
Production AI agents typically process 100 tokens of input for every token they generate. That's the reality that Manus discovered after millions of user interactions.
"Context engineering is effectively the #1 job of engineers building AI agents" - Cognition
The industry is slowly waking up to this fundamental truth: managing what goes into your AI agent's context window matters more than which model you're using. Yet most teams still treat context like a junk drawer - throwing everything in and hoping for the best. The results are predictable: agents that hallucinate, repeat themselves endlessly, or confidently select the wrong tools. Context Rot shows that even GPT-4o's performance can crater from 98.1% to 64.1% accuracy just based on how information is presented in its context.
Welcome to the fourth installment of the multi-agent series. Don't miss out on other pieces in the Mastering Agent series.
The Evolution: From Prompts to Context

Andrej Karpathy crystallized the shift in thinking when he described LLMs as "a new kind of operating system." In this metaphor, the LLM serves as the CPU and its context window functions as RAM - the model's working memory.
"Context engineering is the delicate art and science of filling the context window with just the right information for the next step" - Andrej Karpathy
This evolution happened rapidly. In 2022, we called it "prompt engineering" - crafting clever prompts to coax better responses from GPT-3. By 2024, as agents began tackling multi-step tasks, "context engineering" emerged as a distinct discipline. A typical agent tasks require around 50 tool calls, accumulating massive contexts that can make or break system performance.
Memory vs Context
The distinction between memory and context is one of the most misunderstood aspects of agent design, yet it fundamentally determines your system's architecture. Conflating these two concepts leads to inefficient designs that neither scale nor perform well.
Context is your agent's working memory. It is the immediate information available during inference, analogous to RAM in a computer. It's what the model can "see" right now, limited by the context window, expensive to maintain and cleared between independent sessions. Every token in context directly influences the model's response, for better or worse. With a large input-to-output ratio (ex. 100:1), context management becomes the dominant cost factor.
Memory is your agent's long-term storage. It is the persistent information stored externally that survives beyond individual interactions. It's unlimited in size, cheap to store, but requires explicit retrieval to be useful. Memory doesn't directly influence the model unless actively loaded into context. Think of it as your hard drive with vast capacity but access overhead. Reading memories is another retrieval problem; writing memories requires nuanced strategies.
The practical implications of this shape the architecture of agents:
Context characteristics:
Immediate but expensive: Every token costs money, especially uncached ones (10x more)
Limited but powerful: Direct influence on model behavior, no retrieval needed
Degrades with size: Performance drops after 30k tokens, depending on the model
Volatile: Lost between sessions unless explicitly preserved
Memory characteristics:
Vast but indirect: Can store millions of documents, but requires retrieval
Cheap but slow: Storage costs negligible, but retrieval adds latency
Structured for access: Must be organized (vectors, graphs, files) for efficient retrieval
Persistent: Survives across sessions, builds organizational knowledge
At scale, the distinction between memory systems and RAG blurs. Both involve selecting relevant information and loading it into context. The difference lies in intent. RAG typically handles knowledge retrieval while memory systems manage agent state and learned patterns.
Retrieval bridges memory to context, and this is where most systems fail. Windsurf's experience shows that simple embedding search breaks down as memory grows. They evolved to a multi-technique approach combining semantic search, keyword matching and graph traversal. Each method handles different types of query.
Here is how different products handle this distinction:
ChatGPT: Maintains a separate memory store of user facts and preferences, retrieves relevant memories based on conversation similarity, and loads only pertinent memories into context for each turn. This keeps context focused while maintaining continuity across sessions.
Manus: Treats the file system as infinite memory, with agents writing intermediate results to files and loading only summaries into context. Full content remains accessible via file paths, achieving high compression while maintaining recoverability.
Claude Code: Uses working memory (context) for active task state, with project files as persistent memory. The CLAUDE.md file serves as procedural memory, loaded at session start but not constantly maintained in context.
The critical design decision is what belongs in context versus memory:
Keep in Context:
Current task objectives and constraints
Recent tool outputs (last 3-5 calls)
Active error states and warnings
Immediate conversation history
Currently relevant facts
Store in Memory:
Historical conversations and decisions
Learned patterns and preferences
Large reference documents
Intermediate computational results
Completed task summaries
The future of this distinction may disappear entirely. As models improve and context windows expand, the boundary between memory and context blurs. Till then, we need to do intentional memory design where retrieval is explicit and purposeful.

