maximum similarity score per query term. This is done using scores.max(dim=2).values. The resulting tensor has shape [k, num_query_terms], where each row represents the maximum similarity scores for each query term across all documents.
Total scoring: The maximum scores per query term are summed up to get the total score for each document. This is done using .sum(dim=1), resulting in a tensor with shape [k] containing the total relevance score for each document.
Sorting: The documents are sorted based on their total scores in descending order using .argsort(descending=True).
Here is a code snippet using Jina-ColBERT - a ColBERT-style model but based on JinaBERT so it can support 8k context with better retrieval. The extra context length can help reduce the reliance on chunking techniques.
from colbert.modeling.checkpoint import Checkpoint from colbert.infra import ColBERTConfig query = ["How to use ColBERT for indexing long documents?"] documents = [ "ColBERT is an efficient and effective passage retrieval model.", "Jina-ColBERT is a ColBERT-style model but based on JinaBERT so it can support both 8k context length.", "JinaBERT is a BERT architecture that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.", "Jina-ColBERT model is trained on MSMARCO passage ranking dataset, following a very similar training procedure with ColBERTv2.", ] config = ColBERTConfig(query_maxlen=32, doc_maxlen=512) ckpt = Checkpoint(args.reranker, colbert_config=colbert_config) Q_emb = ckpt.queryFromText([all_queries[i]]) D_emb = ckpt.docFromText(all_passages, bsize=32)[0] D_mask = torch.ones(D.shape[:2], dtype=torch.long) scores = colbert_score(Q_emb, D_emb, D_mask).flatten().cpu().numpy().tolist() ranking = numpy.argsort(scores)[::-1]
Below is the comparison between Jina-ColBERT-v1-en and state-of-the-art late interaction model ColBERT-v2. Both show nearly similar zero-shot performance on 13 public BEIR datasets, rendering it a worthy candidate for reranking.
LLMs for Reranking
As LLMs grow in size, surpassing 10 billion parameters, fine-tuning the reranking model becomes progressively more challenging. Recent endeavors have aimed to tackle this issue by prompting LLMs to improve document reranking autonomously. Broadly, these prompting strategies fall into three categories: pointwise, listwise, and pairwise methods.
Pointwise Methods
Pointwise methods measure relevance between a query and a single document. Subcategories include relevance generation and query generation, both effective in zero-shot document reranking.
Listwise Methods
Listwise methods directly rank a list of documents by inserting the query and a document list into the prompt and instructing the LLMs to output the reranked document identifiers. Due to the limited input length of LLMs, inserting all candidate documents into the prompt is not feasible. To address this issue, these methods employ a sliding window strategy to rerank a subset of candidate documents each time. This involves ranking from back to front using a sliding window and re-ranking only the documents within the window at a time.
Pairwise Methods
In pairwise methods, LLMs receive a prompt containing a query and a document pair. They are then directed to generate the identifier of the document deemed more relevant. Aggregation methods like AllPairs are employed to rerank all candidate documents. AllPairs initially generates all potential document pairs and consolidates a final relevance score for each document. Efficient sorting algorithms like heap sort and bubble sort are typically utilized to expedite the ranking process.
This can be accomplished with the help of GPT-3.5, GPT4 and GPT4-Turbo, where the last one offers the best tradeoff between cost and performance.
Supervised LLMs Rerankers
Supervised fine-tuning is a critical step when applying pre-trained LLMs to reranking tasks. Due to the lack of ranking awareness during pre-training, LLMs cannot accurately measure query-document relevance. Fine-tuning on task-specific ranking datasets, such as MS MARCO passage ranking dataset, allow LLMs to adjust parameters for improved reranking performance. Supervised rerankers can be categorized based on the backbone model structure into two types.
Encoder-Decoder
Studies in this category mainly formulate document ranking as a generation task, optimizing an encoder-decoder-based reranking model. For example, the RankT5 model is fine-tuned to generate classification tokens for relevant or irrelevant query-document pairs.
Decoder-only
Recent attempts involve reranking documents by fine-tuning decoder-only models, such as LLaMA. Different approaches, including RankZephyr and RankGPT, propose various methods for relevance calculation.
Private Reranking APIs
Hosting and improving rerankers is often challenging. Private reranking APIs offer a convenient solution for organizations seeking to enhance their search systems with semantic relevance without making an infrastructure investment. Below, we look into three notable private reranking APIs: Cohere, Jina, and Mixedbread.
Cohere
Cohere's rerank API offers rerank models tailored for English and multilingual documents, each optimized for specific language processing tasks. Cohere automatically breaks down lengthy documents into manageable chunks for efficient processing. The API delivers relevance scores normalized between 0 and 1, facilitating result interpretation and threshold determination.
Jina
Jina's reranking API, exemplified by jina-colbert-v1-en, specializes in enhancing search results with semantic understanding with longer context lengths.
Mixedbread
Mixedbread offers a family of reranking models with an open-source Apache 2.0 license, empowering organizations to integrate semantic relevance into their existing search infrastructure seamlessly.
How to Select a Reranker
Several key factors need to be carefully considered when selecting a reranker to ensure optimal performance and compatibility with system requirements.
Relevance Improvement
The primary objective of adding a reranker is to enhance the relevance of search results. Evaluate the reranker's ability to improve the ranking in terms of retrieval metrics like NDCG or generation metrics like attribution.
Latency Considerations
Assess the additional latency introduced by the reranker to the search system. Measure the time required for reranking documents and ensure that it remains within acceptable limits for real-time or near-real-time search applications.
Contextual Understanding
Determine the reranker's ability to handle varying lengths of context in queries and documents. Some rerankers may be optimized for short text inputs, while others may be capable of processing longer sequences with rich contextual information.
Generalization Ability
Evaluate the reranker's ability to generalize across different domains and datasets. Ensure that the reranker performs well not only on training data but also on unseen or out-of-domain data to prevent overfitting and ensure robust performance in diverse search scenarios.
Latest Research on Comparison of Rerankers
How should you go about all these options? Recent research, highlighted in the paper A Thorough Comparison of Cross-Encoders and LLMs for Reranking SPLADE, sheds light on the effectiveness and efficiency of different reranking methods, especially when coupled with strong retrievers like SPLADEv3. Here are the key conclusions drawn from this research.
