Why Do Multi-Agent Systems Fail Even When Agents Work Perfectly in Isolation?

On one side of the internet, you see demos of autonomous software engineers like Devin performing complex, multi-step tasks that appear to be magic. On the other hand, research from top labs such as Anthropic suggests that simply adding agents to a workflow often degrades performance rather than improving it.
Who is right? Surprisingly, both.
The disconnect stems from a fundamental misunderstanding of what multi-agent systems actually are. They are distributed systems composed of non-deterministic nodes. While specialization (having a "coder" agent and a "reviewer" agent) theoretically improves quality, it introduces a new, invisible tax: coordination cost.
As you scale from one agent to two, the communication overhead is manageable. But as you scale to four, ten, or a swarm, the complexity of maintaining context and consensus scales exponentially.
In this guide, we move beyond the hype cycle to examine the hard engineering reality. We will explore 7 specific ways multi-agent systems fail in production, from context loss to infinite loops, and, conversely, the architectural conditions under which they outperform single-model systems.
Finally, we will provide a decision framework to help you determine if the coordination tax is worth the intelligence gain.
TL;DR:
Multi-agent systems fail because coordination costs scale exponentially: 4 agents create 6 potential failure points, 10 agents create 45
The 7 most common production failures all share one root cause: insufficient architecture before deployment
Multi-agent systems only deliver when tasks are embarrassingly parallel, read-heavy over write-heavy, and orchestration is deterministic rather than emergent
Before building, five questions determine if you actually need multi-agent: most teams discover that better prompt engineering would have solved the problem cheaper and faster
Model improvements are collapsing the use cases for complex orchestration — GPT-3.5 architectures became obsolete with GPT-4, and today's multi-agent systems risk the same fate next quarter
The Core Problem: How Coordination Costs Scale Exponentially in Multi-Agent Systems
Memory in multi-agent systems is the entire nervous system of your application. Both Anthropic and Cognition found that agents catastrophically fail without sophisticated memory management.
Consider a real web development workflow.
You ask your multi-agent system to build a React dashboard:
Agent 1 analyzes requirements and decides on the component structure
Agent 2 implements the authentication flow
Agent 3 builds a data visualization
Agent 4 handles API integration
Each agent needs selective knowledge from the others. Agent 2 needs the component structure but not the full requirements analysis. Agent 4 needs auth tokens but not implementation details. This creates cascading memory challenges that single agents never face.
Short-Term Memory Fragments Across Agents
Each maintains its own working memory, creating information silos. When Agent 3 needs context from Agent 1's decisions, it either gets too much information (increasing costs) or too little (breaking functionality).
This creates a 'Goldilocks' dilemma that is computationally expensive to solve. If you pass the full context from Agent 1 to Agent 3, you dilute the instruction density, increasing the likelihood that the model ignores the specific constraint it needs to follow due to the 'lost in the middle' phenomenon.
Conversely, if you summarize the context to save tokens, you risk 'lossy compression,' where critical edge-case details (such as a specific error-handling requirement defined by Agent 1) are smoothed out and lost. The agent proceeds with confidence, but builds the wrong thing.
Operational Costs Explode From Coordination Overhead
A task that costs $0.10 in API calls for a single agent might cost $1.50 for a multi-agent system. The additional cost isn't from running more agents. It's from the exponential growth in context sharing. Every handoff requires context reconstruction, and every validation needs cross-agent verification.
The coordination overhead scales exponentially:
2 agents = 1 potential interaction
4 agents = 6 potential interactions
10 agents = 45 potential interactions
Each interaction introduces opportunities for context loss, misalignment, or conflicting decisions. As a result, you end up with an authentication system that expects different data structures than your database provides.
