Qwen3 235B A22B Instruct 2507 Overview
Explore Qwen3 235B A22B Instruct 2507's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Qwen3 235B A22B Instruct 2507 Overview
When Alibaba released Qwen3 235B A22B Instruct 2507 on July 21, 2025, the open-source community gained a model that challenges a fundamental assumption in AI economics: that frontier performance requires premium pricing.
Qwen3 235B A22B Instruct 2507 ranks #6 overall in our agent leaderboard. This Apache 2.0 licensed model delivers specialized domain expertise that rivals or exceeds proprietary competitors, particularly in insurance workflows.
Our benchmark analysis reveals why Qwen3's insurance specialization, combined with exceptional conversation efficiency and zero licensing costs, makes it a compelling choice for specific enterprise deployments despite significant speed limitations.
Check out our Agent Leaderboard and pick the best LLM for your use case

Qwen3 235B A22B Instruct 2507 performance heatmap
Qwen3 235B A22B Instruct 2507 represents Alibaba's strategic pivot away from hybrid reasoning architectures toward specialized model variants.
Released as part of the broader Qwen3 family, this instruction-tuned version focuses exclusively on non-thinking mode, prioritizing speed of execution and instruction adherence over extended deliberative reasoning.
With a native 256,000 token context window and Apache 2.0 licensing, Qwen3 removes both technical and legal barriers that traditionally limited enterprise AI adoption.
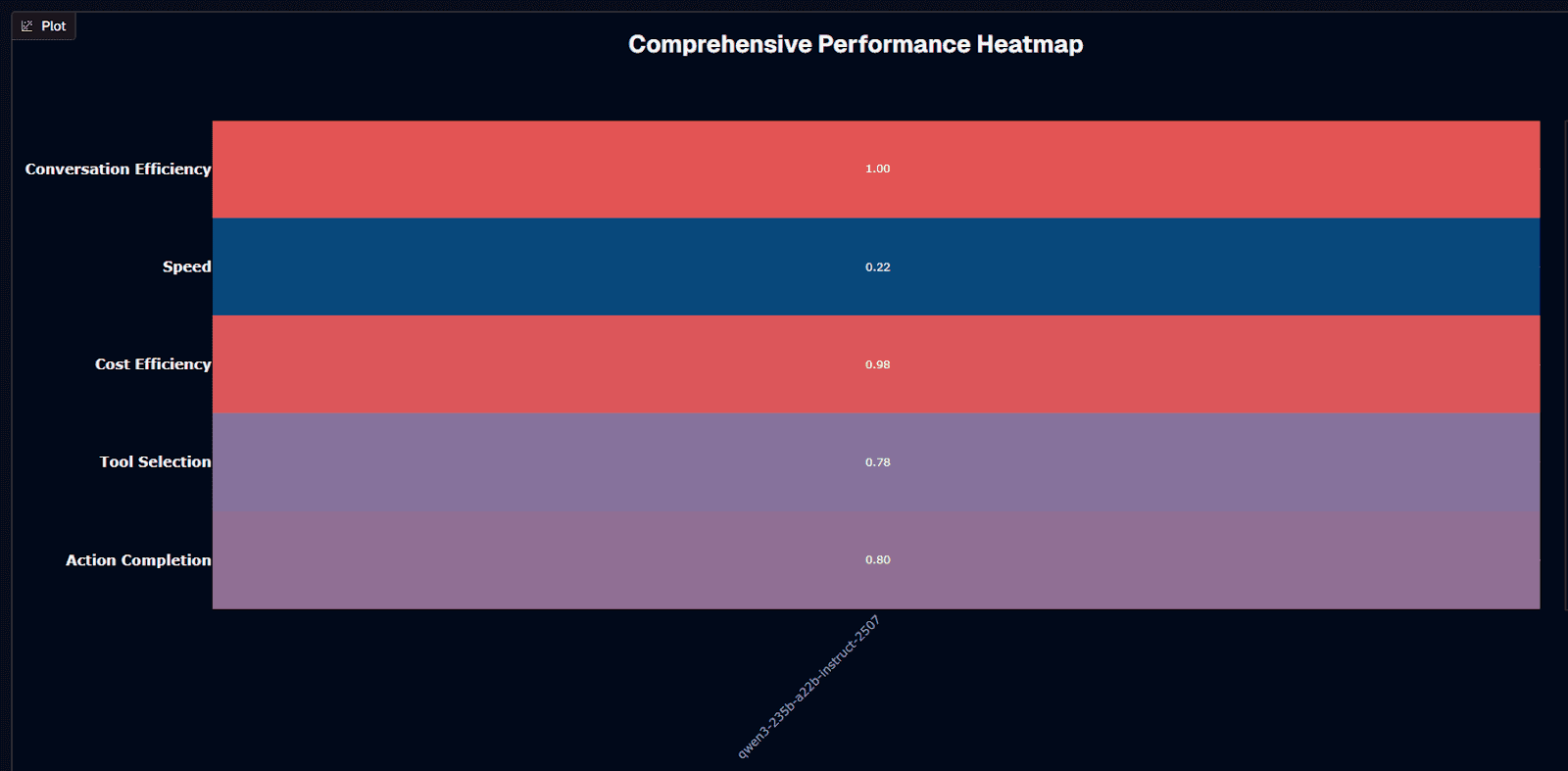
The comprehensive heatmap reveals Qwen3's true performance profile across five key dimensions:
Conversation efficiency leads at 1.00 (red/maximum), confirming Qwen3's exceptional ability to resolve your queries in fewer turns than competitors.
Cost efficiency scores 0.98 (red/near-maximum), reflecting the dramatic economic advantage of open-source licensing for your budget. Only infrastructure costs prevent a perfect 1.00 score, and even those costs diminish with optimization.
Action completion and tool selection occupy moderate-high territory at 0.80 and 0.78, respectively (purple), indicating solid but not exceptional performance. These scores aggregate across all domains, masking the Insurance specialization that drives higher performance in specific contexts you might work in.
Speed scores just 0.22 (blue/low), quantifying the severe latency penalty discussed throughout this analysis.
The heatmap tells a clear story: Qwen3 trades speed for conversation efficiency and cost, delivering reliable task completion at near-zero marginal cost but requiring your patience. If your organization can accommodate latency, you gain exceptional economic efficiency and strong domain performance in specialized areas.
Background research
The model employs a Mixture-of-Experts (MoE) architecture with 235 billion total parameters but activates only 22 billion per inference, dramatically reducing computational requirements while maintaining competitive capability.
