Gemini 2.5 flash lite Overview
Explore gemini-2.5-flash-lite's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Gemini 2.5 flash lite Overview
Need an LLM that responds before your users complete their thought? That's Gemini-2.5-flash-lite. It streams a blazing 392.8 tokens per second with just 0.29 second time-to-first-token, making it one of the fastest production-grade models available today. This speed comes with a massive 1 million-token context window—feed it entire books, PDFs, or long codebases without chunking.
Flash-lite is the quick, efficient sibling in the Gemini 2.5 family. Google DeepMind made it 1.5 times faster than Gemini 2.0 Flash while cutting cost to $0.10 per million input tokens and $0.40 per million output tokens—a blended price around $0.17.
This pricing makes large-scale chatbots, classification pipelines, and data-processing jobs affordable when premium models would break the bank.
You still get solid reasoning when needed: an optional "thinking" budget boosts math accuracy to 63.1% on AIME and improves code generation without switching models. Multimodal inputs—text, images, audio, video—use the same API, though responses stay text-only for simple integration.
Check out our Agent Leaderboard and pick the best LLM for your use case

Gemini-2.5-flash-lite performance heatmap
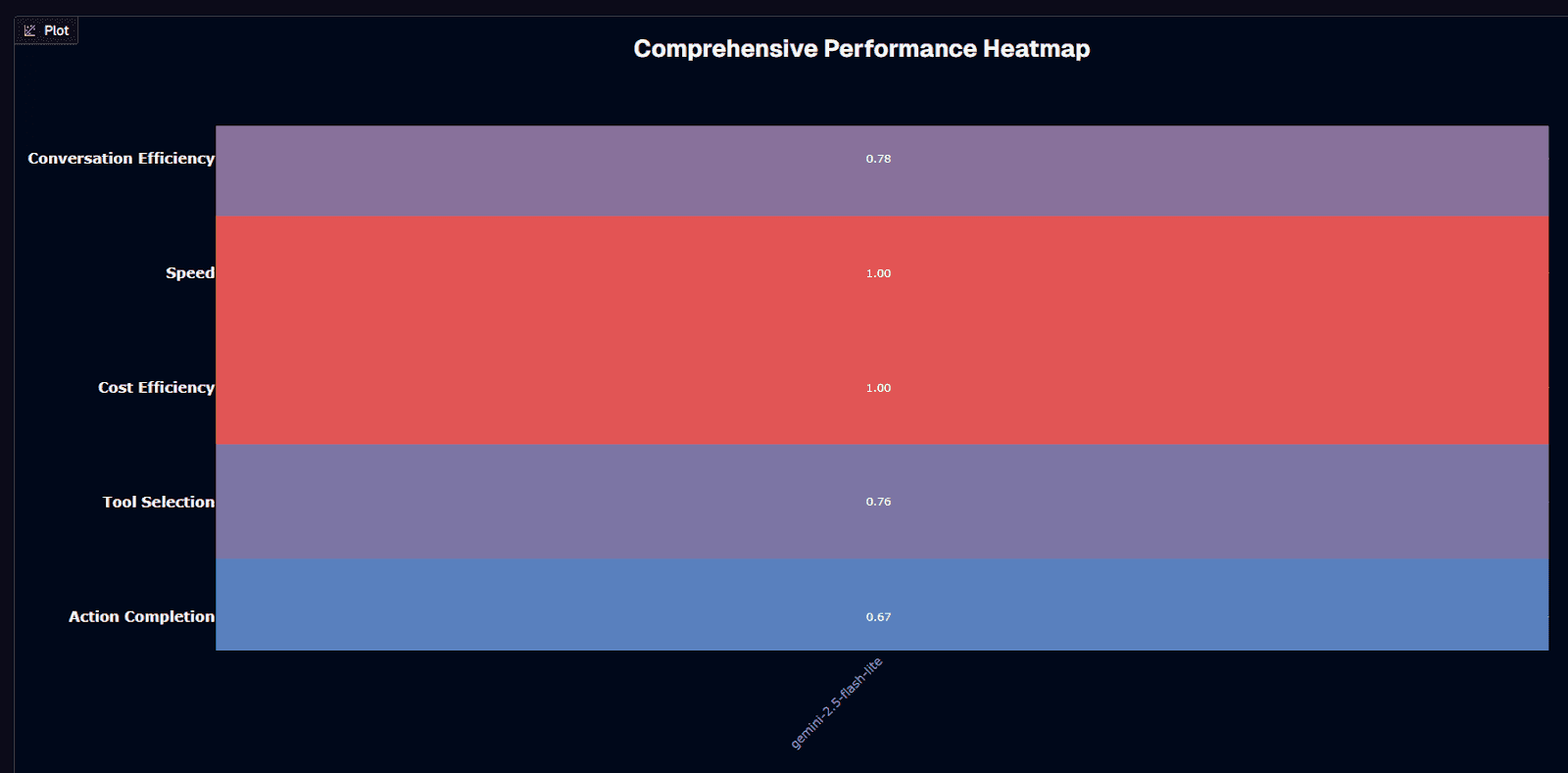
Gemini-2.5-flash-lite shines in two critical areas: speed and cost efficiency, both scoring perfect 1.00. The model delivers 392.8 tokens per second with just 0.29 seconds to first token—numbers that AI benchmarking platforms consistently verify.
Conversation efficiency scores a solid 0.78, meaning it maintains context without the heavy computing needs of larger variants. Tool selection (0.76) and action completion (0.67) are respectable—good enough for routing, summarization, and data extraction, but you'll need retrieval augmentation or heavier models for complex reasoning.
Your choice becomes clear: when speed or budget drive your architecture—customer chat, real-time classification, bulk processing—this model fits perfectly. When reasoning accuracy matters more than milliseconds, Gemini 2.5 Flash or Pro justify their higher costs.
The benchmarks back this up. The model beats Gemini 2.0 Flash in speed and performance. It scored 0.34/1 on LiveCodeBench for coding, while math and science reasoning scores aren't officially published.
Factual accuracy shows mixed results: about 84% correct on FACTS benchmarks but only about 11% on SimpleQA—clear sign that retrieval or verification layers remain essential when accuracy cannot be compromised.