Types of Context in Agent Systems
Let's understand different types of context for effective management as each presents unique challenges.
Instructions Context includes system prompts, few-shot examples, and behavioral guidelines that define how the agent should operate. This context tends to be stable but can grow large with complex instructions. Poor instruction context leads to inconsistent behavior and misaligned responses.
Knowledge Context encompasses facts, memories, retrieved documents, and user preferences that inform the agent's decisions. This dynamic context changes based on the task and can quickly overwhelm the context window. The challenge lies in selecting relevant knowledge while avoiding information overload.
Tools Context contains tool descriptions, feedback from tool calls, and error messages that enable the agent to interact with external systems. As the Agent Leaderboard shows, models perform poorly when given multiple tools, making tool context management critical for performance.
History Context preserves past conversations, previous decisions, and learned patterns from earlier interactions. While valuable for continuity, historical context can introduce contradictions and outdated information that confuse the agent.
Understanding Context Failure Modes
Drew Breunig identified four distinct patterns that everyone building agents will eventually encounter. Understanding these failure modes is critical for building reliable systems.
Context Poisoning: When Errors Compound

Context poisoning occurs when a hallucination or error enters the context and gets repeatedly referenced, compounding the mistake over time. The DeepMind team documented this vividly with their Pokémon-playing Gemini agent:
"Many parts of the context (goals, summary) are 'poisoned' with misinformation about the game state, which can often take a very long time to undo" - DeepMind Team
Here are some real-world context poisoning scenarios
Customer Service Agent:
Initial error: Misidentifies customer's product model
Cascade: Provides wrong troubleshooting steps → References incorrect manual → Suggests incompatible accessories
Result: Frustrated customer, multiple escalations, lost trust
Code Generation Agent:
Initial error: Imports wrong library version
Cascade: Uses deprecated APIs → Generates incompatible syntax → Creates cascading type errors
Result: Completely unrunnable code requiring manual rewrite
Research Agent:
Initial error: Misunderstands research question scope
Cascade: Searches wrong domain → Cites irrelevant sources → Draws incorrect conclusions
Result: Entire research output invalidated
The mechanism is insidious. A single hallucination about the state would get embedded in the agent's goals section. Because goals are referenced at every decision point, the false information reinforces itself. The agent would spend dozens of turns pursuing impossible objectives, unable to recover because the poisoned context kept validating the error.
Context Distraction: The Attention Crisis

Context distraction manifests when a context grows so long that the model over-focuses on the accumulated history, neglecting its trained knowledge in favor of pattern-matching from the context.
"As the context grew significantly beyond 100k tokens, the agent showed a tendency toward favoring repeating actions from its vast history rather than synthesizing novel plans" - Gemini 2.5 technical report
The technical mechanism appears to be attention-based. As context grows, the model allocates increasing attention to the immediate context at the expense of its parametric knowledge. Instead of reasoning about the current situation, it searches for similar historical patterns and repeats them. The Databricks study found something even more concerning: when models hit their distraction threshold, they often default to summarizing the provided context while ignoring instructions entirely.
Context Confusion: Too Many Tools

Context confusion emerges when superfluous information in the context gets used to generate low-quality responses. The Berkeley Function-Calling Leaderboard delivers hard data: every single model performs worse when given multiple tools, without exception.
When researchers gave a quantized Llama 3.1 8B access to 46 tools from the GeoEngine benchmark, it failed completely - even though the context was well within its 16k window. With just 19 tools, it succeeded. The issue wasn't context length; it was context complexity.
Context Clash: Information at War