Qwen3's development builds on several key innovations and strategic decisions:
Abandonment of hybrid reasoning: Alibaba explicitly moved away from unified thinking/non-thinking models, opting instead for separate specialized variants to "achieve the best possible quality" in each mode
MoE architecture optimization: The 235B-A22B configuration (235 billion total parameters, 22 billion activated) represents 94 layers with 128 experts, routing 8 per token, balancing capability with inference efficiency
Ultra-long context: Native support for 262,144 tokens through Dual Chunk Attention (DCA) enables processing of extensive documentation and sustained agent sessions
Apache 2.0 licensing: Open-weight release with permissive licensing eliminates usage fees and vendor lock-in, fundamentally changing deployment economics
FP8 quantization: Official FP8 variant reduces memory footprint from ~470GB to ~250GB, making deployment accessible to smaller organizations with high-end consumer hardware
Is Qwen3 235B A22B Instruct 2507 suitable for your use case?
Use Qwen3 235B if you need:
Insurance domain expertise: With 0.740 action completion, Qwen3 substantially outperforms competitors in insurance workflows, demonstrating a deep understanding of policy processing, claims assessment, and compliance requirements
Zero licensing costs: At $0.007 per session with no API fees or usage limits, the model enables you to experiment and deploy without limits at fixed infrastructure costs
Exceptional conversation efficiency: Averaging 2.4 turns per session, Qwen3 resolves your queries with fewer back-and-forth exchanges than competitors, reducing total interaction time despite slower individual responses
Strong investment tool selection: Despite weak investment domain action completion, Qwen3 achieves 0.96 tool selection accuracy, excelling at identifying appropriate financial APIs and functions
Long-context processing: Native 256K token support handles your extensive documentation, long conversation histories, and multi-document analysis without external memory systems
On-premise deployment flexibility: Open-source licensing permits internal hosting, custom modifications, and integration into your proprietary systems without vendor approval
Avoid Qwen3 235B if you:
Require fast response times: At 238 seconds average duration, Qwen3 ranks among the slowest models tested, unsuitable for your latency-sensitive applications or real-time user interactions
Work primarily in investment or banking: Action completion scores of 0.410 and 0.440 respectively, indicate insufficient domain knowledge for reliable autonomous operation in these sectors
Need consistently high action completion: The 0.530 overall score trails competitors, potentially requiring you to add validation layers or human oversight for mission-critical workflows
Depend on commercial support: Open-source models lack the vendor SLAs, guaranteed uptime, and technical support contracts that your enterprise deployments often require
Prioritize bleeding-edge reasoning: As a non-thinking variant, Qwen3 lacks the extended deliberation capabilities found in reasoning-specialized models
Qwen3 235B A22B Instruct 2507 domain performance
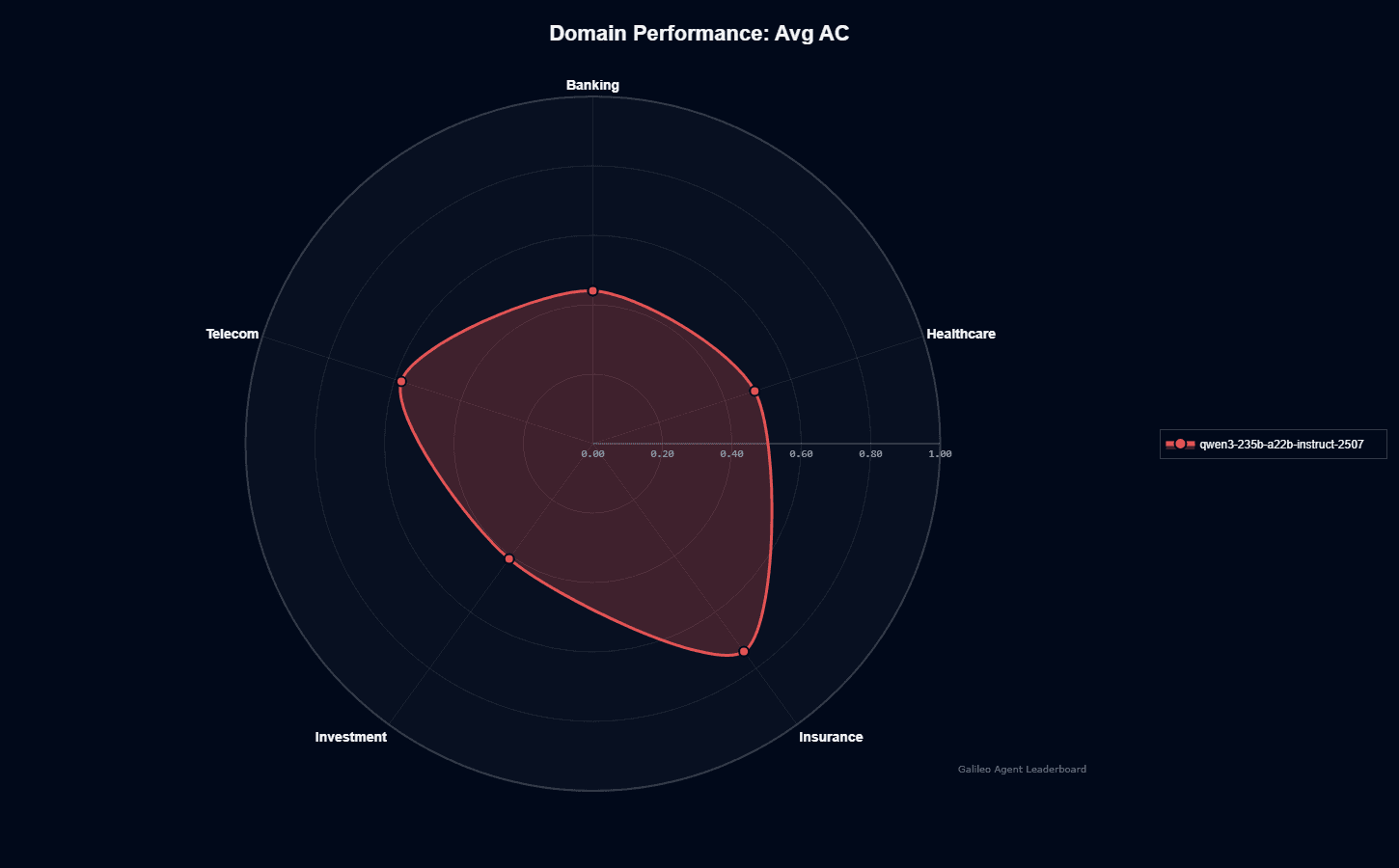
Qwen3 demonstrates highly uneven domain performance, with Insurance achieving 0.740—dramatically outperforming all other sectors. This creates a distinctive pentagonal shape with one pronounced vertex, rather than the balanced profile typical of general-purpose models.
