Caller
Explore Caller performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Caller
Caller sits at #20 on our agent benchmark, defined by extremes rather than averages. You get blistering speed—its 0.95 score puts response latency in the 95th percentile—and rock-bottom pricing backed by a 0.89 cost-efficiency rating.
Those wins arrive with a steep trade-off: only 16% of tasks reach the finish line (0.160 action-completion score) and the model chooses the right tool just 65% of the time (0.650), leaving one request in three misrouted before it begins.
This split creates a deployment decision based on your risk tolerance rather than raw metrics. If your architecture absorbs frequent retries and escalates failures gracefully, Caller's $0.03 average request cost unlocks rapid experimentation. If your workflow demands consistent, single-pass success—think healthcare scheduling or high-value financial transactions—those same failure rates become non-starters.
Our Agent Leaderboard reports and compares evaluated models across key agent metrics like Action Completion and Tool Selection Quality, helping you pick the best LLM for your specific use case. The analysis ahead reveals precisely where Caller's speed advantage justifies its reliability gaps—and where it simply creates unacceptable risk for your agent stack through granular heatmaps, domain-by-domain breakdowns, cost-performance positioning, and concrete deployment patterns.

Caller performance heatmap
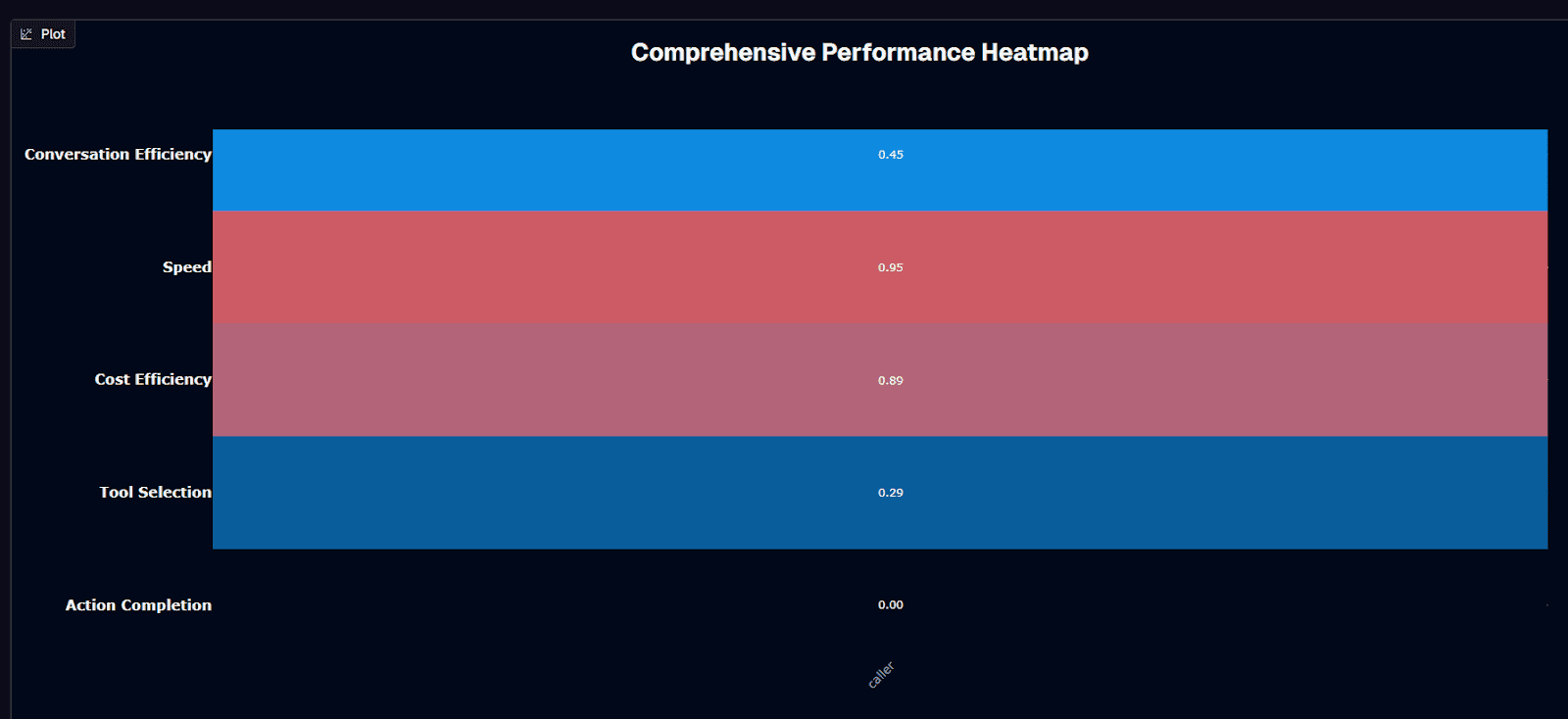
You rarely see a model rocket to the 95th-percentile for speed and still land among the cheapest in the benchmark, yet Caller does exactly that. A 0.95 speed score translates to an average 25.7-second turnaround. The 0.89 cost-efficiency score means each request costs about $0.03. When you're iterating quickly or running millions of low-stakes interactions, that combination feels almost irresistible.
The glow fades once you examine action completion. Caller finishes the job only 16 percent of the time—good for the 20th-percentile. This creates a stark contrast to the 70-80 percent first-call-resolution targets contact centers strive for. In practice, you'd watch 84 of every 100 user tasks stall or fail. Your fallback logic would need to mop up the mess.
