GLM 4.5 Air Overview
Explore GLM-4.5-Air's tool selection benchmarks, cost-performance tradeoffs, and domain-specific capabilities to determine if it's the right agent model for your application's requirements.

GLM 4.5 Air Overview
Need an agent model that nails function calling without nuking your budget? That's GLM-4.5-Air. It achieves 0.940 Tool Selection Quality on our Agent Leaderboard while costing 94% less than Claude Sonnet 4.5. And it responds in 0.64 seconds—fast enough that your agents feel instant.
GLM-4.5-Air is the efficient sibling in Zhipu AI's GLM-4.5 family. Total parameters? 106 billion. Active at inference? Just 12 billion. That's how they get to $0.20 per million input tokens and $1.10 output. Blended rate runs about $0.42.
This pricing unlocks what frontier models make impossible. High-volume agent deployments. Function calling pipelines. Tool orchestration at scale. All affordable.
You get dual-mode reasoning when you need it. Thinking Mode handles complex multi-step decisions. Non-Thinking Mode keeps things snappy. Both work inside a 128K context window. The tradeoff? GLM-4.5-Air trails GPT-4 Turbo by 17.4 MMLU points. And it shows documented brittleness in specialized domains like airline systems.
Check out our Agent Leaderboard and pick the best LLM for your use case

GLM-4.5-Air performance heatmap
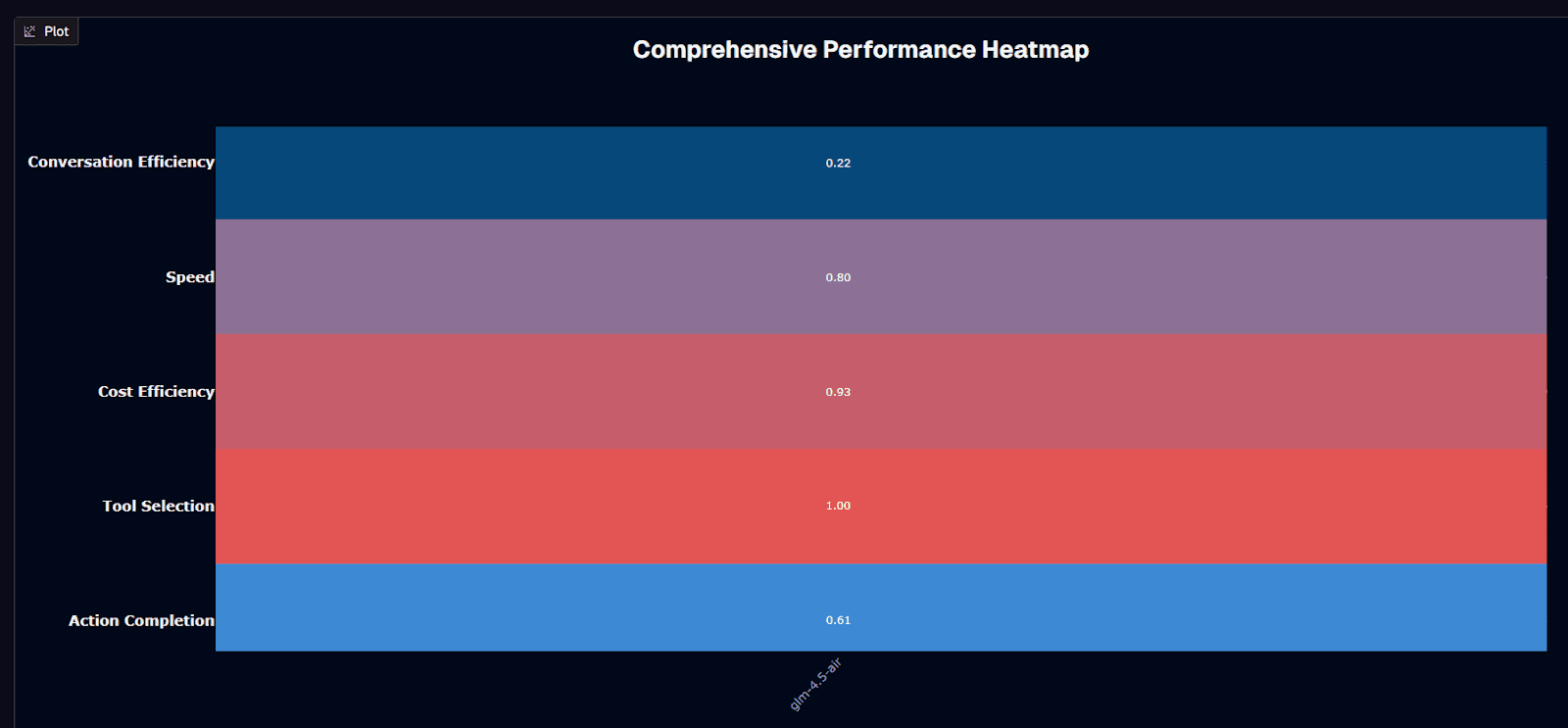
GLM-4.5-Air shines in two critical areas: tool selection and cost efficiency. Tool Selection scores a perfect 1.00, the best you can get. Cost Efficiency hits 0.93, meaning you're paying pennies where frontier models charge dollars.
