

In August 2024, a laboratory demo captured on arXiv showed a chain-of-thought planning agent spiraling into an infinite loop after a single corrupted memory write, consuming its entire GPU quota and locking every downstream service in under 15 minutes.
That incident revealed how one misbehaving node can paralyze an entire multi-agent workflow.
In the multi-agent industry, we're now shipping systems where dozens of specialized LLMs call external tools and hand off tasks hundreds of times per session. Traditional single-model metrics—accuracy, latency, token cost—miss those graph-level hazards, creating gaps that attackers exploit through knowledge-base poisoning or context injection attacks.
When those gaps surface in production, they translate directly into costly outages, compliance violations, and reputational damage your leadership can't ignore.
So what does "success" actually look like for complex agent systems?
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
Performance metrics to define success in multi-agent AI
Defining success in multi-agent AI requires the use of specific metrics for AI agents that capture the effectiveness and efficiency of agent interactions within the system.

For multi-agent AI, here are the essential metrics that translate technical performance into executive confidence:
Action completion: Measures whether AI agents fully accomplish every user goal and provide clear answers or confirmations for every request
Agent efficiency: Evaluates how effectively agents utilize computational resources, time, and actions while maintaining quality outcomes
Tool selection quality: Determines if the right course of action was taken by assessing tool necessity, selection accuracy, and parameter correctness
Tool error: Detects and categorizes failures occurring when agents attempt to use external tools, APIs, or functions during task execution
Context adherence: Measures whether responses are purely grounded in provided context, serving as a precision metric for detecting hallucinations
Correctness: Evaluates factual accuracy of responses through systematic verification and chain-of-thought analysis
Instruction adherence: Measures how consistently models follow system or prompt instructions when generating responses
Conversation quality: Assesses coherence, relevance, and user satisfaction across multi-turn interactions throughout complete sessions
Intent change: Tracks when and how user intentions shift during agent interactions and whether agents successfully adapt
Agent flow: Measures correctness and coherence of agentic trajectories against user-specified natural language test criteria
Uncertainty: Quantifies model confidence by measuring randomness in token-level decisions during response generation
Prompt injection: Identifies security vulnerabilities where user inputs manipulate AI models to bypass safety measures
PII detection: Identifies sensitive data spans, including account information, addresses, and personal identifiers, through specialized models
Toxicity: Evaluates content for harmful, offensive, or inappropriate language that could violate standards or policies
Tone: Classifies emotional characteristics of responses across nine categories, including neutral, joy, anger, and confusion
Chunk utilization: Measures the fraction of retrieved chunk text that influenced the model's response in RAG pipelines
Completeness: Evaluates how thoroughly responses cover relevant information available in the provided context
While these common metrics provide a general framework for evals, custom metrics are crucial for capturing domain-specific requirements and nuances. Tailoring metrics to specific applications allows for a more precise assessment of agent performance in contexts where unique challenges and objectives exist.