In-Domain vs. Out-of-Domain Performance
In the in-domain setting, differences between evaluated rerankers are not as pronounced. However, in out-of-domain scenarios, the gap between approaches widens, suggesting that the choice of reranker can significantly impact performance, especially across different domains.
Impact of Reranked Document Count
Increasing the number of documents to rerank has a positive impact on the final effectiveness of the reranking process. This highlights the importance of considering the trade-off between computational resources and performance gains when determining the optimal number of reranked documents.
Cross-Encoders vs. LLMs
Effective cross-encoders, when paired with strong retrievers, have shown the ability to outperform most LLMs in reranking tasks, except for GPT-4 on some datasets. Notably, cross-encoders offer this improved performance while being more efficient, making them an attractive option for reranking tasks.
Evaluation of LLM-based Rerankers
Zero-shot LLM-based rerankers, including those based on OpenAI and open models, exhibit competitive effectiveness, with some even matching the performance of GPT3.5 Turbo. However, the inefficiency and high cost associated with these models currently limit their practical use in retrieval systems, despite their promising performance.
Overall, the research highlights the significance of reranking methods in enhancing retrieval, with cross-encoders emerging as a particularly promising and efficient option. While LLM-based rerankers show competitive effectiveness, their practical deployment is hindered by inefficiency and high costs.
How to Evaluate Your Reranker
Let's continue with our last RAG example, where we built a Q&A system on Nvidia’s 10-k filings. At the time our goal was to evaluate embedding models. This time we want to see how we can evaluate a reranker.
We leverage the same data and introduce Cohere reranker in the RAG chain as shown below.
import os from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema.runnable import RunnablePassthrough from langchain.schema import StrOutputParser from langchain_community.vectorstores import Pinecone as langchain_pinecone from langchain.retrievers.contextual_compression import ContextualCompressionRetriever from langchain.retrievers.document_compressors import CohereRerank from pinecone import Pinecone def get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature): # setup retriever pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY")) index = pc.Index(index_name) vectorstore = langchain_pinecone(index, embeddings.embed_query, "text") compressor = CohereRerank(top_n=rerank_k) retriever = vectorstore.as_retriever(search_kwargs={"k": emb_k}) # https://github.com/langchain-ai/langchain/blob/master/libs/core/langchain_core/vectorstores.py#L553 # rerank retriever compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) # setup prompt rag_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the question based only on the provided context." ), ("human", "Context: '{context}' \n\n Question: '{question}'"), ] ) # setup llm llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature, tiktoken_model_name="cl100k_base") # helper function to format docs def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) # setup chain rag_chain = ( {"context": compression_retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser() ) return rag_chain
We modify our rag_chain_executor function to include emb_k and rerank_k which are the number of retrieved docs we want from OpenAI’s text-embedding-3-small retrieval and Cohere’s rerank-english-v2.0 reranker.
def rag_chain_executor(emb_model_name: str, dimensions: int, llm_model_name: str, emb_k: int, rerank_k: int) -> None: # initialise embedding model if "text-embedding-3" in emb_model_name: embeddings = OpenAIEmbeddings(model=emb_model_name, dimensions=dimensions) else: embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True}) index_name = f"{emb_model_name}-{dimensions}".lower() # First, check if our index already exists and delete stale index if index_name in [index_info['name'] for index_info in pc.list_indexes()]: pc.delete_index(index_name) # create a new index pc.create_index(name=index_name, metric="cosine", dimension=dimensions, spec=ServerlessSpec( cloud="aws", region="us-west-2" ) ) time.sleep(10) # index the documents _ = langchain_pinecone.from_documents(documents, embeddings, index_name=index_name) time.sleep(10) # load qa chain qa = get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature) # tags to be kept in galileo run run_name = f"{index_name}-emb-k-{emb_k}-rerank-k-{rerank_k}" index_name_tag = pq.RunTag(key="Index config", value=index_name, tag_type=pq.TagType.RAG) encoder_model_name_tag = pq.RunTag(key="Encoder", value=emb_model_name, tag_type=pq.TagType.RAG) llm_model_name_tag = pq.RunTag(key="LLM", value=llm_model_name, tag_type=pq.TagType.RAG) dimension_tag = pq.RunTag(key="Dimension", value=str(dimensions), tag_type=pq.TagType.RAG) emb_k_tag = pq.RunTag(key="Emb k", value=str(emb_k), tag_type=pq.TagType.RAG) rerank_k_tag = pq.RunTag(key="Rerank k", value=str(rerank_k), tag_type=pq.TagType.RAG) evaluate_handler = pq.GalileoPromptCallback(project_name=project_name, run_name=run_name, scorers=all_metrics, run_tags=[encoder_model_name_tag, llm_model_name_tag, index_name_tag, dimension_tag, emb_k_tag, rerank_k_tag]) # run chain with questions to generate the answers print("Ready to ask!") for i, q in enumerate(tqdm(questions)): print(f"Question {i}: ", q) print(qa.invoke(q, config=dict(callbacks=[evaluate_handler]))) print("\n\n") evaluate_handler.finish() pq.login("console.demo.rungalileo.io")
Now we can go ahead and run the same sweep with the required parameters.
pq.sweep( rag_chain_executor, { "emb_model_name": ["text-embedding-3-small"], "dimensions": [384], "llm_model_name": ["gpt-3.5-turbo-0125"], "emb_k": [10], "rerank_k": [3] }, )
The outcome isn't surprising! We get a 10% increase in attribution, indicating we now possess more relevant chunks necessary to address the question. Additionally, there's 5% improvement in Context Adherence, suggesting a reduction in hallucinations.
In most cases, we continue to seek further improvements rather than stopping at this point. Galileo Evaluate facilitates error analysis by examining individual runs and inspecting attributed chunks. The following illustrates the specific chunk attributed from the retrieved chunks in the vector DB.
When we click the rerank node, we can see the total attributed chunks from the reranker and each chunk’s attribution(yes/no).
This approach enables us to swiftly conduct experiments with various rerankers to determine the most effective one for our needs.
Conclusion
The importance of selecting the appropriate reranker cannot be overstated in optimizing RAG systems and ensuring dependable search outcomes by mitigating hallucinations. A nuanced understanding of various reranker types, including cross-encoders and multi-vector models, underscores their pivotal role in augmenting search precision.