Tool selection sits between those extremes. A 0.650 score shows Caller picks the right API roughly two-thirds of the time. That's better than chance yet still leaves a one-in-three risk of invoking the wrong endpoint. You might pass bad parameters or skip an authentication step. For a banking chatbot helping customers check balances, you can wrap that risk in guardrails. Retry when balance data comes back empty. Escalate to a human after two misfires. Swap banking for healthcare scheduling, though, and the same error rate could mean a patient's appointment request vanishes into a black hole—unacceptable when care delays carry real-world consequences.
Map model strengths directly to your workflow requirements. If your application values raw speed and rock-bottom cost over perfect reliability—think routing intents, triaging simple requests, or powering A/B experiments—Caller gives you headroom to scale fast without blowing the budget. If your workflow chains multiple API calls, touches regulated data, or has no tolerance for retries, the 16 percent completion ceiling becomes a hard stop.
Performance Summary: Overall rank #20 | Action Completion: 0.160 (16th percentile) | Tool Selection: 0.650 (65% accuracy) | Average Cost: $0.030 per request | Average Duration: 25.7 seconds | Conversation Efficiency: 0.45 | Speed: 0.95 (95th percentile) | Cost Efficiency: 0.89
Background research
Caller's public footprint remains minimal—you won't find comprehensive documentation disclosing parameter counts or training methodology. What emerges from the performance data is telling: the model ranks 20th on Galileo's benchmark, answers in 25.7 seconds on average, and costs roughly $0.03 per request. Those numbers hint at a small, highly distilled architecture designed to minimize compute rather than chase state-of-the-art reasoning.
Technical due diligence hits walls quickly. No vendor documentation reveals the underlying model family or parameter structure. Given Caller's sub-$0.05 price point and 95th-percentile speed, you're almost certainly looking at a compact, distilled transformer rather than a frontier-scale LLM. The context window remains unpublished, though the 4.2-turn average conversation length suggests a modest window that forces rapid truncation rather than long-form reasoning. All benchmark tasks are text-only with no evidence of vision or audio support, and no function-calling schema beyond the benchmark's basic tool invocation.
Galileo's publicly available information doesn't provide per-token rates or a detailed volume-discount schedule; its pricing page instead lists plan tiers with monthly costs and trace-based usage limits, and there is no verified evaluation data showing a $0.03 end-to-end cost per request. Until those details surface, budget for model costs using the observed average and add a 20% buffer for spike scenarios. Caller exposes a standard REST endpoint for benchmark integration, but no official client libraries—assume you'll be wiring raw HTTP calls or wrapping the API in your own SDK.
Because Caller's creators haven't published training methodology, context limits, or benchmark scores on public datasets like MMLU, you must rely on empirical testing. If you need domain-tuned accuracy gains described in specialized AI literature, be prepared to collect data and fine-tune in-house—there's no turnkey solution yet.
Is Caller suitable for your use case?
Caller's speed and cost advantages matter only when they align with your risk tolerance. These considerations help you decide whether Caller fits your deployment strategy.
Use Caller if you need:
You'll find success with Caller under these specific conditions:
Ultra-low latency responses where sub-second feedback outranks perfect accuracy
High-volume, cost-sensitive traffic—$0.03 per call keeps million-request workloads viable
Straightforward tasks such as classification, routing, or single API invocations
Rapid prototyping cycles where iteration speed outweighs production-grade reliability concerns
Built-in recovery paths—retries, human hand-offs, or validation layers to absorb the high failure rate
Graceful degradation architectures that follow AI phone-system patterns
Avoid Caller if you need:
Your production environment exposes critical gaps that make Caller unsuitable:
Mission-critical workflows where sub-50% completion exposes you to compliance or safety risk
Multi-step tool chains that demand reliable sequencing—Caller's 0.65 score still misfires one in three calls
Regulated verticals like healthcare or finance where completion rates lag 70% FCR benchmarks
Single-pass experiences where your users will not retry or escalate
Autonomous actions with real-world consequences—incorrect API calls create liability you cannot absorb
Caller domain performance
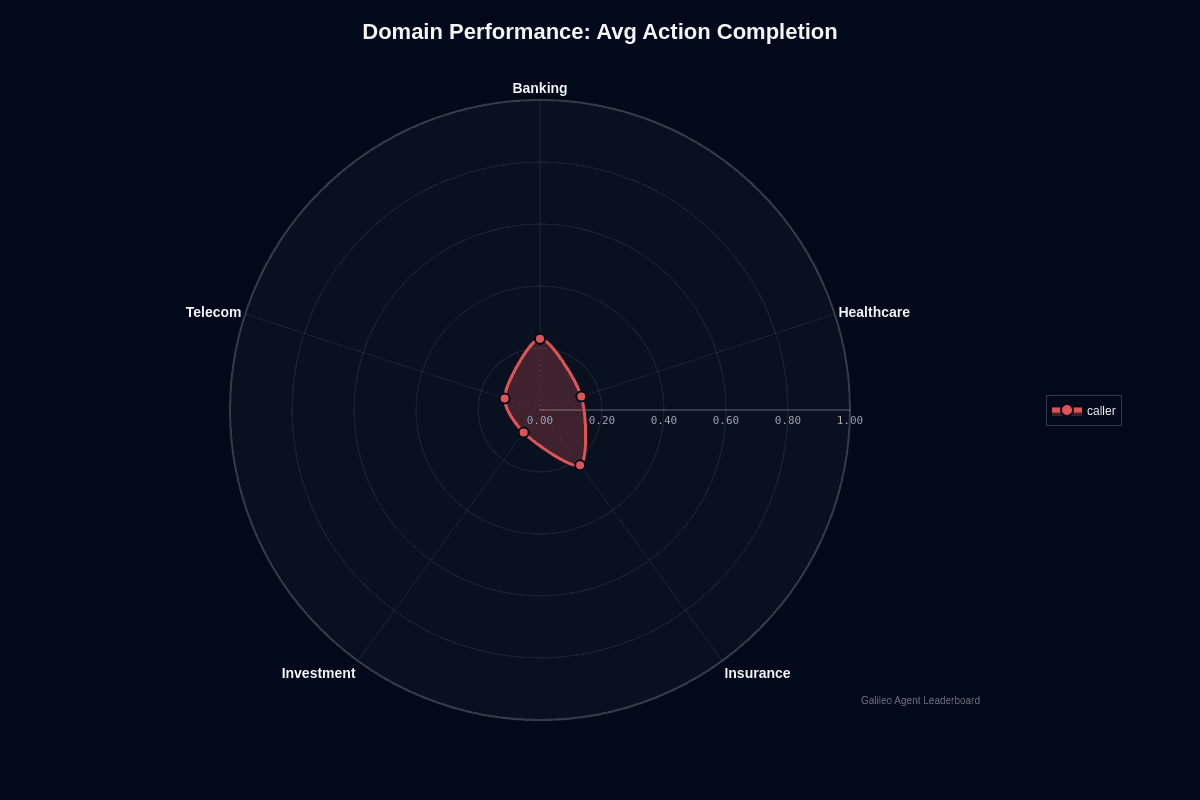
Banking emerges as the sole domain where Caller approaches basic competence, yet even here the numbers barely scrape by. The model completes only 23% of banking tasks. Investment collapses to a 9% success rate—a 14-point gap that translates into 2.5× fewer completed actions. Plot these figures on the radar chart and the asymmetry jumps out. Banking and Insurance points stretch modestly outward at 0.23 and 0.22. Meanwhile, Healthcare (0.14), Telecom (0.12), and Investment (0.09) huddle near the center, exposing sharp domain-specific weaknesses.
Why does Banking edge ahead? Balance inquiries and policy look-ups follow rigid schemas. Caller can pattern-match predictable fields. Insurance enjoys similar structure. The moment workflows demand real-time reasoning—pricing an investment product or triaging a symptom—the model falters. Investment calls in typical call-center workflows often involve multi-step validation, but they do not generally require access to live market data. Caller's planning logic simply stops short. This explains the single-digit completion rate. Healthcare tasks introduce medical terminology and zero-tolerance safety requirements. This throttles success to 14%.
Your industry's performance standards make these numbers even more troubling. Frontline teams in retail banking shoot for 70-75% first-call resolution. Caller's 23% completion doesn't just miss that bar—it crashes through the floor. This leaves 77% of interactions unfinished. Healthcare stakes are higher still. Patient access centers benchmark around 71% FCR. Caller's 14% score is unacceptably risky for appointment scheduling or triage.
Treat Caller as a Tier-0 triage assistant in Banking at most. Let it identify an account or surface a policy number, then escalate instantly. Insurance workflows might tolerate the same guarded approach. In Healthcare and Investment, autonomous deployment is a non-starter. Sub-15% completion rates guarantee frustrated users and potential compliance violations. Remember, every domain score here is alarmingly low. Even Caller's "best" vertical still fails more than three calls out of four. Any production plan must build robust scaffolding around a fundamentally unreliable core.
Caller domain specialization matrix
Domain focus reveals sobering limitations: specialized deployment barely moves the performance needle. This analysis shows how far each vertical sits above or below Caller's baseline performance, independent of raw scores.