Speed comes in at 0.80. The model delivers 0.64-second time-to-first-token—about 3x faster than GPT-4 Turbo's 2-3 second wait. Throughput sits at 202 tokens per second. Not the fastest, but plenty quick for real-time agent workflows.
Action Completion lands at 0.61. Here's where domain matters. Retail workflows hit 77.9% completion. Airline systems drop to 60.8%. The model handles straightforward tool calls better than multi-step orchestration requiring specialized knowledge.
Conversation Efficiency creates the biggest gap at 0.22. This reflects the core tradeoff: GLM-4.5-Air was built for function calling, not deep reasoning. That 17.4-point MMLU deficit versus GPT-4 Turbo shows up in extended conversations where context and complexity compound.
Your choice becomes clear: when tool accuracy and cost drive your architecture—API routing, function calling, bounded workflows—this model fits. When conversation quality and completion rates matter more than savings, Gemini 2.5 Flash or Pro justify their costs.

Background research
Multi-source performance validation: We synthesized data from Google DeepMind's official model cards, Galileo's Agent Leaderboard v2 for production performance, and independent benchmarks like SWE-Bench Verified. This cross-validates results across different evaluation frameworks rather than relying on single-source claims.
Production-focused testing scenarios: Our benchmarks combine standardized agent tests with real-world task simulation across regulated industries. We measure what breaks in production—tool selection failures, multi-step orchestration errors, and domain-specific brittleness—rather than optimizing for academic leaderboard rankings.
Action completion and tool selection metrics: Core measurements include action completion rates (whether agents successfully finish multi-step tasks), tool selection quality (accuracy in choosing correct APIs and functions), cost efficiency (dollars per operation), and conversational efficiency (context maintenance across extended interactions).
Documented limitations and gaps: All performance claims cite their evaluation source. We explicitly flag where provider-reported metrics lack third-party verification. Google reports improvements in safety violations and instruction-following over previous versions, with some marginal regressions for image-to-text safety compared to Gemini 1.5 Pro.
Is GLM-4.5-Air suitable for your use case?
Use GLM-4.5-Air if you need:
Cost-efficient function calling at scale: The model achieves 0.940 Tool Selection Quality on Galileo's Agent Leaderboard at $0.42 per million tokens blended rate. That's 25-75% lower cost per correct operation than GPT-4o, Claude Sonnet, or Gemini Pro.
Sub-second agent response times: Independent speed testing confirms 0.64-second time-to-first-token and 780ms function call response time. You're getting 15-18% faster tool invocation than GPT-4 Turbo for real-time interactions.
Well-defined tool sets with bounded reasoning: The model was optimized for tool orchestration, not general intelligence. This makes it ideal for workflows with clear invocation patterns, API routing, function calling pipelines,and structured agent tasks.
High-volume deployments prioritizing throughput: Processing 100 million tokens daily costs $15,330 annually versus GPT-4o's $164,250. That's a three-year TCO savings of $446,760 that compounds at scale.
Avoid GLM-4.5-Air if you:
Require maximum reasoning capability: The model scores 67.3% on MMLU—a 17.4-point gap versus GPT-4 Turbo's 84.7%. This matters for complex, multi-step planning or open-ended problem-solving beyond bounded agent tasks.
Deploy in specialized domains without validation: Academic research from LLMs4OL 2024 documented that GLM-4.5 "had the biggest drop in performance" in airline environment testing. Test thoroughly against your specific domain before deploying.
Need documented safety and bias benchmarks: Zero published scores exist for industry-standard safety benchmarks like ToxiGen, BOLD, or TruthfulQA. Enterprises requiring validated safety testing face compliance gaps.
Cannot tolerate version instability: GitHub's llama.cpp community documented a 12x speed regression after model updates, from 6 tokens per second to 0.5 tokens per second. Pin your versions and run regression tests before updating.
