Galileo vs Patronus AI: A Comprehensive AI Eval Platform That Delivers Real-Time Protection

Jackson Wells
Integrated Marketing

When you let AI agents make decisions affecting customer trust, revenue, or compliance without proper guardrails, it's like driving blindfolded. Most teams discover this harsh reality after their first disaster, when they're left wondering why nobody stopped the problem before it reached users.
Galileo and Patronus AI both tackle AI reliability challenges, but with fundamentally different approaches. Galileo gives you complete visibility with the power to stop harmful outputs before they happen. Patronus focuses on after-the-fact analysis to detect issues once they've already occurred.
Let's dig into how these philosophical differences play out in real-world deployments and what that means for your mission-critical AI and agentic systems.
Check out our Agent Leaderboard and pick the best LLM for your use case

Galileo vs Patronus AI at a glance
Production agent systems demand more than evaluation metrics. You need automated failure detection, session-level intelligence, and the ability to block unsafe actions in real time. Between these two platforms, the architectural differences become apparent from day one of deployment:
Capability | Galileo | Patronus AI |
Platform approach | End-to-end AI observability and eval platform with runtime protection in unified architecture | Evaluation-first platform with monitoring dashboards focused on scoring and benchmarking workflows |
Runtime intervention | Real-time guardrails powered by Luna-2 SLMs that block unsafe outputs before user exposure | API-based evaluators for post-hoc detection with no native blocking capabilities |
Agent observability | Agent Graph visualization, multi-turn session tracking, and automated Insights Engine for failure pattern detection | Percival agent monitoring with trace analysis and natural language summaries for debugging |
Evaluation architecture | Luna-2 small language models delivering sub-200ms latency at 97% lower cost than GPT-4 with continuous learning via human feedback | Glider 3.8B parameter model and Lynx hallucination detector with LLM-as-judge framework requiring external model costs |
Session intelligence | Complete user journey tracking across multi-step agent workflows with consolidated session metrics | Trace-level monitoring without native session analytics or multi-turn conversation roll-ups |
Deployment options | SaaS, private VPC, or fully on-premises with SOC 2 compliance and enterprise security controls | Cloud-hosted SaaS with AWS Marketplace availability and hybrid deployment options |
Cost structure | Fixed platform pricing with no per-evaluation charges using proprietary Luna-2 models | Pay-as-you-go API pricing at $10-20 per 1,000 calls plus external LLM judge costs |
These core architectural choices boil down to a simple question: are you building for reactive debugging or proactive prevention? Your answer shapes everything from how quickly you can respond to incidents to how much you'll spend at scale.
Core functionality, evaluation and experimentation
Evaluation frameworks show their true colors only under production load. When your agents handle thousands of conversations at once, you need metrics that scale without slowing down or missing critical failures before they reach users.
Galileo
Traditional evaluation methods create dangerous blind spots in your visibility. Single-point scoring misses context across multiple turns, while using GPT-4 as a judge becomes financially impossible at scale.
With its Luna-2 evaluation engine, Galileo eliminates these constraints. These small language models work in milliseconds at about 3% of GPT-4's cost, enabling you to evaluate every single interaction without budget concerns.

The multi-headed design runs hundreds of metrics simultaneously, so you can check for correctness, safety, and compliance without performance penalties.
Creating custom metrics requires nothing more than writing a description in plain English. No coding needed. The platform transforms your words into working metrics and saves them for everyone to use, saving weeks of development time.
When issues arise, token-level error pinpointing shows you exactly which phrase caused a hallucination or policy violation. This precision transforms debugging from guesswork into targeted fixes that address root causes.
As you accept or reject outputs, the system learns from your decisions, automatically adjusting scoring thresholds to match your priorities. This keeps your metrics aligned with your evolving use cases.
Patronus AI
At the heart of Patronus AI's approach is the Glider judge model and specialized tools like Lynx for hallucination detection. The 3.8 billion parameter Glider model provides reasoning chains that explain which factors influenced each judgment.
This transparency helps you understand why scores changed rather than treating them as mysterious black boxes. Glider supports flexible scoring scales from simple pass/fail to detailed rating systems that adapt to your specific needs.
You can access evaluation through their API, connecting to your existing workflows via Python SDK. The platform offers pre-built evaluators for common issues like toxicity and PII leakage or lets you configure custom LLM judges for specialized requirements.
