Gemini 2.5 Pro overview
Explore Gemini 2.5 Pro's tool selection benchmarks, cost-performance tradeoffs, and domain-specific capabilities to determine if it's the right agent model for your application's requirements.

Gemini 2.5 Pro overview
Need an agent model that handles extended conversations without losing context? That's Gemini 2.5 Pro. It achieves 0.64 Conversation Efficiency on our Agent Leaderboard—the highest among its metrics—while delivering 0.860 Tool Selection Quality. At $0.145 per session, it costs 72% less than Claude Sonnet 4.5.
Gemini 2.5 Pro is Google's flagship multimodal model. Context window? 1 million tokens, expanding to 2 million. Architecture? Sparse Mixture-of-Experts routing to specialized experts. Average session runs 125.8 seconds across 3.6 turns.
This makes multi-turn support agents work. Analyzing entire codebases. Processing videos, images, and documents in one request. Troubleshooting sessions spanning dozens of exchanges.
You get coding performance at 63.8% on SWE-Bench Verified. Chain-of-thought reasoning for complex problems. Multimodal inputs without preprocessing overhead. The tradeoff? Action completion sits at 0.430. Insurance workflows complete 54% of tasks. Investment workflows drop to 31%—a 23-point gap showing domain brittleness.

Gemini 2.5 Pro performance heatmap
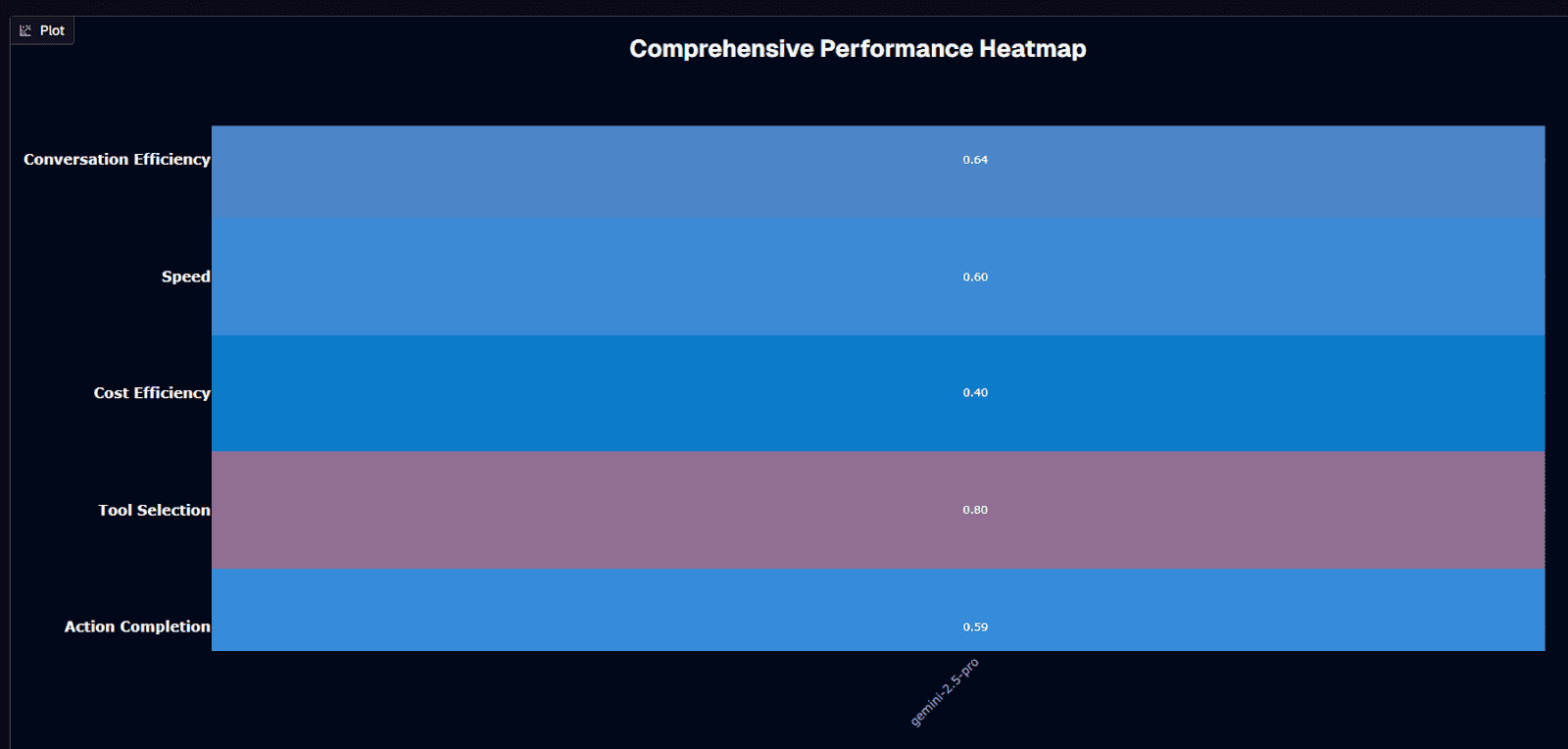
Gemini 2.5 Pro shows strength in two areas: conversation efficiency and tool selection. Conversation Efficiency scores 0.64, the highest metric. The 1M token context window keeps conversations coherent across extended interactions.
Tool Selection hits 0.80. That 0.860 absolute score means roughly 14% of tool selections miss. Comparable to mid-tier alternatives, below the 0.94+ scores of budget models.
Speed lands at 0.60 with 125.8-second average session duration. Mid-range at 3.6 turns per conversation. Throughput sits between fast models and reasoning-heavy alternatives.
Action Completion sits at 0.59 (0.430 absolute). Domain variance matters. Insurance workflows complete at 54%. Investment drops to 31%. The model handles straightforward tasks better than complex multi-step workflows requiring specialized domain knowledge.
