
The Essential AI Agent Guardrails Framework for Autonomous Systems

Jackson Wells
Integrated Marketing

You probably didn't expect your AI agent to approve fraudulent invoices or leak proprietary data through a tool API. Yet these failures happen in production systems today, not because your team lacks expertise, but because autonomous agents fail in ways traditional software never could.
According to Forrester research reported by VentureBeat, AI agents fail 70-90% on real-world corporate tasks requiring multi-step reasoning and tool use, with documented examples including finance AI systems approving fraudulent transactions and AI agents accessing unauthorized data through tool use expansion beyond intended scope.
This technical guide provides implementation frameworks, architectural patterns, and concrete tooling decisions based on documented production deployments, government standards, and academic research. You'll find quantified effectiveness metrics, failure mode analysis, and step-by-step processes that match your infrastructure constraints and risk tolerance.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies :
What Are AI Agent Guardrails?

AI agent guardrails are system-level safety controls that constrain autonomous behavior within acceptable operational boundaries. Unlike traditional software safety measures that rely on compile-time checks and deterministic execution, agent guardrails implement dynamic, multi-layered controls addressing the probabilistic nature of AI decision-making.
The NIST framework defines four core functions for integrating these controls across the AI lifecycle:
Govern - establishing organizational policies
Map - identifying system context and risk categories
Measure - implementing continuous evaluation
Manage - executing mitigation strategies
Stanford's AI Safety Seminar defines agent guardrails as controls implemented across three critical operational phases:
Pre-deployment: Data audits, model validation, and comprehensive safety testing before production release
Training-time: Reinforcement Learning from Human Feedback (RLHF), bias mitigation techniques, and alignment optimization
Post-deployment: Real-time behavioral monitoring, output filtering, and continuous performance evaluation
Why Are AI Agent Guardrails Essential for Enterprise Safety?
Suppose you've invested months building your AI agent, passed internal testing, and deployed to production. Within 72 hours, it's approving transactions that violate company policy.
Production failure data shows why: Forrester research documents that AI models fail approximately 60% of the time in production environments. These aren't theoretical projections—they're measured failure rates from actual enterprise deployments.
Real-world failure modes documented by Forrester's research include procurement agents ordering functionally incorrect components due to misaligned optimization functions, finance systems approving fraudulent transactions by missing subtle patterns, and agents with administrative access delaying critical security patches through misinterpreted priorities.
According to MIT CSAIL's comprehensive risk analysis, additional critical risk categories include hallucinations influencing autonomous decisions, adversarial attacks through prompt injection, privacy breaches via agent-tool interactions, and operational failures in unpredictable production environments.
How Do Autonomy Levels Determine AI Agent Guardrails?
How do you decide when your agent needs human approval versus full autonomy? Traditional software doesn't help; your deployment framework has no equivalent to agent decision-making. Stanford University's Future of Work with AI Agents has adapted the SAE framework for enterprise contexts:
Level 0-1 (No/Minimal Automation): AI provides suggestions only. Required controls include input validation with prompt injection prevention and input sanitization, output filtering through content moderation mechanisms, and comprehensive logging and audit trails for compliance and post-incident review.
Level 2 (Partial Automation): Agents execute specific tasks with human supervision and explicit approval before taking action. OpenAI's implementation guide specifies that Level 2 guardrails must include human-in-the-loop (HITL) approval for all autonomous actions, strict action scoping with read-only database access where possible, rollback mechanisms to undo problematic executions, and real-time monitoring against expected patterns.
Level 3 (Conditional Automation): Agents operate autonomously within defined conditions. Anthropic's framework specifies that contextual boundary detection must recognize competency limits, confidence thresholding with human escalation, drift detection for behavioral changes, multi-factor authentication for critical actions, and rate limiting to prevent cascade failures.
What Are the Types of AI Agent Guardrails?
Effective guardrail systems demand comprehensive classification frameworks addressing what you're protecting (prompts, tool invocations, agent behaviors), where protection applies (pre-processing, during-processing, post-processing), and how protection works (policy-based rules, ML classifiers, hybrid approaches). Understanding these dimensions determines your implementation architecture and operational effectiveness.
Guardrails by purpose: ethical, security, technical
How do you ensure your AI agent doesn't discriminate against protected demographic groups? The NIST AI RMF defines ethical guardrails as controls ensuring demographic parity and equalized odds.