Four evals frameworks for defining success in multi-agent AI
Evaluation frameworks provide realistic testing scenarios to assess how agents perform in various complex tasks.
Galileo Agent Leaderboard
The Galileo Agent Leaderboard provides a comprehensive evaluation framework specifically designed to assess agent performance in real-world business scenarios. Unlike specialized benchmarks, this framework synthesizes multiple eval dimensions to offer practical insights into agent capabilities.
The leaderboard evaluates 17 leading LLMs (12 private, 5 open-source) across 14 diverse benchmarks, focusing on critical aspects of agent performance:
Tool selection quality: Measures agents' ability to choose and execute appropriate tools across varied scenarios
Context management: Evaluates coherence in multi-turn interactions and long-context handling
Cost-effectiveness: Analyzes the balance between performance and computational resources
Error handling: Measures resilience against edge cases, missing parameters, and unexpected inputs
What distinguishes this framework is its focus on practical business impact rather than purely academic metrics.
By incorporating various benchmarks and real-world testing scenarios, it provides actionable insights into how different models handle edge cases and safety considerations—crucial factors for enterprise deployments.
Berkeley Function-Calling Leaderboard (BFCL)
The Berkeley Function-Calling Leaderboard (BFCL) provides an evals benchmark for large language models (LLMs) in making and managing function calls.
Beyond traditional coding assessments, BFCL evaluates agents' abilities to plan, reason, and execute functions across diverse programming environments. This framework is instrumental in defining success in multi-agent AI through performance metrics:
BFCL V2: Incorporates enterprise data to reduce bias and data contamination
BFCL V3: Emphasizes multi-turn, multi-step function calls, assessing how well agents maintain context over extended interactions
τ-bench
τ-bench (tau-bench) is designed to evaluate real-world tool-agent-user interactions by simulating user behavior and domain-specific tasks within partially observable Markov decision processes (POMDPs).
Agents are required to utilize an API constrained by domain policies and databases. According to research studies, τ-bench effectively measures:
Action Completeness: Ensuring that database states align with intended outcomes.
Output Quality: Assessing the correctness and thoroughness of agents' responses.
By addressing these rule-based challenges, τ-bench evaluates agents' flexibility and precision in real-world scenarios, providing realistic testing scenarios that contribute to defining success in multi-agent AI.
PlanBench
PlanBench focuses specifically on planning and adaptability in multi-agent AI systems. Agents are required to develop and adjust plans within environments subject to sudden changes, testing their strategic capabilities and responsiveness to shifting variables.
With PlanBench, research studies have demonstrated how effectively agents strategize within multi-agent configurations, further defining success through performance metrics.
These frameworks emphasize that no single evaluation can capture all aspects of multi-agent performance. Each approach addresses different facets of complexity, from high-level function calls to nuanced human-tool interactions and adaptive planning for future scenarios.
Four common challenges in evaluating multi-agent AI systems
Perfect dashboards mean nothing if they sit on top of brittle operations. You need discipline to evaluate agents continuously, not a one-off scorecard. Even teams tracking every metric hit familiar roadblocks—fragmented traces, runaway eval costs, unpredictable emergent behaviors, and new security holes that open with every additional agent.
Each obstacle has a clear path forward when you pair sound engineering practice with purpose-built tooling.
Data aggregation & real-time monitoring
