
Galileo vs. Langfuse: Real-Time Protection vs. Open Source Flexibility

Enterprise teams continue to pour millions into generative AI, yet the moment a model leaves the lab, most are blind to how it behaves in the wild. One silent hallucination, one leaked Social Security Number, and months of trust and budget, evaporate.
Observability platforms promise relief against these challenges that plague modern AI deployments, but they differ in terms of depth, speed, and cost.
If you're weighing enterprise-grade reliability against open-source flexibility, what follows breaks down how Galileo and Langfuse tackle visibility, scale, and total cost of ownership so you can invest with confidence.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
Galileo vs. Langfuse at a glance
Two platforms dominate conversations about AI observability: Galileo and Langfuse. Both handle complex LLM pipelines, but their philosophies couldn't be more different. Galileo focuses on agent reliability with deep analytics and real-time guardrails that prevent bad outputs from reaching production.
Langfuse takes an open-source approach centered on prompt-level tracing and cost transparency. The comparison below reveals how these different approaches translate into practical capabilities:
Feature | Galileo | Langfuse |
Core focus | Agent observability & runtime protection | Generic LLM tracing & logging |
Licensing & deployment | Commercial SaaS, hybrid or on-prem; closed core | MIT open source plus managed cloud |
Runtime intervention | Real-time guardrails powered by Luna-2 SLMs | Post-hoc analysis only |
Evaluation engine | Agent-focused metrics, millisecond Luna-2 scoring | Manual scripts or LLM-as-judge |
Compliance certifications | SOC 2 Type II with audit trails, ISO 27001 | SOC 2 Type 2, ISO 27001 |
Scale proof-points | 20M+ traces/day, 50K+ live agents | Large OSS community, 10k+ GitHub stars |
Notable customers/community | Fortune-500 deployments and regulated-industry pilots | Startups, research teams, and open-source contributors |
The sections ahead break down these differences so you can match the right platform to your specific requirements.

Core functionality
You can't fix what you can't see. Core functionality in an observability platform determines how quickly you identify agent failures, trace decision paths, and iterate safely. When your agents touch dozens of tools in a single conversation, rich visibility and automated debugging become non-negotiable.
Galileo
Traditional logs flatten complex agent workflows, leaving you guessing where things derailed. Galileo flips that script with a Graph Engine that visualizes every branch, tool call, and decision across frameworks like LangChain, CrewAI, and AutoGen, so you watch reasoning unfold rather than piecing it together afterward.
Conversations grow complex fast, the timeline and conversation views let you replay an entire session turn by turn, even for multimodal interactions.
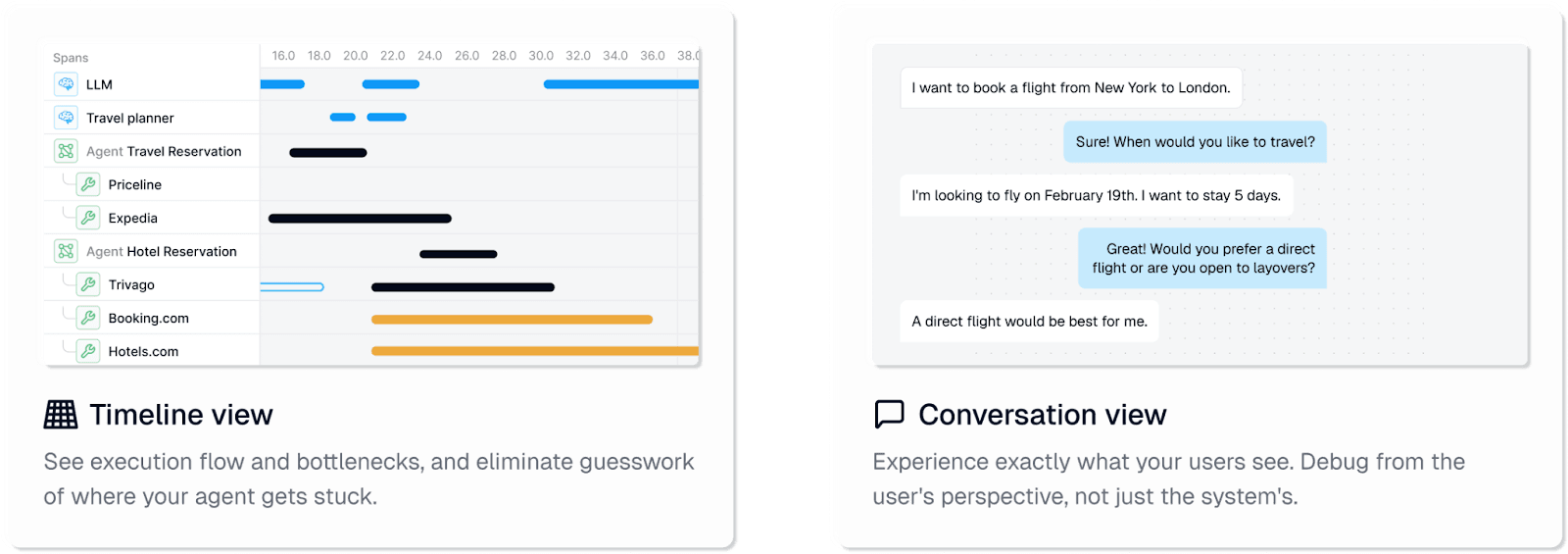
The Insights Engine continuously scans traces and surfaces coordination breakdowns, tool misuse, or off-task detours without manual query writing. Session-aware architecture means that a single click pivots from high-level metrics to root-cause details, shortening the mean-time-to-resolution.