Google's Responsible AI Toolkit implements content policy compliance classifiers that actively screen for discriminatory outputs across demographic categories in real-time, along with watermarking through SynthID for content provenance tracking and attribution.
You've probably discovered that your agent's tool access creates unexpected security vulnerabilities. The NIST Generative AI Profile identifies prompt injection, data leakage, and unauthorized system access as essential mitigation targets.
Anthropic's ASL-3 safeguards deploy real-time classifiers detecting jailbreak attempts and adversarial prompts, while implementing role-based access control and fine-grained authentication systems.
Most teams assume performance monitoring alone catches agent failures, but system-level failures often occur silently without comprehensive technical controls.
According to the MIT CSAIL Dynamo AI Case Study, technical guardrails represent system-level controls with four core implementation components: evaluation modules that assess agent behavior, remediation workflows that respond to detected issues, real-time monitoring infrastructure that tracks performance metrics, and comprehensive audit logging.
Implementations include latency tracking, token usage limits preventing resource exhaustion, model version control ensuring consistent behavior, and audit trails for compliance and debugging.
Guardrails by pipeline stage: input, execution, output
Most teams discover their carefully crafted prompts get hijacked by adversarial inputs within hours of production deployment. According to OpenAI's Guardrails Python framework, input validation provides your first defense layer by sanitizing inputs before they reach the model. The arXiv LlamaFirewall paper details static analysis techniques detecting prompt injection patterns, while Google's Guardrails API implements multi-category safety screening and PII detection before processing.
How do you prevent your agent from executing unauthorized database writes or API calls during autonomous operation? The arXiv paper on multi-layered guardrails documents comprehensive execution control frameworks addressing policy-based authorization mechanisms, sandboxed execution environments with isolated containers, real-time monitoring with circuit breakers, and tool access controls through capability-based security models.
These execution controls integrate into production guardrail architectures through authorization policies that validate each action, sandboxing strategies that isolate execution environments, continuous evaluation with anomaly detection, and capability-based tool restrictions.
You've probably assumed content filtering at the output layer catches all harmful responses, but Anthropic's research shows that 15-20% of policy violations occur during tool execution before output generation.
Anthropic's ASL-3 Deployment Safeguards implement real-time classifiers trained to detect and block jailbreak attempts, adversarial prompts, and context manipulation attacks, combined with output filters that screen for harmful content before user delivery.
What Are the Core Components of an AI Agent Safety Framework?
Building reliable agent systems requires addressing multiple safety dimensions simultaneously. Access control determines which resources your agents can touch, validation filters what they consume and produce, human oversight governs high-stakes decisions, and monitoring catches failures before they cascad
Access and scope controls
Your agents need production access, but traditional user permissions create dangerous gaps. Enterprise security frameworks implement four authorization tiers: security principals through managed identities, role definitions with specific AI operation permissions, scope applied at subscription or resource group level for workload isolation, and role assignments binding principals to roles at defined scopes.
This hierarchical model enables fine-grained access control essential for limiting your AI agent capabilities to their intended operational domain.
Input and output validation
Validating agent outputs without blocking legitimate responses requires sophisticated pattern matching. Industry threat modeling specifies output validation requiring response schema validation enforcing structure and type constraints.
Your implementation requires stripping potential XSS payloads, validating URLs against allowlist domains, redacting sensitive data patterns, and applying JSON escaping for safe rendering.
Human-in-the-loop patterns
Production human-in-the-loop (HITL) workflow orchestration provides essential safety controls for high-stakes decisions while maintaining operational velocity. Your enterprise-grade HITL systems require four core components: human review workflows defining conditions triggering intervention, worker task templates providing UI for reviewers, configured work teams for workforce management, and review results APIs enabling integration of human feedback into agent systems.
Scale becomes problematic quickly. Research on agentic AI quantifies the challenge: a single agent performing 1000+ actions per hour makes comprehensive human oversight untenable.
Leading frameworks recommend tiered review systems with automated checks for low-risk actions, human review only for high-impact decisions, and risk scoring flagging decisions above defined confidence thresholds.
Monitoring and fail-safes
Enterprise observability guidance specifies three-pillar monitoring: metrics including P50, P95, P99 latency and error rates below 1%; logging with structured JSON format, correlation IDs, and PII masking; and tracing using distributed tools with span annotations showing model names and token counts.