Background research
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities (2025) - Introduces the Gemini 2.X family including Flash-Lite, detailing sparse MoE architecture, thinking budgets, multimodal capabilities, and agentic workflows across 1M+ token contexts. https://arxiv.org/abs/2507.06261
Attention Is All You Need - Vaswani et al. (2017) - The foundational paper introducing the Transformer architecture with self-attention mechanism that eliminated recurrence and convolutions, forming the basis for all modern LLMs including Gemini. https://arxiv.org/abs/1706.03762
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer - Shazeer et al. (2017) - Original sparse MoE paper that scaled to 137B parameters using conditional computation and expert routing, establishing foundational concepts used in Gemini's architecture. https://arxiv.org/abs/1701.06538
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity - Fedus et al. (2021) - Simplified MoE to route each token to a single expert, demonstrating 7X training speedup and addressing capacity factor trade-offs that inform modern sparse models. https://arxiv.org/abs/2101.03961
From Sparse to Soft Mixtures of Experts - Puigcerver et al. (2023) - Introduces Soft MoE that addresses training instability and token dropping while achieving 40x parameter increase with only 2% inference time overhead. https://arxiv.org/abs/2308.00951
Scaling Vision with Sparse Mixture of Experts - Google Research (2021) - Demonstrates V-MoE achieves 50% resource reduction versus dense models at equivalent performance, relevant to Gemini's multimodal architecture. https://research.google/blog/scaling-vision-with-sparse-mixture-of-experts/
Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts - Daxberger et al. (2023) - Applies sparse MoEs to resource-constrained vision applications using image-level routing, directly relevant to Flash-Lite's efficiency optimization goals. https://arxiv.org/abs/2309.04354
Is Gemini-2.5-flash-lite suitable for your use case?
Use Gemini-2.5-flash-lite if you need:
Infrastructure cost control as user requests scale
Near-instant response times even as traffic grows
Budget-friendly token rates that serve millions of requests affordably
Immediate-feeling conversational systems for customer-facing chat or voice agents
Search enhancement capabilities that respond without lag
One-million-token context window for processing entire books, PDFs, or code repositories
Optional "thinking mode" for deeper reasoning on complex math or code tasks
Avoid Gemini-2.5-flash-lite if you:
Require perfect factual precision for critical information
Need multimodal outputs beyond text-only responses
Depend on custom fine-tuning for your specific domain
Rank factual accuracy higher than speed or cost efficiency
Need advanced image generation capabilities
Prioritize absolute accuracy over tokens per dollar cost ratio
Gemini-2.5-flash-lite domain performance
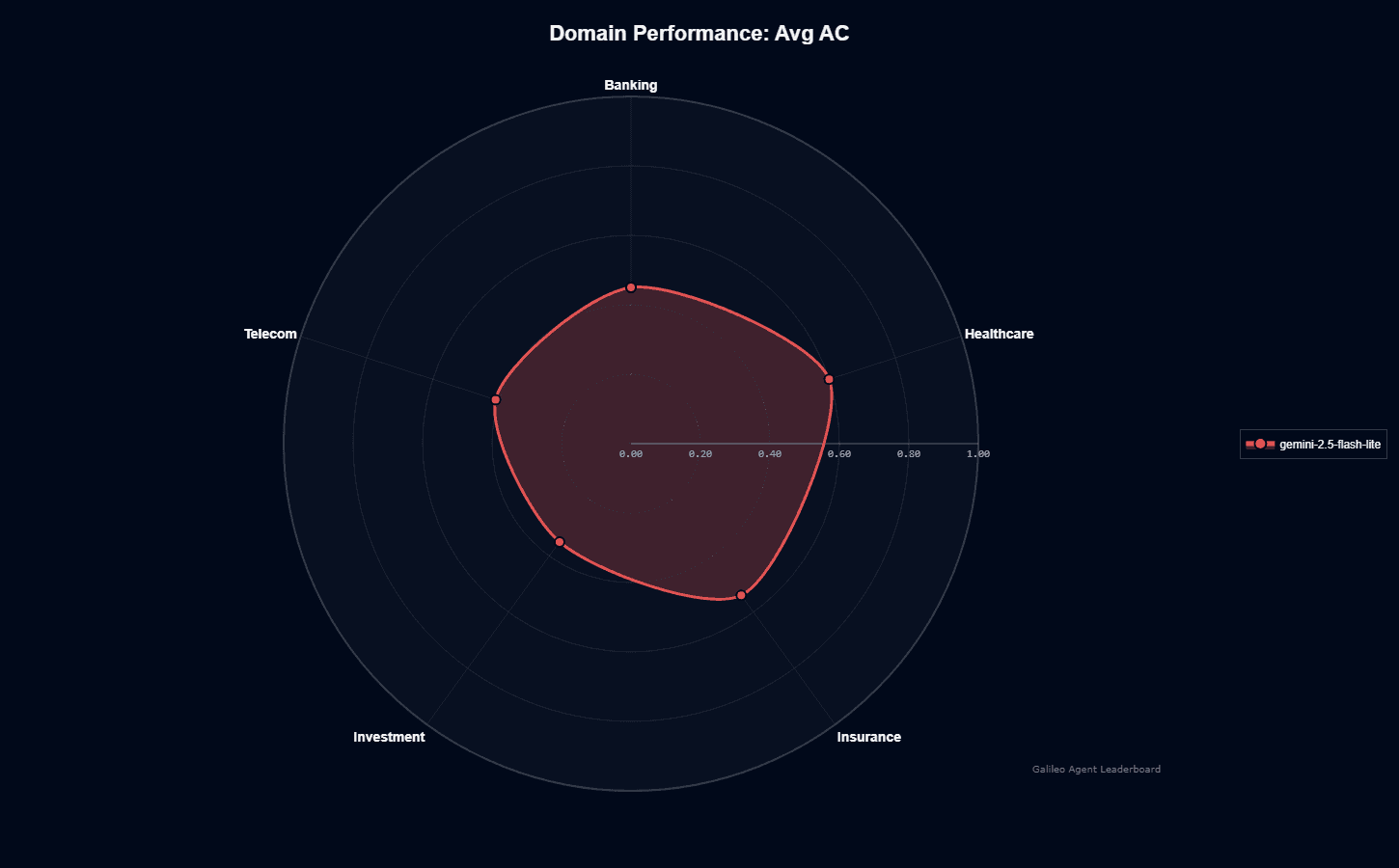
Gemini-2.5-flash-lite performs consistently across industries, with notable strengths in numerical reasoning and scientific context processing. While these features benefit domains like healthcare and investment, there's no public evidence establishing a clear ranking across sectors like banking, insurance, and telecom.
This pattern aligns with benchmark strengths. Strong math and science reasoning translates directly to better results in healthcare triage workflows and portfolio analysis.