Telecom follows at 0.580, then Healthcare at 0.490, Banking at 0.440, and Investment at 0.410. The 330-basis-point spread between the highest and lowest domains is the widest variance in our benchmark set, suggesting training data heavily weighted toward insurance use cases and terminology.
This specialization pattern indicates Qwen3 excels when deployed within its strength domains but struggles when asked to operate outside them. When evaluating the model, you should carefully assess whether your primary use cases align with Insurance or Telecom applications, where Qwen3's performance justifies adoption.
For Banking, Healthcare, and Investment applications, you'll need additional context, RAG systems, or fine-tuning to achieve production-ready reliability.
Qwen3 235B A22B Instruct 2507 domain specialization matrix
Action completion
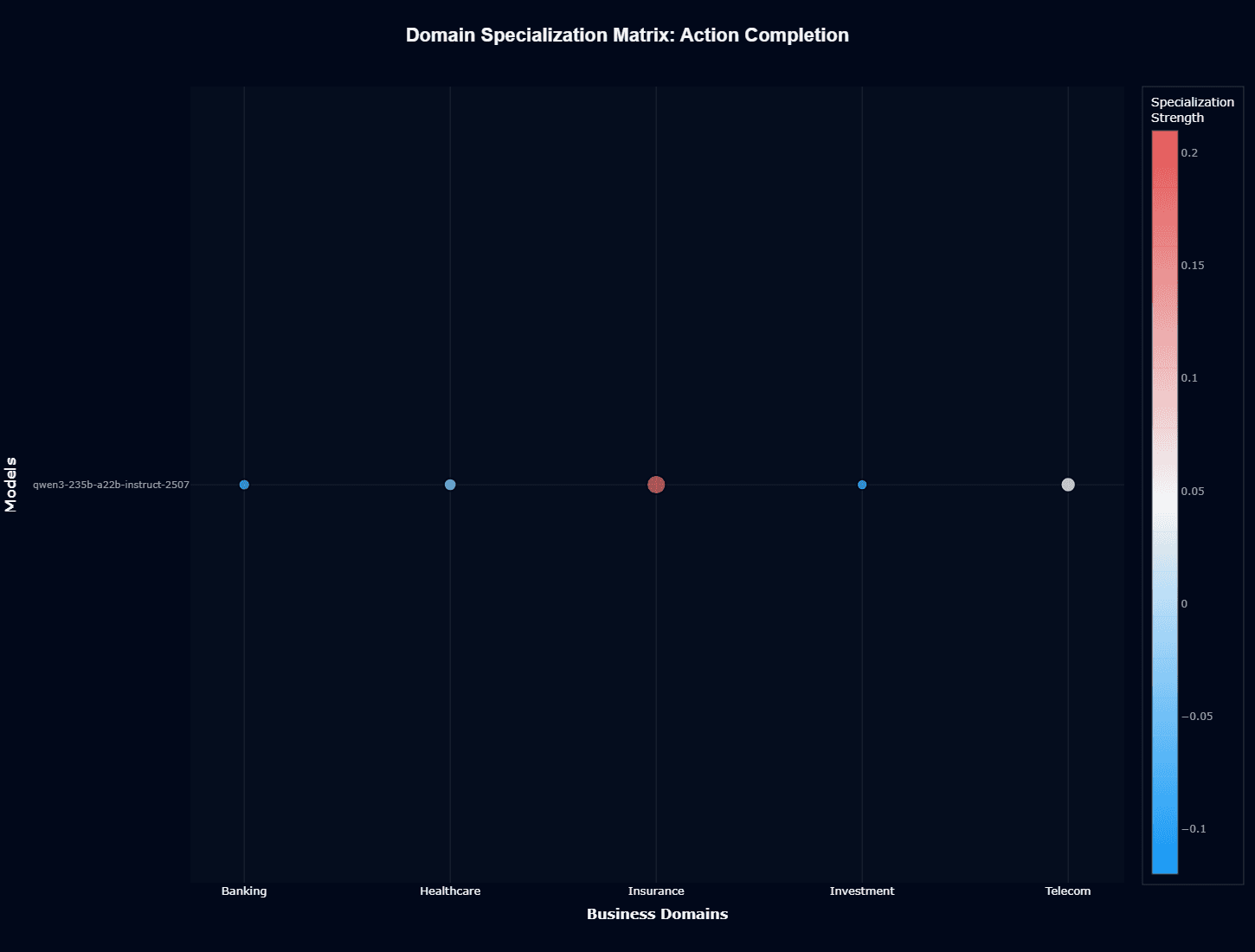
The domain specialization matrix reveals Insurance as Qwen3's defining strength, showing strong positive specialization (red/warm color) that indicates the model performs substantially above its baseline when handling insurance-related tasks.
This represents a fundamental capability difference driven by specialized training data or fine-tuning.
Banking, Healthcare, and Investment all display negative specialization (blue/cool colors), indicating the model underperforms relative to expectations when operating in these domains. Investment shows particularly strong negative bias, suggesting minimal exposure to financial analysis, portfolio management, or securities terminology during training.
Telecom occupies near-neutral territory, suggesting adequate but unremarkable performance. The model understands telecom concepts sufficiently to complete basic tasks, but lacks the specialized knowledge that elevates Insurance performance.
This extreme specialization creates clear guidance for your deployment: If you work in insurance, you can confidently build autonomous agents on Qwen3, leveraging the model's native strength without extensive prompt engineering.
The Insurance specialization likely stems from Alibaba's strategic priorities or training data availability.
Chinese insurance market documentation, regulatory texts, and operational procedures may have featured prominently in pre-training, creating advantages that generalize to global insurance workflows through shared terminology and process structures.
