Kimi K2 Instruct Model Overview
Explore Kimi K2 Instruct's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Kimi K2 Instruct Model Overview
Choosing the right large language model can feel like aiming at a moving target. Latency, cost, security, and domain accuracy all pull in different directions, and a wrong bet locks you into expensive rewrites later.
Moonshot AI positions its open-weight Kimi K2 Instruct as the answer to that tension: a 1-trillion-parameter Mixture-of-Experts model that only lights up about 32 billion parameters per request, promising enterprise-grade performance without GPT-class prices.
So the question to ask is really simple: will this model actually deliver ROI in production? Our comprehensive analysis examines performance across five business domains, revealing where this trillion-parameter open-source model justifies its top ranking.
Check out our Agent Leaderboard and pick the best LLM for your use case

Kimi K2 Instruct performance heatmap
Unlike traditional closed-source models, kimi-k2-instruct ships under a Modified MIT License, enabling you to deploy self-hosted solutions, fine-tune the model, and maintain complete control over your inference infrastructure.
This open-source approach addresses your enterprise concerns around vendor lock-in and data sovereignty while maintaining competitive performance on agent-specific benchmarks:
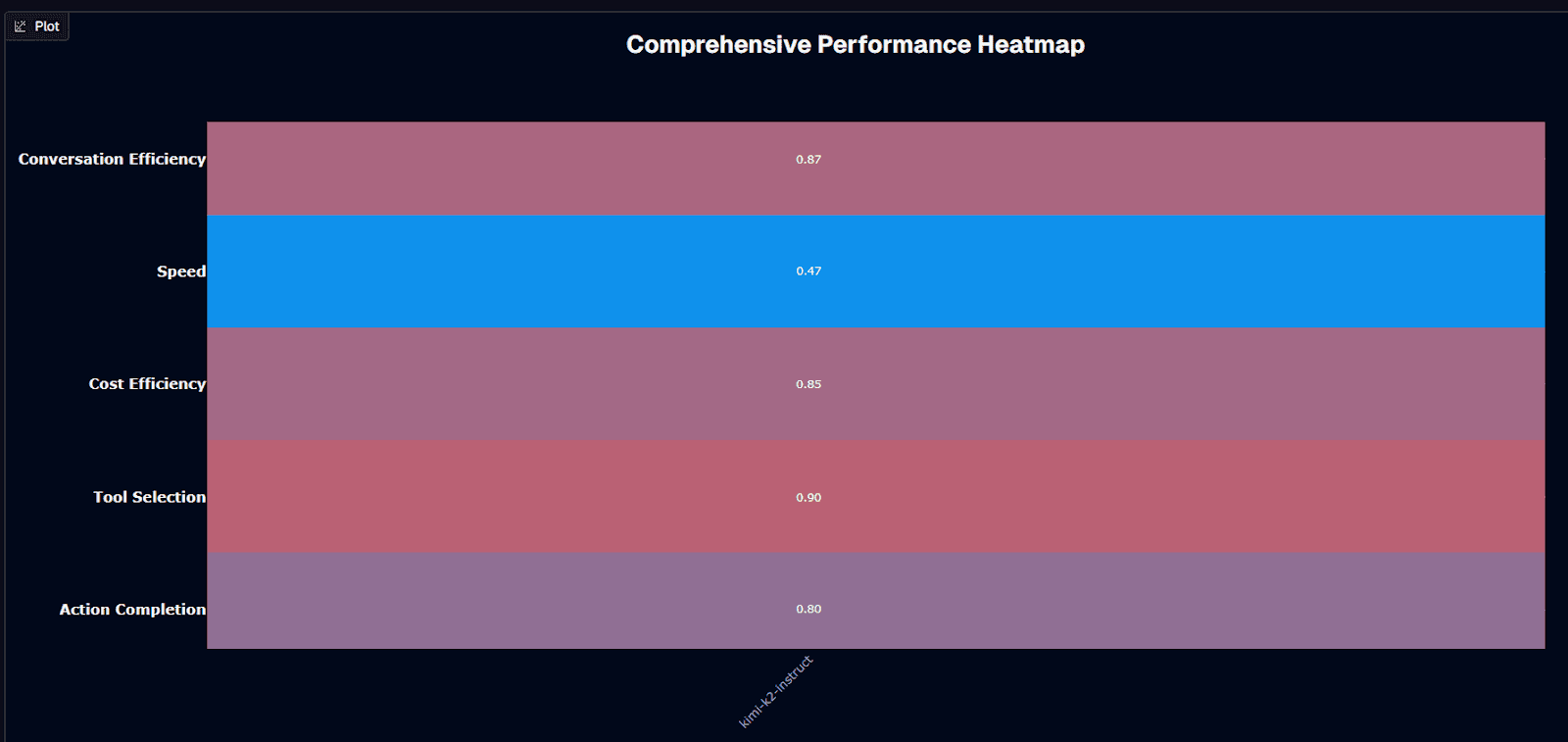
The comprehensive performance heatmap reveals kimi-k2-instruct's complete capability profile across key dimensions:
Tool selection leads at 0.90, confirming the model's strength in choosing appropriate functions
Conversation efficiency scores 0.87, indicating effective multi-turn dialogue management without excessive back-and-forth
Cost efficiency reaches 0.85, reflecting the model's exceptional economics relative to capabilities delivered. This high score validates the value proposition—kimi-k2-instruct provides frontier performance at dramatically reduced cost through open-source deployment
Action completion sits at 0.80 in this normalized view, representing solid but not exceptional task completion reliability
Speed presents the model's primary weakness at 0.47, confirming latency as a fundamental constraint
The heatmap visualization clarifies the model's tradeoff profile: exceptional cost efficiency and tool selection, adequate action completion and conversation efficiency, compromised speed.
Background research
Kimi K2-Instruct's development builds upon several technical innovations:
MuonClip optimizer: Moonshot AI's joint research with UCLA on the Muon optimizer enabled stable training at a trillion-parameter scale. The MuonClip variant prevents "logit explosions" in attention layers that typically crash large MoE training runs, achieving zero training instability across 15.5 trillion tokens.
Sparse MoE architecture: The model implements 384 expert networks with routing to 8 active experts per token, plus 1 shared expert for global context. This sparsity reduces active computation while maintaining model capacity, though it introduces routing overhead that contributes to higher latency.
Agentic training methodology: Unlike models primarily trained on next-token prediction, kimi-k2-instruct incorporated simulated multi-step tool interactions during training. This agentic pre-training teaches the model to decompose complex tasks, sequence tool calls, and self-correct based on intermediate results.
