Galileo vs. Weights & Biases: The Comprehensive Observability Platform That Goes Beyond Evaluations

Jackson Wells
Integrated Marketing

When autonomous AI agents coordinate tools, make decisions, and execute complex reasoning chains, yesterday's experiment trackers struggle to surface what actually matters. Your AI reliability needs more than logging hyperparameters and plotting loss curves.
Production agents fail in ways training metrics never anticipated - picking the wrong tools, mismanaging context windows, or breaking down in multi-turn conversations. These failures remain invisible to platforms built for supervised learning.
Your choice between Galileo's agent-first architecture and Weights & Biases's experiment-tracking heritage will determine whether your team fixes agent failures in minutes or spends hours piecing together decision paths from scattered logs.
Check out our Agent Leaderboard and pick the best LLM for your use case

Galileo vs Weights & Biases at a glance
When evaluating these platforms, fundamental architectural differences emerge immediately. Galileo addresses agent reliability challenges purpose-built for autonomous systems, while Weights & Biases extends its ML experiment tracking foundation into LLM territory through Weave, its observability layer:
Capability | Galileo | Weights & Biases |
Platform focus | Purpose-built AI eval and observability platform with real-time protection and automated failure detection | Classical ML experiment tracking extended to LLM applications through Weave |
Core architecture | Agent Graph visualization, multi-agent session tracking, and Insights Engine for automatic root cause analysis | Traditional experiment tracking with hyperparameter sweeps, model registry, and Weave for LLM tracing |
Evaluation approach | Luna-2 SLMs delivering 97% cost reduction vs GPT-4 with sub-200ms latency for comprehensive scoring | LLM-as-judge approach requiring external model inference at full provider costs |
Runtime protection | Native guardrails with deterministic override/passthrough blocking unsafe outputs pre-delivery | Limited runtime capabilities; primarily relies on pre/post hooks requiring custom implementation |
Agent-specific capabilities | Complete agentic workflow monitoring with tool selection quality, flow adherence, action completion metrics | Basic trace visualization without dedicated agent analytics or multi-step workflow understanding |
Deployment model | SaaS, private VPC, or fully on-premises with enterprise controls from day one | Cloud-hosted SaaS or self-hosted with Kubernetes; private cloud options post-CoreWeave acquisition |
Enterprise customers | 100+ enterprises including Fortune 500s like HP, Reddit, Comcast processing 20M+ traces daily | 1,300+ organizations including OpenAI, Meta, NVIDIA, Microsoft spanning ML and AI development |
These foundational differences cascade through every operational aspect, from how teams investigate production incidents to the total cost of ownership at scale.
Core functionality
Seeing how agents actually run makes the difference between basic monitoring and effective debugging. When multi-step reasoning falls apart, you need immediate understanding, not days spent reconstructing what went wrong from generic logs.
Galileo
When your production agents fail, they rarely do so cleanly. They might pick the wrong tools, wander off-task, or hallucinate mid-conversation while appearing superficially fine. Traditional logs capture these failures as walls of text, forcing you to manually connect dots across disconnected services.
Galileo's Graph Engine changes this dynamic by visualizing every decision branch, tool call, and reasoning step as an interactive map. Unlike flat traces, the graph reveals exactly where coordination breaks down between agents, which tools receive bad inputs, and how context degrades across conversation turns.
Behind the scenes, the Insights Engine works continuously, automatically grouping similar failures across thousands of sessions and identifying patterns you might miss.
