Deepseek V3 Overview
Explore Deepseek V3's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Deepseek V3 Overview
When context windows stretch beyond 20,000 tokens, conventional transformers hit an O(n²) complexity wall that throttles latency and burns through GPU memory. Deepseek-v3 addresses this with sparse-attention patterns that trim complexity toward O(n), delivering more efficient inference while maintaining comparable accuracy.
In this guide, you'll learn when deepseek-v3 beats dense alternatives, how to read performance heatmaps and specialization matrices, and where observability prevents costly failures.
The strategies here help you trace attention flows, catch hallucinations early, and optimize the speed-accuracy-cost triangle that makes or breaks your agent deployments.
Check out our Agent Leaderboard and pick the best LLM for your use case

Deepseek V3 performance heatmap
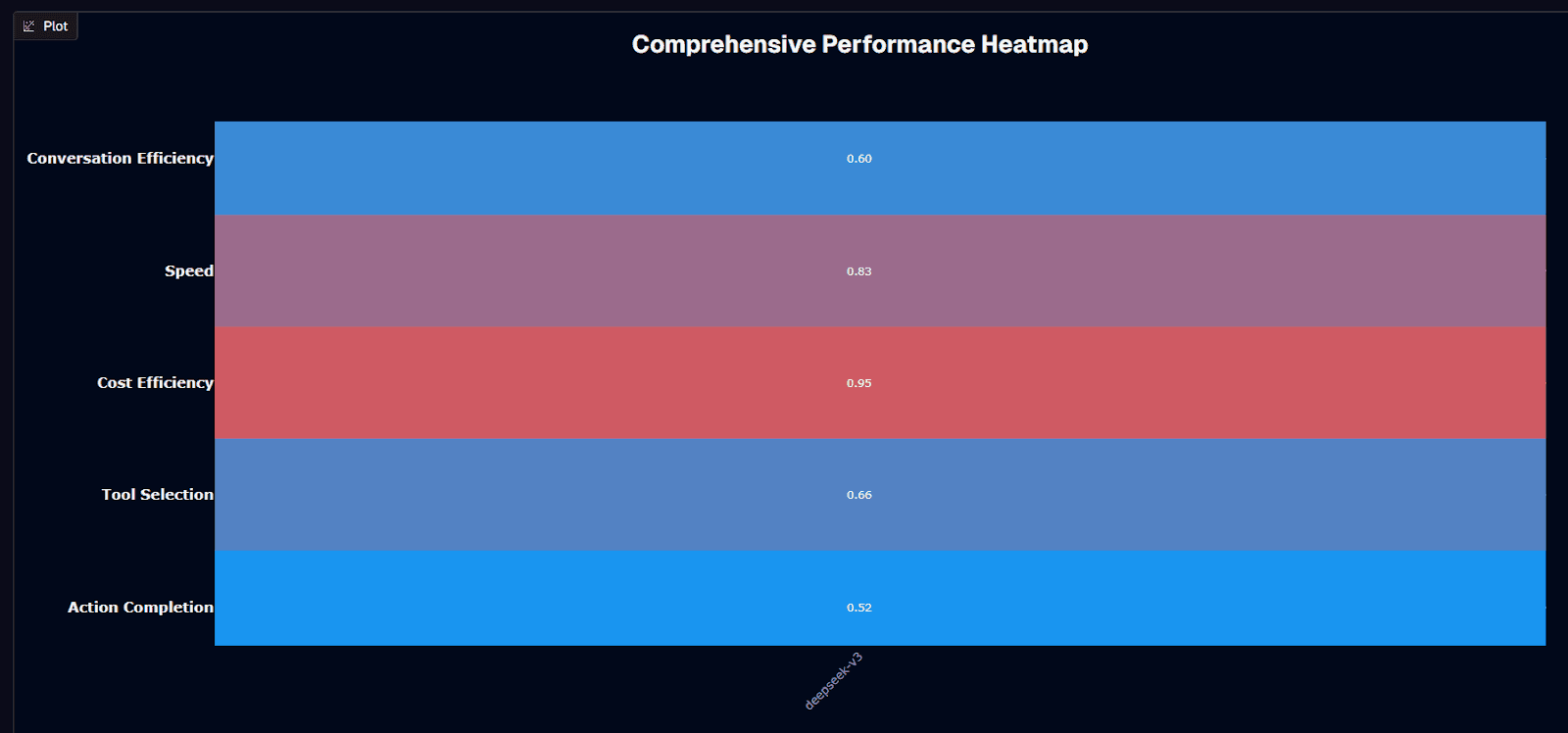
Deepseek-v3's performance heatmap reveals a strikingly imbalanced profile dominated by cost efficiency at 0.95—the model's singular exceptional metric. Speed follows at 0.83, then Tool Selection at 0.66, Conversation Efficiency at 0.60, and Action Completion trailing at 0.52.
The color coding emphasizes this disparity. The 43-basis-point gap between the model's highest and lowest performance metrics indicates a system optimized primarily for economic efficiency rather than task completion.
This pattern suggests architectural or training decisions that prioritized inference cost reduction over agentic capabilities.
When evaluating deepseek-v3, you should recognize this as a model fundamentally designed for high-volume, cost-sensitive deployments where completion rates can be managed through retry logic or human intervention rather than first-pass success.
Background research
DeepSeek V3 was officially released on December 26, 2024, marking a watershed moment in open-source AI development.
The model's foundational research is documented in the comprehensive "DeepSeek-V3 Technical Report", which details the 671-billion-parameter Mixture-of-Experts architecture trained on 14.8 trillion tokens for just $5.576 million—approximately 1/20th the reported cost of GPT-4.
This extraordinarily low training cost sparked significant industry discussion about the democratization of frontier AI capabilities and prompted immediate responses from major AI labs about competitive pressure.
The model was released under the permissive MIT License on GitHub, enabling unrestricted commercial use and modification.
DeepSeek AI followed up in May 2025 with a critical second paper, "Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures" (https://arxiv.org/abs/2505.09343), authored by CEO Wenfeng Liang and the research team.
This explores the hardware-software co-design principles that enabled efficient training on 2,048 H800 GPUs despite US export restrictions. The model received a significant update on March 24, 2025, with the DeepSeek-V3-0324 release featuring improved reasoning and coding capabilities.