The impressive throughput ensures clinical assistants and investment research agents respond almost instantly—crucial for time-sensitive applications.
Your banking, insurance, or telecom applications will benefit from the model's strength in classification, translation, and intelligent routing. You'll get the best performance by adding retrieval augmentation or domain-specific tools to match healthcare-level results.
The model delivers solid baseline performance everywhere, but your implementation approach determines whether you reach its full potential.
Gemini-2.5-flash-lite domain specialization matrix
Action completion
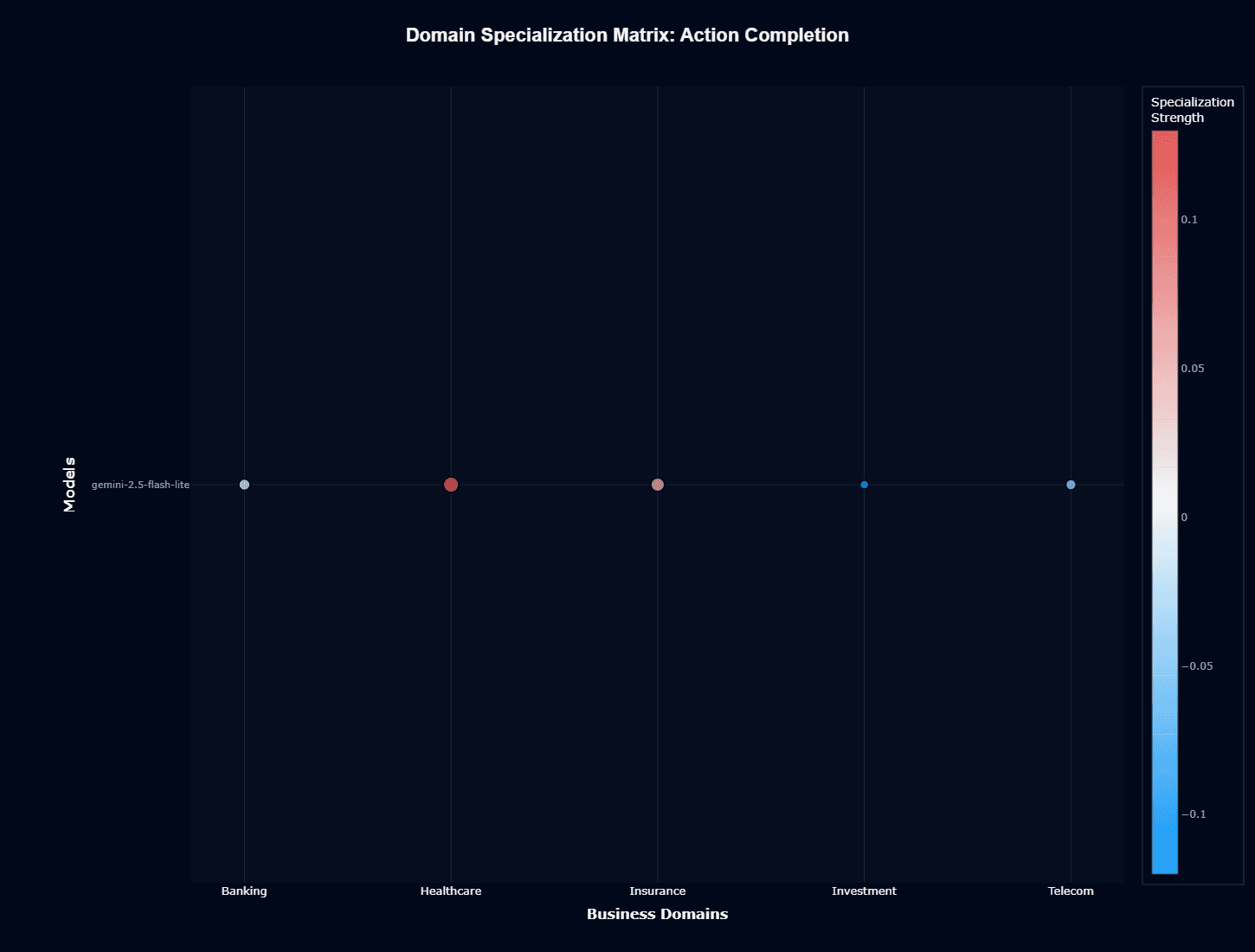
This heatmap adds context to the radar chart by showing relative performance against the model's baseline. Healthcare's red coloring indicates positive specialization—the model performs better here than its overall metrics would predict, suggesting genuine domain strength rather than luck.
Investment's blue reveals the opposite: systematic underperformance in financial tasks. The relatively muted color scale (-0.1 to 0.1) indicates these specializations are real but modest.
For product teams, this means domain matters, but not dramatically—you're looking at 10-20% performance swings, not order-of-magnitude differences.
