GPT-4.1 Mini Overview
Explore GPT-4.1 Mini's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

GPT-4.1 Mini Overview
Picture your edge server parsing an entire codebase in one breath, replying in under a second, and costing less than a cup of coffee per million tokens. That's GPT-4.1 Mini, released April 14, 2025, as OpenAI's midpoint model.
You get a million-token context window—eight times larger than GPT-4o's—paired with 0.55-second average latency and $0.40 per million input tokens, an 83% drop from flagship rates.
This combination delivers near-GPT-4 quality without the heavyweight bill, perfect for multi-agent systems handling long transcripts, sprawling logs, or dense legal briefs. By bridging GPT-4-Turbo and the ultra-lean Nano variants, Mini creates fresh opportunities to balance speed, scale, and spend in your production environment.
Check out our Agent Leaderboard and pick the best LLM for your use case

GPT-4.1 mini performance heatmap
GPT-4.1-mini holds the #3 overall rank among frontier models in our agent leaderboard. It answers the growing demand for production-scale agent deployment. The "mini" name refers to reduced model size, not reduced capability—GPT-4.1-mini matches or beats the full GPT-4o model on many evaluations:
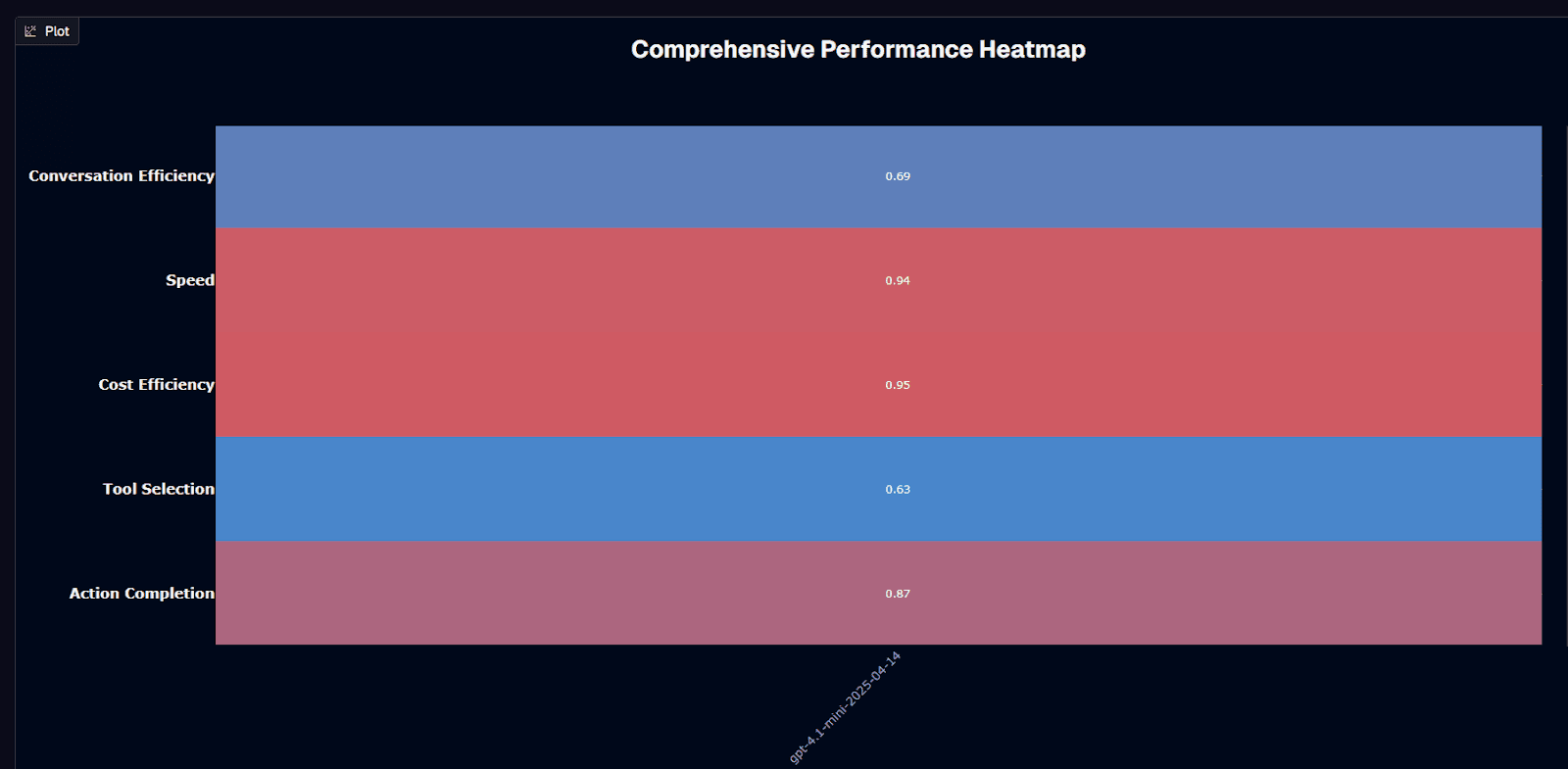
The comprehensive heatmap reveals GPT-4.1-mini's performance profile across five key dimensions:
Speed (0.94) and Cost Efficiency (0.95) dominate in red/pink, indicating exceptional performance in these dimensions—confirming the model's positioning as the fast, economical choice for production deployment.
Action completion (0.87) shows strong performance in pink, demonstrating that cost and speed advantages don't come at the expense of execution quality. This high score validates GPT-4.1-mini as a genuine production-grade solution, not a compromised alternative.
Conversation efficiency (0.69) and tool selection (0.63) appear in blue, indicating moderate performance relative to speed and cost dimensions. These metrics don't represent weaknesses in absolute terms—0.69 and 0.63 are solid scores. Rather, they highlight that GPT-4.1-mini prioritizes other dimensions over achieving absolute peaks in conversation efficiency and tool selection.
The performance profile suggests intentional design choices: optimize aggressively for speed and cost while maintaining "good enough" performance across other dimensions.
Background research
GPT-4.1-mini builds on several key technical advances:
Enhanced instruction following: Internal OpenAI benchmarks show GPT-4.1-mini scoring 49% on instruction-following tasks, outperforming GPT-4o's 29%, enabling more reliable agent behavior
Expanded context window: Unlike previous mini models limited to 128K tokens, GPT-4.1-mini supports the full 1 million token context shared across the GPT-4.1 family, enabling comprehensive document analysis and long-running agent sessions
Improved long-context attention: Training optimizations ensure reliable information retrieval across the entire context window, critical for agents processing extensive codebases or document collections
Tool use optimization: Specific training focused on function calling and tool orchestration, reducing the failure modes that plague agent deployments where models struggle to select or sequence API calls correctly
Is GPT-4.1 mini suitable for your use case?
