
5 Best Hallucination Detection Tools for LLM Applications

Jackson Wells
Integrated Marketing

Hallucinations represent the most consequential barrier to enterprise LLM deployment. When your production models fabricate references, invent statistics, or confidently deliver incorrect information, the damage extends beyond technical failures—reputational costs can be severe, regulatory exposure accelerates, and customer trust evaporates.
As 92% of Fortune 500 companies deploy LLMs in production, AI hallucination detection tools have evolved from optional safeguards to mandatory infrastructure. This analysis provides VP-level technical leaders with a systematic evaluation of platforms enabling trustworthy, auditable, and compliant AI systems at scale.
TLDR
Hallucination detection is now mandatory infrastructure for enterprise LLM deployment, with 92% of Fortune 500 companies requiring systematic factuality verification to avoid costly incidents
Specialized platforms outperform general observability tools by measuring factual consistency through embedding similarity, Chain-of-Thought analysis, retrieval validation, and grounding metrics
Leading solutions vary by focus: Galileo provides turnkey detection with quantified metrics, Arthur Shield emphasizes security-first architectures, while Helicone and TruLens require custom implementation
Production deployment demands sub-200ms latency for real-time screening—platforms like Galileo's Luna-2 achieve this threshold without degrading user experience
ROI frames detection as risk mitigation infrastructure enabling AI productivity gains, with organizations achieving $3.70 return per $1 invested when treating hallucination detection as prerequisite rather than optional enhancement
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
What Is an AI Hallucination Detection Tool?

An AI hallucination detection tool is specialized software that measures factual consistency in large language model outputs by quantifying the alignment between generated content and verified source material to identify fabricated citations, invented statistics, and factually incorrect information.
When your LLM applications enter production, you face a detection gap that traditional monitoring tools cannot bridge. Standard observability platforms track latency spikes and error rates, but they cannot distinguish between a correctly formatted response and one containing fabricated citations or invented statistics.
Hallucination detection tools fill this gap by treating factual consistency as a measurable quality metric—quantifying the alignment between generated outputs and verified source material through specialized evaluation frameworks.
The strategic value lies not in catching every hallucination, but in creating audit trails that prove due diligence. When customers challenge AI-generated recommendations, when regulators question compliance with accuracy requirements, or when board members demand risk quantification, these platforms provide the documentation infrastructure that transforms subjective quality concerns into objective, measurable governance.
Organizations in the legal, healthcare, and financial services sectors now treat hallucination detection as a prerequisite infrastructure for production deployment—analogous to how security scanning became mandatory for code deployment despite adding overhead.
Galileo
How do you catch hallucinations in production without adding 500ms of latency that destroys user experience? Most detection tools force this tradeoff—comprehensive accuracy or real-time performance, never both.
In Galileo's performance benchmarking, Luna-2 runtime protection achieved sub-200 millisecond latency, enabling real-time content blocking without degrading responsiveness—critical for capacity planning when scaling from pilots to millions of daily interactions.
Luna-2 represents just one component of Galileo's integrated platform combining hallucination detection, automated failure analysis through the Signals, and end-to-end AI observability spanning the full lifecycle from experimentation through production monitoring. Evaluation methodologies include embedding-based similarity models, Chain-of-Thought prompting analysis, self-correction frameworks, and the proprietary G-Eval metric measuring context alignment and reasoning quality.
Transparent pricing differentiates from competitors: 5,000 free traces monthly for validation, with production deployments starting at $100/month and clear volume-based scaling enabling precise TCO calculation.