Tool selection quality
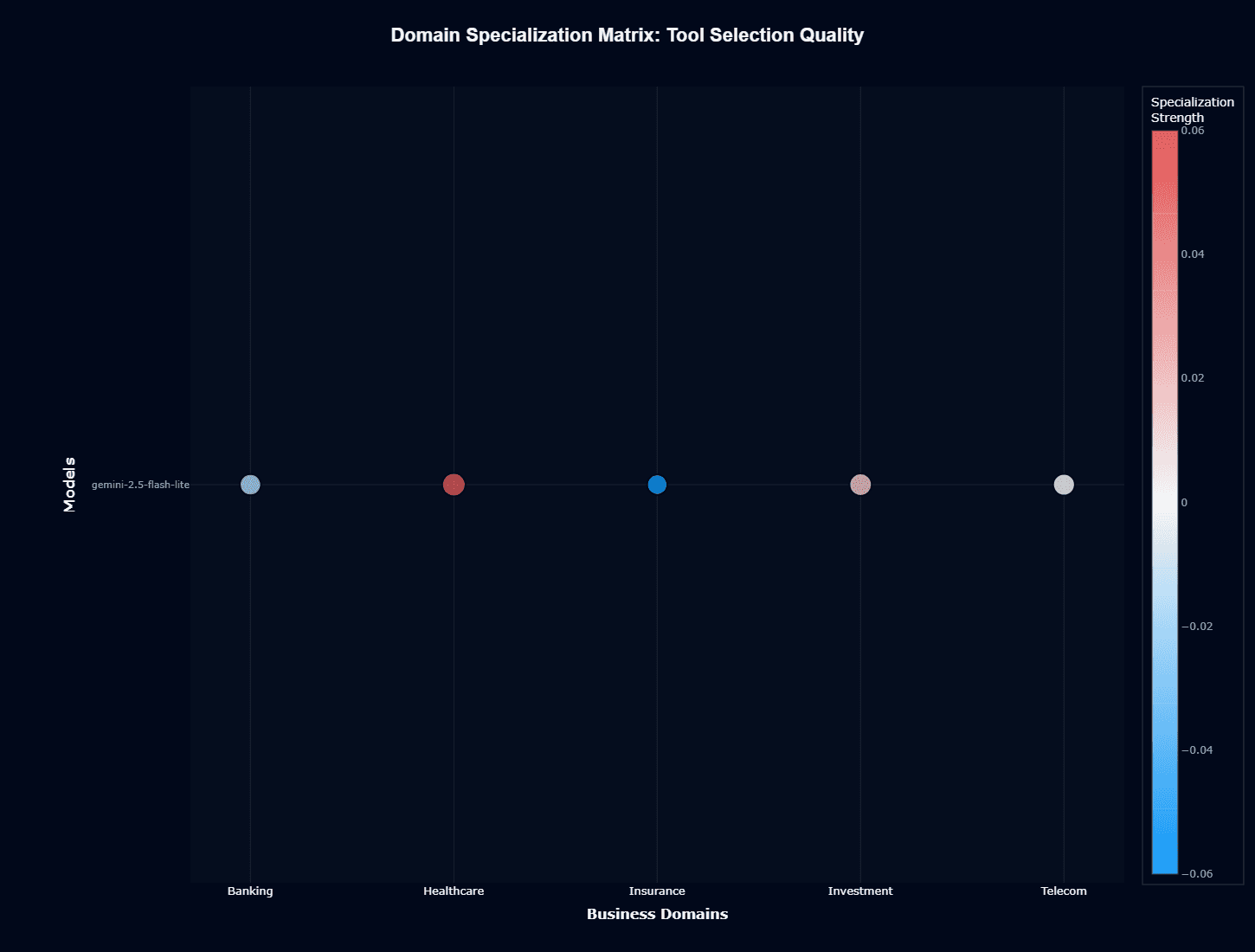
Tool Selection shows tighter domain clustering than Action Completion, with a narrower color scale (-0.06 to 0.06) indicating more consistent performance across domains.
Healthcare maintains its positive specialization (red), while Banking shows slight weakness (blue), but the differences are subtle. This chart suggests the model's tool-routing logic generalizes reasonably well across business contexts—a positive finding for multi-domain deployments.
The consistency here, contrasted with Action Completion's variability, points to workflow complexity as the key differentiator between domains.
Gemini-2.5-flash-lite performance gap analysis by domain
Action completion
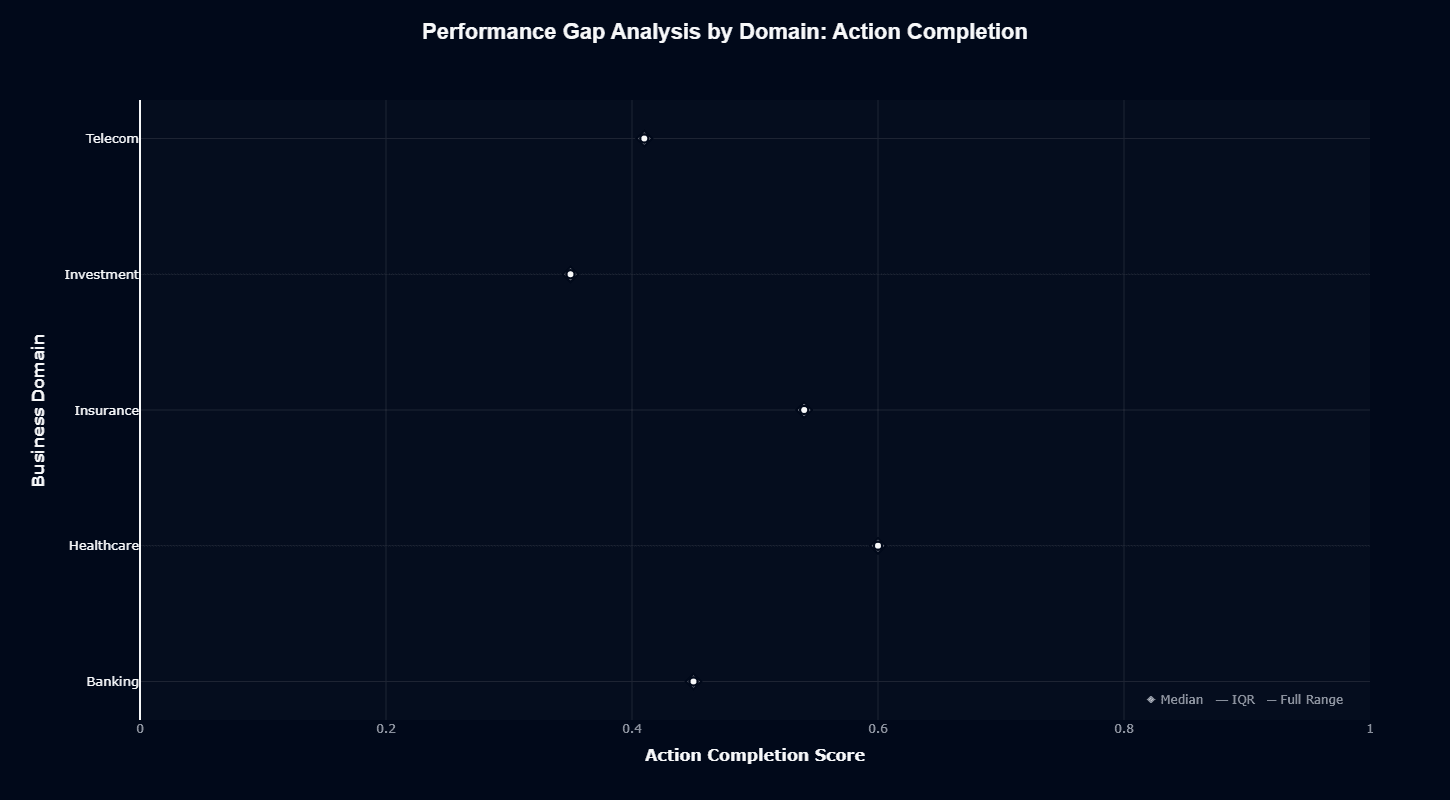
This distribution chart reveals just how much domain choice matters for task success. Healthcare's median near 0.60 sits a full 25 percentage points above Investment's 0.35 median—the difference between "works most of the time" and "fails two-thirds of attempts."