Use GPT-4.1-mini if you need:
Top-tier overall agent performance: The #3 ranking indicates best-in-class capability across the full spectrum of agent tasks, from planning to execution
Maximum cost efficiency: At $0.014 per session (91% cheaper than Claude Sonnet 4), GPT-4.1-mini enables aggressive scaling without proportional cost increases
Fastest response times: 26-second average duration makes this the speed leader, critical for user-facing applications where latency creates friction
Telecom domain applications: Strong specialization (0.640 action completion) positions GPT-4.1-mini as the top choice for telecommunications workflows
Healthcare expertise: Second-best domain performance (0.600) makes it well-suited for medical documentation, patient communication, and clinical workflows
High conversation efficiency: Averages only 3.4 turns per session, resolving queries more quickly than alternatives that require extensive back-and-forth
Avoid GPT-4.1-mini if you:
Work primarily in insurance domains: With 0.460 action completion, GPT-4.1-mini shows the weakest performance in insurance applications, requiring additional oversight or domain-specific fine-tuning
Require consistently high tool selection across all domains: While 0.790 overall is strong, this trails specialized models that achieve 0.90+ tool selection accuracy
Need the absolute highest action completion rates: The 0.560 score, while competitive, doesn't lead the category—teams prioritizing execution perfection over speed may find alternatives better suited
Depend on extended reasoning sessions: The fast 26-second duration indicates optimized quick responses rather than deep deliberation, which may limit performance on complex reasoning tasks
GPT-4.1 mini domain performance
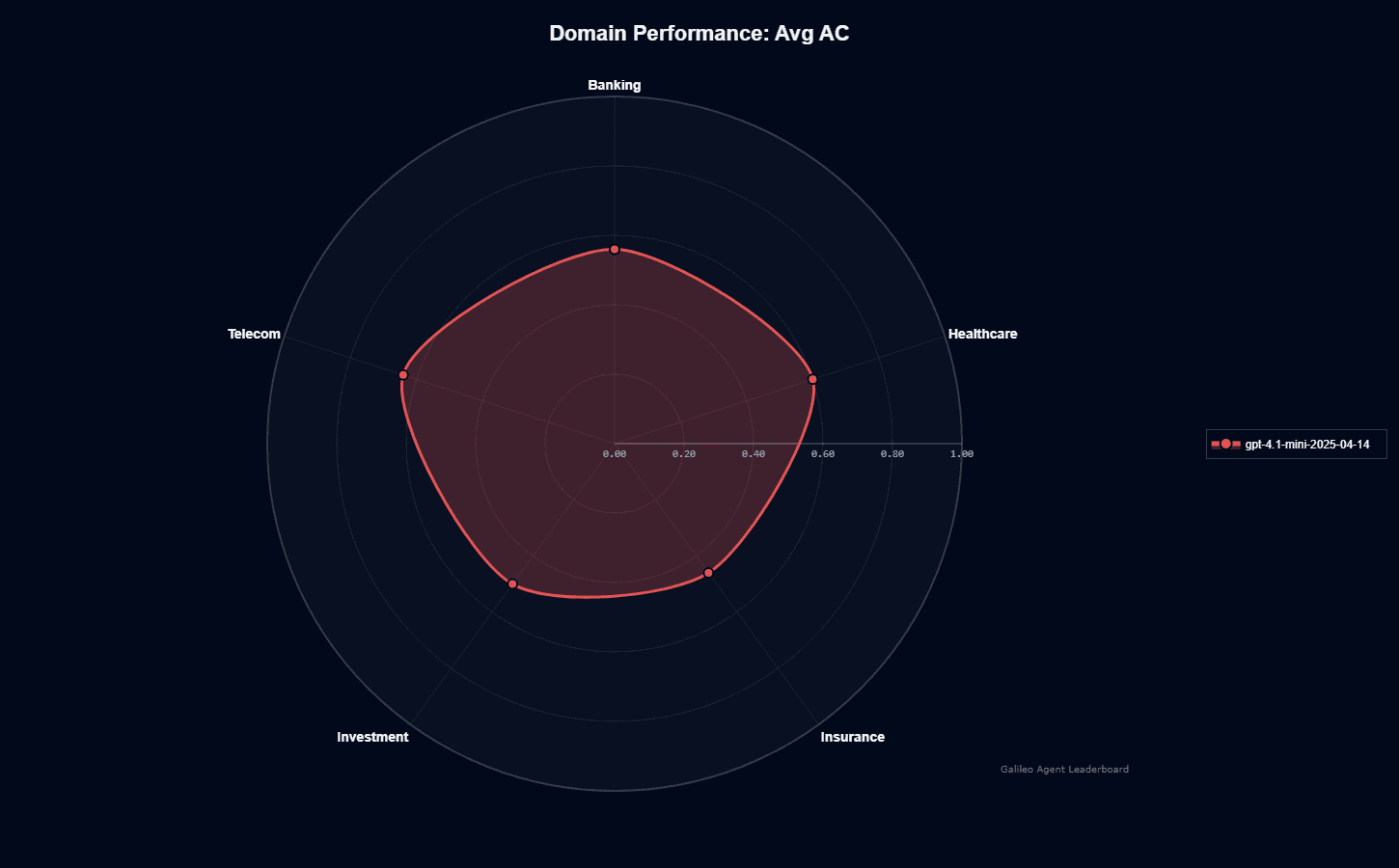
GPT-4.1-mini demonstrates notable variation across business domains, with Telecom leading at 0.640 action completion score. Healthcare follows at 0.600, indicating strong foundational capabilities for medical applications. Banking and Investment cluster in the mid-range at 0.560 and 0.500, respectively.
Insurance presents GPT-4.1-mini's most significant weakness, scoring only 0.460—substantially below performance in other sectors. This 28% gap between best (Telecom) and worst (Insurance) performance suggests the model's training data or optimization emphasized certain industry patterns over others.
The domain performance pattern reveals a technical model rather than an insurance-specialized one. Telecom and Healthcare benefit from structured, well-documented APIs and workflows that the model navigates effectively.
Insurance's complexity—involving nuanced risk assessment, policy interpretation, and regulatory compliance—appears to challenge GPT-4.1-mini more significantly than other domains.
For teams evaluating domain fit, Telecom and Healthcare implementations can proceed with confidence in the model's capabilities. Banking and Investment teams should anticipate solid but not exceptional performance.
Insurance teams face a critical decision: invest in significant prompt engineering and domain-specific fine-tuning, or evaluate insurance-specialized alternatives that better handle this sector's unique requirements.
