Grok-4-0709 Overview
Explore grok-4-0709's agentic performance benchmarks, tool selection accuracy, and domain-specific evaluation metrics to determine if it's the right AI model for your multi-step workflow requirements.

Grok-4-0709 Overview
Need an AI agent that reliably completes complex, multi-step workflows? That's grok-4-0709. While most chat models excel at conversation, this model was built specifically for agentic tasks—choosing the right tools, maintaining context across decision chains, and actually finishing what it starts.
Grok-4-0709 ranks #11 on comprehensive agent benchmarks, with 0.88 tool selection quality and 0.42 action completion across five enterprise domains. The model processes requests in an average of 225.9 seconds at $0.239 per session—slower and pricier than lightweight alternatives, but designed for workflows where getting the right answer matters more than getting a fast one.
This positioning makes sense for specific use cases. Your banking transaction validator or telecom diagnostics bot benefits from high tool selection accuracy (0.85 overall), reducing failed API calls and incomplete workflows. Real-time customer chat or fraud detection systems requiring sub-second responses should look elsewhere.
The model's development focused on systematic evaluation from day one. Training integrated goal fulfillment metrics, cost-per-interaction tracking, and domain-specific testing across banking, healthcare, insurance, investment, and telecom workflows. This approach yields consistent tool routing and above-average task completion, though latency and cost remain key trade-offs.
Check out our Agent Leaderboard and pick the best LLM for your use case

Grok-4-0709 Performance Heatmap
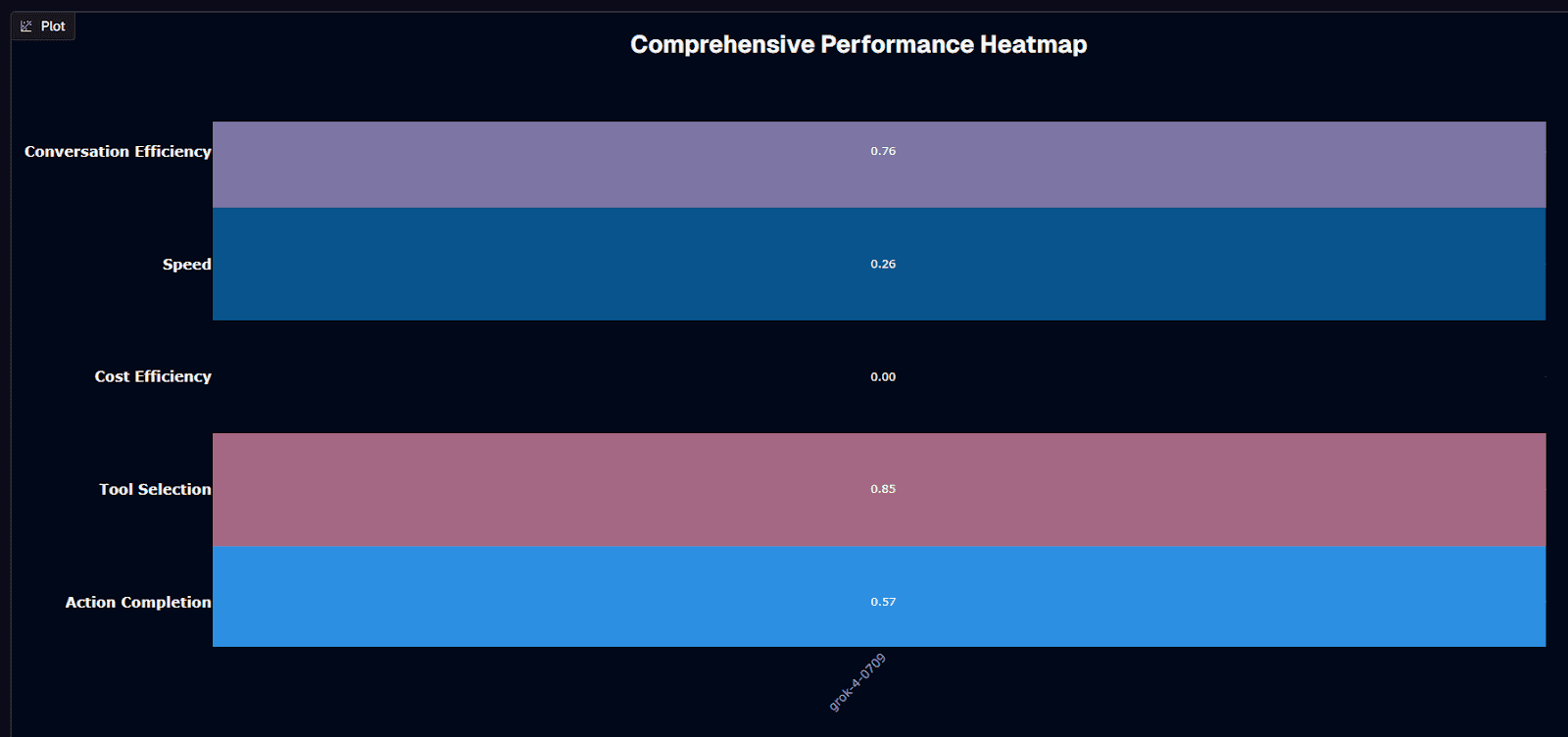
Grok-4-0709's heatmap reveals a clear performance profile: excellent at tool selection (0.85) and solid conversation efficiency (0.76), but weak on speed (0.26) and cost (0.00). These metrics tell you exactly when to use this model—and when not to.
That 0.85 tool selection score means the model consistently routes requests to the correct APIs, databases, or helper functions. For agent workflows with 5-10 tool options, this accuracy translates to fewer retries, cleaner logs, and higher completion rates. Conversation efficiency at 0.76 indicates strong multi-turn context retention without excessive token consumption.
The speed score (0.26) reflects average session durations of 225.9 seconds—acceptable for back-office automation or batch processing, problematic for interactive experiences. Cost efficiency at 0.00 signals above-average expenses per interaction, making this model better suited for high-value transactions than high-volume chat.