For document-heavy RAG systems, the Lynx evaluator catches hallucinations by checking whether generated content matches retrieved context. It outperforms GPT-4o on specific retrieval benchmarks, providing specialized accuracy for document-based applications.
The fundamental approach remains primarily reactive - evaluating outputs after generation provides insights for improvement, but can't prevent bad outputs from reaching your users in real time.
Deep observability for production systems
Visibility needs explode when agents coordinate dozens of tool calls across complex workflows. Traditional logging breaks down completely, leaving teams unable to trace decision paths or understand why things went wrong.
Galileo
In complex systems, failures rarely appear in obvious ways. A small error early in the chain can create cascading problems that manifest much later, renderingcreates cascading problems that manifest much later, making traditional logs nearly useless for identifying root causes.
The Graph Engine solves this challenge with framework-agnostic visualization that maps every decision, tool call, and branch in real time. You can instantly see how reasoning progressed, where execution derailed, and which tool failures triggered downstream problems.
Switching between timeline and conversation views gives you multiple perspectives on the same data. You can toggle between high-level overviews and detailed step-by-step analysis with a single click, maintaining context while examining specific failure points.
The platform captures how errors spread across conversation turns through multi-turn session metrics. While point-in-time metrics miss these patterns entirely, session-aware analytics reveal when context degradation leads to quality issues or when earlier mistakes compound into critical failures.
Behind the scenes, the Insights Engine continuously works to group similar failures and surface patterns automatically. Hallucinations, incorrect citations, and coordination problems get flagged with actionable recommendations, eliminating hours of manual investigation.
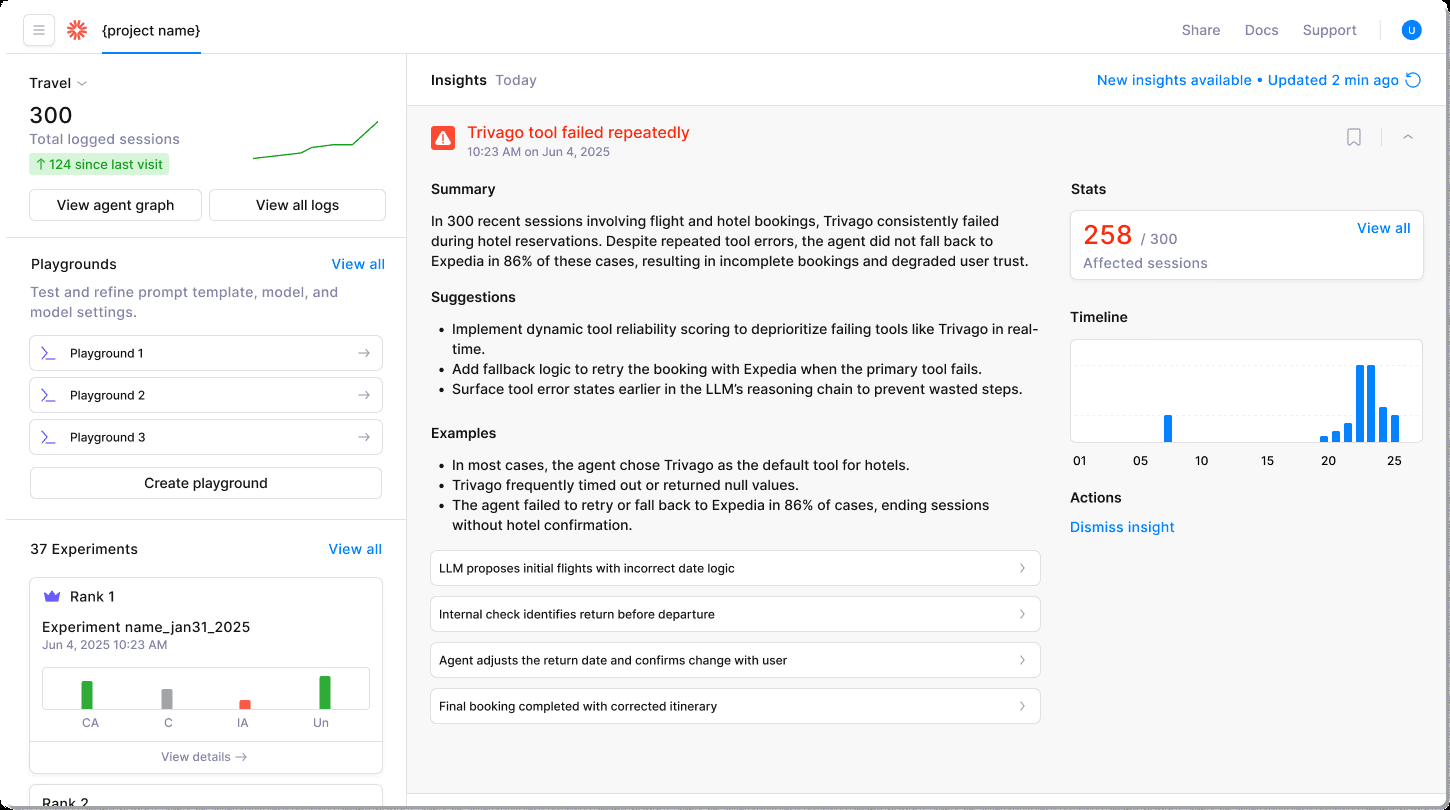
For content retrieval systems, chunk-level explanations pinpoint exactly which retrieved documents influenced generation and whether citations actually match source content. This transforms retrieval quality diagnosis from guesswork into a straightforward process.