Context clash represents the most complex failure mode: when accumulated information contains contradictions that derail reasoning. Researchers uncovered this by taking standard benchmark tasks and "sharding" them across multiple conversation turns. Performance dropped 39% on average across all tested models.
"When LLMs take a wrong turn in a conversation, they get lost and do not recover" - Microsoft/Salesforce
The Five Buckets Framework

Lance Martin presents a comprehensive framework for context engineering that organizes strategies into five core approaches, each with specific use cases and trade-offs.
1. Offloading: Keep Heavy Data External
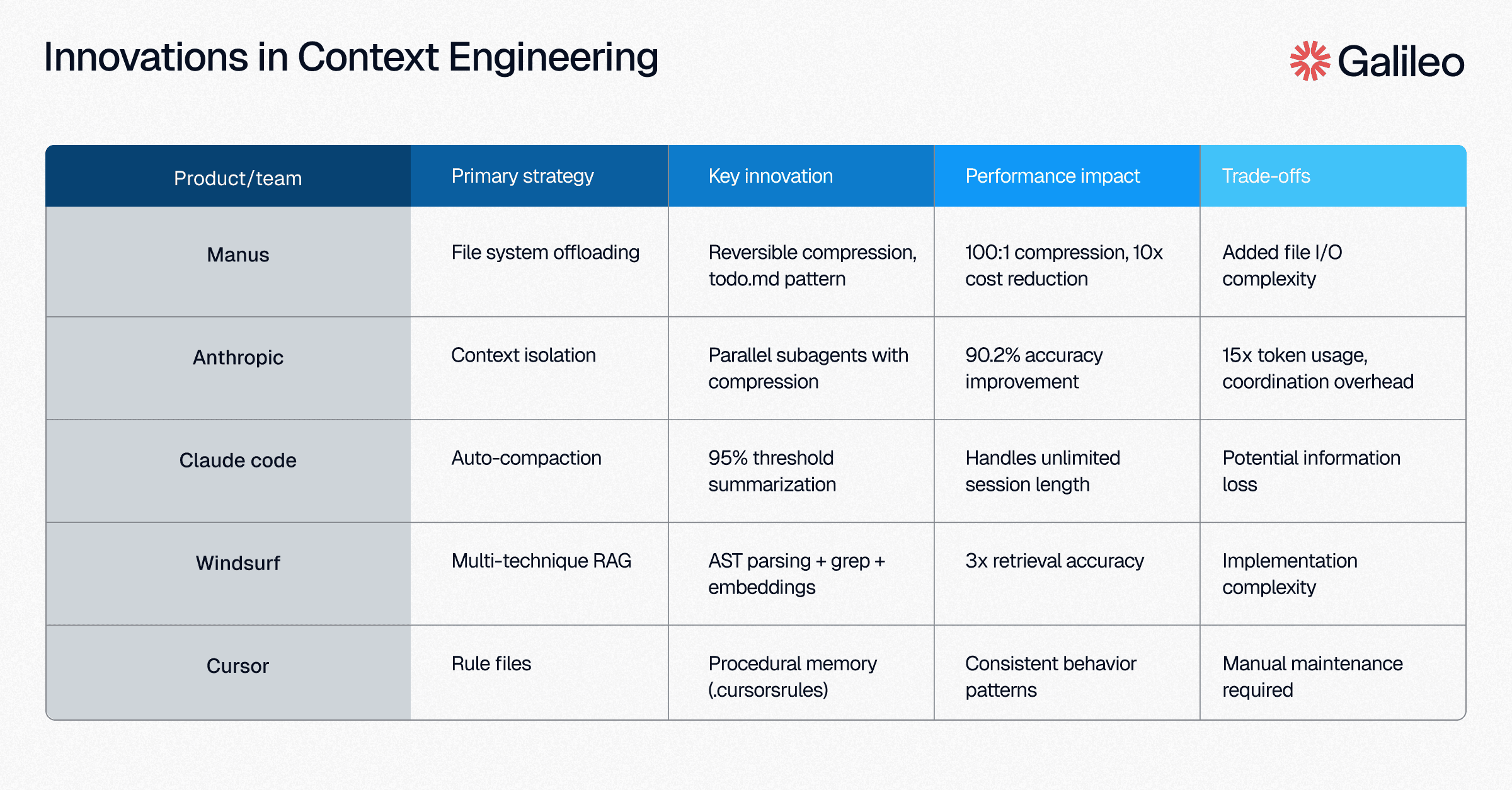
Offloading means not sending raw, token-heavy tool call content to the LLM repeatedly. Instead, save long outputs to disk or external memory and only pass in necessary summaries or metadata. Manus team's approach treats the file system as unlimited external memory, achieving 100:1 compression ratios while maintaining full information recovery capability.
The key insight is reversibility. When you compress a 50,000-token webpage to a 500-token summary plus URL, you can always retrieve the full content if needed. This significantly reduces token usage and cost, but careful summarization is crucial to preserve recall. The Manus team discovered that agents naturally create todo.md files as an offloading pattern, maintaining task state externally while keeping the context focused.
2. Context Isolation (Multi-Agent Systems)
Context isolation works best for parallelizable, "read-only" tasks like research. Anthropic's research system demonstrates this approach: divide work among sub-agents that gather information independently, then have a single agent produce the final output. The result was a 90.2% performance improvement despite using 15x more tokens overall.
"Subagents facilitate compression by operating in parallel with their own context windows, exploring different aspects of the question simultaneously" - Anthropic
However, for tasks like coding, communication overhead and risk of conflicting changes mean isolation may create more problems than it solves. The sweet spot is tasks that can be cleanly divided without interdependencies.
3. Retrieval: From Simple to Sophisticated
There's a spectrum of retrieval approaches. Classical vector store-based RAG with semantic search works well for large document collections, but for many real-world developer workflows, simple tools paired with a good metadata index (like llm.txt files) can outperform complex vector search setups and are easier to maintain.
Windsurf's approach combines multiple techniques: embedding search for semantic similarity, grep for exact matches, knowledge graphs for relationships, and AST parsing for code structure. This multi-technique approach achieves 3x better retrieval accuracy than any single method.
4. Reducing Context (Pruning/Compaction)
Regular summarization or pruning of context prevents bloat. Claude Code's auto-compaction triggers at 95% context usage, summarizing the entire conversation while preserving critical information like objectives and key decisions.
However, aggressive reduction risks information loss. The better approach is to offload full data to external memory and feed back only summaries, ensuring you can retrieve originals if needed. This creates a safety net against over-aggressive pruning.
5. Caching: Speed and Cost Benefits
Caching saves prior message history locally to cut agent latency and costs. The Manus team found that KV-cache optimization provides 10x cost reduction when properly implemented. However, caching doesn't resolve context rot or quality degradation in long message histories. It just makes the problems cheaper and faster.