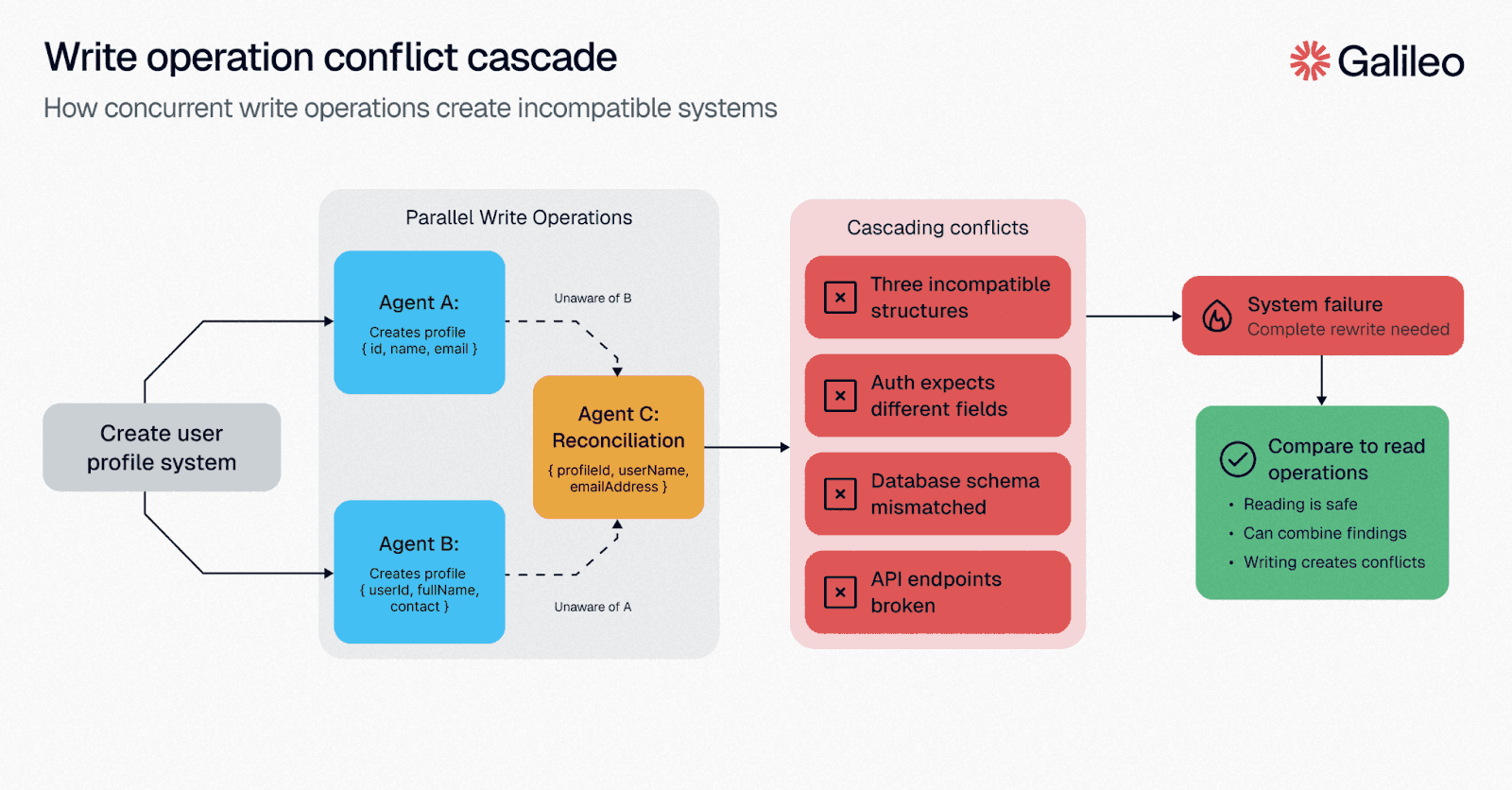
Write Operations Amplify the Problem
When agents read data independently and combine findings, conflicts are manageable. When they write code or modify state, conflicts cascade. Agent A creates a user profile structure. Agent B, unaware, creates a different structure. Agent C tries to reconcile both and creates a third.
Your system now has three incompatible representations of the same concept.
In a single-agent loop, the agent has a unified worldview. It knows it just changed the user schema, so it updates the validation logic immediately. In a multi-agent system, Agent B is operating on a stale snapshot of reality. It builds validation logic for a schema that no longer exists.
By the time the system detects the discrepancy, both agents have wasted compute resources on mutually exclusive paths, requiring a costly rollback or a third 'merger' agent to untangle the mess. Unlike read-only operations, where consensus is easy, write operations require strict serialization, negating the very parallelization benefits you built the system for.
7 Ways Multi-Agent Systems Fail in Production
These failures follow predictable patterns you can identify and fix. Let's explore the most common failures, show you how to spot them in your logs, and provide solutions that transform chaotic agent interactions into reliable workflows.

1. Agent Coordination Breakdowns
When your agents drift out of sync, your entire workflow wobbles. Inter-agent misalignment accounts for a large share of observed breakdowns, making it the most common failure mode in production systems.