Custom dashboards also capture your KPIs alongside agent-specific metrics, while the framework-agnostic SDK connects with one line of code. You spend time solving problems, not wiring plumbing.
Langfuse
Langfuse delivers extensive tracing built specifically for LLM applications, with every prompt, span, and response appearing in an interactive UI that provides chronological insight into model behavior.
Self-hosting through a Helm chart or managed SaaS keeps deployment flexible, while session logging records full conversations for post-mortem playback. However, self-hosting through open-source tools differs significantly from enterprise-grade on-premise deployments.
Regulated industries like financial services or healthcare often require documented deployment architectures, guaranteed SLAs, and vendor support that extends beyond community forums—observability capabilities that Galileo delivers out of the box.
Cost-aware debugging sets this platform apart—dashboards highlight token spend, latency, and error rates in real time. You can attach manual or automated evaluations to each run, then slice results by model version or prompt variant to see what actually improved performance.
Built-in runtime guardrails are minimal, and to block unsafe outputs, you need to leverage external libraries or custom code. This makes Langfuse a powerful passive observer, ideal for teams that want granular traces and are comfortable with handling real-time intervention themselves.
Technical capabilities
When your agent fleet grows from a handful of prototypes to thousands of concurrent conversations, raw model quality alone won't keep things afloat. You need fast, low-cost evaluation, granular metrics, and guardrails that trigger before a rogue tool call drains budget or leaks PII.
Galileo
Your biggest headache hits when trying to score every conversation turn without bankrupting your evaluation budget. Most teams attempt manual sampling or expensive GPT-4 judges, burning cash without comprehensive coverage.
Galileo sidesteps this trap entirely with Luna-2 small language models, delivering evals at roughly 3% of GPT-4's price while maintaining sub-200ms latency and the same level of accuracy, even when tracking 10–20 metrics per call.

Those models run on shared infrastructure, so you can layer hundreds of out-of-the-box or CLHF metrics without spinning up extra GPUs.
Real-time guardrails sit in the same pipeline, intercepting unsafe or wasteful actions before external APIs fire, no retrospective patches required. Purpose-built agent metrics are available automatically, including tool-selection quality, agent flow, action completion rate, and more.
You can still mix in LLM-judge or custom Python code for edge cases. Whether you run nightly offline regression tests or always-on production sampling, eval modes stay consistent, letting you gate releases inside CI/CD while monitoring 100% of live traffic.
Langfuse
How do you score quality when the platform provides no built-in evaluators? This challenge forces teams into manual test suites or expensive LLM-judge scripts where every additional metric incurs full inference costs of whatever model you choose.
While this design keeps the core lightweight and open source, latency stretches to match your chosen judge, making real-time enforcement impractical.
Langfuse excels at retrospective observability instead. Token usage, cost, and latency roll up into clear dashboards while trace viewers highlight the exact prompt and response behind each spike.
Prompt debugging tools help you replay sessions, tweak system messages, and push fixes quickly. The platform stops short of blocking dangerous output in flight, focusing on transparency after actions complete.
Community scripts can automate periodic evals, but you own scheduling, storage, and scaling. Teams comfortable paying per-judge inference and reacting post-incident get solid visibility without proprietary model lock-in.