However, as the RAG pipeline matures, debugging complexities can hinder system improvements. By leveraging comprehensive observability across the entire pipeline, AI teams can build production-ready systems.
Get started with Galileo today for free, or download our free comprehensive guide for building enterprise-grade RAG systems to take the next step in your journey.
Optimizing retrieval results in a RAG system requires various modules to work together in unison. A crucial component of this process is the reranker, a module that improves the order of documents within the retrieved set to prioritize the most relevant items. Let’s dive into the intricacies of selecting an optimal reranker for RAG systems, including the significance of rerankers, scenarios demanding their use, potential drawbacks, and the diverse types available.
What is a Reranker?
A reranker, functioning as the second-pass document filter in information retrieval(IR) systems, focuses on reordering documents retrieved by the initial retriever (semantic search, keyword search, etc.). This reordering is based on the query-document relevance, emphasizing the quality of document ranking. Balancing efficiency with effectiveness, rerankers prioritize the enhancement of search result quality, often involving more complex matching methods than traditional vector inner products.
Why We Need Rerankers
We know that hallucinations happen when unrelated retrieved docs are included in output context. This is exactly where rerankers can be helpful! They rearrange document records to prioritize the most relevant ones. This not only helps address hallucinations but also saves money during the RAG process. Let’s explore this need in more detail and why rerankers are necessary.
Limitations of Embeddings
Let's examine why embeddings fail to adequately address retrieval challenges. Their generalization issues present significant obstacles in real-world applications.
Limited Semantic Understanding
While embeddings capture semantic information, they often lack contrastive information. For example, embeddings may struggle to distinguish between "I love apples" and "I used to love apples" since both convey a similar semantic meaning.
Dimensionality Constraints
Embeddings represent documents or sentences in a relatively low-dimensional space, typically with a fixed number of dimensions (e.g., 1024). This limited space makes it challenging to encode all relevant information accurately, especially for longer documents or queries.
Generalization Issues
Embeddings must generalize well to unseen documents and queries, which is crucial for real-world search applications. However, due to their dimensionality constraints and training data limitations, embeddings-based models may struggle to generalize effectively beyond the training data.
How Rerankers Work
Rerankers fundamentally surpass the limitations of embeddings, rendering them valuable for retrieval applications.
Bag-of-Embeddings Approach
Early interaction models like cross encoders and late-interaction models like ColBERT adopt a bag-of-embeddings approach. Instead of representing documents as single vectors, they break documents into smaller, contextualized units of information.
Semantic Keyword Matching
Reranker models combine the power of strong encoder models, such as BERT, with keyword-based matching. This allows them to capture semantic meaning at a finer granularity while retaining the simplicity and efficiency of keyword matching.
Improved Generalization
They alleviate generalization issues faced by traditional embeddings by focusing on smaller contextualized units. They can better handle unseen documents and queries, leading to improved retrieval performance in real-world scenarios.
Types of Rerankers
Rerankers have been used for years, but the field is rapidly evolving. Let's examine current options and how they differ.
Model | Type | Performance | Cost | Example |
Cross encoder | Open source | Great | Medium | BGE, sentence, transformers, Mixedbread |
Multi-vector | Open source | Good | Low | ColBERT |
LLM | Open source | Great | High | RankZephyr, RankT5 |
LLM API | Private | Best | Very High | GPT, Claude |
Rerank API | Private | Great | Medium | Cohere, Mixedbread, Jina |
Cross-Encoders
Cross-encoder models redefine the conventional approach by employing a classification mechanism for pairs of data. The model takes a pair of data, such as two sentences, as input, and produces an output value between 0 and 1, indicating the similarity between the two items. This departure from vector embeddings allows for a more nuanced understanding of the relationships between data points.
It's important to note that cross-encoders require a pair of "items" for every input, making them unsuitable for handling individual sentences independently. In the context of search, a cross-encoder is employed with each data item and the search query to calculate the similarity between the query and the data object.
Here is a snippet of how to use state-of-the-art rerankers like BGE.
from FlagEmbedding import FlagReranker reranker = FlagReranker('BAAI/bge-reranker-base, use_fp16=True) score = reranker.compute_score(['query', 'passage']) print(score) scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
Multi-Vector Rerankers
Cross encoders perform very well, but what about alternative options that require less compute?
Multi-vector embedding models like ColBERT feature late interaction, where the interaction between query and document representations occurs late in the process, after both have been independently encoded. This approach contrasts with early interaction models like cross-encoder, where query and document embeddings interact at earlier stages, potentially leading to increased computational complexity. While in case of cosine similarity of embeddings for retrieval, there is no interaction!
The late interaction design allows for the pre-computation of document representations, contributing to faster retrieval times and reduced computational demands, making it suitable for processing large document collections.
ColBERT offers the best of both worlds, so let's see how it is implemented. Below is a code snippet of from Jina’s blog.
import torch def compute_relevance_scores(query_embeddings, document_embeddings, k): """Compute relevance scores for top-k documents given a query.""" scores = torch.matmul(query_embeddings.unsqueeze(0), document_embeddings.transpose(1, 2)) max_scores_per_query_term = scores.max(dim=2).values total_scores = max_scores_per_query_term.sum(dim=1) sorted_indices = total_scores.argsort(descending=True) return sorted_indices
How the score is calculated using late interaction:
Dot Product: It computes the dot product between the query embeddings and document embeddings. This operation is performed using torch.matmul(), which calculates the matrix multiplication between query_embeddings.unsqueeze(0) (unsqueeze is used to add a batch dimension) and document_embeddings.transpose(1, 2) (transposed to align dimensions for multiplication). The result is a tensor with shape [k, num_query_terms, max_doc_length], where each element represents the similarity score between a query term and a document term.
Max pooling: Max-pooling operation is applied across document terms (dimension 2) to find the maximum similarity score per query term. This is done using scores.max(dim=2).values. The resulting tensor has shape [k, num_query_terms], where each row represents the maximum similarity scores for each query term across all documents.
Total scoring: The maximum scores per query term are summed up to get the total score for each document. This is done using .sum(dim=1), resulting in a tensor with shape [k] containing the total relevance score for each document.
Sorting: The documents are sorted based on their total scores in descending order using .argsort(descending=True).