Key Features
Multi-method hallucination detection combining embedding similarity, Chain-of-Thought analysis, and G-Eval factuality scoring
20+ out-of-the-box LLM-based evaluation metrics including Correctness for open-domain hallucination detection, Context Adherence for closed-domain grounding verification, Completeness, Chunk Attribution, and Context Relevance—eliminating the need for custom metric engineering
Luna-2 runtime guardrails (validated at sub-200 millisecond response time in Galileo's testing) for production inference paths with automated content blocking
Signals automating root cause analysis for production failures without manual log review
End-to-end observability capturing inputs, outputs, and internal reasoning traces across complex agent workflows
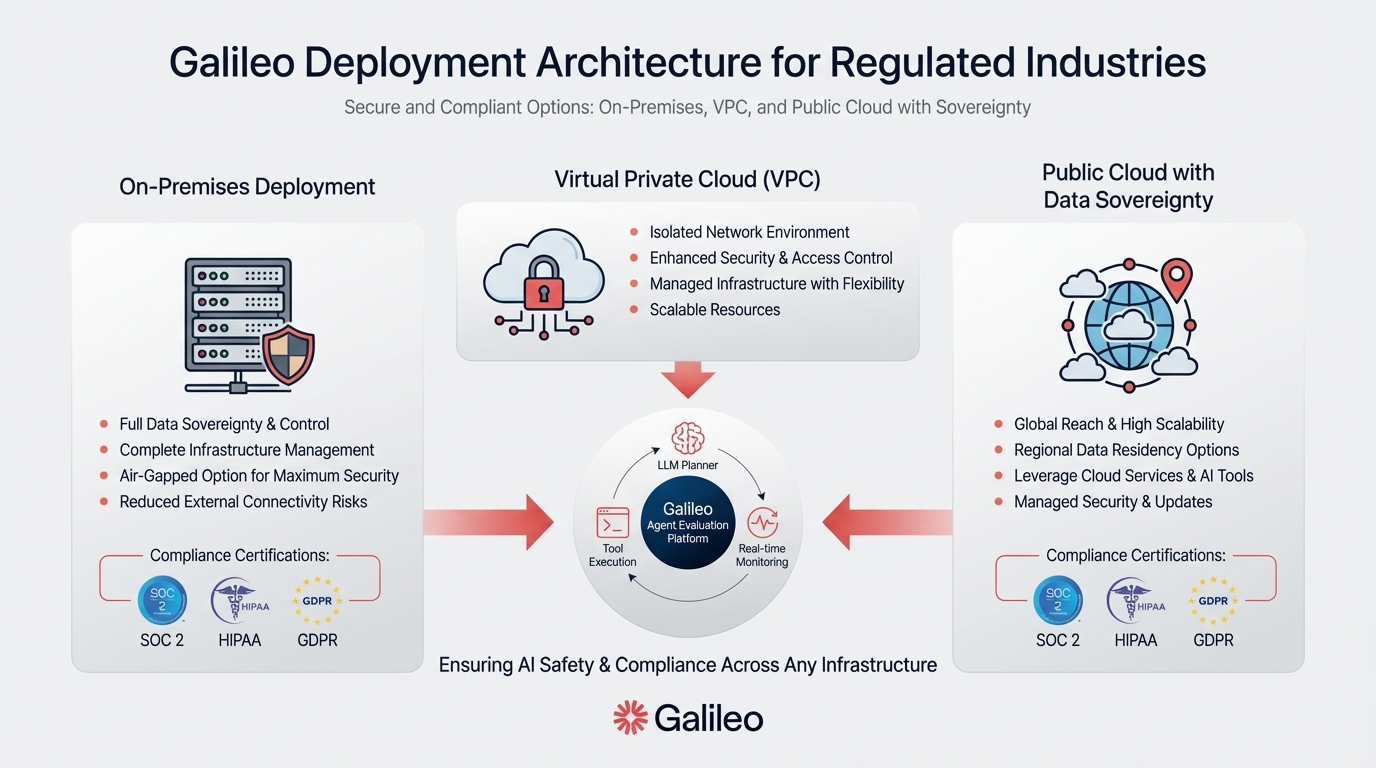
Flexible deployment options supporting cloud-hosted SaaS and on-premise installations for data sovereignty requirements
Provider-agnostic architecture integrating with OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and custom models
Strengths and Weaknesses
Strengths:
Quantified performance metrics (sub-200ms latency validated in testing) enabling precise capacity planning
Transparent pricing with free tier sufficient for meaningful POC validation
Documented customer outcomes (Magid achieved 100% visibility on AI inputs/outputs)
Multiple detection methodologies—embedding-based similarity, Chain-of-Thought prompting, self-correction mechanisms, and G-Eval metric—rather than single-approach dependency
Provider-agnostic architecture integrating seamlessly with OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and custom models
Automated root cause analysis through Insights Engine reducing manual debugging from 40 hours to under 5 hours weekly
End-to-end observability capturing inputs, outputs, and internal reasoning traces across complex agent workflows
Flexible deployment supporting both cloud-hosted SaaS and on-premise installations for data sovereignty
Fortune 100 enterprise deployments including JPMorgan Chase agent observability implementation
Weaknesses:
Advanced algorithmic details remain at blog-level depth rather than technical white papers
Enterprise compliance certifications not publicly documented beyond standard security practices
Use Cases
Financial services teams leverage audit trail capabilities for regulatory compliance across customer-facing LLM interactions. News organizations like Magid maintain editorial standards when AI assists content creation, achieving complete visibility into every model decision.