Integration and scalability
Keeping a single proof-of-concept alive is easy. The real challenge begins when you scale to thousands of daily conversations across cloud regions, on-prem clusters, and multiple agent frameworks.
You need an observability layer that integrates seamlessly and expands effortlessly as volume, complexity, and compliance demands grow.
Galileo
Your agents can fail mysteriously when they span multiple tools and execution branches. Traditional log pipelines crumble under this complexity, leaving you blind to critical decision paths.
Galileo captures every interaction with 100% sampling, monitoring millions of agent turns without budget strain thanks to its in-house Luna-2 models.
Deployment flexibility means you're never locked into a single architecture. Run the platform as SaaS, in a private VPC, or fully on-prem across AWS, GCP, or Azure. Your sensitive data stays behind your firewalls while maintaining full functionality.
The framework-agnostic SDK instruments LangChain, CrewAI, or AutoGen with a single-line import.
OpenTelemetry compatibility ensures traces flow into existing monitoring stacks. CI/CD hooks gate releases on automated evals. Enterprise controls, audit trails, and policy versioning scale with traffic, eliminating bottlenecks.
You get rapid time-to-value at the prototype stage and no surprises when usage hits tens of millions of calls.
Langfuse
How do you maintain visibility when your team values open-source flexibility above managed services? Langfuse addresses this with lightweight SDKs for TypeScript, Python, and Java, plus a Helm chart that deploys self-hosted instances in minutes.
This transparency drives fast innovation cycles and a vibrant contributor community. Integrations with LangChain, LlamaIndex, and popular toolkits feel native. The session recorder preserves every span, prompt, and response for detailed debugging sessions.
You own the scaling story completely. As trace volume climbs, you provision databases, tune ClickHouse, and harden networking.
Capacity planning becomes your responsibility. Many startups find this trade-off acceptable; open code, granular cost visibility, and freedom to modify internals outweigh extra DevOps overhead.
Self-hosting also addresses data-residency concerns while providing encryption-at-rest and granular access controls.
Compliance and security
In production, a single policy misconfiguration can expose sensitive data or trigger costly regulatory fines. You must prove that every request is logged, every output is safe, and every engineer sees only what they should.
That expectation only intensifies under GDPR, HIPAA, or PCI-DSS. The next two sections examine how Galileo and Langfuse help you meet these obligations without throttling innovation.
Galileo
Auditors rarely care how clever your agents are; they want proof that controls never lapse. Ad-hoc logs create dangerous blind spots, especially when multiple agents chain tool calls together.
Galileo eliminates these gaps through SOC 2 Type II–certified architecture and optional fully on-prem deployment that keeps every byte inside your firewall.
Every decision, prompt, and model output gets stamped with a tamper-proof audit trail. This gives you line-item evidence during compliance reviews. Policy versioning tracks exactly which guardrail set stopped, or failed to stop, a risky action, transforming post-mortems from guesswork into deterministic science.
Enterprise RBAC, SSO, and network isolation prevent lateral movement between projects. Deterministic policy enforcement guarantees blocked behaviors stay blocked across environments.
An inline PII detector reviews responses in real time, automatically redacting or blocking sensitive content before it leaves the cluster.
Langfuse
Sometimes you need complete control behind your own firewall while still satisfying auditors. Langfuse embraces this requirement with a self-hosted, open-source core deployable via Helm or air-gapped when data residency laws demand it.
Security foundations include TLS in transit and AES-256 at rest, plus annual SOC 2 Type 2 and ISO 27001 audits that provide external validation. Regular penetration tests hunt for exploits before attackers find them.
Granular role-based permissions control access to traces, prompts, and raw user inputs. Custom retention policies, masking, and one-click deletion help you honor GDPR's right-to-be-forgotten without manual database surgery.
However, the platform lacks a native runtime policy engine, so blocking malicious outputs still requires your own code or upstream guardrails.
Usability and cost
Even the most feature-rich observability platform stalls if your team can't adopt it quickly or foot the bill long term. You need tooling that turns insight into value within days, not quarters, while keeping operating expenses predictable.
Evaluating usability and cost reveals two very different philosophies, one prioritizing automated acceleration, the other betting on open-source flexibility.
Galileo
You've probably spent weeks wiring custom metrics into home-grown dashboards only to watch developers ignore them. Most teams make the same mistake: building complex instrumentation that delivers insights nobody uses.
Continuous Learning via Human Feedback (CLHF) auto-generates the most relevant agent metrics the moment you connect your pipeline. Meaningful signals appear before the first sprint closes.
