
Galileo vs. Athina AI: Comparison Across Key Platform Features

Jackson Wells
Integrated Marketing

Your agent-powered applications create value with every tick of the clock—but they also spawn hidden failure modes—tool-call loops, prompt-injection exploits, and hallucinated facts that slip past reviews.
Standard APM dashboards can't spot these issues because they weren't designed to trace reasoning steps or decision trees. Without specialized observability, you only discover problems after users complain.
Modern observability platforms aim to solve this visibility gap. Athina AI offers a spreadsheet-style IDE and after-the-fact monitoring with charts and queries to dissect problems.
However, suppose you're responsible for keeping systems running, meeting regulations, and managing costs. In that case, Galileo's combination of live tracking, automated safeguards, flexible deployment, and enterprise security makes it the stronger choice for complex agent systems.
We recently explored this topic on our Chain of Thought podcast, where industry experts shared practical insights and real-world implementation strategies:
Galileo vs Athina AI at a glance
Your agents process thousands of decisions hourly, and traditional monitoring creates dangerous blind spots. Athina AI approaches the problem by focusing on a spreadsheet-like interface that lets both technical and non-technical teams prototype, evaluate, and iterate on AI features together.
Galileo tackles the problems head-on as an agent observability platform that actively protects live traffic through Luna-2 small language models delivering sub-200ms guardrails—at up to 97% lower cost than GPT-based checks.
The fundamental divide lies in when protection happens:
Capability | Galileo | Athina AI |
Core focus | Agent observability + runtime protection | Collaborative development & evaluation |
Evaluation engine | Luna-2 SLMs, sub-200ms, 97% cheaper than GPT-4 | 50+ preset evals via LLM-as-judge |
Runtime intervention | Inline blocking with Agent Protect API | Post-hoc analysis, no real-time blocking |
Synthetic data generation | Behavior profiles (injection, toxic, off-topic) | Requires production logs |
Metric reusability | Metric Store with CLHF versioning | Custom evals per project |
Interface design | Production observability dashboards | Spreadsheet-like IDE for collaboration |
Agent-specific metrics | 8 purpose-built (tool selection, flow, efficiency) | General evaluation metrics |
Session-level analysis | Multi-turn conversation tracking | Trace-level monitoring |
Scale proven | Millions of traces daily, Fortune 50 deployments | Growing startup and mid-market adoption |
Deployment options | SaaS, hybrid, on-prem; SOC 2, ISO 27001 | SaaS, self-hosted VPC; SOC 2 Type 2 |
Framework support | Framework-agnostic (CrewAI, LangGraph, custom) | Framework-agnostic with SDK integrations |
Galileo delivers production-grade reliability with real-time protection. Athina AI provides collaborative workflows that democratize AI development across teams.

Core functionality
Your agents can fail mid-conversation, their issues buried among thousands of logs with no clear explanation why tool selection broke or which prompt triggered the failure. Here’s how the two platforms tackle debugging.
Galileo
Have you ever spent hours piecing together failure scenarios from scattered logs, trying to figure out why an agent chose the wrong tool three turns into a conversation? Most teams resort to adding log statements everywhere until the problem reveals itself—or doesn't.
Galileo replaces this hunt with Graph Engine visualization showing every decision branch, tool call, and context handoff on an interactive map. You can hover over any node to see inputs, outputs, latency, and cost instantly. Bottlenecks become obvious without grep commands.
The Insights Engine runs continuously, automatically detecting flow breaks, hallucinations, and prompt injection attempts as they happen. Everything you need—observability, evaluation, and guardrails—exists in one interface.