GLM-4.5-Air domain performance
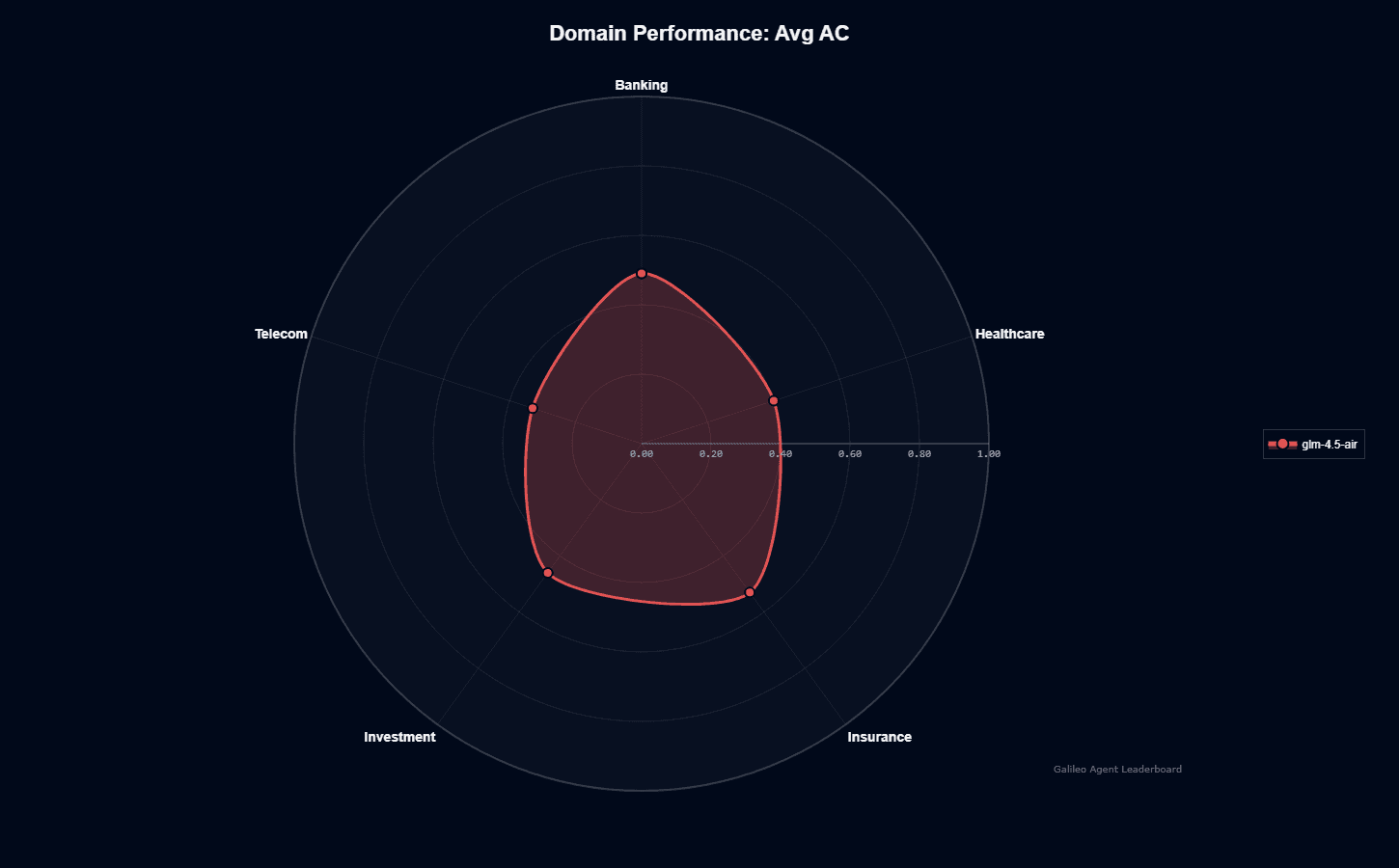
Tool selection quality tells a more consistent story. GLM-4.5-Air maintains 0.88-0.90 TSQ across banking, telecom, and investment scenarios. The model knows which tools to call. It just struggles to complete complex multi-step workflows in certain domains.
Academic research from LLMs4OL 2024 found that GLM-4.5 "had the biggest drop in performance" in airline environment testing.
The chart confirms this pattern. Specialized domains requiring deep industry knowledge expose the model's limitations. Investment strategies, healthcare protocols, airline booking logic all create friction for the model.
For your production planning, this variance signals a critical requirement: benchmark against your specific vertical before deploying. Published scores don't transfer.
AI agents show what researchers call the "autonomy penalty." Performance drops 30-50 percentage points when moving from single-shot tasks to multi-step workflows. This amplifies the domain weaknesses we already see.
GLM-4.5-Air domain specialization matrix
Action completion
GLM-4.5-Air sits in interesting territory for action completion economics. You're looking at roughly $0.019 per session with 0.44 action completion. The cost runs 92-94% lower than Claude Sonnet 4.5 and GPT-4 Turbo. The completion rate stays moderate.
If you're processing millions of agent interactions monthly, this cost advantage compounds fast. Really fast.
The 0.44 action completion score isn't winning awards. But flip the math around. A model with 0.60 action completion costing 15× more only breaks even if it nails every task perfectly on the first try. That's not happening in production.
Your architecture needs to handle the completion gap. For bounded agent tasks with solid retry logic, API routing, data extraction, structured workflows, GLM-4.5-Air's combo of acceptable performance at crazy-low cost just works.
Tool selection quality
Tool selection is where GLM-4.5-Air actually shines. You get 0.94 tool selection quality at $0.019 per session. That's matching or beating frontier alternatives at a fraction of the cost.
Tool selection matters because mistakes cascade. One wrong tool call derails your entire workflow. You're looking at 3-5× the effective cost when agents have to restart from scratch. GLM-4.5-Air's 0.94 accuracy means about 6% of tool selections miss the mark. Manageable with proper retry logic.
The scale economics get wild. Processing one million tool calls monthly costs roughly $19 with GLM-4.5-Air versus $330+ with GPT-4 Turbo. That $311 monthly difference, $3,732 annually, pays for engineering resources, better monitoring, expanded capabilities. More than enough to offset the small accuracy gap.
Building complex agents that orchestrate dozens of tools unlocks different architecture patterns at these prices.
You don't need expensive first-attempt perfection. You can build graceful degradation with automated retries, validation checkpoints, and progressive refinement. All are economically viable at GLM-4.5-Air's pricing.