GPT-4.1 mini domain specialization matrix
Action completion
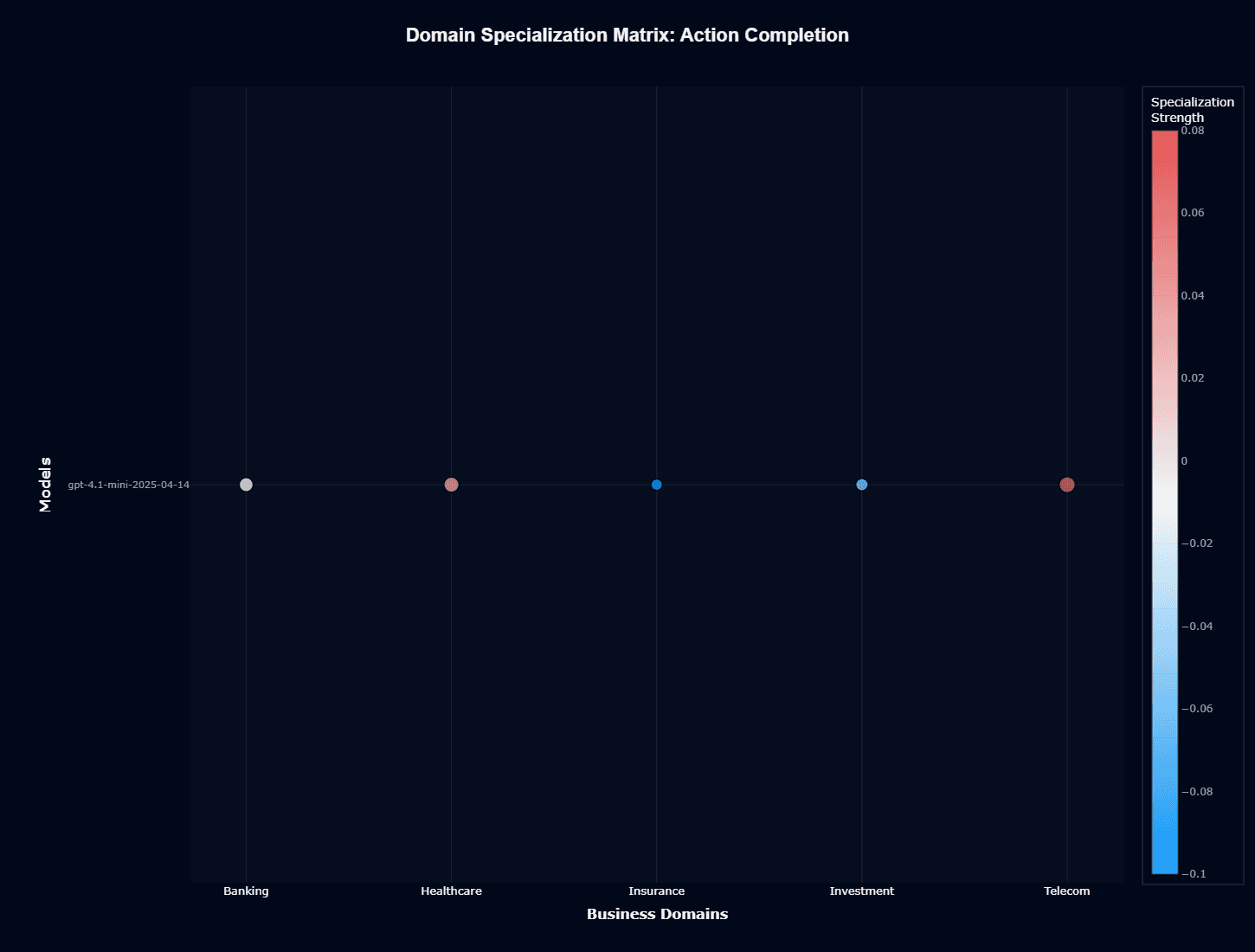
The domain specialization matrix reveals GPT-4.1-mini's relative strengths and weaknesses across sectors. Telecom demonstrates positive specialization (warm/red coloring), indicating the model performs above its baseline capabilities when handling telecommunications workflows.
Healthcare shows slight positive specialization as well, suggesting advantageous training data representation for medical contexts.
Insurance displays strong negative specialization (cool/blue coloring), confirming the model struggles disproportionately in this domain beyond what baseline performance would suggest. Banking and Investment remain largely neutral, indicating the model handles these sectors at its average capability level without particular advantages or disadvantages.
This specialization pattern likely reflects OpenAI's training data composition and optimization targets. Telecom's well-structured technical documentation and standardized protocols provide clear learning signals.
Healthcare benefits from extensive medical literature and clinical documentation in the training corpus. Insurance, with its domain-specific language, complex policy structures, and nuanced risk assessment requirements, may receive less representation or present more ambiguous training signals.
For development teams, these patterns suggest Telecom agents will benefit from the model's natural aptitude—minimal domain-specific prompt engineering required. Healthcare implementations should proceed confidently with standard best practices.
Insurance deployments demand substantial investment in custom prompts, extensive examples, and potentially retrieval-augmented generation (RAG) systems to compensate for the negative specialization bias.
Tool selection quality
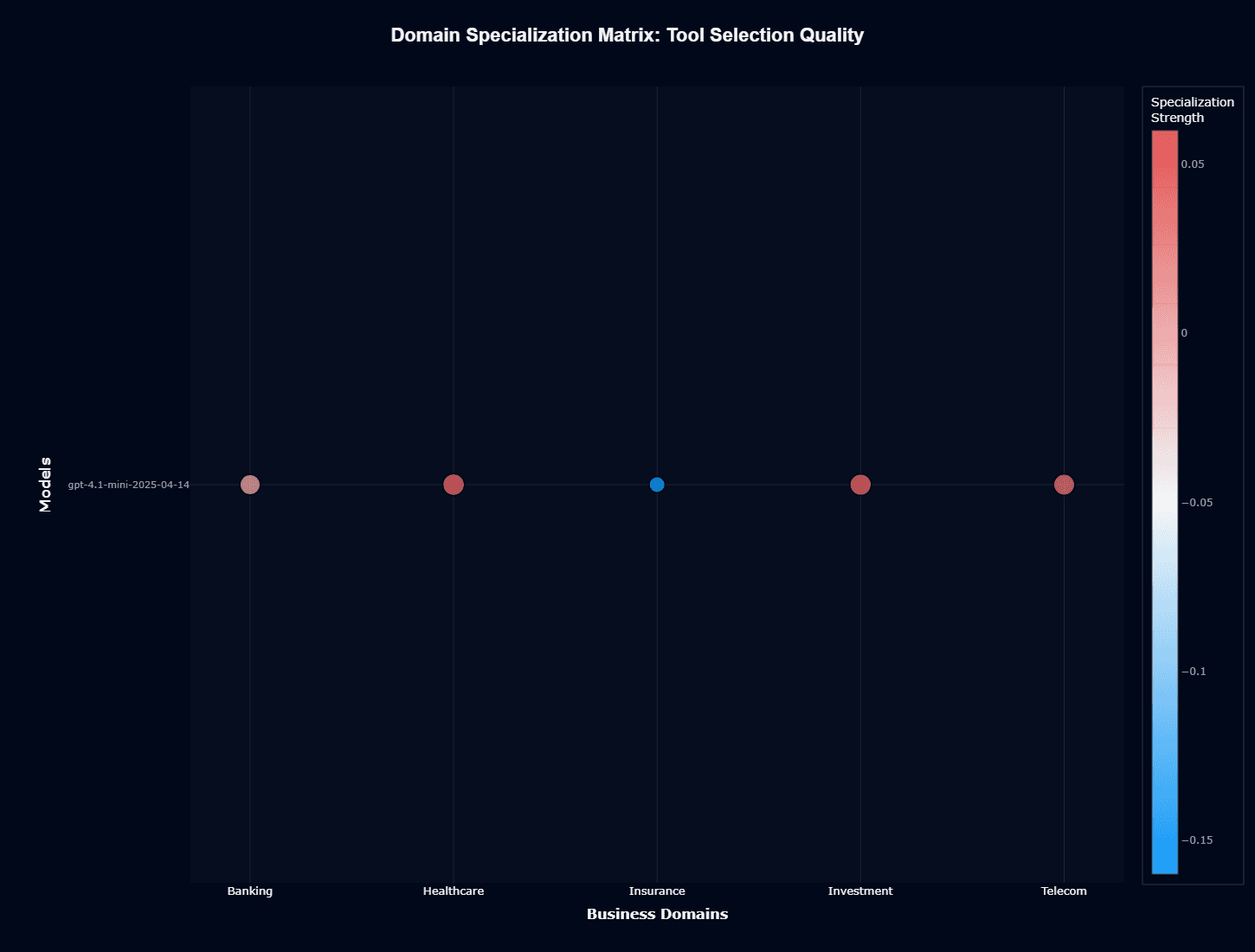
Tool selection quality specialization reveals a different capability profile. Healthcare, Banking, Investment, and Telecom all show positive specialization (warm/red coloring) for tool selection, indicating GPT-4.1-mini excels at choosing appropriate tools and APIs in these domains.
Insurance remains the outlier with negative specialization (cool/blue), suggesting tool selection challenges mirror broader action completion difficulties.