You probably waste hours stitching together logs from orchestration layers, model gateways, and tool APIs. Most teams sample a handful of traces, hoping they represent the whole system. That shortcut hides systemic faults—slow tool calls, silent failures, cascading errors—that only surface when you see every agent in context.
Comprehensive monitoring platforms, such as Galileo, present the full picture through interactive dashboards. Each node shows an agent step, every edge its dependency. Automated pattern mining highlights clusters of similar failures before users notice.
Stream traces into a unified store, tag each with run-id and parent-child links, and attach low-latency evaluators.
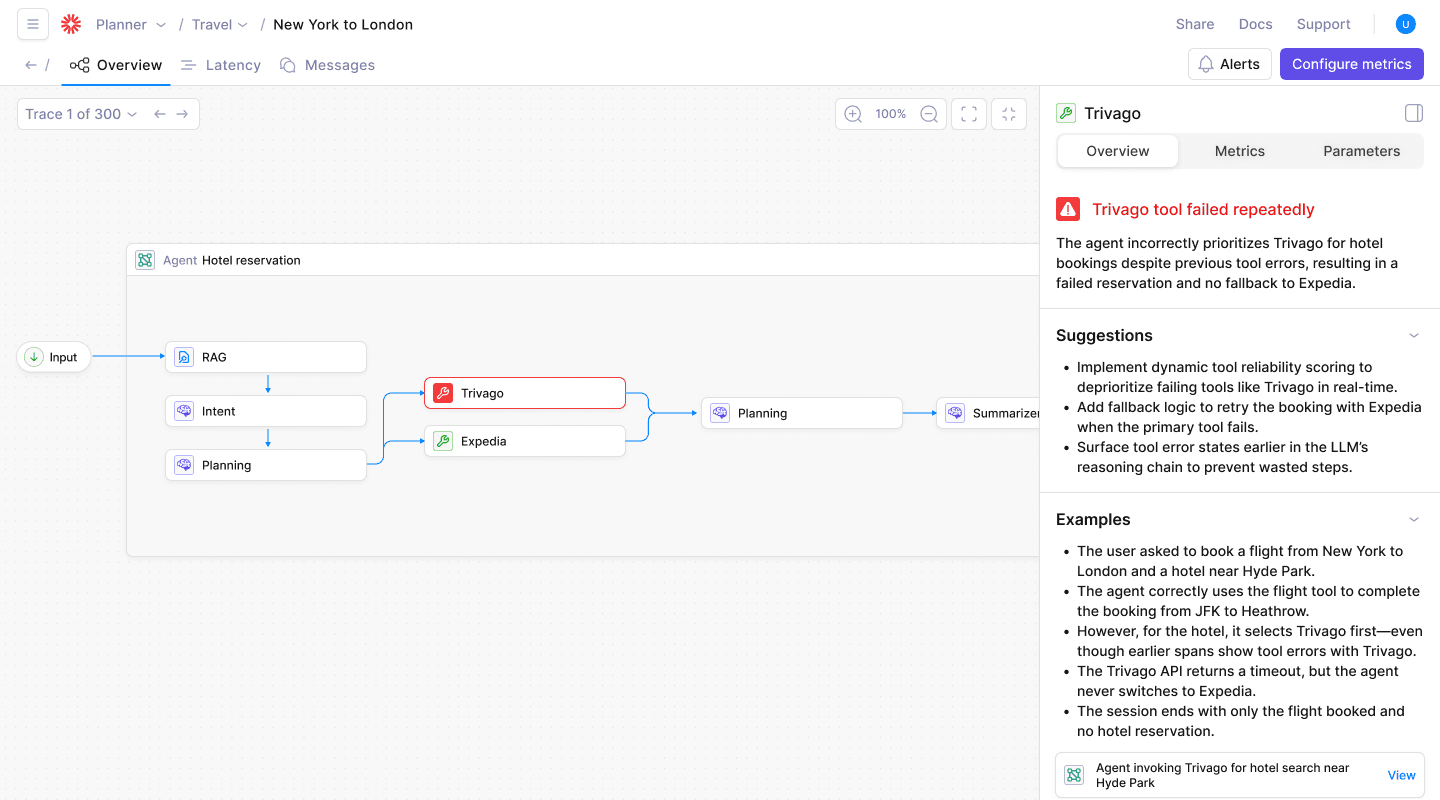
When a spike appears in the dashboard, you drill down in seconds instead of grepping gigabytes of JSON. Teams that aggregate this way routinely cut debug cycles from hours to minutes.
Evaluating emergent dynamics
How do you judge behavior no one explicitly programmed? Cooperation patterns can surface overnight, delivering clever shortcuts—or spawning feedback loops that wreck data quality. Traditional per-agent metrics miss both extremes because they focus on isolated outputs.
Multi-agent evals research shows the gap: you must capture conversation arcs and state transitions, then score them for coherence and alignment. Continuous learning via human feedback closes the loop by ranking multi-turn consistency, flagging divergent goals, and routing edge cases for quick annotation.
Start by sampling whole interaction threads, not single responses. Create evaluators that check goal adherence across turns. As your feedback data grows, fine-tune a small evaluator model to automate the same judgment. You'll turn emergent behavior from a liability into a competitive moat.
Scalability and resource optimization
Multi-agent workloads explode costs non-linearly. Doubling agents can quadruple tool calls and metric checks. If you price each evaluation at GPT-4 rates, monitoring becomes the first sacrifice when bills spike. Small language models change that calculus completely.
Low-cost evaluation models like Luna-2 deliver verdicts at roughly 3% of GPT-4 cost while maintaining millisecond latency. This makes scoring every step, every time, economically feasible. Architect your pipeline to batch evals, reuse shared model weights, and offload heavy lifting to SLMs fine-tuned for grading, not generation.

Using this approach, you can evaluate hundreds of metrics across millions of traces without touching budget caps. The payoff is twofold: richer observability and clearer optimization targets for prompts, caching, or tool selection. When you can measure everything cheaply, you iterate with confidence instead of flying blind.
Security and resilience
Autonomous agents open attack surfaces that traditional models never faced. Prompt injections, over-permissioned tool calls, chain reactions between cooperating bots. A single overlooked action can leak sensitive data or execute an irreversible transaction.
Advanced runntime protection is the antidote. Deterministic override layers evaluate each proposed action against policy in real time and block or rewrite anything non-compliant. Isolate credentials per agent, enforce least privilege, and insert eval hooks before external calls execute.

Pair that with continuous anomaly detection so you catch novel attack vectors as they emerge. Proactive guardrails turn potential brand incidents into non-events while your agents keep learning.
Ship reliable multi-agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy agents that deliver consistent value while avoiding costly failures.
Galileo's Agent Observability Platform provides the comprehensive capabilities you need:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evals on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evals: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how comprehensive observability can elevate your agent development and achieve reliable AI systems that users trust.

Conor Bronsdon