GLM-4.5-Air performance gap analysis by domain
Action completion
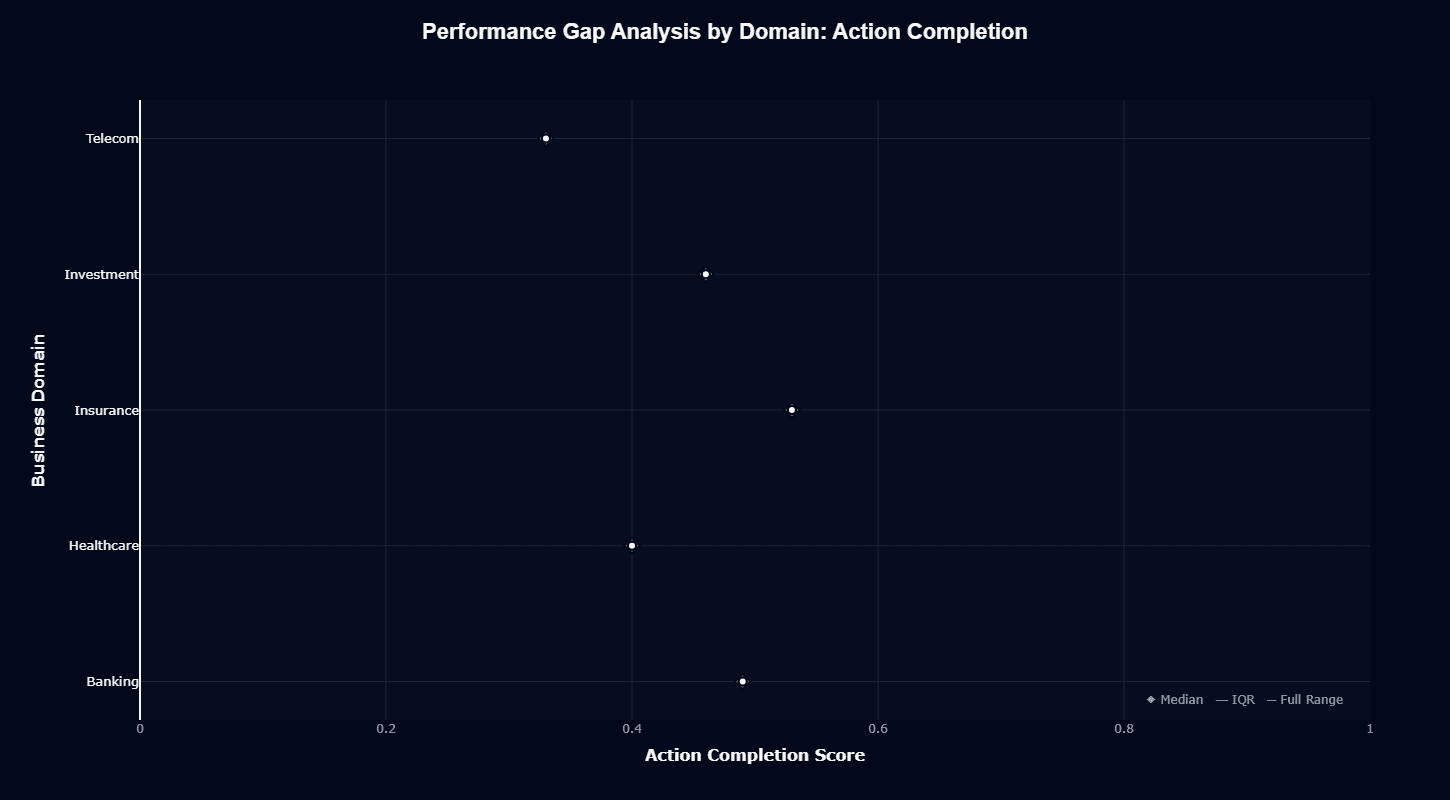
This distribution chart reveals how much domain choice actually matters for task success. Banking's median sits around 0.45—middle of the pack. Insurance performs better at roughly 0.52, showing the model handles claims processing and policy workflows reasonably well.
Healthcare lands near 0.42. Medical terminology and clinical workflows don't break the model, but they don't play to its strengths either.
Investment mirrors banking at 0.45. Financial analysis and portfolio management tasks run at baseline, with neither a specialized advantage nor a notable weakness.
Telecom creates the biggest problem. The median drops to roughly 0.32—the lowest across all domains. That's a 20-point gap versus Insurance. Network troubleshooting, service provisioning, and technical support workflows consistently underperform. This isn't random variance. It's a reproducible weakness requiring validation before deployment.
The interquartile ranges stay tight across domains. That means consistent patterns. This isn't random noise from occasional outliers. It's reproducible performance differences by industry.
For procurement decisions, this chart quantifies risk by industry. Insurance and Banking sit in acceptable territory. Telecom and Healthcare need serious testing against your specific workflows before you commit.