Cost Efficiency creates the biggest gap at 0.40. At $0.145 per session, pricing runs 72% below Claude Sonnet 4.5 but 7-10× above budget alternatives like GLM-4.5-Air. Mid-tier economics.
The tradeoff: conversational quality and context retention cost more. Workflows needing extended reasoning benefit from the 1M token window. Workflows prioritizing cost efficiency or maximum action completion need different models.
Background research
Multi-source performance validation: Data synthesized from Google DeepMind model cards, Galileo's Agent Leaderboard v2, and SWE-Bench Verified benchmarks. Cross-validates results across evaluation frameworks.
Production-focused testing: Benchmarks measure production failures—tool selection errors, multi-step orchestration breaks, domain-specific brittleness—rather than academic rankings.
Core metrics: Action completion rates (multi-step task success), tool selection quality (API/function accuracy), cost efficiency (dollars per operation), conversational efficiency (context maintenance).
Documented gaps: All claims cite evaluation sources. Google reports safety improvements over Gemini 1.5 Pro, with marginal image-to-text safety regressions. No third-party verification for some provider metrics.
Is Gemini 2.5 Pro suitable for your use case?
Use Gemini 2.5 Pro if you need:
Extended context maintenance across multi-turn workflows: 1 million token context window handles comprehensive conversation histories without truncation. Essential for customer support, document analysis, and troubleshooting spanning dozens of interactions.
Native multimodal processing: Accepts text, code, images, audio, and video as inputs without preprocessing. Reduces pipeline complexity for workflows combining multiple data types.
Balanced tool selection with conversational depth: 0.860 Tool Selection Quality combined with 0.64 Conversation Efficiency. Routes to correct APIs while maintaining context across complex reasoning chains.
Strong coding and reasoning capabilities: 63.8% on SWE-Bench Verified benchmark. Advanced chain-of-thought processing surfaces explicit reasoning chains for debugging multi-step technical problems.
Mid-tier cost tolerance: Processing 100 million tokens monthly costs $48,000 annually versus $164,250 for GPT-4o—71% savings while maintaining stronger conversational performance than budget alternatives.
Avoid Gemini 2.5 Pro if you:
Require maximum action completion rates: The model scores 0.430 on action completion—below 50% task success. Mission-critical workflows requiring high first-attempt reliability face completion gaps requiring architectural workarounds.
Deploy in specialized domains without validation: Performance variance spans 23 points between Insurance (0.540) and Investment (0.310). Healthcare sits at 0.400, Telecom at 0.440. Domain-specific testing becomes mandatory before production deployment.
Prioritize pure cost efficiency: At $0.145 per session, pricing runs 7-10× higher than budget alternatives like GLM-4.5-Air. High-volume deployments processing millions of simple tool calls face significant cost differences.
Need fastest possible response times: 125.8-second average session duration with 3.6 turns per conversation. Speed-optimized models like Gemini 2.5 Flash deliver faster throughput for latency-sensitive applications.
Cannot architect around moderate completion rates: The 0.430 action completion demands robust retry logic, validation checkpoints, and fallback mechanisms. Systems requiring simple, reliable execution without error handling overhead face engineering complexity.
Gemini 2.5 Pro domain performance
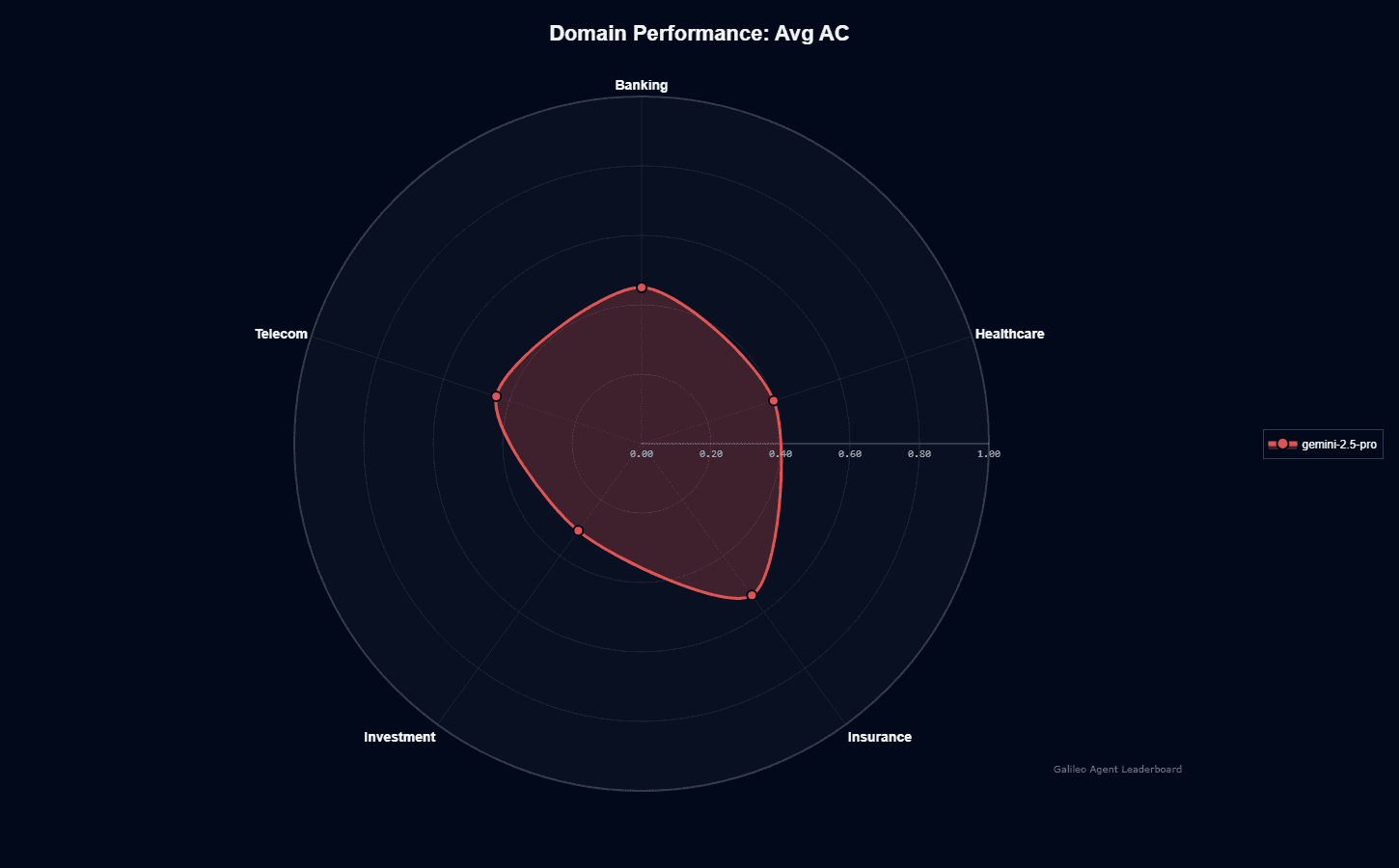
Action completion varies by domain. Insurance leads at 0.540, the highest performance across all verticals. Banking follows at 0.450, slightly above the model's 0.430 average.