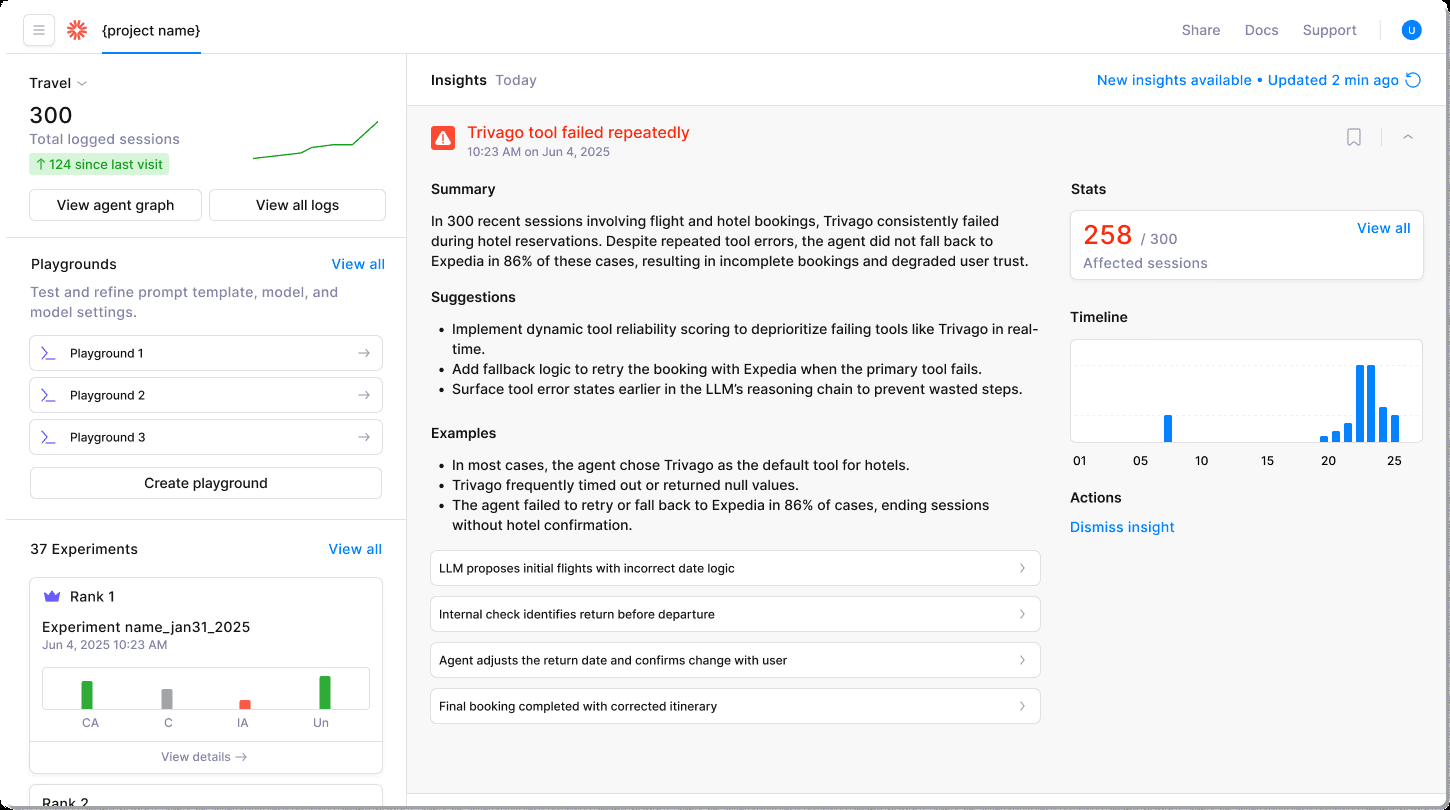
You can block unsafe responses with Agent Protect and rerun failed paths without switching tools. Teams report cutting debugging time from hours to minutes—a speed impossible with manual log analysis.

Athina AI
Rapidly iterating across prompts, models, and retrievers while switching between tools wastes valuable time. Athina AI addresses this challenge with a spreadsheet-like IDE where dynamic columns let you run LLM prompts, execute code, make API calls, and retrieve data in one place.
Your non-technical team members—product managers, QA teams, data scientists—can prototype pipelines alongside engineers in the same workspace. With just a few clicks, you can change a prompt parameter, swap models, or adjust retrieval logic, then run 50+ preset evaluations to measure impact.
The platform shines during experimentation phases: compare datasets side-by-side, run evaluations on multiple configurations at once, and share results via Slack. Human annotation workflows enable your domain experts to label edge cases that automated tests miss, feeding directly into feedback loops.
What you won't find are built-in guards that prevent bad outputs before they reach production. Athina AI helps you discover and fix issues during development—Galileo stops them at serve time.
Technical capabilities
Your evaluation system becomes the bottleneck when LLM-as-judge costs multiply with every metric and latency stretches into seconds. Production systems can't wait for feedback that takes minutes when agents make thousands of decisions per hour.
Galileo
When running production agents, you need millisecond evaluation cycles, not multi-second delays from GPT-4 judges. Galileo's Luna-2 SLMs return scores in under 200ms even checking 100% of traffic—fast enough to block problematic outputs before users see them.

At just 3B–8B parameters, these purpose-built low-cost evaluator models cut your costs by up to 97% compared to GPT-4, allowing you to run 10–20 concurrent metrics without budget strain. Through Continuous Learning via Human Feedback (CLHF), you can turn just 2-5 labeled examples into custom metrics fine-tuned for your domain.