DeepSeek V3's success built directly on DeepSeek-V2 (released May 2024) and preceded the January 2025 launch of DeepSeek-R1, a reasoning-focused model that competed directly with OpenAI's o1.
The V3 series demonstrated that open-source models could match closed-source performance from Anthropic and OpenAI while maintaining unprecedented cost efficiency, fundamentally shifting industry assumptions about the capital requirements for frontier model development.
Is Deepseek V3suitable for your use case?
Use Deepseek V3 if you need:
Cost-efficient processing of long context windows (legal briefs, multi-day chat logs, telemetry streams)
Predictable memory usage as sequences grow in large-scale deployments
Rapid, consistent answers in resource-constrained environments (edge devices, lightweight microservices)
Clearer visibility into reasoning patterns with sharper attention heatmaps for easier audits
Up to 6× speedup in practice using DeepSpeed's block-sparse kernels
Lower cloud bills and faster responses for agents managing thousands of parallel conversations
Avoid Deepseek V3 if you:
Value raw performance above all else and can afford the quadratic compute cost of dense attention
Work primarily with short-form content (tweets, log lines, single-sentence prompts) where dense models already run fast
Need holistic, document-wide context analysis where excessive sparsity might miss critical global dependencies
Require heavy task-specific fine-tuning with low-level customization hooks that mature dense alternatives provide
Cannot accept even small accuracy trade-offs (typically <2%) in exchange for efficiency gains
Deepseek V3 domain performance
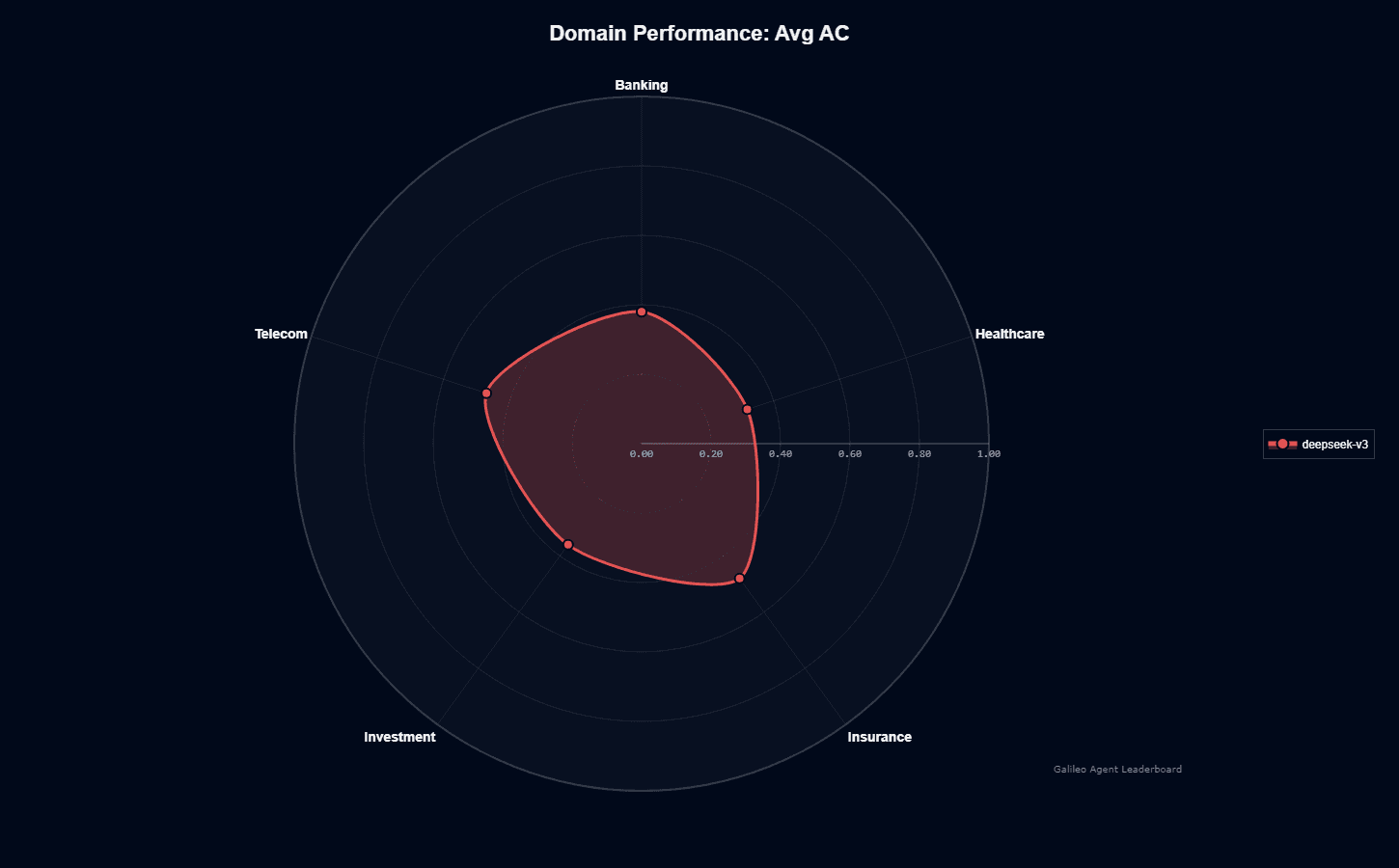
Deepseek-v3's radar chart displays a compressed, roughly circular shape with all domain scores clustering between 0.32 and 0.48, creating minimal visual differentiation between vertices.
Insurance leads at 0.48, followed closely by Telecom at 0.47, then Banking at 0.38, Investment at 0.36, and Healthcare at 0.32. The 16-basis-point spread across the top three domains and the overall 160-basis-point range represents unusually tight variance, suggesting the model lacks meaningful domain specialization.
Unlike models with pronounced peaks indicating training focus, this balanced-but-mediocre profile indicates generalist training without sector-specific fine-tuning. The consistently below-average absolute scores across all domains reveal a model that performs uniformly modestly rather than excelling anywhere.