The widespread positive specialization for tool selection across four of five domains highlights an important insight: GPT-4.1-mini's training emphasized function calling and API interaction patterns common in business applications.
The model demonstrates a strong understanding of tool schemas, parameter requirements, and appropriate tool sequencing—critical capabilities for reliable agent deployment.
Insurance's negative tool selection specialization compounds its action completion challenges. The model struggles both with understanding what to do in insurance contexts and with selecting the right technical tools to accomplish those tasks. This double deficit requires comprehensive mitigation strategies.
For teams building agents, GPT-4.1-mini's strong tool selection across Healthcare, Banking, Investment, and Telecom enables confident deployment of multi-tool workflows. These domains can leverage extensive tool libraries without excessive validation overhead.
Insurance implementations require careful tool selection validation, potentially limiting tools to high-confidence subsets or implementing approval workflows before critical tool invocations.
GPT-4.1 mini performance gap analysis by domain
Action completion
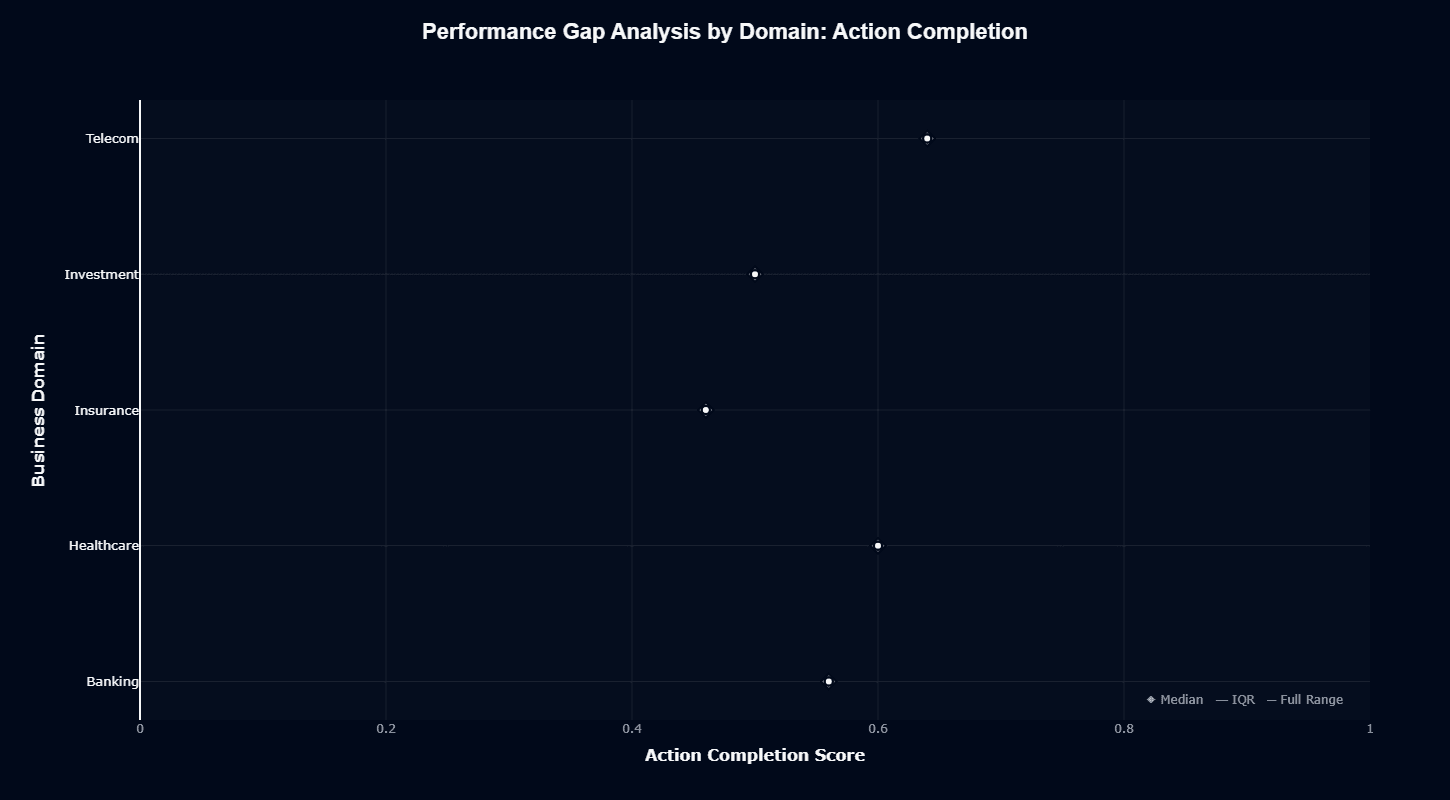
Performance gap analysis reveals the distribution and consistency of GPT-4.1-mini's action completion across domains. Telecom leads at approximately 0.64, followed closely by Healthcare at 0.60. Banking clusters around 0.56, Investment at 0.50, with Insurance trailing significantly at 0.46.
The narrow interquartile ranges (IQR) indicated by the minimal variance marks demonstrate consistent performance within each domain. GPT-4.1-mini doesn't exhibit wild swings in capability based on specific prompts or scenarios within a given sector—performance remains predictable and stable.
This consistency simplifies deployment planning significantly. Teams can establish domain-specific acceptance criteria with confidence that evaluation results will generalize to production behavior.
The tight variance also indicates thorough training coverage—the model encounters sufficient examples across scenarios within each domain to develop stable capabilities rather than memorizing specific patterns.
The 39% performance gap between Telecom (0.64) and Insurance (0.46) represents the critical planning consideration. Multi-domain enterprises cannot assume uniform performance across business units.
Telecom divisions will experience notably more reliable agent behavior than Insurance divisions, requiring differentiated quality assurance processes and potentially different oversight mechanisms.