Action completion
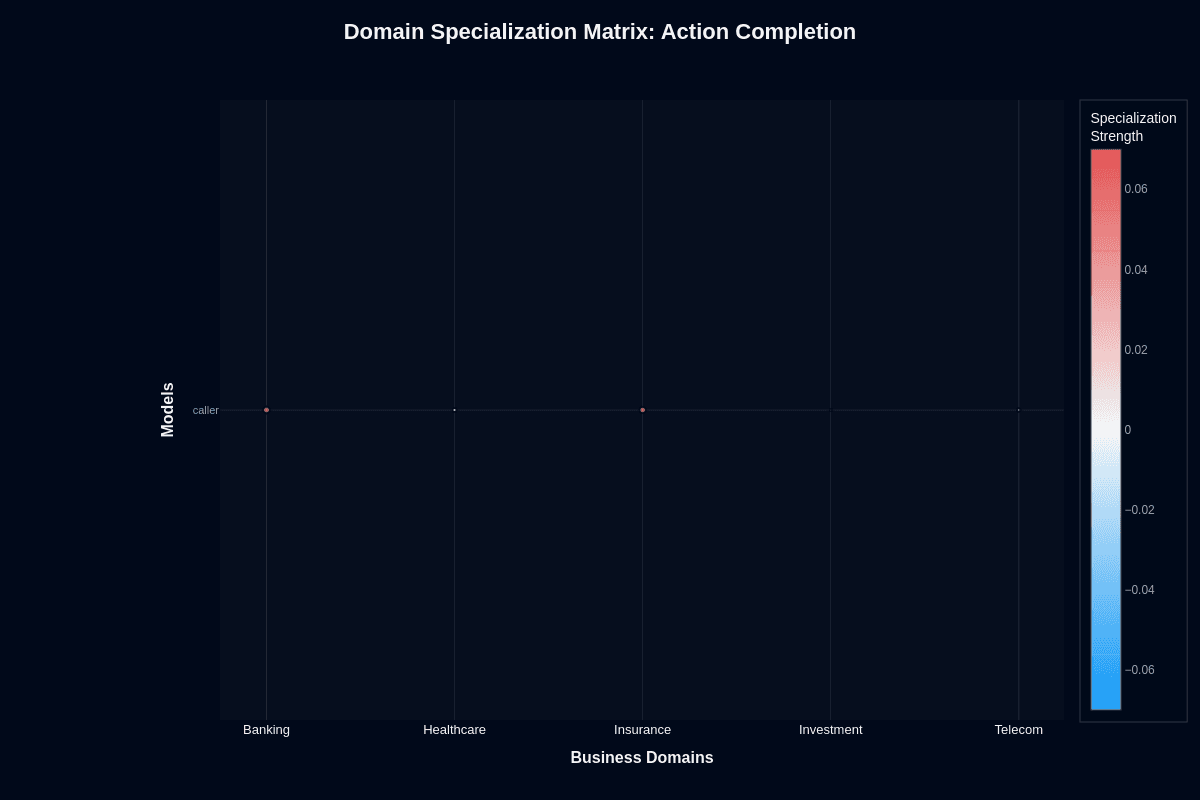
Switching Caller from generic workloads to banking-only tasks nudges the completion rate from 0.160 to roughly 0.200—a mere 4-percentage-point gain. Banking edges slightly above baseline (+0.03), with insurance trailing close behind (+0.02). Healthcare, investment, and telecom hover at neutral or slip below zero.
The entire spread across domains spans just four percentage points. Compare that to the 14-point chasm separating banking's 23% raw completion from investment's 9%. Specialized language models typically deliver 15–30% improvements over their baselines. Caller manages only 2–4 points, suggesting its limitations run deeper than training data tweaks.
This pattern exposes a fundamental issue. Your choice of domain simply doesn't unlock meaningful performance gains. Your safest approach treats domain specialization as irrelevant—Caller's reliability problems transcend vertical-specific optimization.
Tool selection quality
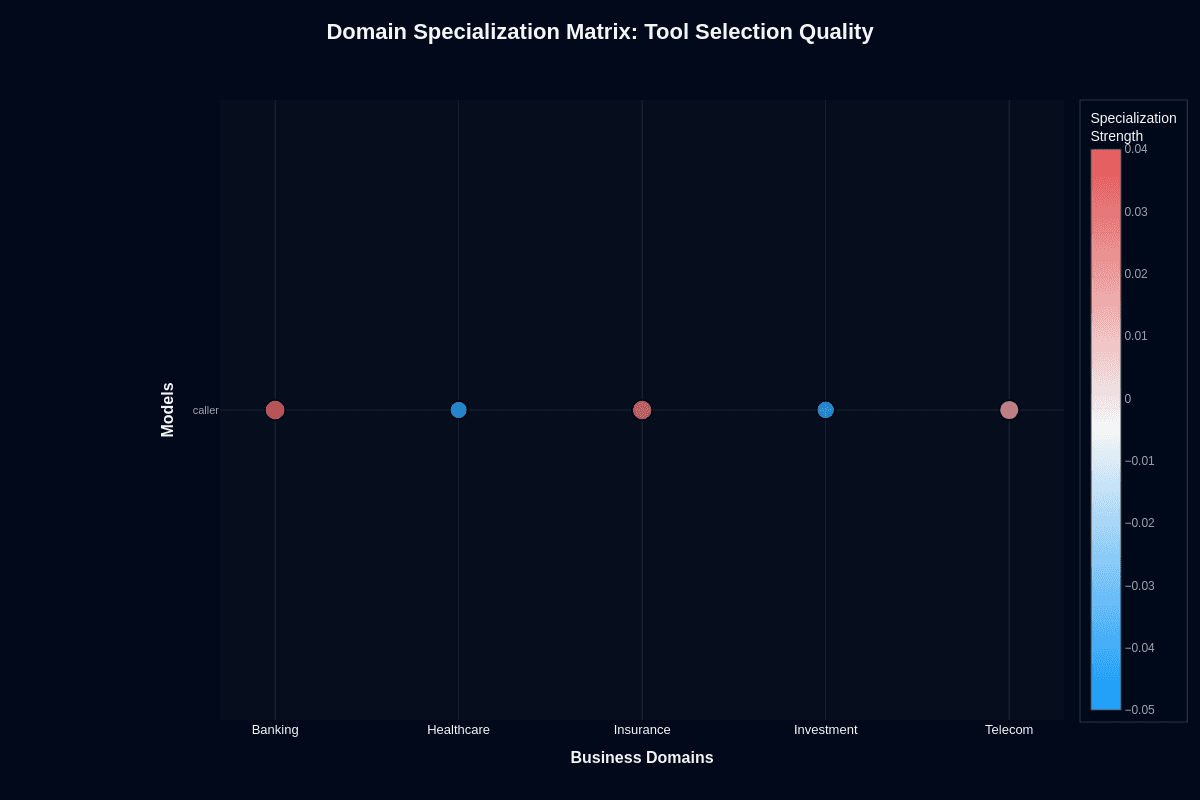
The picture brightens modestly when you examine API routing rather than complete task execution. Banking pops to +0.04 above the 0.650 baseline, telecom adds +0.02, and insurance manages +0.01.