Tool selection quality
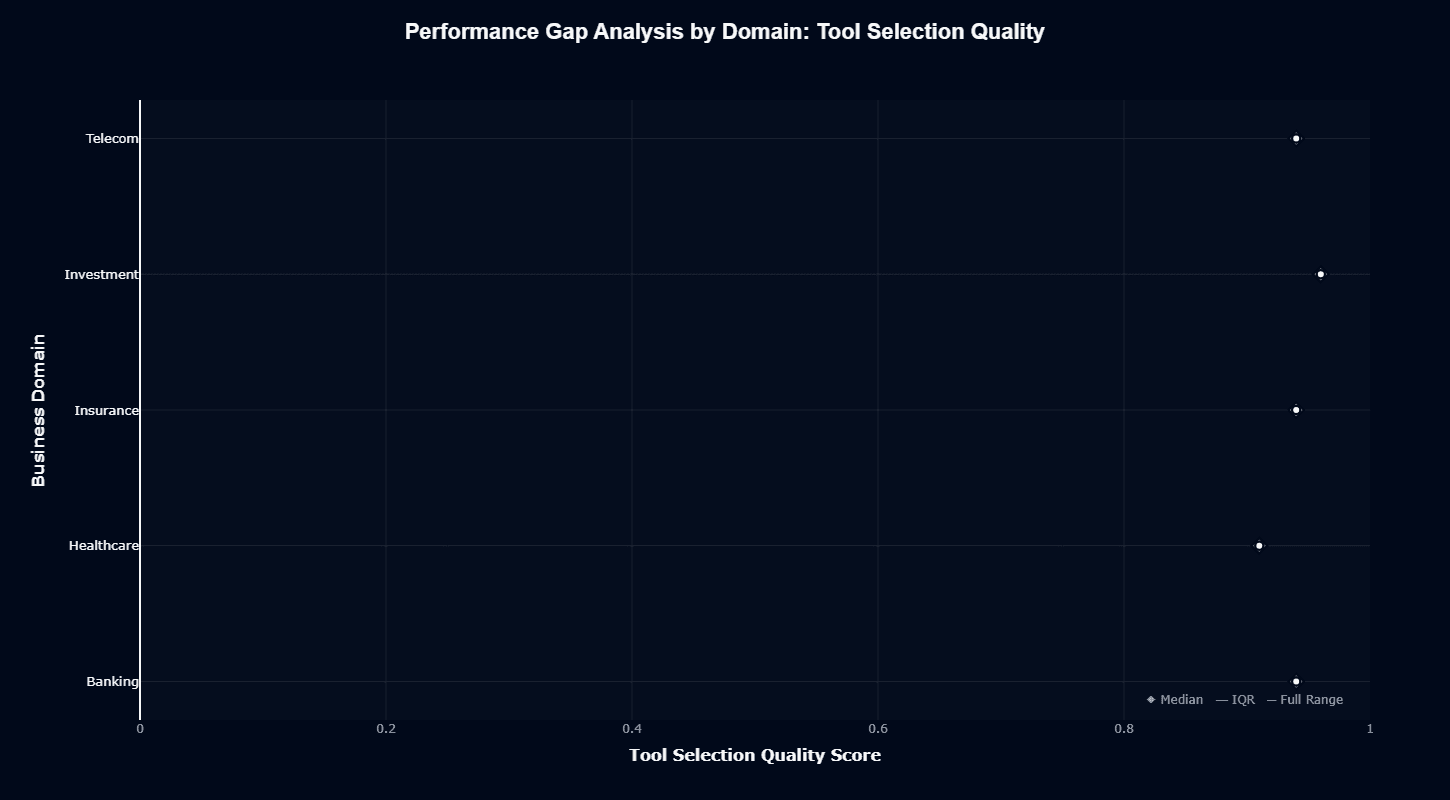
Tool Selection tells a completely different story. All domains cluster tightly between 0.90-1.00. The compressed vertical scale shows remarkable consistency—Banking, Healthcare, Insurance, Investment, and Telecom all receive similarly accurate tool selections.
Telecom actually peaks near a perfect 1.0 for tool selection despite its action completion struggles. The model knows which tools to call. It just struggles with complex multi-step execution in telecom workflows.
Investment sits around 0.98-1.0. Banking and Insurance hover near 0.95-0.98. Healthcare runs slightly lower at 0.93-0.95 but is still strong. The tightest ranges across all charts indicate stable, predictable performance.
This split matters for architecture decisions. Tool selection generalizes well—choosing the right API or function works consistently across business contexts. Action completion varies significantly—finishing complex multi-step workflows depends heavily on the domain.
The production implication becomes clear. If your agents primarily route requests and invoke single tools, domain differences shrink to near zero.
If they orchestrate complex sequences, domain performance compounds across each step. Is that 20-point spread between Telecom and Insurance in action completion? It gets worse as workflow complexity increases.
