

Picture this: Your bank's AI chatbot confidently tells a customer they can withdraw funds from their fixed-term deposit without penalty. The problem? It's completely wrong. The damage? Millions in waived fees and compliance headaches.
The culprit? Your RAG system pulling outdated policy documents while missing current terms. Even worse—your monitoring tools showed everything working perfectly.
This isn't some hypothetical nightmare. It's happening right now across organizations where RAG systems fail silently, creating financial liability, regulatory exposure, and damaged trust. Standard monitoring misses the mark because it tracks technical stats like latency but completely overlooks semantic failures—when systems confidently present fiction as fact.
Let's dive into RAG's architecture, examine why these costly failures happen, and build practical strategies to protect you from the expensive mistakes that standard monitoring misses.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What is retrieval-augmented generation (RAG)?
Retrieval-Augmented Generation (RAG) is an advanced AI framework that integrates external information retrieval systems with generative capabilities to enhance large language models.
Unlike traditional LLMs that rely solely on their training data for responses, RAG actively fetches and incorporates relevant external sources before generation.
Think of it as a well-informed assistant that not only has extensive knowledge but can also reference the latest information to provide accurate, contextually relevant answers.
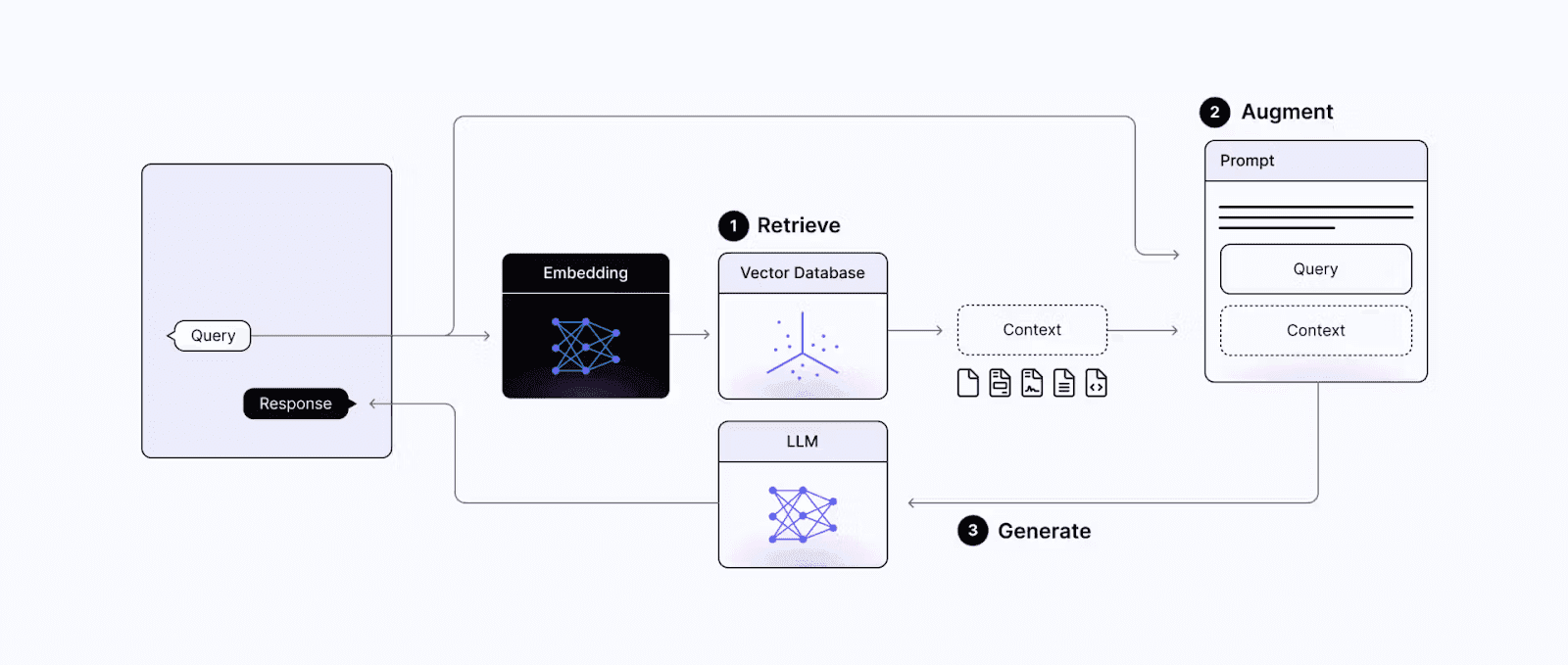
RAG’s core components
RAG architecture comprises two core components that work in tandem:
Retrieval Module: This module identifies and fetches relevant documents or data from external knowledge sources. When given a query, it searches databases, documentation, or other specified sources for the most pertinent information.
