Why 93% of AI Teams Struggle with LLM-as-a-Judge and 8 Alternatives That Work

Jackson Wells
Integrated Marketing

The AI industry has converged on a default: "LLM-as-a-judge." Adoption has widened. Our survey of 500 AI practitioners shows that 67% of teams now rely on large language models to score their own outputs.
Yet, the satisfaction gap is massive.
A staggering 93% of these teams report major reliability problems, and 42.4% cite "consistency", where the same input yields different scores, as the breaking point.
For engineering leaders, this is an architectural crisis.
We are attempting to validate probabilistic systems (the agent) against other probabilistic systems (the judge), resulting in a compounding error rate that makes rigorous QA impossible. If your CI/CD pipeline only passed 42% of the time on the same code, you would dismantle it immediately.
However, the solution isn't to abandon AI-based evaluation; it is to recognize that "LLM-as-a-judge" is just one tool in a much larger toolbox. Elite teams (those achieving 70%+ reliability) don't rely on a single oracle. They build composite evaluation architectures. Below are eight alternative approaches that, when combined, solve the consistency crisis.
Eight alternative approaches to LLM-as-a-judge demonstrate how teams can build a comprehensive evaluation infrastructure that delivers the consistency, accuracy, and scale that pure LLM-as-a-judge approaches struggle to achieve.
TL;DR:
Deterministic validators catch 80% of failures LLMs miss at zero marginal cost by validating formats, schemas, and structural requirements
Fine-tuned specialized evaluators achieve ChainPoll-level 90% accuracy at 97% lower cost than general-purpose LLMs through purpose-built architecture
Human-in-the-loop evaluation closes feedback gaps that automation cannot bridge, identifying unknown unknowns that define quality improvement roadmaps
Hybrid ensemble approaches combine multiple methods for resilience against any single technique’s weaknesses, achieving comprehensive coverage

1. Deterministic Rule-Based Validators (The Foundation Layer)
Before reaching for LLM judges, start with the evaluation method that costs nothing per run and achieves perfect consistency: deterministic validation. Regex patterns verify formats, schema validators check structure, and output parsers confirm machine-readability.
These rule-based approaches handle entire classes of failures that LLMs either miss entirely or evaluate inconsistently across runs.
The power of deterministic validation comes from its zero marginal cost and instant feedback.
Every evaluation executes in microseconds without API calls or inference costs. The same input always produces the same validation result: no temperature settings, no sampling variation, no model updates that change behavior. For teams processing millions of agent interactions, this translates to massive cost savings while improving reliability.
Picture a financial services agent extracting account information from customer requests. Account numbers must be exactly 10 digits, routing numbers follow specific format patterns, and transaction amounts must be in two decimal places.
Here, simple regex patterns can catch violations instantly — no need to ask GPT-4 whether ‘1234567’ looks like a valid 10-digit account number. The rule is known definitively.
Where deterministic validation falls short: semantic quality and nuance.
Rules can verify an email address matches format patterns, but can’t evaluate whether a customer service response sounds empathetic. They confirm JSON parses correctly, but don’t assess if extracted entities make sense in context. Teams need both — deterministic checks as the foundation, with other methods layered on top for semantic evaluation.
The insight elite teams recognize: they over-relied on LLMs for validation that simple rules handle perfectly. Before implementing any LLM-based evaluation, ask what deterministic checks could eliminate entire failure classes at zero cost. Most teams discover they can catch issues through pure rule-based validation.
2. Fine-Tuned Specialized Evaluator Models (The Accuracy Play)
When evaluation requires semantic understanding beyond what rules capture, teams face a choice: use expensive general-purpose LLMs inconsistently, or build specialized evaluators purpose-designed for assessment tasks.
The ChainPoll methodology demonstrated that small language models, when asked binary questions, achieve 90% accuracy (comparable to GPT-4 judges) at a fraction of the cost and with dramatically improved consistency.
The breakthrough comes from specialization.
General-purpose foundation models are over-engineered for evaluation: they contain capabilities for creative writing, coding, analysis, and dozens of other tasks that contribute nothing to assessment quality.
However, specialized evaluators strip away everything except the ability to judge specific quality dimensions, resulting in models that are smaller, faster, cheaper, and often more accurate than their general-purpose counterparts.