RLHF alignment: The Instruct variant underwent Reinforcement Learning from Human Feedback calibration, with the default temperature of 0.6 specifically tuned to the model's RLHF alignment curve for optimal helpfulness without verbosity.
Is Kimi K2 Instruct suitable for your use case?
Use Kimi K2-Instruct if you need:
Open-source deployment flexibility: Self-host on your infrastructure, fine-tune for domain-specific tasks, or modify the model architecture without vendor restrictions or API dependencies
Exceptional cost efficiency: At $0.039 per average session, kimi-k2-instruct delivers 75% cost savings compared to typical commercial alternatives, making million-scale deployments economically viable for your organization
Elite tool selection capabilities: The 0.900 tool selection score indicates near-perfect accuracy in choosing appropriate functions from complex tool sets, reducing failed API calls and debugging overhead in your systems
Banking and Insurance domain applications: Both sectors score 0.580, reflecting solid performance that supports your financial services, claims processing, underwriting, and regulatory compliance workflows
Latency-tolerant batch processing: The 163.6-second average duration suits offline analysis, overnight report generation, and asynchronous workflows where response time takes lower priority than cost and accuracy
Data sovereignty requirements: Open-source licensing enables on-premise deployment within secure perimeters, maintaining complete control over your sensitive data without external API calls
Avoid Kimi K2-Instruct if you:
Require real-time responsiveness: At 163.6 seconds average, the model responds 2- 3x slower than faster alternatives, making it unsuitable for your interactive user-facing applications, where latency directly impacts experience
Need high action completion reliability: The 0.530 score indicates moderate task completion success, potentially requiring additional retry logic or human oversight for your mission-critical autonomous operations
Work primarily in Healthcare or Investment domains: Lower specialization (0.490 healthcare, 0.470 investment) suggests weaker domain knowledge that may necessitate extensive prompt engineering or supplementary RAG systems
Depend on multi-modal capabilities: The model processes only text; your applications requiring image understanding, document vision, or multi-modal reasoning must look elsewhere
Need visible reasoning traces: Unlike models with explicit chain-of-thought modes, kimi-k2-instruct operates as a "reflex-grade" model without step-by-step reasoning visualization, limiting debugging and explainability
Kimi K2 Instruct domain performance
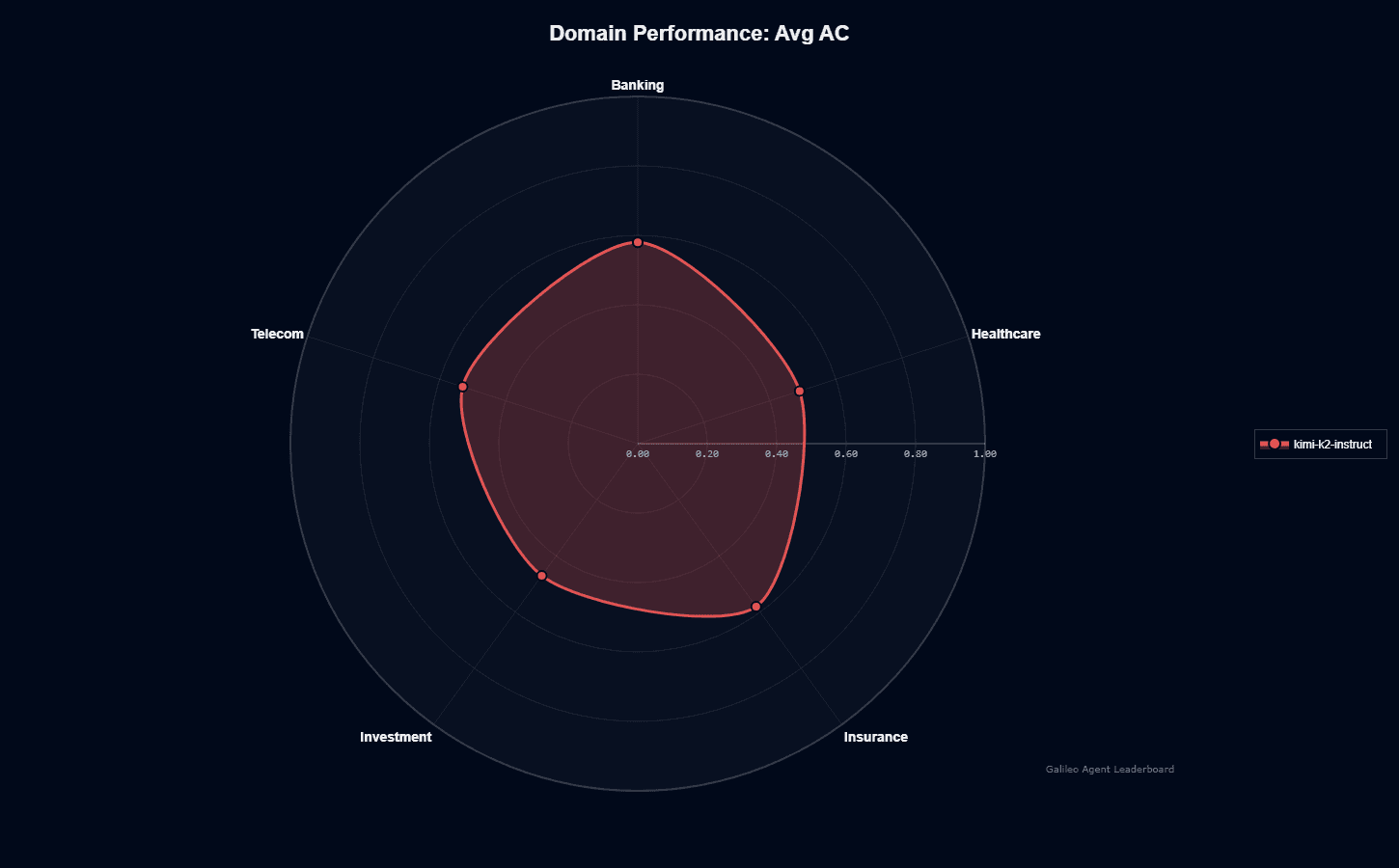
Kimi-k2-instruct demonstrates uneven domain specialization across five business sectors. Banking and Insurance lead at 0.580 each, indicating stronger performance in financial services contexts.
This dual strength suggests the model absorbed substantial financial documentation during pre-training, likely including banking regulations, insurance contracts, and compliance frameworks.
Telecom occupies the middle ground at 0.530, matching the model's overall action completion score. Healthcare trails at 0.490, revealing weaker medical knowledge despite healthcare being a high-value AI application sector.