Generation Module: Once relevant data is retrieved, this component combines it with the original input prompt and sends it to the generative model. The model then synthesizes a response that incorporates both the retrieved context and its own generative capabilities.
The technical architecture of RAG implements a sophisticated two-step process. First, it employs retrieval algorithms such as BM25 or dense vector search to identify the most relevant documents.
Then, using transformer-based architectures, it combines the retrieved information with the original prompt to create coherent and informative responses.
RAG versus traditional LLMs
Traditional LLMs rely solely on information learned during training, while RAG systems actively retrieve and incorporate external knowledge when generating responses. This fundamental difference gives RAG significant advantages in accuracy, transparency, and adaptability. By grounding responses in retrieved documents rather than just pre-trained patterns, RAG provides factual, verifiable answers that can evolve without retraining.
Capability | Traditional LLMs | RAG Systems | Business Impact |
Knowledge Access | Limited to information learned during training | Can access and incorporate current information from external sources | Your systems deliver accurate, up-to-date responses even for rapidly changing domains |
Hallucination Prevention | Often produce plausible yet incorrect information, known as hallucinations in AI | Ground responses in retrieved factual data, significantly reducing fabricated content | You avoid costly errors and compliance violations from AI-generated misinformation |
Transparency | Offer minimal transparency about information sources | Provide clear attribution by referencing the specific documents used | Your teams can trace and verify exactly which sources informed each response |
Adaptability | Require complete retraining to incorporate new information | Can be updated by simply adding documents to the knowledge base | You maintain accuracy with significantly lower maintenance costs and faster updates |
RAG architecture is especially beneficial for applications demanding accurate, up-to-date information, such as customer support systems, research assistants, and content creation tools. By coupling robust retrieval with generative capabilities, RAG advances your AI systems toward greater reliability and factual grounding.
How does retrieval-augmented generation work?
RAG operates through a sophisticated three-phase process that combines information retrieval with neural text generation. Let’s break down each phase to understand how they work together to produce accurate, context-aware responses.
The retrieval process
The retrieval phase begins by searching through a knowledge base to find relevant information for a given query. This process primarily uses two methods:
Vector Search: Documents and queries are transformed into high-dimensional vectors using embedding models like BERT or Sentence Transformers. The resulting embeddings capture semantic meaning, allowing the system to compute similarities between the query and stored documents based on their contextual relationships.
Keyword Matching: As a complementary approach, the system also performs traditional keyword matching to catch exact matches that might be missed by semantic search. While simpler than vector search, it helps ensure critical exact matches aren’t overlooked.
The augmentation step
Once relevant information is retrieved, the augmentation phase integrates it with the original query. That integration happens through two main techniques:
Document Concatenation: The system appends retrieved documents to the original query, creating an enriched context. For example, if you query about climate change, the system might append recent scientific studies or verified data to provide comprehensive context.
Embedding-Based Integration: Both the query and retrieved documents are transformed into embeddings and combined using sophisticated attention mechanisms. These mechanisms help the model focus on the most relevant parts of the retrieved information, creating a coherent context for generation.
The generation phase
The final phase involves processing the augmented input to produce coherent, factual responses. It leverages:
Transformer Architectures: The system uses transformer-based models that excel at processing large contexts and maintaining coherence. These architectures enable parallel processing of input data, making the generation both efficient and contextually aware.
Fine-tuning Strategies: Pre-trained models like GPT-3 or GPT-4 are often fine-tuned on domain-specific datasets to handle specialized knowledge and terminology better. This adaptation helps ensure generated responses maintain both accuracy and relevance to the specific use case.
That evaluation feeds back into the system’s optimization, creating a cycle of continuous improvement in response quality.
Advanced RAG architecture
Advanced RAG architectures move beyond simple retrieval to create intelligent systems that can solve complex, multi-step problems with improved accuracy and flexibility.
Agent-RAG integration
Remember that basic RAG prototype that failed with multi-step questions? AI agents solve this limitation. While traditional RAG simply retrieves once and generates, agents plan, reason, and execute multiple steps, knowing when to dig deeper, call APIs, or change approach.
The power lies in orchestrated specialization. A planning agent breaks questions into manageable tasks, determining whether to search data, run calculations, or use services. Retrieval agents then select sources and pull relevant passages, while a reasoning agent checks for contradictions before a generation agent crafts the final response. This layered approach keeps components focused and debugging straightforward, as explained in agentic architecture research.