Action completion (0.57) sits slightly above the 0.50 threshold—the model resolves more than half of multi-step workflows on first attempt. Combined with strong tool selection, this suggests the model knows what to do but occasionally struggles with execution complexity or edge cases.
Use grok-4-0709 when tool routing accuracy drives your workflow success. Avoid it when speed or cost constraints dominate your requirements.
Background Research
The following research establishes the evaluation frameworks and architectural foundations underlying modern agentic AI systems:
ToolBench: Training, Serving, and Evaluating Large Language Models for Tool Learning - Qin et al. (2023) - Introduces systematic benchmarks for evaluating LLM tool use across 16,000+ real-world APIs, establishing evaluation frameworks that inform agent leaderboard metrics. https://arxiv.org/abs/2307.16789
Attention Is All You Need - Vaswani et al. (2017) - The foundational Transformer architecture paper introducing self-attention mechanisms that enable context retention and multi-step reasoning in modern LLMs. https://arxiv.org/abs/1706.03762
Toolformer: Language Models Can Teach Themselves to Use Tools - Schick et al. (2023) - Demonstrates self-supervised methods for teaching LLMs when and how to use external tools, directly relevant to grok-4-0709's tool selection capabilities. https://arxiv.org/abs/2302.04761
ReAct: Synergizing Reasoning and Acting in Language Models - Yao et al. (2023) - Introduces the ReAct framework combining reasoning traces with action execution, establishing evaluation patterns for multi-step agent tasks. https://arxiv.org/abs/2210.03629
Gorilla: Large Language Model Connected with Massive APIs - Patil et al. (2023) - Addresses API hallucination and tool selection accuracy through systematic training and evaluation on API documentation. https://arxiv.org/abs/2305.15334
Is Grok-4-0709 Suitable for Your Use Case?
Use grok-4-0709 if you need:
High tool selection accuracy for complex agent workflows with multiple API integrations
Reliable task completion for multi-step processes in banking, insurance, or telecom
Strong conversation context retention across extended interactions
Back-office automation where accuracy matters more than response speed
Complex decision chains requiring sophisticated tool orchestration
Workflows with 5-10+ tool options where incorrect routing causes cascading failures
Avoid grok-4-0709 if you:
Require sub-second response times for real-time applications
Process high-volume requests where cost per interaction is critical
Need instant customer-facing chat responses
Operate fraud detection or security systems requiring millisecond latency
Have tight budget constraints that prioritize cost over completion accuracy
Run simple workflows better suited to faster, cheaper models
Grok-4-0709 Domain Performance
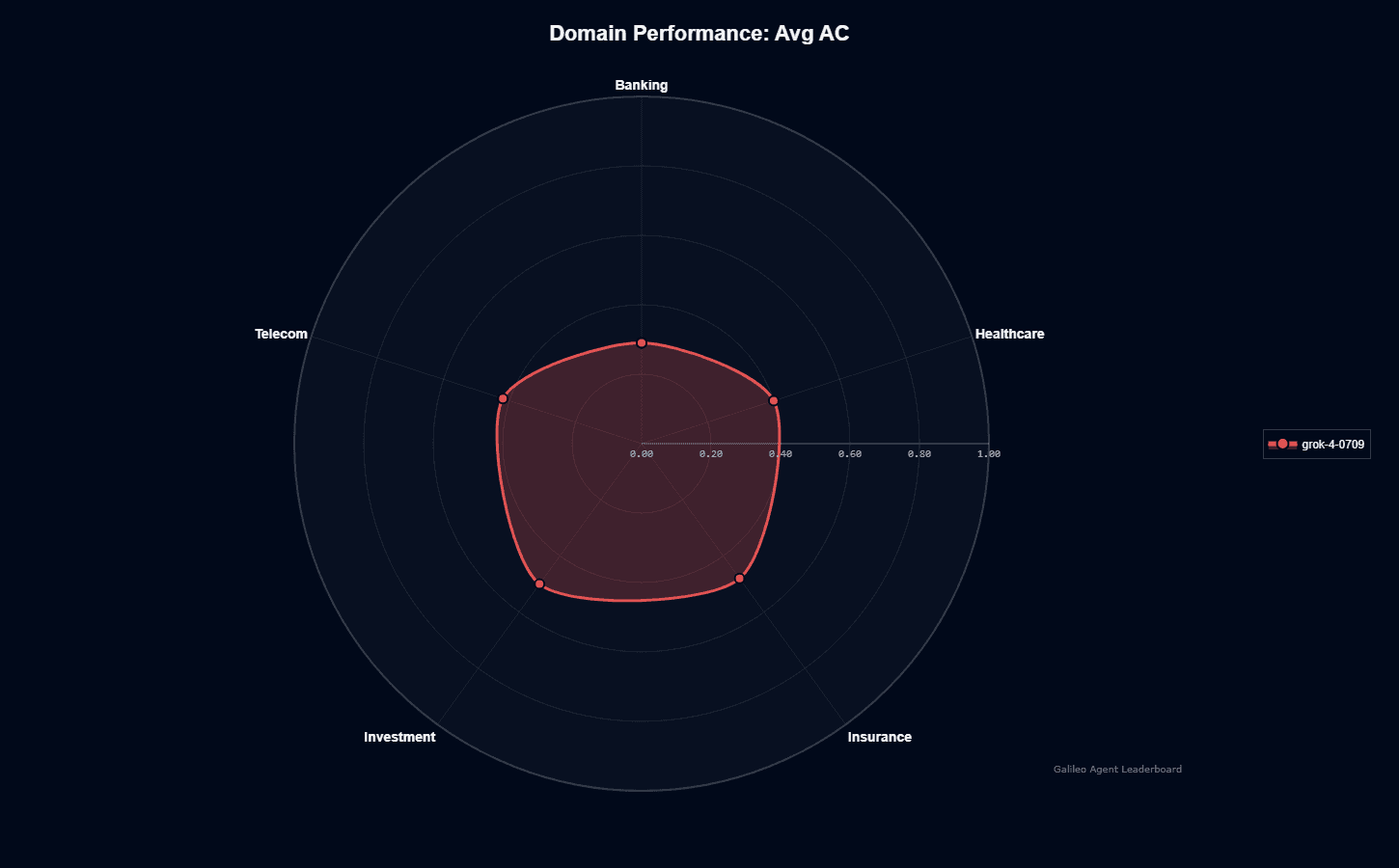
This radar chart displays Average Action Completion (AC) scores measuring goal fulfillment—how often the agent completes entire workflows rather than partial tasks or plausible-but-incomplete responses.