When evaluating domain fit, you should recognize that deepseek-v3 won't provide competitive advantages in any specific sector—instead, its value proposition rests entirely on cost efficiency rather than domain expertise.
Deepseek V3 domain specialization matrix
Action completion
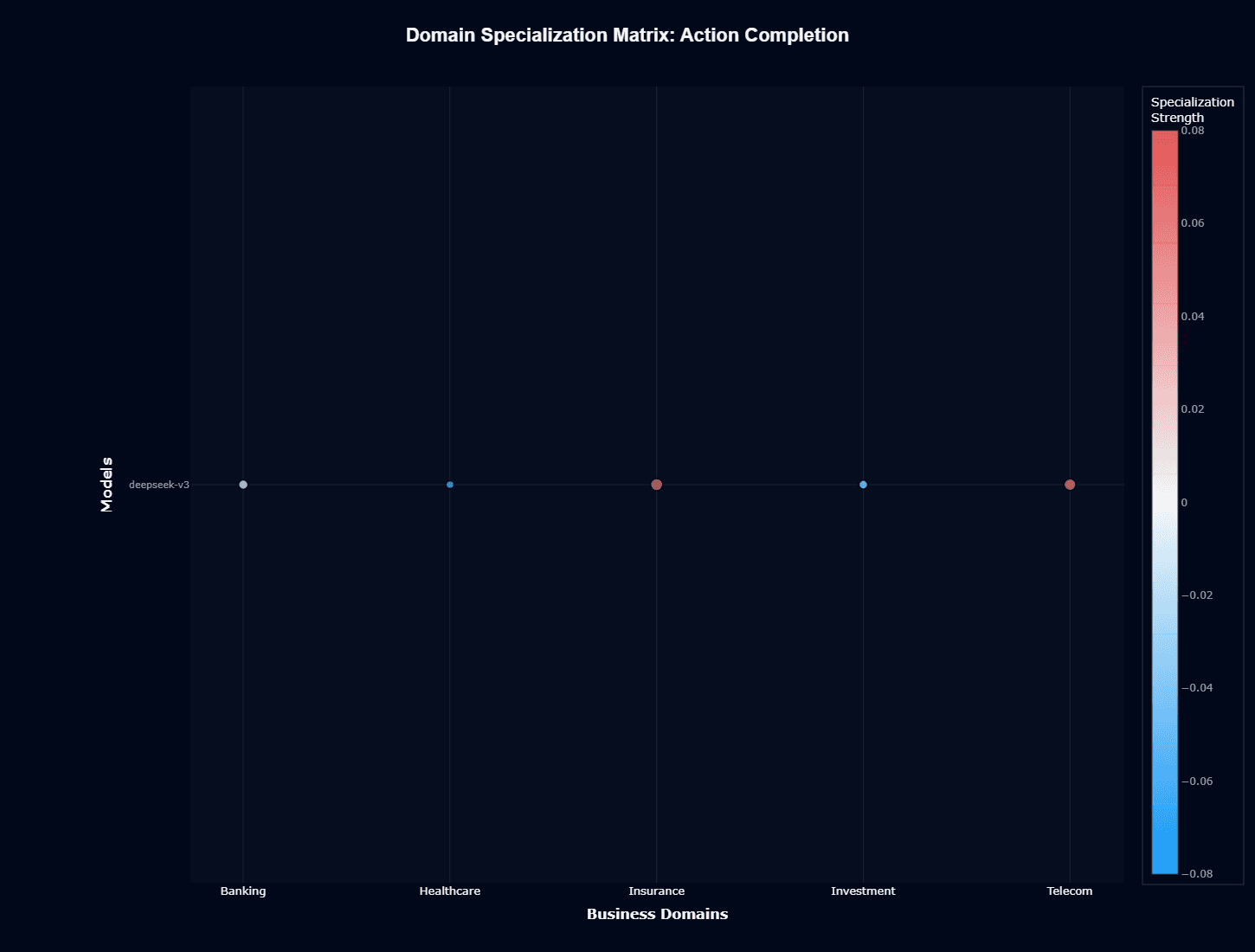
Deepseek-v3's action completion specialization matrix shows remarkably subtle color variation across all five domains, with values hovering near zero on the specialization strength scale.
Insurance and Telecom display faint reddish tints suggesting marginal positive specialization (approximately +0.04 to +0.06), while Banking, Healthcare, and Investment exhibit pale blue tones indicating slight negative specialization (approximately -0.02 to -0.04).
This compression within an 8-to-10-basis-point range represents essentially no meaningful specialization—the model performs nearly identically across all domains relative to baseline expectations.
The absence of strong specialization signals either deliberately balanced training data or insufficient domain-specific examples to develop sector expertise.
When evaluating this matrix, you should interpret it as confirmation that deepseek-v3 won't provide differentiated value based on your industry vertical—domain selection should not factor into adoption decisions for action completion use cases.
