
How to Govern AI Agents When 57% of Leaders Don't Trust Their Outputs

AI leaders reveal a stark reality: 57% don't fully trust their agents' outputs, and 60% can't explain how those agents use sensitive data. Only 9% of enterprises operate with a mature AI governance framework, yet autonomous agents already drive critical workflows.
These numbers expose a widening gap—you're shipping code that reasons and acts independently faster than you can monitor it.
Traditional controls—periodic audits, manual sign-offs, static risk reviews—were built for deterministic software. Agents spawn recursive tool calls, ingest fresh data, and hallucinate new instructions in milliseconds.
One ungoverned decision ripples across APIs, customers, and regulators long before you spot the blast radius.
This 10-step framework closes that gap. You'll start with a lightweight pilot, layer in measurable guardrails, and automate oversight as scale demands. The result is governance that lets you accelerate agent deployment, satisfy risk teams, and keep executive confidence—all without killing innovation.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies
Step #1: Kick-off with a lightweight pilot and success metrics
You probably feel the pressure to draft thick binders of AI policies before anyone writes a single line of agent code. Yet the stark governance maturity gap shows that over-engineering early rules rarely delivers real assurance.
Rather than get bogged down in committee deliberations, launch a 30-day pilot that proves value while exposing risks in a controlled setting. Pick a low-risk, highly visible workflow—think internal ticket triage or FAQ deflection—so results resonate across teams but no customer data is at stake.
Agree on just two or three measurable targets: ticket deflection rate, mean time to detect (MTTD) incidents, and customer satisfaction (CSAT) often reveal the impact fastest.
Document the experiment in a single-page charter that names owners, KPIs, and start-to-end dates, then store it in your central agent inventory. This lightweight artifact satisfies audit needs without slowing iteration, addressing the risk where unsanctioned agents proliferate outside official oversight.
When the pilot closes, you'll have hard numbers to rally the cross-functional Agent Council that shapes every subsequent governance step.

Step #2: Assemble a cross-functional "Agent council"
Siloed teams almost guarantee blind spots. The enterprise governance maturity gap often traces back to fragmented oversight—when your data scientists, risk officers, and security engineers each set rules in isolation, conflicting standards emerge, and no one feels fully accountable.
You sidestep this chaos by convening an Agent Council where every critical viewpoint sits at the same table. The core seats rarely change:
AI/ML lead
Risk or compliance officer
Product owner
Security representative
Line-of-business sponsor
Executive champion
Once those roles are locked in, speed becomes your ally. Have the executive sponsor draft a three-bullet mandate email spelling out objectives, decision rights, and expected time commitment.
During your 30-day pilot, bi-weekly syncs capped at 30 minutes keep things moving—projecting screenshots anchors everyone to the same evidence rather than subjective opinions.
The council itself needs governance, too. Publish a lightweight charter, rotate the chair quarterly, and map RACI responsibilities so escalation paths stay clear as new agents appear. This cross-functional rhythm transforms governance from paperwork into shared ownership that scales with every workflow you automate.
Step #3: Map the agent lifecycle and risk surface
"You can't govern what you haven't mapped." Until you see every hand-off, dataset, and tool call, hidden failures slip past reviews and land in auditors' reports. Most teams jump straight to policies, but blind spots in the lifecycle keep surfacing, forcing endless patchwork fixes.
Start with a visual inventory that shows where risk actually lives.
Sketch the full journey of a single agent—design, development, staging, production, and eventual retirement. Under each phase, note the prompts, fine-tuning sets, external APIs, and user contexts the agent touches.
This living inventory satisfies the first requirement of an AI risk maturity assessment while exposing "shadow" data flows that siloed teams often miss.
Once you have your map, feed those execution traces into Galileo’s Insights Engine. It clusters previous outages and hallucination spikes, highlighting the hotspots that need controls before code reaches production.