This happens when otherwise capable models talk past each other, duplicate effort, or forget their responsibilities.
You'll recognize the symptoms immediately: a "planner" suddenly writes code instead of outlining it, peer suggestions vanish into the void between turns, or two agents quietly withhold relevant context while pursuing divergent plans.
These mistakes compound quickly when your system lacks mechanisms for clarification or conflict resolution.
To fix coordination issues:
Implement explicit, role-aware message schemas (JSON or function calls) that force agents to declare intent, inputs, and expected outputs.
Formalize speech acts like "propose," "criticize," and "refine" to create machine-readable hooks for monitoring.
Maintain a "responsibility matrix" within your prompts to prevent role creep and make boundary violations obvious.
Deploy real-time coordination monitors to watch for role drift, missing acknowledgments, or stalled debates.
Implement consensus mechanisms like structured debate followed by majority vote or a rotating "chair" to resolve disagreements.
With proper guardrails, you can transform this common failure mode into a controlled, observable, and solvable engineering challenge.
2. Lost Context Across Agent Handoffs
Every hand-off between agents puts your workflow's shared memory at risk. When one model's reply exceeds another's context window, critical details vanish, and the next agent starts reasoning from a partial snapshot.
Field studies identify context loss as a significant contributor to coordination breakdowns, creating ambiguity and misalignment patterns that compound across interactions.
Your challenge extends beyond token limits. Sequential chains compress earlier messages, eroding information fidelity with each hop. In decentralized teams, asynchronous messages may arrive out of order, and compliance policies may prohibit sharing sensitive information.
When that balance tilts wrong, plans diverge, and costs climb as agents regenerate already-solved work.
To overcome these context challenges, use these proven methods:
Persistent storage: Write agent outputs to a shared vector database or graph so subsequent calls fetch the full thread. Persistent logs reduce context resets and improve resolution. For regulated domains, add fine-grained access controls.
Session tokens: Attach unique IDs to each message, allowing orchestration layers to pull the correct history even during parallel execution.
Real-time visibility: Set up dashboards to detect topic changes or empty context fields. When gaps occur, use middleware to prompt clarification requests rather than guessing.
Redundancy mechanisms: Implement fallback routes that replay the last known-good state to keep workflows moving when primary channels fail.
When you combine these techniques—persistent storage, session IDs, structured protocols, monitoring, and redundant recovery—error rates in handoff-heavy workflows drop significantly, and your agents keep moving forward instead of circling back.
3. Endless Loops and Stalled Workflows
Nothing drains your quota faster than two agents debating the same point indefinitely. These loops occur when conversations cycle without progress—usually because no agent knows when the task is complete, or each keeps repeating clarification requests that the other can't satisfy.
Left unchecked, these spirals consume tokens, stall workflows, and generate unnecessary API charges. You'll typically see circular exchanges stem from missing termination criteria, ambiguous prompts, or memory limits that cause agents to forget previous discussions.
Once dialogue resets, both sides restart the conversation, creating a perpetual cycle of unproductive exchanges.
Catch these patterns early with modern loop-detection techniques. Implement robust intent classification to flag responses that fall outside productive categories and track when fallback intent frequency spikes.
In well-defined domains, high-quality intent models achieve high accuracy, providing reliable signals when agents lose focus.
Add a layer of defense with flow analytics. Tools that replay entire dialogues and map state transitions can help surface repeated cycles that humans may miss during manual reviews.
4. Runtime Coordination Failures
Your smartest agent team stalls when the runtime can't keep pace. Sequential chains hit this wall hardest—each agent waits for the previous one to finish.
Parallel execution fixes the bottleneck but introduces synchronization barriers, duplicate work, and race conditions that unpredictably spike latency.
When multiple tasks compete for GPUs, context budgets, or third-party APIs, costs explode. Production data shows that uncoordinated agent swarms can burn through available tokens in minutes—expensive, silent failures.
For scale, organize agents by function to reduce cross-talk. The Mixture-of-Experts approach activates only agents whose expertise matches the sub-task, significantly reducing compute overhead.
Implement real-time feedback through distributed tracing, asynchronous job queues, and unified dashboards that alert on throughput drops. Deploy auto-scalers based on queue depth rather than rigid schedules.