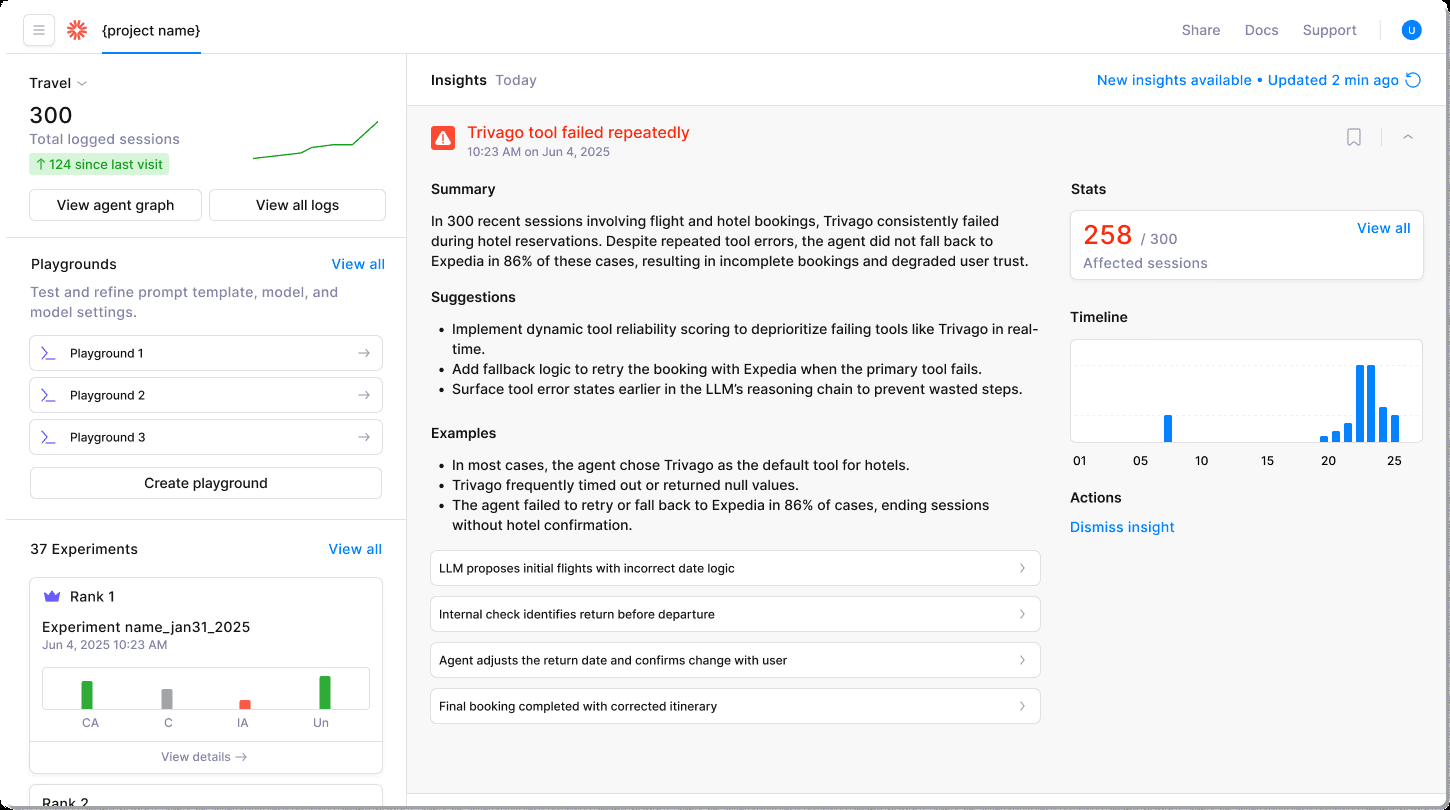
For instance, if tool selection quality suddenly drops 15%, the system flags it before your users complain. When agents get stuck in decision loops, automated alerts pinpoint the prompt issue causing the behavior.
For complex dialogues, multi-turn session views maintain full context, tracking how agents build on previous responses and highlighting where memory management fails. This session-level insight becomes crucial for debugging conversations spanning dozens of interactions.
Weights & Biases
Staying organized while testing dozens of prompt variants simultaneously presents a significant challenge. Weights & Biases built its reputation solving this problem for traditional ML through comprehensive experiment tracking, model registries, and hyperparameter sweeps that accelerate scientific iteration.
The platform continues to excel at experiment management. You can log every training run with automatic versioning, compare loss curves across hundreds of configurations, and track lineage from dataset preparation through deployment.
Automated sweeps explore parameter combinations that manual testing would inevitably miss.
Through its Weave extension, this foundation now reaches into LLM territory. You'll capture prompt chains, trace API calls to external models, and visualize execution flows. Your team can log evaluations against each prompt version, building datasets that inform future experiments and track performance over time.
However, Weave lacks agent-specific analytics capabilities. Multi-agent coordination, tool selection quality, and complex reasoning workflows receive generic trace treatment without specialized failure detection.
While the platform excels at tracking what happened, determining why your agents behaved strangely requires significant manual investigation.
Technical capabilities
Agent reliability depends on continuous quality checks without manual bottlenecks. Evaluation costs explode when every production conversation needs expensive judge models, while delayed feedback makes improvements painfully slow.