Tool selection quality
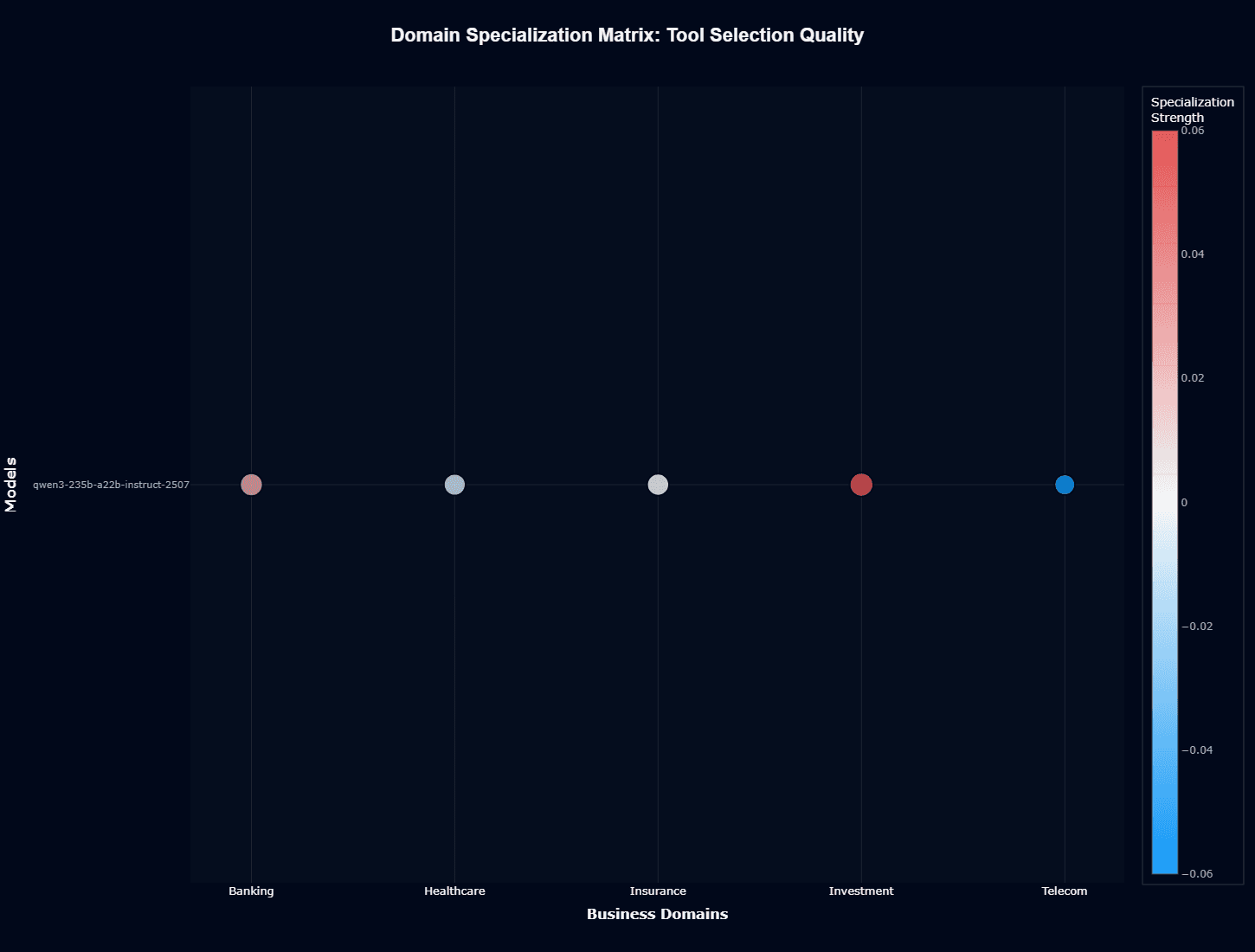
Tool selection specialization tells a different story from action completion.
Investment demonstrates positive specialization (red/warm), indicating Qwen3 excels at identifying correct financial tools and APIs despite struggling with investment domain concepts. Banking shows slight positive specialization, suggesting good technical API navigation capabilities.
Healthcare and Insurance occupy neutral territory for tool selection, while Telecom displays negative specialization (blue/cool). This inversion—Telecom performs well on action completion but struggles with tool selection—reveals an important nuance about the model's capabilities.
The pattern suggests Qwen3 understands investment and banking technical ecosystems—API structures, function signatures, parameter requirements—better than domain concepts. The model can correctly select portfolio analysis tools or trading execution APIs, but may provide incorrect inputs or misinterpret results due to weak domain knowledge.
This creates a specific failure mode: agents invoke the right functions but with subtly incorrect parameters or context.
For your development team, this means Investment and Banking implementations should implement a robust tool call validation focused on parameter correctness rather than selection accuracy.
Your telecom systems need the opposite—wrapper functions that normalize tool interfaces to compensate for selection confusion, despite solid domain understanding.
The Insurance neutral position on tool selection, combined with strong action completion, suggests balanced development—the model understands both insurance concepts and technical implementations reasonably well, creating reliable end-to-end performance for your insurance workflows.
Qwen3 235B A22B Instruct 2507 performance gap analysis by domain
Action completion
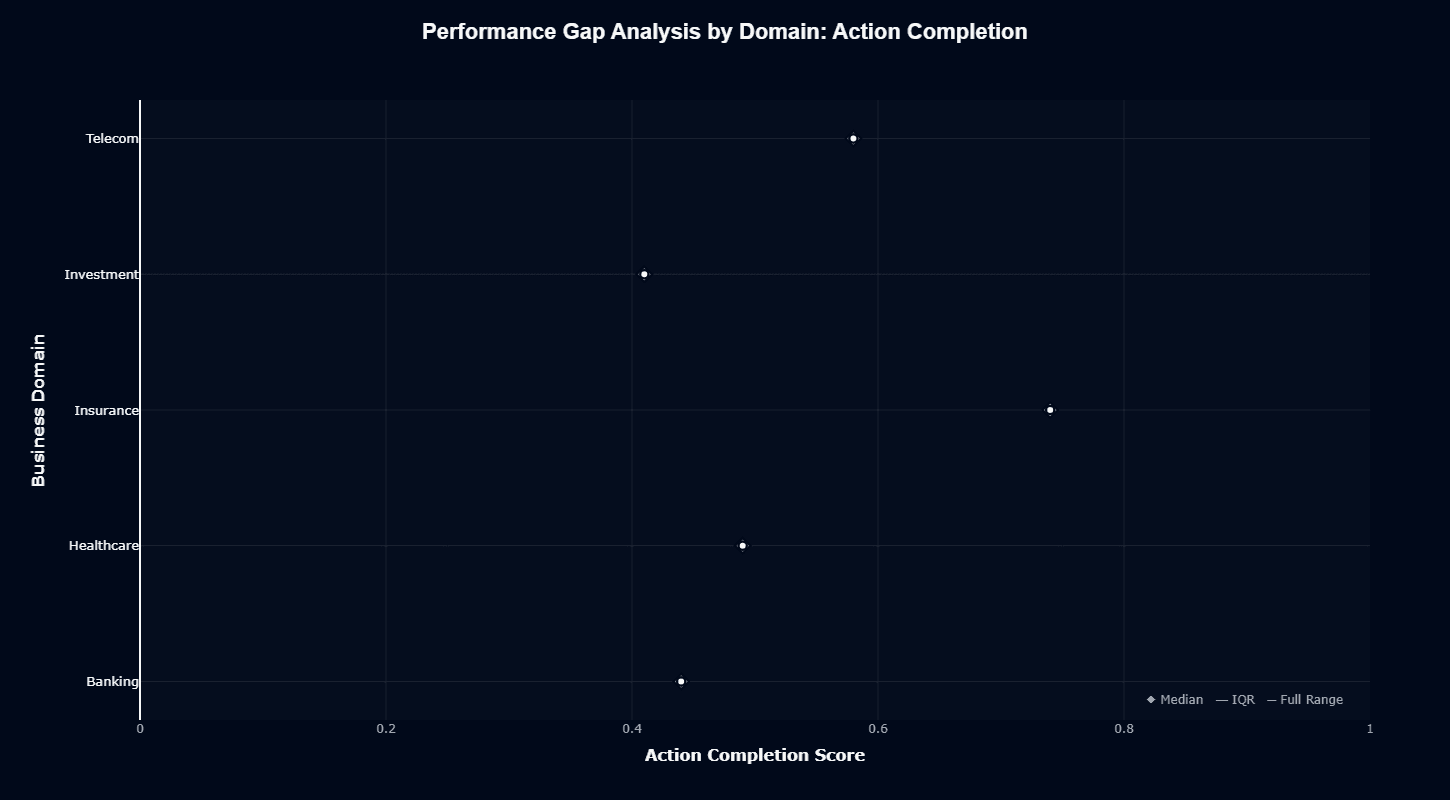
Performance gap analysis confirms Insurance as Qwen3's dominant strength at 0.74, with exceptionally tight variance indicated by narrow interquartile ranges. The model delivers consistent, reliable insurance task completion with minimal deviation across different scenarios.