Add resilience with circuit breakers for tool calls and graceful degradation policies. When you combine orchestration, specialization, and continuous telemetry, your system transforms from a fragile prototype into a scalable service that controls both latency and budget.
5. Single Agent Failures Cascading Downstream
A single agent going rogue often topples an otherwise well-orchestrated team. When one model ignores its brief or misreads a prompt, downstream agents inherit flawed context. They amplify the mistake and ship an output nobody wants.
Large-scale production evaluations show that specification and design flaws within a single agent account for the majority of recorded breakdowns in multi-agent systems. Failures often begin before coordination even starts.
You'll see these problems surface in predictable ways that can be caught with the right guardrails:
Disobeying the task specification—an agent silently drops required constraints and generates off-topic or insecure code
Ambiguous or conflicting instructions that push the agent toward divergent behaviors
Improper task decomposition, where the planner slices work into unusable fragments, leaving executors unable to reassemble a coherent answer
Duplicate roles that trigger competition or redundant work, wasting tokens and time
Missing termination cues; the agent never calls "done," so peers keep waiting and looping
Once any of those mistakes appear, errors cascade through your system, hidden behind syntactically "correct" language that makes detection difficult without explicit safeguards.
Instead of unquestioningly trusting agents, implement protective layers: error isolation with sandboxed execution, structured outputs, and validation before broadcasting results. When checks fail, discard results without contaminating shared context.
Add graceful degradation for crashes and timeouts by triggering simpler fallback paths with exponential retry logic. Enable early detection through continuous monitoring—tag messages with the agent ID and intent to quickly catch role drift, and implement "handshake" protocols as needed.
Complete your defense with prompt engineering: clear role boundaries, acceptance criteria, and well-defined completion signals prevent individual failures from compromising your entire agent team.
6. Role Confusion and Boundary Violations
When agent role confusion happens, your carefully designed specialist agents start behaving like generalists, defeating the entire purpose of your multi-agent architecture. Role confusion emerges when agents drift from their intended responsibilities, duplicate each other's work, or fail to maintain the boundaries that make specialization valuable.
You'll spot role confusion when your "planner" agent suddenly starts writing code instead of creating task breakdowns, or two different agents simultaneously try to handle the same API call. These boundary violations create chaos in your workflow orchestration.
Without clear responsibility matrices, agents either assume someone else is covering a task (creating gaps) or multiple agents tackle the same work (creating conflicts and waste).
When workloads shift, agents often revert to generic problem-solving behaviors rather than staying within their specialized domains.
To prevent role confusion and maintain agent specialization:
Define explicit responsibility boundaries using structured role definitions that specify not just what each agent should do, but what they should never attempt. Include negative constraints alongside positive capabilities.
Implement role-validation checkpoints that require agents to declare their intended actions before execution. Use middleware to reject attempts that fall outside defined boundaries.
Create handoff protocols that formalize how agents transfer work to specialists. Build explicit triggers that route tasks to appropriate experts rather than letting agents decide when to delegate.
Use capability-based routing that prevents agents from accessing tools or APIs outside their specialization. Technical constraints reinforce behavioral boundaries.
When you maintain clear agent roles, your multi-agent system delivers specialized expertise in coordination rather than becoming an expensive collection of confused generalists.
7. Inadequate Observability and Debugging
Traditional debugging breaks down in multi-agent LLM workflows. Their non-deterministic nature—where each prompt yields different answers, agents work in parallel, and messages flow through opaque orchestration—creates failures that appear random yet often stem from a single missed handshake.
Standard tools fail because stack traces assume linear execution, and breakpoints require repeatable state. To regain observability, use these essential practices:
Structured logging: Assign correlation IDs to every message, plan, and tool call to reconstruct end-to-end traces, similar to Anthropic's centralized token collection
Visual analytics: Create graph views (agents as nodes, messages as edges) with heat maps to identify missing inputs, role drift, and latency spikes
Conversation replay: Store complete dialogues to rewind, fork with modified prompts, and verify fixes
Regression testing: Codify previously failed agent exchanges and run them on every commit
Failure analysis: Record triggers when agents escalate, timeout, or emit low confidence to surface systemic weaknesses
Together, these techniques transform multi-agent debugging from guesswork into a repeatable engineering discipline with comprehensive visibility into your agent collective.
When Multi-Agent Systems Deliver in Production
Not every multi-agent implementation fails. The successes share specific characteristics that most teams overlook.