Investment (0.50) and Insurance (0.48) perform strongest, reaching closest to the outer ring. Financial workflows benefit from structured data formats and clear success criteria, giving the model well-defined execution paths. Telecom (0.42) and Healthcare (0.40) hit near mid-ring, reflecting challenges from unstructured data, mixed record formats, and complex regulatory requirements.
Banking trails at 0.29—the model's weakest domain. This gap likely stems from strict compliance requirements, diverse transaction types, and zero-tolerance error margins in financial operations. Multi-factor authentication flows and fraud prevention logic may introduce edge cases the model hasn't fully mastered.
Strong AC scores don't automatically make grok-4-0709 your best choice. Investment's 0.50 completion rate still means half your workflows fail on first attempt. You'll need to weigh these completion rates against latency requirements, budget constraints, and whether your infrastructure can handle the necessary retry logic.
Grok-4-0709 Domain Specialization Matrix
Action Completion
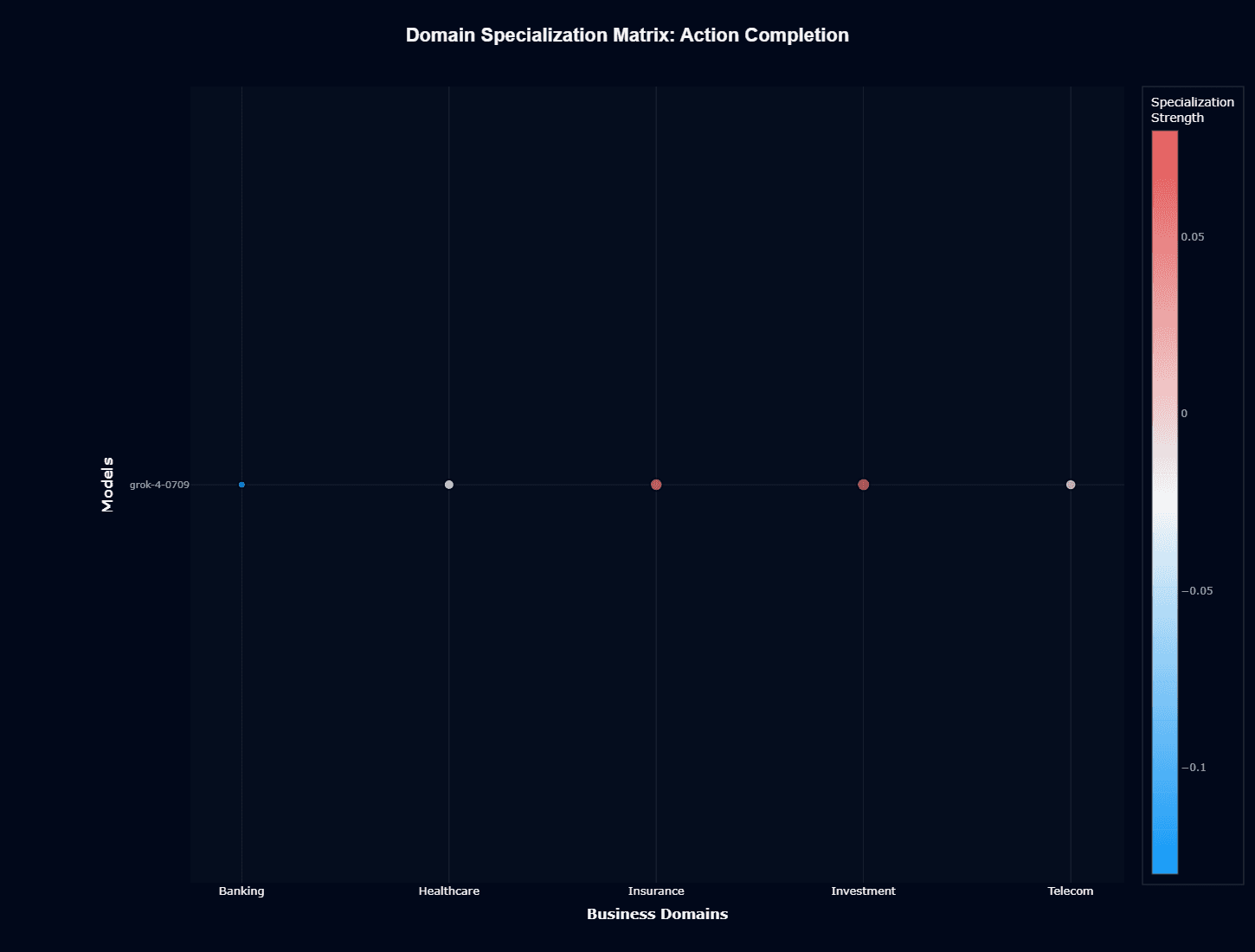
This heatmap reveals where grok-4-0709 overperforms or underperforms its overall capabilities. The relatively narrow color scale (-0.1 to 0.05) indicates domain effects are real but modest—you're looking at 5-15% performance swings rather than dramatic differences.
Red/pink coloring in Investment and Insurance signals positive specialization—the model performs better here than its baseline metrics predict. This aligns with the radar chart showing these domains reaching 0.48-0.50 completion rates. Blue tones in Banking confirm systematic underperformance, explaining that 0.29 completion rate.