Telecom sits at 0.440, close to baseline. Healthcare drops to 0.400, showing reduced effectiveness for medical terminology and clinical workflows.
Investment creates the biggest problem. Performance drops to 0.310—the lowest across all domains. That's a 23-point gap versus Insurance. Financial analysis and portfolio management workflows consistently underperform.
The radar chart shows uneven coverage. Insurance and Banking create a stronger profile on the upper section. Investment pulls the shape downward, revealing reproducible weakness in financial domains.
Tool selection tells a different story. All domains cluster tightly between 0.88-0.90 TSQ. The model knows which tools to call. It struggles to complete complex multi-step workflows in certain verticals.
For production planning, this variance signals a critical requirement: benchmark against your specific vertical before deploying. Published scores don't transfer between domains.
Gemini 2.5 Pro domain specialization matrix
Action completion
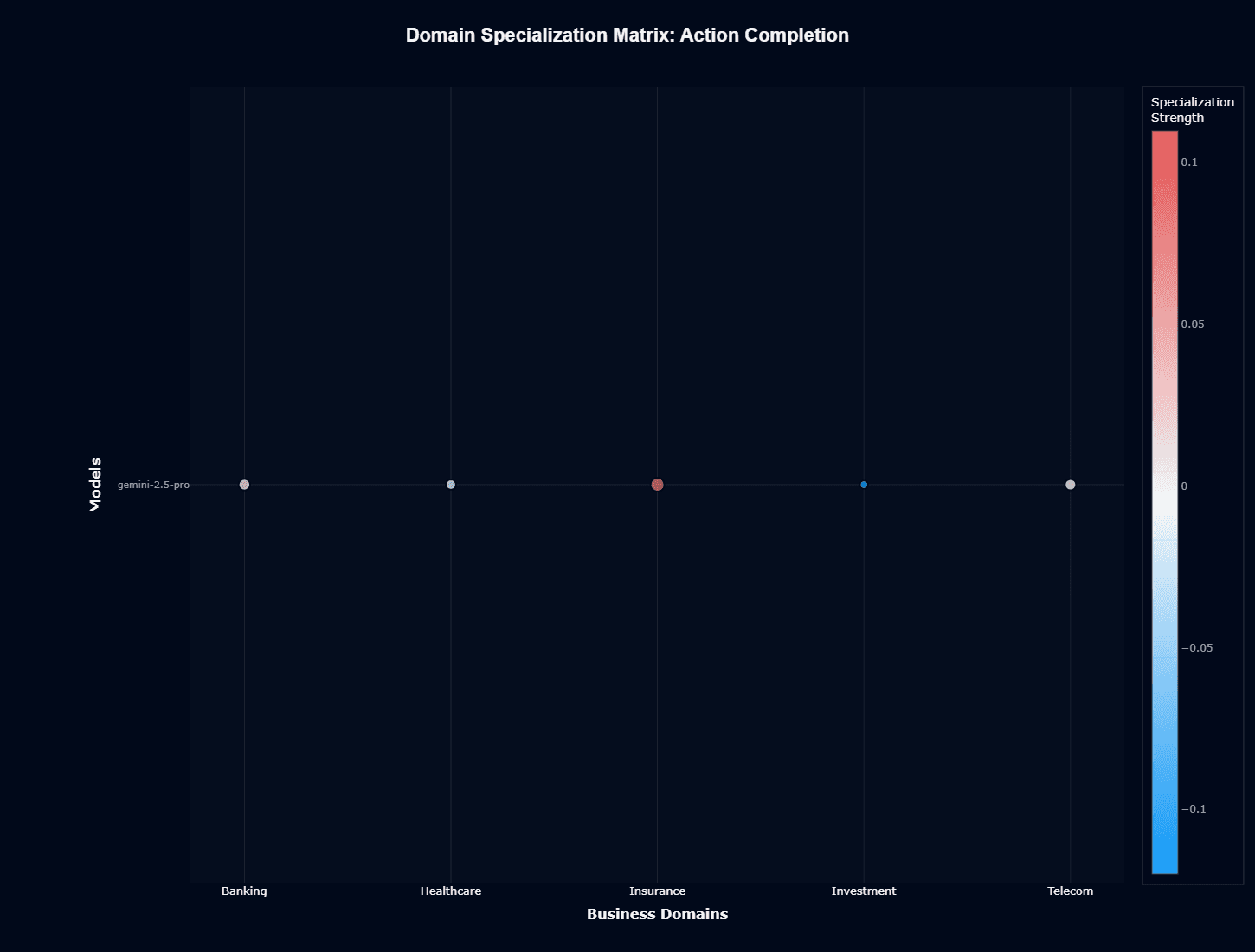
The specialization matrix reveals where Gemini 2.5 Pro shows domain preferences. Insurance appears in red—positive specialization strength of roughly 0.1. The model performs better here than baseline expectations.