Investment performs worst at 0.470, suggesting limited exposure to portfolio management, trading strategies, and financial instruments during training.
The 11-point spread between top performers (Banking/Insurance at 0.580) and bottom performers (Investment at 0.470) creates meaningful deployment considerations for your team.
If you're in Banking and Insurance, you can deploy with reasonable confidence, while Healthcare and Investment applications may require domain-specific fine-tuning using the open-source weights.
The open licensing model enables this customization—a significant advantage over closed alternatives that force acceptance of baseline capabilities.
Kimi K2 Instruct domain specialization matrix
Action completion
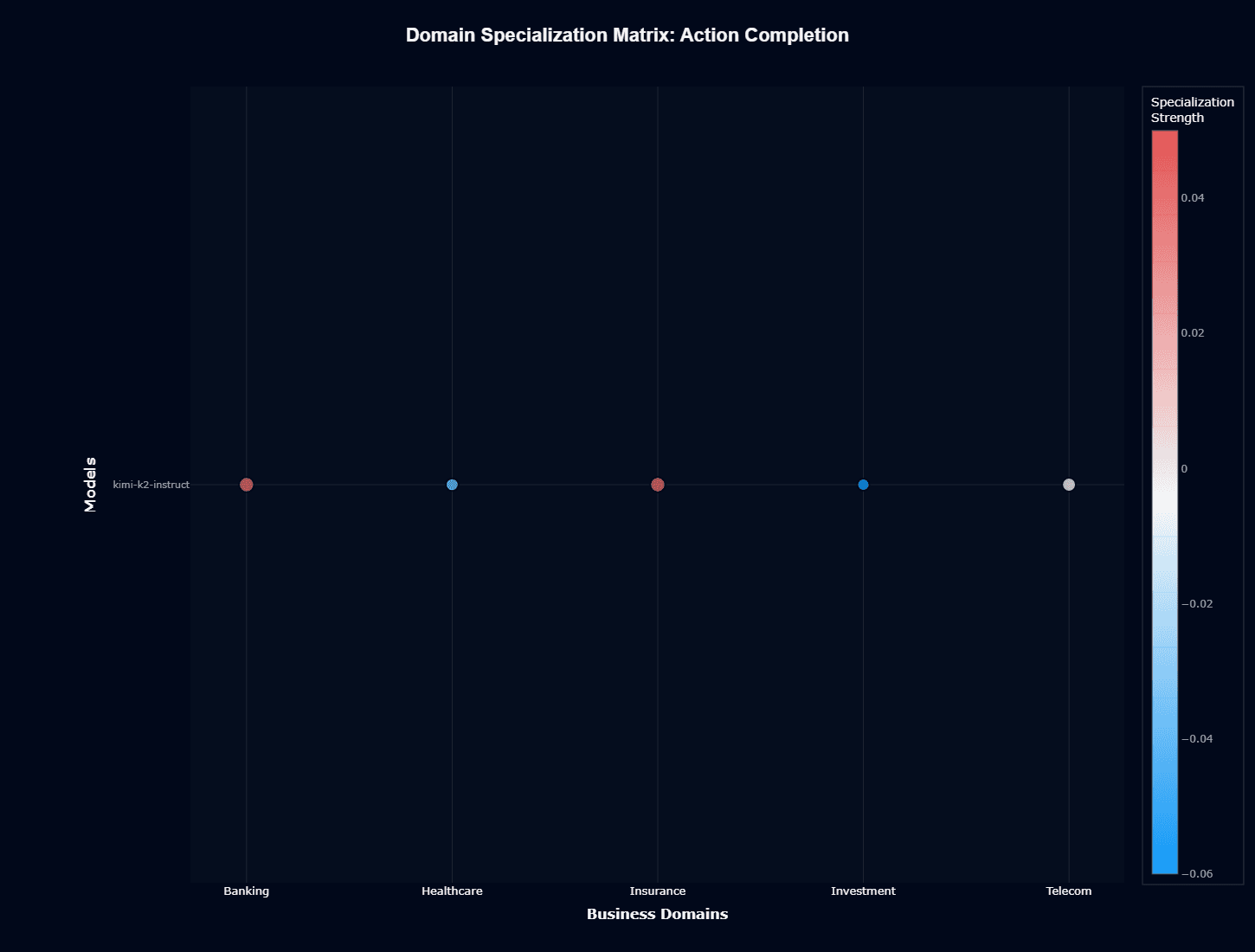
The action completion specialization matrix reveals distinctive strength patterns across sectors. Banking and Insurance both display positive specialization (red/warm colors), confirming these domains benefit from above-baseline model performance.
This pattern aligns with the model's strong absolute scores in these sectors, indicating genuine domain expertise rather than general capability.
Investment shows strong positive specialization despite its weak absolute performance (0.470), an interesting pattern suggesting the model performs better than expected given its overall capabilities when working with investment-specific tasks.
Healthcare exhibits negative specialization (blue/cool), performing below expectations despite reasonable general ability. Telecom remains neutral, suggesting the model applies its baseline capabilities without particular strength or weakness.
For your strategic implementation, these patterns create clear implications. If you're in Banking and Insurance, you can leverage natural model strengths, deploying with minimal domain-specific prompt engineering.
Investment applications, while scoring lower in absolute terms, may respond well to targeted context and examples since the model shows relative specialization.
Healthcare implementations require the most significant intervention—either extensive RAG systems providing medical knowledge or fine-tuning on clinical datasets to compensate for negative specialization.