Patronus AI
The observability foundation of Patronus AI centers on Percival, their agent monitoring platform. This system automatically analyzes execution traces, identifying patterns across four failure categories: reasoning errors, execution problems, planning issues, and domain-specific challenges.
Unlike static LLM judges, Percival functions as an agent that remembers previous errors. This context-aware analysis connects events across complex execution paths, capturing failures that traditional evaluators would miss.
When examining traces, Percival provides plain English explanations of what went wrong, groups similar errors, and suggests prompt improvements to prevent recurrence. The platform integrates with major frameworks, including LangChain, Hugging Face Smolagents, Pydantic AI, and OpenAI Agent SDK.
Despite these strengths, the architecture lacks comprehensive session analytics. While Percival excels at individual trace analysis, you won't find consolidated views of multi-turn conversations or user journey tracking across multiple agent interactions.
If you work with conversational agents or complex multi-session workflows, these limitations might impact your visibility.
Integration and scalability
Agent architectures push observability systems to their limits. Thousands of concurrent executions generating millions of data points per hour need platforms that scale transparently while capturing every interaction and decision.
Galileo
When your production agent systems generate massive data volumes, traditional monitoring tools often buckle under pressure. As each conversation creates dozens of tool calls and multiple agent interactions, sampling becomes risky while comprehensive logging grows expensive.
The auto-instrumentation capabilities solve this by connecting directly to major providers like OpenAI, Anthropic, Vertex AI, and AWS without requiring custom code. With a serverless architecture that scales automatically, you can eliminate capacity planning concerns.
Multi-tier storage keeps your recent data accessible for debugging while cost-effectively archiving older information. The Luna-2 models make continuous evaluation financially viable, reducing costs by up to 97% compared to GPT-based alternatives.
This makes comprehensive coverage practical even at enterprise scale.
During ingestion, PII detection and redaction happen automatically, ensuring sensitive data gets scrubbed before storage. If you work in regulated industries, you can stream production traffic directly without building separate sanitization pipelines.
Deployment flexibility lets you choose fully managed SaaS, private VPC for data sovereignty, or complete on-premises installation behind your firewall. This addresses diverse compliance requirements without architectural compromises.
With just one SDK call added to your agent code, traces flow immediately. As your usage grows across regions or environments, the platform manages scaling complexity automatically.
Patronus AI
The API-first architecture of Patronus AI makes integration straightforward through their Python SDK, especially if you're already using Python-based agent frameworks.
For teams comfortable with SaaS solutions, cloud-hosted deployment through AWS Marketplace simplifies adoption. The infrastructure, scaling, and updates are managed for you without additional operational overhead.
If you have data residency requirements, on-premises deployment options allow evaluation models to run inside your infrastructure. This addresses privacy concerns if you work in regulated industries that can't send sensitive data externally.
The open-source nature of the Glider evaluation model provides additional flexibility. You can download and run Glider on your own hardware, avoiding external API dependencies while maintaining evaluation capabilities.
Beyond the base API costs, custom LLM judges for specialized criteria mean additional expenses for external model calls. The evaluation architecture requires you to provision and manage these judge models yourself, adding complexity that built-in evaluators like Luna-2 eliminate.