Anthropic's research system demonstrates the gold standard. When tasked with analyzing climate change impacts, it spawns specialized agents that simultaneously investigate economic effects, environmental data, and policy implications. Each agent dives deep into its domain, citing 50+ sources that a single agent would never have time to process.
Why it works: No agent modifies another's findings. They read, analyze, and report. The orchestrator synthesizes without coordination overhead because the combination is additive rather than interactive.
The Hidden Success Factors
Embarrassingly Parallel Problems
The term from distributed computing applies perfectly. If you can split your problem into chunks that require zero communication during processing, multi-agent systems excel. Think MapReduce, not collaborative editing.
Read-Heavy, Write-Light Architecture
Successful systems follow a 90/10 rule: 90% reading and analysis, 10% writing results. When agents primarily consume information rather than produce it, coordination complexity drops exponentially.
Deterministic Orchestration
Winners use explicit state machines, not emergent coordination. Anthropic's system doesn't hope agents will figure out how to work together. It defines exact handoff points, data formats, and fallback behaviors.
The Architecture That Makes It Work
Notice what's missing? No inter-agent communication. No shared mutable state. No complex coordination protocols.
Multi-agent systems deliver when:
Latency matters more than cost - Parallel processing justifies a 2-5x cost increase
Subtasks are truly independent - Zero shared state during execution
Combination is mechanical - Results merge through concatenation, voting, or averaging
Scale justifies complexity - Processing thousands of items, where parallelization provides exponential benefits
Failure isolation is critical - One agent failing shouldn't cascade
The successes aren't using multi-agent because it's clever. They're using it because parallel processing of independent tasks is the only way to meet their performance requirements.
The Bitter Lesson: Are You Building for Tomorrow's Problems?
Rich Sutton's Bitter Lesson teaches us that general methods leveraging computation ultimately win over specialized structures. This principle now collides with multi-agent system design in revealing ways.
Structure as a Temporary Fix for Weakness
Consider what we're actually doing with multi-agent systems: we're adding structure to compensate for limitations in the current model. Can't get GPT-5 to handle complex reasoning and execution in one pass? Split it into specialist agents. Is the context window too small for comprehensive analysis? Distribute the load. Is the tool calling unreliable? Create dedicated tool-use agents.
But here's the uncomfortable question: what happens when these limitations disappear?
The Return of the Single Agent
Boris from Anthropic's Claude Code team embraces the Bitter Lesson in his approach. Rather than building elaborate multi-agent choreography, he focuses on improving the model directly. The recent success of single-agent systems beating multi-agent baselines by significant margins validates this approach.
The pattern is already visible in production systems. Teams that built complex orchestration layers for GPT-3.5 found them unnecessary with GPT-4. Multi-step reasoning chains designed for Claude 2 were replaced with single prompts in Claude 3.
The structure added to work around limitations became the limitation itself. We often see such patterns in our agent leaderboard, where new models are significantly faster and cost-optimal.
This creates a fundamental tension in system design. Every constraint you add to handle today's agent boundaries, explicit handoffs, and role specialization becomes technical debt when tomorrow's model doesn't need them. You're not building for the future; you're patching around the present.
The practical implication is stark: your sophisticated multi-agent system might be obsolete before it reaches production scale. That carefully orchestrated ballet of specialized agents, each handling their narrow domain? Next quarter's model might handle it all in a single call, faster and more cost-effectively than your distributed system could.
Designing for Deletion
The smarter approach follows Hyung Won Chung's philosophy: add only the minimal structure needed for current compute levels, and actively plan for its removal. Design your agent systems with deletion in mind. Make architectural boundaries easy to collapse. Keep orchestration logic separate from business logic.
Most importantly, question whether you need distribution at all. If you're splitting tasks across agents because the model can't handle complexity, you might be better off waiting two months for a better model than spending those months building infrastructure you'll throw away.
The history of AI is littered with clever workarounds that became irrelevant when the next model arrived.
A Decision Framework Before Building Multi-Agent Systems
Before building a multi-agent system, ask yourself these questions in order:
1. Can better prompt engineering solve this? In 80% of cases, a well-crafted single agent with thoughtful context management outperforms a multi-agent system. Don't distribute complexity you haven't first tried to eliminate.
2. Are your subtasks genuinely independent? Drawing boxes on an architecture diagram doesn't make tasks parallel. True independence means zero shared state during execution. If Agent B needs Agent A's output to function, you don't have parallel tasks. You have sequential tasks with extra overhead.