Tips for Context Engineering
If context < 10k tokens: → Use simple append-only approach with basic caching
If 10k-50k tokens: → Add compression at boundaries + KV-cache optimization
If 50k-100k tokens: → Implement offloading to external memory + smart retrieval
If > 100k tokens: → Consider multi-agent isolation architecture
If task is parallelizable: → Always evaluate multi-agent approach regardless of size
If cost is critical: → Prioritize caching and compression strategies
If latency is critical: → Focus on cache optimization and parallel processing
If accuracy is critical: → Implement comprehensive retrieval and memory systems
Anti-Patterns to Avoid
Understanding what not to do is as important as knowing the right approaches. These anti-patterns consistently cause problems in production systems:
❌ Modifying previous context breaks cache validity and multiplies costs. Any modification to earlier context invalidates the KV-cache from that point forward. Always use append-only designs.
❌ Loading all tools upfront degrades performance. Use dynamic tool selection or masking instead.
❌ Aggressive pruning without recovery loses critical information permanently. Follow reversible compression to maintain the ability to retrieve original data.
❌ Ignoring error messages misses valuable learning opportunities. Keeping error messages in context prevents agents from repeating the same mistakes.
❌ Over-engineering too early violates the "Bitter Lesson". Simpler, more general solutions tend to win over time as models improve. Start simple and add complexity only when proven necessary.