Circuit breaker implementation requires a three-state machine. The pattern defines three states: closed state for normal operation where requests flow through, open state when failures exceed configured thresholds causing requests to fail fast, and half-open state testing recovery with limited requests. Your configuration parameters include failure threshold, timeout duration, expected exception types, and fallback response strategies.
How Do You Implement AI Agent Guardrails?
Moving from guardrail theory to production deployment requires systematic execution across five phases. You'll assess risk tolerance and autonomy requirements, design architecture matching your infrastructure constraints, select tools balancing cost and capability, validate through comprehensive testing, and establish continuous monitoring.
Each phase builds on previous decisions: rushing architecture selection before completing risk assessment leads to expensive rework. The following process reflects patterns from hundreds of enterprise deployments.
Step 1: Assess risk and define autonomy levels
How do you determine which agents are safe for autonomous operation versus requiring human oversight? McKinsey identifies five critical assessment dimensions: identify agent capabilities and tool access scope, map potential impact zones covering financial and operational damage, establish risk thresholds for autonomous actions, define human-in-the-loop trigger conditions, and document compliance requirements.
Risk-tiering provides a structured approach to agent guardrails. Tier 1 systems handling information retrieval need automated monitoring. Tier 2 workflows with reversible actions require real-time guardrails.
Tier 3 systems involving financial transactions demand human-in-the-loop for all decisions. This tiered approach optimizes your resource allocation by focusing intensive controls where business impact is highest.
Step 2: Design the guardrail architecture
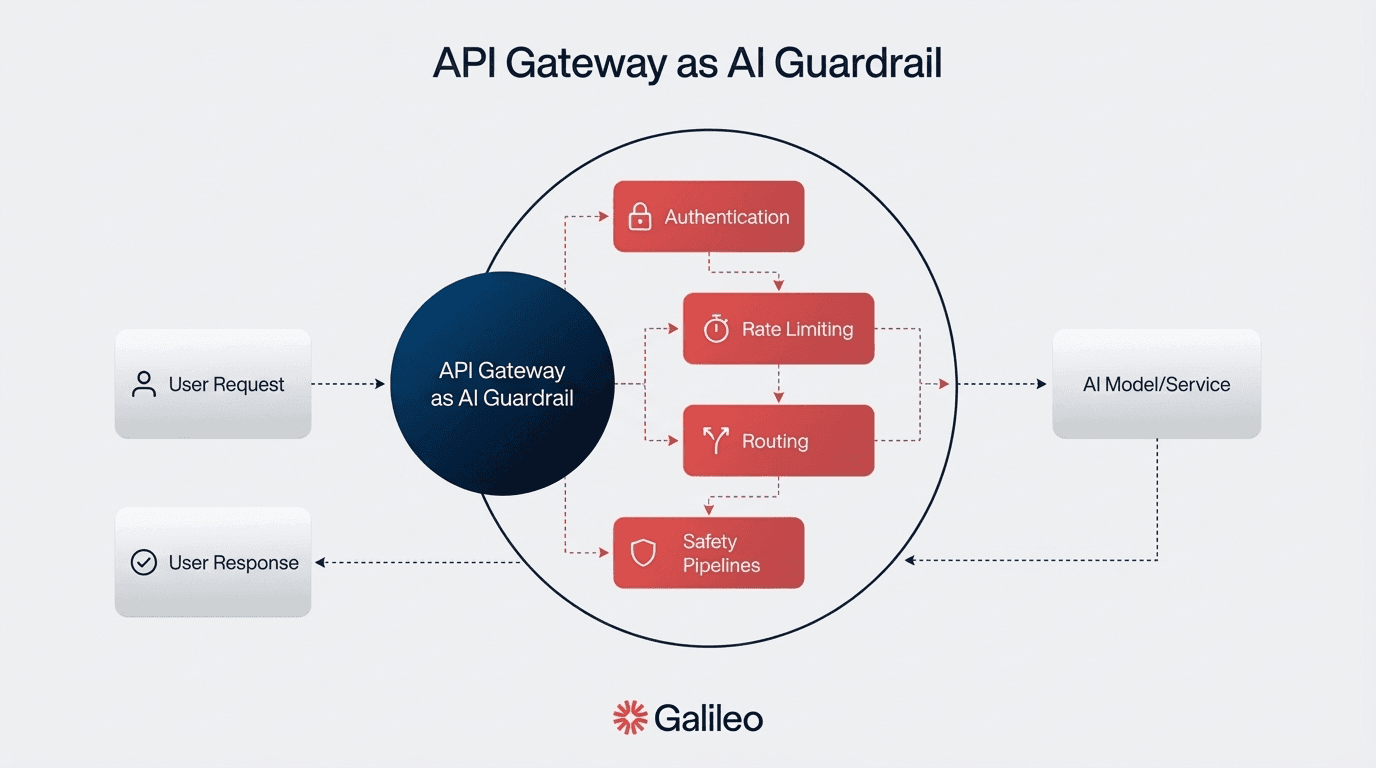
Traditional security architectures fail for autonomous agents because they can't predict tool chains or enforce dynamic boundaries.