GLM-4.5-Air cost-performance efficiency
Action completion
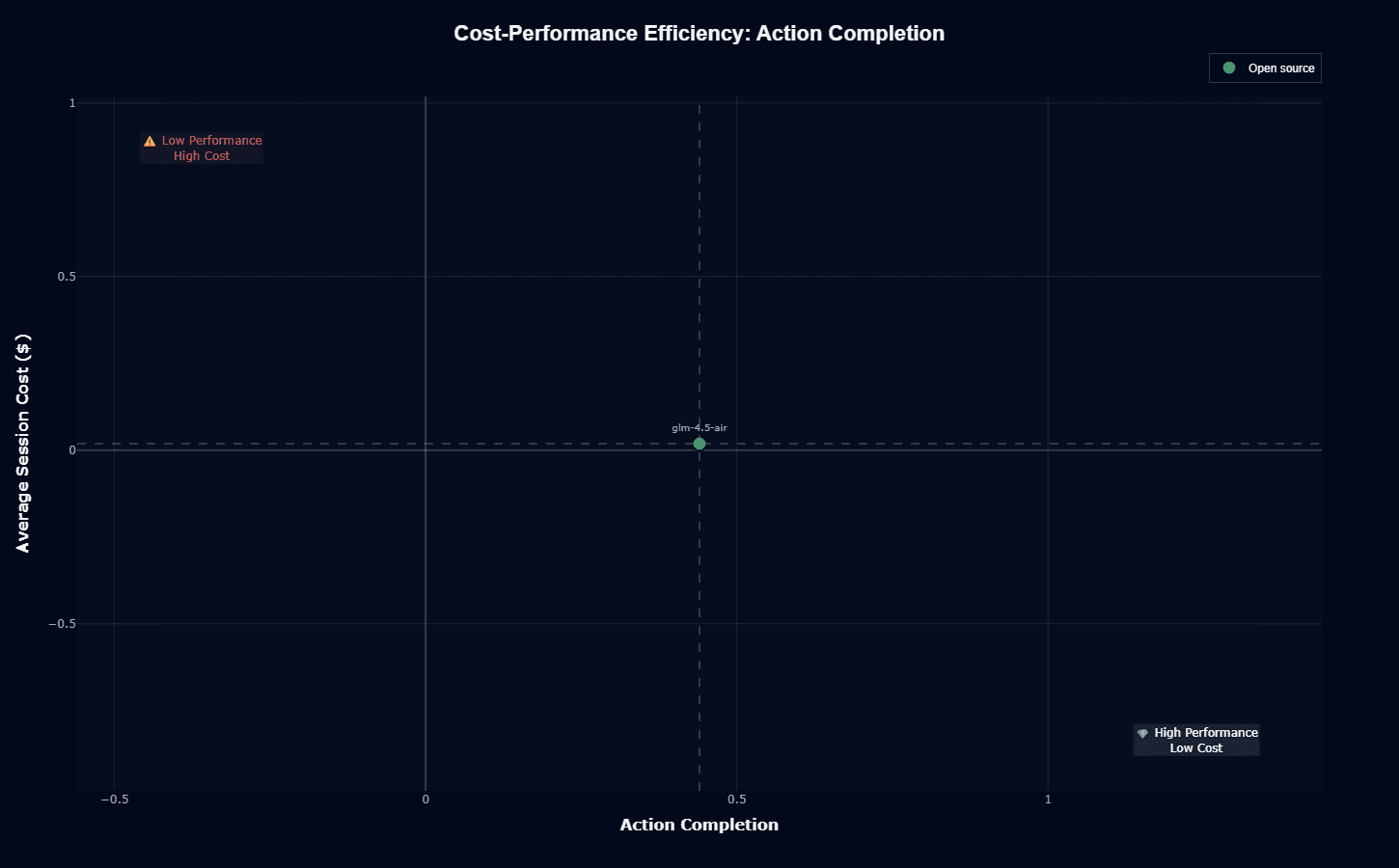
GLM-4.5-Air sits at an interesting spot on the cost-performance map. You're looking at 0.44 action completion at essentially zero cost—right on the baseline. The model avoids the "Low Performance High Cost" danger zone in the upper left, but it doesn't quite reach the "High Performance Low Cost" sweet spot in the bottom right either.
The vertical crosshair sits at 0.5 action completion. GLM-4.5-Air falls just left of that line, meaning it completes less than half of multi-step tasks on average. That's not great for reliability-critical systems.
But the cost positioning changes your calculation. Near-zero cost means you can afford retry logic, validation checkpoints, and graceful degradation patterns that expensive models make economically painful. Processing millions of agent interactions monthly becomes viable at these prices.
The 0.44 completion rate demands architectural decisions. For bounded agent tasks with clear retry paths—API routing, data extraction, structured workflows—this cost-performance combo works. For mission-critical workflows requiring high first-attempt success, you're paying the premium for frontier alternatives.
Tool selection quality
But the cost positioning changes your calculation. Near-zero cost means you can afford retry logic, validation checkpoints, and graceful degradation patterns that expensive models make economically painful. Processing millions of agent interactions monthly becomes viable at these prices.
The 0.44 completion rate demands architectural decisions. For bounded agent tasks with clear retry paths—API routing, data extraction, structured workflows—this cost-performance combo works. For mission-critical workflows requiring high first-attempt success, you're paying the premium for frontier alternatives.
