
Banking today is about more than transactions and account balances. It is about delivering seamless, personalized experiences at scale. From reporting a lost credit card to setting up mortgage payments and exchanging foreign currency, customers expect instant, accurate support in a highly regulated environment. AI agents powered by LLMs are stepping into this role, automating complex workflows and ensuring consistency across every interaction.
Choosing the right LLM for your banking agent can mean the difference between a satisfied customer and a costly failure. In our Agent Leaderboard v2 we explore the top-performing models for banking as a domain, share key insights, and consider what these findings mean for deploying AI assistants in finance.
→ Explore the Live Leaderboard
Banking Agents in Action
Banks today confront the dual challenge of meeting digital-first customer expectations and adhering to stringent regulatory requirements. At the same time, fraud schemes and compliance mandates grow increasingly complex. AI agents promise to handle everything from lost-card reports to multi-step loan servicing, orchestrating workflows while ensuring adherence to evolving regulations. Across the industry, leading banks have deployed AI assistants that deliver real-world impact.

Wells Fargo’s Fargo
Wells Fargo’s virtual assistant Fargo, powered by Google’s Flash 2.0 model, surpassed 245 million interactions in 2024 and continues to handle tasks from card controls to transaction searches with built-in privacy safeguards. In 2025, it remains on track for over 100 million interactions annually, demonstrating strong adoption for secure, efficient customer support.
Bank of America’s Erica
Bank of America’s virtual assistant Erica has handled over 2.5 billion client interactions since its launch, serving more than 20 million active users. It assists with balance inquiries, bill payments, fraud alerts, and personalized financial insights. Erica’s proactive notifications and conversational guidance drive faster resolutions and boost digital engagement, with expansions in 2025 including enhanced generative AI features.
Royal Bank of Canada’s NOMI
Royal Bank of Canada’s NOMI provides personalized insights, budgeting tools, and predictive savings features, delivering over 2 billion insights and helping customers save more than $3.6 billion. NOMI analyzes cash flow, categorizes transactions, and sends notifications, boosting household savings rates significantly through its "Find & Save" option in 2025.
Commonwealth Bank’s Ceba
Commonwealth Bank’s Ceba handles over 200 banking tasks, including card activation, balance checks, and payments, managing 60% of incoming contacts end-to-end. Available 24/7, Ceba processes 550,000 queries monthly, promotes clean energy initiatives, and offers educational guidance, enhancing customer self-service in 2025.
Citi’s Citi Bot SG
Citi’s Citi Bot provides real-time support within the mobile app, handling account balances, transactions, payments, and personalized insights using AI and machine learning. In 2025, it is expanding with generative AI tools like Agent Assist and enhanced IVR systems to improve query resolution and security.
Ally Bank’s Ally Assist
Ally Bank’s Ally Assist offers 24/7 voice and text support for transfers, payments, deposits, and spending insights using machine learning and NLP. Recent updates include features to research product prices and ratings, providing predictive advice on investments and expenditures.
PenFed Credit Union’s Einstein
PenFed Credit Union is implementing Einstein, a generative AI virtual assistant, to streamline communications by suggesting responses for service representatives. This 2025 rollout emphasizes enhanced customer experiences through faster, more accurate support in compliance-sensitive workflows.
Takeaways:
AI agents automate high-volume, repeatable tasks and reduce error rates in legal and financial workflows.
Virtual assistants like Erica and Ceba achieve billions of interactions and insights, demonstrating strong user adoption.
Internal and customer-facing tools drive productivity, savings, and compliance without increasing risk.
Real World Failures of AI Support Agents
AI support agents have shown remarkable promise but also exposed critical weaknesses in real-world deployments. In banking and beyond we’ve seen AI replacements backfiring so badly that firms had to rehire humans, conversational bots propagating hateful content within hours, chatbots making glaring factual errors raising red flags over legal compliance. These failures underscore the importance of robust guardrails, human oversight and thorough testing before entrusting AI with customer-facing workflows.
Klarna’s AI Replacement Reversal
Klarna replaced 700 customer-service employees with AI-powered systems only to admit that service quality plunged and customer satisfaction collapsed (The Economic Times). Within months the fintech giant announced it would rehire humans to patch the gaps left by its automated agents (Tech.co). In a separate analysis, testers found ways to confuse Klarna’s bot in unexpected scenarios, revealing brittle handling of edge-case queries.
IBM Watson for Oncology’s Clinical Missteps
IBM marketed Watson for Oncology as a revolutionary tool for recommending cancer treatments, but internal reviews revealed it often gave unsafe or incorrect advice to clinicians (Healthcare Dive). The failure eroded trust among healthcare providers and led to the dissolution of partnerships with leading cancer centers.
Regulatory Concerns for Banking Chatbots
U.S. consumer watchdogs have warned that poorly designed banking chatbots can violate debt-collection and privacy laws, exposing banks to legal risk (PBS). Regulators flagged inconsistent disclosures and incorrect information as major failure modes in AI-driven customer support.
Citi’s Warning After Early Experiments
Citi executives have publicly cautioned that deploying generative AI for external customer support “can go wrong very quickly,” delaying the bank’s own plans for an external-facing chatbot (QA Financial). Their stance reflects a broader industry hesitancy rooted in early failure case studies (QA Financial).
These high-profile failures remind us that AI agents require rigorous evaluation, transparent error-handling strategies and seamless human-in-the-loop integrations to prevent costly breakdowns in customer-facing applications.
The Role of AI in Banking Agents
In the banking domain, user interactions with AI agents often involve complex, multifaceted queries that combine multiple tasks into a single conversation. These requests typically stem from urgent personal or business needs, such as travel preparations, fraud concerns, or financial planning. Based on analysis of real-world user personas and interactions, common request types include:
Fraud and security actions: Reporting lost or stolen cards, disputing unauthorized transactions, and setting up fraud alerts. These are frequent, with users often providing specific details like transaction amounts, dates, and merchants.
Funds transfers: Moving money between accounts, to family members, or internationally via wires. Requests may specify currencies, deadlines, and recipient details, including routing numbers or IBANs.
Status checks: Verifying the progress of transfers, loan applications, payments, or deposits. Users expect precise confirmations, often referencing IDs or dates.
Payment setups: Configuring automatic bill payments for mortgages, utilities, loans, or recurring expenses, with varying amounts, frequencies, and start dates.
Information updates: Changing contact details like phone numbers, addresses, or emails, sometimes with temporary changes for travel.
Appointments and consultations: Scheduling meetings with specialists for loans, investments, or refinancing, often with preferred times or advisors.
Currency and location services: Obtaining exchange rates, converting funds, or locating branches/ATMs, especially for international travel.
Product research: Inquiring about loans, CDs, savings accounts, or credit cards, including comparisons of rates, terms, and eligibility.
What makes these requests difficult for AI agents includes:
Multi-task bundling: Users frequently combine 4-7 unrelated goals in one initial message, requiring the agent to parse, prioritize, and sequence actions while maintaining context.
Urgency and deadlines: Many queries involve time-sensitive elements, like transfers before flights or payments by specific dates, increasing the risk of errors under pressure.
Sensitive data handling: Requests involve PII, account numbers, and financial details, demanding strict compliance with GDPR or PCI DSS, along with secure verification processes.
Growing regulatory pressure: Frameworks like SR11-7 (U.S. Federal Reserve guidance on model risk management) and the EU AI Act impose increasing demands for robust, transparent, and explainable AI systems. LLM-based AI agents are inherently black-box models, making it challenging to provide the required interpretability, auditability, and risk mitigation.
Ambiguity and edge cases: Incomplete details (e.g., missing account numbers) or ambiguous instructions require clarification without frustrating users, while handling international variations in currencies, time zones, and locations adds complexity.
Interdependencies: Tasks often depend on others, such as confirming a transfer before making another or checking balances before approving investments, necessitating logical reasoning and tool orchestration.
Human-like interaction: Users expect empathetic, conversational responses in a regulated environment, where errors could lead to financial loss or compliance violations.
To ensure reliable, compliant performance, addressing these challenges requires LLMs that excel in tool selection, context retention, and error handling.

What Is the Agent Leaderboard?
The Agent Leaderboard v2 is a publicly accessible ranking of 17 leading language models tested on realistic, multi-turn enterprise scenarios across five industries: banking, healthcare, investment, telecom and insurance Galileo AI. Unlike academic benchmarks focusing on one-off tasks, it simulates back-and-forth dialogues with synthetic personas, reflecting the complexity of real customer interaction. Each agent has access to domain-specific tools and is scored on how effectively it navigates them to solve user problems. Results are updated monthly so you can always compare the latest models and variants.
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
https://galileo.ai/agent-leaderboard
Banking-Domain Challenges
Deploying an AI agent in banking requires careful planning and robust technology. Key challenges include:
Regulatory compliance
Models must respect strict data-privacy requirements and maintain audit trails for every action.Multi-step transactions
A single conversation might involve reporting a lost card, querying a mortgage schedule and booking a foreign exchange order.Context preservation
Agents must carry context across turns, coordinating tool calls to internal APIs or external services without losing track of user goals.Latency sensitivity
Customers expect near-real-time responses. Prolonged delays undermine trust and drive users to call human support.Error handling
Edge cases and ambiguous requests require clear validation steps and fallback logic to avoid incomplete or incorrect operations.