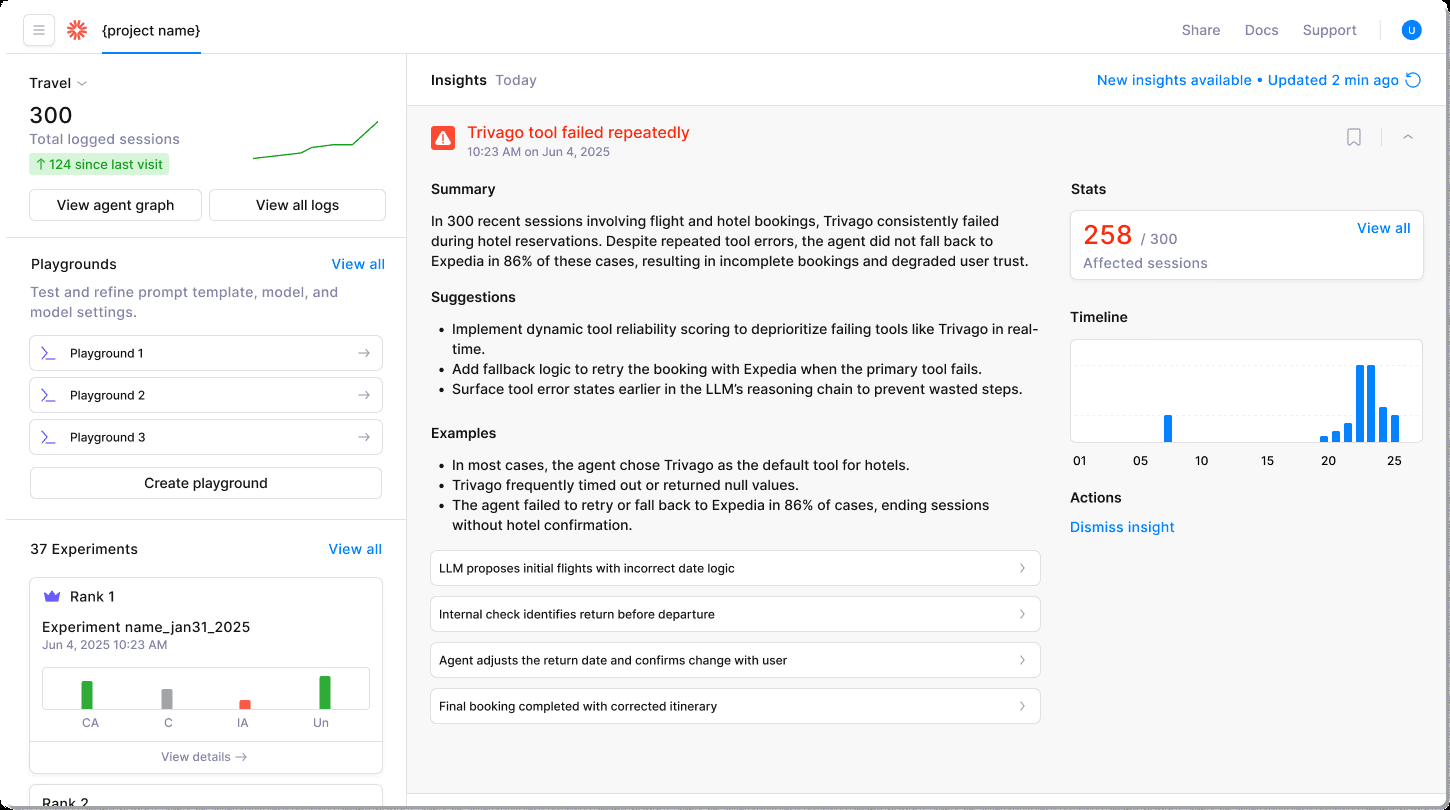
Transform these findings into an Agent Risk Matrix—rate every node by severity and likelihood, then list the guardrails you can apply. Traditional chatbot diagrams ignore tool-selection loops and planning cycles. Your matrix shouldn't.