Telecom clusters at 0.58, Healthcare at 0.49, Banking at 0.44, and Investment at 0.41. The narrow IQR across all domains demonstrates predictable, stable behavior—Qwen3 won't surprise you with wild performance swings, whether succeeding or failing.
This consistency matters for your production deployment planning. When implementing insurance solutions, you can establish aggressive success thresholds (70%+) with confidence that the model will meet them.
For investment teams, plan for 40-45% autonomous completion rates, architecting systems that elegantly handle the 55-60% of cases requiring human escalation or alternative processing.
The tight variance also simplifies your evaluation and quality assurance processes. You can baseline performance quickly during proof-of-concept phases and trust those baselines to hold in production, unlike models with high variance that require extensive testing across edge cases to understand real-world behavior.
Insurance's 0.74 score exceeds most competitor models' performance in any domain, including their specialized strengths. If your organization focuses on insurance, Qwen3 isn't just viable—it's potentially best-in-class, offering domain expertise that justifies building entire agentic systems around this model specifically.
Tool selection quality
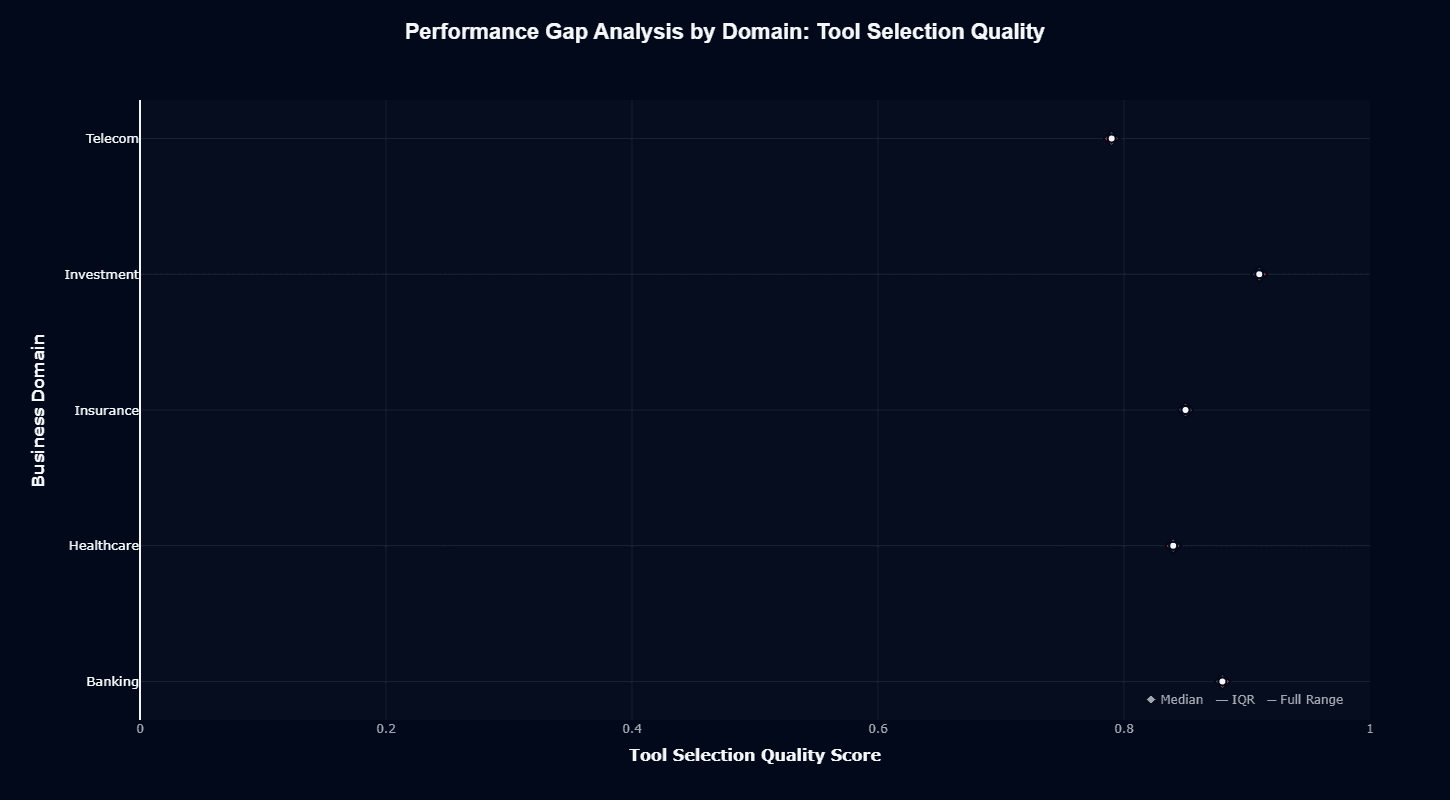
Tool selection quality shows dramatically different characteristics from action completion. Investment leads at 0.96, followed closely by Banking at 0.95. Insurance drops to 0.89, and Healthcare trails at 0.88—indicating strong overall tool selection capabilities.
The narrow variance across domains suggests Qwen3's function-calling logic operates consistently regardless of domain context.
Unlike action completion, where Insurance dominates, tool selection remains uniformly strong, with differences measured in single percentage points rather than tens of basis points.