Understanding these challenges helps us interpret the performance metrics and choose models that balance capability, cost and responsiveness.
Evaluation Criteria

Our analysis focuses on four core metrics drawn from the Agent Leaderboard v2 benchmark:
Action Completion (AC)
Measures end-to-end task success. Did the agent fulfill every user goal in the scenario?Tool Selection Quality (TSQ)
Captures precision and recall in selecting and parameterizing the correct APIs. High TSQ means fewer unnecessary or erroneous calls.Cost per Session
Estimates the dollars spent per complete user interaction. Balancing budget constraints with performance needs is critical for high-volume deployments.Average Session Duration
Reflects latency and turn count. Faster sessions improve user experience but may trade off thoroughness.
With these metrics in mind, let us explore the standout models for banking agents.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
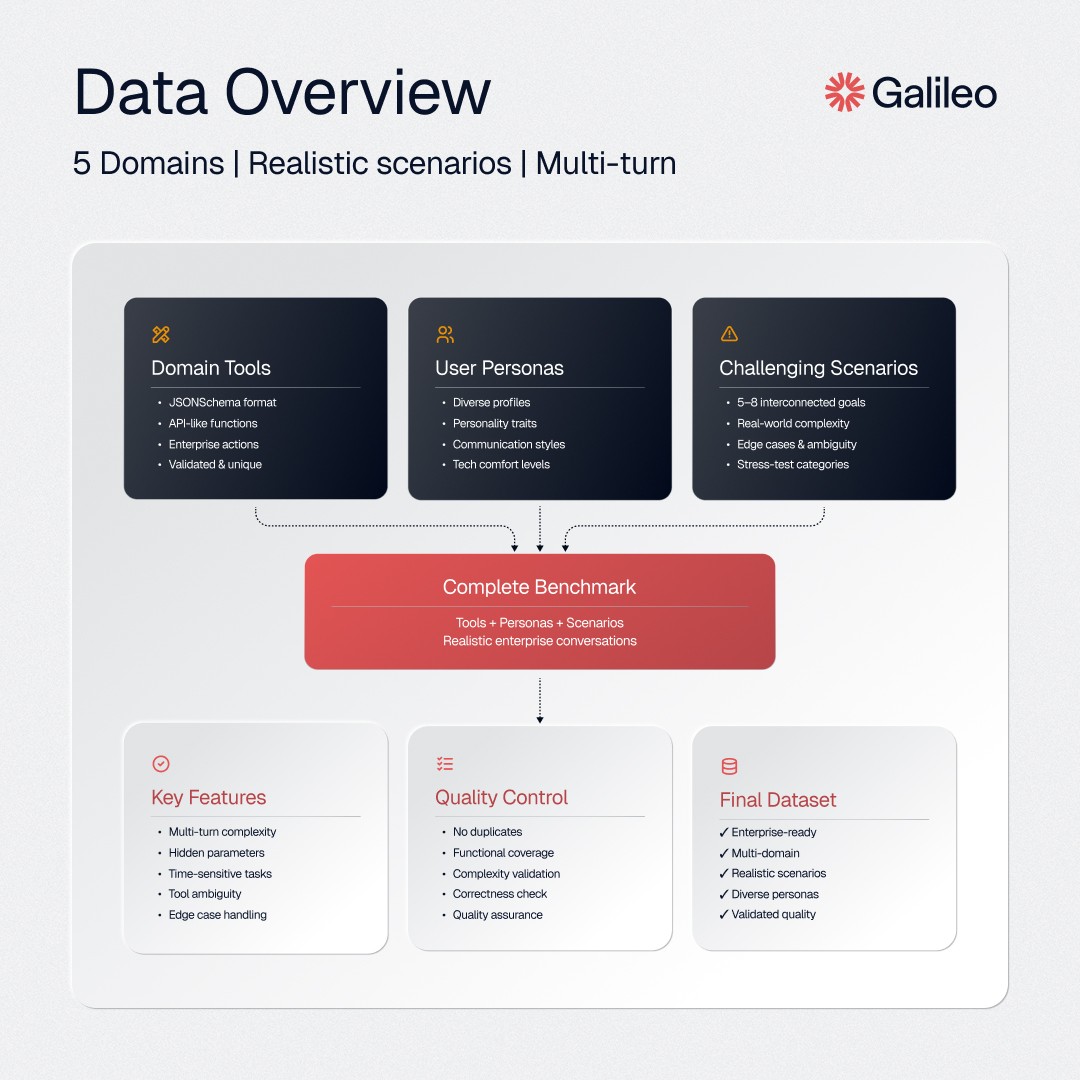
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and guarantee functional domain coverage. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.

Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
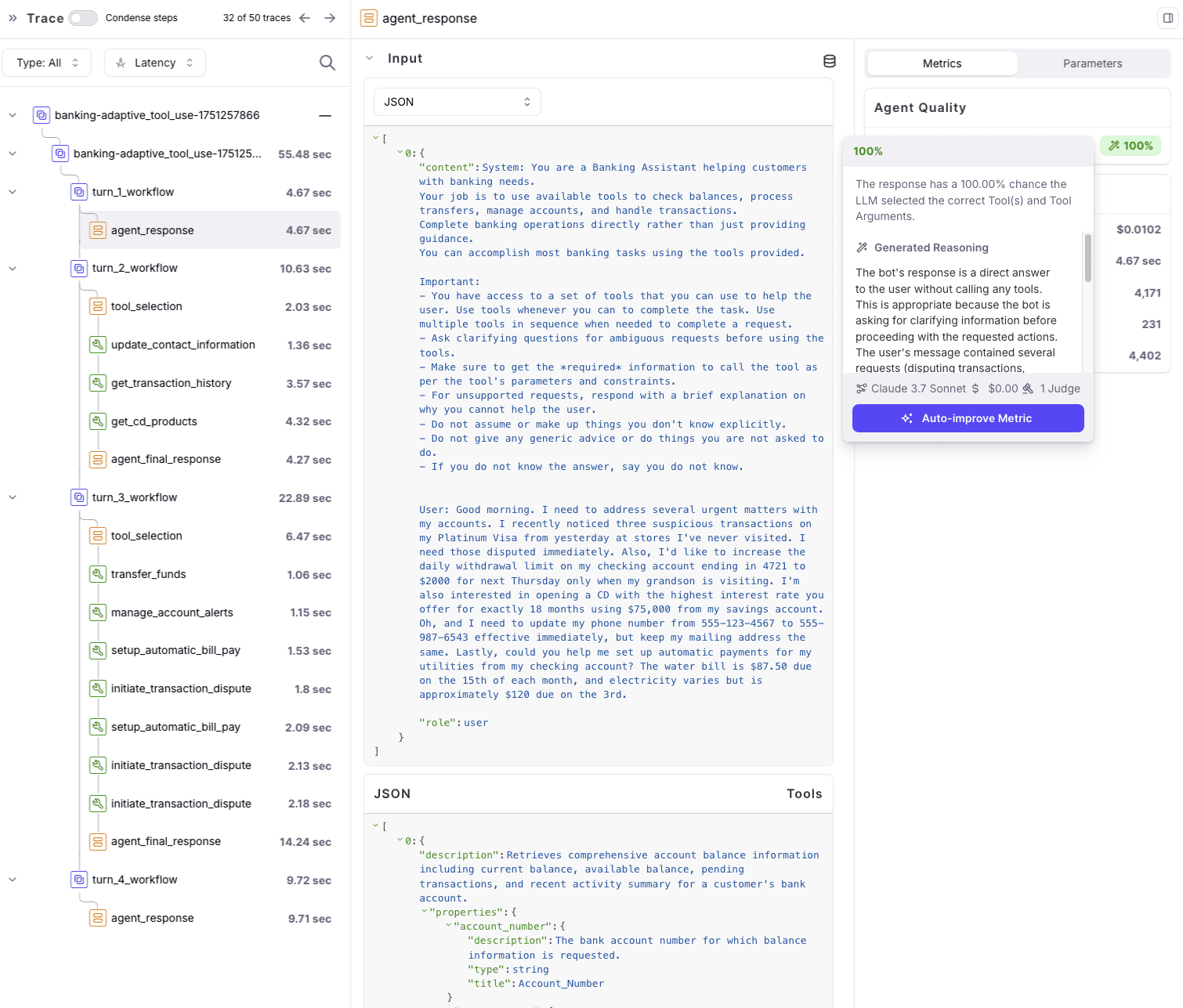
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
Cost per Session: Estimates the dollars spent per complete user interaction.
Average Session Duration: Reflects latency and turn count.
Average Turns: Measures the average number of conversational turns (back-and-forth exchanges) per session.