Here is a code snippet using Jina-ColBERT - a ColBERT-style model but based on JinaBERT so it can support 8k context with better retrieval. The extra context length can help reduce the reliance on chunking techniques.
from colbert.modeling.checkpoint import Checkpoint from colbert.infra import ColBERTConfig query = ["How to use ColBERT for indexing long documents?"] documents = [ "ColBERT is an efficient and effective passage retrieval model.", "Jina-ColBERT is a ColBERT-style model but based on JinaBERT so it can support both 8k context length.", "JinaBERT is a BERT architecture that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.", "Jina-ColBERT model is trained on MSMARCO passage ranking dataset, following a very similar training procedure with ColBERTv2.", ] config = ColBERTConfig(query_maxlen=32, doc_maxlen=512) ckpt = Checkpoint(args.reranker, colbert_config=colbert_config) Q_emb = ckpt.queryFromText([all_queries[i]]) D_emb = ckpt.docFromText(all_passages, bsize=32)[0] D_mask = torch.ones(D.shape[:2], dtype=torch.long) scores = colbert_score(Q_emb, D_emb, D_mask).flatten().cpu().numpy().tolist() ranking = numpy.argsort(scores)[::-1]
Below is the comparison between Jina-ColBERT-v1-en and state-of-the-art late interaction model ColBERT-v2. Both show nearly similar zero-shot performance on 13 public BEIR datasets, rendering it a worthy candidate for reranking.
LLMs for Reranking
As LLMs grow in size, surpassing 10 billion parameters, fine-tuning the reranking model becomes progressively more challenging. Recent endeavors have aimed to tackle this issue by prompting LLMs to improve document reranking autonomously. Broadly, these prompting strategies fall into three categories: pointwise, listwise, and pairwise methods.
Pointwise Methods
Pointwise methods measure relevance between a query and a single document. Subcategories include relevance generation and query generation, both effective in zero-shot document reranking.
Listwise Methods
Listwise methods directly rank a list of documents by inserting the query and a document list into the prompt and instructing the LLMs to output the reranked document identifiers. Due to the limited input length of LLMs, inserting all candidate documents into the prompt is not feasible. To address this issue, these methods employ a sliding window strategy to rerank a subset of candidate documents each time. This involves ranking from back to front using a sliding window and re-ranking only the documents within the window at a time.
Pairwise Methods
In pairwise methods, LLMs receive a prompt containing a query and a document pair. They are then directed to generate the identifier of the document deemed more relevant. Aggregation methods like AllPairs are employed to rerank all candidate documents. AllPairs initially generates all potential document pairs and consolidates a final relevance score for each document. Efficient sorting algorithms like heap sort and bubble sort are typically utilized to expedite the ranking process.
This can be accomplished with the help of GPT-3.5, GPT4 and GPT4-Turbo, where the last one offers the best tradeoff between cost and performance.
Supervised LLMs Rerankers
Supervised fine-tuning is a critical step when applying pre-trained LLMs to reranking tasks. Due to the lack of ranking awareness during pre-training, LLMs cannot accurately measure query-document relevance. Fine-tuning on task-specific ranking datasets, such as MS MARCO passage ranking dataset, allow LLMs to adjust parameters for improved reranking performance. Supervised rerankers can be categorized based on the backbone model structure into two types.
Encoder-Decoder
Studies in this category mainly formulate document ranking as a generation task, optimizing an encoder-decoder-based reranking model. For example, the RankT5 model is fine-tuned to generate classification tokens for relevant or irrelevant query-document pairs.
Decoder-only
Recent attempts involve reranking documents by fine-tuning decoder-only models, such as LLaMA. Different approaches, including RankZephyr and RankGPT, propose various methods for relevance calculation.
Private Reranking APIs
Hosting and improving rerankers is often challenging. Private reranking APIs offer a convenient solution for organizations seeking to enhance their search systems with semantic relevance without making an infrastructure investment. Below, we look into three notable private reranking APIs: Cohere, Jina, and Mixedbread.
Cohere
Cohere's rerank API offers rerank models tailored for English and multilingual documents, each optimized for specific language processing tasks. Cohere automatically breaks down lengthy documents into manageable chunks for efficient processing. The API delivers relevance scores normalized between 0 and 1, facilitating result interpretation and threshold determination.
Jina
Jina's reranking API, exemplified by jina-colbert-v1-en, specializes in enhancing search results with semantic understanding with longer context lengths.
Mixedbread
Mixedbread offers a family of reranking models with an open-source Apache 2.0 license, empowering organizations to integrate semantic relevance into their existing search infrastructure seamlessly.
How to Select a Reranker
Several key factors need to be carefully considered when selecting a reranker to ensure optimal performance and compatibility with system requirements.
Relevance Improvement
The primary objective of adding a reranker is to enhance the relevance of search results. Evaluate the reranker's ability to improve the ranking in terms of retrieval metrics like NDCG or generation metrics like attribution.
Latency Considerations
Assess the additional latency introduced by the reranker to the search system. Measure the time required for reranking documents and ensure that it remains within acceptable limits for real-time or near-real-time search applications.
Contextual Understanding
Determine the reranker's ability to handle varying lengths of context in queries and documents. Some rerankers may be optimized for short text inputs, while others may be capable of processing longer sequences with rich contextual information.
Generalization Ability
Evaluate the reranker's ability to generalize across different domains and datasets. Ensure that the reranker performs well not only on training data but also on unseen or out-of-domain data to prevent overfitting and ensure robust performance in diverse search scenarios.
Latest Research on Comparison of Rerankers
How should you go about all these options? Recent research, highlighted in the paper A Thorough Comparison of Cross-Encoders and LLMs for Reranking SPLADE, sheds light on the effectiveness and efficiency of different reranking methods, especially when coupled with strong retrievers like SPLADEv3. Here are the key conclusions drawn from this research.
In-Domain vs. Out-of-Domain Performance
In the in-domain setting, differences between evaluated rerankers are not as pronounced. However, in out-of-domain scenarios, the gap between approaches widens, suggesting that the choice of reranker can significantly impact performance, especially across different domains.
Impact of Reranked Document Count
Increasing the number of documents to rerank has a positive impact on the final effectiveness of the reranking process. This highlights the importance of considering the trade-off between computational resources and performance gains when determining the optimal number of reranked documents.