Tool selection quality
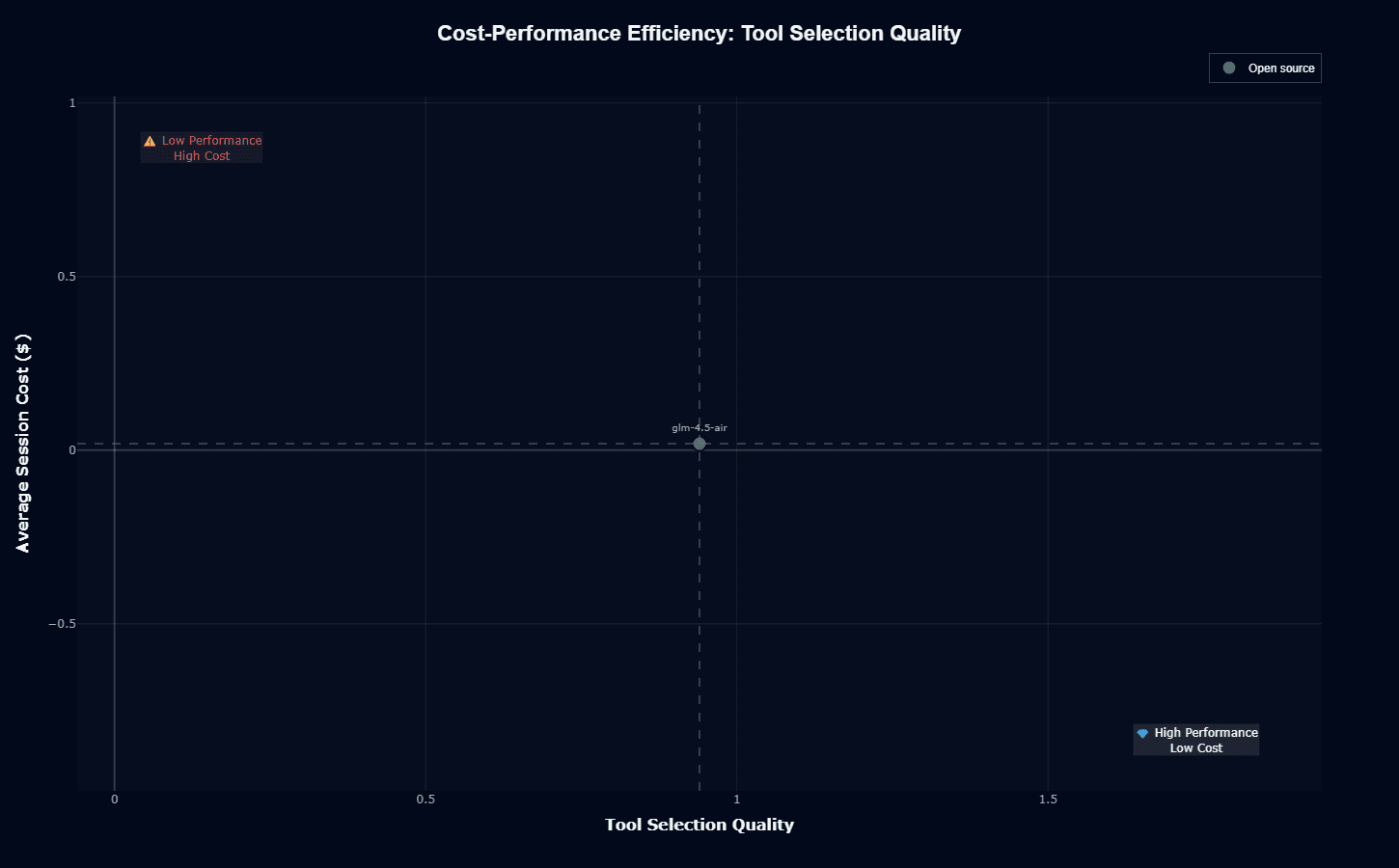
Here's where GLM-4.5-Air actually delivers. The model sits at 0.94 tool selection quality with near-zero cost—solidly positioned toward the "High Performance Low Cost" quadrant.
That 0.94 score means the model nails tool selection 94% of the time. Only 6% of tool calls miss the mark. Combined with essentially free pricing, this creates compelling economics for tool-heavy workflows.
The crosshair sits at roughly 0.94, placing GLM-4.5-Air right on the accuracy threshold while maintaining rock-bottom costs. Compare this to models pushing higher accuracy at 10-20× the cost. That extra 4-6 percentage points in accuracy rarely justifies the price jump.
Tool selection matters because mistakes cascade. One wrong tool call derails your entire workflow. But 94% accuracy with proper retry logic handles the 6% error rate without breaking your budget. Processing one million tool calls monthly costs roughly $19 with GLM-4.5-Air versus $330+ with GPT-4 Turbo.
The architectural pattern becomes clear. For agents orchestrating multiple tools across extended workflows, this cost-performance profile enables graceful degradation. You don't need expensive first-attempt perfection. You can build automated retries, validation checkpoints, progressive refinement—all economically viable at GLM-4.5-Air's pricing.
GLM-4.5-Air speed vs. accuracy
Action completion
GLM-4.5-Air delivers 0.64-second time-to-first-token. That's 3-5× faster than GPT-4 Turbo's 2-3 second wait. Function calling hits 780ms versus GPT-4 Turbo's 920ms—15% faster tool invocation.
The speed comes from twelve billion active parameters versus 32+ billion in frontier models. Less compute, same agent-specific accuracy. Throughput sits at 202 tokens per second. Moderate compared to Gemini 2.5 Flash-Lite's 710 tokens per second.