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed on accuracy and their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
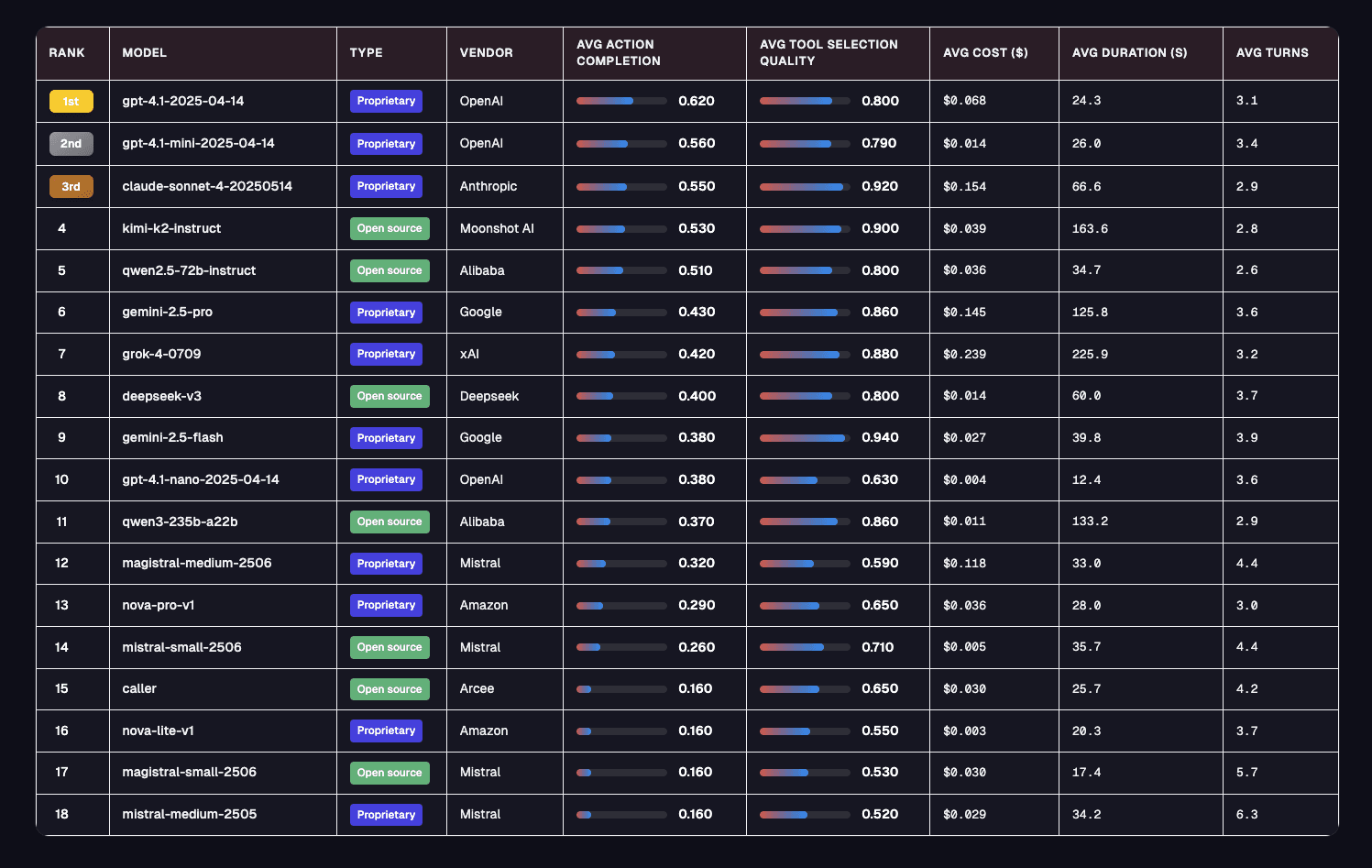
Top Model Picks for Banking Agents
Here are the results from our experiments containing various scores – Action Completion, Tool Selection Quality, average cost of a session, average session duration, and average turns per session.
1. gpt-4.1-2025-04-14 (OpenAI)
Action Completion (AC): 0.60
Tool Selection Quality (TSQ): 0.81
Cost/Session: $0.052
Avg Duration: 18.5 s
GPT-4.1 maintains its top-tier status for banking workflows, demonstrating the highest action completion across the models, with robust tool selection quality. It confidently handles complex, multi-step banking operations and dynamic requirements, making it the most reliable choice for mission-critical scenarios. While the session cost is moderate, its performance justifies the price for enterprises where reliability and compliance matter most.
2. gpt-4.1-mini-2025-04-14 (OpenAI)
Action Completion (AC): 0.56
Tool Selection Quality (TSQ): 0.80
Cost/Session: $0.011
Avg Duration: 21.3 s
The “mini” variant of GPT-4.1 delivers ~93% of the flagship model’s action completion at less than a quarter of the cost. It is optimized for high-volume, cost-sensitive banking use cases such as balance inquiries, account statements, and straightforward transactions. Occasional edge cases may need review, but its speed and value are hard to beat for routine operations.
3. kimi-k2-instruct (Moonshot AI)
Action Completion (AC): 0.58
Tool Selection Quality (TSQ): 0.89
Cost/Session: $0.034
Avg Duration: 165.4 s
As the leading open-source contender, Kimi’s K2 offers transparency and strong tool selection, rivaling proprietary models. Its longer session duration is suited for complex reasoning tasks and back-office banking, where thoroughness trumps speed. The open-source model is a compelling choice for banks valuing auditability and cost control.
4. gemini-2.5-flash (Google)
Action Completion (AC): 0.48
Tool Selection Quality (TSQ): 0.94
Cost/Session: $0.025
Avg Duration: 33.0 s
Gemini-2.5-flash leads in tool selection quality, making it a strong fit for workflows that hinge on accurate API calls or compliance logging. However, its action completion lags behind, meaning it may require additional checks or fallback logic to reach final outcomes. It is ideal for pilot projects or scenarios where correct tool invocation is more important than end-to-end task success.
Strategic Recommendations
Choose Models Based on Task Complexity
For multi-step, compliance-sensitive workflows, favor high Action Completion agents like GPT-4.1. For simpler automations, cost-efficient variants such as GPT-4.1-mini may suffice.Plan for Error Handling
Edge scenarios with low completion rates need fallback guards—validation layers or human-in-the-loop checks.Optimize for Cost and Latency
Balance performance with budget and SLA constraints by benchmarking session costs and response times.Selecting Reasoning Models
Deploy models like Gemini-2.5-flash for high tool accuracy, but layer in business logic to cover task gaps.Implement Safety Controls
Enforce policies and restrict tool access for models with inconsistent tool detection to avoid harmful calls.Open Source vs. Closed Source
Use Kimi’s K2 for baseline operations and closed-source frontrunners for mission-critical tasks.
What Next?
AI agents are reshaping banking from contract review to customer service and internal compliance. The Agent Leaderboard v2 offers actionable insights into which LLMs best fit your needs, whether you prioritize completion rates, cost-efficiency or tool precision. Read the launch blog to dive deeper into our methodology and full benchmark results.
To know more, read our in-depth eBook to learn how to:
Choose the right agentic framework for your use case
Evaluate and improve AI agent performance
Identify failure points and production issues

Banking today is about more than transactions and account balances. It is about delivering seamless, personalized experiences at scale. From reporting a lost credit card to setting up mortgage payments and exchanging foreign currency, customers expect instant, accurate support in a highly regulated environment. AI agents powered by LLMs are stepping into this role, automating complex workflows and ensuring consistency across every interaction.
Choosing the right LLM for your banking agent can mean the difference between a satisfied customer and a costly failure. In our Agent Leaderboard v2 we explore the top-performing models for banking as a domain, share key insights, and consider what these findings mean for deploying AI assistants in finance.
→ Explore the Live Leaderboard
Banking Agents in Action
Banks today confront the dual challenge of meeting digital-first customer expectations and adhering to stringent regulatory requirements. At the same time, fraud schemes and compliance mandates grow increasingly complex. AI agents promise to handle everything from lost-card reports to multi-step loan servicing, orchestrating workflows while ensuring adherence to evolving regulations. Across the industry, leading banks have deployed AI assistants that deliver real-world impact.
Wells Fargo’s Fargo
Wells Fargo’s virtual assistant Fargo, powered by Google’s Flash 2.0 model, surpassed 245 million interactions in 2024 and continues to handle tasks from card controls to transaction searches with built-in privacy safeguards. In 2025, it remains on track for over 100 million interactions annually, demonstrating strong adoption for secure, efficient customer support.
Bank of America’s Erica
Bank of America’s virtual assistant Erica has handled over 2.5 billion client interactions since its launch, serving more than 20 million active users. It assists with balance inquiries, bill payments, fraud alerts, and personalized financial insights. Erica’s proactive notifications and conversational guidance drive faster resolutions and boost digital engagement, with expansions in 2025 including enhanced generative AI features.
Royal Bank of Canada’s NOMI
Royal Bank of Canada’s NOMI provides personalized insights, budgeting tools, and predictive savings features, delivering over 2 billion insights and helping customers save more than $3.6 billion. NOMI analyzes cash flow, categorizes transactions, and sends notifications, boosting household savings rates significantly through its "Find & Save" option in 2025.
Commonwealth Bank’s Ceba
Commonwealth Bank’s Ceba handles over 200 banking tasks, including card activation, balance checks, and payments, managing 60% of incoming contacts end-to-end. Available 24/7, Ceba processes 550,000 queries monthly, promotes clean energy initiatives, and offers educational guidance, enhancing customer self-service in 2025.
Citi’s Citi Bot SG
Citi’s Citi Bot provides real-time support within the mobile app, handling account balances, transactions, payments, and personalized insights using AI and machine learning. In 2025, it is expanding with generative AI tools like Agent Assist and enhanced IVR systems to improve query resolution and security.