Product teams at high-growth enterprises use Insights Engine to identify hallucination patterns automatically—reducing manual review from 40 hours per week to under 5 hours by clustering failure patterns across 500K+ daily interactions. Fortune 100 banks deploy on-premise instances within air-gapped environments while maintaining the sub-200ms detection latency validated in Galileo's testing. Legal research platforms flag fabricated case citations before they reach attorneys.
Arthur Shield
Should hallucination detection live inside your application or in front of it? Arthur Shield implements the firewall model—middleware sitting between LLM applications and model endpoints, screening both prompts at the input stage and responses before they reach your end users.
This architectural choice enables hallucination detection as one component within a broader security suite addressing prompt injection, jailbreak attempts, data loss prevention, and toxic content filtering.
SOC 2 Type II certification demonstrates enterprise security compliance, yet the middleware architecture lacks published accuracy metrics. Deployment options span fully managed SaaS, customer cloud VPC, and self-hosted on-premise installations.
Key Features
Middleware firewall architecture intercepting all LLM traffic for security screening before user delivery
Dual validation checkpoints examining prompt safety and response filtering through rule-based detection methods
Model-agnostic support working across proprietary and open-source LLMs without vendor lock-in
Multi-deployment flexibility offering SaaS, managed cloud, and on-premise options
SOC 2 Type II compliance demonstrating security control effectiveness over time
Comprehensive security suite bundling rule-based output monitoring with toxicity filtering and prompt injection prevention
Strengths and Weaknesses
Strengths:
Multi-faceted hallucination detection employing diverse methodologies rather than single-point detection
Flexible deployment architectures supporting cloud, hybrid, and on-premises options
Model-agnostic integration patterns enabling multi-provider LLM strategies
Security certifications including SOC 2 Type II compliance
Weaknesses:
Rule-based detection methodology requires manual tuning for evolving hallucination patterns
No specific latency measurements, accuracy metrics, false positive rates, precision, recall, or F1 scores publicly disclosed
Pricing transparency limited—requires direct sales engagement for TCO calculation
No publicly available Arthur Shield-specific case studies or ROI data
Use Cases
Comprehensive LLM security infrastructure requires bundled protection—Arthur Shield's middleware addresses prompt injection, data leakage, and factuality through unified architecture. When you face strict data residency mandates, leverage on-premise deployment for air-gapped production environments.
Helicone
Helicone solves a different problem than the other tools here—and that clarity matters. Instead of turnkey hallucination detection, you get an open-source architecture providing foundational monitoring: request/response logging, latency tracking, cost attribution, and session trees visualizing multi-step workflows.
Hallucination detection requires custom implementation through anomaly detection, user feedback collection, and LLM-as-a-Judge evaluation.
Integration simplicity represents the core value proposition. If you use OpenAI SDK, change your base URL to https://oai.helicone.ai/v1 for immediate observability across 100+ LLM providers.
Key Features
AI Gateway integration providing unified access to 100+ models via single endpoint with support for OpenAI, Anthropic, Google Vertex/Gemini, AWS Bedrock, and Azure OpenAI
OpenAI-compatible SDK requiring minimal code changes
Zero markup pricing with transparent pass-through of provider costs
Session tree visualization showing complex multi-step agent workflows for debugging and monitoring
Open-source foundation with Apache 2.0 licensed core enabling self-hosting and customization
Cost attribution tracking linking token usage and latency to specific AI systems, users, and features for AI FinOps governance
Strengths and Weaknesses
Strengths:
Rapid multi-provider gateway integration requiring only base URL modification for OpenAI users
True multi-provider observability reducing vendor lock-in risk through 100+ LLM model support
Open-source licensing providing code transparency and customization options (Apache 2.0)
Generous free tier (unlimited requests with 1-month data retention) for POC validation
Weaknesses:
No turnkey hallucination detection—requires custom engineering implementation
Anomaly detection implementation lacks sufficient technical depth and customization documentation
Limited documentation on automated evaluation capabilities with details beyond blog-level mentions
Absence of published customer case studies demonstrating cost optimization outcomes
Use Cases
Managing multiple LLM providers demands unified observability. Helicone's gateway approach delivers this with minimal integration effort.
The platform's hallucination detection relies on methodology-based approaches requiring custom implementation by engineering teams—not turnkey AI-powered detection. Open-source tooling provides code transparency and self-hosting options, avoiding proprietary lock-in.