Investment shows blue—negative specialization around -0.05. The model underperforms in financial analysis and portfolio management tasks beyond its general capability level.
Banking, Healthcare, and Telecom cluster near neutral (white). Performance matches baseline without significant specialization advantages or disadvantages.
This pattern indicates selective domain optimization. Insurance workflows benefit from architectural advantages. Investment workflows face consistent headwinds requiring validation and potential model alternatives.
Tool selection quality
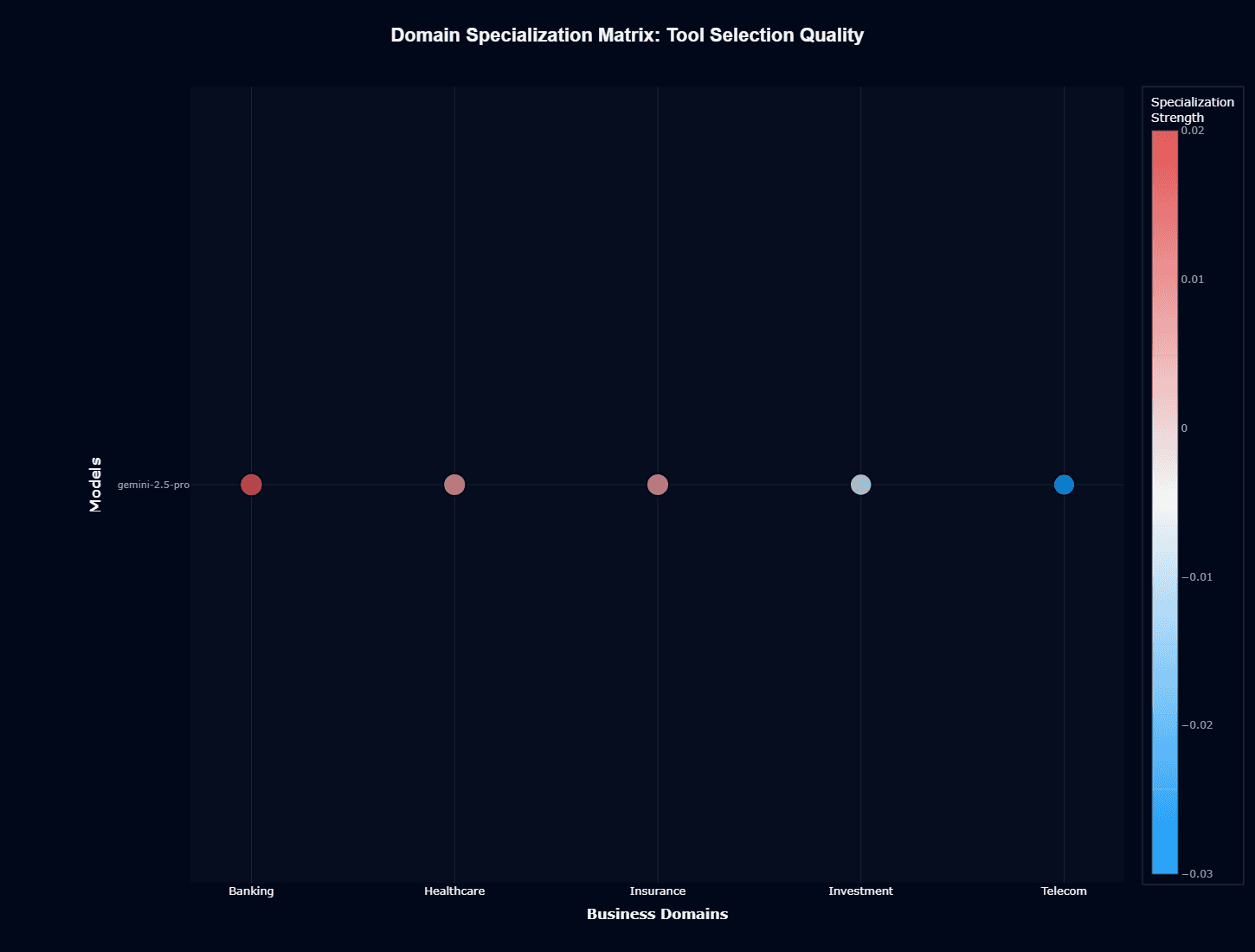
Tool selection specialization shows tighter variance. Telecom leads with slight positive specialization (blue, around 0.02). Banking, Healthcare, and Insurance cluster together with minimal specialization differences.
Investment remains neutral despite action completion weakness. The model selects correct tools in financial domains—it just struggles with multi-step execution after tool invocation.
This split matters for architecture decisions. Tool selection generalizes well across business contexts. Action completion depends heavily on domain complexity and specialized knowledge requirements.
The production implication: if your agents primarily route requests and invoke single tools, domain differences shrink to near zero. If they orchestrate complex sequences, domain performance compounds across each step.