Athina AI
How do you evaluate complex AI pipelines when your team includes people who understand the domain but not Python? This is where Athina AI bridges the gap with over 50 preset evaluators from providers including OpenAI, Ragas, and Guardrails—all accessible without coding.
The platform offers three ways to create custom evaluations: LLM-as-judge prompts, Python functions, or external API calls. This flexibility allows your team to choose evaluation approaches that match their technical abilities and speed requirements.
With Athina AI, you can run evaluations across multiple prompt variations simultaneously, compare outputs side-by-side, and iterate based on metrics.
The tradeoff comes at scale—evaluation costs increase with LLM pricing since there's no cost-optimized layer like low-cost small language models. At high volumes, your token fees add up quickly.
The platform also lacks session-level insights that track how agent behavior changes across multi-turn conversations—each trace evaluates independently.
Integration and scalability
AI stacks rarely stay fixed. You might prototype with one framework, switch to a custom orchestrator, then deploy behind compliance-mandated firewalls. Your observability layer must adapt without forcing architecture changes.
Galileo
When your codebase mixes CrewAI agents, LangGraph workflows, and custom orchestration logic, framework-agnostic SDKs handle this complexity naturally. Galileo works with any agent framework via open standards like OpenTelemetry.
This neutrality becomes crucial at scale. Galileo processes millions of traces daily across enterprise deployments supporting thousands of live agents without slowdowns. Your deployment strategy remains flexible—start with SaaS, move to private cloud, or run fully on-premises without changing instrumentation code.
Behind the scenes, enterprise-grade infrastructure supports these capabilities: low-latency storage, automatic failover, and turnkey auto-instrumentation delivering horizontal scale without framework dependencies.
When your orchestration layer evolves, your observability investment comes along.
Athina AI
Looking for a quick setup with minimal code changes? Athina AI's SDK integrations work with major frameworks and model providers—OpenAI, Anthropic, Cohere, Azure OpenAI, AWS Bedrock, Vertex AI, and custom models.
The platform uses standard callbacks that forward data without invasive code changes.
Getting started takes just minutes: add an API key, insert instrumentation in your application, and trace flow to dashboards. The spreadsheet interface handles datasets with millions of rows, letting you analyze production logs or test data with SQL queries.
For regulated environments, Athina AI offers VPC deployment options where data stays within your infrastructure. Fine-grained permissions control which users access specific features and datasets, meeting your security requirements.
The platform handles growing workloads well but lacks proven scale metrics of processing 20+ million daily traces. If your team works with high volumes, you might hit performance limits during complex evaluations across massive datasets.
Compliance and security
AI compliance isn't optional—regulators expect complete audit trails and immediate risk control. When an agent leaks PII or generates harmful content, you bear the liability regardless of model provider disclaimers.
Galileo
Unlike platforms that let you investigate incidents after they happen, Galileo prevents them mid-flight. SOC 2 Type II and ISO 27001 certifications come standard, with data-residency controls keeping records in specified regions.
Every agent decision gets logged, hashed, and timestamped—creating audit trails you can hand directly to regulators.
The system's real-time guardrails block policy violations in under 200ms at 97% lower cost than GPT-based judges, making 100% production sampling financially viable. When sensitive information appears in prompts, automatic PII detection and redaction clean it before storage.
For your most sensitive use cases, healthcare and finance teams can run regulated AI without constant auditor oversight. On-premises deployment options support air-gapped environments where data never leaves internal systems.
Athina AI
Security-conscious teams will appreciate that Athina AI provides SOC 2 Type 2 compliance as baseline security, ensuring your data meets industry protection standards. The platform supports deployment entirely within your VPC for complete data privacy in sensitive workloads.
Through fine-grained access controls, you can specify exactly which users can access different features, datasets, and evaluation results. This becomes essential when separating development, QA, and production environments across teams with different access levels.
Comprehensive audit trails capture experimentation history, prompt versions, and evaluation runs—useful for showing due diligence during compliance reviews. However, the platform focuses on development-time safeguards rather than runtime intervention.
For real-time blocking of policy violations, you'll need external tools. When harmful content reaches production, Athina AI provides thorough forensics showing exactly what happened—but lacks a prevention layer to stop outputs before users see them.
Usability and cost
You need more than powerful features—you need a platform teams actually use without drowning in complexity or watching costs explode as traffic grows. Usability and economics often determine whether deployment succeeds or stalls.
Galileo
Many teams hit roadblocks when turning evaluation ideas into working metrics because every change requires code and consumes LLM tokens. Galileo eliminates this friction with custom metric creation, requiring just plain language descriptions—no Python needed.
Once running, the Insights Engine continuously monitors your traces, identifies root causes of problems, and suggests specific fixes. You rarely need raw logs because automated clustering handles pattern recognition.