Giskard AI
Red-teaming LLMs manually consumes weeks. Giskard automates this through an Apache 2.0 licensed testing framework detecting hallucinations, contradictions, prompt injections, and data disclosures. Enterprise deployment options span cloud-hosted SaaS and on-premises installations, with compliance certifications including GDPR, SOC 2 Type II, and HIPAA for regulated industries.
The open-source foundation enables VP-level technical evaluation without vendor commitment, though production-grade hallucination detection capabilities should be validated through proof-of-concept testing as hallucination detection integrates as one component within a broader vulnerability testing approach.
Key Features
Open-source testing framework with Apache 2.0 license eliminating vendor lock-in
Automated red-teaming continuously detecting multiple vulnerability types including hallucinations, contradictions, prompt injections, data disclosures, and inappropriate content
Enterprise compliance certifications including GDPR, SOC 2 Type II, and end-to-end encryption
Multi-provider testing support through LiteLLM integration layer supporting OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and open-source models
CI/CD native integration enabling shift-left testing practices with GitHub Actions, GitLab CI, and Jenkins
Flexible deployment options supporting cloud and on-premises infrastructure for data sovereignty requirements
Strengths and Weaknesses
Strengths:
Open-source foundation enabling risk-free evaluation and community-driven development
Security and compliance certifications (SOC 2, HIPAA, GDPR) addressing regulated industry requirements
Comprehensive testing capabilities across multiple vulnerability types including hallucinations, prompt injections, and data disclosures
Flexible deployment options supporting cloud, hybrid, and on-premises installations for data residency requirements
Weaknesses:
Performance benchmarks at enterprise scale (millions of traces/month) lack public documentation
Limited security certification documentation—SOC 2, ISO 27001, and HIPAA compliance status not publicly confirmed
Hallucination detection positioned as one component of a broader vulnerability testing platform rather than a specialized deep capability
Absence of published customer case studies with detailed outcome metrics and ROI validation
Use Cases
Regulated industries deploying LLM agents benefit from Giskard's compliance certifications and on-premise flexibility for strict data governance. The open-source strategy enables technical leaders to evaluate capabilities thoroughly before enterprise commitment.
When your primary requirements focus on advanced, specialized hallucination detection, conduct detailed technical evaluations and consider whether supplementary tools in combination with Giskard's broader security testing framework serve your needs.
TruLens by TruEra
How do you know your RAG system's retrieval actually supports its generated answers? TruLens tackles this specific problem through the "RAG Triad" methodology—open-source evaluation measuring three core dimensions: groundedness (whether outputs align with retrieved context), question-answer relevance (response accuracy), and context relevance (retrieval quality).
This RAG-specific focus differentiates from general-purpose observability platforms, with programmable "feedback functions" enabling custom evaluation logic beyond black-box monitoring.
Key Features
RAG Triad methodology with groundedness, QA relevance, and context relevance metrics for retrieval-augmented generation
Programmable feedback functions enabling domain-specific evaluation logic customization
Lifecycle coverage spanning experimentation, testing, and production monitoring
Open-source foundation providing code transparency and community development
Multi-app comparison dashboards for evaluating competing implementations
Kappa architecture for streaming ingestion (vendor-claimed support for high-event-volume scenarios, requiring validation through proof-of-concept testing)
Strengths and Weaknesses
Strengths:
RAG-specific evaluation metrics purpose-built for retrieval-augmented generation workflows rather than generic quality scoring
Programmable feedback functions enabling custom evaluation logic tailored to domain-specific requirements and business rules
Comprehensive lifecycle coverage from experimentation through production monitoring without requiring multiple tool integrations
Open-source foundation providing code transparency and community development under Apache 2.0 licensing
Weaknesses:
Pricing opacity compared to tier-1 vendors: Like many emerging hallucination detection tools (Arthur Shield, TruLens), pricing is not publicly transparent, requiring direct sales engagement for TCO analysis
Limited technical depth on detection methodologies: Integration documentation focuses on practical deployment rather than algorithmic approaches used for hallucination detection
No third-party validation through case studies: A consistent market gap identified in the research—no authoritative sources from Gartner, Forrester, or McKinsey provide specific adoption percentages or validated ROI metrics for hallucination detection tools, indicating this emerging category lacks standardized measurement frameworks
Absence of independent benchmark validation: Unlike specialized approaches, this platform has not published performance metrics against academic hallucination benchmarks
Use Cases
Retrieval-augmented generation systems require specialized evaluation. TruLens' RAG Triad approach measures groundedness, question-answer relevance, and context relevance. VP-level decision makers should conduct proof-of-concept testing to validate performance claims, request detailed pricing and licensing terms, verify specific integrations with LLM providers and infrastructure components, and obtain customer references before procurement commitment.