Tool selection quality
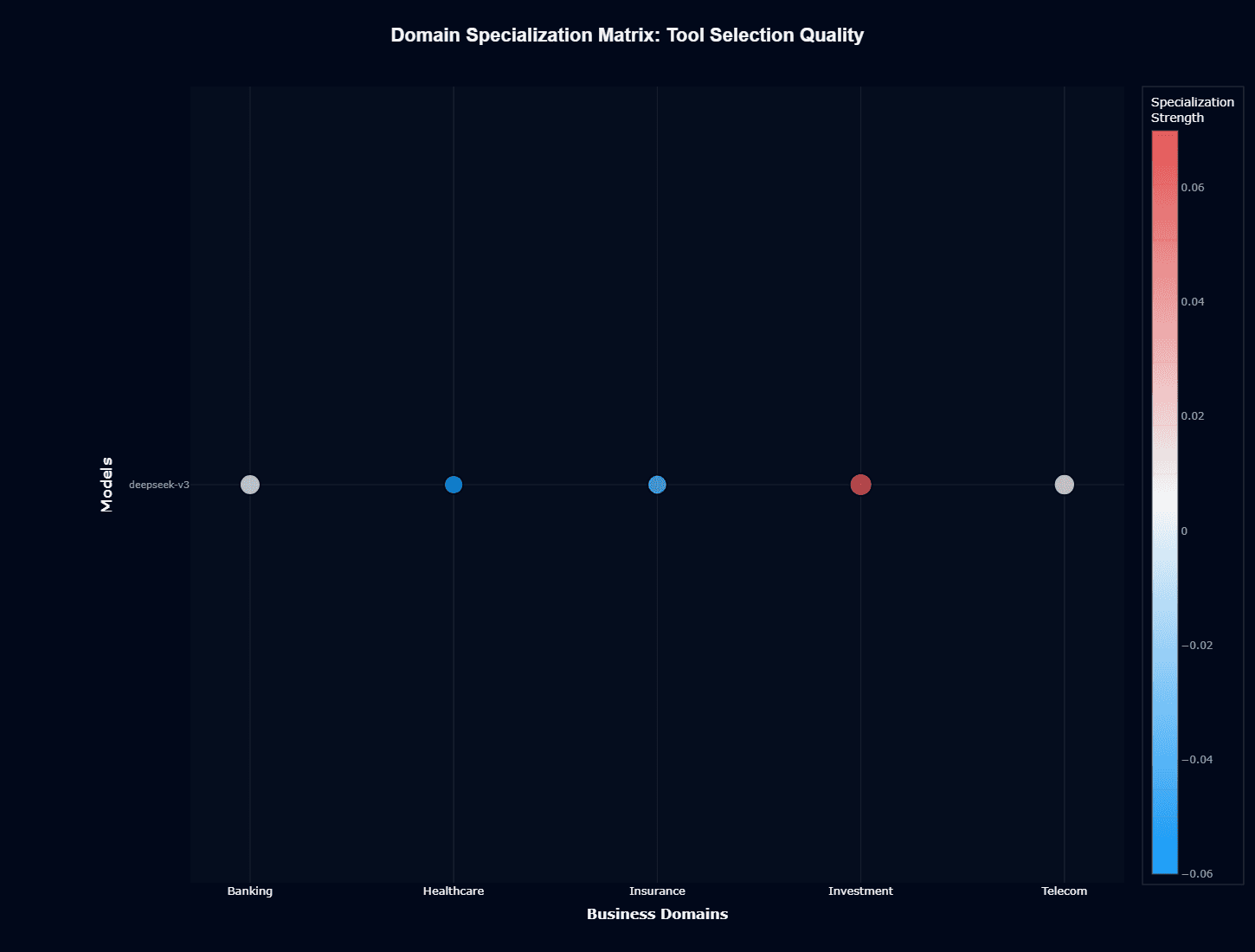
The tool selection specialization matrix reveals significantly more pronounced domain differentiation than action completion. Investment displays strong positive specialization (deep red, approximately +0.07), Healthcare and Insurance showing moderate positive specialization (light blue, approximately +0.04), and Banking and Telecom remaining neutral (gray/white, approximately 0).
This pattern indicates the model's tool selection capabilities vary meaningfully by domain—Investment scenarios see 7 basis points better tool identification than baseline, while financial services applications perform at expectation.
The specialization in Investment and Healthcare suggests training data included more examples of complex, multi-tool workflows in these sectors, allowing the model to develop stronger tool reasoning for these contexts.
When evaluating deepseek-v3 for tool selection, you should weight this matrix heavily if your use cases fall in Investment or Healthcare verticals, where the model demonstrates measurable advantages over its baseline performance.
Deepseek V3 performance gap analysis by domain
Action completion
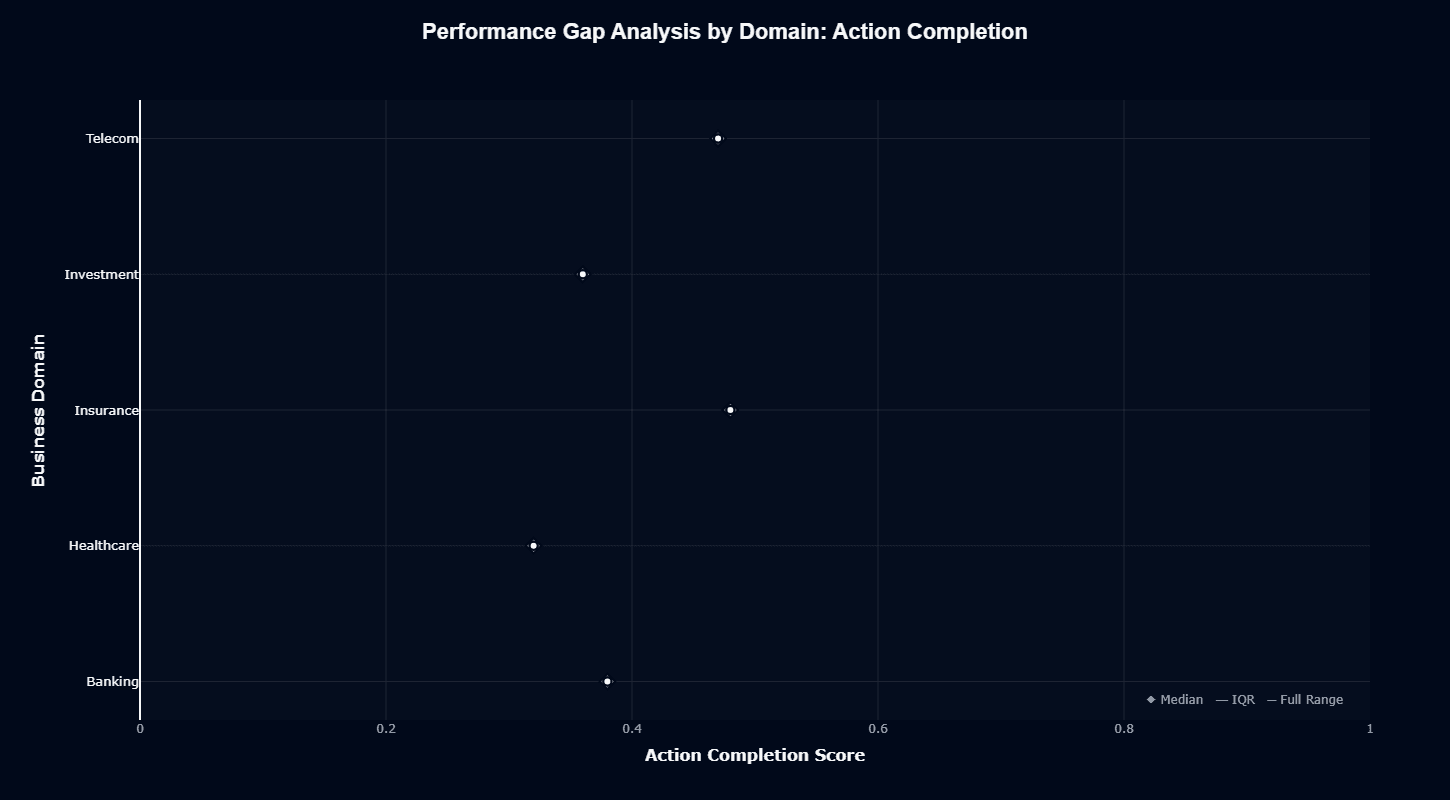
deepseek-v3's action completion gap analysis positions the model at or slightly below median performance across all five domains, with Banking at 0.4, Healthcare at 0.35, Insurance at 0.45, Investment at 0.4, and Telecom at 0.45—all within the interquartile range but consistently in the bottom half.