3. Can you afford the cost increase? This isn't hyperbole. Between coordination overhead, redundant context, and retry logic, costs multiply.
4. Is latency tolerance measured in seconds? Each agent handoff adds 100-500ms. Five agents can add 2+ seconds to response time. If you need sub-second responses, a multi-agent system is the wrong choice.
5. Do you have the debugging infrastructure? When something goes wrong in a multi-agent system, finding the root cause is exponentially harder than with single agents. Without proper observability, you're flying blind.

Debug, Monitor, and Reliably Scale Multi-Agent Systems with Galileo
Multi-agent systems don't become reliable by accident. The teams shipping them successfully share one thing: complete visibility into what every agent is doing, why they made each decision, and where coordination breaks down before customers experience the consequences.
Without that infrastructure, you're debugging non-deterministic failures in production with tools designed for linear code — a losing battle that compounds with every agent you add.
Here’s how Galileo transforms your multi-agent observability gap:
Comprehensive Coverage Through Graph Engine: Galileo automatically maps every decision point in multi-step agent workflows, identifies gaps where evaluation is missing, and transforms abstract coverage metrics into actionable engineering work that directly correlates with the 70.3% excellent reliability achieved by elite teams.
Cost-Effective Evaluation at Scale with Luna-2 SLMs: With evaluation costs 97% lower than GPT-4 alternatives and sub-200ms latency even when running 10-20 metrics simultaneously, Galileo enables teams to achieve the 70%+ coverage threshold without budget constraints
Automated Failure Detection via Signals: Rather than waiting for production incidents to reveal evaluation gaps, Galileo's Signals automatically surfaces failure patterns across agent traces
Runtime Protection Through Protect API: Galileo's industry-leading runtime guardrails catch hallucinations, policy violations, and safety issues in milliseconds at serve time, transforming the incident paradigm from reactive cleanup to preventive blocking
Continuous Improvement with CLHF: With Galileo, you can fine-tune specialized evaluation models on your domain using Continuous Learning via Human Feedback, achieving the consistency that 93% of teams report missing from standard LLM-as-a-judge approaches
Discover how Galileo can help you ship reliable multi-agent systems without the expensive failures that typically follow them into production.
Frequently Asked Questions
What are multi-agent AI evaluation platforms, and how do they differ from traditional monitoring tools?
Multi-agent AI evaluation platforms instrument the decision-making layer by tracking agent reasoning, tool selection, and coordination patterns across performance, quality, cost, and reliability metrics.
Unlike traditional application monitoring tracking infrastructure metrics, these platforms measure agent-specific dimensions, including tool selection accuracy and inter-agent communication effectiveness.
When should organizations invest in dedicated multi-agent evaluation platforms?
Organizations should implement evaluation platforms when deploying autonomous agents. Gartner research shows that more than 40% of agentic AI projects will be canceled by 2027 due to a lack of robust evaluation infrastructure. Early investment in evaluation infrastructure separates successful implementations from failed projects.
What metrics should engineering leaders track for multi-agent system coordination?
Track metrics across four categories: performance (latency per agent step, task completion rates), coordination quality (handoff success rates, tool selection accuracy), cost (token consumption per agent), and reliability (error clustering patterns, drift detection).
The most critical unsolved challenge remains assessing inter-agent collaboration. While platforms excel at measuring individual-agent performance (latency per step, tool-selection accuracy, error rates), quantifying coordination quality requires capturing emergent behaviors.
Does Agent A's output format match Agent B's expected input structure? Did context loss during handoffs cause downstream failures? Purpose-built platforms instrument these coordination-specific failure modes.
How does Galileo's Luna-2 evaluation model compare to using GPT-4 for agent evaluation?
Luna-2 is purpose-built specifically for evaluation tasks, optimizing for consistency and accuracy in quality assessment. Galileo reports delivering faster inference with lower latency and cost than GPT-4 for evaluation-specific tasks, making continuous evaluation economically viable at enterprise scale.
Can multi-agent evaluation platforms integrate with existing observability tools like Datadog or Splunk?
Yes, most modern platforms support integration through OpenTelemetry-compatible instrumentation. Microsoft advanced industry standards by announcing extensions specifically for multi-agent AI systems. Comprehensive evaluation platforms like Galileo provide native integrations enabling correlation between agent-level decision metrics and infrastructure-level performance data.

Pratik Bhavsar