Evaluation and Measurement
Galileo's framework for agent evaluation identifies three critical levels that need measurement. Session-level metrics track whether the agent accomplished all user goals (Action Completion) and whether progress was made toward at least one goal (Action Advancement). Step-level metrics measure whether correct tools and parameters were chosen (Tool Selection Quality) and whether responses use the provided context (Context Adherence).
"Galileo's agent reliability platform is the industry's first comprehensive solution purpose-built to enable reliable multi-agent systems at scale." - Vikram (CEO @ Galileo)
Unlike traditional LLMs with single input-output pairs, agents can take completely different routes to the same destination. This requires sophisticated tracing and analysis to understand not just whether the agent succeeded, but how it used context at each step.
Galileo's Comprehensive Observability Suite includes:
Trace View: Visualize the complete execution flow of your agent with detailed step-by-step breakdowns. See exactly how context flows through each decision point, which tools were called, and how responses were generated. The collapsible tree structure lets you drill into specific steps to understand context utilization patterns.
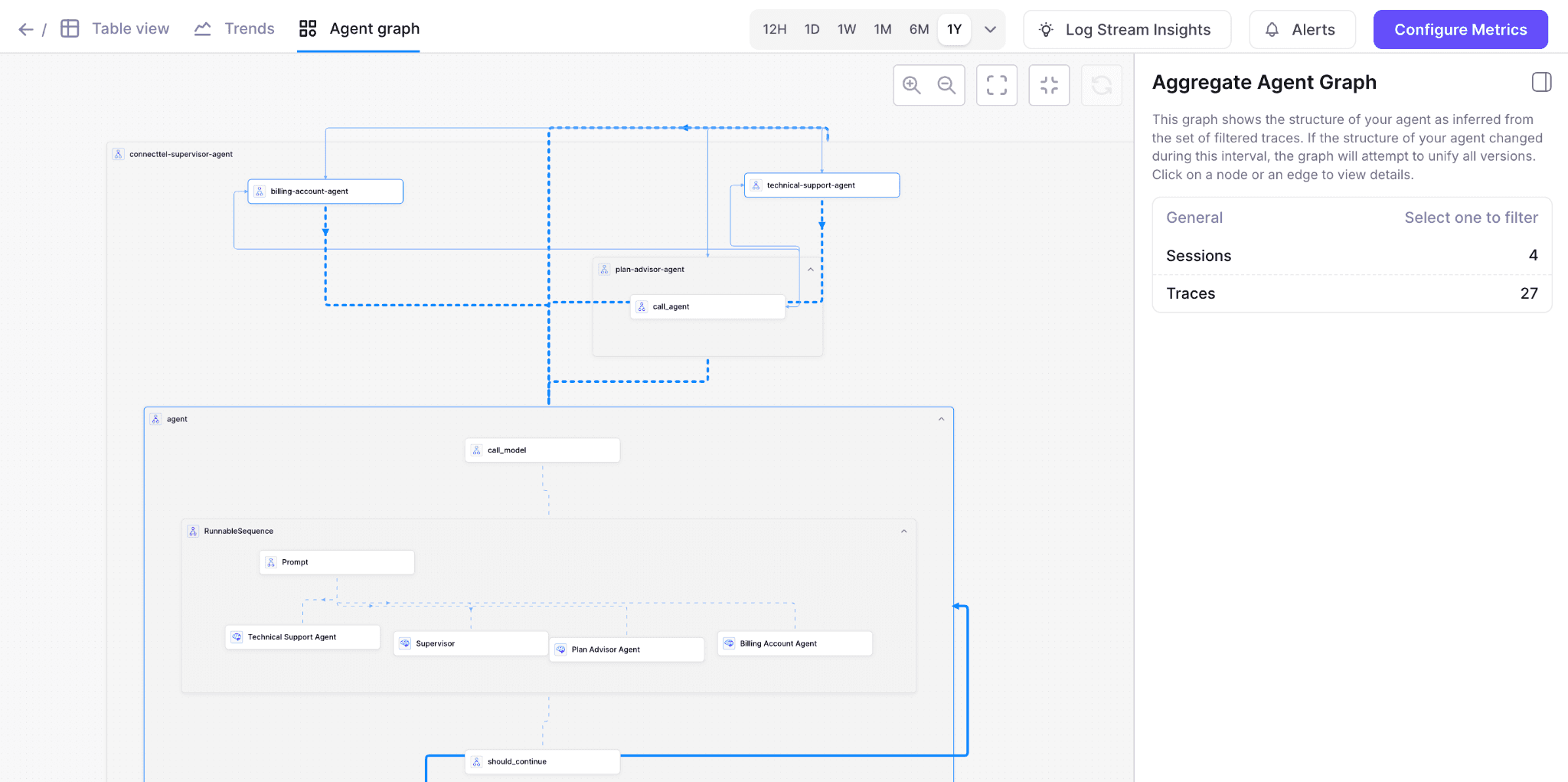
Graph View: Get a visual representation of your agent's decision tree and execution paths. This network visualization shows how different context segments connect and influence agent behavior, making it easy to identify bottlenecks or circular dependencies in your context flow.