The Road to Trustworthy Enterprise AI with Galileo
Hallucination detection has evolved from experimental safeguard to production infrastructure requirement. For VP-level technical leaders, reliability and governance now differentiate successful AI initiatives from abandoned projects. Galileo leads the market with turnkey detection combining sub-200ms Luna-2 runtime protection, multi-method evaluation (embedding similarity, Chain-of-Thought analysis, G-Eval metrics), transparent pricing starting at $100/month, and automated root cause analysis through the Signals.
Documented enterprise deployments—Magid's 100% AI visibility and JPMorgan Chase agent observability—validate Galileo as the purpose-built solution for factual consistency at scale. AI leaders should embed hallucination detection into their AI quality assurance infrastructure, treating quality management as prerequisite for value capture.
Here’s why Galileo stands out for enterprise hallucination detection.
Quantified performance validated in testing: sub-200ms Luna-2 runtime protection enabling precise capacity planning at scale
Transparent pricing architecture with Free Tier offering 5,000 traces/month and Pro Tier starting at $100/month for 50,000 traces with advanced analytics and real-time guardrails
Multi-method detection approach combining embedding similarity, Chain-of-Thought analysis, self-correction mechanisms, and G-Eval metrics vs. single-technique dependency
Automated root cause analysis through Galileo Signals providing production debugging support
Documented customer outcomes including Magid's 100% AI visibility achievement and JPMorgan Chase agent observability deployment
Provider-agnostic integration supporting OpenAI, Anthropic, Azure OpenAI, AWS Bedrock, and custom models with flexible cloud or on-premise deployment
Ready to eliminate hallucinations before they reach production? Explore Galileo's evaluation platform and start your free trial today—the free tier includes 5,000 traces per month to validate detection accuracy against your specific use cases.
FAQs
What differentiates hallucination detection tools from general LLM observability platforms?
Hallucination detection tools employ specialized methodologies—factuality scoring, retrieval validation, groundedness measurement—specifically designed to identify fabricated outputs. Galileo uniquely integrates both capabilities with sub-200ms detection latency validated in testing, while combining multiple detection methodologies (embedding similarity, Chain-of-Thought analysis, G-Eval metrics) rather than relying on single approaches. VP-level buyers should prioritize solutions like Galileo offering turnkey hallucination detection with quantified performance metrics over tools requiring custom implementation.
How should technical leaders evaluate ROI for hallucination detection investments?
Frame detection tools as risk mitigation infrastructure enabling AI productivity gains. Galileo's transparent pricing (starting at $100/month with 5,000 free traces for validation) enables precise TCO calculation, while platforms requiring sales engagement introduce evaluation friction. Organizations treating hallucination detection as prerequisite infrastructure rather than optional enhancement achieve measurable returns when factual consistency becomes foundational to deployment strategy.
Which deployment architecture best serves regulated industries with strict compliance requirements?
Galileo offers flexible deployment options supporting both cloud-hosted SaaS and on-premise installations, enabling Fortune 100 banks to deploy air-gapped instances while maintaining sub-200ms detection latency. Comprehensive audit trails and quantifiable grounding metrics prove essential for regulatory reporting—capabilities Galileo delivers through its Signals and end-to-end observability. Prioritize platforms with documented enterprise deployments in regulated sectors.
What technical approaches prove most effective for production hallucination detection?
Production systems require hybrid strategies combining multiple methodologies. Galileo's multi-method approach—combining embedding similarity, Chain-of-Thought analysis, self-correction mechanisms, and G-Eval metrics—outperforms single-technique dependencies while maintaining sub-200ms latency through Luna-2 runtime protection. Evaluate platforms supporting threshold-based quality control rather than binary validation approaches, with preference for solutions offering quantified performance metrics enabling precise capacity planning.
How does Galileo's approach differ from specialized security platforms like Lakera Guard?
Galileo specializes in hallucination detection and AI observability with multi-method detection, automated failure analysis through the Insights Engine, and sub-200ms runtime protection focused specifically on factual consistency. This specialized depth enables sophisticated hallucination management with quantified grounding metrics, transparent pricing starting at $100/month, and documented customer outcomes. For most enterprise LLM deployments where factual consistency represents the core risk, Galileo's purpose-built architecture provides superior value.
Jackson Wells