Ally Bank’s Ally Assist
Ally Bank’s Ally Assist offers 24/7 voice and text support for transfers, payments, deposits, and spending insights using machine learning and NLP. Recent updates include features to research product prices and ratings, providing predictive advice on investments and expenditures.
PenFed Credit Union’s Einstein
PenFed Credit Union is implementing Einstein, a generative AI virtual assistant, to streamline communications by suggesting responses for service representatives. This 2025 rollout emphasizes enhanced customer experiences through faster, more accurate support in compliance-sensitive workflows.
Takeaways:
AI agents automate high-volume, repeatable tasks and reduce error rates in legal and financial workflows.
Virtual assistants like Erica and Ceba achieve billions of interactions and insights, demonstrating strong user adoption.
Internal and customer-facing tools drive productivity, savings, and compliance without increasing risk.
Real World Failures of AI Support Agents
AI support agents have shown remarkable promise but also exposed critical weaknesses in real-world deployments. In banking and beyond we’ve seen AI replacements backfiring so badly that firms had to rehire humans, conversational bots propagating hateful content within hours, chatbots making glaring factual errors raising red flags over legal compliance. These failures underscore the importance of robust guardrails, human oversight and thorough testing before entrusting AI with customer-facing workflows.
Klarna’s AI Replacement Reversal
Klarna replaced 700 customer-service employees with AI-powered systems only to admit that service quality plunged and customer satisfaction collapsed (The Economic Times). Within months the fintech giant announced it would rehire humans to patch the gaps left by its automated agents (Tech.co). In a separate analysis, testers found ways to confuse Klarna’s bot in unexpected scenarios, revealing brittle handling of edge-case queries.
IBM Watson for Oncology’s Clinical Missteps
IBM marketed Watson for Oncology as a revolutionary tool for recommending cancer treatments, but internal reviews revealed it often gave unsafe or incorrect advice to clinicians (Healthcare Dive). The failure eroded trust among healthcare providers and led to the dissolution of partnerships with leading cancer centers.
Regulatory Concerns for Banking Chatbots
U.S. consumer watchdogs have warned that poorly designed banking chatbots can violate debt-collection and privacy laws, exposing banks to legal risk (PBS). Regulators flagged inconsistent disclosures and incorrect information as major failure modes in AI-driven customer support.
Citi’s Warning After Early Experiments
Citi executives have publicly cautioned that deploying generative AI for external customer support “can go wrong very quickly,” delaying the bank’s own plans for an external-facing chatbot (QA Financial). Their stance reflects a broader industry hesitancy rooted in early failure case studies (QA Financial).
These high-profile failures remind us that AI agents require rigorous evaluation, transparent error-handling strategies and seamless human-in-the-loop integrations to prevent costly breakdowns in customer-facing applications.
The Role of AI in Banking Agents
In the banking domain, user interactions with AI agents often involve complex, multifaceted queries that combine multiple tasks into a single conversation. These requests typically stem from urgent personal or business needs, such as travel preparations, fraud concerns, or financial planning. Based on analysis of real-world user personas and interactions, common request types include:
Fraud and security actions: Reporting lost or stolen cards, disputing unauthorized transactions, and setting up fraud alerts. These are frequent, with users often providing specific details like transaction amounts, dates, and merchants.
Funds transfers: Moving money between accounts, to family members, or internationally via wires. Requests may specify currencies, deadlines, and recipient details, including routing numbers or IBANs.
Status checks: Verifying the progress of transfers, loan applications, payments, or deposits. Users expect precise confirmations, often referencing IDs or dates.
Payment setups: Configuring automatic bill payments for mortgages, utilities, loans, or recurring expenses, with varying amounts, frequencies, and start dates.
Information updates: Changing contact details like phone numbers, addresses, or emails, sometimes with temporary changes for travel.
Appointments and consultations: Scheduling meetings with specialists for loans, investments, or refinancing, often with preferred times or advisors.
Currency and location services: Obtaining exchange rates, converting funds, or locating branches/ATMs, especially for international travel.
Product research: Inquiring about loans, CDs, savings accounts, or credit cards, including comparisons of rates, terms, and eligibility.
What makes these requests difficult for AI agents includes:
Multi-task bundling: Users frequently combine 4-7 unrelated goals in one initial message, requiring the agent to parse, prioritize, and sequence actions while maintaining context.
Urgency and deadlines: Many queries involve time-sensitive elements, like transfers before flights or payments by specific dates, increasing the risk of errors under pressure.
Sensitive data handling: Requests involve PII, account numbers, and financial details, demanding strict compliance with GDPR or PCI DSS, along with secure verification processes.
Growing regulatory pressure: Frameworks like SR11-7 (U.S. Federal Reserve guidance on model risk management) and the EU AI Act impose increasing demands for robust, transparent, and explainable AI systems. LLM-based AI agents are inherently black-box models, making it challenging to provide the required interpretability, auditability, and risk mitigation.
Ambiguity and edge cases: Incomplete details (e.g., missing account numbers) or ambiguous instructions require clarification without frustrating users, while handling international variations in currencies, time zones, and locations adds complexity.
Interdependencies: Tasks often depend on others, such as confirming a transfer before making another or checking balances before approving investments, necessitating logical reasoning and tool orchestration.
Human-like interaction: Users expect empathetic, conversational responses in a regulated environment, where errors could lead to financial loss or compliance violations.
To ensure reliable, compliant performance, addressing these challenges requires LLMs that excel in tool selection, context retention, and error handling.
What Is the Agent Leaderboard?
The Agent Leaderboard v2 is a publicly accessible ranking of 17 leading language models tested on realistic, multi-turn enterprise scenarios across five industries: banking, healthcare, investment, telecom and insurance Galileo AI. Unlike academic benchmarks focusing on one-off tasks, it simulates back-and-forth dialogues with synthetic personas, reflecting the complexity of real customer interaction. Each agent has access to domain-specific tools and is scored on how effectively it navigates them to solve user problems. Results are updated monthly so you can always compare the latest models and variants.
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
https://galileo.ai/agent-leaderboard
Banking-Domain Challenges
Deploying an AI agent in banking requires careful planning and robust technology. Key challenges include:
Regulatory compliance
Models must respect strict data-privacy requirements and maintain audit trails for every action.Multi-step transactions
A single conversation might involve reporting a lost card, querying a mortgage schedule and booking a foreign exchange order.Context preservation
Agents must carry context across turns, coordinating tool calls to internal APIs or external services without losing track of user goals.Latency sensitivity
Customers expect near-real-time responses. Prolonged delays undermine trust and drive users to call human support.Error handling
Edge cases and ambiguous requests require clear validation steps and fallback logic to avoid incomplete or incorrect operations.
Understanding these challenges helps us interpret the performance metrics and choose models that balance capability, cost and responsiveness.
Evaluation Criteria
Our analysis focuses on four core metrics drawn from the Agent Leaderboard v2 benchmark:
Action Completion (AC)
Measures end-to-end task success. Did the agent fulfill every user goal in the scenario?Tool Selection Quality (TSQ)
Captures precision and recall in selecting and parameterizing the correct APIs. High TSQ means fewer unnecessary or erroneous calls.Cost per Session
Estimates the dollars spent per complete user interaction. Balancing budget constraints with performance needs is critical for high-volume deployments.Average Session Duration
Reflects latency and turn count. Faster sessions improve user experience but may trade off thoroughness.
With these metrics in mind, let us explore the standout models for banking agents.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and guarantee functional domain coverage. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
Cost per Session: Estimates the dollars spent per complete user interaction.
Average Session Duration: Reflects latency and turn count.
Average Turns: Measures the average number of conversational turns (back-and-forth exchanges) per session.
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed on accuracy and their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Top Model Picks for Banking Agents
Here are the results from our experiments containing various scores – Action Completion, Tool Selection Quality, average cost of a session, average session duration, and average turns per session.
1. gpt-4.1-2025-04-14 (OpenAI)
Action Completion (AC): 0.60
Tool Selection Quality (TSQ): 0.81
Cost/Session: $0.052
Avg Duration: 18.5 s
GPT-4.1 maintains its top-tier status for banking workflows, demonstrating the highest action completion across the models, with robust tool selection quality. It confidently handles complex, multi-step banking operations and dynamic requirements, making it the most reliable choice for mission-critical scenarios. While the session cost is moderate, its performance justifies the price for enterprises where reliability and compliance matter most.
2. gpt-4.1-mini-2025-04-14 (OpenAI)
Action Completion (AC): 0.56
Tool Selection Quality (TSQ): 0.80
Cost/Session: $0.011
Avg Duration: 21.3 s
The “mini” variant of GPT-4.1 delivers ~93% of the flagship model’s action completion at less than a quarter of the cost. It is optimized for high-volume, cost-sensitive banking use cases such as balance inquiries, account statements, and straightforward transactions. Occasional edge cases may need review, but its speed and value are hard to beat for routine operations.
3. kimi-k2-instruct (Moonshot AI)
Action Completion (AC): 0.58
Tool Selection Quality (TSQ): 0.89
Cost/Session: $0.034
Avg Duration: 165.4 s
As the leading open-source contender, Kimi’s K2 offers transparency and strong tool selection, rivaling proprietary models. Its longer session duration is suited for complex reasoning tasks and back-office banking, where thoroughness trumps speed. The open-source model is a compelling choice for banks valuing auditability and cost control.