Log Stream Insights: Real-time streaming of agent logs with intelligent filtering and pattern detection. Watch as your agents process context in production, with automatic highlighting of anomalies, errors, and performance issues. The log stream automatically correlates related events across distributed agent systems.
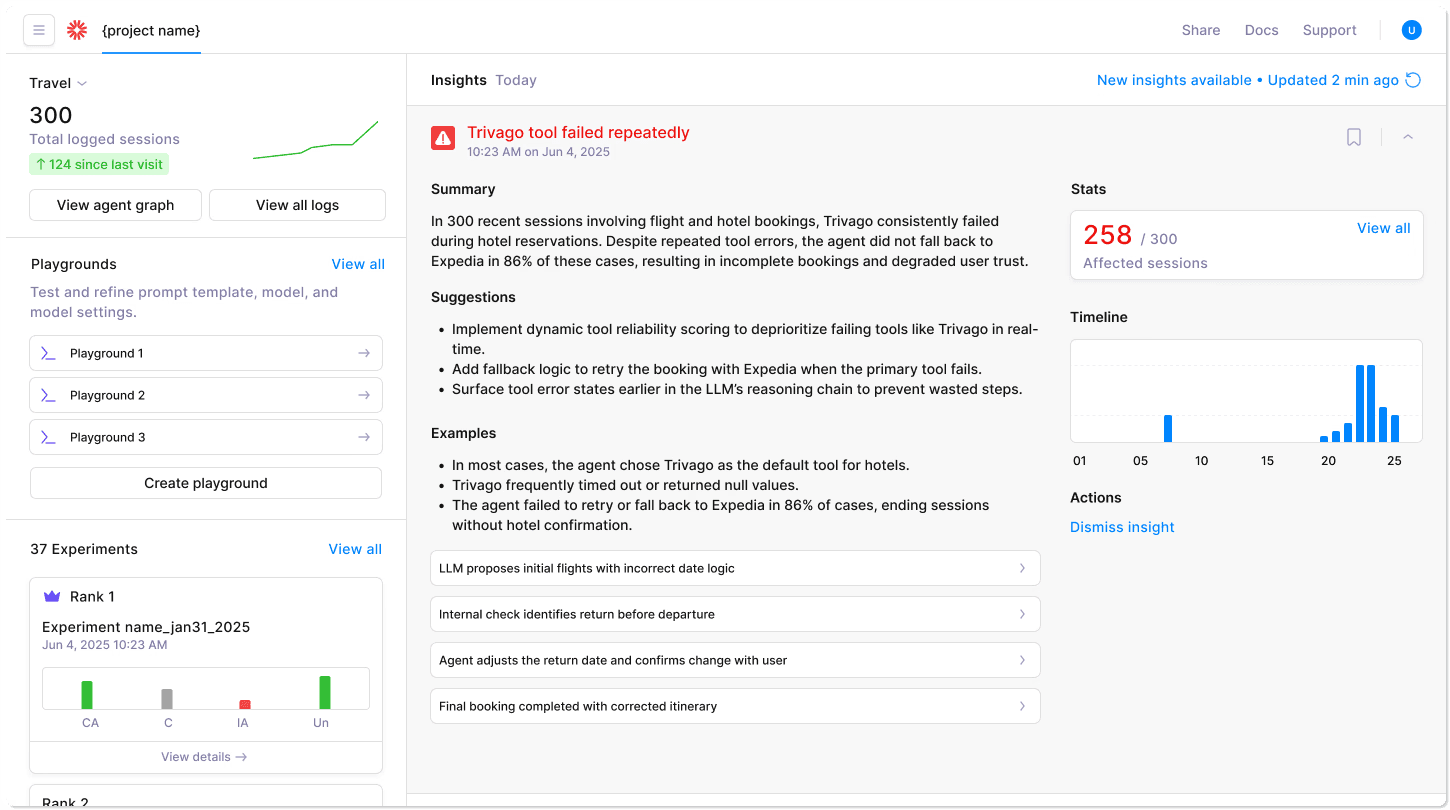
Latency Chart: Comprehensive latency breakdown showing time spent in context retrieval, processing, and generation phases. Identify whether slowdowns come from oversized context windows, inefficient retrieval, or model inference. The chart provides percentile distributions (p50, p95, p99) to catch outliers affecting user experience.
Additional Core Metrics:
Hallucination Detection: Real-time identification of when agents generate information not grounded in their context
Cost Analytics: Track token consumption patterns with context-aware breakdowns
Safety Guardrails: Monitor for prompt injections, jailbreaks, and unsafe outputs
Retrieval Quality: Measure how effectively agents access and utilize retrieved context
Loop Detection: Identify when agents get stuck in repetitive patterns due to context confusion
Here is how you can effectively leverage metrics to improve context engineering:
1. Establish a Measurement Framework
Session-level tracking: Use Action Completion and Action Advancement to measure overall goal achievement. The Trace View lets you replay entire sessions to see how your context successfully (or unsuccessfully) guides agents to accomplish user objectives. Each trace shows the complete context state at every step.