Tool selection quality
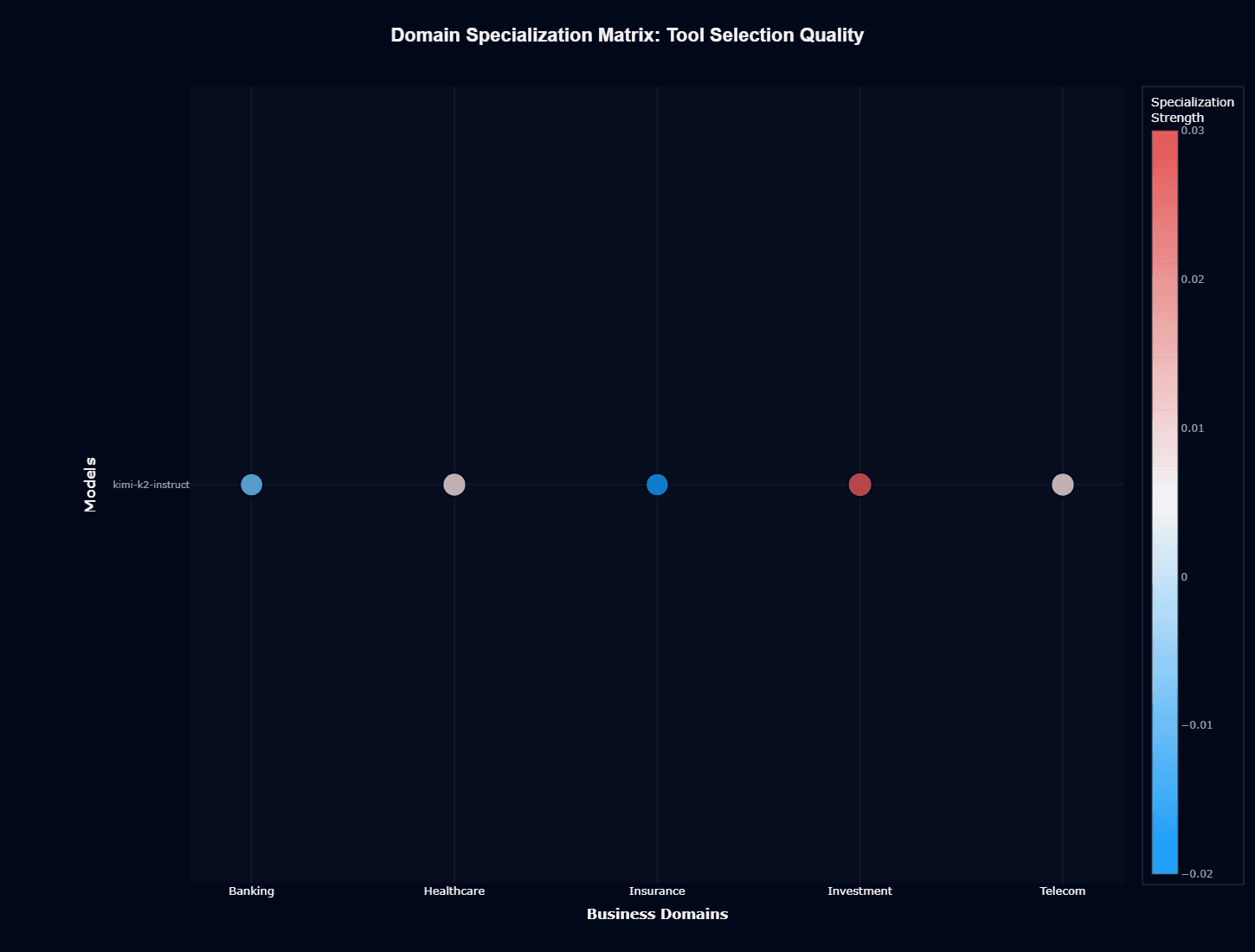
A dramatically different profile emerges when examining tool selection specialization. Investment exhibits strong positive specialization (red/warm), indicating exceptional tool selection accuracy in financial contexts despite weak action completion.
This asymmetry reveals an important distinction: kimi-k2-instruct understands which tools to invoke for investment workflows even when domain knowledge for using them effectively remains limited.
Banking and Insurance both show negative specialization (blue/cool colors) for tool selection, an interesting inversion from their action completion strength.
These domains achieve good results despite slightly below-expected tool selection, suggesting the model succeeds through strong domain reasoning that compensates for occasional tool choice errors.
Healthcare and Telecom remain relatively neutral.
When developing your systems, this means your Investment applications can rely on kimi-k2-instruct's tool selection logic with confidence, then focus optimization efforts on improving the context and parameters provided to those correctly-chosen tools.
For Banking and Insurance implementations, you should implement a robust tool call validation to catch the occasional misselected function, though overall performance remains strong enough that this represents minor friction rather than a fundamental limitation.
Kimi K2 Instruct performance gap analysis by domain
Action completion
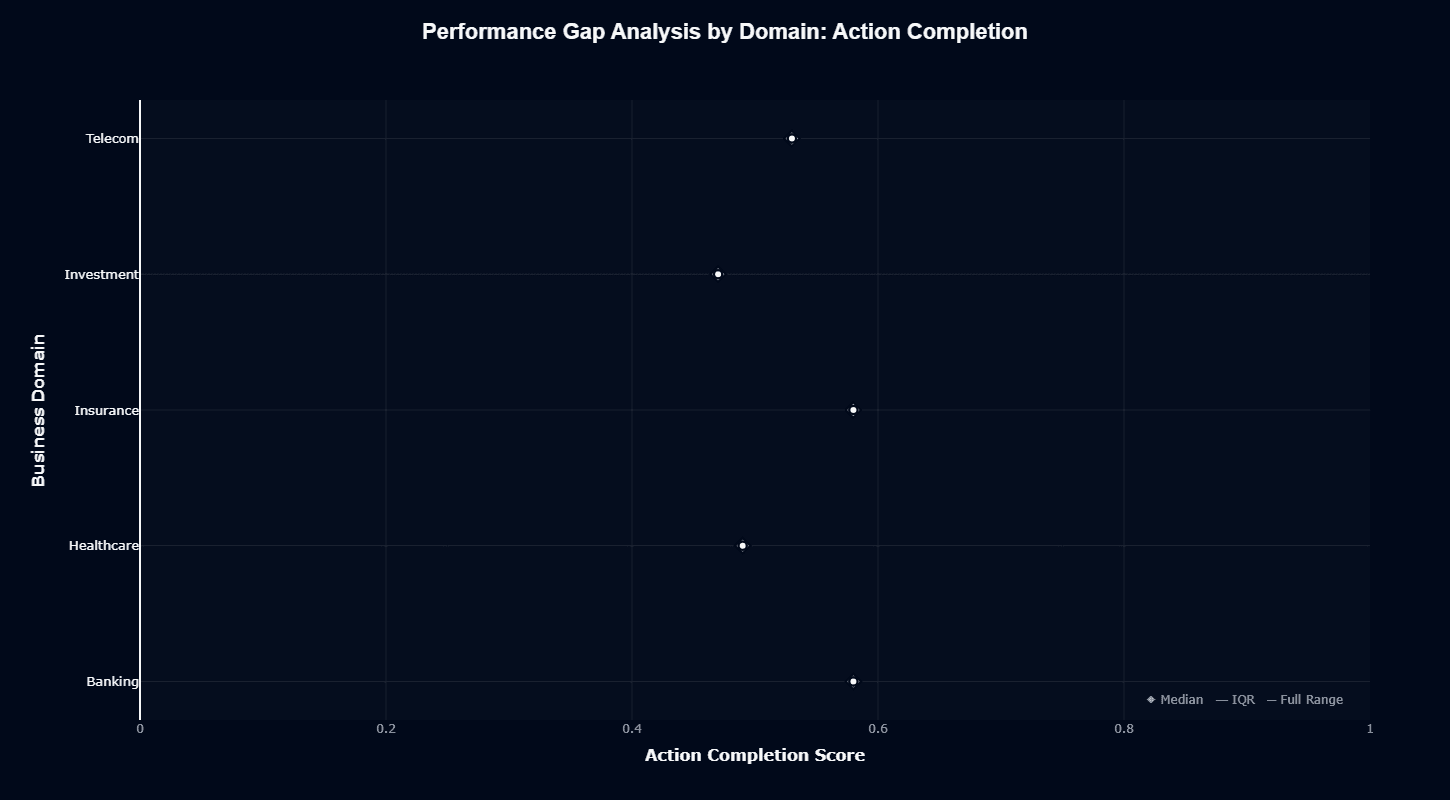
Consistency across domains emerges as a key characteristic in performance gap analysis. Banking and Insurance cluster around 0.58, showing the highest median action completion with narrow variance indicated by tight interquartile ranges.