Cross-Encoders vs. LLMs
Effective cross-encoders, when paired with strong retrievers, have shown the ability to outperform most LLMs in reranking tasks, except for GPT-4 on some datasets. Notably, cross-encoders offer this improved performance while being more efficient, making them an attractive option for reranking tasks.
Evaluation of LLM-based Rerankers
Zero-shot LLM-based rerankers, including those based on OpenAI and open models, exhibit competitive effectiveness, with some even matching the performance of GPT3.5 Turbo. However, the inefficiency and high cost associated with these models currently limit their practical use in retrieval systems, despite their promising performance.
Overall, the research highlights the significance of reranking methods in enhancing retrieval, with cross-encoders emerging as a particularly promising and efficient option. While LLM-based rerankers show competitive effectiveness, their practical deployment is hindered by inefficiency and high costs.
How to Evaluate Your Reranker
Let's continue with our last RAG example, where we built a Q&A system on Nvidia’s 10-k filings. At the time our goal was to evaluate embedding models. This time we want to see how we can evaluate a reranker.
We leverage the same data and introduce Cohere reranker in the RAG chain as shown below.
import os from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema.runnable import RunnablePassthrough from langchain.schema import StrOutputParser from langchain_community.vectorstores import Pinecone as langchain_pinecone from langchain.retrievers.contextual_compression import ContextualCompressionRetriever from langchain.retrievers.document_compressors import CohereRerank from pinecone import Pinecone def get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature): # setup retriever pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY")) index = pc.Index(index_name) vectorstore = langchain_pinecone(index, embeddings.embed_query, "text") compressor = CohereRerank(top_n=rerank_k) retriever = vectorstore.as_retriever(search_kwargs={"k": emb_k}) # https://github.com/langchain-ai/langchain/blob/master/libs/core/langchain_core/vectorstores.py#L553 # rerank retriever compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) # setup prompt rag_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the question based only on the provided context." ), ("human", "Context: '{context}' \n\n Question: '{question}'"), ] ) # setup llm llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature, tiktoken_model_name="cl100k_base") # helper function to format docs def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) # setup chain rag_chain = ( {"context": compression_retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser() ) return rag_chain
We modify our rag_chain_executor function to include emb_k and rerank_k which are the number of retrieved docs we want from OpenAI’s text-embedding-3-small retrieval and Cohere’s rerank-english-v2.0 reranker.
def rag_chain_executor(emb_model_name: str, dimensions: int, llm_model_name: str, emb_k: int, rerank_k: int) -> None: # initialise embedding model if "text-embedding-3" in emb_model_name: embeddings = OpenAIEmbeddings(model=emb_model_name, dimensions=dimensions) else: embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True}) index_name = f"{emb_model_name}-{dimensions}".lower() # First, check if our index already exists and delete stale index if index_name in [index_info['name'] for index_info in pc.list_indexes()]: pc.delete_index(index_name) # create a new index pc.create_index(name=index_name, metric="cosine", dimension=dimensions, spec=ServerlessSpec( cloud="aws", region="us-west-2" ) ) time.sleep(10) # index the documents _ = langchain_pinecone.from_documents(documents, embeddings, index_name=index_name) time.sleep(10) # load qa chain qa = get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature) # tags to be kept in galileo run run_name = f"{index_name}-emb-k-{emb_k}-rerank-k-{rerank_k}" index_name_tag = pq.RunTag(key="Index config", value=index_name, tag_type=pq.TagType.RAG) encoder_model_name_tag = pq.RunTag(key="Encoder", value=emb_model_name, tag_type=pq.TagType.RAG) llm_model_name_tag = pq.RunTag(key="LLM", value=llm_model_name, tag_type=pq.TagType.RAG) dimension_tag = pq.RunTag(key="Dimension", value=str(dimensions), tag_type=pq.TagType.RAG) emb_k_tag = pq.RunTag(key="Emb k", value=str(emb_k), tag_type=pq.TagType.RAG) rerank_k_tag = pq.RunTag(key="Rerank k", value=str(rerank_k), tag_type=pq.TagType.RAG) evaluate_handler = pq.GalileoPromptCallback(project_name=project_name, run_name=run_name, scorers=all_metrics, run_tags=[encoder_model_name_tag, llm_model_name_tag, index_name_tag, dimension_tag, emb_k_tag, rerank_k_tag]) # run chain with questions to generate the answers print("Ready to ask!") for i, q in enumerate(tqdm(questions)): print(f"Question {i}: ", q) print(qa.invoke(q, config=dict(callbacks=[evaluate_handler]))) print("\n\n") evaluate_handler.finish() pq.login("console.demo.rungalileo.io")
Now we can go ahead and run the same sweep with the required parameters.
pq.sweep( rag_chain_executor, { "emb_model_name": ["text-embedding-3-small"], "dimensions": [384], "llm_model_name": ["gpt-3.5-turbo-0125"], "emb_k": [10], "rerank_k": [3] }, )
The outcome isn't surprising! We get a 10% increase in attribution, indicating we now possess more relevant chunks necessary to address the question. Additionally, there's 5% improvement in Context Adherence, suggesting a reduction in hallucinations.
In most cases, we continue to seek further improvements rather than stopping at this point. Galileo Evaluate facilitates error analysis by examining individual runs and inspecting attributed chunks. The following illustrates the specific chunk attributed from the retrieved chunks in the vector DB.
When we click the rerank node, we can see the total attributed chunks from the reranker and each chunk’s attribution(yes/no).
This approach enables us to swiftly conduct experiments with various rerankers to determine the most effective one for our needs.
Conclusion
The importance of selecting the appropriate reranker cannot be overstated in optimizing RAG systems and ensuring dependable search outcomes by mitigating hallucinations. A nuanced understanding of various reranker types, including cross-encoders and multi-vector models, underscores their pivotal role in augmenting search precision.
However, as the RAG pipeline matures, debugging complexities can hinder system improvements. By leveraging comprehensive observability across the entire pipeline, AI teams can build production-ready systems.
Get started with Galileo today for free, or download our free comprehensive guide for building enterprise-grade RAG systems to take the next step in your journey.
Optimizing retrieval results in a RAG system requires various modules to work together in unison. A crucial component of this process is the reranker, a module that improves the order of documents within the retrieved set to prioritize the most relevant items. Let’s dive into the intricacies of selecting an optimal reranker for RAG systems, including the significance of rerankers, scenarios demanding their use, potential drawbacks, and the diverse types available.