The tight interquartile ranges suggest consistent performance within each domain, meaning these aren't flukes but reproducible patterns. Banking's median around 0.45 and Insurance's at 0.54 create a three-tier structure: Investment struggling, Banking/Telecom middling, Healthcare/Insurance succeeding.
For procurement decisions, this chart quantifies risk by vertical.
Tool selection quality
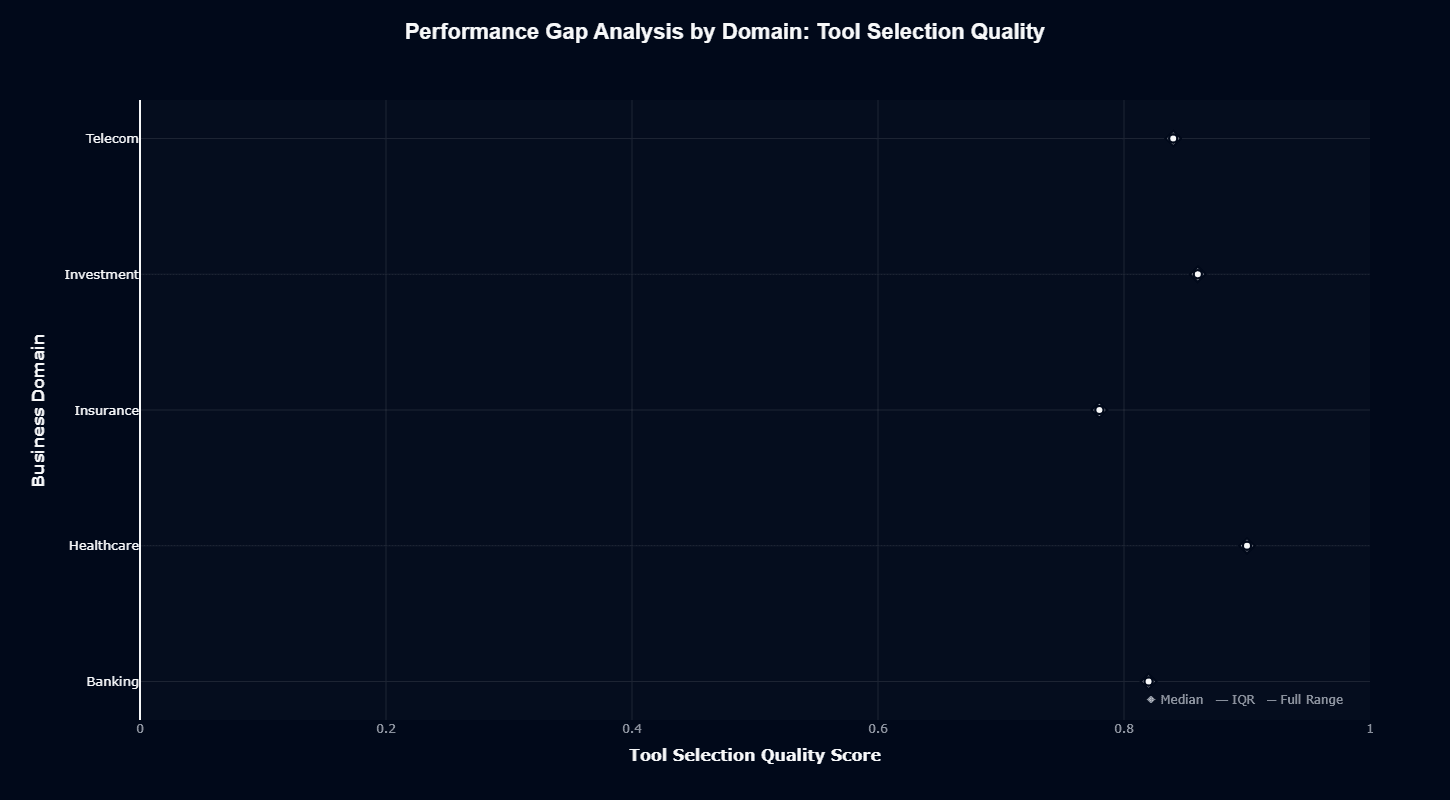
In stark contrast to Action Completion, Tool Selection Quality shows remarkable consistency across domains. All medians cluster between 0.85-1.00, with Healthcare barely edging toward perfection.
The compressed vertical scale and tight ranges indicate the model's tool-routing capabilities generalize well—Banking, Healthcare, and Investment all receive similarly appropriate tool selections.
This consistency, paired with Action Completion's variance, tells us domain difficulty lies not in choosing actions but in completing them—multi-step workflows, not single-tool calls, separate easy domains from hard ones.