Gemini 2.5 Pro performance gap analysis by domain
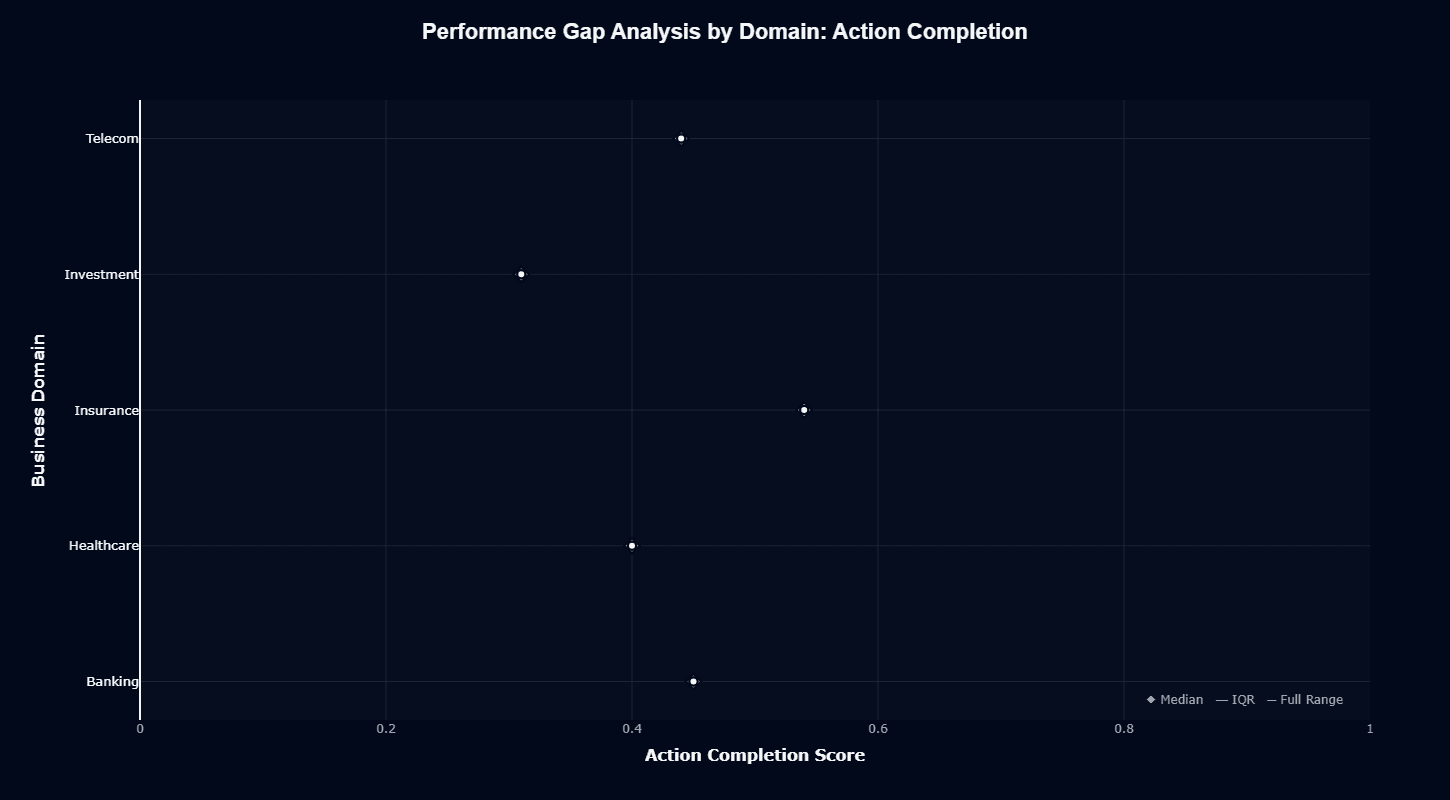
Action completion
This distribution chart reveals how domain choice impacts task success. Banking's median sits around 0.45—middle of the pack with tight interquartile ranges showing consistent performance.
Insurance performs best at roughly 0.54 median. The model handles claims processing and policy workflows with fewer failures than other verticals.
Healthcare lands near 0.40. Medical terminology and clinical workflows don't break the model, but they create friction. Performance sits below baseline without catastrophic failures.
Telecom mirrors baseline at 0.44. Network troubleshooting and service provisioning tasks run at expected levels without specialized advantages.
Investment creates the biggest problem. The median drops to roughly 0.31—the lowest across all domains. That's a 23-point gap versus Insurance. Financial analysis, portfolio management, and investment strategy workflows consistently underperform. This isn't random variance—it's a reproducible weakness.
The interquartile ranges stay relatively tight across domains. Consistent patterns rather than occasional outliers. Reproducible performance differences by industry.
For procurement decisions, this chart quantifies risk by vertical. Insurance and Banking sit in acceptable territory. Investment needs serious testing against your specific workflows before commitment.