4. gemini-2.5-flash (Google)
Action Completion (AC): 0.48
Tool Selection Quality (TSQ): 0.94
Cost/Session: $0.025
Avg Duration: 33.0 s
Gemini-2.5-flash leads in tool selection quality, making it a strong fit for workflows that hinge on accurate API calls or compliance logging. However, its action completion lags behind, meaning it may require additional checks or fallback logic to reach final outcomes. It is ideal for pilot projects or scenarios where correct tool invocation is more important than end-to-end task success.
Strategic Recommendations
Choose Models Based on Task Complexity
For multi-step, compliance-sensitive workflows, favor high Action Completion agents like GPT-4.1. For simpler automations, cost-efficient variants such as GPT-4.1-mini may suffice.Plan for Error Handling
Edge scenarios with low completion rates need fallback guards—validation layers or human-in-the-loop checks.Optimize for Cost and Latency
Balance performance with budget and SLA constraints by benchmarking session costs and response times.Selecting Reasoning Models
Deploy models like Gemini-2.5-flash for high tool accuracy, but layer in business logic to cover task gaps.Implement Safety Controls
Enforce policies and restrict tool access for models with inconsistent tool detection to avoid harmful calls.Open Source vs. Closed Source
Use Kimi’s K2 for baseline operations and closed-source frontrunners for mission-critical tasks.
What Next?
AI agents are reshaping banking from contract review to customer service and internal compliance. The Agent Leaderboard v2 offers actionable insights into which LLMs best fit your needs, whether you prioritize completion rates, cost-efficiency or tool precision. Read the launch blog to dive deeper into our methodology and full benchmark results.
To know more, read our in-depth eBook to learn how to:
Choose the right agentic framework for your use case
Evaluate and improve AI agent performance
Identify failure points and production issues
Banking today is about more than transactions and account balances. It is about delivering seamless, personalized experiences at scale. From reporting a lost credit card to setting up mortgage payments and exchanging foreign currency, customers expect instant, accurate support in a highly regulated environment. AI agents powered by LLMs are stepping into this role, automating complex workflows and ensuring consistency across every interaction.
Choosing the right LLM for your banking agent can mean the difference between a satisfied customer and a costly failure. In our Agent Leaderboard v2 we explore the top-performing models for banking as a domain, share key insights, and consider what these findings mean for deploying AI assistants in finance.
→ Explore the Live Leaderboard
Banking Agents in Action
Banks today confront the dual challenge of meeting digital-first customer expectations and adhering to stringent regulatory requirements. At the same time, fraud schemes and compliance mandates grow increasingly complex. AI agents promise to handle everything from lost-card reports to multi-step loan servicing, orchestrating workflows while ensuring adherence to evolving regulations. Across the industry, leading banks have deployed AI assistants that deliver real-world impact.
Wells Fargo’s Fargo
Wells Fargo’s virtual assistant Fargo, powered by Google’s Flash 2.0 model, surpassed 245 million interactions in 2024 and continues to handle tasks from card controls to transaction searches with built-in privacy safeguards. In 2025, it remains on track for over 100 million interactions annually, demonstrating strong adoption for secure, efficient customer support.
Bank of America’s Erica
Bank of America’s virtual assistant Erica has handled over 2.5 billion client interactions since its launch, serving more than 20 million active users. It assists with balance inquiries, bill payments, fraud alerts, and personalized financial insights. Erica’s proactive notifications and conversational guidance drive faster resolutions and boost digital engagement, with expansions in 2025 including enhanced generative AI features.
Royal Bank of Canada’s NOMI
Royal Bank of Canada’s NOMI provides personalized insights, budgeting tools, and predictive savings features, delivering over 2 billion insights and helping customers save more than $3.6 billion. NOMI analyzes cash flow, categorizes transactions, and sends notifications, boosting household savings rates significantly through its "Find & Save" option in 2025.
Commonwealth Bank’s Ceba
Commonwealth Bank’s Ceba handles over 200 banking tasks, including card activation, balance checks, and payments, managing 60% of incoming contacts end-to-end. Available 24/7, Ceba processes 550,000 queries monthly, promotes clean energy initiatives, and offers educational guidance, enhancing customer self-service in 2025.
Citi’s Citi Bot SG
Citi’s Citi Bot provides real-time support within the mobile app, handling account balances, transactions, payments, and personalized insights using AI and machine learning. In 2025, it is expanding with generative AI tools like Agent Assist and enhanced IVR systems to improve query resolution and security.
Ally Bank’s Ally Assist
Ally Bank’s Ally Assist offers 24/7 voice and text support for transfers, payments, deposits, and spending insights using machine learning and NLP. Recent updates include features to research product prices and ratings, providing predictive advice on investments and expenditures.
PenFed Credit Union’s Einstein
PenFed Credit Union is implementing Einstein, a generative AI virtual assistant, to streamline communications by suggesting responses for service representatives. This 2025 rollout emphasizes enhanced customer experiences through faster, more accurate support in compliance-sensitive workflows.
Takeaways:
AI agents automate high-volume, repeatable tasks and reduce error rates in legal and financial workflows.
Virtual assistants like Erica and Ceba achieve billions of interactions and insights, demonstrating strong user adoption.
Internal and customer-facing tools drive productivity, savings, and compliance without increasing risk.
Real World Failures of AI Support Agents
AI support agents have shown remarkable promise but also exposed critical weaknesses in real-world deployments. In banking and beyond we’ve seen AI replacements backfiring so badly that firms had to rehire humans, conversational bots propagating hateful content within hours, chatbots making glaring factual errors raising red flags over legal compliance. These failures underscore the importance of robust guardrails, human oversight and thorough testing before entrusting AI with customer-facing workflows.
Klarna’s AI Replacement Reversal
Klarna replaced 700 customer-service employees with AI-powered systems only to admit that service quality plunged and customer satisfaction collapsed (The Economic Times). Within months the fintech giant announced it would rehire humans to patch the gaps left by its automated agents (Tech.co). In a separate analysis, testers found ways to confuse Klarna’s bot in unexpected scenarios, revealing brittle handling of edge-case queries.
IBM Watson for Oncology’s Clinical Missteps
IBM marketed Watson for Oncology as a revolutionary tool for recommending cancer treatments, but internal reviews revealed it often gave unsafe or incorrect advice to clinicians (Healthcare Dive). The failure eroded trust among healthcare providers and led to the dissolution of partnerships with leading cancer centers.
Regulatory Concerns for Banking Chatbots
U.S. consumer watchdogs have warned that poorly designed banking chatbots can violate debt-collection and privacy laws, exposing banks to legal risk (PBS). Regulators flagged inconsistent disclosures and incorrect information as major failure modes in AI-driven customer support.
Citi’s Warning After Early Experiments
Citi executives have publicly cautioned that deploying generative AI for external customer support “can go wrong very quickly,” delaying the bank’s own plans for an external-facing chatbot (QA Financial). Their stance reflects a broader industry hesitancy rooted in early failure case studies (QA Financial).
These high-profile failures remind us that AI agents require rigorous evaluation, transparent error-handling strategies and seamless human-in-the-loop integrations to prevent costly breakdowns in customer-facing applications.
The Role of AI in Banking Agents
In the banking domain, user interactions with AI agents often involve complex, multifaceted queries that combine multiple tasks into a single conversation. These requests typically stem from urgent personal or business needs, such as travel preparations, fraud concerns, or financial planning. Based on analysis of real-world user personas and interactions, common request types include:
Fraud and security actions: Reporting lost or stolen cards, disputing unauthorized transactions, and setting up fraud alerts. These are frequent, with users often providing specific details like transaction amounts, dates, and merchants.
Funds transfers: Moving money between accounts, to family members, or internationally via wires. Requests may specify currencies, deadlines, and recipient details, including routing numbers or IBANs.
Status checks: Verifying the progress of transfers, loan applications, payments, or deposits. Users expect precise confirmations, often referencing IDs or dates.
Payment setups: Configuring automatic bill payments for mortgages, utilities, loans, or recurring expenses, with varying amounts, frequencies, and start dates.
Information updates: Changing contact details like phone numbers, addresses, or emails, sometimes with temporary changes for travel.
Appointments and consultations: Scheduling meetings with specialists for loans, investments, or refinancing, often with preferred times or advisors.
Currency and location services: Obtaining exchange rates, converting funds, or locating branches/ATMs, especially for international travel.
Product research: Inquiring about loans, CDs, savings accounts, or credit cards, including comparisons of rates, terms, and eligibility.
What makes these requests difficult for AI agents includes:
Multi-task bundling: Users frequently combine 4-7 unrelated goals in one initial message, requiring the agent to parse, prioritize, and sequence actions while maintaining context.
Urgency and deadlines: Many queries involve time-sensitive elements, like transfers before flights or payments by specific dates, increasing the risk of errors under pressure.
Sensitive data handling: Requests involve PII, account numbers, and financial details, demanding strict compliance with GDPR or PCI DSS, along with secure verification processes.
Growing regulatory pressure: Frameworks like SR11-7 (U.S. Federal Reserve guidance on model risk management) and the EU AI Act impose increasing demands for robust, transparent, and explainable AI systems. LLM-based AI agents are inherently black-box models, making it challenging to provide the required interpretability, auditability, and risk mitigation.