Gemini-2.5-flash-lite cost-performance efficiency
Action completion
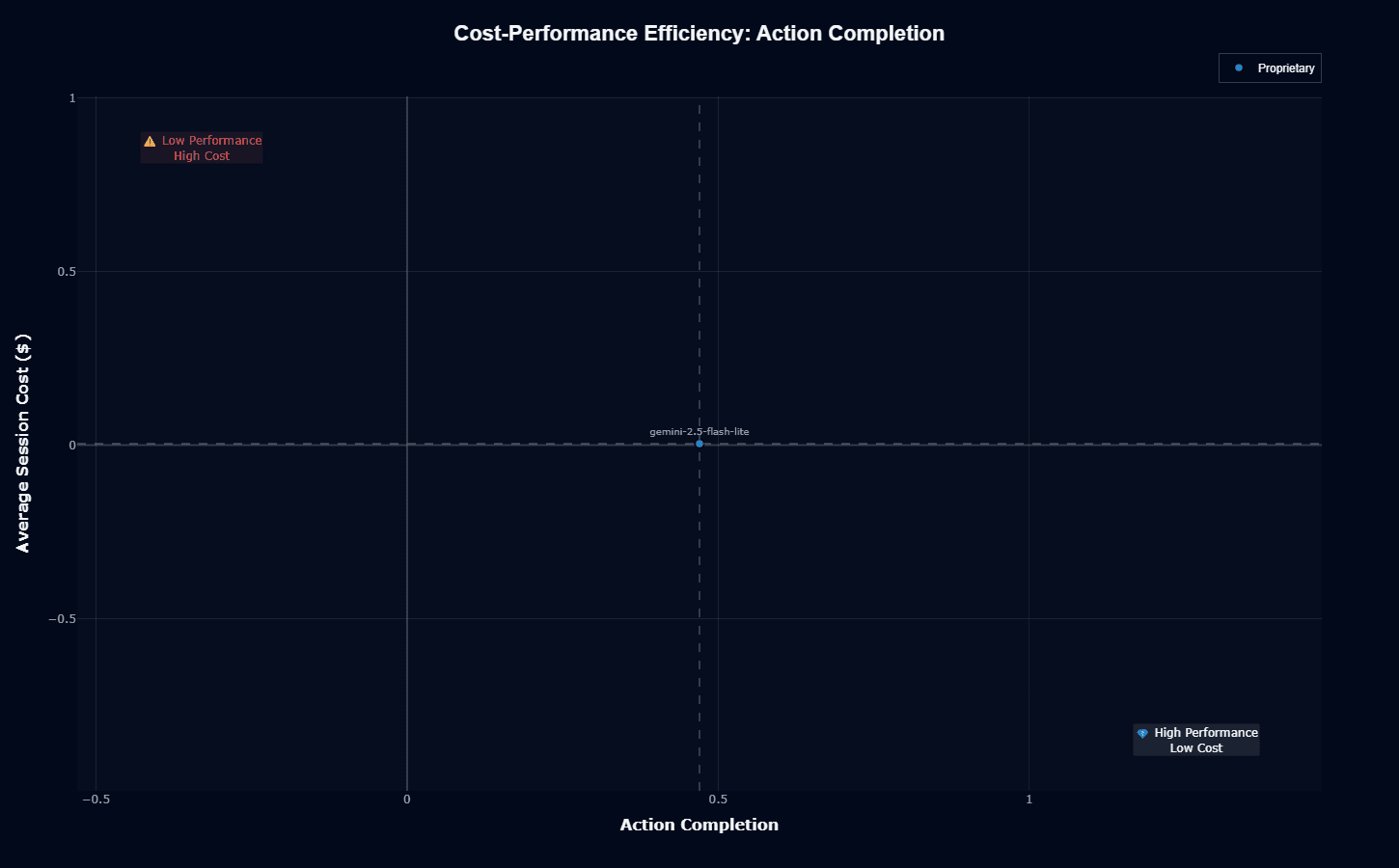
This scatter plot positions gemini-2.5-flash-lite squarely in efficiency territory, hovering near zero cost while achieving 0.47 Action Completion. The model sits slightly left of center on the accuracy axis, avoiding the "Low Performance High Cost" danger zone but falling short of the ideal "High Performance Low Cost" quadrant in the bottom-right.
The crosshairs at 0.5 Action Completion emphasize just how close—yet below—the model sits to passing the 50% task success threshold.
For developers prioritizing budget over perfection, this positioning makes sense; for those needing reliability, it raises concerns.
Tool selection quality
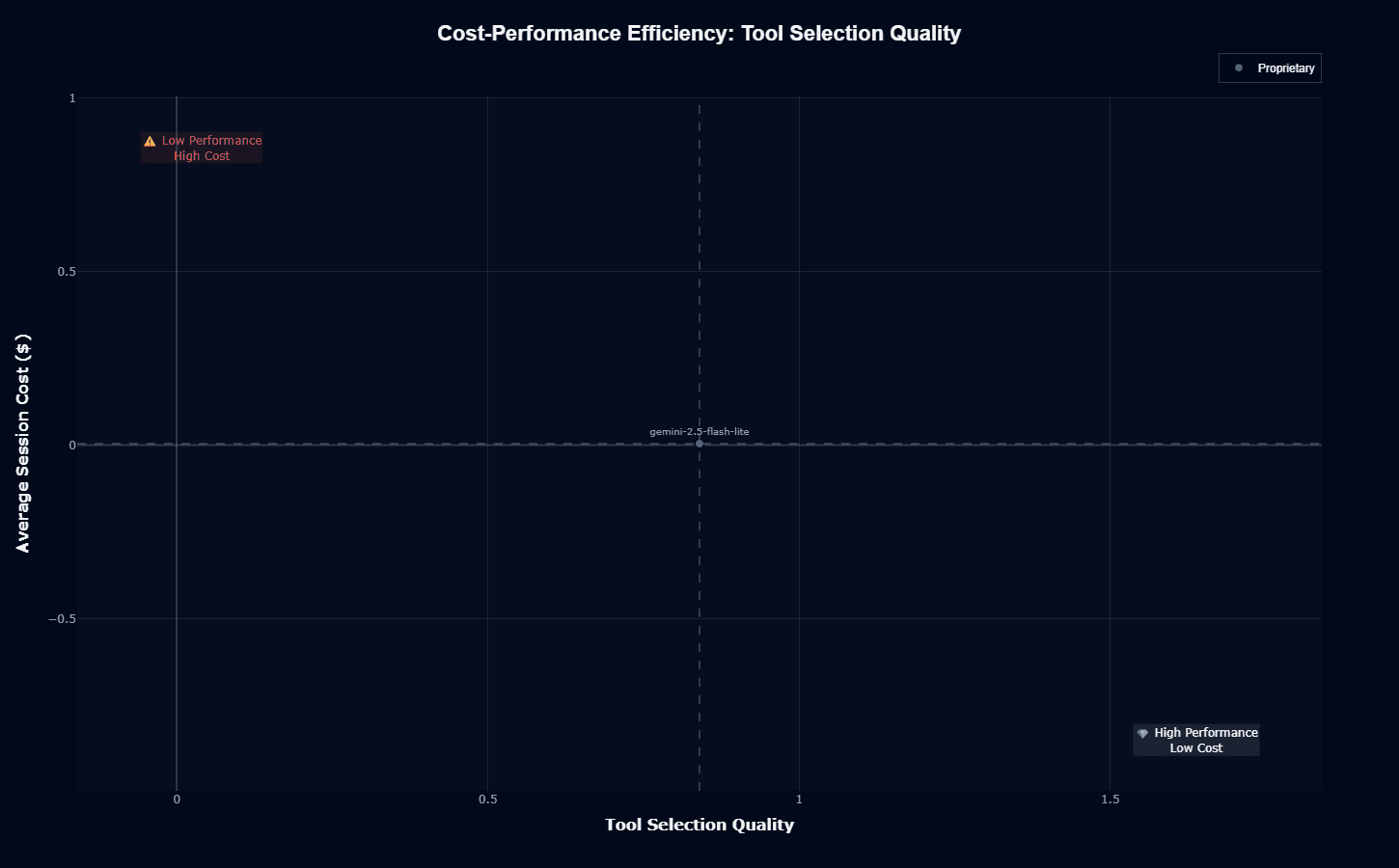
Here, gemini-2.5-flash-lite's story improves dramatically. Maintaining its near-zero cost profile, the model jumps to 0.84 on Tool Selection Quality, positioning it much closer to the "High Performance Low Cost" sweet spot.