Central orchestration routes all messages through a controller that tracks operations, enforces security, and logs tool usage. This allows you to integrate specialty agents without system-wide changes. Recent studies show multiple cooperating agents reduced hallucinations by more than half in complex medical inquiries.
Key benefits include:
Enhanced reasoning for multi-step problems requiring diverse knowledge
Dynamic workflows adapting to specific information needs
Specialized agents for domain tasks like financial analysis
Improved accuracy through cross-verification
Reduced hallucination rates with evidence-grounded steps
Real-world results are compelling: one manufacturer implemented this for their service desk, reducing resolution times from 18 minutes to under 5.
The challenge? Complexity grows exponentially. You must track every query, document, and tool interaction to prevent silent failures. With proper observability, these powerful workflows deliver control, accuracy, and compliance.
Multi-hop RAG systems
Ever asked a question requiring multiple data points? Traditional RAG systems retrieve once and hope for the best. Multi-hop RAG solves this limitation by performing sequential retrieval-generation cycles.
At its core, multi-hop RAG chains together multiple searches. After your initial query, the system reformulates follow-up questions based on partial findings, retrieves fresh context, and stores validated facts in memory before the next cycle. This approach connects information scattered across different documents, creating relationships that single retrievals miss.
The architecture extends standard RAG with three key components: a decomposition module that breaks complex questions into sub-queries, an intermediate reasoning agent that synthesizes findings from each hop, and a memory store that maintains context between cycles. Retrieval methods can vary by hop, using vector search for some queries and keyword filters for others.
Multi-hop RAG excels in applications like:
Financial analysis connecting reports, trends, and competitor data
Medical diagnosis linking symptoms, history, and protocols
Legal research bridging case law, statutes, and procedures
Investigative work following evidence chains
Technical troubleshooting combining architecture, logs, and documentation
Challenges include exponential complexity with each hop, requiring hop-aware metrics, aggressive relevance filtering, and memory pruning to prevent context contamination. While additional hops increase latency and potential failure points, proper implementation transforms your system into an investigative partner that follows evidence trails until finding complete answers.
Tools and frameworks for RAG
Your RAG demo wowed the exec team. Now they want it production-ready by next quarter, and you're facing a maze of framework options, database choices, and cloud integrations. Three open-source frameworks now lead enterprise deployments, each solving different challenges.
LangChain: Offers pre-built chains for retrieval, routing, and evaluation—perfect when you need a working prototype fast
LlamaIndex: Specializes in data connectors and query engines; if your knowledge spans many different systems, its ingestion pipelines save you from building custom integrations
Haystack: Focuses on production readiness with pipeline orchestration and built-in monitoring, making it your bridge from notebook to production cluster
For observability and evaluation needs, purpose-built platforms like Galileo provide comprehensive RAG analytics with automated evaluation metrics, context adherence scoring, and chunk attribution analysis. These capabilities help you debug retrieval errors, improve chunking strategies, and ensure factual responses—critical for maintaining reliability once your RAG system reaches production.
Vector databases present their own trade-offs beyond the proof-of-concept stage. Pinecone delivers managed similarity search with auto-scaling you don't have to maintain, plus clear documentation.
Cloud providers now bundle these pieces into complete solutions. AWS includes retrieval in Bedrock and pairs it with vector-aware services like Kendra and Neptune.
Google's Vertex AI Search connects directly to existing BigQuery pipelines, while Azure Cognitive Search offers a complete pattern ready to use. These managed services handle the DevOps checklist—identity, logging, encryption, and autoscaling come built-in.
When building your RAG implementation, focus on three key decision factors:
Data gravity: How many systems you need to connect and where your data currently lives
Latency requirements: What response times your interactive use cases demand
Governance needs: What level of audit trails, access controls, or regional data rules you must follow
Start with the framework that matches your team's language skills, then move storage and orchestration to platforms that meet your compliance and cost requirements as usage grows.
Three benefits and use cases of RAG
Understanding the full potential of Retrieval-Augmented Generation means exploring both its technical strengths and practical applications. In this section, we’ll review major benefits RAG brings to AI systems and showcase how it's being applied across different sectors.
Leverage the technical advantages of RAG
Retrieval-Augmented Generation delivers significant technical improvements over traditional LLMs by combining the power of language models with external knowledge bases. The key technical benefits include:
Improved accuracy and relevance through real-time data access, ensuring responses are based on the most current information rather than potentially outdated training data
Enhanced control over source material, allowing organizations to maintain authority over the information their AI systems use
Reduced hallucinations by grounding responses in retrieved documents rather than relying solely on the model’s training data
Faster response times through efficient retrieval mechanisms that quickly access relevant information. Adopting innovative approaches and game-changing RAG tools can further enhance these benefits.