Tool selection quality
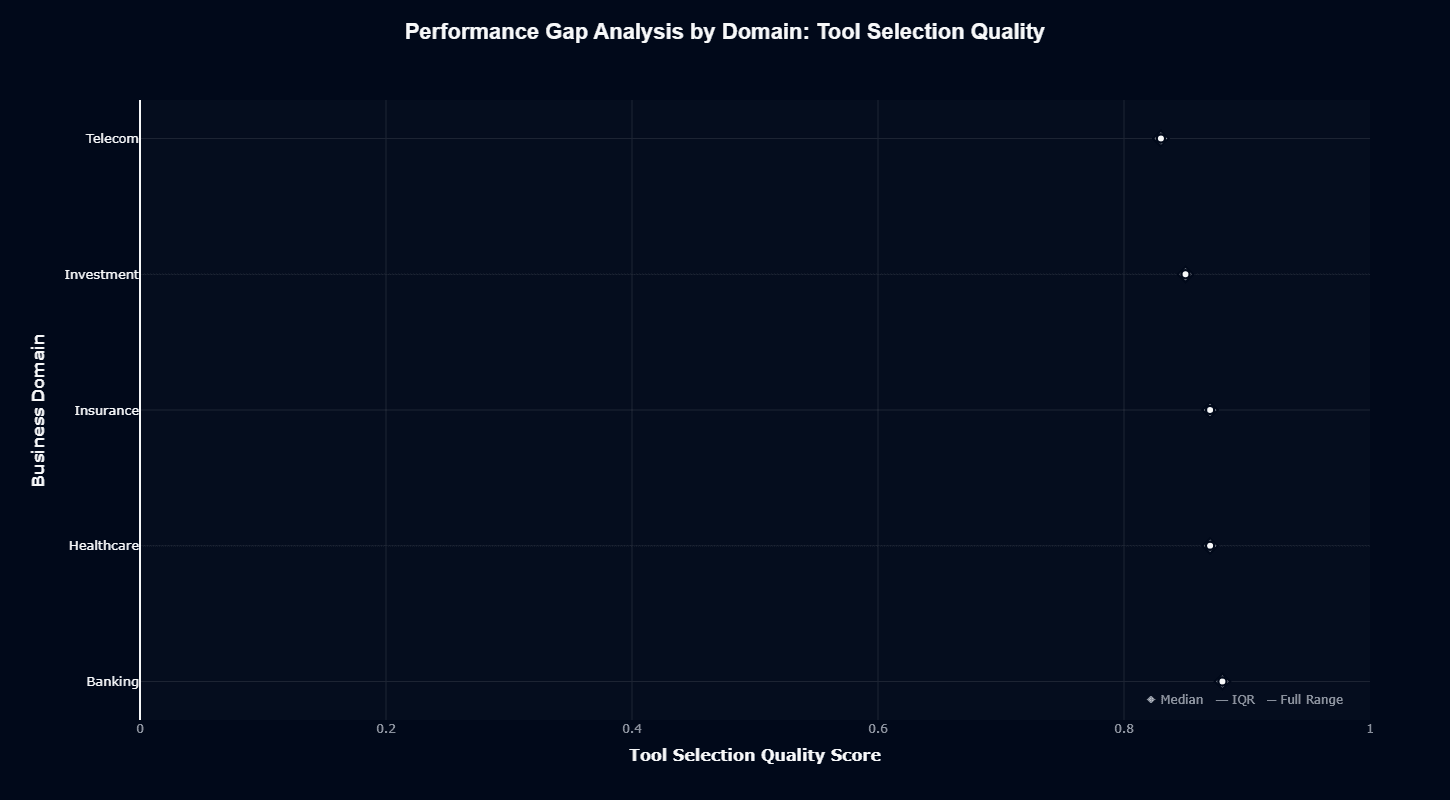
Tool Selection tells a completely different story. All domains cluster between 0.88-0.90. Minimal variance. Banking, Healthcare, Insurance, Investment, and Telecom all get similarly accurate tool selections.
Investment sits around 0.88-0.90 despite its action completion struggles. The model knows which tools to call in financial workflows. It fails at execution after tool invocation.
Telecom peaks near 0.90 for tool selection. Banking and Insurance hover near 0.88-0.90. Healthcare runs at 0.88-0.90. Tight ranges. Stable, predictable performance.
This split matters for architecture decisions. Tool selection generalizes well. Choosing the right API or function works consistently across business contexts. Action completion varies significantly. Finishing complex multi-step workflows depends heavily on domain knowledge.
The production implication: if your agents primarily route requests and invoke single tools, domain differences shrink to near zero. If they orchestrate complex sequences, domain performance compounds across each step. That 23-point spread between Investment and Insurance in action completion amplifies as workflow complexity increases.
Gemini 2.5 Pro cost-performance efficiency
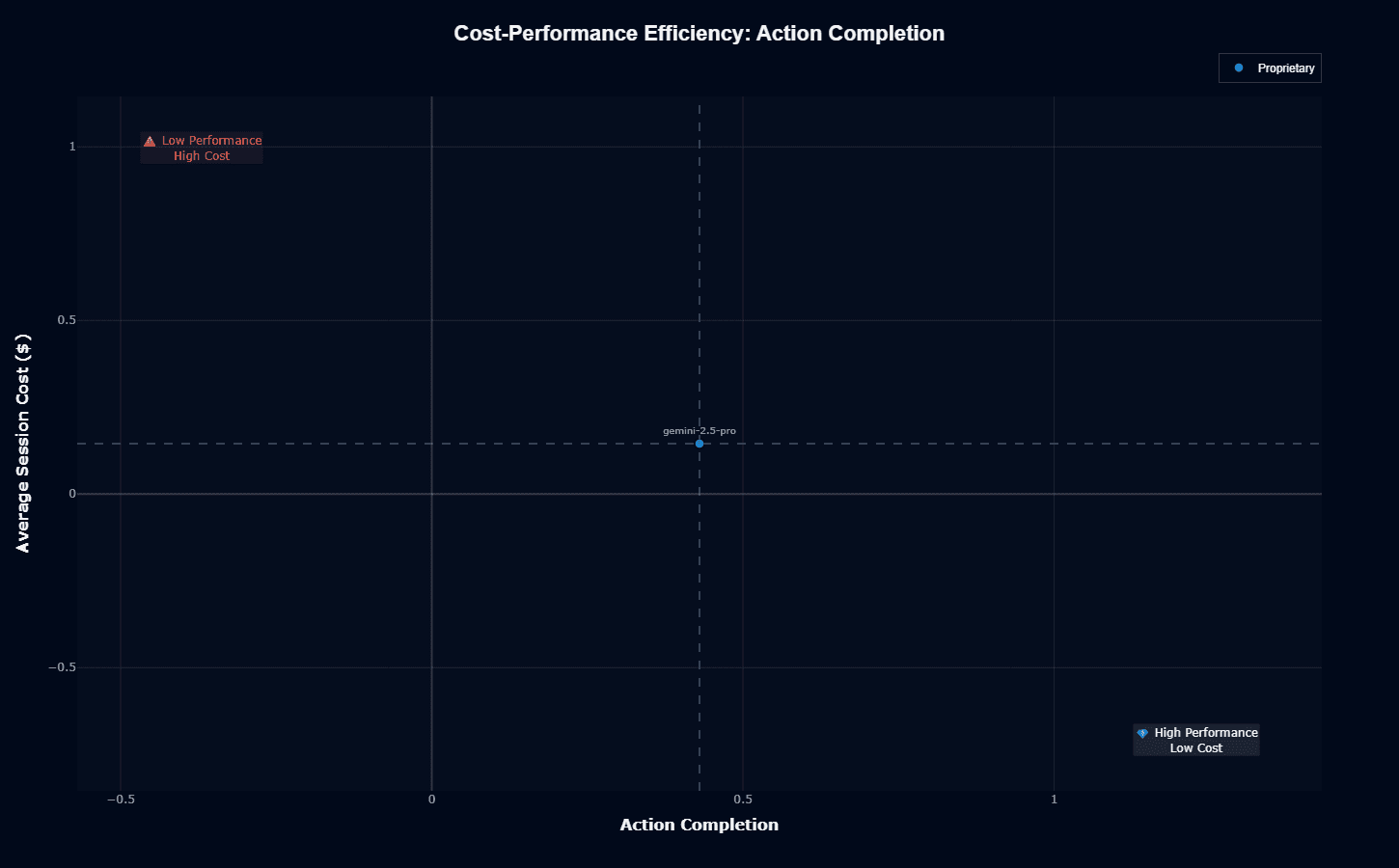
Action completion
Gemini 2.5 Pro sits at 0.43 action completion with $0.145 per session—center positioning. The model avoids "Low Performance High Cost" territory but doesn't reach the "High Performance Low Cost" sweet spot either.