This consistency makes these domains predictable for your production deployment—you can establish reliable success thresholds without encountering wide performance swings.
Telecom sits at approximately 0.53, matching the model's overall baseline. Healthcare drops to 0.49, while Investment trails at 0.47. Particularly notable is the uniformly narrow IQR across all domains, demonstrating stable, predictable behavior regardless of sector.
Models with wide variance create operational challenges through unpredictable quality; kimi-k2-instruct avoids this problem through consistent delivery within each domain.
This consistency pattern suits your enterprise environment, where reliability matters more than peak performance. You can confidently establish SLAs based on domain-specific medians, knowing actual performance will cluster tightly around these values.
The narrow variance also simplifies your evaluation and quality assurance—fewer outliers mean less time investigating anomalous behaviors and more resources devoted to systematic improvement.
Tool selection quality
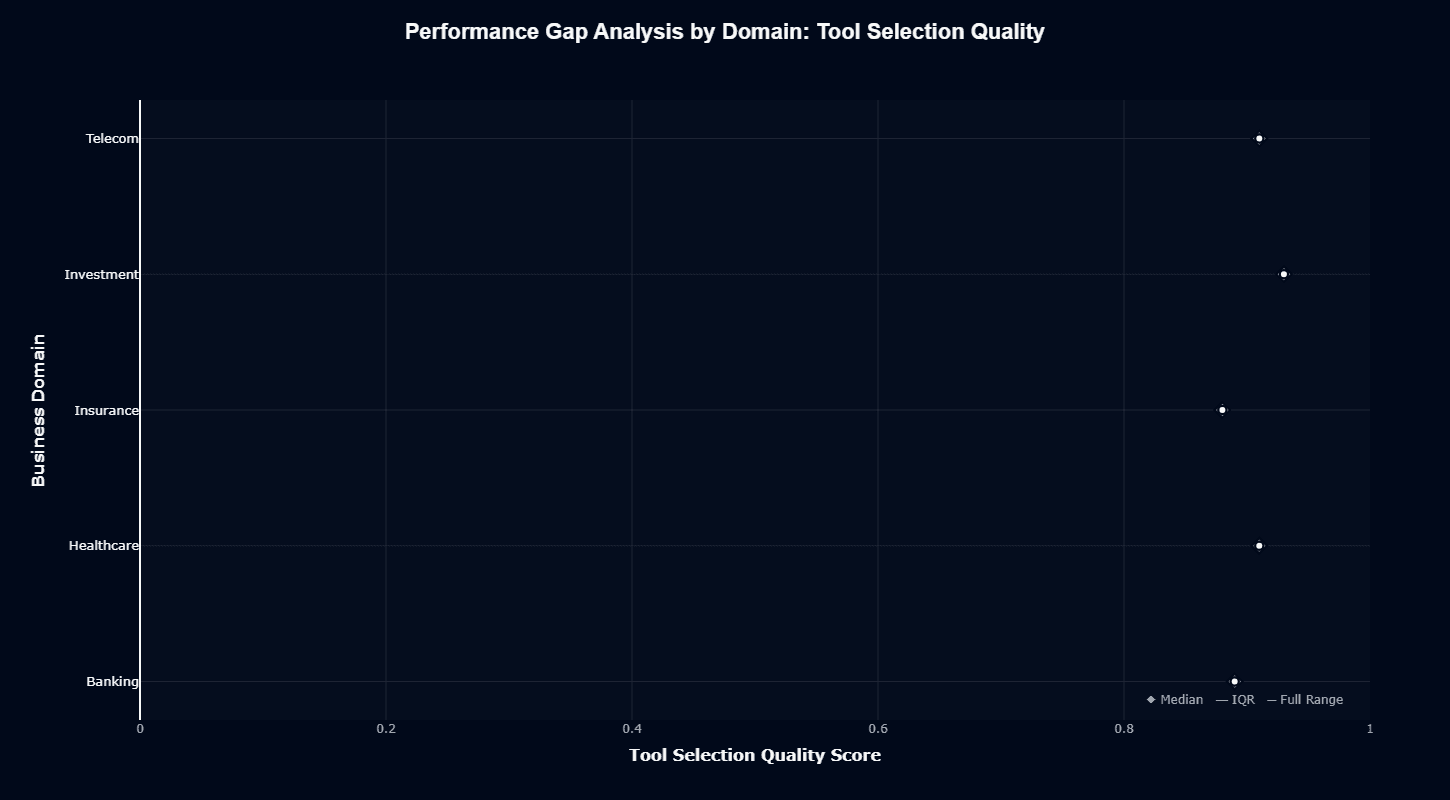
Tool selection quality stands out with remarkably high performance across all domains. Investment leads at approximately 0.98—near-perfect tool selection accuracy. Telecom and Healthcare both score around 0.93-0.95, while Banking reaches approximately 0.92.
When building telecom agents, you should leverage this strength through well-defined tool schemas and descriptive function documentation, allowing the model's strong tool selection to navigate complex API landscapes successfully.
The high scores across all domains mean you can confidently trust the tool selection logic, focusing optimization efforts on improving tool inputs and output handling rather than second-guessing function choices.