Galileo’s Luna-2 SLMs exemplify this approach: an evaluation-specific architecture that delivers a 97% cost reduction compared to GPT-4-based alternatives while maintaining accuracy through a purpose-built design.
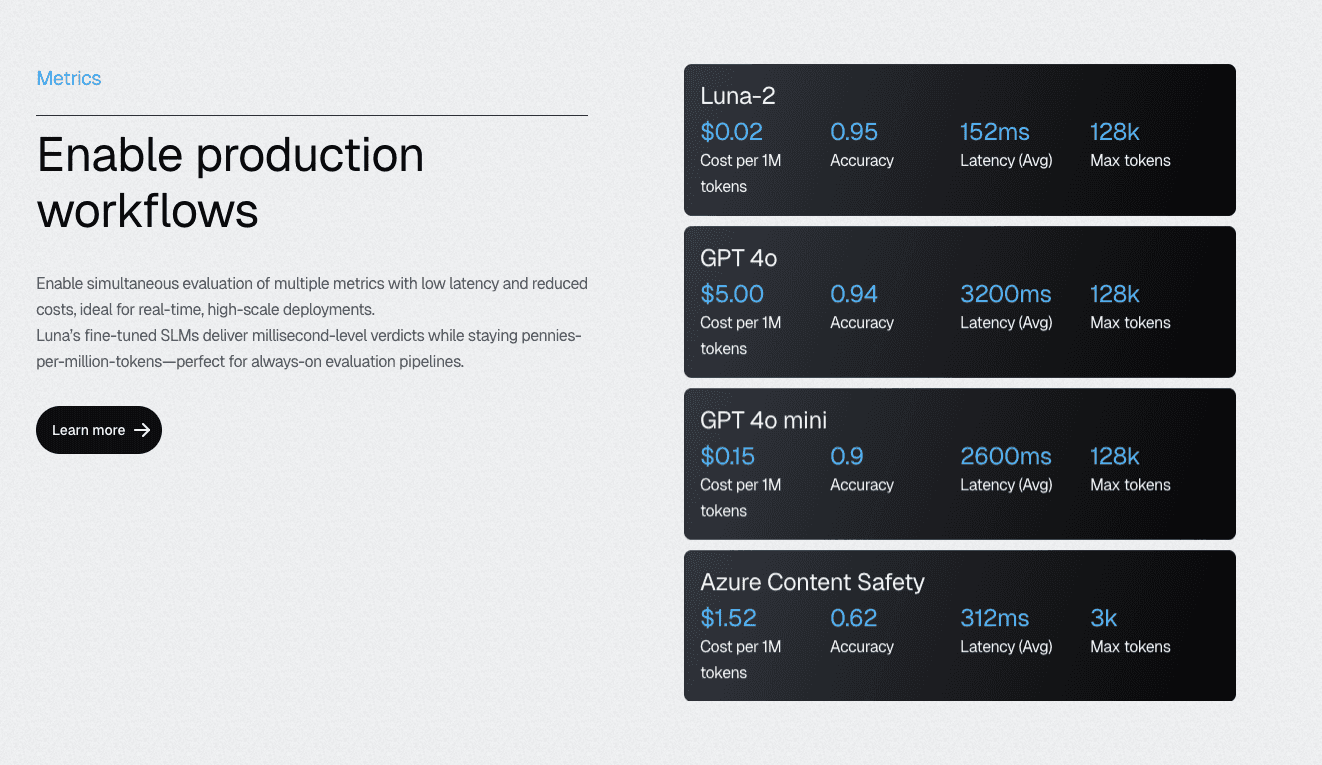
The multi-headed architecture enables running 10–20 different metrics simultaneously on shared infrastructure; each metric benefits from specialization without requiring separate model deployments.
Instead of prompting GPT-4 to evaluate every output, consider training an evaluator specifically for YOUR domain, YOUR quality criteria, and YOUR edge cases.
The trade-off: specialized evaluators require initial training data and domain expertise to build effectively. Teams need representative examples of good and bad outputs, clear quality criteria, and iteration cycles to refine evaluator behavior.
But this upfront investment pays dividends at scale. Every evaluation after training costs less while delivering more consistent results.