This finished map becomes your foundation for the next step's policy work—evidence-backed, gap-free, and ready for cross-functional scrutiny.
Step #4: Draft baseline policies & guardrail requirements
Shelf-ware policies look impressive in a wiki but do nothing when your agent hallucinates in production. Security leaders' lack of confidence in system transparency and accuracy repeatedly surfaces in agentic incidents.
With the EU AI Act's risk-based obligations and widely adopted frameworks such as NIST's AI RMF raising the bar, you need policies that engineers actually embed in code.
Start by grouping requirements into four clear buckets that map directly to business risk:
Data privacy guidelines
Hallucination thresholds
Tool access scope and limitations
Human override protocols
Each bucket demands concrete, testable targets that leave no room for interpretation. "≤ 1% hallucination rate," "No PII in outbound text," or "Mandatory human review for transactions over $10,000" become enforceable standards rather than aspirational goals.
Guardrail platforms like Galileo translate those sentences into machine-readable rules. Keeping the file under 100 lines forces clarity, and linking each rule to a measurable evaluator means violations surface instantly—fuel for the deep observability you'll instrument in the next step.
Step #5: Instrument agents for deep observability
Most agents fail mysteriously in production, leaving teams scrolling through endless traces without understanding why a tool selection loop started or decisions suddenly changed. Traditional log aggregators capture events but miss the reasoning chain—that critical "why" behind each choice.
This opacity creates real problems: most security leaders admit they can't fully explain their agents' behavior, directly undermining compliance confidence.
Most teams also try manual log analysis, burning hours without finding root causes. Purpose-built agent observability changes this dynamic entirely.

Start by integrating the Graph Engine—it traces every multi-turn, multi-agent interaction without touching your business logic. Tag each decision node with its governing policy ID, creating direct links between violations and specific rules.
Stream these enriched traces to real-time analytics that flag anomaly patterns like tool selection loops or sudden latency spikes.
Capture arguments, return values, and internal reasoning while automatically redacting sensitive data for GDPR compliance. Route curated traces to your governance dashboard, creating a living map of agent behavior that supports audits, feeds council reviews, and transforms transparency from aspiration into operational reality.
Step #6: Establish continuous evaluation metrics
You can't manually review thousands of daily agent interactions—yet most teams still rely on spot-checks that miss critical failures. Research shows fewer than one-third of enterprises formally track governance performance with defined indicators, creating blind spots that regulators and customers eventually expose.
Traditional post-mortem analysis just fails when agents operate at scale.
Start with a balanced scorecard targeting five to seven core indicators that matter. Most teams anchor on tool-selection precision, task-completion rate, response coherence, compliance score, and fairness deviation—covering technical, business, and ethical dimensions.
This addresses concerns from security leaders who doubt their systems' reliability. Your metrics should span the full governance spectrum, not just technical performance.
Wire measurement directly into your delivery pipeline for real-time visibility. You can leverage Luna-2 small language models to score every interaction in under 200 ms at roughly 3% of GPT-4 cost, so you catch regressions the moment they appear instead of discovering them weeks later.

Feed production results back through Continuous Learning via Human Feedback, letting your evaluators evolve as policies tighten and data shifts. When you gate releases and connect real-time scores to your dashboards, evaluation becomes the operational heartbeat that keeps your governance framework responsive and audit-ready.
Step #7: Implement runtime protection & intervention paths
You might assume that an agent scoring 98% in staging will behave just as well in production, yet live traffic later tells a different story. Runtime attacks—prompt injections, data-exfiltration beacons, even "sleeper" backdoors—only surface when real users and real data collide with your model.
Start by placing Galileo's Agent Protect in shadow mode. You watch, but don't interfere, collecting a baseline of suspicious prompts, tool calls, and latency overhead.

Once the numbers are clear, flip from "listen" to "act": deterministic overrides block policy violations—say, leaking PII or exceeding a $10,000 transaction limit—while every intervention gets written to an immutable log for post-mortem analysis.