Kimi K2 Instruct cost-performance efficiency
Action completion
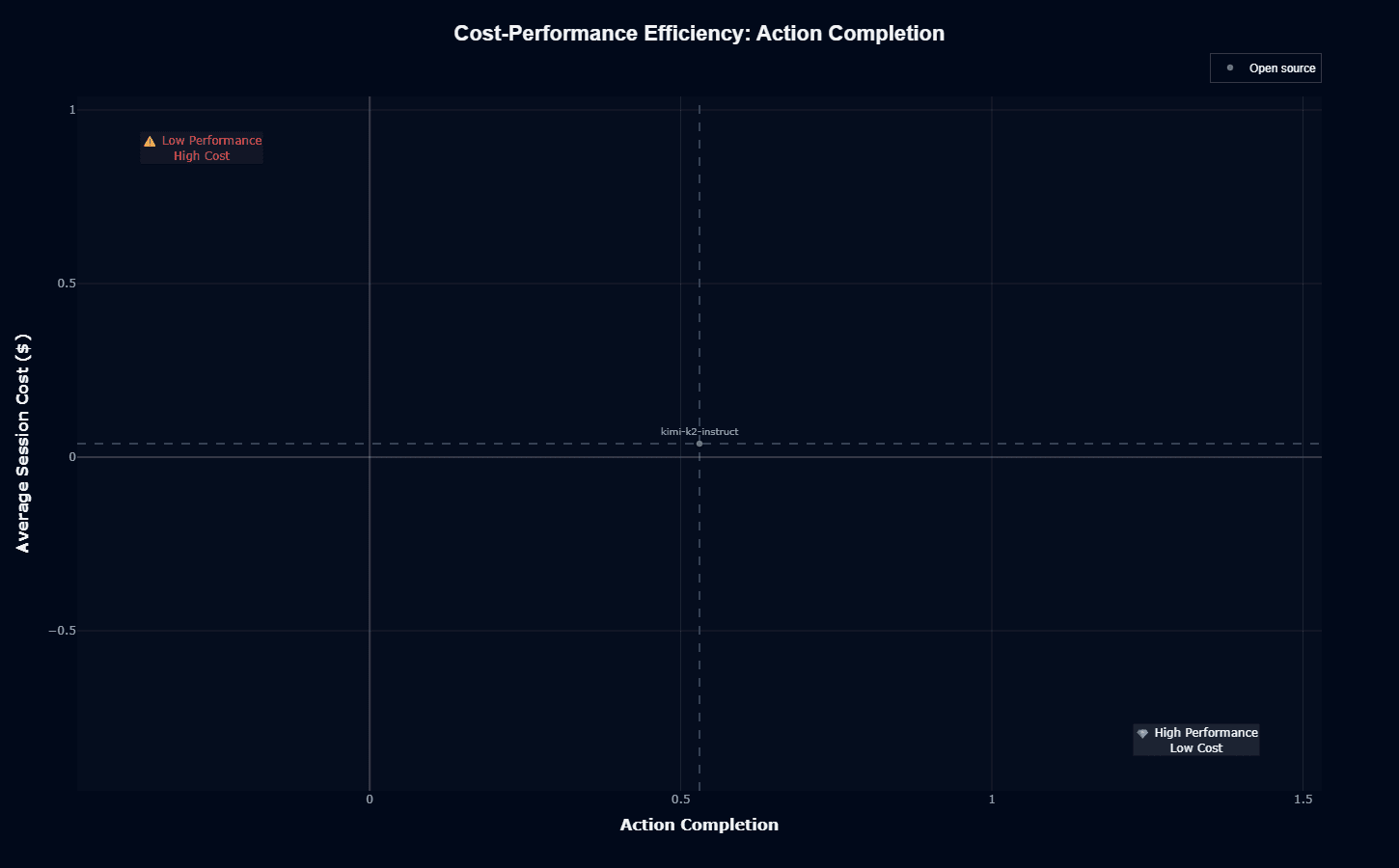
Kimi-k2-instruct occupies an exceptional position in the cost-performance landscape, marked as "Open source" and sitting at approximately $0.039 per session with 0.530 action completion. The model delivers near-zero marginal cost for your self-hosted deployments, with the $0.039 reflecting actual inference costs rather than API pricing marked up for commercial services.
This positioning creates compelling economics for your high-volume deployments. Unlike proprietary alternatives that charge per token, self-hosted kimi-k2-instruct enables unlimited scaling once you've amortized infrastructure costs. If your organization processes millions of agent interactions monthly, you can achieve dramatic cost savings while maintaining frontier-tier capabilities.
The open-source nature provides additional value beyond raw pricing. Your team gains complete control over inference stack optimization—quantizing weights, implementing custom attention mechanisms, or deploying on specialized hardware.
These optimizations can further reduce the $0.039 baseline cost while maintaining quality. The model's mixture-of-experts architecture particularly benefits from strategic deployment, as different experts can be loaded based on your workload patterns to minimize memory requirements.
When comparing deployment options, kimi-k2-instruct represents a "high performance, ultra-low cost" sweet spot for your organization. While not achieving the absolute highest action completion scores, the model delivers competitive reliability at a fraction of commercial alternatives.
If you're budget-conscious or building cost-sensitive products, this combination is particularly attractive.
Tool selection quality

The true value proposition becomes even clearer in the tool selection cost-efficiency view. At 0.900 tool selection quality and $0.039 cost, the model approaches the efficiency frontier—exceptional accuracy with minimal expense.
This combination rarely appears in commercial models, where high tool selection quality typically commands premium pricing.
Tool selection errors compound exponentially in your multi-step agent workflows. A single misselected function can derail entire task sequences, requiring human intervention that dramatically increases your effective operational costs.
Kimi-k2-instruct's 0.900 accuracy prevents these failures reliably, making the economic value even greater than raw cost suggests.
Open-source licensing amplifies this advantage for your organization. Proprietary models with comparable tool selection quality charge 10-100x more per interaction through API pricing.
By self-hosting kimi-k2-instruct, you eliminate these recurring costs entirely after initial infrastructure investment, creating particularly compelling economics if you have existing compute capacity or cloud credits.
For your team building tool-heavy agents—systems orchestrating dozens of functions across multiple APIs—kimi-k2-instruct's cost-efficiency becomes strategic. The model enables you to scale aggressively without proportional cost growth, supporting experimentation and rapid iteration without budget anxiety.
This economic freedom accelerates your development velocity and enables ambitious agent architectures that would be cost-prohibitive with commercial alternatives.