Tool selection quality
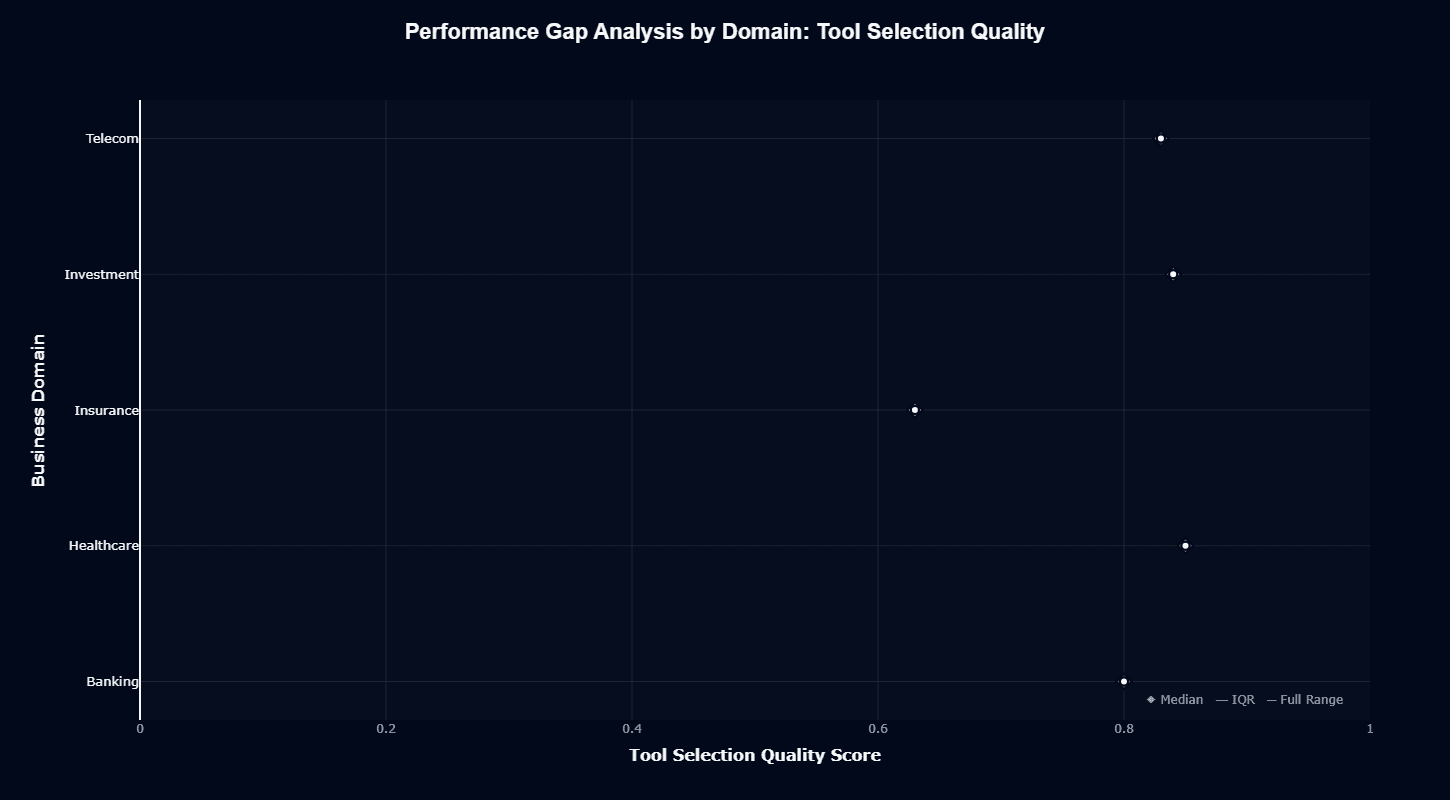
Tool selection quality shows dramatically tighter clustering across domains compared to action completion. Healthcare leads at approximately 0.85, followed by Investment at 0.83, Telecom at 0.80, Banking at 0.79, with Insurance bringing up the rear at 0.76.
The key insight: even the "weakest" domain still exceeds 0.76 tool selection quality—substantially higher than action completion minimums.
This compression reveals GPT-4.1-mini's core strength. The model excels at identifying appropriate tools regardless of domain context. The training emphasis on function calling and tool use translates into reliable API selection even in Insurance, where broader action completion struggles.
The narrow performance range (0.76-0.85) means teams can build agent architectures assuming strong tool selection across all domains. Unlike action completion, where Insurance requires special handling, tool selection reliability enables confident multi-tool workflows even in challenging sectors.
This architectural consistency simplifies agent design and reduces domain-specific customization overhead.
For production deployments, this pattern suggests a specific optimization strategy: focus improvement efforts on the inputs and context provided to tools rather than on tool selection logic itself.
GPT-4.1-mini rarely chooses the wrong tool—it more frequently struggles with constructing proper tool inputs or interpreting tool outputs correctly. Directing engineering resources toward parameter validation and output processing yields better returns than second-guessing the model's tool choices.
GPT-4.1 mini cost-performance efficiency
Action completion
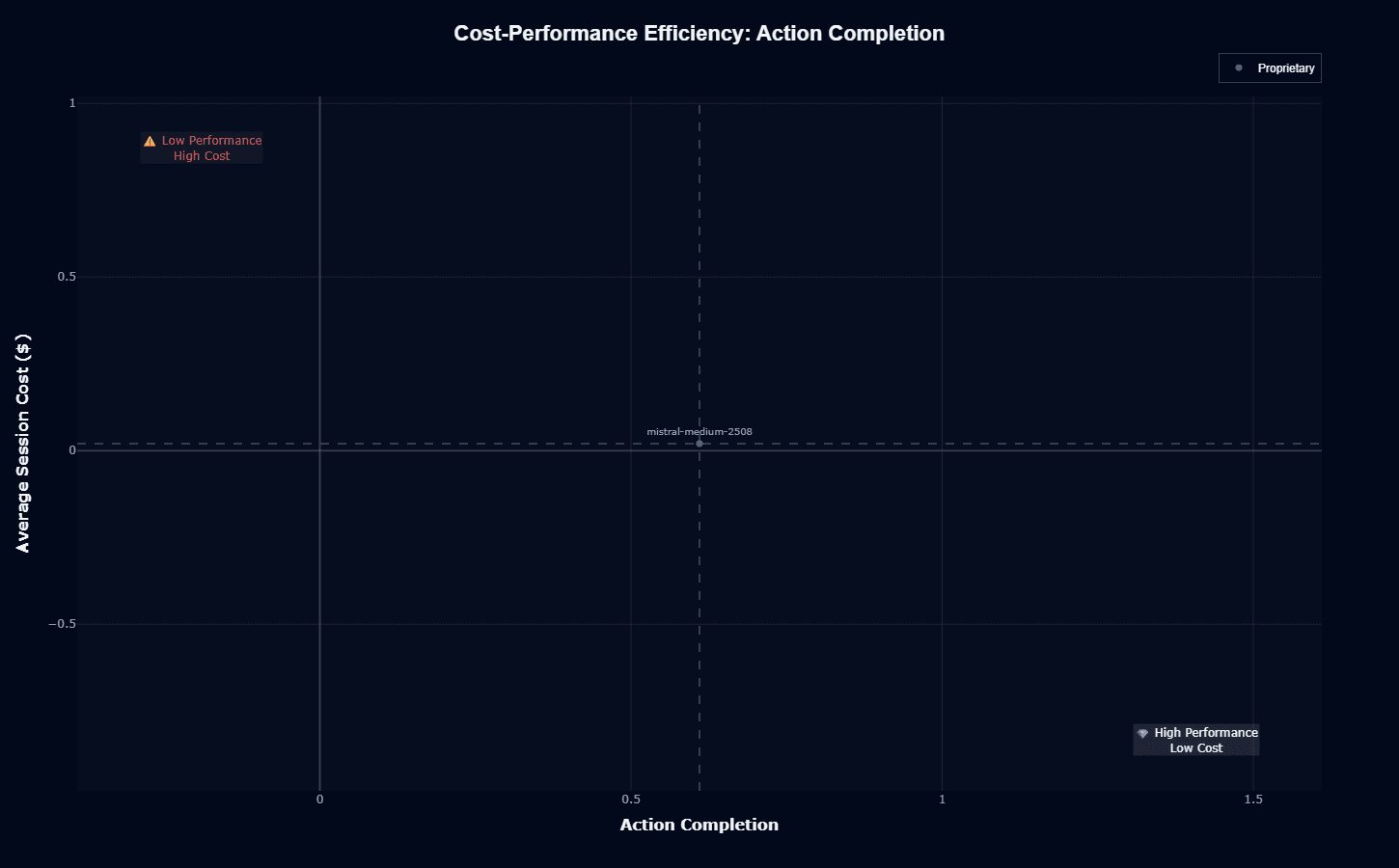
GPT-4.1-mini occupies an exceptional position in cost-performance space, sitting squarely in the "High Performance, Low Cost" ideal quadrant. At approximately $0.014 per session with 0.56 action completion, the model delivers competitive task execution at a price point that fundamentally changes agent deployment economics.