Latency matters, so keep enforcement rules precise. Replace blanket request blocking with context-aware fallbacks: redact only the sensitive field, or route the task to a human when confidence dips below the threshold.
Pair these controls with least-privilege IAM roles so an exploited agent can't drift laterally.
Real-world paths often combine PII redaction, harmful-content filtering, and financial guardrails. Implemented well, runtime protection becomes a safety net that investors and regulators respect, while your engineering team retains the freedom to push new agent capabilities into production at full speed.
Step #8: Build an audit-ready documentation & version control trail
Regulators expect a complete record of every autonomous decision your agents make. The EU AI Act demands traceability across the entire lifecycle, and SOC 2 auditors routinely trace decisions from data source to production output. Without that lineage, you face costly remediation or blocked deployments.
You probably store prompts in one repository, evaluation datasets in another, and screenshots scattered across Slack channels. Most enterprises lack mature, well-documented governance frameworks, leaving teams scrambling when audits arrive. That fragmentation destroys trust as quickly as a faulty model.
Successful teams centralize all artifacts—prompts, datasets, guardrail configurations—inside purpose-built platforms. Each commit links directly to a policy ID, so auditors can jump from governance rules to exact code changes in seconds.
Automatic change logs capture who altered what and why, replacing manual spreadsheets that inevitably fall out of date.
Standardize your templates and keep descriptions concise. Export cold-storage snapshots quarterly to satisfy GDPR retention requirements. With this disciplined approach, you walk into any internal review or external inspection with confidence backed by verifiable evidence.
Step #9: Operationalize review & escalation loops
Your governance framework dies the moment you stop feeding it attention. Most enterprises report immature AI oversight today precisely because policies become shelfware without an operational rhythm. You need systematic processes that make governance feel automatic, not burdensome.
Start with instrumentation that feeds a live dashboard, then set alert thresholds tied to your defined metrics. Every week, convene your Agent Council for focused 30-minute triage sessions—prune false positives and assign owners for genuine issues.
Close each month with a concise, metrics-first briefing to executives so leadership sees trends, not just incident reports.
Formal role clarity prevents chaos when problems hit production. Draft a lightweight RACI matrix spelling out who approves rollbacks, who contacts customers, and who fine-tunes evaluators.
Explicit ownership accelerates response time and limits liability. Pair this matrix with lifecycle gates—intake, recertification, retirement—so unresolved risks never slip through.
Finally, rotate an on-call governance steward each sprint. Fresh eyes prevent review fatigue and surface novel patterns your team might miss. The result is a living, self-correcting process that grows stronger as your agents gain autonomy.
Step #10: Scale governance through automation & continuous learning
Manual reviews crumble once you're wrangling hundreds of agents and millions of daily interactions. Frameworks built for single pilots often disintegrate at enterprise scale, creating blind spots that attackers and regulators exploit.
Start by encoding every guardrail as reusable policy-as-code templates, then integrate them into your CI/CD pipeline so new agents inherit controls automatically upon deployment. Weave governance data into your existing DevSecOps stack for maximum efficiency.
Policy breaches should trigger alerts in the same dashboards your security team monitors daily—shared context eliminates handoffs and cuts response times dramatically. Set an ambitious target of 95% governance coverage within six months and track progress with a living inventory that updates whenever agents are deployed or retired.
Regulation will evolve, autonomy will expand, and multi-agent ecosystems will proliferate. By converting oversight into executable code and coupling it with continuous learning loops, you build a self-reinforcing system that scales with your ambitions rather than your headcount.
Operationalize your AI governance with Galileo
You want to build something powerful—transforming a 30-day pilot into a fully automated governance pipeline that tames enterprise-scale agent deployments. Every risk surface needs to be mapped, policies codified, and continuous evaluation embedded so problems get caught before customers notice.
Here’s how Galileo accelerates every milestone:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you implement enterprise-grade multi-agent governance strategies and achieve reliable AI systems that users trust.

Conor Bronsdon