Ambiguity and edge cases: Incomplete details (e.g., missing account numbers) or ambiguous instructions require clarification without frustrating users, while handling international variations in currencies, time zones, and locations adds complexity.
Interdependencies: Tasks often depend on others, such as confirming a transfer before making another or checking balances before approving investments, necessitating logical reasoning and tool orchestration.
Human-like interaction: Users expect empathetic, conversational responses in a regulated environment, where errors could lead to financial loss or compliance violations.
To ensure reliable, compliant performance, addressing these challenges requires LLMs that excel in tool selection, context retention, and error handling.
What Is the Agent Leaderboard?
The Agent Leaderboard v2 is a publicly accessible ranking of 17 leading language models tested on realistic, multi-turn enterprise scenarios across five industries: banking, healthcare, investment, telecom and insurance Galileo AI. Unlike academic benchmarks focusing on one-off tasks, it simulates back-and-forth dialogues with synthetic personas, reflecting the complexity of real customer interaction. Each agent has access to domain-specific tools and is scored on how effectively it navigates them to solve user problems. Results are updated monthly so you can always compare the latest models and variants.
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
https://galileo.ai/agent-leaderboard
Banking-Domain Challenges
Deploying an AI agent in banking requires careful planning and robust technology. Key challenges include:
Regulatory compliance
Models must respect strict data-privacy requirements and maintain audit trails for every action.Multi-step transactions
A single conversation might involve reporting a lost card, querying a mortgage schedule and booking a foreign exchange order.Context preservation
Agents must carry context across turns, coordinating tool calls to internal APIs or external services without losing track of user goals.Latency sensitivity
Customers expect near-real-time responses. Prolonged delays undermine trust and drive users to call human support.Error handling
Edge cases and ambiguous requests require clear validation steps and fallback logic to avoid incomplete or incorrect operations.
Understanding these challenges helps us interpret the performance metrics and choose models that balance capability, cost and responsiveness.
Evaluation Criteria
Our analysis focuses on four core metrics drawn from the Agent Leaderboard v2 benchmark:
Action Completion (AC)
Measures end-to-end task success. Did the agent fulfill every user goal in the scenario?Tool Selection Quality (TSQ)
Captures precision and recall in selecting and parameterizing the correct APIs. High TSQ means fewer unnecessary or erroneous calls.Cost per Session
Estimates the dollars spent per complete user interaction. Balancing budget constraints with performance needs is critical for high-volume deployments.Average Session Duration
Reflects latency and turn count. Faster sessions improve user experience but may trade off thoroughness.
With these metrics in mind, let us explore the standout models for banking agents.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and guarantee functional domain coverage. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
Cost per Session: Estimates the dollars spent per complete user interaction.
Average Session Duration: Reflects latency and turn count.
Average Turns: Measures the average number of conversational turns (back-and-forth exchanges) per session.
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed on accuracy and their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Top Model Picks for Banking Agents
Here are the results from our experiments containing various scores – Action Completion, Tool Selection Quality, average cost of a session, average session duration, and average turns per session.
1. gpt-4.1-2025-04-14 (OpenAI)
Action Completion (AC): 0.60
Tool Selection Quality (TSQ): 0.81
Cost/Session: $0.052
Avg Duration: 18.5 s
GPT-4.1 maintains its top-tier status for banking workflows, demonstrating the highest action completion across the models, with robust tool selection quality. It confidently handles complex, multi-step banking operations and dynamic requirements, making it the most reliable choice for mission-critical scenarios. While the session cost is moderate, its performance justifies the price for enterprises where reliability and compliance matter most.
2. gpt-4.1-mini-2025-04-14 (OpenAI)
Action Completion (AC): 0.56
Tool Selection Quality (TSQ): 0.80
Cost/Session: $0.011
Avg Duration: 21.3 s
The “mini” variant of GPT-4.1 delivers ~93% of the flagship model’s action completion at less than a quarter of the cost. It is optimized for high-volume, cost-sensitive banking use cases such as balance inquiries, account statements, and straightforward transactions. Occasional edge cases may need review, but its speed and value are hard to beat for routine operations.
3. kimi-k2-instruct (Moonshot AI)
Action Completion (AC): 0.58
Tool Selection Quality (TSQ): 0.89
Cost/Session: $0.034
Avg Duration: 165.4 s
As the leading open-source contender, Kimi’s K2 offers transparency and strong tool selection, rivaling proprietary models. Its longer session duration is suited for complex reasoning tasks and back-office banking, where thoroughness trumps speed. The open-source model is a compelling choice for banks valuing auditability and cost control.
4. gemini-2.5-flash (Google)
Action Completion (AC): 0.48
Tool Selection Quality (TSQ): 0.94
Cost/Session: $0.025
Avg Duration: 33.0 s
Gemini-2.5-flash leads in tool selection quality, making it a strong fit for workflows that hinge on accurate API calls or compliance logging. However, its action completion lags behind, meaning it may require additional checks or fallback logic to reach final outcomes. It is ideal for pilot projects or scenarios where correct tool invocation is more important than end-to-end task success.
Strategic Recommendations
Choose Models Based on Task Complexity
For multi-step, compliance-sensitive workflows, favor high Action Completion agents like GPT-4.1. For simpler automations, cost-efficient variants such as GPT-4.1-mini may suffice.Plan for Error Handling
Edge scenarios with low completion rates need fallback guards—validation layers or human-in-the-loop checks.Optimize for Cost and Latency
Balance performance with budget and SLA constraints by benchmarking session costs and response times.Selecting Reasoning Models
Deploy models like Gemini-2.5-flash for high tool accuracy, but layer in business logic to cover task gaps.Implement Safety Controls
Enforce policies and restrict tool access for models with inconsistent tool detection to avoid harmful calls.Open Source vs. Closed Source
Use Kimi’s K2 for baseline operations and closed-source frontrunners for mission-critical tasks.
What Next?
AI agents are reshaping banking from contract review to customer service and internal compliance. The Agent Leaderboard v2 offers actionable insights into which LLMs best fit your needs, whether you prioritize completion rates, cost-efficiency or tool precision. Read the launch blog to dive deeper into our methodology and full benchmark results.
To know more, read our in-depth eBook to learn how to:
Choose the right agentic framework for your use case
Evaluate and improve AI agent performance
Identify failure points and production issues
Banking today is about more than transactions and account balances. It is about delivering seamless, personalized experiences at scale. From reporting a lost credit card to setting up mortgage payments and exchanging foreign currency, customers expect instant, accurate support in a highly regulated environment. AI agents powered by LLMs are stepping into this role, automating complex workflows and ensuring consistency across every interaction.
Choosing the right LLM for your banking agent can mean the difference between a satisfied customer and a costly failure. In our Agent Leaderboard v2 we explore the top-performing models for banking as a domain, share key insights, and consider what these findings mean for deploying AI assistants in finance.
→ Explore the Live Leaderboard
Banking Agents in Action
Banks today confront the dual challenge of meeting digital-first customer expectations and adhering to stringent regulatory requirements. At the same time, fraud schemes and compliance mandates grow increasingly complex. AI agents promise to handle everything from lost-card reports to multi-step loan servicing, orchestrating workflows while ensuring adherence to evolving regulations. Across the industry, leading banks have deployed AI assistants that deliver real-world impact.
Wells Fargo’s Fargo
Wells Fargo’s virtual assistant Fargo, powered by Google’s Flash 2.0 model, surpassed 245 million interactions in 2024 and continues to handle tasks from card controls to transaction searches with built-in privacy safeguards. In 2025, it remains on track for over 100 million interactions annually, demonstrating strong adoption for secure, efficient customer support.
Bank of America’s Erica
Bank of America’s virtual assistant Erica has handled over 2.5 billion client interactions since its launch, serving more than 20 million active users. It assists with balance inquiries, bill payments, fraud alerts, and personalized financial insights. Erica’s proactive notifications and conversational guidance drive faster resolutions and boost digital engagement, with expansions in 2025 including enhanced generative AI features.
Royal Bank of Canada’s NOMI
Royal Bank of Canada’s NOMI provides personalized insights, budgeting tools, and predictive savings features, delivering over 2 billion insights and helping customers save more than $3.6 billion. NOMI analyzes cash flow, categorizes transactions, and sends notifications, boosting household savings rates significantly through its "Find & Save" option in 2025.
Commonwealth Bank’s Ceba
Commonwealth Bank’s Ceba handles over 200 banking tasks, including card activation, balance checks, and payments, managing 60% of incoming contacts end-to-end. Available 24/7, Ceba processes 550,000 queries monthly, promotes clean energy initiatives, and offers educational guidance, enhancing customer self-service in 2025.
Citi’s Citi Bot SG
Citi’s Citi Bot provides real-time support within the mobile app, handling account balances, transactions, payments, and personalized insights using AI and machine learning. In 2025, it is expanding with generative AI tools like Agent Assist and enhanced IVR systems to improve query resolution and security.
Ally Bank’s Ally Assist
Ally Bank’s Ally Assist offers 24/7 voice and text support for transfers, payments, deposits, and spending insights using machine learning and NLP. Recent updates include features to research product prices and ratings, providing predictive advice on investments and expenditures.
PenFed Credit Union’s Einstein
PenFed Credit Union is implementing Einstein, a generative AI virtual assistant, to streamline communications by suggesting responses for service representatives. This 2025 rollout emphasizes enhanced customer experiences through faster, more accurate support in compliance-sensitive workflows.