When deeper eval is required, Luna-2 small language models step in at roughly $0.02 per million tokens, about 97 percent cheaper than GPT-4-based judges. This makes 100% sampling financially viable for production monitoring.
Real-time guardrails halt hallucinations or PII leaks before downstream tools execute, preventing the costly incidents that drive hidden support and compliance spend. Because dashboards, root-cause analysis, and policy editing are fully self-service, you avoid the platform-team bottlenecks that inflate TCO in traditional APM roll-outs.
Langfuse
Langfuse repo is free to self-host, and the managed SaaS follows a pay-as-you-go model. You start tracing prompts with almost no upfront cash outlay. Open-source code means you can bend the UI or data model to niche requirements, a boon when internal standards trump vendor roadmaps.
This freedom shifts labor costs onto your backlog. Evals aren't auto-generated; you'll script each metric, maintain LLM judges, and tune thresholds manually. Infrastructure bills also arrive under your own AWS or GCP account if you choose self-hosting.
You'll need engineers on call for upgrades, backups, and security patches. Langfuse's built-in token and cost dashboards surface real-time spend, helping you rein in runaway inference budgets.
For a lean startup chasing rapid prototypes, that transparency and control can outweigh the hidden staffing expense, but at enterprise scale, the DIY tax grows quickly.
What customers say
Choosing between two observability platforms isn't about feature checklists; you want evidence from teams already running millions of calls in production. Unfiltered customer stories cut through marketing polish, revealing how tools behave under real load and tight deadlines.
The experiences below show where each platform shines and where you might still need to roll up your sleeves.
Galileo
You'll join over 100 enterprises already relying on Galileo daily, including high-profile adopters like HP, Reddit, and Comcast, who publicly credit the platform for keeping sprawling agent fleets stable at scale.
Galileo customers report significant results:
"The best thing about this platform is that it helps a lot in the evaluation metrics with precision and I can rely on it, also from the usage I can understand that it is exactly built for the specific needs of the organization and I can say that it's a complete platform for experimentation and can be used for observations as well"
"The platform is helping in deploying the worthy generative ai applications which we worked on efficiently and also most of the time i can say that its cost effective too, the evaluation part is also making us save significant costs with the help of monitoring etc"
"Galileo makes all the effort that is required in assessing and prototyping much easier. Non-snapshots of the model's performance and bias are incredibly useful since they allow for frequent checkups on the model and the application of generative AI in general."
"Its best data visualization capabilities and the ability to integrate and analyze diverse datasets on a single platform is very helpful. Also, Its UI with customizations is very simple."
Industry leader testimonials

"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products. Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow. With Luna, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and
accuracy. This is a game changer for the industry." - Alex Klug, Head of Product, Data Science & AI at HP
"What Galileo is doing with their Luna-2 small language models is amazing. This is a key step to having total, live in-production evaluations and guard-railing of your AI system." - Industry testimonial
"Galileo's Luna-2 SLMs and evaluation metrics help developers guardrail and understand their LLM-generated data. Combining the capabilities of Galileo and the Elasticsearch vector database empowers developers to build reliable, trustworthy AI systems and agents." - Philipp Krenn, Head of DevRel & Developer Advocacy, Elastic
Which platform fits your needs? Choosing the right option
Choosing between these platforms often comes down to a fundamental question: do you need protection or just visibility? Most teams discover this distinction only after their first production incident:
Galileo fits enterprises that cannot afford surprises in production. You get runtime intervention that blocks hallucinations before they reach users, plus rapid custom metrics powered by Luna-2 SLMs at a fraction of GPT-4 costs. The platform handles millions of traces daily without sampling, while SOC 2 readiness and on-prem deployment options satisfy regulated industries.
Langfuse appeals to teams wanting extensive tracing with minimal upfront cost. The open-source flexibility enables deep customization and self-hosting, with zero license fees and pay-as-you-go cloud pricing. You'll need bandwidth to code your own evaluations and maintain infrastructure, but this path excels for single-agent workloads and straightforward tracing needs.
Galileo’s approach works when your agents make decisions that could impact revenue, compliance, or user trust.
Evaluate your LLMs and agents with Galileo
Every week that you run production agents without visibility, you're rolling the dice. Hallucinations slip past QA, token costs spiral out of control, and compliance breaches surface only when customers complain.
You can secure your agents today. Here’s how Galileo's comprehensive observability platform provides a unified solution:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evals: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based eval approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you build reliable LLMs and AI agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.

Conor Bronsdon