What is a Reranker?
A reranker, functioning as the second-pass document filter in information retrieval(IR) systems, focuses on reordering documents retrieved by the initial retriever (semantic search, keyword search, etc.). This reordering is based on the query-document relevance, emphasizing the quality of document ranking. Balancing efficiency with effectiveness, rerankers prioritize the enhancement of search result quality, often involving more complex matching methods than traditional vector inner products.
Why We Need Rerankers
We know that hallucinations happen when unrelated retrieved docs are included in output context. This is exactly where rerankers can be helpful! They rearrange document records to prioritize the most relevant ones. This not only helps address hallucinations but also saves money during the RAG process. Let’s explore this need in more detail and why rerankers are necessary.
Limitations of Embeddings
Let's examine why embeddings fail to adequately address retrieval challenges. Their generalization issues present significant obstacles in real-world applications.
Limited Semantic Understanding
While embeddings capture semantic information, they often lack contrastive information. For example, embeddings may struggle to distinguish between "I love apples" and "I used to love apples" since both convey a similar semantic meaning.
Dimensionality Constraints
Embeddings represent documents or sentences in a relatively low-dimensional space, typically with a fixed number of dimensions (e.g., 1024). This limited space makes it challenging to encode all relevant information accurately, especially for longer documents or queries.
Generalization Issues
Embeddings must generalize well to unseen documents and queries, which is crucial for real-world search applications. However, due to their dimensionality constraints and training data limitations, embeddings-based models may struggle to generalize effectively beyond the training data.
How Rerankers Work
Rerankers fundamentally surpass the limitations of embeddings, rendering them valuable for retrieval applications.
Bag-of-Embeddings Approach
Early interaction models like cross encoders and late-interaction models like ColBERT adopt a bag-of-embeddings approach. Instead of representing documents as single vectors, they break documents into smaller, contextualized units of information.
Semantic Keyword Matching
Reranker models combine the power of strong encoder models, such as BERT, with keyword-based matching. This allows them to capture semantic meaning at a finer granularity while retaining the simplicity and efficiency of keyword matching.
Improved Generalization
They alleviate generalization issues faced by traditional embeddings by focusing on smaller contextualized units. They can better handle unseen documents and queries, leading to improved retrieval performance in real-world scenarios.
Types of Rerankers
Rerankers have been used for years, but the field is rapidly evolving. Let's examine current options and how they differ.
Model | Type | Performance | Cost | Example |
Cross encoder | Open source | Great | Medium | BGE, sentence, transformers, Mixedbread |
Multi-vector | Open source | Good | Low | ColBERT |
LLM | Open source | Great | High | RankZephyr, RankT5 |
LLM API | Private | Best | Very High | GPT, Claude |
Rerank API | Private | Great | Medium | Cohere, Mixedbread, Jina |
Cross-Encoders
Cross-encoder models redefine the conventional approach by employing a classification mechanism for pairs of data. The model takes a pair of data, such as two sentences, as input, and produces an output value between 0 and 1, indicating the similarity between the two items. This departure from vector embeddings allows for a more nuanced understanding of the relationships between data points.
It's important to note that cross-encoders require a pair of "items" for every input, making them unsuitable for handling individual sentences independently. In the context of search, a cross-encoder is employed with each data item and the search query to calculate the similarity between the query and the data object.
Here is a snippet of how to use state-of-the-art rerankers like BGE.
from FlagEmbedding import FlagReranker reranker = FlagReranker('BAAI/bge-reranker-base, use_fp16=True) score = reranker.compute_score(['query', 'passage']) print(score) scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
Multi-Vector Rerankers
Cross encoders perform very well, but what about alternative options that require less compute?
Multi-vector embedding models like ColBERT feature late interaction, where the interaction between query and document representations occurs late in the process, after both have been independently encoded. This approach contrasts with early interaction models like cross-encoder, where query and document embeddings interact at earlier stages, potentially leading to increased computational complexity. While in case of cosine similarity of embeddings for retrieval, there is no interaction!
The late interaction design allows for the pre-computation of document representations, contributing to faster retrieval times and reduced computational demands, making it suitable for processing large document collections.
ColBERT offers the best of both worlds, so let's see how it is implemented. Below is a code snippet of from Jina’s blog.
import torch def compute_relevance_scores(query_embeddings, document_embeddings, k): """Compute relevance scores for top-k documents given a query.""" scores = torch.matmul(query_embeddings.unsqueeze(0), document_embeddings.transpose(1, 2)) max_scores_per_query_term = scores.max(dim=2).values total_scores = max_scores_per_query_term.sum(dim=1) sorted_indices = total_scores.argsort(descending=True) return sorted_indices
How the score is calculated using late interaction:
Dot Product: It computes the dot product between the query embeddings and document embeddings. This operation is performed using torch.matmul(), which calculates the matrix multiplication between query_embeddings.unsqueeze(0) (unsqueeze is used to add a batch dimension) and document_embeddings.transpose(1, 2) (transposed to align dimensions for multiplication). The result is a tensor with shape [k, num_query_terms, max_doc_length], where each element represents the similarity score between a query term and a document term.
Max pooling: Max-pooling operation is applied across document terms (dimension 2) to find the maximum similarity score per query term. This is done using scores.max(dim=2).values. The resulting tensor has shape [k, num_query_terms], where each row represents the maximum similarity scores for each query term across all documents.
Total scoring: The maximum scores per query term are summed up to get the total score for each document. This is done using .sum(dim=1), resulting in a tensor with shape [k] containing the total relevance score for each document.
Sorting: The documents are sorted based on their total scores in descending order using .argsort(descending=True).