3. Human-in-the-Loop Evaluation (The Ground Truth Builder)
No matter how sophisticated your automated metrics become, they can eventually drift. The "unknown unknowns" (new types of user queries, novel jailbreak attempts, or subtle factual errors) can only be reliably identified by human domain experts.
Elite teams do not view human evaluation as a bottleneck to be eliminated, but as the source of truth that calibrates their automated systems.
Consider a clinical healthcare agent. An LLM judge might mark a response as "safe" because it sounds polite and structured. A clinical SME, however, immediately spots that the drug interaction recommendation is outdated. That single human insight is worth a thousand automated checks.
Continuous Learning via Human Feedback (CLHF) transforms these reviews from one-time assessments into systematic improvement cycles. SME feedback tunes evaluators, improving their accuracy on domain-specific quality criteria.
Disagreements between human reviewers and automated evaluators identify calibration gaps. Patterns in human corrections reveal evaluation blind spots that require additional metrics or refined criteria.
The strategic allocation: human evaluation for discovery and calibration, automation for scale and consistency. Elite teams structure dedicated time for SME review sessions; not ad-hoc feedback when someone happens to notice problems, but systematic sampling of agent outputs with clear evaluation protocols.
Human insights feed back into automated systems, driving compounding improvements over time.
4. Statistical Uncertainty Quantification (The Confidence Layer)
LLMs won’t tell you when they’re guessing, but their behavior patterns reveal uncertainty. Run the same prompt five times; high variance in outputs indicates the model lacks confidence in its response.
Measure entropy across token predictions. Low confidence at decision points indicates unreliable generations. Use ensemble models and track disagreement — when multiple models produce different outputs, trust decreases.
Statistical uncertainty quantification provides a confidence layer that catches unreliable outputs before they reach users.
Rather than evaluating whether an output is correct, this approach identifies when the model is uncertain about its correctness, and when such uncertainty warrants human review or alternative processing paths. High-stakes decisions shouldn’t rely on agent outputs with high variance or low confidence scores.
Consider a legal research agent generating case citations.
Running the same query five times produces five different case references — none matching across runs. This variance immediately flags the output as unreliable without needing to verify each citation’s accuracy. The statistical signal says “don’t trust this” before expensive verification processes begin or, worse, before incorrect citations reach legal briefs.
The mechanism is model-agnostic. It works with any LLM by analyzing output patterns rather than internal model states. Measure consistency across temperature variations by tracking token probability distributions.
Then, compare outputs from different model versions. Each statistical technique reveals aspects of model confidence that traditional evaluation misses, enabling smarter routing decisions about which outputs need additional validation.
The cost trade-off: uncertainty quantification requires multiple inferences for the same input, increasing evaluation costs. Teams balance this against the benefit of catching unreliable outputs early.
5. Golden Dataset Regression Testing (The Stability Anchor)
In the rush to build dynamic, "smart" evaluations, many teams neglect the stability of static regression testing. A "Golden Dataset" is a version-controlled collection of inputs with known, perfect outputs (or perfect assertions) that the system must pass before deployment.
This is the anchor that prevents regression.
While probabilistic judges handle open-ended queries, the Golden Dataset handles the non-negotiables. If you update your system prompt to be friendlier, you run it against the Golden Set to ensure it doesn't lose the ability to format SQL queries correctly.
What you can’t measure consistently, you can’t improve systematically. Golden datasets provide the stability anchor that probabilistic LLM judges inherently lack: curated test cases with known correct outputs, version-controlled alongside code, running automatically on every change.

The same inputs always expect the same outputs, making regression detection deterministic rather than dependent on LLM judge consistency.
The power of golden datasets lies in their absolute consistency.
Traditional software testing has long used this approach: unit tests with expected outputs that never change unless requirements change. AI evaluation requires the same foundation: a set of behaviors that always work the same way and are evaluated identically on every run.
When prompt updates or model changes cause these golden tests to fail, teams immediately know that regressions have occurred.
Picture maintaining 500 golden examples covering critical agent behaviors.
Customer data extraction patterns, common query variations, edge cases that previously caused incidents, compliance scenarios that must never fail. Every prompt modification runs against all 500 examples before deployment.