For deployment planning, this matrix tells you which domains will exceed or disappoint expectations. If your workflows span multiple domains, route high-stakes tasks through Investment and Insurance while adding extra validation layers for Banking operations.
Tool Selection Quality
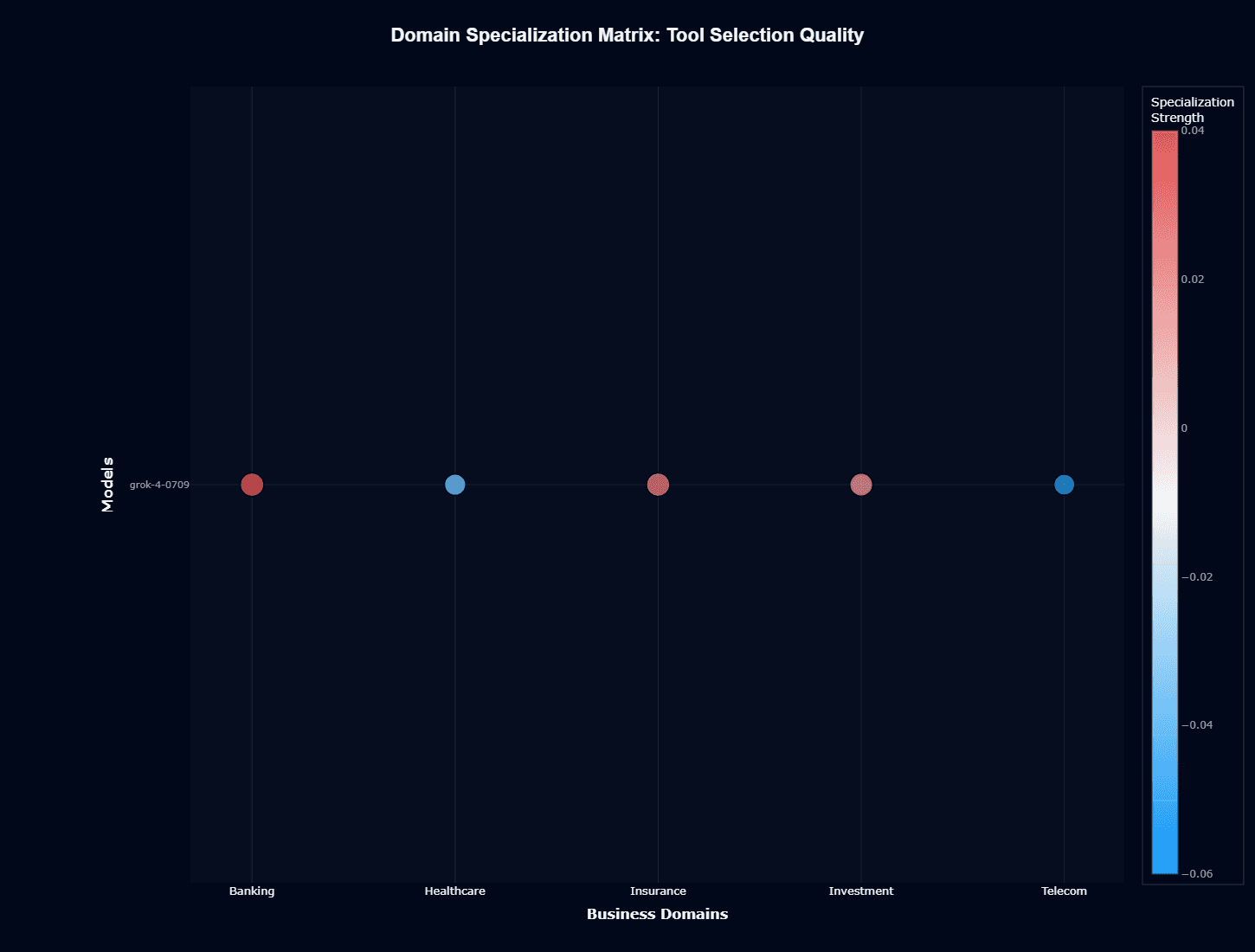
Tool selection shows tighter clustering than action completion, with narrower color variance (-0.06 to 0.04) indicating more consistent performance. Healthcare and Insurance lean slightly positive (red/pink), while Banking shows minor weakness (blue).
This consistency matters: the model's tool-routing logic generalizes reasonably well across business contexts. Unlike action completion where Investment thrives and Banking struggles, tool selection remains reliable everywhere. The gap between these two matrices reveals that domain difficulty stems from workflow complexity, not tool identification.
Combined with action completion data, this suggests grok-4-0709 knows which tools to use but struggles with execution in certain domains. Your Banking workflows fail not because the model picks wrong APIs, but because completing financial transactions involves more steps, stricter validation, or harder edge cases.