Healthcare drops to -0.03 and investment falls to -0.02. This split makes architectural sense. Well-structured banking endpoints let Caller map user intents cleanly. Ambiguous healthcare terminology like "schedule" or "order" sends it down wrong paths.
The quality gap matters for your deployment strategy. Banking and telecom offer your best bet for tool routing, where Caller acts as a low-cost classifier. Layer validation gates over healthcare and investment flows—the negative specialization signals active harm in these domains.
Research shows correct API routing is necessary but insufficient. Execution still fails one-third of the time, which aligns with Caller's 65% overall tool accuracy. Your architecture should position Caller as a specialized router, not an autonomous executor.
Caller performance gap analysis by domain
The domain breakdown reveals deployment risks that uniform policies cannot address. Banking achieves a modest 0.23 median completion rate, while Investment collapses to 0.09. That 14-point spread creates vastly different failure patterns—and fundamentally changes your safeguard requirements.
Action completion
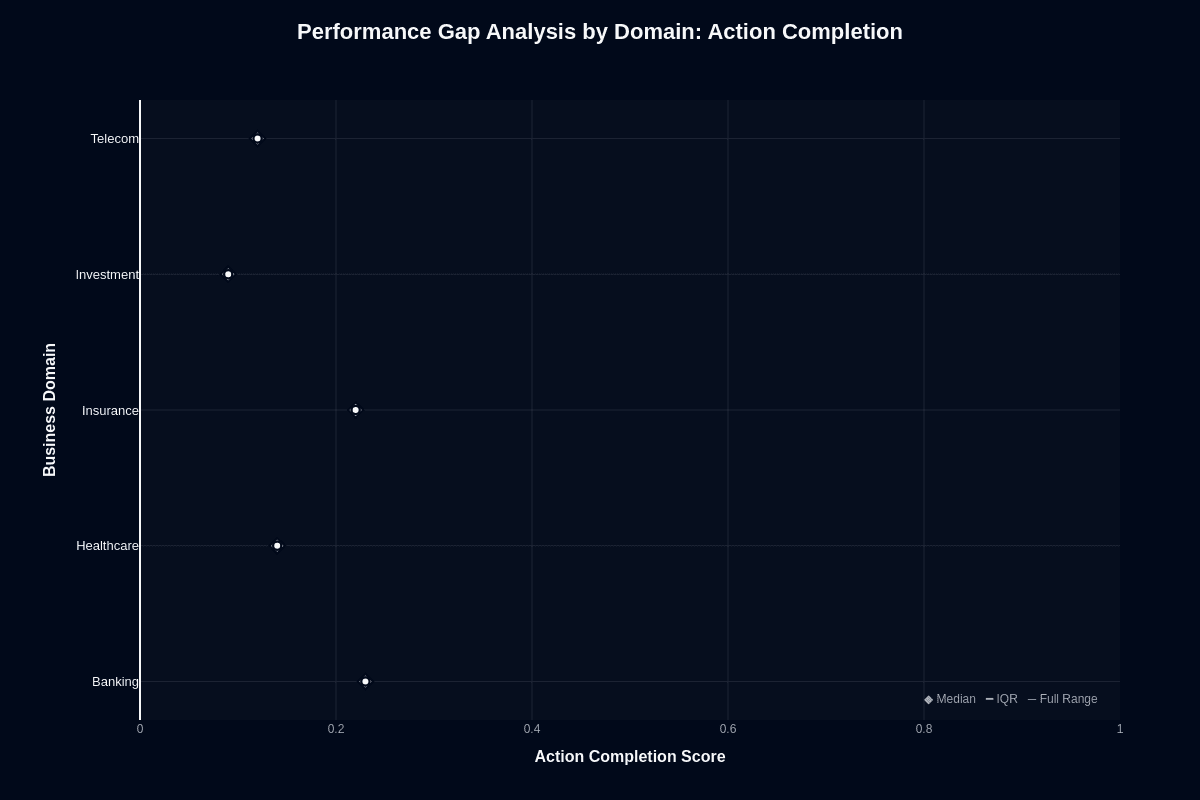
Banking teams might feel optimistic about 23% completion rates, yet this still means 77% task failure. Banking and Insurance cluster around 0.22-0.23 completion, while Healthcare and Telecom drop into the low teens. Investment misses nine out of ten requests entirely. If you deploy uniform policies across domains, you'll discover Investment queues drowning in retries and escalations.
Calculate your domain's failure cost—lost revenue, compliance exposure, customer churn. Multiply by Caller's expected 77-91% miss rate. Compare that against the $0.03 request savings. Human agents target under 5% abandonment and 70-80% first-call resolution. Even Banking falls short by about 3x to 3.5x compared with typical human first‑call resolution benchmarks.
Your architecture must assume near-continuous human backup. Investment becomes economically unviable. Banking marginally justifies deployment only with sophisticated validation layers catching three-quarters of failures before they reach your users.