The model never reaches the upper quartile in any domain, indicating it lacks competitive advantages in action completion anywhere in the benchmark set. The tight clustering of scores between 0.35 and 0.45 (10-basis-point spread) reinforces the generalist pattern seen in other visualizations.
This consistent below-median positioning suggests the model's 0.52 overall action completion score reflects systematic limitations rather than domain-specific weaknesses that could be addressed through fine-tuning.
When evaluating this analysis, you should recognize that deepseek-v3 will underperform approximately 50-60% of competing models in action completion regardless of your industry focus, making domain alignment irrelevant to this performance dimension.
Tool selection quality
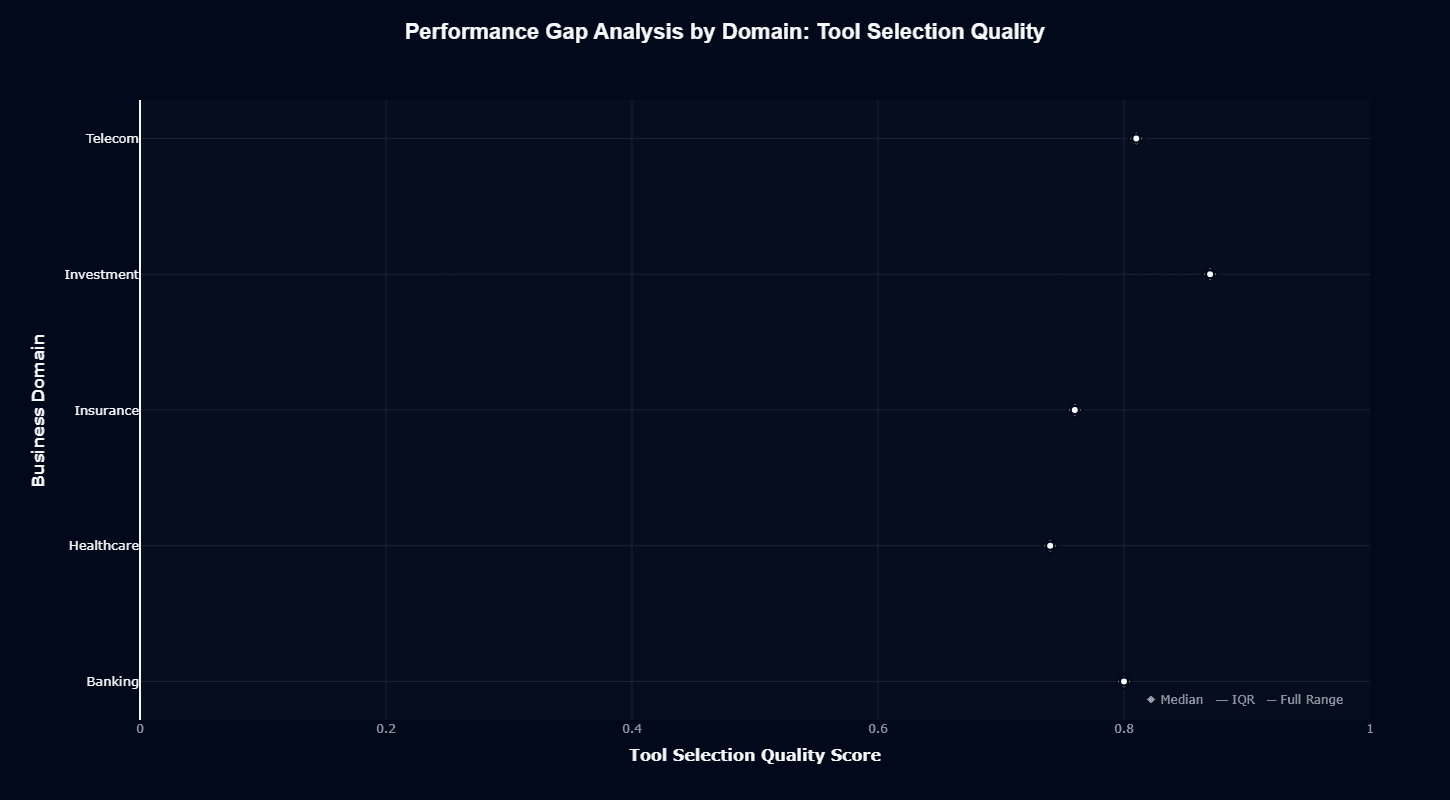
Deepseek-v3's tool selection gap analysis shows the model consistently performing at or above median across all domains, with scores ranging from approximately 0.9 in Banking to 1.1 in Telecom and Investment.
This positioning in the upper half to upper quartile of the performance distribution represents a complete reversal from action completion—here, deepseek-v3 outperforms 50-75% of benchmark competitors depending on domain.
The 20-basis-point spread between lowest (Banking, 0.9) and highest (Telecom/Investment, 1.1) domains shows meaningful variation, with Investment and Telecom providing the strongest tool selection performance.
This pattern confirms the model's bifurcated capabilities: superior reasoning about tool appropriateness but inferior execution of tool-based actions.