Galileo
You often face an impossible choice: sample a tiny fraction of traffic for affordable evaluation, or destroy your budget attempting full coverage. GPT-4-based judges charge full rates per assessment, making 100% production monitoring financially impossible for most organizations.
Galileo's Luna-2 small language models solve this dilemma. These purpose-built evaluation models match GPT-4's accuracy while costing roughly 3% as much—about $0.02 per million tokens versus GPT-4's rates.

Sub-200-ms latency enables real-time scoring without user-facing delays, supporting dozens of simultaneous metrics on shared infrastructure.
With the multi-headed design, scaling economics transform dramatically. Instead of separate services for each quality dimension, Luna-2 allows hundreds of metrics to run efficiently together.
You can layer hallucination detection, sentiment analysis, safety scoring, and domain-specific checks without multiplying costs.
Continuous Learning via Human Feedback (CLHF) shrinks metric development from weeks to minutes. By providing just 2-5 examples of what you want, the system tunes evaluators to match your standards.
This capability proves essential when conventional metrics miss quality dimensions specific to your business needs.
To complete the protection suite, real-time guardrails check every response before delivery, applying policies that block harmful outputs, redact PII, and prevent tool misuse. These guardrails work in line rather than alerting after something goes wrong, shifting from reactive to proactive protection.
Weights & Biases
Classical ML evaluation relies on ground truth labels and clear metrics like accuracy and precision. LLM evaluation breaks these assumptions—no single right answer exists for most prompts, and quality remains subjective without clear measurement frameworks.
For your evaluation needs, Weights & Biases implements the LLM-as-judge methodology. You define evaluation criteria, then use external models like GPT-4 or Claude to score outputs against these guidelines.
This approach offers flexibility—any natural language evaluation prompt becomes a metric you can run across experiments.
The costs, however, add up quickly.
Each evaluation uses full model inference at provider rates, making comprehensive production monitoring expensive at scale. If you're scoring 10 quality dimensions across 100,000 daily agent interactions, you'll face substantial monthly bills before even considering retrieval, generation, or other operational costs.
Runtime capabilities remain limited in comparison. Guardrails exist as pre/post-hooks requiring custom code rather than integrated protection. You'll need to build your own logic to intercept unsafe outputs, enforce policies, or prevent harmful actions—features Galileo provides out-of-the-box but require engineering work here.
Integration and scalability
Observability becomes useless when integration takes months or performance crashes under production load. Real enterprise adoption depends on painless instrumentation and reliable scaling.
Galileo
Your agent deployments typically use multiple frameworks—LangChain for prototyping, CrewAI for multi-agent coordination, and AutoGen for code generation. Maintaining visibility across this mix traditionally requires separate instrumentation for each stack.
Galileo's framework-agnostic SDK eliminates this headache. A single-line import instrument any framework, automatically capturing traces without manual logging sprinkled throughout your code.
The platform handles serialization, batching, and transmission invisibly, letting you focus on agent logic rather than observability plumbing.
For compatibility with existing systems, OpenTelemetry support ensures traces flow into your current monitoring setup. If you're already using OTEL, you can add Galileo without disrupting established dashboards or alerts.
This interoperability matters when you have mature observability practices and don't want to replace working systems.
Deployment flexibility addresses diverse security requirements. Run fully SaaS for simplicity, use a private VPC for enhanced control, or install completely on-premises when your data must stay internal.
Features work consistently across deployments—unlike competitors, where self-hosting means losing functionality.
As your traffic grows, the platform scales seamlessly.
Processing 20 million traces daily across 50,000 concurrent agents, Galileo handles enterprise load without complex capacity planning. Luna-2 models maintain sub-200ms response times regardless of concurrent metrics, preventing evaluation from becoming a bottleneck.
Weights & Biases
Balancing easy experiment tracking with enterprise-grade control presents a challenge. Weights & Biases started serving researchers running laptop experiments, then evolved toward production monitoring as LLM applications moved beyond research.
The platform offers straightforward cloud SaaS deployment with minimal setup required. You can create accounts, get API keys, and start logging experiments in minutes. If your organization is comfortable with data leaving your environment, this option provides maximum convenience and zero maintenance.
For stricter data requirements, self-hosting is accommodated through Kubernetes deployments. You maintain complete control over experiment data, choosing storage backends and network configurations that match your security policies.
However, self-hosting shifts operational work internally—upgrades, backups, scaling, and troubleshooting become your responsibility.