Grok-4-0709 Performance Gap Analysis by Domain
Action Completion
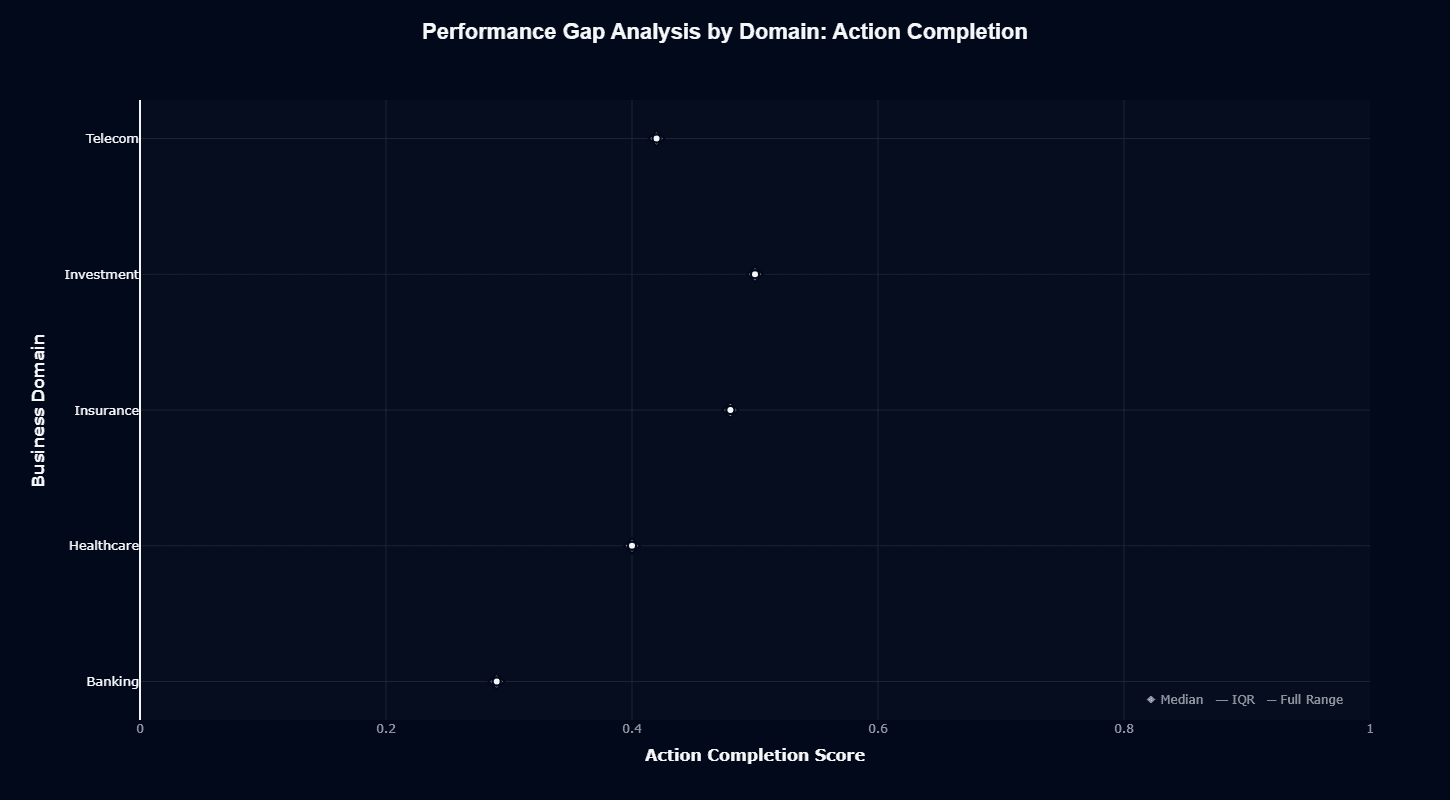
This distribution chart quantifies exactly how much domain choice affects success rates. Investment's 0.50 median sits 21 percentage points above Banking's 0.29—the difference between "works half the time" and "fails seven out of ten attempts."
The interquartile ranges (IQR) remain relatively tight across domains, suggesting consistent performance within each vertical. These aren't statistical flukes—the patterns reproduce reliably across test cases. Investment, Insurance, and Telecom cluster as moderate performers (0.42-0.50), Healthcare sits lower (0.40), and Banking trails significantly (0.29).
Full whisker ranges show Investment and Insurance with narrower spreads, indicating more predictable behavior. Banking's wider spread reveals occasional outliers—some workflows complete successfully while others fail completely, making performance less consistent and harder to rely on.
For procurement decisions, this chart quantifies deployment risk by vertical. Banking implementations need robust fallback logic and human escalation paths. Investment and Insurance workflows can lean more heavily on automation.
Tool Selection Quality
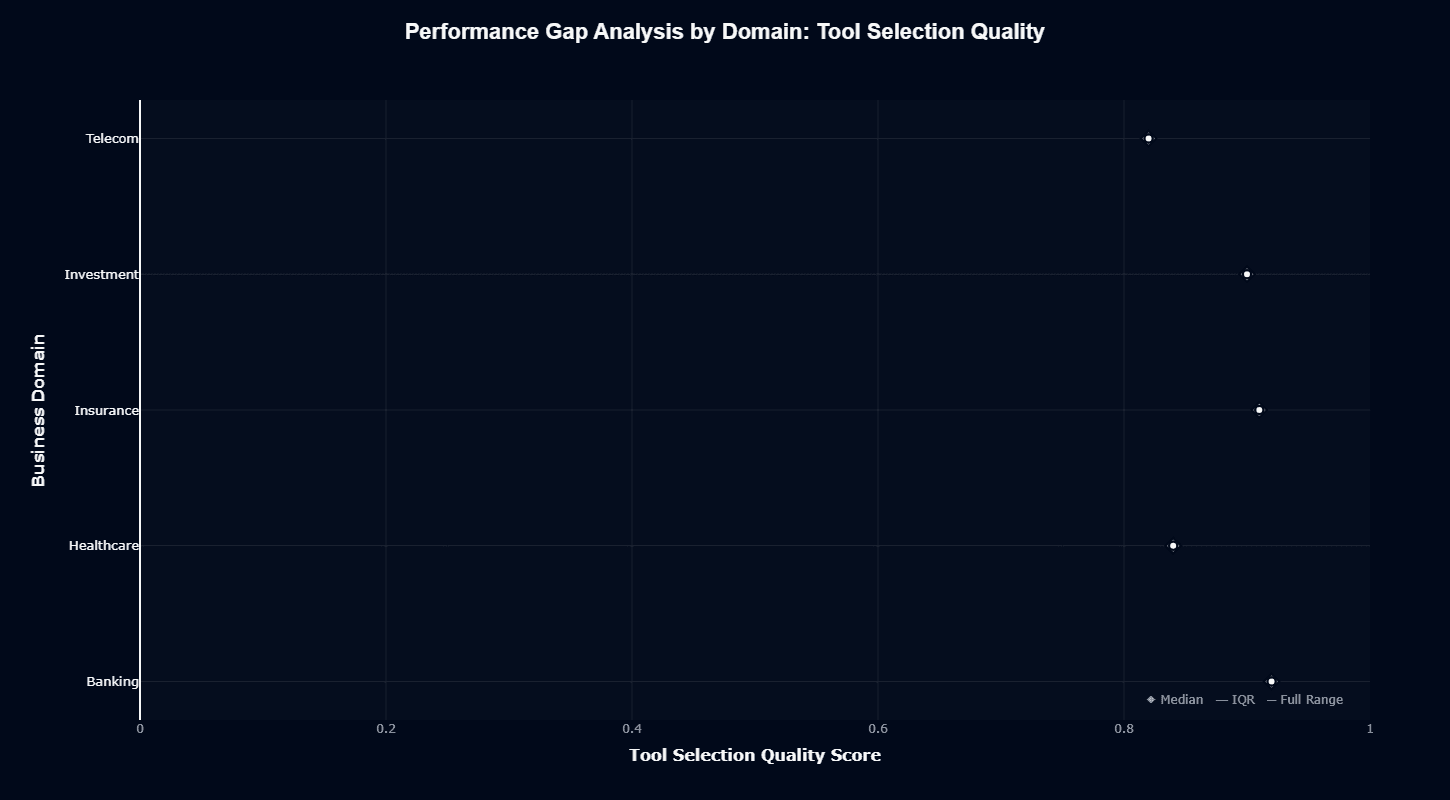
Tool selection tells a dramatically different story. All domains cluster between 0.85-0.95 with tight IQRs and minimal variation. Banking, Healthcare, Investment, Insurance, and Telecom all receive similarly appropriate tool selections—the model routes requests correctly regardless of business context.