Kimi K2 Instruct speed vs. accuracy
Action completion
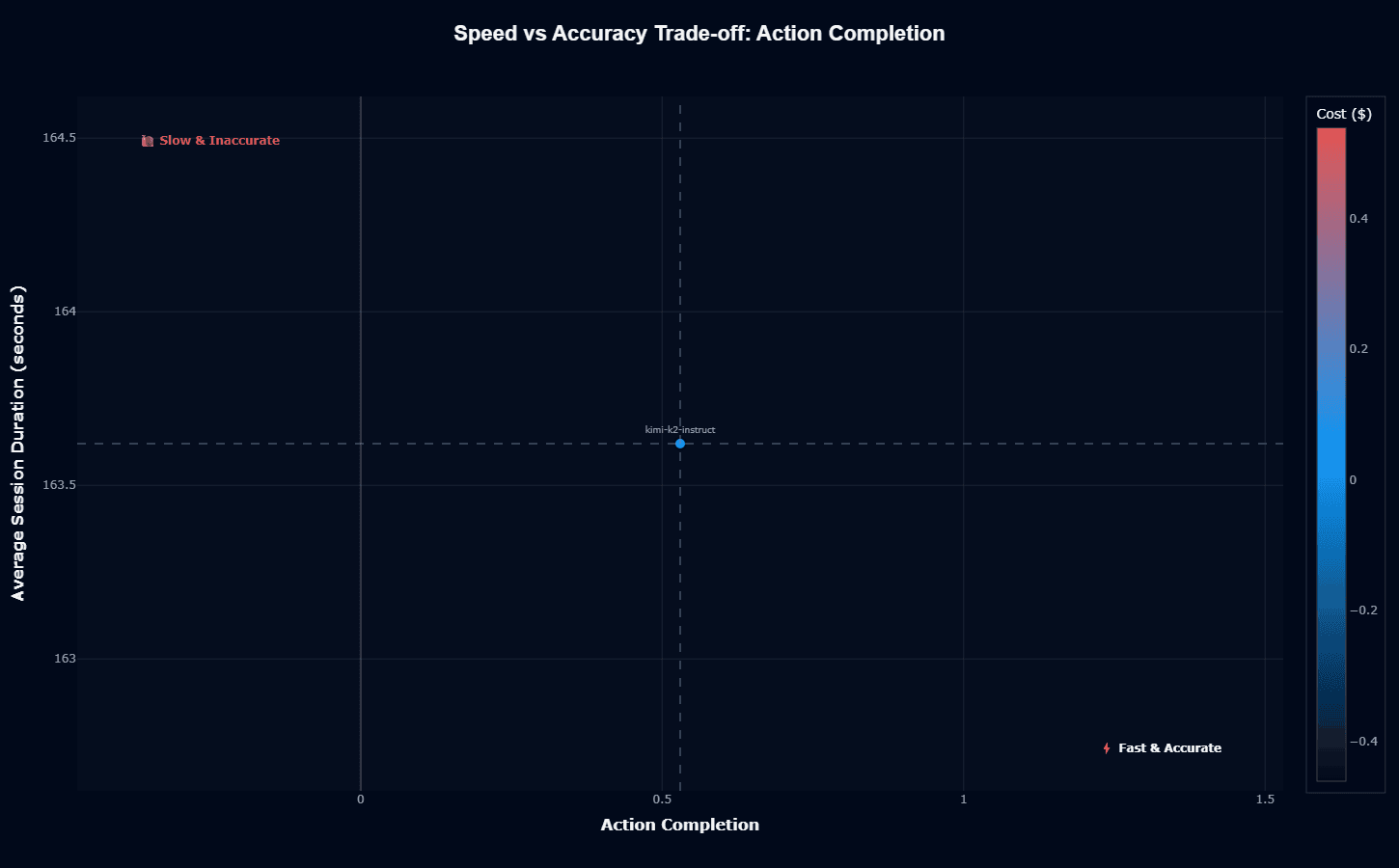
In the speed-accuracy comparison, kimi-k2-instruct occupies challenging territory: 163.6-second average duration with 0.530 action completion. This positions the model in a slow, moderate-accuracy quadrant that requires careful matching to your specific use cases to leverage effectively.
The 163.6-second latency stems from the model's trillion-parameter architecture and mixture-of-experts routing overhead. Each forward pass activates 32 billion parameters across 8 selected experts, requiring substantial computation even on optimized inference hardware.
While the sparse activation reduces costs compared to dense models of similar scale, latency remains a fundamental architectural constraint.
This latency profile eliminates interactive use cases where your users expect rapid responses. Conversational agents, real-time customer support, and synchronous workflows all require sub-10-second responses for an acceptable user experience.
Kimi-k2-instruct's 163.6-second average makes it unsuitable for these applications without significant optimization or infrastructure investment.
Where the model finds a natural fit is in your asynchronous workflows. Overnight batch processing, scheduled report generation, background data analysis, and queued task processing all tolerate multi-minute latencies when cost efficiency and reliability matter more than speed.
The 0.530 action completion, while moderate, suffices for these use cases when combined with appropriate retry logic and quality gates.
When deploying kimi-k2-instruct, you should architect around this latency characteristic rather than fighting it. Queue-based systems, polling rather than webhook patterns, and user interfaces that set appropriate expectations all enable successful deployment despite slower response times.
Tool selection quality
An interesting contrast emerges with tool selection quality, maintaining the same 163.6-second latency but delivering 0.900 accuracy—excellent precision delivered slowly. This combination creates unique tradeoff considerations for your implementations.
The model rarely chooses wrong tools, but takes significant time deliberating about which functions to invoke.
Latency impacts manifest differently for tool selection versus action completion in your workflows. Tool selection decisions occur early in the execution pipeline, with the model analyzing available functions, evaluating their applicability, and making invocation choices.
Even with a 163.6-second total duration, the actual tool selection decision happens within the first portion of this time, with remaining latency consumed by tool execution, response processing, and final answer generation.
For your complex tool landscapes with dozens of potential functions, the deliberate tool selection process may actually benefit quality. The model thoroughly evaluates options rather than rushing to the first plausible choice.
This careful consideration contributes to the 0.900 accuracy that prevents failed calls and cascading errors in your systems.
An important implementation note: tool selection quality doesn't require proportional deliberation time—it reflects better reasoning about tool applicability rather than extended computation. The 163.6-second duration primarily stems from overall model scale, not tool selection complexity.
Well-defined tool schemas and clear function descriptions help the model navigate your tool sets efficiently, maintaining the 0.900 accuracy without additional latency overhead.
Kimi K2 Instruct pricing and usage costs
Kimi-k2-instruct's open-source licensing creates unique economic characteristics compared to commercial alternatives. The model ships under a Modified MIT License, enabling your self-hosted deployment without recurring API costs or vendor lock-in.