Your costs stay predictable through Luna-2 evaluation, delivering sub-200ms response times while reducing compute costs by up to 97% compared to GPT-4 judges. At 20 million daily traces, that's $6K monthly versus $200K—making 100% production sampling affordable where competitors force sampling to control budgets.
With usage-based pricing and a generous free tier, you pay only for what you monitor. This means lower ownership costs, faster onboarding, and fewer 2 AM calls about unexpected bills.
Athina AI
How quickly can your non-technical team members contribute to AI development? Athina AI answers this challenge with its spreadsheet-like interface, where product managers can prototype pipelines, run evaluations, and refine prompts without engineering bottlenecks.
The collaborative canvas lets anyone experiment with prompt variations, compare model outputs, and analyze results—spreading AI development beyond the data science team. Teams report 10x faster iteration because domain experts can optimize directly, rather than explaining requirements to engineers.
Budget-conscious teams will appreciate pricing that begins with a free tier appropriate for small teams and early projects. However, be aware that evaluation costs increase with LLM provider pricing—there's no cost-optimized layer for high-volume production monitoring.
At enterprise scale, running a comprehensive evaluation across millions of traces using GPT-4 judges quickly multiplies token fees. The trade-off becomes an excellent developer experience during prototyping versus growing costs during scale-up.
What customers say
Production agent failures cost real money, and teams running millions of traces have hard data showing which platforms actually prevent costly incidents versus just documenting them after they happen.
Galileo
You'll join over 100 enterprises already relying on Galileo daily, including high-profile adopters like HP, Reddit, and Comcast, who publicly credit the platform for keeping sprawling agent fleets stable at scale.
Galileo customers report significant results:
"The best thing about this platform is that it helps a lot in the evaluation metrics with precision and I can rely on it, also from the usage I can understand that it is exactly built for the specific needs of the organization and I can say that it's a complete platform for experimentation and can be used for observations as well"
"The platform is helping in deploying the worthy generative ai applications which we worked on efficiently and also most of the time i can say that its cost effective too, the evaluation part is also making us save significant costs with the help of monitoring etc"
"Galileo makes all the effort that is required in assessing and prototyping much easier. Non-snapshots of the model's performance and bias are incredibly useful since they allow for frequent checkups on the model and the application of generative AI in general."
"Its best data visualization capabilities and the ability to integrate and analyze diverse datasets on a single platform is very helpful. Also, Its UI with customizations is very simple."
Industry leader testimonials

"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products. Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow. With Luna, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and accuracy. This is a game changer for the industry." - Alex Klug, Head of Product, Data Science & AI at HP
"What Galileo is doing with their Luna-2 small language models is amazing. This is a key step to having total, live in-production evaluations and guard-railing of your AI system." - Industry testimonial
"Galileo's Luna-2 SLMs and evaluation metrics help developers guardrail and understand their LLM-generated data. Combining the capabilities of Galileo and the Elasticsearch vector database empowers developers to build reliable, trustworthy AI systems and agents." - Philipp Krenn, Head of DevRel & Developer Advocacy, Elastic
Which platform fits your needs?
Your decision depends on where failures hurt most. If runtime protection matters—blocking hallucinations, PII leaks, or policy violations before users see them—Galileo's sub-200ms guardrails and 97% cost reduction make it the production choice.
Choose Galileo when you need:
Real-time protection for regulated workloads (financial services, healthcare, PII-sensitive domains)
Cost-efficient evaluation at massive scale (millions of daily traces)
Metric reusability across teams and projects via CLHF
Agent-specific observability with session-level conversation tracking
On-premises or hybrid deployment for data residency requirements
Sub-200ms runtime guardrails that block failures inline
Framework-agnostic observability that survives orchestration changes
When collaborative development speed matters more, Athina AI's spreadsheet-like interface and 50+ preset evaluators create the most accessible environment for cross-functional teams to iterate rapidly.
Choose Athina AI when you need:
Collaborative development workflows accessible to non-technical users
Spreadsheet-like interface for rapid prompt and model experimentation
Development-phase observability and evaluation tooling
Familiar UI paradigm that reduces learning curves
Observability isn't optional. Without reliable metrics and proactive safeguards, even the best model can lose user trust overnight. Start evaluating, but when you need production-grade protection for thousands of live agent sessions, look at Galileo's runtime capabilities first.
Evaluate your LLMs and agents with Galileo
Moving from reactive debugging to proactive quality assurance requires the right platform—one purpose-built for the complexity of modern multi-agent systems.
Here’s how Galileo's comprehensive observability platform provides a unified solution:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you build reliable LLMs and AI agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.
Jackson Wells