Here is a code snippet using Jina-ColBERT - a ColBERT-style model but based on JinaBERT so it can support 8k context with better retrieval. The extra context length can help reduce the reliance on chunking techniques.
from colbert.modeling.checkpoint import Checkpoint from colbert.infra import ColBERTConfig query = ["How to use ColBERT for indexing long documents?"] documents = [ "ColBERT is an efficient and effective passage retrieval model.", "Jina-ColBERT is a ColBERT-style model but based on JinaBERT so it can support both 8k context length.", "JinaBERT is a BERT architecture that supports the symmetric bidirectional variant of ALiBi to allow longer sequence length.", "Jina-ColBERT model is trained on MSMARCO passage ranking dataset, following a very similar training procedure with ColBERTv2.", ] config = ColBERTConfig(query_maxlen=32, doc_maxlen=512) ckpt = Checkpoint(args.reranker, colbert_config=colbert_config) Q_emb = ckpt.queryFromText([all_queries[i]]) D_emb = ckpt.docFromText(all_passages, bsize=32)[0] D_mask = torch.ones(D.shape[:2], dtype=torch.long) scores = colbert_score(Q_emb, D_emb, D_mask).flatten().cpu().numpy().tolist() ranking = numpy.argsort(scores)[::-1]
Below is the comparison between Jina-ColBERT-v1-en and state-of-the-art late interaction model ColBERT-v2. Both show nearly similar zero-shot performance on 13 public BEIR datasets, rendering it a worthy candidate for reranking.
LLMs for Reranking
As LLMs grow in size, surpassing 10 billion parameters, fine-tuning the reranking model becomes progressively more challenging. Recent endeavors have aimed to tackle this issue by prompting LLMs to improve document reranking autonomously. Broadly, these prompting strategies fall into three categories: pointwise, listwise, and pairwise methods.
Pointwise Methods
Pointwise methods measure relevance between a query and a single document. Subcategories include relevance generation and query generation, both effective in zero-shot document reranking.
Listwise Methods
Listwise methods directly rank a list of documents by inserting the query and a document list into the prompt and instructing the LLMs to output the reranked document identifiers. Due to the limited input length of LLMs, inserting all candidate documents into the prompt is not feasible. To address this issue, these methods employ a sliding window strategy to rerank a subset of candidate documents each time. This involves ranking from back to front using a sliding window and re-ranking only the documents within the window at a time.
Pairwise Methods
In pairwise methods, LLMs receive a prompt containing a query and a document pair. They are then directed to generate the identifier of the document deemed more relevant. Aggregation methods like AllPairs are employed to rerank all candidate documents. AllPairs initially generates all potential document pairs and consolidates a final relevance score for each document. Efficient sorting algorithms like heap sort and bubble sort are typically utilized to expedite the ranking process.
This can be accomplished with the help of GPT-3.5, GPT4 and GPT4-Turbo, where the last one offers the best tradeoff between cost and performance.
Supervised LLMs Rerankers
Supervised fine-tuning is a critical step when applying pre-trained LLMs to reranking tasks. Due to the lack of ranking awareness during pre-training, LLMs cannot accurately measure query-document relevance. Fine-tuning on task-specific ranking datasets, such as MS MARCO passage ranking dataset, allow LLMs to adjust parameters for improved reranking performance. Supervised rerankers can be categorized based on the backbone model structure into two types.
Encoder-Decoder
Studies in this category mainly formulate document ranking as a generation task, optimizing an encoder-decoder-based reranking model. For example, the RankT5 model is fine-tuned to generate classification tokens for relevant or irrelevant query-document pairs.
Decoder-only
Recent attempts involve reranking documents by fine-tuning decoder-only models, such as LLaMA. Different approaches, including RankZephyr and RankGPT, propose various methods for relevance calculation.
Private Reranking APIs
Hosting and improving rerankers is often challenging. Private reranking APIs offer a convenient solution for organizations seeking to enhance their search systems with semantic relevance without making an infrastructure investment. Below, we look into three notable private reranking APIs: Cohere, Jina, and Mixedbread.
Cohere
Cohere's rerank API offers rerank models tailored for English and multilingual documents, each optimized for specific language processing tasks. Cohere automatically breaks down lengthy documents into manageable chunks for efficient processing. The API delivers relevance scores normalized between 0 and 1, facilitating result interpretation and threshold determination.
Jina
Jina's reranking API, exemplified by jina-colbert-v1-en, specializes in enhancing search results with semantic understanding with longer context lengths.
Mixedbread
Mixedbread offers a family of reranking models with an open-source Apache 2.0 license, empowering organizations to integrate semantic relevance into their existing search infrastructure seamlessly.
How to Select a Reranker
Several key factors need to be carefully considered when selecting a reranker to ensure optimal performance and compatibility with system requirements.
Relevance Improvement
The primary objective of adding a reranker is to enhance the relevance of search results. Evaluate the reranker's ability to improve the ranking in terms of retrieval metrics like NDCG or generation metrics like attribution.
Latency Considerations
Assess the additional latency introduced by the reranker to the search system. Measure the time required for reranking documents and ensure that it remains within acceptable limits for real-time or near-real-time search applications.
Contextual Understanding
Determine the reranker's ability to handle varying lengths of context in queries and documents. Some rerankers may be optimized for short text inputs, while others may be capable of processing longer sequences with rich contextual information.
Generalization Ability
Evaluate the reranker's ability to generalize across different domains and datasets. Ensure that the reranker performs well not only on training data but also on unseen or out-of-domain data to prevent overfitting and ensure robust performance in diverse search scenarios.
Latest Research on Comparison of Rerankers
How should you go about all these options? Recent research, highlighted in the paper A Thorough Comparison of Cross-Encoders and LLMs for Reranking SPLADE, sheds light on the effectiveness and efficiency of different reranking methods, especially when coupled with strong retrievers like SPLADEv3. Here are the key conclusions drawn from this research.
In-Domain vs. Out-of-Domain Performance
In the in-domain setting, differences between evaluated rerankers are not as pronounced. However, in out-of-domain scenarios, the gap between approaches widens, suggesting that the choice of reranker can significantly impact performance, especially across different domains.
Impact of Reranked Document Count
Increasing the number of documents to rerank has a positive impact on the final effectiveness of the reranking process. This highlights the importance of considering the trade-off between computational resources and performance gains when determining the optimal number of reranked documents.
Cross-Encoders vs. LLMs
Effective cross-encoders, when paired with strong retrievers, have shown the ability to outperform most LLMs in reranking tasks, except for GPT-4 on some datasets. Notably, cross-encoders offer this improved performance while being more efficient, making them an attractive option for reranking tasks.
Evaluation of LLM-based Rerankers
Zero-shot LLM-based rerankers, including those based on OpenAI and open models, exhibit competitive effectiveness, with some even matching the performance of GPT3.5 Turbo. However, the inefficiency and high cost associated with these models currently limit their practical use in retrieval systems, despite their promising performance.