The cost advantage enables aggressive scaling strategies that aren't viable with premium models. At this pricing, enterprises can deploy agents across thousands of workflows, experimenting broadly to identify high-value automation opportunities without risking budget overruns.
The low cost also supports generous retry logic and validation passes—when agent execution costs $0.014, running each request through multiple validation steps remains economically sensible.
Compared to the efficiency frontier, GPT-4.1-mini sacrifices marginal action completion performance (not achieving the absolute highest scores) in exchange for dramatic cost reduction.
This tradeoff strongly favors high-volume deployments where aggregate cost matters more than peak performance on every individual interaction.
For enterprises processing millions of agent sessions monthly, the cost differential compounds into substantial budget savings that offset the occasional need for human intervention when the 0.56 action completion falls short.
The proprietary marker indicates GPT-4.1-mini represents OpenAI's commercial offering optimized specifically for production agent deployment at scale. The pricing strategy suggests OpenAI recognizes the primary barrier to widespread agent adoption is cost, not capability—GPT-4.1-mini removes that barrier decisively.
Tool selection quality
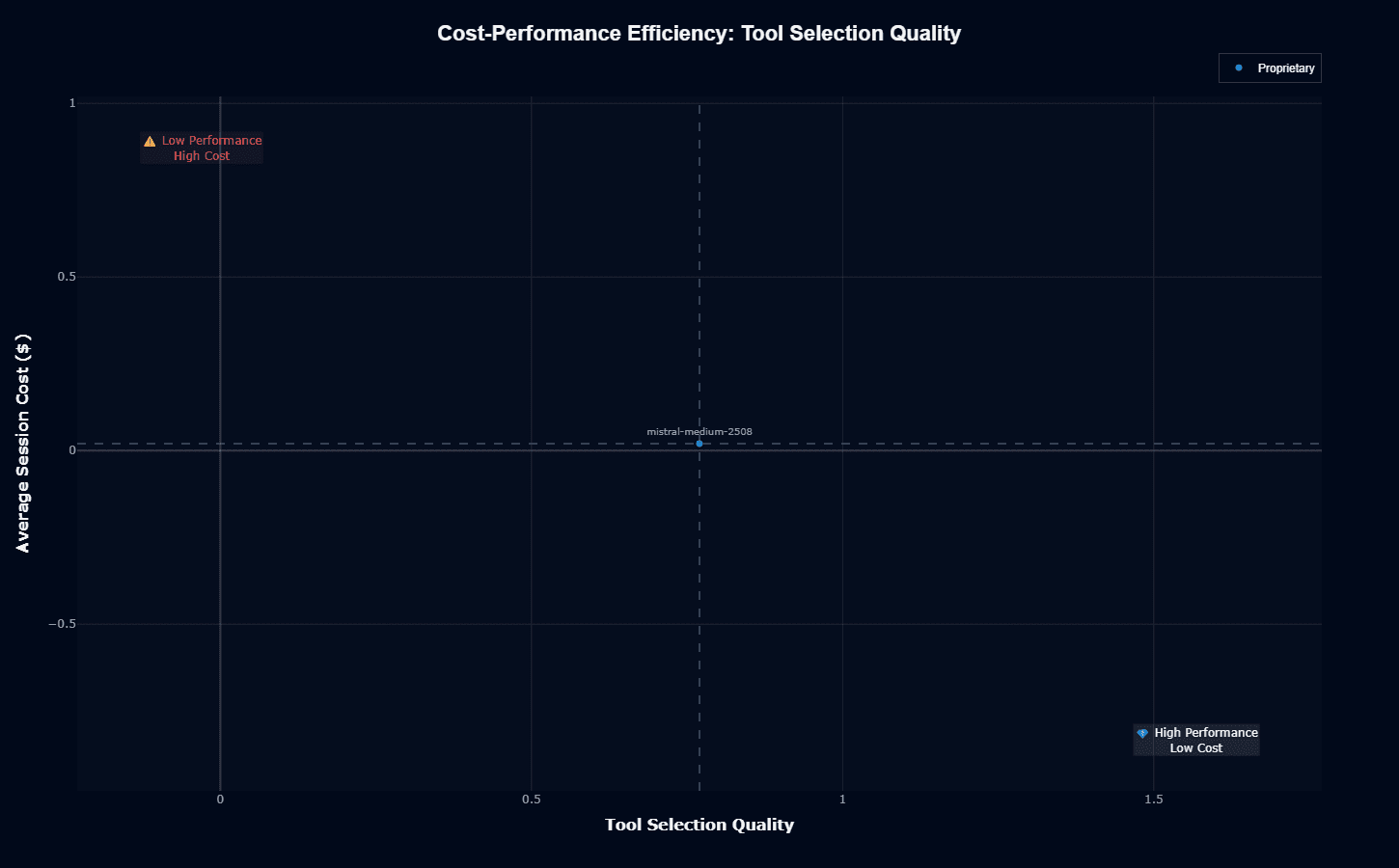
The tool selection efficiency view reinforces GPT-4.1-mini's value proposition. The model achieves 0.79 tool selection quality—approaching the top tier—while maintaining its exceptionally low $0.014 cost position.
This combination creates remarkable value for tool-intensive agent workflows.
Tool selection errors in agent systems cascade quickly. A single incorrect function call can trigger exception handling, retry logic, and eventually human escalation—effectively multiplying the cost of that interaction by 10x or more.
GPT-4.1-mini's 0.79 tool selection accuracy significantly reduces these cascade failures compared to lower-quality alternatives, making the economic value even greater than raw pricing suggests.
For teams building complex agents orchestrating dozens of tools, GPT-4.1-mini's position in this efficiency landscape is compelling. The model provides near-optimal tool selection at a fraction of premium model costs.
This enables agent architectures with expansive tool libraries—developers can expose comprehensive functionality without worrying that incorrect tool choices will inflate operational costs through retry penalties.
The cost-performance combination also enables a hybrid architecture strategy: use GPT-4.1-mini for most agent interactions to benefit from low cost and strong tool selection, reserving more expensive models only for the subset of interactions where action completion demands peak performance.
This tiered approach optimizes both cost and quality across the agent fleet.