Step-level analysis: Apply Tool Selection Quality and Context Adherence to evaluate individual decisions. The Graph View reveals the decision tree, showing where your prompts fail to guide proper tool usage or context following. Click any node to see the exact context that was available at that decision point.

Real-time monitoring: The Log Stream Insights feature provides instant visibility into agent performance with intelligent pattern detection. Set up custom filters to monitor specific context-related events, such as when agents ignore provided context or when retrieval fails.
2. Iterative Improvement Process
Identify patterns: Monitor metrics over time using the Latency Chart to spot performance degradation as context grows. Correlate latency spikes with specific context sizes or retrieval patterns. Galileo's automated insights highlight which context segments consistently cause failures or slowdowns.
Visualize agent behavior: The Graph View makes it easy to compare different execution paths for the same task. See how context variations lead to different agent routes and identify which paths are most efficient. Export these visualizations for team reviews and documentation.
Test variations: Create different versions of your context/prompts and use A/B Testing to compare performance. The Trace View allows side-by-side comparison of different context strategies, showing exactly where behaviors diverge.
Benchmark against baselines: Compare your agents against Galileo's evaluation datasets and industry benchmarks. The platform provides pre-built test suites for common agent tasks like RAG, tool use, and multi-step reasoning.
3. Specific Optimization Strategies
For debugging complex flows: Use the Trace View's collapsible interface to navigate through nested agent calls and multi-agent interactions. Each trace includes the full context window at that point, making it easy to identify context bloat or missing information.