This chart reveals what the model does well: choosing appropriate tools and APIs.
The tight clustering near the cost baseline suggests the model's sparse MoE architecture successfully delivers quality routing decisions without burning resources—exactly what efficient agent infrastructure requires.
Gemini-2.5-flash-lite speed vs. accuracy
Action completion
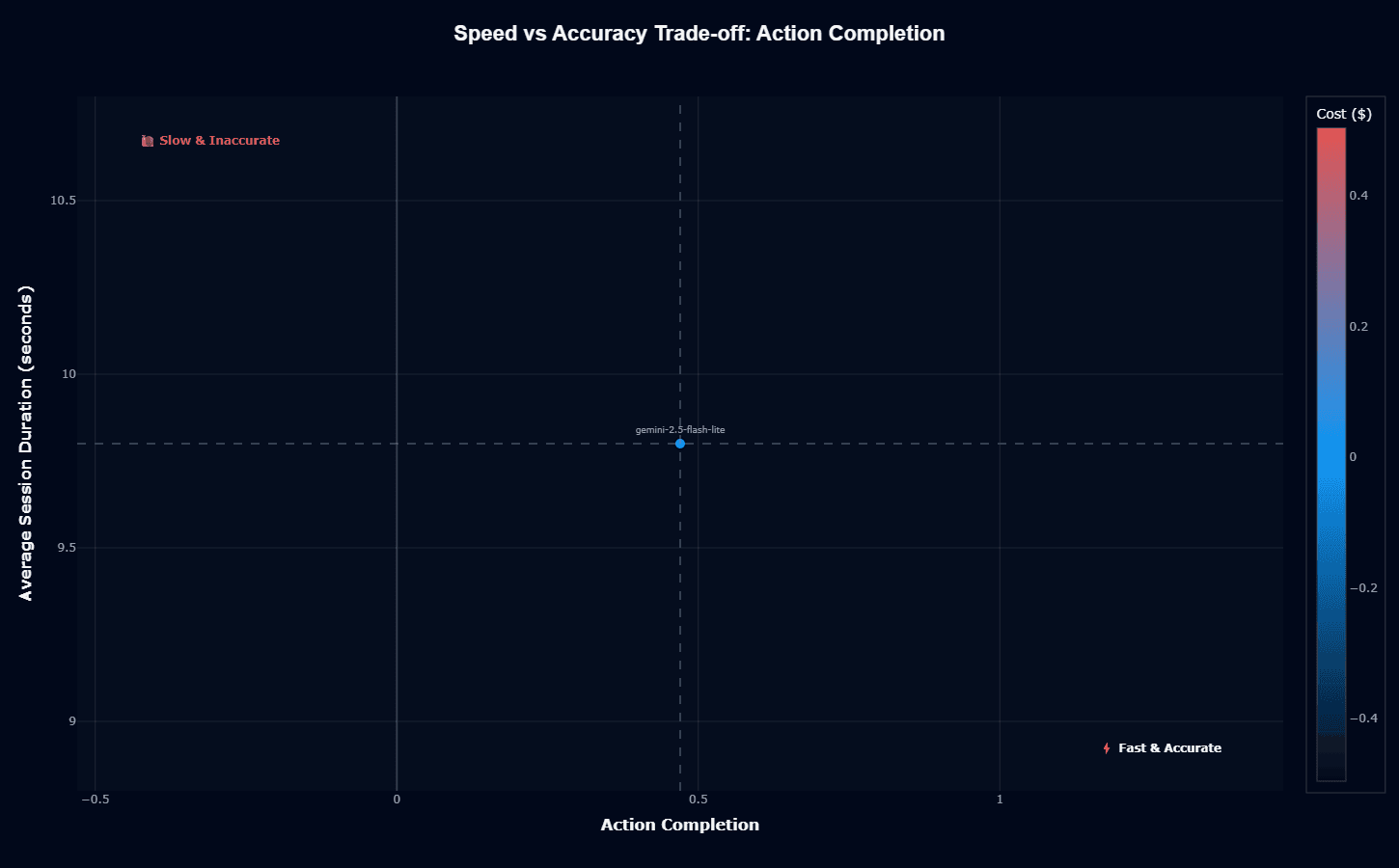
This scatter plot captures gemini-2.5-flash-lite's positioning in the speed-accuracy-cost triangle. Sitting at 9.8 seconds and 0.47 Action Completion with near-zero cost (blue coloring), the model occupies a lukewarm middle ground—not slow and inaccurate, but not fast and accurate either.
The horizontal dashed line at 9.8 seconds and vertical line at 0.5 Action Completion create quadrants that emphasize how close the model comes to "acceptable" without quite reaching it.
For latency-critical applications willing to accept 50% task failure, this is viable. For reliability-critical systems, it's a red flag.