Realize tangible business benefits
While such technical advantages are impressive, they translate into significant business value across multiple dimensions:
Reduced operational costs through automation of information retrieval and response generation, particularly in customer service operations
Enhanced compliance and risk management by maintaining control over information sources and ensuring responses are based on approved content
Improved scalability as organizations can easily update their knowledge bases without retraining their entire AI system
Better customer satisfaction through more accurate and contextually relevant responses
Implement RAG in real-world scenarios
Many organizations are already reaping these benefits across various industries:
Customer Support Systems: Enabling support teams to provide accurate, contextual responses by accessing up-to-date product documentation and customer histories highlighting significant improvements in first-response accuracy.
Healthcare Decision Support: Assisting healthcare professionals by retrieving relevant medical literature and patient data for improved clinical decision-making. That approach has led to more informed treatment plans.
Financial Services: Supporting risk assessment and compliance by retrieving and analyzing historical financial data and regulatory requirements, enabling improved decision-making processes in financial institutions.
E-commerce Personalization: Enhancing product recommendations by combining user preferences with real-time inventory and pricing data, leading to more personalized shopping experiences.
Legal Research and Compliance: Enabling legal professionals to quickly access and analyze relevant case law, regulations, and internal documentation for more efficient legal research and compliance monitoring.
Content Management: Helping organizations maintain consistency in their communications by retrieving and referencing approved content and brand guidelines during content generation.
Each of these applications demonstrates RAG’s ability to combine the power of LLMs with domain-specific knowledge, resulting in more accurate, reliable, and contextually appropriate AI systems that deliver real business value.
Implementation challenges and solutions
While Retrieval-Augmented Generation offers powerful capabilities for enhancing AI applications, effectively implementing these systems presents significant technical challenges.
As RAG systems combine complex retrieval mechanisms with generative AI, organizations must navigate various obstacles to ensure reliable and efficient operation. Let’s explore the key challenges and their corresponding solutions.
Complexity and opaqueness in RAG systems
RAG architectures combine multiple components that interact in complex ways, making it challenging to understand system behavior and identify the root cause of issues. The interaction between retrieval and generation components can create a “black box” effect, where it’s unclear why certain outputs are produced or where improvements are needed.
Implementing effective LLM observability practices is crucial to understanding system behavior and identifying root causes of issues.
Galileo’s RAG & Agent Analytics addresses this challenge by providing comprehensive system visibility and detailed insights into each component’s performance. The tool offers AI builders powerful metrics and AI-assisted workflows to evaluate and optimize the inner workings of their RAG systems, enhancing visibility and debugging capabilities.
Labor-intensive manual evaluation
Traditional RAG evaluation requires extensive manual effort to assess both retrieval accuracy and generation quality. This process is time-consuming and often leads to inconsistent results due to varying evaluation criteria and human subjectivity.
Galileo’s automated RAG evaluation metrics and analytics provide consistent, scalable evaluation methods. The platform automatically tracks key performance indicators and generates comprehensive reports, which enhances visibility and helps AI builders optimize and evaluate their RAG systems effectively.
Advanced failure modes
You've likely encountered RAG systems that perform flawlessly in testing but stumble when facing real users' complex queries. These failures occur across the entire pipeline, not just in the LLM component.
Retrieval failures happen when your knowledge base lacks answers ("missing content"), aggressive chunking scatters information across multiple passages, or overly permissive similarity thresholds flood prompts with irrelevant text. Even semantic rankers can introduce "seductive distractors" that appear relevant but mislead the model.
Generation problems manifest as confident-sounding responses containing hallucinations or contradictions. When context is thin, models fabricate data; when sources conflict, they blend contradictory information. These errors bypass casual review because they're delivered with artificial confidence.
Effective monitoring requires end-to-end traceability from query to citation. Implement retrieval logging (chunk IDs, similarity scores) to replay failures, add relevance checks comparing retrieved passages to known-good answers, and use automated grounding verification to flag statements lacking evidence.
Chunking complexity
Determining the optimal way to chunk and retrieve information significantly impacts RAG system performance. Poor chunking strategies can lead to irrelevant context being retrieved or important information being missed, affecting the quality of generated responses.
Galileo’s Chunk Attribution and Chunk Utilization metrics offer insights into the performance of chunking strategies, the effectiveness of chunks in generation, and how chunk size and structure impact system performance.
Chunk Attribution assesses a chunk's influence on the model’s response, while Chunk Utilization evaluates the extent of text involved, providing a comprehensive view of chunk efficiency in RAG workflows. For more details, see: Chunk Attribution Plus and Chunk Utilization.