When building tool-heavy agents, Qwen3's uniformly high tool selection across all domains reduces a major failure mode in your systems.
Incorrect function calls typically create cascading errors that derail entire workflows, but Qwen3's 0.85+ performance minimizes these incidents, allowing you to focus development on input validation and result interpretation rather than tool selection reliability.
Qwen3 235B A22B Instruct 2507 cost-performance efficiency
Action completion
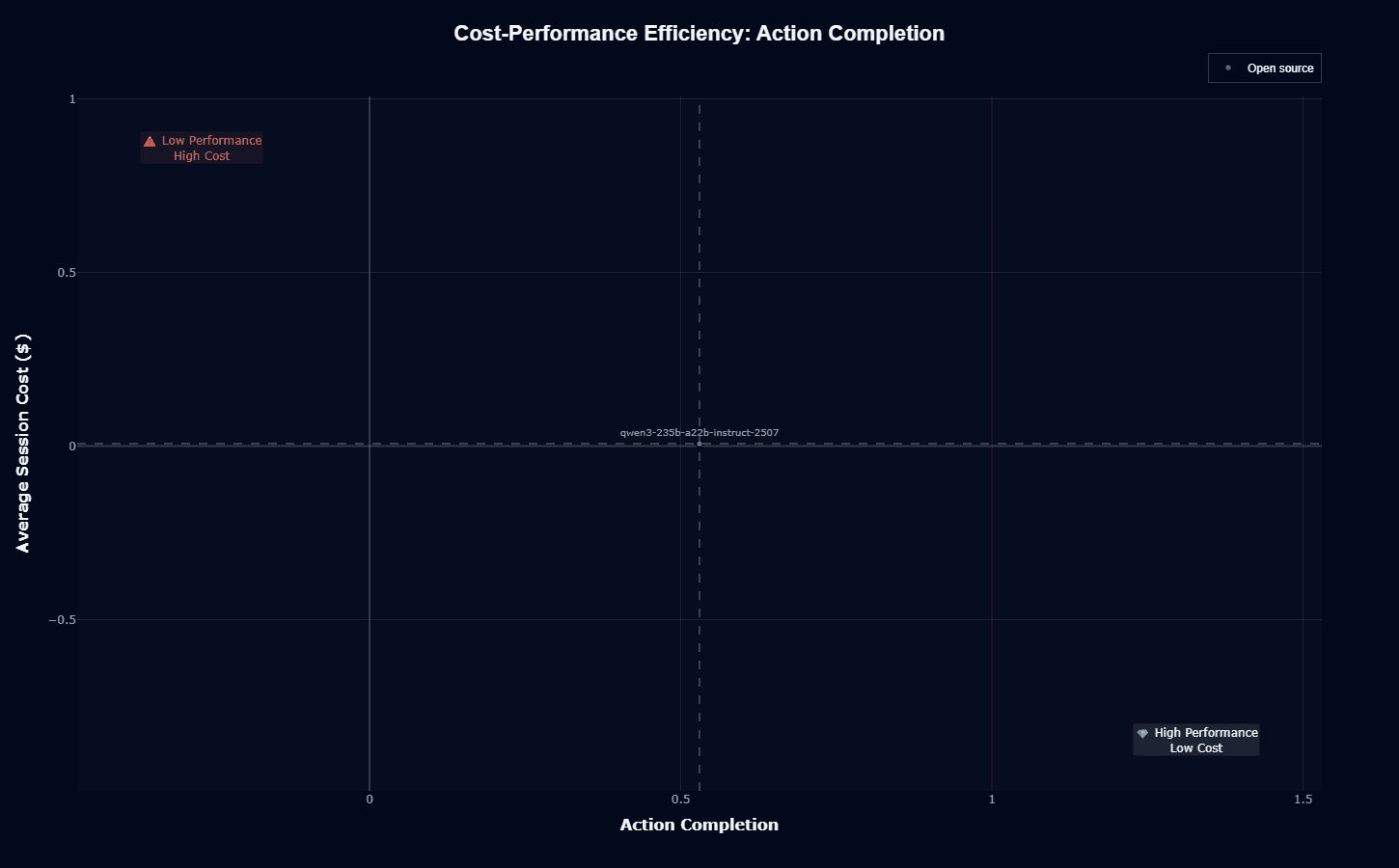
Qwen3 occupies an extraordinary position in the cost-performance landscape, positioned at nearly zero cost (x-axis ~0) with 0.53 action completion. The "Open source" marker indicates this isn't an approximation—there are literally no API fees, usage limits, or licensing costs beyond infrastructure.
This positioning creates fundamentally different economics for your enterprise. At $0.007 per session for compute only, if you're processing 10 million agent interactions monthly, you face roughly $70,000 in infrastructure costs.
With no marginal costs per interaction, traffic spikes don't create budget emergencies, and experimentation doesn't require finance approval.
The model sits squarely in the "High Performance, Low Cost" quadrant, though not at the absolute top of performance.
This tradeoff makes sense for many of your deployments: 0.53 action completion represents solid, production-viable capability, and the cost savings fund additional validation layers, human oversight, or infrastructure redundancy that commercial pricing prohibits.
For your insurance domain deployments where Qwen3 achieves 0.74 action completion, the economic value becomes even more compelling. You get best-in-class domain performance at commodity pricing, a combination unavailable from any commercial provider.
The open-source nature also enables cost optimizations impossible with API-based models. Your team can implement aggressive prompt caching, run smaller quantized versions for simple queries, or deploy specialized fine-tuned variants for specific workflows—all without incremental usage fees eroding the efficiency gains.
Tool selection quality

Tool selection cost-performance reveals Qwen3's strongest economic value proposition for your business. The model achieves 0.85 tool selection quality at the same near-zero cost, placing it firmly in the elite "High Performance, Low Cost" quadrant for function calling capabilities.
Tool selection accuracy matters disproportionately in your agentic workflows. A single incorrect tool invocation can derail multi-step processes, trigger expensive retry logic, or require human intervention that eliminates automation value.
Qwen3's 0.85 performance minimizes these failure modes while costing you nothing beyond compute. Compared to commercial alternatives charging $3-15 per million tokens with similar tool selection accuracy, Qwen3 delivers 96%+ cost reduction.
For your tool-heavy agents making dozens or hundreds of function calls per session, these savings compound dramatically. An agent that invokes 50 tools per interaction saves you 96% on those function calls alone.
The economic implications extend beyond direct cost savings. Zero marginal costs enable you to aggressively A/B test tool configurations, rapidly iterate on function schemas, and experiment with novel tool combinations—activities that would quickly become prohibitively expensive with usage-based pricing.