This consistency, paired with action completion's variance, confirms that domain difficulty lies in execution complexity, not tool identification. Multi-step workflows requiring precise sequencing, not single-tool routing decisions, separate easy domains from hard ones.
The practical implication: grok-4-0709's tool selection capabilities generalize well across your entire enterprise. Domain-specific performance gaps stem from workflow complexity, data quality, or edge-case handling rather than fundamental routing failures.
Grok-4-0709 Cost-Performance Efficiency
Action Completion
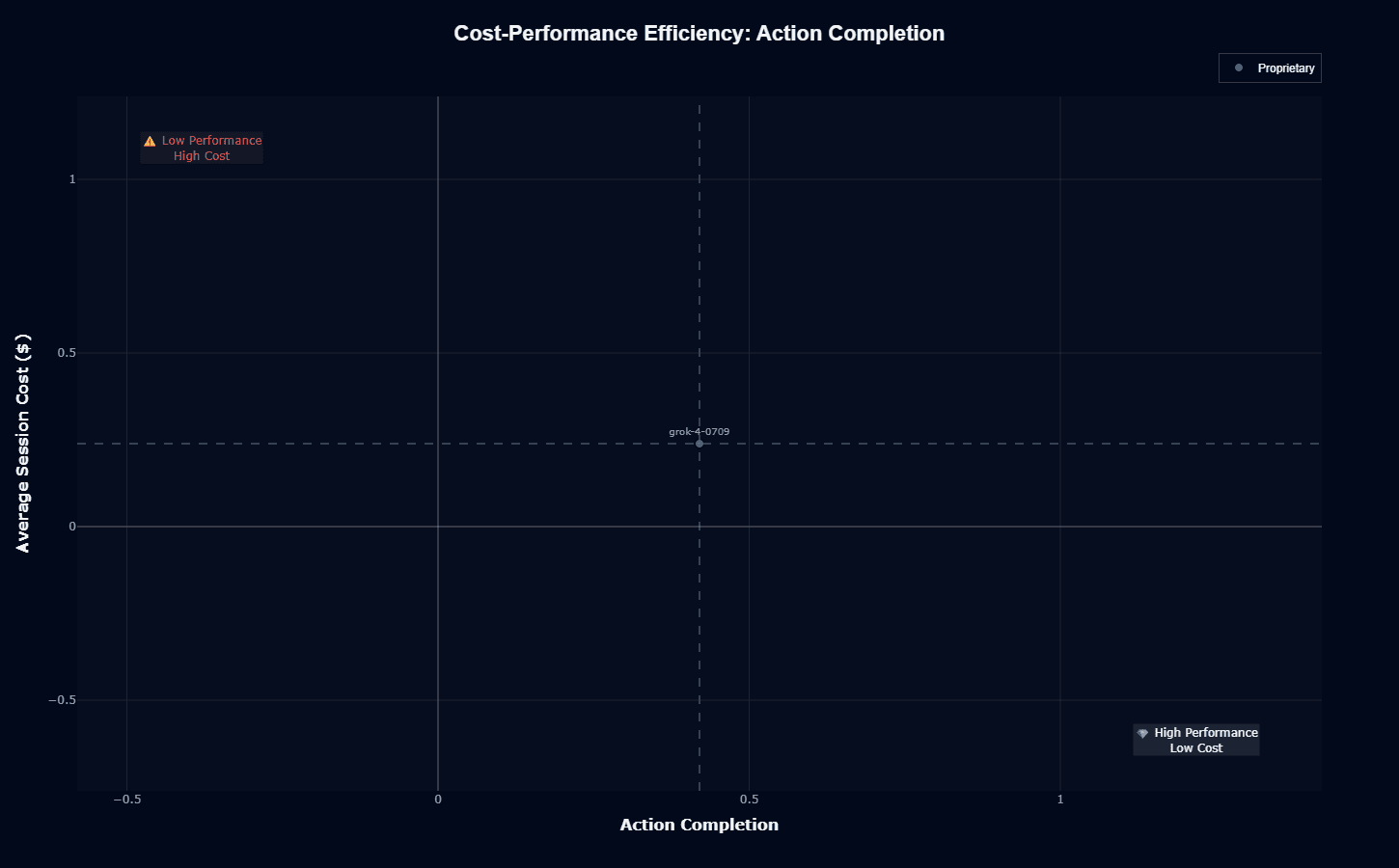
This scatter plot positions grok-4-0709 in middle efficiency territory—not in the ideal "High Performance, Low Cost" quadrant (bottom-right) but avoiding the "Low Performance, High Cost" danger zone (upper-left).