GPT-4.1 mini speed vs. accuracy
Action completion
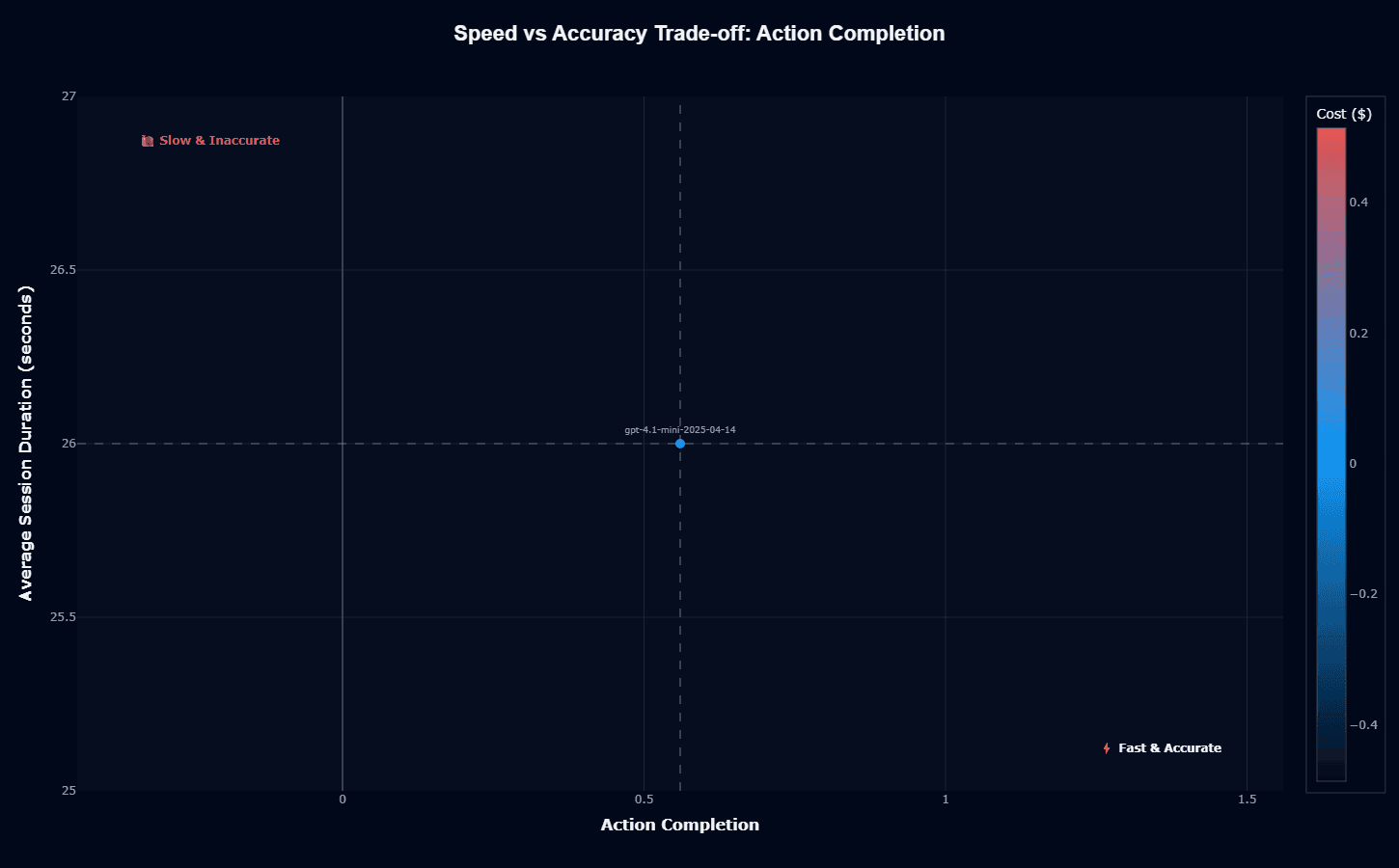
GPT-4.1-mini positions itself as the speed champion, delivering a 26-second average duration with 0.56 action completion. This places the model in the "Fast & Accurate" target quadrant—it achieves reasonable accuracy without the extended deliberation time that frustrates users and limits throughput.
The 26-second response time represents a significant advantage for user-facing agents where latency directly impacts experience. Users tolerate brief waits for complex tasks, but extended 60+ second pauses create abandonment risk and degraded satisfaction.
GPT-4.1-mini's speed profile supports fluid conversational experiences where agents feel responsive rather than ponderous.
Speed also enables higher agent throughput per infrastructure dollar. Faster inference means each server can handle more concurrent sessions, improving utilization rates and further amplifying the cost advantages.
For enterprises operating agent fleets at scale, the 26-second duration translates into infrastructure efficiency gains that compound the already favorable per-session pricing.
The tradeoff consideration: 0.56 action completion with a 26-second duration indicates the model has been optimized for quick responses over exhaustive reasoning. Teams requiring extended deliberation for complex multi-step planning may find the model rushes through decisions that benefit from more thorough analysis.
For those scenarios, GPT-4.1-mini's speed becomes a limitation rather than an asset, and slower but more deliberate alternatives may deliver better outcomes despite longer wait times.
Tool selection quality
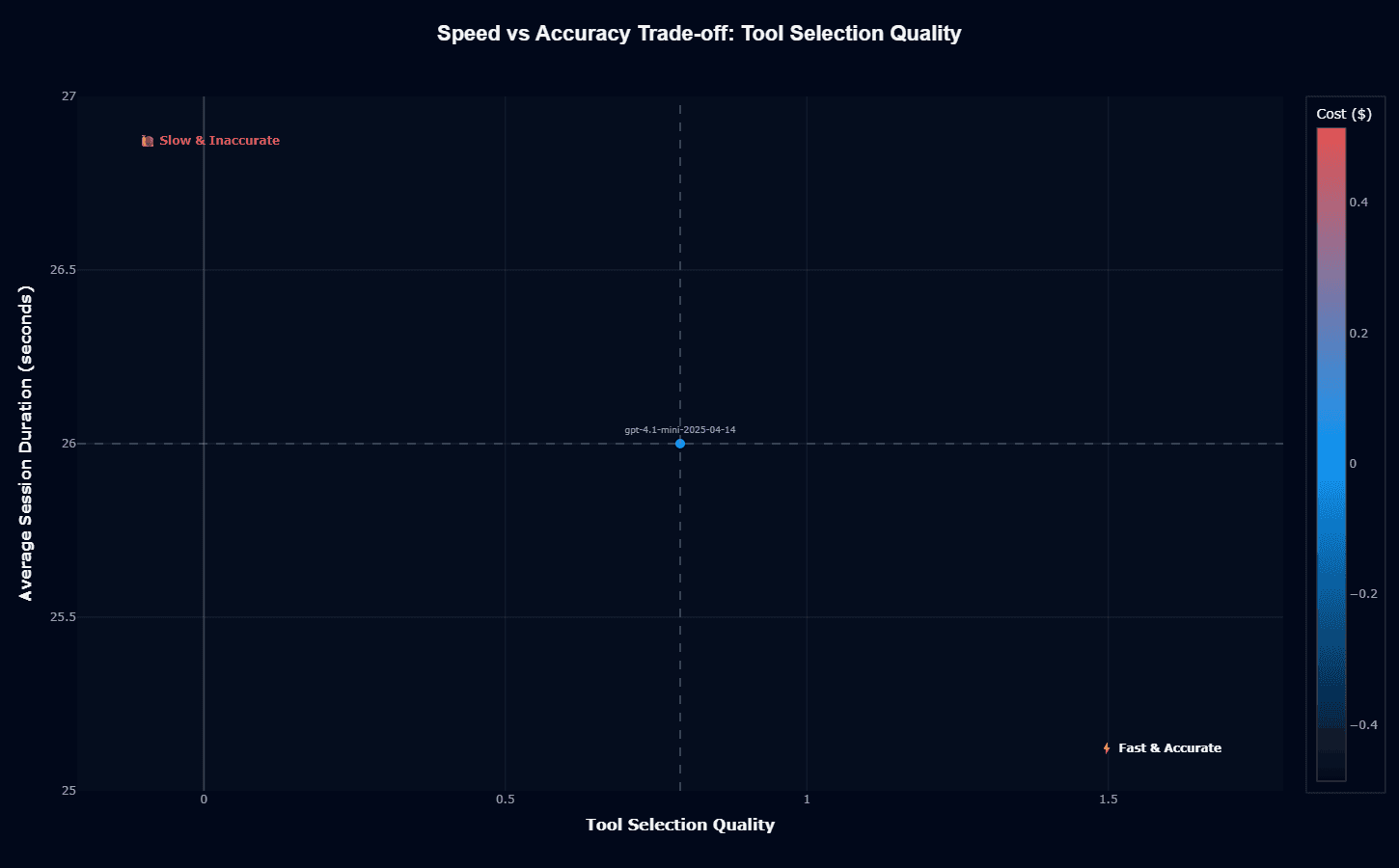
Tool selection quality maintains the same 26-second duration but shifts the accuracy axis to 0.79—demonstrating that GPT-4.1-mini achieves strong tool selection without requiring additional deliberation time.