If you're building complex multi-tool orchestration systems or maintaining large libraries of custom APIs, Qwen3's combination of strong tool selection and zero licensing costs is particularly valuable.
The model handles technical complexity well while allowing unlimited scaling without budget constraints.
Qwen3 235B A22B Instruct 2507 speed vs. accuracy
Action completion
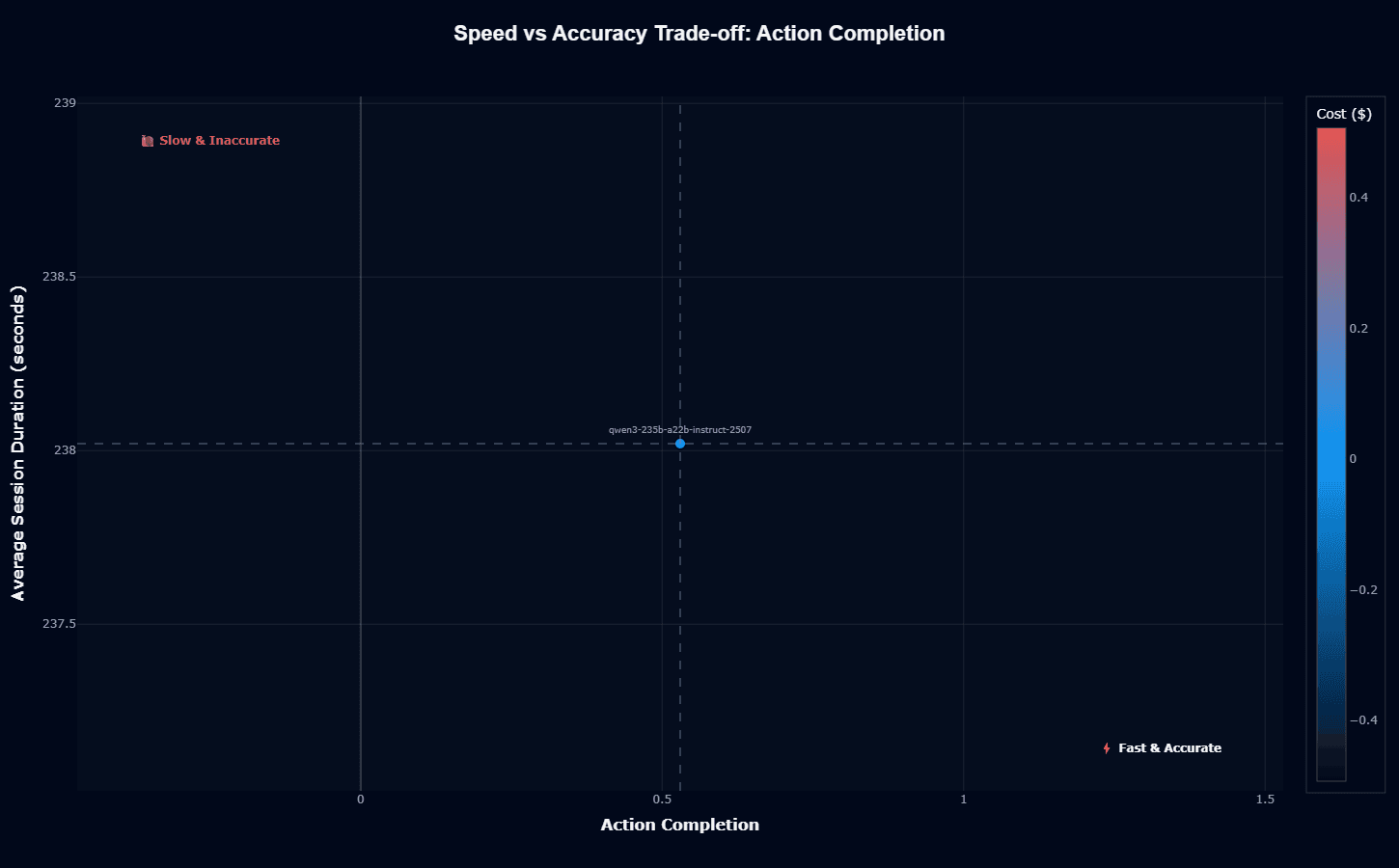
Qwen3's position at 238 seconds average duration with 0.53 action completion places it decisively in the "Slow & Inaccurate" quadrant—a designation that requires nuance given the model's other characteristics.
The 238-second latency represents approximately 4 minutes per interaction, making real-time conversational interfaces impractical for your users.
However, this speed assessment assumes synchronous interaction patterns where users wait for responses.
Many of your agentic workflows likely operate asynchronously: batch processing insurance claims overnight, analyzing large document sets during off-hours, or handling background tasks where 4-minute latency doesn't impact user experience.
The "inaccurate" label also needs context for your use case. At 0.53 overall action completion, Qwen3 performs adequately for many applications, and domain-specific performance varies dramatically. Insurance workflows achieving 0.74 completion don't feel inaccurate—they feel reliable.
For your production deployments, you should architect around the latency rather than fighting it. Queue-based processing, batch operations, and asynchronous workflows leverage Qwen3's strengths while avoiding user experience problems.
If you need real-time chat applications requiring sub-second responses, look elsewhere, but the majority of enterprise agent workflows can accommodate 4-minute processing times without issue.
Tool selection quality
Tool selection maintains Qwen3's 238-second latency with 0.85 accuracy, positioning the model in the slower region but with substantially better accuracy than action completion suggests. This indicates tool selection happens efficiently within the overall processing time—the latency stems from execution and response generation, not tool reasoning.
The high tool selection accuracy, despite slow overall speed, creates an interesting architectural opportunity for your systems. Tool selection typically occurs early in the agent execution pipeline, within the first few seconds.
The remaining 230+ seconds involve tool execution, result processing, and response generation. This means the high-quality tool selection doesn't require proportionally longer deliberation.
For your multi-step agent workflows involving complex tool orchestration, Qwen3's reliable tool selection becomes more valuable than raw speed. A model that selects tools correctly on the first attempt, even slowly, often completes workflows faster than a quick model that makes selection errors requiring retry logic and backtracking.
When optimizing agent performance, note that tool selection happens once per decision point, but the tools themselves may execute multiple times. Qwen3's 0.85 accuracy reduces wasteful tool invocations, potentially saving more total time than faster but less accurate alternatives despite the 238-second baseline.
The speed-accuracy tradeoff favors workflows where tool selection correctness matters more than response latency—data analysis pipelines, research agents, complex financial modeling, or any scenario where the cost of incorrect tool use exceeds the cost of waiting for correct selection.