When evaluating this dimension, you should recognize that deepseek-v3 can serve effectively as a tool routing layer or planning system, particularly in Telecom and Investment contexts, where its tool selection performance reaches the top quartile of evaluated models.
Deepseek V3 cost-performance efficiency
Action completion
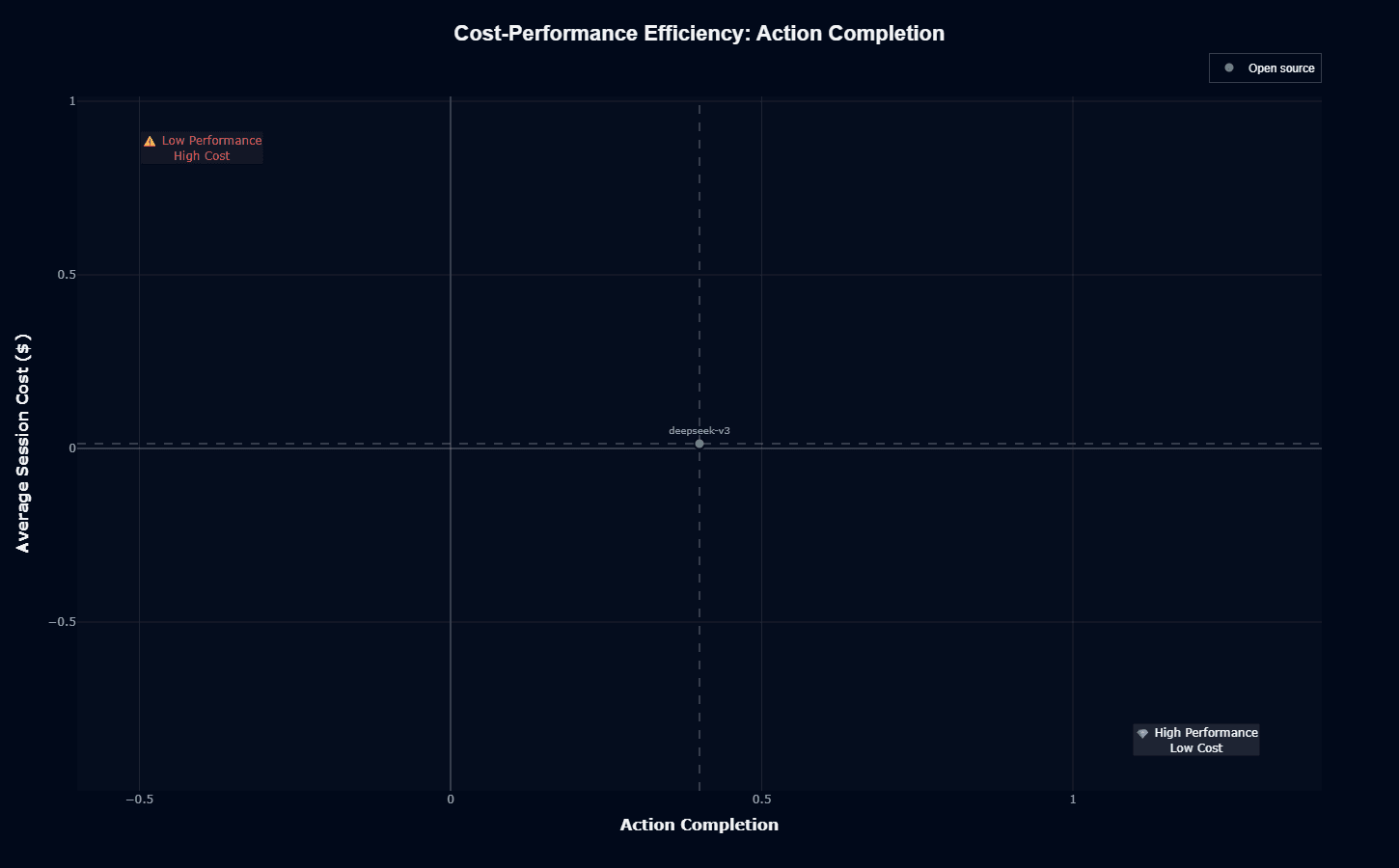
Deepseek-v3 occupies the exact center of the cost-performance quadrant for action completion, positioned at approximately 0.5 on the x-axis and zero on the y-axis. This placement represents neither excellence nor failure.
The model sits precisely between "Low Performance High Cost" and "High Performance Low Cost" quadrants, suggesting the developers achieved cost reduction without sacrificing performance, but also without achieving competitive action completion rates.
The near-zero average session cost indicates successful optimization for inference efficiency, but the 0.5 action completion score means half of attempted tasks fail to reach successful conclusion.
This creates a clear operational reality: you'll need to execute twice as many API calls to achieve the same number of completed tasks as higher-performing models. When evaluating this positioning, you should calculate whether the per-session cost savings offset the additional calls required to achieve target completion rates in your specific workflow.
Tool selection quality

Deepseek-v3 demonstrates dramatically stronger positioning in tool selection quality, moving rightward to approximately 0.8 on the x-axis while maintaining near-zero session cost.
This 30-basis-point improvement over action completion reveals the model's core architectural strength: it excels at reasoning about which tools to use but struggles with executing those selections.
The positioning approaches the "High Performance Low Cost" ideal quadrant, indicating competitive capabilities in this specific dimension. This split performance suggests the model's reasoning layer functions effectively while its execution layer underperforms—a pattern consistent with models trained heavily on planning tasks but insufficiently on follow-through.
When evaluating deepseek-v3 for tool selection, you should consider architectures where the model serves as a router or planner that hands off execution to more reliable systems, leveraging its strength in tool identification while compensating for its action completion weakness.