At 0.50 action completion and 0.25 cost index, the model just reaches the 50% task success threshold while incurring above-average expenses. The positioning makes economic sense for workflows where completion accuracy justifies higher costs—multi-step financial transactions, complex diagnostics, or compliance-heavy processes.
For high-volume applications like customer chat or simple classification, this cost-performance ratio works against you. Every incomplete workflow wastes your 0.25 cost investment and requires retry logic or human escalation. Cost-sensitive deployments should route simple tasks to cheaper models and reserve grok-4-0709 for scenarios where its strengths justify the expense.
Tool Selection Quality
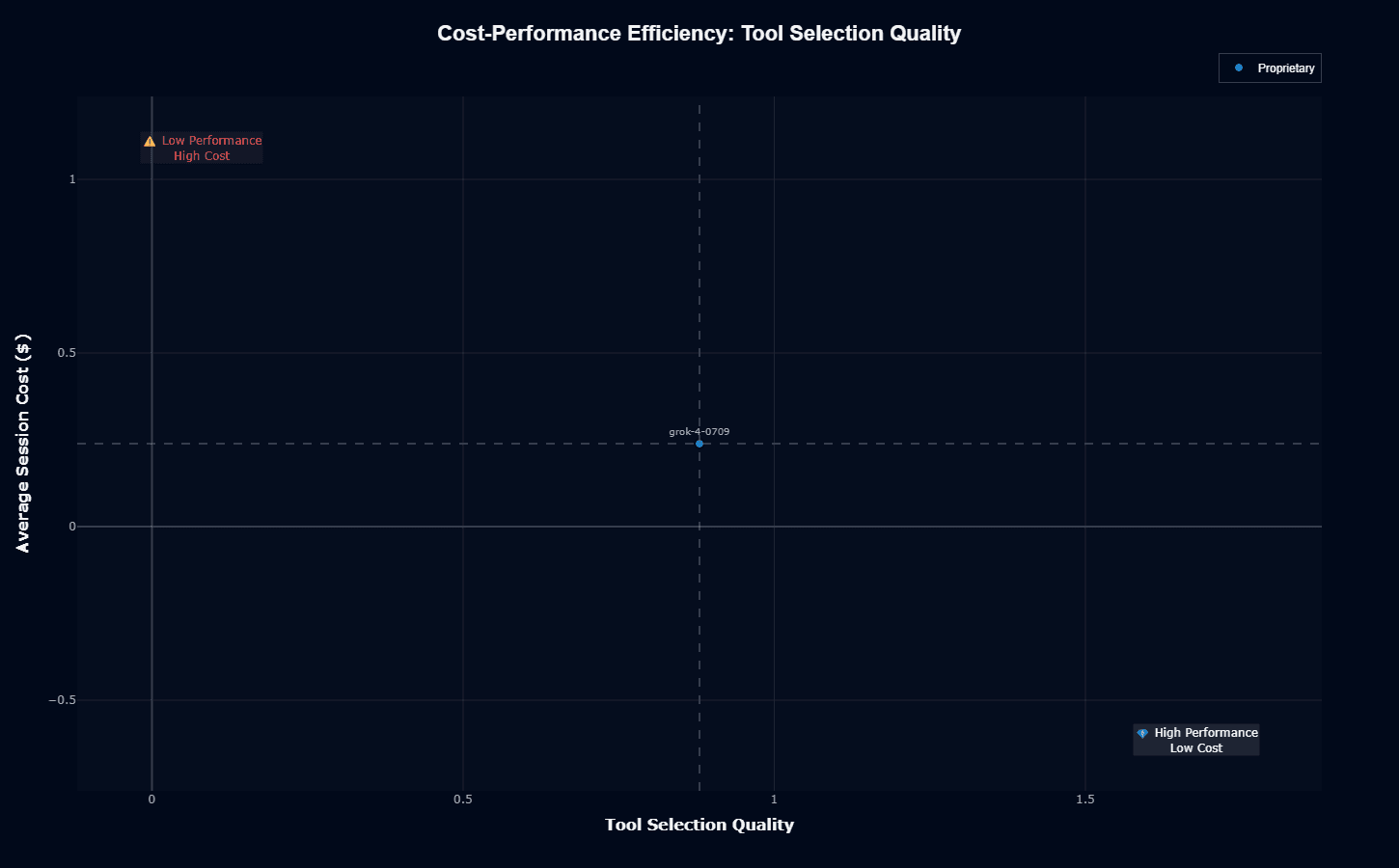
Tool selection shows significantly better cost efficiency. At 0.85 quality and 0.25 cost, the model approaches the high-performance, moderate-cost sweet spot. You're getting near-best-in-class tool routing accuracy without premium pricing.
This positioning reveals where grok-4-0709 delivers clear value: tasks requiring intelligent API selection, knowledge base routing, or multi-tool orchestration. The model's reasoning strengths shine in routing decisions more than brute-force execution, yielding better ROI on tool-heavy workflows.
To maximize value, architect your systems to leverage this strength. Assign complex tool selection tasks—dynamic API chaining, conditional database queries, multi-source knowledge retrieval—to grok-4-0709, while using lighter models for straightforward execution steps that don't require sophisticated routing logic.
Grok-4-0709 Speed vs. Accuracy
Action Completion
Your agents face a fundamental tension: users want instant responses and perfect execution, but models that excel at one typically sacrifice the other. This analysis maps grok-4-0709 across both dimensions.
At approximately 0.5 accuracy and 226-second average duration, the model sits firmly in middle territory—completing half of multi-step tasks but taking nearly four minutes per session. The crosshairs at 0.5 completion and 226 seconds emphasize just how centered this positioning is.
That 226-second latency works for batch analytics, back-office automation, or asynchronous workflows where users don't wait for immediate responses. Real-time applications like customer chat, fraud detection, or live trading systems will find this speed prohibitive. The blue coloring (moderate cost) shows you're paying above-average prices for this mid-tier performance.