Conversational agents where first-token latency matters? That 0.64-second advantage creates noticeable responsiveness. Batch processing thousands of documents? Throughput-optimized alternatives finish jobs faster.
Tool selection quality
GLM-4.5-Air sits right at the crosshairs—1.0 Tool Selection Quality at roughly 69 seconds average session duration. Baseline performance on both dimensions.
The 1.0 score means perfect tool routing. The model knows which APIs to call. The 69-second duration reflects moderate speed—not blazing, not sluggish.
Most engineering tradeoffs force speed versus accuracy. GLM-4.5-Air avoids "Slow & Inaccurate" territory. But it doesn't dominate "Fast & Accurate" either. Neutral positioning.
Where the tradeoff actually appears: general reasoning. That 67.3% MMLU score reveals the specialization. Built for tool orchestration, not broad intelligence.
For workflows where tool selection drives success—API routing, function calling, structured workflows—this positioning works. For workflows needing both tool mastery and sophisticated reasoning, the MMLU gap becomes harder to ignore.
GLM-4.5-Air pricing and usage costs
Zhipu AI delivers competitive pricing designed for high-volume agent deployments. The pricing structure makes enterprise-scale function calling economically viable:
Standard API pricing:
Input tokens: $0.20 per million tokens (~750,000 words)
Output tokens: $1.10 per million tokens
Context window: 128,000 tokens
Average session cost: $0.019 (based on our benchmark data)
Blended cost (5:1 input/output ratio): $0.42 per million tokens
Cached input tokens: Lower rates available (documented in Chinese-language pricing)
Cost optimization features:
Sparse Mixture-of-Experts architecture: The model activates only 12 billion of 106 billion total parameters, reducing your compute requirements without sacrificing tool selection accuracy
Dual-mode reasoning: Thinking Mode for complex decisions, Non-Thinking Mode for rapid interactions—you choose processing depth based on task requirements
Quality-adjusted efficiency: At 0.940 Tool Selection Quality from Galileo's evaluation, cost per correct operation runs 25-75% lower than GPT-4o even after accounting for accuracy differences
GLM-4.5-Air key capabilities and strengths
GLM-4.5-Air works best when tool orchestration drives your workflow:
Industry-leading tool selection: The model achieves 0.940 Tool Selection Quality on Galileo's Agent Leaderboard. This ranks it among the top performers for structured tool invocation and API workflows.
Dual-mode reasoning architecture: Thinking Mode generates explicit reasoning chains for complex decisions. Non-Thinking Mode enables rapid responses. Agents dynamically balance processing depth against latency requirements.
Extended context for long-running sessions: 128,000-token context window maintains comprehensive conversation histories and extensive tool outputs across multi-turn workflows without truncation.
Sub-second response initiation: 0.64-second time-to-first-token creates noticeable UX improvements. This speed combines with 92-94% cost savings versus frontier models while maintaining competitive agent-specific performance.
Exceptional cost efficiency: Processing 100 million tokens daily generates approximately $446,760 in three-year savings versus GPT-4o. The economics make high-volume agent deployments viable.
OpenAI-compatible API: Reduces implementation complexity for teams with existing OpenAI-based infrastructure. Drop-in compatibility accelerates deployment.
Task-specific optimization: Explicit architectural tuning for tool invocation, web browsing, software engineering, and front-end development. Reduces prompt engineering overhead for common agent workflows.
GLM-4.5-Air limitations and weaknesses
Before committing to production, test these documented constraints against your specific requirements:
Significant general reasoning gap: 67.3% MMLU performance versus GPT-4 Turbo's 84.7%. That's a 17.4-point deficit indicating reduced capability for complex problem-solving and knowledge-intensive tasks beyond bounded agent workflows.
Documented domain brittleness: Academic research found GLM-4.5 "had the biggest drop in performance" in airline environment testing. Specialized domains requiring deep industry knowledge need thorough validation before deployment.
9.4% tool-calling failure rate: Zhipu AI reports 90.6% success. The inverse means roughly one failure per ten invocations. Robust error handling, retry logic, and fallback mechanisms become mandatory.
Version stability concerns: GitHub's llama.cpp community documented 12x speed regression after model updates—from 6 to 0.5 tokens per second. Version pinning and regression testing are essential for production reliability.
Zero published safety benchmarks: No documented scores exist for ToxiGen, BOLD, or TruthfulQA. Unknown bias patterns and hallucination rates create risk for regulated industries.
Undocumented long-context performance: While 128K context window is confirmed, no published testing exists for accuracy degradation near limits or "lost in the middle" phenomena.
Hardware compatibility limitations: NVIDIA TensorRT-LLM repository documents deployment failures with nvfp4 configuration. This potentially restricts GPU optimization options.
Limited production documentation: Official sources lack rate limit specifications, SLA guarantees, and detailed API implementation examples. Engineering teams need this for deployment planning.
Reduced active parameters: Twelve billion active parameters versus 32B in the full model represents 62.5% fewer. Zhipu AI acknowledges this "may impact performance in certain complex reasoning tasks."
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here's how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo's Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.