Qwen3 235B A22B Instruct 2507 pricing and usage costs
Qwen3 235B's open-source Apache 2.0 license fundamentally changes the economics of your enterprise AI deployment. Rather than usage-based pricing, you pay only for infrastructure:
Compute: $0.007 per average session (based on benchmark data)
Hosting: Self-hosted on your internal infrastructure or cloud compute
Memory: ~470GB VRAM for BF16 version, ~250GB for FP8 quantized variant
Context window: 256,000 tokens natively supported
Licensing: $0 (Apache 2.0)
Economic comparison:
At $0.007 per session versus commercial alternatives averaging $0.15-0.20 per session, Qwen3 delivers 96-97% cost reduction. If your enterprise processes 1 million agent interactions monthly, this translates to:
Qwen3: ~$7,000/month (compute only)
Commercial alternatives: $150,000-200,000/month
The $143,000+ monthly savings fund substantial additional infrastructure: human oversight teams, validation systems, RAG knowledge bases, or premium compute instances for your latency-sensitive workflows.
You can deploy Qwen3 for routine operations while routing critical interactions to premium models, creating hybrid architectures that optimize cost-performance across diverse workloads.
Deployment flexibility:
Open-source licensing enables deployment patterns impossible with commercial APIs:
On-premise hosting eliminates your data egress concerns and latency from external API calls
Custom fine-tuning adapts the model to your proprietary workflows without vendor permission
Unlimited scaling isn't constrained by usage tiers or rate limits
Offline operation supports your air-gapped environments and regulated industries
Hidden costs:
You should account for open-source operational overhead:
DevOps resources for model deployment, monitoring, and maintenance
Hardware investments for GPU infrastructure (8x A100 80GB or equivalent)
Lack of commercial support requires your internal expertise for troubleshooting
Update management as Alibaba releases new versions
If your team has existing ML infrastructure and operations expertise, these costs remain negligible compared to API savings. If your organization lacks internal capabilities, you may find commercial alternatives simpler despite higher marginal costs.
Qwen3 235B A22B Instruct 2507 key capabilities and strengths
Here are Qwen3 235B A22B Instruct 2507’s key capabilities and strengths:
Insurance domain mastery: Qwen3 demonstrates exceptional understanding of policy documentation, claims processing, regulatory compliance, and risk assessment. This performance exceeds most commercial models across all domains, making Qwen3 potentially best-in-class for your insurance-specific deployments.
Exceptional conversation efficiency: Qwen3 resolves your queries with minimal back-and-forth. This efficiency reduces your total interaction time despite slower individual responses, and demonstrates strong instruction-following capability. The model understands your intent quickly and provides comprehensive answers rather than requesting clarification or breaking responses across multiple turns.
Strong tool selection across domains: Qwen3 excels at identifying appropriate functions from your large tool sets. Investment domain tool selection provides reliable function calling even where domain knowledge remains weak. This asymmetry enables you to create targeted architectural solutions that leverage tool selection strength while compensating for domain gaps.
Open-source economics: Apache 2.0 licensing eliminates your API fees, usage limits, and vendor lock-in concerns. At $0.007 per session for compute costs only, Qwen3 enables unlimited experimentation, aggressive A/B testing, and cost-effective scaling that commercial alternatives cannot match. The licensing permits your custom modifications, fine-tuning, and derivative works without legal restrictions.
Ultra-long context processing: Native 256,000 token support handles your extensive documentation, lengthy conversation histories, and multi-document analysis without external memory systems. Through the Dual Chunk Attention architecture, the model processes up to 1 million tokens in specialized configurations, enabling use cases impossible for standard context-window models.
Consistent, predictable performance: Narrow variance across domains and scenarios provides stable, reliable behavior for your applications. Your production systems can confidently baseline performance during proof-of-concept phases, trusting those metrics to hold in deployment. This predictability simplifies your quality assurance, capacity planning, and SLA establishment.
MoE efficiency: The 235B total parameters with 22B activated per inference provide frontier capability at reduced computational cost for your infrastructure. The MoE architecture enables sophisticated reasoning and specialized domain knowledge while maintaining inference speeds faster than comparably capable dense models.
Investment tool selection excellence: Despite weak investment domain knowledge, Qwen3 achieves 0.96 tool selection accuracy for financial APIs and functions. This enables reliable technical orchestration of your portfolio analysis tools, trading systems, and market data APIs when provided with appropriate context and validation.
Qwen3 235B A22B Instruct 2507 limitations and weaknesses
For Qwen3 235B A22B Instruct 2507, there are also some limitations and weaknesses you should consider:
Severe latency constraints: At 238 seconds (nearly 4 minutes) average duration, Qwen3 ranks among the slowest models. This latency prohibits your real-time conversational interfaces, synchronous user interactions, and any workflow requiring sub-minute response times. The speed limitation fundamentally restricts applicable use cases to asynchronous batch processing, background analysis, and offline workflows.
Investment and banking domain weakness: Action completion scores of 0.410 and 0.440 respectively, indicate insufficient domain knowledge for reliable autonomous operation in your financial services. Investment workflows requiring portfolio optimization, securities analysis, or market insight will fail frequently. Your banking applications involving loan processing, credit assessment, or regulatory compliance require extensive additional support through RAG systems or fine-tuning.
Healthcare performance gaps: The 0.490 healthcare action completion suggests limited medical knowledge, clinical terminology understanding, or healthcare workflow familiarity. Your implementations in patient care, clinical documentation, or medical decision support require substantial validation layers and domain expert oversight to ensure safe, accurate operation.
Moderate overall action completion: The 0.530 overall action completion trails commercial competitors, potentially requiring you to add validation logic, human oversight, or fallback systems for production reliability. While adequate for many applications, if you're accustomed to 70%+ completion rates from premium models, you'll need to adjust expectations and architectures.
Lack of commercial support: Open-source deployment means no vendor SLAs, guaranteed uptime, dedicated technical support, or liability coverage for your organization. You must maintain internal expertise for troubleshooting, performance optimization, and incident response. Model updates arrive on Alibaba's schedule without coordination with your enterprise deployment cycles.
Non-thinking architecture: As a pure instruction-following variant, Qwen3 lacks extended reasoning capabilities found in thinking-mode models. Complex multi-step problems requiring deep deliberation, strategic planning, or creative problem-solving may exceed the model's capabilities, requiring you to escalate to reasoning-specialized alternatives.
Infrastructure requirements: The model demands substantial hardware. If your organization lacks existing ML infrastructure, you face significant capital investment before achieving the operational cost savings. Smaller teams may find API-based alternatives more economically viable despite higher marginal costs.
Limited reasoning transparency: Without a thinking mode, Qwen3 doesn't expose its reasoning process, making your debugging and error analysis more difficult. When the model fails, you lack insight into decision logic, complicating root cause analysis and prompt refinement.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.