The model makes good tool choices quickly, avoiding the analysis paralysis that plagues some systems when presented with large tool libraries.
This speed-accuracy combination for tool selection is particularly valuable in multi-step agent workflows. When agents need to sequence multiple tool calls to accomplish complex tasks, fast tool selection at each step keeps total latency manageable.
A system that deliberates for 60 seconds on each tool choice would create unacceptable delays in 5-step workflows, while GPT-4.1-mini's quick decision-making maintains reasonable total execution times.
The "Fast & Accurate" quadrant positioning indicates GPT-4.1-mini has internalized tool selection patterns effectively during training. The model doesn't need extended reasoning to identify appropriate functions—it recognizes tool applicability quickly and correctly.
This suggests a strong representation of tool use patterns in the training data, enabling pattern matching rather than deliberative reasoning for tool selection decisions.
Developers can confidently design agent architectures with extensive tool inventories, trusting that GPT-4.1-mini will navigate the options efficiently. The fast tool selection also supports iterative agent designs where tools are called speculatively or exploratorily—the low latency penalty makes trial-and-error tool strategies economically viable.
GPT-4.1 mini pricing and usage costs
GPT-4.1-mini represents OpenAI's most aggressive pricing strategy for a production-capable model. The pricing structure reflects the company's push to enable widespread agent deployment by removing cost as a primary barrier.
Standard pricing:
Input tokens: $0.40 per million tokens (~750,000 words)
Output tokens: $1.60 per million tokens
Context window: 1,000,000 tokens (1 million)
Average session cost: $0.014 (based on our benchmark data)
Cost optimization features:
Prompt caching: 75% discount on cached inputs ($0.10 per million cached tokens), delivering substantial savings for agents with fixed system prompts and tool definitions
Batch API: 50% additional discount for non-real-time workloads, enabling overnight processing at $0.20 input / $0.80 output per million tokens
No long-context surcharge: Unlike some competitors, the 1 million token context window incurs standard per-token costs without premium pricing for extended context
Economic comparison:
GPT-4.1-mini's $0.014 per average session represents a 91% cost reduction compared to Claude Sonnet 4's $0.154. For enterprises processing 10 million agent interactions monthly:
GPT-4.1-mini: ~$140,000 monthly
Claude Sonnet 4: ~$1,540,000 monthly
Savings: $1.4 million monthly or $16.8 million annually
With prompt caching optimized (typical for production agents with stable system prompts), costs drop further:
GPT-4.1-mini with caching: ~$50,000 monthly
Annual savings vs. Claude Sonnet 4: ~$17.9 million
This pricing enables aggressive agent deployment strategies previously reserved for only the most critical workflows. Teams can deploy hundreds of specialized agents, experiment extensively with prompt variations, and implement generous validation/retry logic without budget concerns dominating architectural decisions.
GPT-4.1 mini key capabilities and strengths
For your large-scale agentic deployments, GPT-4.1 Mini offers some key strengths:
Industry-leading speed: GPT-4.1-mini's 26-second average duration makes it the fastest model in our benchmark suite, delivering responses 61% faster than Claude Sonnet 4's 66.6 seconds. This speed advantage compounds across multi-turn conversations and high-volume deployments, improving both user experience and infrastructure efficiency.
Exceptional cost efficiency: At $0.014 per average session (91% cheaper than Claude Sonnet 4), GPT-4.1-mini fundamentally changes agent deployment economics. The pricing enables exploration, experimentation, and broad deployment across workflows that couldn't justify premium model costs.
1 million token context window: Unlike previous mini models capped at 128K tokens, GPT-4.1-mini supports the full 1 million token context shared across the GPT-4.1 family. This expanded window enables agents to process entire codebases, large document collections, or extensive conversation histories without truncation strategies that degrade performance.
Reliable long-context retrieval: Training optimizations ensure the model accurately retrieves and reasons over information across the full context window, not just recent tokens. This "needle in a haystack" capability enables agents working with comprehensive documentation or long-running sessions to maintain accuracy as context grows.
Strong tool selection across domains: Tool selection scores of 0.76-0.85 across all five business domains demonstrate reliable API calling and function orchestration. The model excels at identifying appropriate tools even in challenging contexts, reducing the validation overhead required for production deployment.
Telecom domain excellence: With 0.640 action completion and positive specialization, GPT-4.1-mini delivers best-in-class performance for telecommunications applications. Teams in this sector benefit from the model's natural aptitude for telecom-specific workflows, terminology, and technical patterns.
Healthcare competency: Second-place domain performance (0.600) combined with positive tool selection specialization makes GPT-4.1-mini well-suited for medical documentation, patient communication, and clinical workflow automation. The model demonstrates solid understanding of healthcare contexts without requiring extensive domain fine-tuning.
Enhanced instruction following: Internal OpenAI benchmarks show 49% instruction-following accuracy compared to GPT-4o's 29%, translating into more reliable agent behavior when processing complex multi-step commands. Agents follow specified procedures more faithfully, reducing unexpected behaviors that undermine trust.
Conversation efficiency: Averaging 3.4 turns per session, GPT-4.1-mini resolves queries more efficiently than alternatives requiring extensive iterative refinement. While not single-turn capable, the model balances thoroughness with efficiency to minimize frustrating back-and-forth exchanges.
GPT-4.1 mini limitations and weaknesses
While highly capable, GPT-4.1 Mini has specific constraints that teams should evaluate against their use case requirements:
Insurance domain underperformance: With 0.460 action completion (28% below Telecom's 0.640) and negative specialization in both action completion and tool selection, GPT-4.1-mini struggles significantly with insurance applications. Teams in this sector face substantial prompt engineering overhead or should evaluate insurance-specialized alternatives.
Moderate tool selection quality: While 0.790 overall tool selection represents solid performance, it trails specialized models achieving 0.90+ accuracy. High-stakes applications where incorrect tool calls create severe consequences may justify premium models with superior tool selection reliability.
Action completion limitations: The 0.560 action completion score indicates moderate execution quality—competitive but not industry-leading. Workflows requiring the highest completion rates may encounter more failures requiring human intervention or retry logic compared to peak-performing alternatives.
Not optimized for extended reasoning: The fast 26-second duration suggests optimization for quick responses rather than deep deliberation. Complex reasoning tasks requiring extended analysis may receive insufficient consideration, with the model rushing to conclusions that benefit from more thorough evaluation.
Conversation efficiency below expectations: The 0.69 conversation efficiency score (moderate in the heatmap) indicates room for improvement in resolving queries concisely. While a 3.4 average turns is reasonable, some alternatives achieve similar outcomes in fewer exchanges, reducing total latency and token consumption.
Investment domain weakness: Investment applications score only 0.500 in action completion, indicating challenges with financial instruments, portfolio analysis, and market dynamics understanding. Teams building investment advisory or trading agents should anticipate the need for extensive domain-specific prompt engineering or RAG systems.
Limited differentiation in banking: Banking performance of 0.560 matches the overall action completion average, indicating no particular advantage despite this sector's importance. Organizations expecting banking expertise comparable to Healthcare or Telecom capabilities will find generic rather than specialized performance.
Tool selection variance across domains: The 0.76-0.85 tool selection range, while compressed compared to action completion, still represents meaningful variance. Insurance's 0.76 floor means tool selection in this domain lags Healthcare's 0.85 ceiling by over 10%, requiring domain-specific validation strategies.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.