Compliance and security
Production AI systems face scrutiny that test environments never see. Auditors demand complete logs, security teams need PII protection, and regulators expect consistent policy enforcement with documentation of every decision.
Galileo
In regulated industries, a single compliance failure can have serious consequences. Every agent conversation potentially contains PII, each tool call generates audit requirements, and all responses need policy verification before execution.
To address these diverse needs, Galileo offers three deployment options:
Fully managed SaaS for rapid implementation
Private VPC for data sovereignty
Complete on-premises deployment where sensitive data stays within your infrastructure
With SOC 2 Type II certification validating security controls and enterprise features like role-based access and encrypted storage, your logs remain protected throughout their lifecycle. These safeguards are foundational to the platform architecture.
The critical advantage comes from runtime protection. Galileo Protect evaluates every agent response in under 150 milliseconds, blocking policy violations before they execute or reach users. You configure rules once, and they apply consistently across all services.

During processing, sensitive information gets automatically detected and redacted, keeping regulated data secure without manual intervention. Your security team can implement these same protections across services using dedicated guardrails.
For compliance verification, permanent audit trails capture every request, response, and intervention with tamper-proof timestamps.
During audits, you can demonstrate exactly which guardrail prevented which action and when, transforming compliance reviews from investigations into straightforward documentation checks.
High-availability clusters across multiple regions ensure your compliance infrastructure remains operational during traffic spikes or regional outages. This continuous protection prevents the gaps that could create liability.
Patronus AI
Security validation through SOC 2 Type 2 and ISO 27001 certifications demonstrates Patronus AI's commitment to robust security practices. Their cloud deployments use TLS encryption in transit and AES-256 encryption at rest to protect your data.
For teams requiring on-premises solutions, self-hosting evaluation models keep sensitive information within your infrastructure. This addresses data residency requirements common in financial services and healthcare organizations.
Following industry frameworks, including OWASP and NIST, ensures that evaluation workflows meet established security standards. Automated data lifecycle management through custom retention policies helps you satisfy privacy requirements without manual processes.
Granular role-based access controls let you restrict who can view evaluation results, traces, and sensitive inputs. You can configure permissions based on job functions and need-to-know principles.
The primary limitation stems from the evaluation-first architecture, which lacks native runtime blocking capabilities.
When unsafe outputs are detected, the system triggers webhook alerts that your application must intercept and handle. This creates a potential gap between detection and prevention, where policy violations might reach users if your integration code fails.
For air-gapped environments or scenarios requiring complete network isolation, the external API dependency might present challenges. You must either accept outbound connectivity or implement separate offline evaluation workflows that sacrifice the real-time capabilities of the hosted solution.
Usability and cost of ownership
Platform success depends on more than feature lists. Daily workflows must feel natural, iteration must be fast rather than slow, and long-term costs must stay reasonable as you scale from hundreds to millions of agent interactions.
Galileo
The unified workspace interface provides complete visibility where full traces, live diffs, and A/B comparisons appear without context switching.
When you need to replay last week's incident, one click recreates the entire session with instantly computed metrics, allowing you to improve prompts and immediately see quality improvements.
Because evaluations run on small language models, response time remains under 200 milliseconds even when scoring across dozens of dimensions.
The Luna-2 architecture costs up to 97% less than GPT-4 for similar evaluation tasks, making comprehensive coverage standard practice rather than an expensive luxury.
This cost efficiency means you can layer sentiment analysis, toxicity detection, hallucination checks, and custom business rules without worrying about evaluation expenses. Many teams routinely run 10-20 metrics per interaction because it's finally economically feasible.
As you review outputs, the system adapts metrics automatically. When you accept a response as good or reject it as problematic, the evaluation model adjusts to match your preferences. Historical traces get rescored with updated criteria, maintaining consistency for comparison over time.
Without per-seat charges, you can add reviewers, product managers, or executives to dashboards at no extra cost. This pricing approach removes artificial constraints that force other tools to limit access, enhancing collaboration across teams.
Patronus AI
The evaluation workflow centers on Evaluation Runs, where you select models, datasets, and criteria, then compare performance through side-by-side views. This clear visual approach simplifies benchmarking different strategies.
To overcome the initial challenge of building evaluation datasets, the Loop assistant generates test cases automatically. This AI feature suggests variations and edge cases you might otherwise overlook.