Scaling requires planning as well. Unlike Galileo's transparent expansion, running high-volume workloads means you must provision databases, tune ClickHouse configurations, and monitor infrastructure health.
Compliance and security
Production AI systems crumble under regulatory scrutiny when audit trails are incomplete, data governance lacks documentation, or runtime controls fail. Compliance isn't optional—it determines whether your agents ever reach real users.
Galileo
Auditors want evidence, not promises. They need timestamped proof that every agent interaction followed policy, sensitive data never leaked, and unsafe outputs were blocked before delivery.
Ad-hoc logging creates dangerous gaps where critical decisions go undocumented.
With SOC 2 Type II certified architecture, Galileo provides comprehensive audit trails capturing every agent decision.
When regulators question an interaction from six months ago, you can show exactly what inputs were received, which reasoning paths were taken, what tools were used, which guardrails were applied, and what outputs were delivered.
Policy versioning proves equally important for compliance needs. Your compliance officers must show which specific ruleset governed each interaction, especially when policies change over time.
The platform tracks policy history automatically, preventing situations where incident investigation reveals outdated rules were actually in effect.
For maximum data control, full on-premises deployment ensures sensitive healthcare records, financial transactions, and other regulated data never cross external networks. Unlike competitors, where "on-prem" means hybrid setups with external control planes, Galileo runs entirely behind your firewalls when needed.
Built-in PII detection and redaction work automatically at runtime. Agent responses are scanned before delivery, masking social security numbers, credit cards, and other sensitive patterns.
Weights & Biases
Classical ML compliance is relatively straightforward compared to autonomous agent governance, where runtime behavior determines regulatory risk.
The platform provides essential security controls expected from mature solutions. SOC 2 Type II and ISO 27001 certifications demonstrate commitment to security processes, while annual penetration testing identifies vulnerabilities before attackers find them.
Your data remains protected with encryption both in transit and at rest.
To address data residency requirements, self-hosting keeps experiment data completely internal, satisfying regulations that prohibit external data transmission. Role-based access controls limit who can view sensitive experiments, while audit logs track access patterns for security investigations.
However, runtime policy enforcement remains largely DIY. Weave provides pre/post hooks where you can inject custom guardrail logic, but implementing comprehensive protection requires significant engineering effort.
Your organization will need developers writing safety checks, maintaining policy engines, and ensuring guards actually prevent harmful actions rather than just logging them after they happen.
Usability and cost
Platform sophistication means nothing when your team can't adopt it quickly or costs explode at scale. Daily experience and financial sustainability determine whether observability becomes a competitive advantage or an abandoned experiment.
Galileo
Most observability platforms require lengthy implementation projects. Teams typically spend weeks instrumenting code, configuring dashboards, and training colleagues before seeing value.
During this time, production incidents continue accumulating while visibility remains poor.
Galileo dramatically shrinks this timeline. Framework-agnostic instrumentation needs just one line of code—import the SDK and traces start flowing automatically. You won't need manual logging scattered throughout your codebase, complex configuration files, or separate setups per framework.
The traditional metric development bottleneck disappears with Continuous Learning via Human Feedback. Instead of spending weeks coding custom evaluators, you can describe desired quality dimensions in natural language.
The system generates appropriate metrics immediately, then fine-tunes based on your feedback. This transforms specialized evaluation from a technical blocker into a self-service capability.
Evaluation economics fundamentally change with Luna-2 small language models. At about $0.02 per million tokens—97% cheaper than GPT-4 alternatives—comprehensive production monitoring becomes financially viable.
You can score every single agent interaction across dozens of quality dimensions without budget crises.
When agents leak PII, generate harmful content, or execute wasteful tool calls, the downstream impact—legal liability, customer churn, support overhead, remediation—vastly exceeds any monthly observability charge.
Galileo's inline protection blocks these incidents before they occur, delivering value that passive monitoring never achieves.
Weights & Biases
At enterprise scale, understanding the true cost of comprehensive experiment tracking can be challenging. Weights & Biases pricing grows with usage across multiple dimensions—tracked hours, storage, and Weave data ingestion—making the total cost less transparent than competitors.
Individual researchers and small teams benefit from a useful free tier. Academic users get unlimited tracked hours plus 200GB storage, enabling legitimate research without payment barriers.
This generous policy helped build the extensive user community that sets Weights & Biases apart from newer options.