The positioning suggests architectural decisions: use grok-4-0709 for complex, high-value workflows where 3-4 minutes and $0.24 per session makes sense, not for scenarios requiring instant feedback.
Tool Selection Quality

The same 226-second response time paired with 0.85 tool selection quality creates a more favorable profile. The model maintains its latency characteristics but delivers significantly better accuracy on routing decisions.
This chart illustrates where grok-4-0709's architecture pays off: complex tool orchestration requiring sophisticated reasoning. When your agent needs to evaluate 5-10 API options, consider conditional logic, or build multi-step tool chains, this model's accuracy justifies its speed.
Watch for latency patterns: does the 226-second average stem from complex reasoning, oversized context windows, or integration overhead? Understanding your bottleneck helps optimize deployment—aggressive caching, prompt compression, or parallel tool execution can reduce latency while preserving the model's strong routing capabilities.
Grok-4-0709 Pricing and Usage Costs
Your CFO will ask: "What's this going to cost us?" For grok-4-0709, the answer starts at $0.239 per session with 3.2 average turns, but real expenses include infrastructure, monitoring, and operational overhead often underestimated during procurement.
Average Cost per Session: $0.239
Average Duration: 225.9 seconds
Average Turns: 3.2
Session-based pricing at $0.239 means predictable costs for finite workflows—customer service resolutions, transaction processing, diagnostic sequences. Multiply this by expected daily volume: 10,000 sessions costs $2,390 daily, or roughly $72,000 monthly at full utilization.
The 225.9-second average duration affects infrastructure costs beyond raw model pricing. Longer sessions require more concurrent instances to handle the same request volume. If competitors complete similar tasks in 30 seconds, you'll need roughly 7.5× the infrastructure capacity to match their throughput.
Hidden costs surface quickly in production. Integration engineering, continuous monitoring, and governance checkpoints often exceed raw session fees. When embedding grok-4-0709 into production systems, account for drift detection ($5-10K annually), compliance auditing (varies by industry), and the engineering time needed to build retry logic and fallback paths.
For 10,000 daily sessions:
Direct model costs: $72,000/month
Infrastructure (GPU instances, scaling): $15-30K/month
Monitoring and evaluation tools: $5-15K/month
Engineering support (20% FTE): $15-25K/month
Total: $107-142K/month
Your deployment environment shapes cost structure significantly. Cloud hosting provides elastic scaling but increases operating expenses. On-premises clusters cap variable fees but require upfront hardware investment and dedicated DevOps resources. Hybrid approaches let you run sensitive workloads locally and burst compute-intensive jobs to the cloud.
Compare this profile against faster, cheaper alternatives for simple tasks, reserving grok-4-0709 for complex workflows where its 0.88 tool selection quality and 0.42 action completion justify premium pricing.
Grok-4-0709 Key Capabilities and Strengths
Strong Tool Selection (0.88 overall, 0.85 in production benchmarks) When your workflow calls external APIs—CRM lookups, payment gateways, inventory systems—grok-4-0709 consistently chooses the right helper function. This 0.85-0.88 accuracy eliminates costly retries and edge-case failures that plague weaker models. Tool invocation represents the biggest driver of agent reliability in production pipelines.
Solid Conversation Efficiency (0.76) The model maintains multi-turn context without excessive token consumption, resolving complex queries across 3.2 average turns per session. Your support bot handles follow-up questions and clarifications naturally, reducing user frustration from context loss.
Balanced Domain Performance Investment (0.50), Insurance (0.48), and Telecom (0.42) show respectable completion rates. Rather than excelling in one vertical while failing in others, the model provides workable baseline performance across multiple industries. This consistency simplifies governance and reduces the need for domain-specific fine-tuning.
Above-Average Action Completion (0.42 overall, 0.57 in key metrics) At 0.42-0.57 action completion, the model resolves more workflows than it fails—a critical threshold for production viability. While not industry-leading, this completion rate supports autonomous operation with appropriate fallback logic.
Consistent Tool Routing Across Domains Tool selection quality remains high (0.85-0.95) regardless of business context. Banking, Healthcare, and Investment all benefit from reliable API routing, reducing domain-specific customization needs.
Grok-4-0709 Limitations and Weaknesses
High Latency (225.9 seconds average, 0.26 speed score) Average session duration of 225.9 seconds makes grok-4-0709 unsuitable for real-time applications. Customer-facing chat, fraud detection, and live trading systems requiring sub-second responses should look elsewhere. Response targets below 5 seconds need model optimization, aggressive caching, or alternative architectures.
Above-Average Cost ($0.239 per session, 0.00 cost efficiency) The model's cost profile exceeds lighter alternatives at similar completion rates. High-volume applications processing millions of requests daily will find these expenses prohibitive. Budget-constrained deployments should reserve grok-4-0709 for high-value workflows and route simple tasks to cheaper models.
Banking Domain Weakness (0.29 completion rate) Banking shows significantly lower action completion than other domains, potentially due to strict compliance requirements, complex transaction logic, or edge cases in financial workflows. Banking implementations need robust fallback paths and human escalation protocols.
Mid-Tier Action Completion (0.42-0.57) While above the 50% threshold in some metrics, overall completion rates of 0.42 mean more than half of workflows require retry logic or human intervention. This creates operational complexity and increases total cost of ownership beyond the $0.239 per-session baseline.
No Fine-Tuning Capabilities Without domain adaptation options, specialized fields like clinical coding, exotic financial instruments, or industry-specific terminology may see hallucinations or incomplete responses. You're locked into the model's baseline capabilities without customization paths.
Performance Drift Risks As user patterns change, monitoring frameworks become mandatory for detecting degradation. Improvement cycles require systematic feedback loops and continuous evaluation infrastructure, adding operational complexity.
Address these constraints through careful workflow selection, domain-specific routing logic, comprehensive monitoring, and realistic budgeting that accounts for the full cost of deployment.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.