The Latency Chart breaks down time spent in each phase for performance optimization:
Context retrieval latency (identifying slow vector searches or API calls)
Processing latency (showing when context size impacts performance)
Generation latency (revealing when output length affects response time)
Use these insights to implement targeted caching or context pruning strategies

Leverage Log Stream Insights(LSI) for production debugging:
Real-time error detection with stack traces
Automatic correlation of related events across services
Pattern matching to identify recurring context-related issues
Export capabilities for offline analysis
Leverage Graph View for architectural decisions:
Identify redundant paths that could be optimized
Spot parallel processing opportunities
Visualize multi-agent coordination and context sharing
Export graphs for architecture documentation
4. Continuous Monitoring and Alerting
Set up alerts based on patterns detected in the Log Stream to catch issues early. Configure thresholds in the Latency Chart to notify when context processing exceeds SLA limits.
Intelligent Alerting: Anomaly detection that learns your normal patterns and flags deviations
Custom Dashboards: Combine Trace, Graph, and Latency views into unified monitoring screens
Integrations: Native connectors for Langgraph, CrewAI and other frameworks
API Access: Programmatic access to all metrics for custom analysis
The key is treating these visualization and monitoring tools as a continuous feedback loop.
Trace View shows → what happened
Graph View shows → where it happened
Latency Chart shows → how fast it happened
Log Stream Insights shows → why it happened
Together, they provide complete observability into your context engineering effectiveness.
Roadmap for Context Engineering

Start with measurement: you can't optimize what you don't understand. Deploy comprehensive logging to capture every agent interaction, token usage, cache hit rates, and failure patterns. Analyse the input to output ratio to focus the efforts on reduction. This baseline reveals where you're bleeding money and performance.
Your first week should focus on the highest-impact, lowest-effort optimizations. Optimize tool descriptions for clarity and distinctiveness. Add basic error retention by keeping failed attempts in context prevents repeated mistakes and costs nothing to implement. Deploy production guardrails for safety and reliability. These changes often provide 80% of the benefit with 20% of the effort. These changes take hours to implement but save thousands of dollars monthly.
Once you've captured the easy gains, build your core infrastructure over the next month. Implement dynamic tool retrieval when you exceed 20 tools. Add reversible compression by storing URLs not web pages, file paths not contents. Deploy auto-summarization at 80% context capacity to prevent hard failures. Create a simple memory system with basic file storage.

Only after mastering the fundamentals should you explore advanced techniques. Multi-agent architectures make sense for truly parallelizable tasks. Anthropic saw 90% improvement but at 15x token cost. Attention manipulation through todo lists and goal recitation reduces drift in long-running tasks. Evaluation insights help catch emerging failure patterns before users notice them. These optimizations require significant engineering investment, so ensure your basics are rock-solid first.
When NOT to Use These Techniques
Context engineering is costly. Every optimization adds complexity, latency, and maintenance burden. Simple, single-turn queries don't benefit from elaborate memory systems or compression strategies. If your agent answers basic questions or performs straightforward lookups, standard prompting suffices. Don't over-engineer solutions that model improvements will make obsolete.
But the overhead becomes worthwhile at specific thresholds. When context exceeds 30,000 tokens, you approach distraction limits where models start deteriorating significantly. When tasks require more than 10 tool calls, the accumulated context starts degrading performance. When you're processing over 1,000 sessions daily, the 10x cost difference from caching becomes material. The investment in reliability pays for itself when accuracy truly matters for domains like insurance and finance.
Consider your constraints honestly. If latency is absolutely critical (real-time trading, emergency response), the overhead of retrieval and compression may be unacceptable. If you're prototyping or validating concepts, focus on core functionality rather than optimization.
The Path to Reliable Context
The evidence from others' implementation points to a clear conclusion: whether you're using GPT-5, Claude, or open-source models, your context strategy makes the difference between success and failure.
Profile your current system and identify your failure modes. Then, apply strategies incrementally, measuring impact at each step. Remember the fundamental principle: every token in your context influences the response. Make them earn their place.
Do you want to optimise your context without losing your mind?
To know more, read our in-depth eBook to learn how to:
Choose the right agentic framework for your use case
Evaluate and improve AI agent performance
Identify failure points and production issues

Pratik Bhavsar