As you move to production deployment, costs add up quickly. Tracked hours measure wall-clock training time, so long-running experiments consume quota rapidly. Storage fees apply to artifacts and logged data, calculated as rolling 30-day averages that can surprise you when model checkpoints accumulate.
Weave data ingestion has separate limits requiring careful monitoring at scale.
The LLM-as-judge approach adds another cost layer beyond the platform itself. Unlike Galileo's built-in Luna-2 models, every evaluation invokes external LLM APIs at full provider rates. If you need comprehensive production scoring across multiple quality dimensions, this generates substantial monthly inference charges.
Self-hosting shifts costs rather than eliminating them. You avoid SaaS fees but inherit operational work—provisioning infrastructure, managing databases, ensuring uptime, and troubleshooting issues.
Fixed dashboard templates also limit customization without engineering work. If you want specialized views, you'll need to build custom integrations or export data to external visualization tools.
What customers say
Marketing claims dissolve under production reality. Customer experiences reveal how platforms perform when reliability matters, deadlines loom, and budget constraints bite.
Galileo
You'll join over 100 enterprises already relying on Galileo daily, including high-profile adopters like HP, Reddit, and Comcast, who publicly credit the platform for keeping sprawling agent fleets stable at scale.
Galileo customers report significant results:
"The best thing about this platform is that it helps a lot in the evaluation metrics with precision and I can rely on it, also from the usage I can understand that it is exactly built for the specific needs of the organization and I can say that it's a complete platform for experimentation and can be used for observations as well"
"The platform is helping in deploying the worthy generative ai applications which we worked on efficiently and also most of the time i can say that its cost effective too, the evaluation part is also making us save significant costs with the help of monitoring etc"
"Galileo makes all the effort that is required in assessing and prototyping much easier. Non-snapshots of the model's performance and bias are incredibly useful since they allow for frequent checkups on the model and the application of generative AI in general."
"Its best data visualization capabilities and the ability to integrate and analyze diverse datasets on a single platform is very helpful. Also, Its UI with customizations is very simple."
Industry leader testimonials

"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products. Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow. With Luna, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and accuracy. This is a game changer for the industry." - Alex Klug, Head of Product, Data Science & AI at HP
"What Galileo is doing with their Luna-2 small language models is amazing. This is a key step to having total, live in-production evaluations and guard-railing of your AI system." - Industry testimonial
"Galileo's Luna-2 SLMs and evaluation metrics help developers guardrail and understand their LLM-generated data. Combining the capabilities of Galileo and the Elasticsearch vector database empowers developers to build reliable, trustworthy AI systems and agents." - Philipp Krenn, Head of DevRel & Developer Advocacy, Elastic
Which platform fits your needs
Your agent architecture complexity and operational maturity determine the right choice. Simple evaluation workflows need different tooling than production systems, making autonomous decisions that affect business outcomes.
Choose Galileo when:
Your organization deploys autonomous agents making real-time decisions with business impact, requiring comprehensive runtime protection
Agent complexity spans multiple tools, reasoning chains, and coordination patterns invisible to generic trace viewers
Production scale demands cost-effective evaluation across 100% of agent interactions rather than small samples
Compliance requirements mandate deterministic policy enforcement, comprehensive audit trails, and on-premises deployment options
Teams need actionable insights from automated failure detection rather than manual log analysis
Multi-agent systems require session-level analytics, tracking how context and coordination evolve across conversation turns
Budget constraints make GPT-4-based evaluation financially prohibitive at desired coverage levels
Integration simplicity matters more than customizing every observability component
Choose Weights & Biases when:
Primary focus remains classical ML model training, fine-tuning, and hyperparameter optimization, where the platform excels
LLM applications consist of straightforward prompt chains without complex multi-agent coordination
Team priorities emphasize experiment reproducibility and scientific rigor over runtime protection
Organization already invested heavily in Weights & Biases infrastructure and workflows for traditional ML
Teams operating both traditional ML training pipelines and production agentic applications increasingly deploy both platforms—Weights & Biases for model development cycles, Galileo for agent reliability monitoring.
Evaluate your AI applications and agents with Galileo
Every production agent failure that reaches users erodes the trust you spent months building. Between missed tool calls, hallucinated responses, and policy violations that slip through manual reviews, the reliability gap directly impacts revenue and reputation.
Here’s how Galileo transforms your agent development from reactive debugging to proactive quality assurance through a comprehensive reliability platform:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you build reliable LLMs and AI agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.
Jackson Wells