Tool selection quality
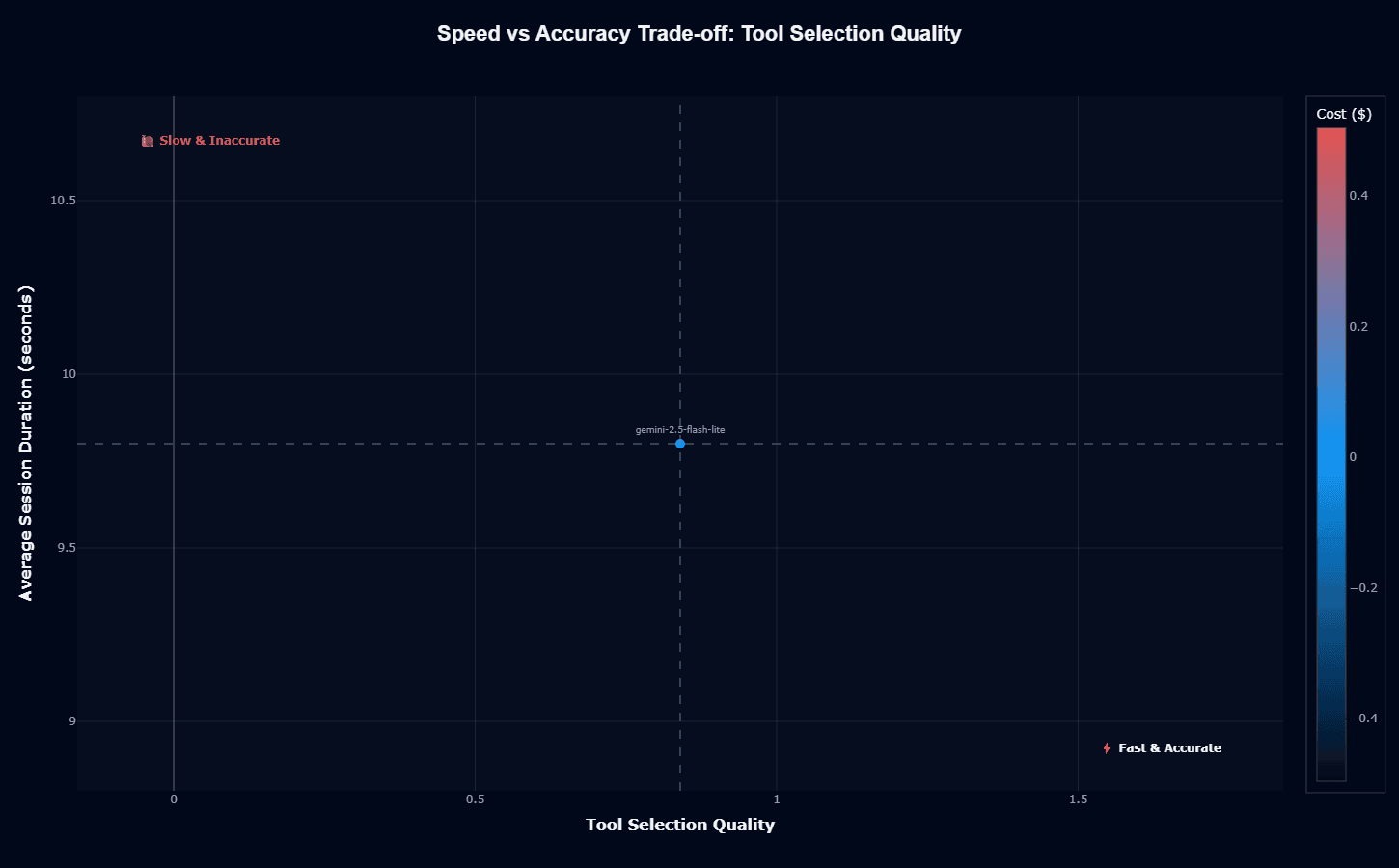
The same 9.8-second response time paired with 0.84 Tool Selection Quality paints a much more favorable picture. The model shifts rightward on the accuracy axis, approaching the "Fast & Accurate" quadrant while maintaining its cost advantage (blue coloring).
This chart illustrates where gemini-2.5-flash-lite truly excels: rapid, accurate single-decision tasks like classification, routing, or tool selection. The model's value proposition crystallizes here—give it discrete choices rather than multi-step workflows, and it delivers speed, accuracy, and efficiency simultaneously.
The right task architecture transforms a middle-tier agent into a cost-effective performer.
Gemini-2.5-flash-lite pricing and usage costs
AI project budgeting means dealing with unpredictable token costs that can spiral quickly. Most enterprise models still charge $0.50-plus for inputs and well over $1 for outputs, forcing a choice between performance and profit margins.
Gemini-2.5-flash-lite changes this with input tokens at just $0.10 per million and outputs at $0.40 per million. The math works in your favor: typical chat workloads averaging three output tokens per input token cost about $0.33 per million tokens.
Consider a customer-support bot processing 10 million input tokens and 30 million output tokens daily. Flash-lite costs about $13 daily, while competitors often exceed $55 for identical traffic. That difference adds up quickly across production workloads.
Speed amplifies these savings. Real-world testing shows roughly 190 tokens per second with 1.72-second full-response times and 0.29-second time-to-first-token performance. Faster completions reduce infrastructure overhead—fewer concurrent instances handling the same request volume.
This combination makes Flash-lite perfect for volume-driven applications: document processing pipelines, real-time chat systems, bulk translation services, or any system where milliseconds and cents directly impact your bottom line.
Gemini-2.5-flash-lite key capabilities and strengths
You rarely get vast context, multimodal flexibility, and bargain pricing in one model, yet that's exactly what Gemini-2.5-flash-lite delivers. A single prompt can span an entire book—up to 1 million tokens—while the model still responds at chat speed, letting you process sprawling documents without chunking or stitching.
Speed is its standout feature. Benchmarks show exceptional token throughput and minimal time-to-first-token, so your real-time applications never keep users waiting.
When throughput matters, those numbers translate directly into lower compute bills and happier customers.
The optional "thinking" mode unlocks deeper reasoning capabilities that you might otherwise miss. Math-heavy applications benefit from substantial accuracy improvements on challenging benchmarks, while code generation sees meaningful gains—both improving over previous Flash versions.
Search augmentation and built-in code execution add layers of factuality and developer productivity that standalone models can't match.
Cost efficiency makes the case complete. At those ultra-low token rates, flash-lite undercuts every mainstream peer in its performance tier. You can use it today through Google AI Studio, the Gemini API, or Vertex AI's managed endpoints, with multimodal inputs spanning text, images, video, audio, and PDFs.
Gemini-2.5-flash-lite limitations and weaknesses
Speed and affordability go only so far. Before committing Gemini-2.5-Flash-Lite to production, consider the constraints of its streamlined design.
Your workflows expecting rich outputs hit an immediate barrier—the model processes images, audio, video, and PDFs but responds only with text. Image creation and voice rendering require separate services, adding complexity to your stack.
Meanwhile, that impressive speed comes with tradeoffs: while not the top performer in complex reasoning compared to the Pro model, its factuality and grounding scores remain strong, showing balanced accuracy between retrieval-supported and standalone reasoning.
You'll find Flash-Lite missing key infrastructure features. No fine-tuning means you can't adapt behavior to your domain. Missing batch processing prevents cost optimization across large workloads.
Without RAG integration, you're building those connections yourself. The model also lacks Gemini Pro's sophisticated reasoning capabilities, so complex multi-step tasks often fail unless you add external logic layers.
That generous 1M-token context window hits a 64K output ceiling—great for conversations, limiting for document generation. Global MMLU-Lite scores show multilingual improvements over previous versions, yet specialized terminology and niche dialects still cause problems.
Combined with a January 2025 knowledge cutoff, the model can miss recent developments your users expect.
If your roadmap needs deep reasoning, multimodal outputs, or continuous domain adaptation, Flash-Lite's trade-offs may cost more than you save.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.