For troubleshooting agent issues, Percival's trace analysis explains failures in plain language instead of requiring you to parse raw logs. This accessibility extends the tool's value to product managers and non-technical stakeholders who need visibility without engineering expertise.
The usage-based pricing model charges $10-20 per 1,000 API calls, depending on evaluator size. While this eliminates upfront commitments, costs scale directly with production volume. If your agents handle one million conversations monthly with five evaluators per interaction, this generates $50,000-100,000 in monthly API expenses alone.
Beyond these base fees, custom LLM judges for specialized criteria incur additional model inference costs. The platform gives you the flexibility to configure any evaluation logic needed, but you pay for running those models.
What customers say
Marketing tells one story. Customer experiences reveal how platforms actually perform under pressure, showing which features deliver and which ones break when volume and complexity increase.
Galileo
You'll join over 100 enterprises already relying on Galileo daily, including high-profile adopters like HP, Reddit, and Comcast, who publicly credit the platform for keeping sprawling agent fleets stable at scale.
Galileo customers report significant results:
"The best thing about this platform is that it helps a lot in the evaluation metrics with precision and I can rely on it, also from the usage I can understand that it is exactly built for the specific needs of the organization and I can say that it's a complete platform for experimentation and can be used for observations as well"
"The platform is helping in deploying the worthy generative ai applications which we worked on efficiently and also most of the time i can say that its cost effective too, the evaluation part is also making us save significant costs with the help of monitoring etc"
"Galileo makes all the effort that is required in assessing and prototyping much easier. Non-snapshots of the model's performance and bias are incredibly useful since they allow for frequent checkups on the model and the application of generative AI in general."
"Its best data visualization capabilities and the ability to integrate and analyze diverse datasets on a single platform is very helpful. Also, Its UI with customizations is very simple."
Industry leader testimonials

"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products. Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow. With Luna, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and accuracy. This is a game changer for the industry." - Alex Klug, Head of Product, Data Science & AI at HP
"What Galileo is doing with their Luna-2 small language models is amazing. This is a key step to having total, live in-production evaluations and guard-railing of your AI system." - Industry testimonial
"Galileo's Luna-2 SLMs and evaluation metrics help developers guardrail and understand their LLM-generated data. Combining the capabilities of Galileo and the Elasticsearch vector database empowers developers to build reliable, trustworthy AI systems and agents." - Philipp Krenn, Head of DevRel & Developer Advocacy, Elastic
Which platform fits your needs
Your choice ultimately depends on whether your agents make decisions with real consequences that demand prevention rather than detection. The architectural differences between these solutions create distinct operational profiles.
Choose Galileo when you require:
Deep visibility: Graph Engine visualization and automated Insights Engine help you trace complex decision paths and identify failure patterns automatically
Real-time protection: Runtime guardrails block unsafe outputs before execution, preventing harmful actions rather than just detecting them
Cost-effective evaluation: Luna-2 models deliver evaluation at 97% lower cost than GPT-based alternatives while maintaining sub-200ms latency
Session intelligence: Complete tracking of user journeys across multi-turn workflows reveals patterns invisible to point-in-time evaluation
Enterprise flexibility: Deployment options, including on-premises installation, meet regulated industry requirements without sacrificing capabilities
This architecture suits teams building complex multi-agent systems where preventing failures matters more than detecting them after they've already affected users.
Choose Patronus AI when:
Your workflows center on traditional LLM evaluation rather than complex multi-agent systems requiring real-time intervention
You prioritize post-hoc trace analysis and debugging over inline prevention capabilities
Your team prefers open-source evaluation models that can be self-hosted within your infrastructure
You're comfortable building your own runtime protection layers and handling alert webhooks for incident response
Your use cases focus on offline experimentation and benchmarking rather than always-on production guardrails
The choice comes down to your operational philosophy.
Teams requiring guaranteed prevention rather than detection will find Galileo's runtime intervention essential. Organizations satisfied with evaluation workflows and post-incident analysis can use Patronus AI's specialized evaluators and debugging tools.

Evaluate your AI applications and agents with Galileo
Achieving agent reliability requires more than metrics and dashboards. You need automated failure detection that identifies problems before they cascade, evaluation infrastructure that scales without linear cost increases, and runtime protection that prevents harmful outputs from reaching users or executing dangerous actions.
Galileo's comprehensive agent reliability platform provides this unified solution:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you build reliable LLMs and AI agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.
Jackson Wells