Any change in expected outputs triggers investigation: intentional improvement or unintended regression? The golden set provides ground truth for decision-making.
Limitation: Golden datasets only capture regressions on known test cases. They don’t discover novel failures outside the test set, identify emerging edge cases from production traffic, or adapt as requirements evolve.
Teams need both — golden datasets for stability plus production monitoring for discovery. The combination prevents regressions while enabling continuous quality improvement.
6. Comparative Pairwise Evaluation (The Relative Quality Approach)
Asking an LLM (or a human) to score a response on a scale of 1 to 10 is fraught with subjectivity. Is this summary a 7 or an 8? The criteria are often vague, leading to "grade inflation" where models rate themselves highly. A more robust alternative is Comparative Pairwise Evaluation, which simply asks, "Is Response A better than Response B?"
Humans and models are significantly more reliable at relative ranking than at absolute scoring. By presenting two outputs side by side, perhaps from the current production model versus a candidate release, you can establish a clear "win rate."
The mechanism works particularly well for A/B testing and prompt optimization scenarios where “better” matters more than “perfect.” When comparing two customer service responses, judges (human or LLM) can reliably identify which one sounds more helpful, empathetic, or professional.
But asking them to assign absolute quality scores introduces calibration challenges, subjective thresholds, and score drift over time.
Envision testing two variants of a product recommendation agent.
Rather than scoring each variant’s outputs independently, present pairs of responses side-by-side to evaluators:
Which recommendation better matches user preferences?
Which explanation is clearer?
Which call-to-action is more compelling?
The pairwise winner emerges clearly even when absolute quality remains debatable.
This approach also reduces the burden on evaluators for both human reviewers and LLM judges. Comparative judgments are cognitively simpler than absolute assessments. People naturally think in relative terms: this meal tastes better than that one, this explanation is clearer than the alternative.
Translating those preferences into 1–10 scales introduces artificial precision and reduces reliability.
The limitation: pairwise evaluation doesn’t provide absolute quality measures. Teams learn which variants perform relatively better, but not whether any variant meets acceptance thresholds.
Organizations need both — absolute evaluation to determine whether outputs are acceptable and pairwise comparison to identify improvements. The methods serve different but complementary purposes in comprehensive evaluation strategies.
7. Output Structure Validation (The Format Enforcer)
LLMs hallucinate content, but they also format inconsistently — and malformed outputs break downstream systems regardless of semantic correctness.
For agents that interact with APIs or databases, semantic quality is secondary to structural integrity. If an agent writes a beautiful SQL query but outputs it as plain text instead of a JSON object, the downstream system crashes. Output Structure Validation is the strict enforcement of schema constraints.
JSON schema validation ensures required fields exist. Type checking confirms data matches expected formats. Constraint enforcement verifies values fall within acceptable ranges. Structure validation catches entire failure classes before they propagate through processing pipelines.
The reliability gap that structure validation addresses: you can’t process outputs you can’t parse. An agent might extract perfectly accurate customer information but format it as invalid JSON, causing downstream database writes to fail.
A data extraction task might identify all required entities but miss formatting requirements — API calls reject the payload. Content accuracy becomes irrelevant when the structure prevents use.
Picture an agent extracting customer data for CRM integration. Schema validation can ensure that email fields contain valid email addresses, phone fields match expected patterns, dates parse correctly, and enum values are from the allowed sets.
Structure checks happen before any semantic evaluation, as there’s no point assessing content quality if target systems can’t ingest the output.
This validation layer enables downstream automation. When every output passes structure validation, integration code doesn’t need defensive parsing, error handling for malformed data, or fallback logic for missing fields. The guarantee of correct structure simplifies subsequent steps, reducing complexity for systems that consume agent outputs.
The distinction to maintain: structure validation doesn’t verify content correctness. An email field might contain a validly formatted address that belongs to the wrong person. A date might parse correctly but represent an impossible appointment time.
Structure validation is necessary but insufficient; teams layer semantic evaluation on top of structural checks.
8. Hybrid Ensemble Approaches (The Resilience Strategy)
From our survey, the 93% who report LLM-as-a-judge reliability problems share a common pattern: they use only LLMs for evaluation. Elite teams that achieve comprehensive quality assurance use multiple methods, each catching what others miss.