The 0.43 score falls below the 0.5 threshold. Less than half of multi-step tasks complete on average. That's problematic for reliability-critical systems requiring high first-attempt success.
Cost runs 72% cheaper than Claude Sonnet 4.5, but 7-10× more than budget alternatives like GLM-4.5-Air. Mid-tier economics without budget savings or frontier capabilities.
The 0.43 completion rate demands architectural decisions. Retry logic, validation checkpoints, and fallback mechanisms become necessary. For bounded agent tasks with moderate complexity, this works. For high-volume simple tool calls or mission-critical workflows, alternatives make more sense.
Tool selection quality
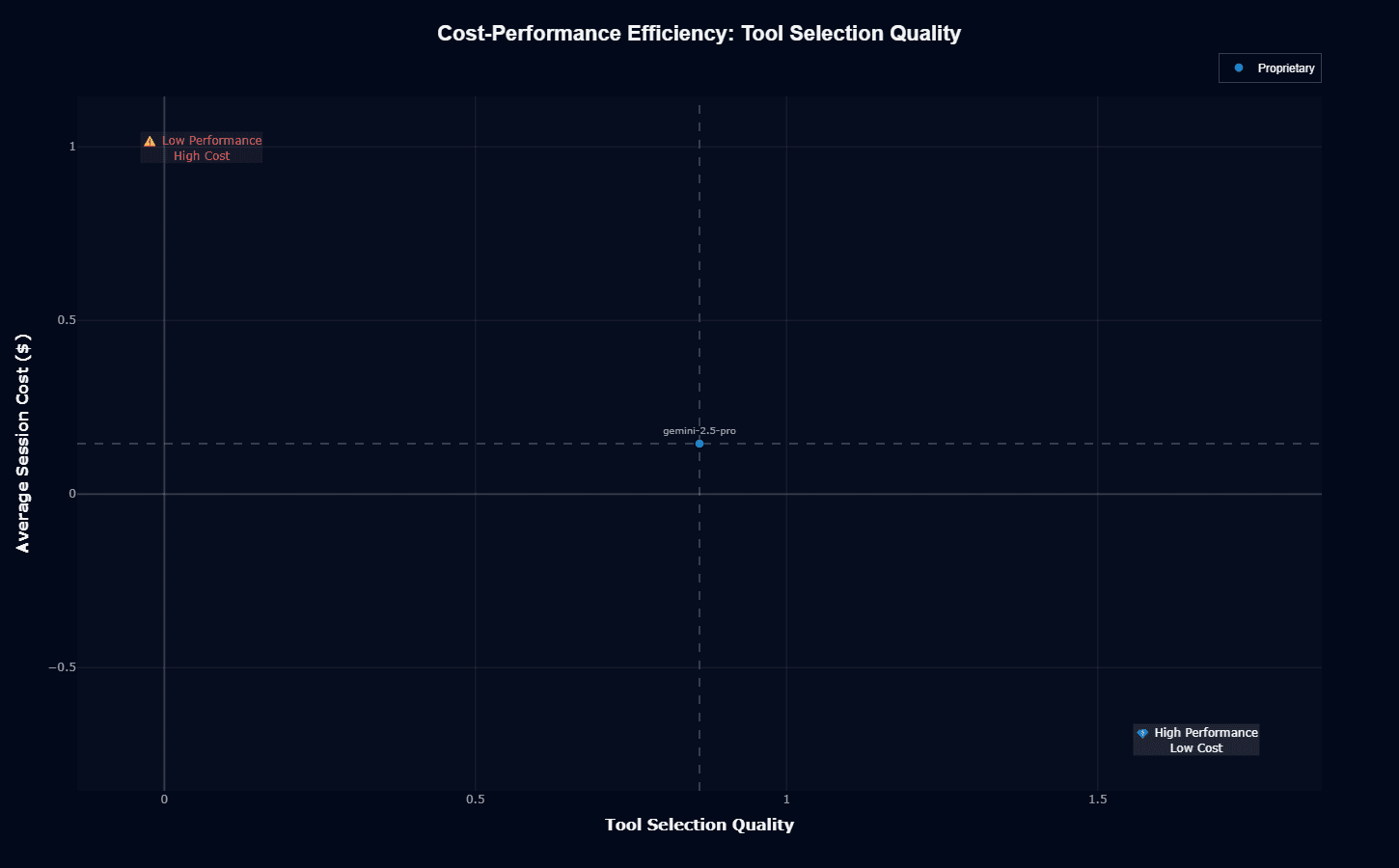
Tool selection shows stronger positioning. Gemini 2.5 Pro hits 0.86 quality at $0.145 per session, toward the "High Performance Low Cost" quadrant without reaching the extreme corner.