Takeaways:
AI agents automate high-volume, repeatable tasks and reduce error rates in legal and financial workflows.
Virtual assistants like Erica and Ceba achieve billions of interactions and insights, demonstrating strong user adoption.
Internal and customer-facing tools drive productivity, savings, and compliance without increasing risk.
Real World Failures of AI Support Agents
AI support agents have shown remarkable promise but also exposed critical weaknesses in real-world deployments. In banking and beyond we’ve seen AI replacements backfiring so badly that firms had to rehire humans, conversational bots propagating hateful content within hours, chatbots making glaring factual errors raising red flags over legal compliance. These failures underscore the importance of robust guardrails, human oversight and thorough testing before entrusting AI with customer-facing workflows.
Klarna’s AI Replacement Reversal
Klarna replaced 700 customer-service employees with AI-powered systems only to admit that service quality plunged and customer satisfaction collapsed (The Economic Times). Within months the fintech giant announced it would rehire humans to patch the gaps left by its automated agents (Tech.co). In a separate analysis, testers found ways to confuse Klarna’s bot in unexpected scenarios, revealing brittle handling of edge-case queries.
IBM Watson for Oncology’s Clinical Missteps
IBM marketed Watson for Oncology as a revolutionary tool for recommending cancer treatments, but internal reviews revealed it often gave unsafe or incorrect advice to clinicians (Healthcare Dive). The failure eroded trust among healthcare providers and led to the dissolution of partnerships with leading cancer centers.
Regulatory Concerns for Banking Chatbots
U.S. consumer watchdogs have warned that poorly designed banking chatbots can violate debt-collection and privacy laws, exposing banks to legal risk (PBS). Regulators flagged inconsistent disclosures and incorrect information as major failure modes in AI-driven customer support.
Citi’s Warning After Early Experiments
Citi executives have publicly cautioned that deploying generative AI for external customer support “can go wrong very quickly,” delaying the bank’s own plans for an external-facing chatbot (QA Financial). Their stance reflects a broader industry hesitancy rooted in early failure case studies (QA Financial).
These high-profile failures remind us that AI agents require rigorous evaluation, transparent error-handling strategies and seamless human-in-the-loop integrations to prevent costly breakdowns in customer-facing applications.
The Role of AI in Banking Agents
In the banking domain, user interactions with AI agents often involve complex, multifaceted queries that combine multiple tasks into a single conversation. These requests typically stem from urgent personal or business needs, such as travel preparations, fraud concerns, or financial planning. Based on analysis of real-world user personas and interactions, common request types include:
Fraud and security actions: Reporting lost or stolen cards, disputing unauthorized transactions, and setting up fraud alerts. These are frequent, with users often providing specific details like transaction amounts, dates, and merchants.
Funds transfers: Moving money between accounts, to family members, or internationally via wires. Requests may specify currencies, deadlines, and recipient details, including routing numbers or IBANs.
Status checks: Verifying the progress of transfers, loan applications, payments, or deposits. Users expect precise confirmations, often referencing IDs or dates.
Payment setups: Configuring automatic bill payments for mortgages, utilities, loans, or recurring expenses, with varying amounts, frequencies, and start dates.
Information updates: Changing contact details like phone numbers, addresses, or emails, sometimes with temporary changes for travel.
Appointments and consultations: Scheduling meetings with specialists for loans, investments, or refinancing, often with preferred times or advisors.
Currency and location services: Obtaining exchange rates, converting funds, or locating branches/ATMs, especially for international travel.
Product research: Inquiring about loans, CDs, savings accounts, or credit cards, including comparisons of rates, terms, and eligibility.
What makes these requests difficult for AI agents includes:
Multi-task bundling: Users frequently combine 4-7 unrelated goals in one initial message, requiring the agent to parse, prioritize, and sequence actions while maintaining context.
Urgency and deadlines: Many queries involve time-sensitive elements, like transfers before flights or payments by specific dates, increasing the risk of errors under pressure.
Sensitive data handling: Requests involve PII, account numbers, and financial details, demanding strict compliance with GDPR or PCI DSS, along with secure verification processes.
Growing regulatory pressure: Frameworks like SR11-7 (U.S. Federal Reserve guidance on model risk management) and the EU AI Act impose increasing demands for robust, transparent, and explainable AI systems. LLM-based AI agents are inherently black-box models, making it challenging to provide the required interpretability, auditability, and risk mitigation.
Ambiguity and edge cases: Incomplete details (e.g., missing account numbers) or ambiguous instructions require clarification without frustrating users, while handling international variations in currencies, time zones, and locations adds complexity.
Interdependencies: Tasks often depend on others, such as confirming a transfer before making another or checking balances before approving investments, necessitating logical reasoning and tool orchestration.
Human-like interaction: Users expect empathetic, conversational responses in a regulated environment, where errors could lead to financial loss or compliance violations.
To ensure reliable, compliant performance, addressing these challenges requires LLMs that excel in tool selection, context retention, and error handling.
What Is the Agent Leaderboard?
The Agent Leaderboard v2 is a publicly accessible ranking of 17 leading language models tested on realistic, multi-turn enterprise scenarios across five industries: banking, healthcare, investment, telecom and insurance Galileo AI. Unlike academic benchmarks focusing on one-off tasks, it simulates back-and-forth dialogues with synthetic personas, reflecting the complexity of real customer interaction. Each agent has access to domain-specific tools and is scored on how effectively it navigates them to solve user problems. Results are updated monthly so you can always compare the latest models and variants.
Example: Banking scenario
"I need to report my Platinum credit card as lost, verify my mortgage payment on the 15th, set up automatic bill payments, find a branch near my Paris hotel, get EUR exchange rates, and configure travel alerts—all before I leave for Europe Thursday."
This isn't just about calling the right API. The agent must:
Maintain context across 6+ distinct requests
Handle time-sensitive coordination
Navigate tool dependencies
Provide clear confirmations for each goal
https://galileo.ai/agent-leaderboard
Banking-Domain Challenges
Deploying an AI agent in banking requires careful planning and robust technology. Key challenges include:
Regulatory compliance
Models must respect strict data-privacy requirements and maintain audit trails for every action.Multi-step transactions
A single conversation might involve reporting a lost card, querying a mortgage schedule and booking a foreign exchange order.Context preservation
Agents must carry context across turns, coordinating tool calls to internal APIs or external services without losing track of user goals.Latency sensitivity
Customers expect near-real-time responses. Prolonged delays undermine trust and drive users to call human support.Error handling
Edge cases and ambiguous requests require clear validation steps and fallback logic to avoid incomplete or incorrect operations.
Understanding these challenges helps us interpret the performance metrics and choose models that balance capability, cost and responsiveness.
Evaluation Criteria
Our analysis focuses on four core metrics drawn from the Agent Leaderboard v2 benchmark:
Action Completion (AC)
Measures end-to-end task success. Did the agent fulfill every user goal in the scenario?Tool Selection Quality (TSQ)
Captures precision and recall in selecting and parameterizing the correct APIs. High TSQ means fewer unnecessary or erroneous calls.Cost per Session
Estimates the dollars spent per complete user interaction. Balancing budget constraints with performance needs is critical for high-volume deployments.Average Session Duration
Reflects latency and turn count. Faster sessions improve user experience but may trade off thoroughness.
With these metrics in mind, let us explore the standout models for banking agents.
Building a Multi-Domain Synthetic Dataset
Creating a benchmark that truly reflects the demands of enterprise AI requires not just scale, but depth and realism. For Agent Leaderboard v2, we built a multi-domain dataset from the ground up, focusing on five critical sectors: banking, investment, healthcare, telecom, and insurance. Each domain required a distinct set of tools, personas, and scenarios to capture the complexities unique to that sector. Here is how we constructed this dataset.
Step 1: Generating domain-specific tools
The foundation of our dataset is a suite of synthetic tools tailored to each domain. These tools represent the actions, services, or data operations an agent might need when assisting real users. We used Anthropic’s Claude, guided by a structured prompt, to generate each tool in strict JSON schema format. Every tool definition specifies its parameters, required fields, expected input types, and the structure of its response.
We carefully validated each generated tool to ensure no duplicates and guarantee functional domain coverage. This step ensures the simulated environment is rich and realistic, giving agents a robust toolkit that mirrors actual APIs and services used in enterprise systems.
Example tool call definition:
{ "title": "get_account_balance", "description": "Retrieves comprehensive account balance information including current balance, available balance, pending transactions, and recent activity summary for a customer's bank account.", "properties": { "account_number": { "description": "The bank account number for which balance information is requested.", "type": "string", "title": "Account_Number" }, "account_type": { "description": "The type of bank account to check balance for.", "type": "string", "title": "Account_Type", "enum": [ "checking", "savings", "credit", "money_market", "cd" ] }, "include_pending": { "description": "Whether to include pending transactions in the balance calculation.", "type": "boolean", "title": "Include_Pending" }, "transaction_days": { "description": "Number of days of recent transaction history to include in the summary.", "type": "integer", "title": "Transaction_Days" } }, "required": [ "account_number", "account_type" ], "type": "object" }
Step 2: Designing synthetic personas
After establishing the available tools, we focused on the users themselves. We developed a diverse set of synthetic personas to reflect the range of customers or stakeholders that an enterprise might serve. Each persona is defined by their name, age, occupation, personality traits, tone, and preferred level of communication detail. We prompted Claude to create personas that differ in age group, profession, attitude, and comfort with technology. The validation process checks that each persona is unique and plausible.