The resilience comes from redundancy. When one evaluation approach produces ambiguous results, others provide clarity. When one method has blind spots, others compensate.
Hybrid ensemble architecture layers evaluation methods strategically: deterministic checks validate structure and format, statistical methods flag uncertainty, specialized evaluators assess semantic quality, and human review handles edge cases.
Each layer filters outputs, passing only those meeting its criteria to the next stage. The cumulative effect: comprehensive coverage without evaluating everything through every method.
Consider a financial compliance agent using a four-layer evaluation:
First, regex validates that account numbers and transaction amounts match required formats; Most outputs pass immediately at zero cost.
Second, schema checking confirms that all required fields exist with the correct types.
Third, a fine-tuned compliance evaluator scores remaining outputs on regulatory adherence.
Finally, humans review the 10% where automated evaluators show confidence below a 0.8 threshold.
Galileo’s platform orchestrates multi-method evaluation pipelines, enabling teams to define custom workflows combining deterministic checks, specialized models, and human feedback loops.
Rather than building integration code for each evaluation approach, you can configure pipelines declaratively by defining which methods apply to which outputs, how results combine, and when to escalate to human review.
Build a Comprehensive Evaluation for AI Models with Galileo
The high failure rate of LLM-as-a-judge is not a sign that evaluation is impossible; it is a signal that single-method approaches are insufficient. You need a unified infrastructure to move beyond simple prompting and build a robust, multi-layered evaluation strategy.
Here’s how Galileo enables teams to move beyond LLM-as-a-judge limitations through a comprehensive evaluation infrastructure:
Comprehensive Coverage Through Agent Graph: Galileo automatically maps every decision point in multi-step agent workflows, identifies gaps where evaluation is missing, and transforms abstract coverage metrics into actionable engineering work that directly correlates with the 70.3% excellent reliability achieved by elite teams.
Cost-Effective Evaluation at Scale with Luna-2 SLMs: With evaluation costs 97% lower than GPT-4 alternatives and sub-200ms latency even when running 10-20 metrics simultaneously, Galileo enables teams to achieve the 70%+ coverage threshold without budget constraints
Automated Failure Detection via Galileo Signals: Rather than waiting for production incidents to reveal evaluation gaps, Galileo's Insights Engine automatically surfaces failure patterns across agent traces
Runtime Protection: Galileo's industry-leading runtime guardrails catch hallucinations, policy violations, and safety issues in milliseconds at serve time, transforming the incident paradigm from reactive cleanup to preventive blocking
Continuous Improvement with Signals and CLHF: With Galileo, you can fine-tune specialized evaluation models on your domain using Continuous Learning via Human Feedback, achieving the consistency that 93% of teams report missing from standard LLM-as-a-judge approaches
Explore how Galileo orchestrates comprehensive evaluation approaches that achieve elite-level reliability.
Frequently asked questions
What is the multi-judge consensus for LLM evaluation?
Multi-judge consensus uses multiple LLM models to evaluate the same output independently, then aggregates their judgments through majority voting or weighted averaging. Research shows multi-judge systems achieve Cohen's kappa of 0.79 — substantially exceeding human inter-rater reliability of 0.48 (NVIDIA Judge's Verdict benchmark).
How do fine-tuned specialist evaluators compare to GPT-4 judges?
Fine-tuned specialist evaluators, such as Galileo's Luna-2 evaluation model, deliver a 97% cost reduction relative to GPT-4o while maintaining competitive accuracy, highlighting the potential cost-efficiency gains of these models.
How do I implement a hybrid deterministic-LLM evaluation?
Start with deterministic pre-filtering: regex validators for format requirements, rule-based safety checks, and lightweight ML models for content moderation. Route only cases requiring semantic judgment to LLM evaluation. Implement fail-closed guardrails that enforce critical constraints even during LLM service degradation.
Should I use LLM-as-a-judge or human evaluation?
The choice isn't binary. Production systems combine both. Use automated LLM evaluation to scale assessment of routine cases, with human-in-the-loop calibration to ensure automated systems remain aligned with expert judgment. Route high-disagreement cases (where automated judges conflict) to human review, treating disagreement as a signal about evaluation difficulty rather than system failure.
Jackson Wells