Tool selection quality
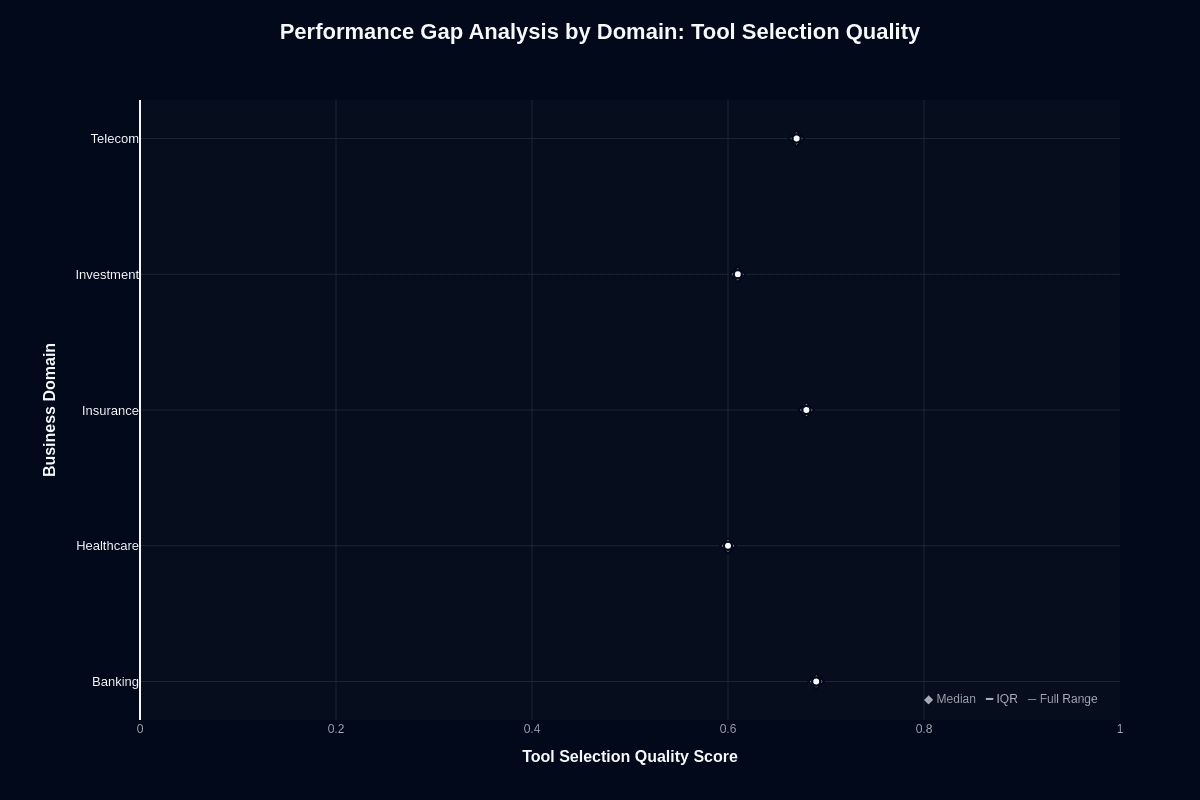
Here's the counterintuitive finding: Caller picks correct tools 67-77% of the time despite catastrophic execution failures. Banking and Insurance lead at 0.77, while Healthcare and Investment trail at 0.67. The model understands which endpoint to invoke—it just fumbles everything afterward.
This unlocks a specialist-orchestrator pattern. Position Caller as a lightning-fast router handing requests to capable executors once tools are chosen. You get 77% routing accuracy at $0.03 cost, then invoke specialized models for execution. Banking and Insurance deliver 77% routing success for pennies. Healthcare requires validation hooks catching one-third misrouted calls. Treat Caller as traffic control, not task completion. You contain risk while preserving its speed advantage.
Caller cost-performance efficiency
Model selection balances reliability against every dollar you spend. Caller occupies an unusual position on that efficiency curve, creating deployment decisions based on acceptable trade-offs rather than absolute performance.