Lack of context evaluation tools
Evaluating how effectively a RAG system uses retrieved context is crucial but often difficult to measure. Traditional evaluation methods may not capture the nuanced ways in which context influences generation quality.
Galileo's Context Adherence metric offers a quantitative measure of how effectively the system uses retrieved context. It ensures that generated responses accurately reflect and incorporate the provided information while remaining relevant to the query.
Lengthy experimentation processes
Testing different RAG configurations and improvements often involves lengthy cycles of trial and error, making it difficult to iterate quickly and optimize system performance. Without proper tools, experiments can be time-consuming and yield unclear results.
Galileo’s GenAI Studio offers a platform that supports teams in optimizing system performance and making informed decisions about improvements.
Best practices for RAG implementation
Successfully implementing a RAG system requires careful planning and adherence to proven strategies. In this section, we'll outline essential best practices to help you optimize your RAG implementation for maximum effectiveness.
Optimize your data pipeline
Begin with high-quality, well-structured data preparation. Clean your data by removing duplicates and standardizing formats. Use a robust chunking strategy that preserves semantic meaning while maintaining context.
Employing effective data strategies for RAG, such as generating synthetic data, can help build a diverse dataset covering various domain scenarios to improve retrieval accuracy and contextual understanding.
Select and configure your models strategically
Choose your models based on specific use-case requirements instead of general popularity. For retrieval, select embedding models aligned with your domain vocabulary and context. For generation, consider the trade-offs between model size and performance.
Larger models may provide higher-quality outputs but demand more computing resources. Evaluate multiple model combinations to identify the ideal balance when optimizing LLM performance.
Design a scalable architecture
Build your RAG system with scalability in mind from the outset. Employ efficient indexing and retrieval mechanisms that accommodate growing data volumes. Designing an enterprise RAG system architecture will help you keep components separate so they can scale and update independently.
When possible, incorporate asynchronous processing to reduce latency and enhance throughput. For reliability, implement robust error handling and fallback methods.
Implement comprehensive testing protocols
Develop thorough testing procedures for individual components and the entire system. Incorporate diverse test sets, including edge cases and challenging queries. Automate testing wherever possible to detect regressions or performance drops quickly.
Use A/B testing frameworks to compare retrieval strategies or model configurations. Monitor metrics such as retrieval accuracy, latency, and generation quality.
Establish continuous monitoring and maintenance
Silent retrieval failures and hallucinations erode trust before complaints emerge. Implement layered monitoring starting with retrieval quality metrics (precision, recall, and mean reciprocal rank) to identify content gaps. For generation, prioritize factuality over style with automatic flags for citations not found in retrieved sources.
Track both technical metrics (latency, token costs) and business outcomes (task completion, ticket deflection). Deploy drift detectors comparing query embeddings against historical patterns to catch relevance shifts early, and route uncertain responses to human review.
Structure dashboards by feature and region with percentile-based alerts, using feedback to drive continuous improvement.
Implement enterprise governance controls
Your production RAG system requires guardrails that satisfy compliance requirements. Add access controls at the embedding level with comprehensive audit trails.
Implement rigorous source vetting and versioning to prevent data drift, with clear prompt instructions forcing your LLM to rely on retrieved text and provide accurate citations.
Maintain complete traceability by logging all retrieved chunks and linking responses to sources. This lineage simplifies troubleshooting while satisfying auditors.
Complete your framework with regular bias monitoring to identify and correct skew in both retrieval and generation components.
Measure RAG applications accurately
Implementing RAG systems requires careful attention to retrieval quality, generation accuracy, and comprehensive eval metrics to ensure optimal performance and reliability. Employing effective AI eval methods is essential in this process.
Here’s how Galileo can help.
Comprehensive pipeline tracing: Galileo automatically logs every step from query to response, creating visual traces that make debugging intuitive instead of overwhelming
Hallucination detection: Context adherence analysis identifies when your LLM references facts not found in retrieved documents, flagging potential misinformation before it reaches users
Retrieval quality metrics: Quantitative measurement of relevance between queries and retrieved chunks helps you fine-tune vector search parameters for maximum accuracy
Custom evaluation guardrails: Deploy specialized metrics for your industry's needs, such as regulatory completeness checks for financial or healthcare applications
Continuous improvement framework: Track performance trends over time, identifying degradation patterns before they affect user trust
Galileo’s suite of analytics tools offers visibility and metrics for measuring, evaluating, and optimizing RAG applications, including metrics for chunk attribution and context adherence. Explore how Galileo can improve your RAG implementation.

Conor Bronsdon