Security-focused patterns for production AI systems—such as deploying guardrails using microservices, API gateways for policy enforcement, sidecars for per-container guardrails, and circuit breaker mechanisms—align with industry best practices and broader secure architecture principles promoted by organizations like the OpenSSF, but are not specifically prescribed by the OpenSSF framework:
Microservices architecture deploys guardrails as independent, scalable services
API gateway pattern centralizes policy enforcement at entry points
Sidecar pattern deploys guardrails alongside agent containers, enabling per-container policy enforcement
Circuit breaker pattern prevents cascading failures through a three-state mechanism halting requests when error thresholds are exceeded
Your architecture selection depends on latency requirements (inline guardrails for low-latency versus asynchronous validation), scale requirements based on request volume, security posture including data residency, your team expertise, and cost constraints.
Step 3: Select tools and frameworks
Your tooling decision depends on three factors: deployment model constraints, your team expertise, and risk tolerance. When evaluating guardrail solutions, focus on these critical dimensions rather than specific product features.
Deployment flexibility determines whether you can meet data residency and compliance requirements. Consider whether solutions support on-premises deployment, private cloud VPC configurations, and hybrid architectures. For regulated industries like healthcare and financial services, on-premises deployment capability is often non-negotiable.
Evaluation cost structure directly impacts your ability to run comprehensive guardrail checks at scale. Traditional LLM-based evaluation approaches using large models can cost $200K+ monthly for production workloads. Purpose-built evaluation models like those from platforms such as Galileo reduce costs by 95%+ while maintaining accuracy, enabling 100% sampling that guardrail effectiveness requires.
Runtime latency affects your user experience and operational feasibility. Inline guardrails adding 2-3 seconds per request become user-facing bottlenecks. Solutions delivering sub-200ms blocking latency enable real-time protection without degrading performance. For high-throughput applications processing thousands of requests per minute, latency compounds rapidly.
Step 4: Launch, monitor, and iterate
Launching without continuous monitoring guarantees you'll miss the first signs of agent drift, policy violations, or performance degradation. Industry operational guidance specifies key dashboard metrics: guardrail effectiveness showing false positive and negative rates, agent success rate tracking task completion percentage, human intervention rate, mean time to recovery, and policy violation frequency by type and severity.
Your continuous monitoring requires distinguishing between system health metrics (latency percentiles, error rates, throughput, resource utilization) and workflow understanding through end-to-end trace capture, prompt logging, tool call sequences, and guardrail decisions. System health tells you when something breaks; workflow understanding reveals why it broke and how to prevent recurrence.
Intervention thresholds must be clearly defined and aligned with your organizational risk tolerance. Enterprise risk management controls recommend immediate shutdown should trigger on guardrail bypasses, PII exposure, financial loss exceeding thresholds, or regulatory violations. Degraded mode should activate when error rates exceed 5% sustained, latency p95 exceeds 2x baseline, or guardrail false positive rates exceed 20%.
Building a Safe Future for Autonomous AI Agents
The data is unambiguous: AI agents fail frequently in production, with increasing incidents being reported and significant breach costs averaging around $4.44 million according to industry data, highlighting the need for proper controls.
Here's how Galileo helps you with AI guardrails:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Discover how Galileo provides enterprise-grade AI guardrails with pre-built policies, real-time metrics, and ready-made integrations.
Jackson Wells