Overall, the research highlights the significance of reranking methods in enhancing retrieval, with cross-encoders emerging as a particularly promising and efficient option. While LLM-based rerankers show competitive effectiveness, their practical deployment is hindered by inefficiency and high costs.
How to Evaluate Your Reranker
Let's continue with our last RAG example, where we built a Q&A system on Nvidia’s 10-k filings. At the time our goal was to evaluate embedding models. This time we want to see how we can evaluate a reranker.
We leverage the same data and introduce Cohere reranker in the RAG chain as shown below.
import os from langchain_openai import ChatOpenAI from langchain.prompts import ChatPromptTemplate from langchain.schema.runnable import RunnablePassthrough from langchain.schema import StrOutputParser from langchain_community.vectorstores import Pinecone as langchain_pinecone from langchain.retrievers.contextual_compression import ContextualCompressionRetriever from langchain.retrievers.document_compressors import CohereRerank from pinecone import Pinecone def get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature): # setup retriever pc = Pinecone(api_key=os.getenv("PINECONE_API_KEY")) index = pc.Index(index_name) vectorstore = langchain_pinecone(index, embeddings.embed_query, "text") compressor = CohereRerank(top_n=rerank_k) retriever = vectorstore.as_retriever(search_kwargs={"k": emb_k}) # https://github.com/langchain-ai/langchain/blob/master/libs/core/langchain_core/vectorstores.py#L553 # rerank retriever compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=retriever ) # setup prompt rag_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Answer the question based only on the provided context." ), ("human", "Context: '{context}' \n\n Question: '{question}'"), ] ) # setup llm llm = ChatOpenAI(model_name=llm_model_name, temperature=temperature, tiktoken_model_name="cl100k_base") # helper function to format docs def format_docs(docs): return "\n\n".join([d.page_content for d in docs]) # setup chain rag_chain = ( {"context": compression_retriever | format_docs, "question": RunnablePassthrough()} | rag_prompt | llm | StrOutputParser() ) return rag_chain
We modify our rag_chain_executor function to include emb_k and rerank_k which are the number of retrieved docs we want from OpenAI’s text-embedding-3-small retrieval and Cohere’s rerank-english-v2.0 reranker.
def rag_chain_executor(emb_model_name: str, dimensions: int, llm_model_name: str, emb_k: int, rerank_k: int) -> None: # initialise embedding model if "text-embedding-3" in emb_model_name: embeddings = OpenAIEmbeddings(model=emb_model_name, dimensions=dimensions) else: embeddings = HuggingFaceEmbeddings(model_name=emb_model_name, encode_kwargs = {'normalize_embeddings': True}) index_name = f"{emb_model_name}-{dimensions}".lower() # First, check if our index already exists and delete stale index if index_name in [index_info['name'] for index_info in pc.list_indexes()]: pc.delete_index(index_name) # create a new index pc.create_index(name=index_name, metric="cosine", dimension=dimensions, spec=ServerlessSpec( cloud="aws", region="us-west-2" ) ) time.sleep(10) # index the documents _ = langchain_pinecone.from_documents(documents, embeddings, index_name=index_name) time.sleep(10) # load qa chain qa = get_qa_chain(embeddings, index_name, emb_k, rerank_k, llm_model_name, temperature) # tags to be kept in galileo run run_name = f"{index_name}-emb-k-{emb_k}-rerank-k-{rerank_k}" index_name_tag = pq.RunTag(key="Index config", value=index_name, tag_type=pq.TagType.RAG) encoder_model_name_tag = pq.RunTag(key="Encoder", value=emb_model_name, tag_type=pq.TagType.RAG) llm_model_name_tag = pq.RunTag(key="LLM", value=llm_model_name, tag_type=pq.TagType.RAG) dimension_tag = pq.RunTag(key="Dimension", value=str(dimensions), tag_type=pq.TagType.RAG) emb_k_tag = pq.RunTag(key="Emb k", value=str(emb_k), tag_type=pq.TagType.RAG) rerank_k_tag = pq.RunTag(key="Rerank k", value=str(rerank_k), tag_type=pq.TagType.RAG) evaluate_handler = pq.GalileoPromptCallback(project_name=project_name, run_name=run_name, scorers=all_metrics, run_tags=[encoder_model_name_tag, llm_model_name_tag, index_name_tag, dimension_tag, emb_k_tag, rerank_k_tag]) # run chain with questions to generate the answers print("Ready to ask!") for i, q in enumerate(tqdm(questions)): print(f"Question {i}: ", q) print(qa.invoke(q, config=dict(callbacks=[evaluate_handler]))) print("\n\n") evaluate_handler.finish() pq.login("console.demo.rungalileo.io")
Now we can go ahead and run the same sweep with the required parameters.
pq.sweep( rag_chain_executor, { "emb_model_name": ["text-embedding-3-small"], "dimensions": [384], "llm_model_name": ["gpt-3.5-turbo-0125"], "emb_k": [10], "rerank_k": [3] }, )
The outcome isn't surprising! We get a 10% increase in attribution, indicating we now possess more relevant chunks necessary to address the question. Additionally, there's 5% improvement in Context Adherence, suggesting a reduction in hallucinations.
In most cases, we continue to seek further improvements rather than stopping at this point. Galileo Evaluate facilitates error analysis by examining individual runs and inspecting attributed chunks. The following illustrates the specific chunk attributed from the retrieved chunks in the vector DB.
When we click the rerank node, we can see the total attributed chunks from the reranker and each chunk’s attribution(yes/no).
This approach enables us to swiftly conduct experiments with various rerankers to determine the most effective one for our needs.
Conclusion
The importance of selecting the appropriate reranker cannot be overstated in optimizing RAG systems and ensuring dependable search outcomes by mitigating hallucinations. A nuanced understanding of various reranker types, including cross-encoders and multi-vector models, underscores their pivotal role in augmenting search precision.
However, as the RAG pipeline matures, debugging complexities can hinder system improvements. By leveraging comprehensive observability across the entire pipeline, AI teams can build production-ready systems.
Get started with Galileo today for free, or download our free comprehensive guide for building enterprise-grade RAG systems to take the next step in your journey.

Pratik Bhavsar