Action completion
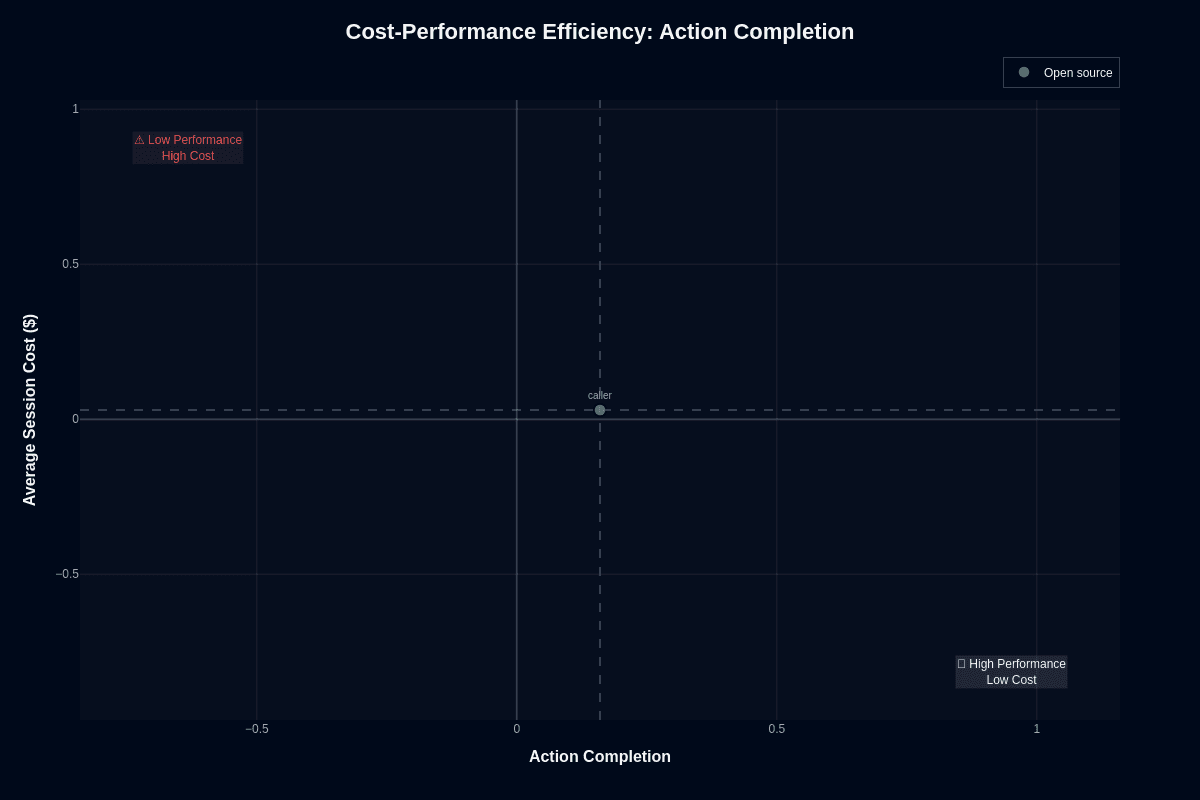
Exceptional cost meets terrible completion rates in Caller's value proposition. You pay $0.03 per request but finish tasks only one time in six. The math becomes brutal for workflows requiring first-attempt success. An 84% failure rate forces expensive fallbacks that erase savings. But three-cent calls open doors that pricier models slam shut. You can issue ten parallel attempts, add majority voting, or route failed outputs to humans without budget concerns.
Deploy Caller when your architecture includes retries, validation layers, or human review. Skip it when missed steps trigger compliance risk or customer churn.
Tool selection quality
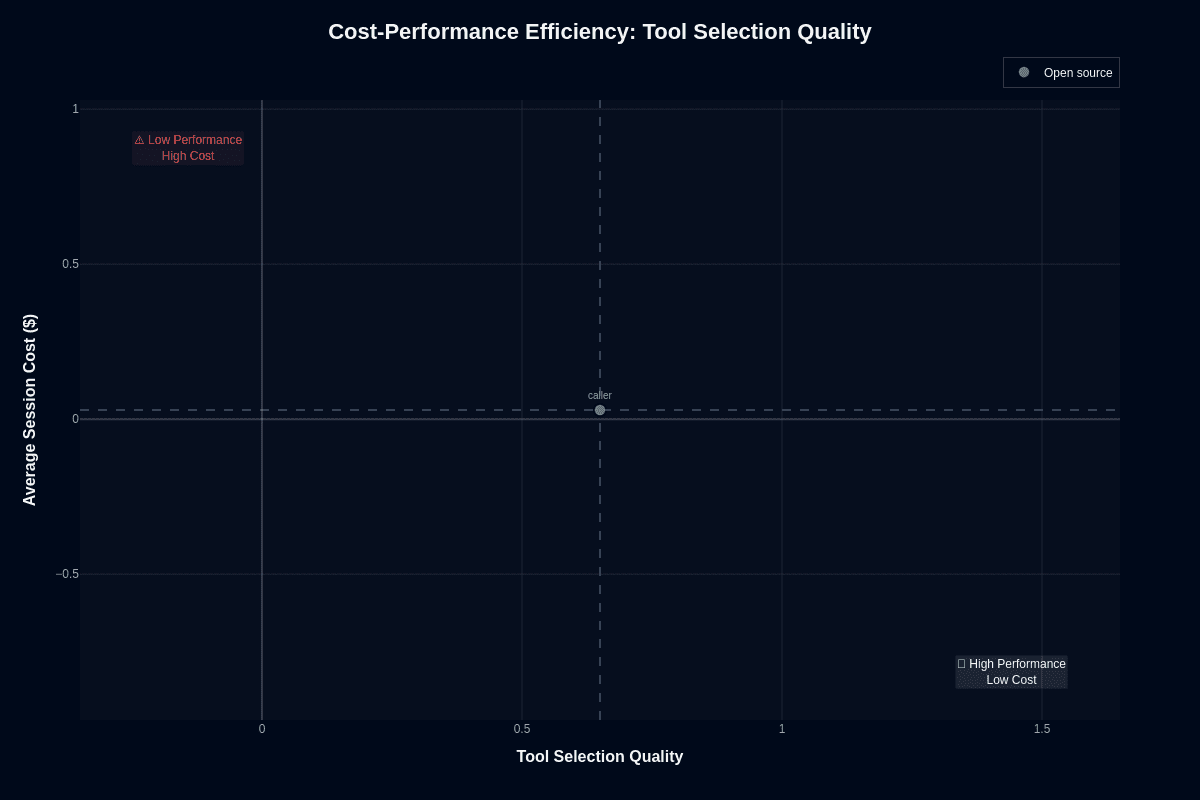
The efficiency equation shifts when you examine tool selection. Caller posts 0.65 accuracy—comfortably past the "better than chance" line—while keeping that $0.03 price tag. Those coordinates drop it squarely into the "high performance, low cost" quadrant.