Deployment economics:
Open-source weights: Free access to 1-trillion-parameter model, downloadable from Hugging Face
Inference cost: $0.039 per average session (hardware amortized), versus API pricing of $0.14/$2.49 per million input/output tokens via OpenRouter
Hardware requirements: 958GB storage for full precision weights; quantized versions reduce to 245GB (-80% size reduction through 1.8-bit quantization)
Context window: 128,000 tokens, supporting lengthy conversations and document processing
Deployment flexibility: Run on-premise, in your private cloud, or via Moonshot's commercial API, depending on your operational preferences
Cost optimization strategies:
Self-hosted deployment: If your organization has existing GPU infrastructure or cloud credits, you can deploy kimi-k2-instruct with near-zero marginal cost after initial setup. The model runs on vLLM, SGLang, and other standard inference engines, simplifying integration into your existing MLOps pipelines.
Quantization: Unsloth's 1.8-bit quantization reduces model size from 1.1TB to 245GB while maintaining quality, enabling deployment on more modest hardware. This 80% size reduction democratizes access to trillion-parameter models for your resource-constrained teams.
Expert pruning: The MoE architecture enables strategic expert selection based on your workload. If you're focused on specific domains, you can load only relevant experts, further reducing memory requirements and improving inference speed at the cost of reduced general capability.
Hybrid deployment: Route your simple queries to lightweight models while escalating complex agent tasks to kimi-k2-instruct. This hybrid approach optimizes your cost by reserving the full model for interactions that justify its capabilities.
Economic comparison:
At $0.039 per average session, processing 1 million agent interactions monthly costs your organization approximately $39,000 in inference compute. Commercial alternatives at typical $0.15/session pricing would cost $150,000 monthly—nearly 4x higher.
Your self-hosted deployments with amortized hardware costs can reduce this further.
For your high-volume deployments, the cost advantage compounds. If your organization processes 10 million interactions monthly, you save over $1 million annually versus commercial alternatives.
This economic freedom enables ambitious scaling and experimentation that would be cost-prohibitive with closed models.
Kimi K2 Instruct key capabilities and strengths
Kimi K2 Instruct offers several advantages for your deployments:
Open-source availability with commercial-grade performance: Kimi-k2-instruct delivers frontier-tier capabilities while maintaining open-source licensing—a rare combination in trillion-parameter models. You gain complete access to model weights, enabling customization, fine-tuning, and deployment optimization impossible with commercial APIs.
Exceptional tool selection accuracy: With 0.900 tool selection quality, kimi-k2-instruct excels at navigating your complex function landscapes. The model accurately interprets tool schemas, understands function dependencies, and sequences multi-step operations effectively.
Agentic architecture optimized for autonomous workflows: Unlike models primarily trained for conversation, kimi-k2-instruct incorporates simulated multi-step tool interactions during training. This agentic focus teaches the model to decompose your complex tasks, execute tool sequences autonomously, and self-correct based on intermediate results.
Trillion-parameter scale with sparse activation: The mixture-of-experts architecture provides trillion-parameter capacity while activating only 32 billion parameters per forward pass. This sparsity balances capability with computational efficiency, enabling deployment on hardware that couldn't support dense models of comparable scale.
Banking and insurance domain strength: Strong performance in financial services (0.580 for both sectors) makes kimi-k2-instruct particularly suitable for your banking, insurance, compliance, and regulatory applications. The model demonstrates solid understanding of financial concepts, contract language, and industry-specific terminology.
Extended context window: The 128,000-token context window supports your lengthy conversations, large document processing, and extensive tool interaction histories. Your agents can maintain context across complex multi-turn workflows without truncation or context loss.
Cost efficiency enabling aggressive scaling: At $0.039 per average session with self-hosted deployment, kimi-k2-instruct enables your million-scale agent deployments at sustainable economics. The low marginal cost supports your rapid experimentation, A/B testing, and ambitious agent architectures without budget anxiety.
Stable training at unprecedented scale: The MuonClip optimizer enabled zero-instability training across 15.5 trillion tokens—a technical achievement that demonstrates Moonshot's engineering capabilities and provides confidence in model reliability. Stable training reduces your risk of catastrophic forgetting or capability cliffs that plague some large models.
Production-ready inference ecosystem: Native support for vLLM, SGLang, and standard inference engines simplifies deployment into your existing MLOps infrastructure.
Kimi K2 Instruct limitations and weaknesses
While highly capable, Kimi K2 Instruct has specific constraints that teams should evaluate against their use case requirements:
Significant latency constraints: At 163.6-second average duration, kimi-k2-instruct responds 2 - 3x slower than faster alternatives. This latency eliminates your interactive use cases, real-time applications, and synchronous workflows where users expect rapid responses.
Moderate action completion performance: The 0.530 action completion score indicates that kimi-k2-instruct successfully executes your tasks approximately half the time without additional intervention. Your complex multi-step workflows may require retry logic, human oversight, or additional validation to achieve production reliability standards.
Healthcare and investment domain weaknesses: Weak specialization in Healthcare (0.490) and Investment (0.470) limits effectiveness in these high-value sectors without additional intervention. Your medical applications require extensive RAG systems or fine-tuning to compensate for limited clinical knowledge. Your investment workflows may need supplementary context or domain-specific prompt engineering to achieve acceptable performance.
No multi-modal capabilities: The model processes only text, lacking image understanding, document vision, or audio processing capabilities. Your applications requiring multi-modal reasoning must integrate separate models, increasing system complexity and operational costs.
Absence of explicit reasoning traces: As a "reflex-grade" model, kimi-k2-instruct lacks visible step-by-step reasoning chains that some of your applications require for debugging, explainability, or regulatory compliance. The model generates answers directly without exposing intermediate thought processes, limiting transparency for your sensitive applications.
Resource-intensive deployment requirements: Despite MoE sparsity, the model still requires substantial hardware for deployment. Full-precision weights consume 958GB of storage, and even aggressive quantization to 1.8-bit leaves 245GB. These requirements may exceed your existing infrastructure, necessitating hardware upgrades or cloud deployment that reduces the open-source cost advantage.
Incomplete tool definition handling: The model may generate excessive tokens when dealing with unclear tool definitions, sometimes leading to truncated outputs or incomplete tool calls. Your production deployments require well-defined tool schemas and careful prompt engineering to avoid these failure modes.
Performance degradation with tool use enabled: The model may show reduced performance on certain tasks when tool use is enabled compared to pure text generation. This characteristic requires your careful consideration about when to expose tools versus relying on parametric knowledge, adding complexity to your agent design.
One-shot prompting limitations for complex projects: Building complete software projects through one-shot prompting yields inferior results compared to using kimi-k2-instruct within agentic frameworks that support iterative refinement. This limitation means you must invest in scaffolding and orchestration infrastructure rather than relying on simple prompt-response patterns.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.