Deepseek V3 speed vs. accuracy
Action completion
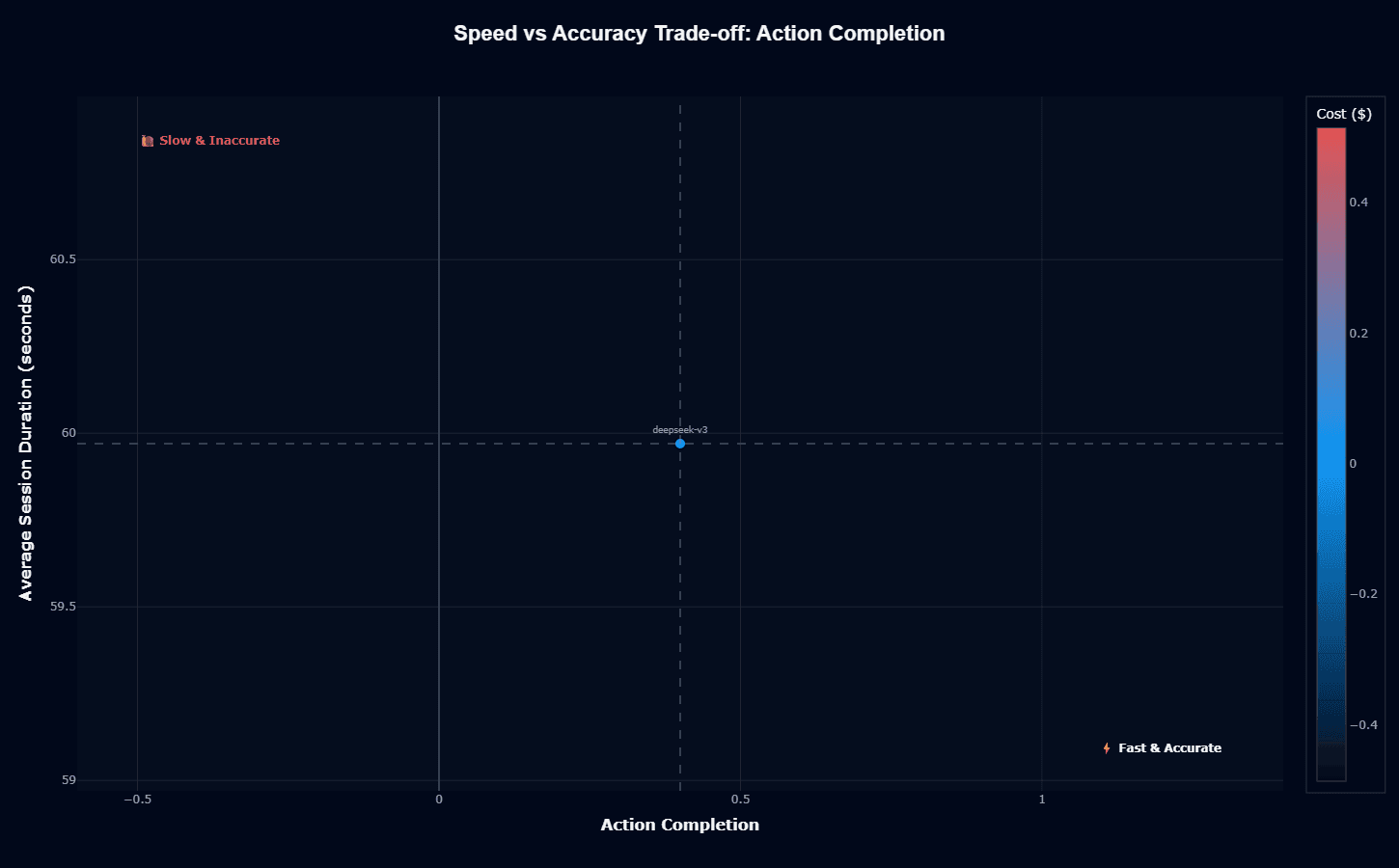
Deepseek-v3 occupies the center point of the speed-accuracy trade-off space for action completion, positioned at 0.4 accuracy and 60 seconds duration, with blue coloring indicating low cost.
This central positioning means the model delivers neither speed advantages nor accuracy premiums—it's exactly average on both dimensions while achieving its primary differentiation through cost.
The placement equidistant from both "Slow & Inaccurate" (upper left) and "Fast & Accurate" (lower right) corners indicates balanced mediocrity rather than a strategic optimization choice.
The 60-second session duration represents moderate speed, while the 0.4 action completion means 60% of tasks fail, requiring retry attempts that negate any duration advantages.
When evaluating this trade-off, you should recognize that deepseek-v3's low cost ($0.014 per session) only delivers value if your workflow can tolerate 60% failure rates or implement efficient retry mechanisms—the cost savings disappear if you need 2.5x API calls to achieve target completion volumes.