You identify the right API almost two-thirds of the time for one-tenth frontier model costs. This efficiency matters when your agents fire dozens of tool calls per user session. Predictable spend lets you budget confidently instead of fearing runaway bills. Monitor for that remaining one-third error rate. Auto-recover when the model chooses poorly. Treat Caller as a fast, cheap switchboard—not the electrician who fixes the wiring.
Caller speed vs. accuracy
Model selection often hinges on response time versus correctness. Caller's benchmark numbers reveal a harsh trade-off: it replies in roughly 26 seconds—faster than most—but still fails to finish 84 percent of your tasks.
Action completion
Picture this scenario: you trigger Caller for a workflow, wait half a minute, and discover the task remains unresolved. With an action-completion score of 0.16 and an average duration of 25.7 seconds, Caller sits in the lower-right corner of the speed-accuracy scatter plot—fast enough to keep queues short, yet inaccurate enough to disappoint most users.
Caller's "quick miss" pattern creates a peculiar user experience—the wait time of a normal interaction but only one-fifth of the expected success rate. This profile works in low-stakes contexts like autocomplete or search previews where speed trumps correctness. Avoid it entirely when every attempt must land: fraud detection, emergency triage, or any scenario with no second chance.
Tool selection quality
Latency management becomes critical when your agent makes five or ten routing decisions per request. Caller's numbers shine here. It identifies the correct tool 65 percent of the time while maintaining sub-26-second turnaround, placing it near the "fast & accurate" quadrant for routing tasks. The math works: five sequential selections complete in about 130 seconds and cost roughly $0.15 total—orders of magnitude cheaper than premium models handling each decision.
This efficiency prevents your end-to-end response times from ballooning as your agent chain grows. The trade-off remains a one-in-three chance of choosing the wrong endpoint, requiring validation hooks. With proper guardrails, Caller delivers a sweet spot of speed and cost that lets your higher-accuracy models focus on execution rather than every branching choice.
Caller pricing and usage costs
Caller lacks public pricing documentation. Benchmark data shows an average of $0.03 per request—an all-in price covering input, output, and infrastructure overhead.
At this rate, a 1,000-word prompt with 500-word response costs three cents
Your agent could retry five times to overcome Caller's 16% completion rate, but the expected cost would be about $0.19 per successful interaction
Some expensive or very long/context-heavy calls on frontier models can cost around 10× more per call, but many typical short or medium calls are cheaper than $0.03 and do not reach a 10× premium
Caller uses tiered, usage-based pricing rather than a flat $0.03 fee per response, so your costs vary with minutes used, plan, and features.
Expecting 1 million monthly requests? Budget ~$30,000 for baseline inference
Add telephony and storage separately
Smart teams allocate 10-15% of their Caller budget toward evaluation infrastructure—this keeps your total cost predictable even as request volume spikes
Your $30,000 monthly inference budget should include $3,000-4,500 for monitoring and quality assurance tools that catch failures before they reach your users
Caller key capabilities and strengths
Caller delivers exceptional inference speed with a 0.95 speed score, placing it in the fastest 5% of benchmarked models at roughly 26 seconds per response.
That latency matters in production—quick turnarounds keep your users engaged and accelerate your debug cycles
The $0.03 per request pricing makes experimentation, A/B testing, and ensemble retries economically viable without triggering budget alarms
Caller identifies the correct tool 65% of the time—solid performance that slots it into the "high performance, low cost" quadrant for routing and classification
You can rely on it for upstream triage, deciding whether queries need billing endpoints or knowledge-base lookups before delegating execution to heavier models
Teams using quality-assurance tooling recognize this value—fewer misroutes translate directly into lower handle times downstream
Banking prompts nudge Caller above its baseline, hinting at pattern familiarity with account lookups and policy checks
Combined with sub-26-second responses, this makes Caller a natural fit for high-volume financial triage where milliseconds beat perfect reasoning
Caller limitations and weaknesses
The allure of Caller's 95th-percentile speed and rock-bottom price disappears once you examine outcomes.
The model completes only 16 percent of tasks—this 0.160 action-completion score translates to an 84 percent failure rate
Industry support teams aim for 70–80 percent first-call resolution—Caller's best effort lands less than one-quarter of the way to basic service expectations
Caller decides which tool to invoke correctly 65 percent of the time—one-third of its choices still hit the wrong API or pass malformed parameters
Every misfire cascades through your system—downstream services return errors, retries stack up, and user frustration mounts
Healthcare and investment scenarios worsen the picture—action completion plunges to 14 percent and 9 percent respectively
Tool-selection accuracy drifts below the 0.650 average in these domains, which carry steep regulatory and financial penalties
Unsupervised deployment becomes a gamble few leaders can stomach
Domain focus won't lift performance meaningfully:
Specialization variance tops out at four percentage points
Banking gains a marginal bump to 23 percent completion
Every other vertical hugs the dismal 0.160 baseline
You cannot tune away these gaps—they stem from fundamental model behavior: rapid single-pass reasoning that forgoes multi-step verification in favor of latency
The operational reality is clear:
Caller demands extensive scaffolding—validation layers, retry logic, human escalation, and continuous monitoring
This infrastructure exists solely to offset the 80-plus-percent failure rate
Without those guardrails, autonomous rollout jeopardizes customer trust and inflates support costs
Runtime observability platforms built for conversational AI become mandatory, not optional
You decide whether Caller's cost savings justify this architectural complexity
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.