That 0.86 score means 14% of tool calls need correction. Combined with mid-tier pricing, this creates reasonable economics for tool-heavy workflows. Budget alternatives achieve 0.94+ accuracy at lower cost, an 8-10-point advantage over other architectures.
Tool selection matters because mistakes cascade. One wrong tool call derails entire workflows. But 86% accuracy with proper retry logic handles the 14% error rate without breaking execution patterns.
Processing one million tool calls monthly costs roughly $145 versus $330+ with GPT-4 Turbo or $19 with GLM-4.5-Air. You're paying for the 1M token context window and conversational depth, not just tool routing.
Gemini 2.5 Pro speed vs. accuracy
Action completion
Gemini 2.5 Pro sits at 0.43 action completion with 125.8-second average session duration. Center positioning. Neither fast nor slow, neither highly accurate nor struggling.
The 125.8-second duration reflects moderate processing across 3.6 turns per conversation. Not optimized for speed. Not optimized for accuracy. Balanced.
Most models force tradeoffs between speed and accuracy. Gemini 2.5 Pro avoids slow and inaccurate territory. But it doesn't dominate fast and accurate either. Middle ground.
The model prioritizes conversational depth over raw speed, context maintenance over completion rates. That 1M token window and 0.64 Conversation Efficiency show where optimization effort went.
For workflows where extended reasoning matters (customer support, document analysis, technical troubleshooting) this positioning works. For workflows needing maximum speed or maximum completion rates, specialized alternatives deliver better results.
Tool selection quality
Gemini 2.5 Pro sits at 0.86 in Tool Selection Quality and 125.8 seconds in average session duration, both baseline performances.
The 0.86 score means 14% of tool selections need correction. The 125.8-second duration reflects moderate speed across multi-turn conversations. Mid-range.
The actual tradeoff: conversational depth versus action completion. The model achieves 0.64 in Conversation Efficiency, its highest metric, while action completion sits at 0.43. Built for extended reasoning, not task completion.
For workflows where tool selection and context maintenance matter—such as multi-turn troubleshooting, document analysis, and customer support—this works. For workflows that need maximum completion rates, the 0.43 score poses problems.
Gemini 2.5 Pro key capabilities and strengths
Gemini 2.5 Pro works best when extended reasoning and multimodal processing drive your workflow:
Extended context window: 1 million tokens, expanding to 2 million. Handles entire codebases, lengthy documents, and extended conversations without truncation. GPT-4 Turbo offers 128K, Claude 3.5 Sonnet provides 200K. Only Grok 3 matches at 1M.
Native multimodal processing: Accepts text, code, images, audio, and video without preprocessing. Reduces pipeline complexity for multi-format workflows. Built-in architecture, not bolted-on features.
Integrated reasoning capabilities: Thinking built directly into the model. Reasons through problems before responding. Different from prompt-based chain-of-thought that adds latency and cost.
Strong coding performance: 63.8% on SWE-Bench Verified. Trails Claude 3.7 Sonnet (70.3%) but leads o3-mini (61.0%). Generates complex code, creates interactive applications, understands entire repositories.
Advanced math and science reasoning: Leads Humanity's Last Exam at 18.8%. Scores 84.0% on GPQA Diamond and 86.7% on AIME 2025. Built for multi-step logic problems.
Exceptional long-context performance: 91.5% on MRCR at 128K tokens, 83.1% at 1M tokens. GPT-4.5 scores 48.8%, o3-mini reaches 36.3%. Maintains accuracy across extremely long documents.
Tool use and function calling: Supports structured JSON output, code execution, Google Search grounding, and custom developer tools. Enables real-time information and external capabilities.
Leading multimodal understanding: 81.7% on MMMU (visual reasoning). Highest among all models. Analyzes complex diagrams, reads handwritten notes, generates code from whiteboard sketches.
Multilingual capabilities: 89.8% on Global MMMU across multiple languages. Native audio output supports 24 languages with low latency.
Gemini 2.5 Pro limitations and weaknesses
Before committing to production, test these documented constraints against your specific requirements:
Moderate action completion rates: Scores 0.430 on action completion—below 50% task success. Multi-step workflows requiring high first-attempt reliability need architectural workarounds with retry logic and validation checkpoints.
Significant domain performance variance: Action completion spans 23 points between Insurance (0.540) and Investment (0.310). Healthcare at 0.400, Telecom at 0.440, Banking at 0.450. Domain-specific testing mandatory before production deployment.
Tool selection accuracy at 86%: 0.860 Tool Selection Quality means 14% of tool selections need correction. Budget models like GLM-4.5-Air achieve 0.940+ accuracy. Requires error handling and validation logic.
Mid-tier cost structure: $2.50 input / $15.00 output per million tokens under 200K context. Long context (200K+) doubles to $5.00 input/$20.00 output. High-volume deployments incur significant costs compared to budget alternatives.
Coding performance trails category leader: 63.8% on SWE-Bench Verified. Claude 3.7 Sonnet leads at 70.3%—a 6.5-point gap. For maximum coding performance, Claude remains the stronger option.
Limited published safety benchmarks: No documented scores for ToxiGen, BOLD, or TruthfulQA. Unknown bias patterns and hallucination rates create compliance gaps for regulated industries.