Tool selection quality
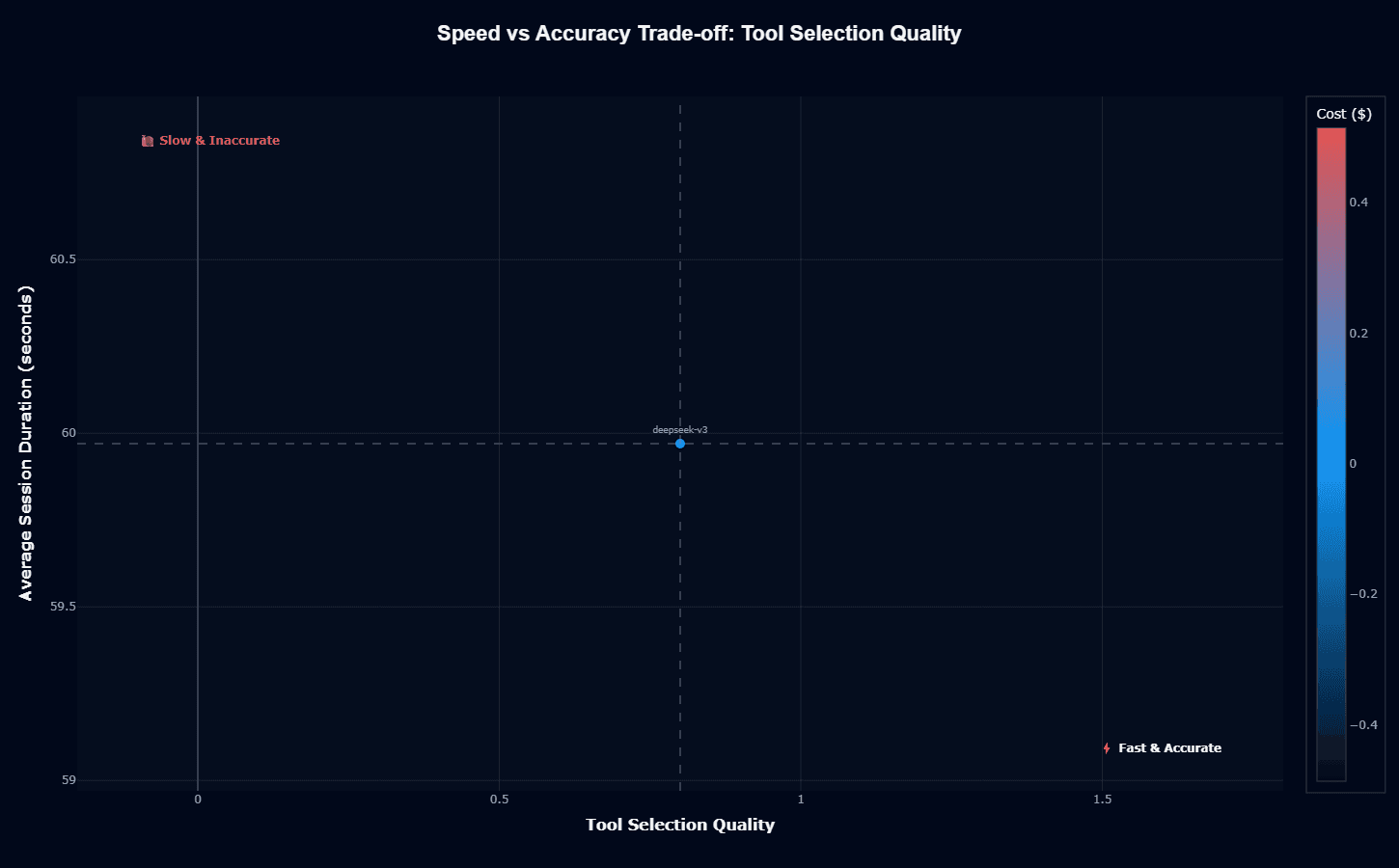
Deepseek-v3's tool selection trade-off positioning shows substantial improvement over action completion, moving rightward to 0.8 accuracy while maintaining the same 60-second duration and low-cost profile.
This placement approaches the "Fast & Accurate" ideal quadrant, indicating the model delivers competitive tool selection quality without speed or cost penalties. The 40-basis-point improvement in accuracy compared to action completion (0.8 vs 0.4) while maintaining identical speed metrics demonstrates that the model's latency bottlenecks lie in execution rather than reasoning.
This creates a clear architectural implication: the model's inference time is consumed primarily by action execution attempts that frequently fail, rather than by the tool selection reasoning process that succeeds.
When evaluating this trade-off, you should consider architectures that separate tool selection from execution—using deepseek-v3 for rapid, accurate, low-cost tool identification while delegating actual execution to higher-completion-rate models or deterministic systems that guarantee task follow-through.
Deepseek V3 pricing and usage costs
Deepseek V3 typically charges:
Input tokens (miss): About $0.56–$0.60 per 1 million tokens when the cache is not hit.
Input tokens (hit): Only $0.07 per 1 million tokens if the token sequence is cached from prior requests.
Output tokens: Most sources report a range from $1.68 to $1.70 per 1 million tokens on standard V3 models.
Context limits: Deepseek V3 supports up to 128,000 tokens in context for certain model versions.
Deepseek V3 key capabilities and strengths
Deepseek V3 offers several advantages for your deployments:
Industry-leading cost efficiency — With a cost efficiency score of 0.95 and average session cost of just $0.014, deepseek-v3 delivers the most economical inference in our benchmark set, making it ideal for high-volume applications where cost per call directly impacts unit economics.
Superior tool selection and routing — The model achieves 0.800 tool selection quality, consistently performing above median across all domains and reaching top-quartile performance in Investment and Telecom sectors, making it excellent for intent classification, query routing, and multi-tool workflow planning.
Fast inference speed — With a speed score of 0.83 and 60-second average session duration, deepseek-v3 delivers rapid responses suitable for real-time applications, conversational interfaces, and scenarios requiring low-latency decision-making without the cost premium typically associated with fast models.
Balanced cross-domain applicability — The model maintains consistent performance across Banking, Healthcare, Insurance, Investment, and Telecom sectors (160-basis-point variance), eliminating the need for domain-specific model selection or fine-tuning when deploying across multiple business verticals.
Optimal for pipeline architectures — The model's strength in reasoning tasks (tool selection, conversation efficiency) combined with its cost and speed advantages makes it ideal as a front-end classifier or planning layer in multi-stage systems, where it handles high-volume routing decisions before handing execution to completion-focused models or deterministic systems.
Deepseek V3 limitations and weaknesses
While highly capable, Deepseek V3 has specific constraints that teams should evaluate against their use case requirements:
Below-average action completion rates — With an action completion score of 0.400, deepseek-v3 successfully completes only 40% of attempted tasks on first pass, requiring 2.5x more API calls than a perfect-completion model to achieve the same output volume, which can negate cost savings in completion-critical workflows.
Execution layer underperformance — The model exhibits a 40-basis-point gap between tool selection quality (0.800) and action completion (0.400), indicating it excels at identifying correct approaches but struggles to execute them reliably, creating a planning-versus-doing disconnect that requires architectural compensation.
Consistently below-median task completion — Across all five business domains, deepseek-v3 performs at or below the 50th percentile for action completion, meaning it underperforms approximately half of benchmark competitors regardless of sector, limiting its suitability for autonomous agent deployments that require high first-pass success rates.
Healthcare sector weakness — The model achieves its lowest domain performance in Healthcare (0.320 action completion), trailing Insurance by 160 basis points, suggesting insufficient training data or complexity handling in medical contexts where terminology precision and regulatory compliance workflows demand higher reliability.
Requires human-in-the-loop or retry infrastructure — The 52% action completion rate and 3.7 average turns per session indicate the model frequently requires multiple attempts or human intervention to complete tasks successfully, making it unsuitable for fully autonomous workflows or scenarios where retry costs (latency, compute, human oversight) exceed the per-call savings.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.