This diversity is key for simulating authentic interactions and ensures that agents are evaluated not only on technical skills but also on adaptability and user-centric behavior.
Example personas:
{ "description": "Account balance information with current balance, available funds, and transaction summary.", "type": "object", "properties": { "current_balance": { "description": "The current account balance amount.", "type": "number" }, "available_balance": { "description": "The available balance amount that can be withdrawn or spent.", "type": "number" }, "pending_transactions_count": { "description": "The number of pending transactions affecting the account.", "type": "integer" } }, "required": [ "current_balance", "available_balance", "pending_transactions_count" ] }
Step 3: Crafting challenging scenarios
The final step is where the dataset comes to life. We generated chat scenarios for each domain that combine the available tools and personas. Each scenario is constructed to challenge the agent with 5 to 8 interconnected user goals that must be accomplished within a single conversation. Scenarios are carefully engineered to introduce real-world complexity: hidden parameters, time-sensitive requests, interdependent tasks, tool ambiguity, and potential contradictions. We target a range of failure modes, such as incomplete fulfillment, tool selection errors, or edge-case handling.
Each scenario also belongs to a specific stress-test category, such as adaptive tool use or scope management, to ensure coverage of different agent capabilities. Every scenario is validated for complexity and correctness before being included in the benchmark.
Example scenarios:
[ { "name": "Margaret Chen", "age": 58, "occupation": "High School English Teacher nearing retirement", "personality_traits": [ "methodical", "skeptical", "patient" ], "tone": "formal", "detail_level": "comprehensive" }, { "name": "Jamal Williams", "age": 32, "occupation": "Freelance software developer and tech startup founder", "personality_traits": [ "tech-savvy", "impatient", "analytical" ], "tone": "casual", "detail_level": "comprehensive" } ]
Why a synthetic approach?
We chose a synthetic data approach for several vital reasons. First, generative AI allows us to create an unlimited variety of tools, personas, and scenarios without exposing any real customer data or proprietary information. This eliminates the risk of data leakage or privacy concerns.
Second, a synthetic approach lets us precisely control each benchmark's difficulty, structure, and coverage. We can systematically probe for known model weaknesses, inject edge cases, and have confidence that no model has “seen” the data before.
Finally, by designing every component—tools, personas, and scenarios—from scratch, we create a fully isolated, domain-specific testbed that offers fair, repeatable, and transparent evaluation across all models.
The Result
The result is a highly realistic, multi-domain dataset that reflects enterprise AI agents' challenges in the real world. It enables us to benchmark beyond standard basic tool use and explore the agent’s reliability, adaptability, and ability to accomplish real user goals under dynamic and complex conditions.
Simulation For Evaluating AI Agents
Once the tools, personas, and scenarios have been created for each domain, we use a robust simulation pipeline to evaluate how different AI models behave in realistic, multi-turn conversations. This simulation is the heart of the updated Agent Leaderboard, designed to mimic enterprise agents' challenges in production environments.
Step 1: Experiment orchestration
The process begins by selecting which models, domains, and scenario categories to test. For each unique combination, the system spins up parallel experiments. This parallelization allows us to benchmark many models efficiently across hundreds of domain-specific scenarios.
Step 2: The simulation engine
Each experiment simulates a real chat session between three key components:
The AI Agent (LLM): This is the model being tested. It acts as an assistant that tries to understand the user’s requests, select the right tools, and complete every goal.
The User Simulator: A generative AI system roleplays as the user, using the previously created persona and scenario. It sends the initial message and continues the conversation, adapting based on the agent’s responses and tool outputs.
The Tool Simulator: This module responds to the agent’s tool calls, using predefined tool schemas to generate realistic outputs. The agent never interacts with real APIs or sensitive data—everything is simulated to match the domain's specification.
The simulation loop begins with the user’s first message. The agent reads the conversation history, decides what to do next, and may call one or more tools. Each tool call is simulated, and the responses are fed back into the conversation. The user simulator continues the dialog, pushing the agent through all of the user’s goals and adapting its language and requests based on the agent’s performance.
Step 3: Multi-turn, multi-goal evaluation
Each chat session continues for a fixed number of turns or until the user simulator determines the conversation is complete. The agent must navigate complex, interdependent goals—such as transferring funds, updating preferences, or resolving ambiguous requests—all while coordinating multiple tools and keeping context across turns. We record tool calls, arguments, responses, and conversation flow at every step for later evaluation.
Step 4: Metrics and logging
After each simulation run, we analyze the conversation using two primary metrics:
Tool Selection Quality: Did the agent pick the right tool and use it correctly at each turn?
Action Completion: Did the agent complete every user goal in the scenario, providing clear confirmation or a correct answer?
Cost per Session: Estimates the dollars spent per complete user interaction.
Average Session Duration: Reflects latency and turn count.
Average Turns: Measures the average number of conversational turns (back-and-forth exchanges) per session.
These scores, along with full conversation logs and metadata, are optionally logged to Galileo for advanced tracking and visualization. Results are also saved for each model, domain, and scenario, allowing detailed comparison and reproducibility.
Step 5: Scaling and analysis
Thanks to parallel processing, we can evaluate multiple models across many domains and categories at once. This enables robust benchmarking at scale, with experiment results automatically saved and organized for further analysis.
Why this approach matters
Our simulation pipeline delivers far more than static evaluation. It recreates the back-and-forth, high-pressure conversations agents face in the real world, ensuring models are assessed on accuracy and their ability to adapt, reason, and coordinate actions over multiple turns. This method uncovers strengths and weaknesses that would be missed by simpler, one-shot benchmarks and provides teams with actionable insights into how well their chosen model will work when deployed with real users.
Top Model Picks for Banking Agents
Here are the results from our experiments containing various scores – Action Completion, Tool Selection Quality, average cost of a session, average session duration, and average turns per session.
1. gpt-4.1-2025-04-14 (OpenAI)
Action Completion (AC): 0.60
Tool Selection Quality (TSQ): 0.81
Cost/Session: $0.052
Avg Duration: 18.5 s
GPT-4.1 maintains its top-tier status for banking workflows, demonstrating the highest action completion across the models, with robust tool selection quality. It confidently handles complex, multi-step banking operations and dynamic requirements, making it the most reliable choice for mission-critical scenarios. While the session cost is moderate, its performance justifies the price for enterprises where reliability and compliance matter most.
2. gpt-4.1-mini-2025-04-14 (OpenAI)
Action Completion (AC): 0.56
Tool Selection Quality (TSQ): 0.80
Cost/Session: $0.011
Avg Duration: 21.3 s
The “mini” variant of GPT-4.1 delivers ~93% of the flagship model’s action completion at less than a quarter of the cost. It is optimized for high-volume, cost-sensitive banking use cases such as balance inquiries, account statements, and straightforward transactions. Occasional edge cases may need review, but its speed and value are hard to beat for routine operations.
3. kimi-k2-instruct (Moonshot AI)
Action Completion (AC): 0.58
Tool Selection Quality (TSQ): 0.89
Cost/Session: $0.034
Avg Duration: 165.4 s
As the leading open-source contender, Kimi’s K2 offers transparency and strong tool selection, rivaling proprietary models. Its longer session duration is suited for complex reasoning tasks and back-office banking, where thoroughness trumps speed. The open-source model is a compelling choice for banks valuing auditability and cost control.
4. gemini-2.5-flash (Google)
Action Completion (AC): 0.48
Tool Selection Quality (TSQ): 0.94
Cost/Session: $0.025
Avg Duration: 33.0 s
Gemini-2.5-flash leads in tool selection quality, making it a strong fit for workflows that hinge on accurate API calls or compliance logging. However, its action completion lags behind, meaning it may require additional checks or fallback logic to reach final outcomes. It is ideal for pilot projects or scenarios where correct tool invocation is more important than end-to-end task success.
Strategic Recommendations
Choose Models Based on Task Complexity
For multi-step, compliance-sensitive workflows, favor high Action Completion agents like GPT-4.1. For simpler automations, cost-efficient variants such as GPT-4.1-mini may suffice.Plan for Error Handling
Edge scenarios with low completion rates need fallback guards—validation layers or human-in-the-loop checks.Optimize for Cost and Latency
Balance performance with budget and SLA constraints by benchmarking session costs and response times.Selecting Reasoning Models
Deploy models like Gemini-2.5-flash for high tool accuracy, but layer in business logic to cover task gaps.Implement Safety Controls
Enforce policies and restrict tool access for models with inconsistent tool detection to avoid harmful calls.Open Source vs. Closed Source
Use Kimi’s K2 for baseline operations and closed-source frontrunners for mission-critical tasks.
What Next?
AI agents are reshaping banking from contract review to customer service and internal compliance. The Agent Leaderboard v2 offers actionable insights into which LLMs best fit your needs, whether you prioritize completion rates, cost-efficiency or tool precision. Read the launch blog to dive deeper into our methodology and full benchmark results.
To know more, read our in-depth eBook to learn how to:
Choose the right agentic framework for your use case
Evaluate and improve AI agent performance
Identify failure points and production issues

Pratik Bhavsar