Qwen3-235B-A22B-Thinking-2507 Overview
Explore Qwen3-235B-A22B-Thinking-2507 performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Qwen3-235B-A22B-Thinking-2507 Overview
When your agents face problems that demand rigorous logic rather than quick banter, Qwen3-235B-A22B-Thinking-2507 steps in as a purpose-built reasoning engine. This open-weight Mixture-of-Experts model packs 235 billion total parameters but activates only 22 billion per token—giving you sophisticated reasoning without the compute bill of a dense giant.
The weights are downloadable, so you can deploy on-prem or in a private cloud and keep sensitive data under your control.
Three traits set it apart. A native 262K-token context window lets you feed entire project repositories, contract bundles, or weeks of chat history in one pass. The model operates in structured "thinking mode," wrapping its step-by-step reasoning inside <think> tags for transparent auditing and tool orchestration.
Its training emphasizes agent workflows—planning, tool calls, reflection—so it handles multi-step tasks that trip up smaller chat models.
Part of Alibaba's Qwen3 family built around "Think deeper, act faster," this variant pushes depth even further, trading speed for meticulous analysis. The sections ahead will help you decide whether that trade-off matches your deployment goals.
Check out our Agent Leaderboard and pick the best LLM for your use case

Qwen3-235B-A22B-Thinking-2507 performance heatmap
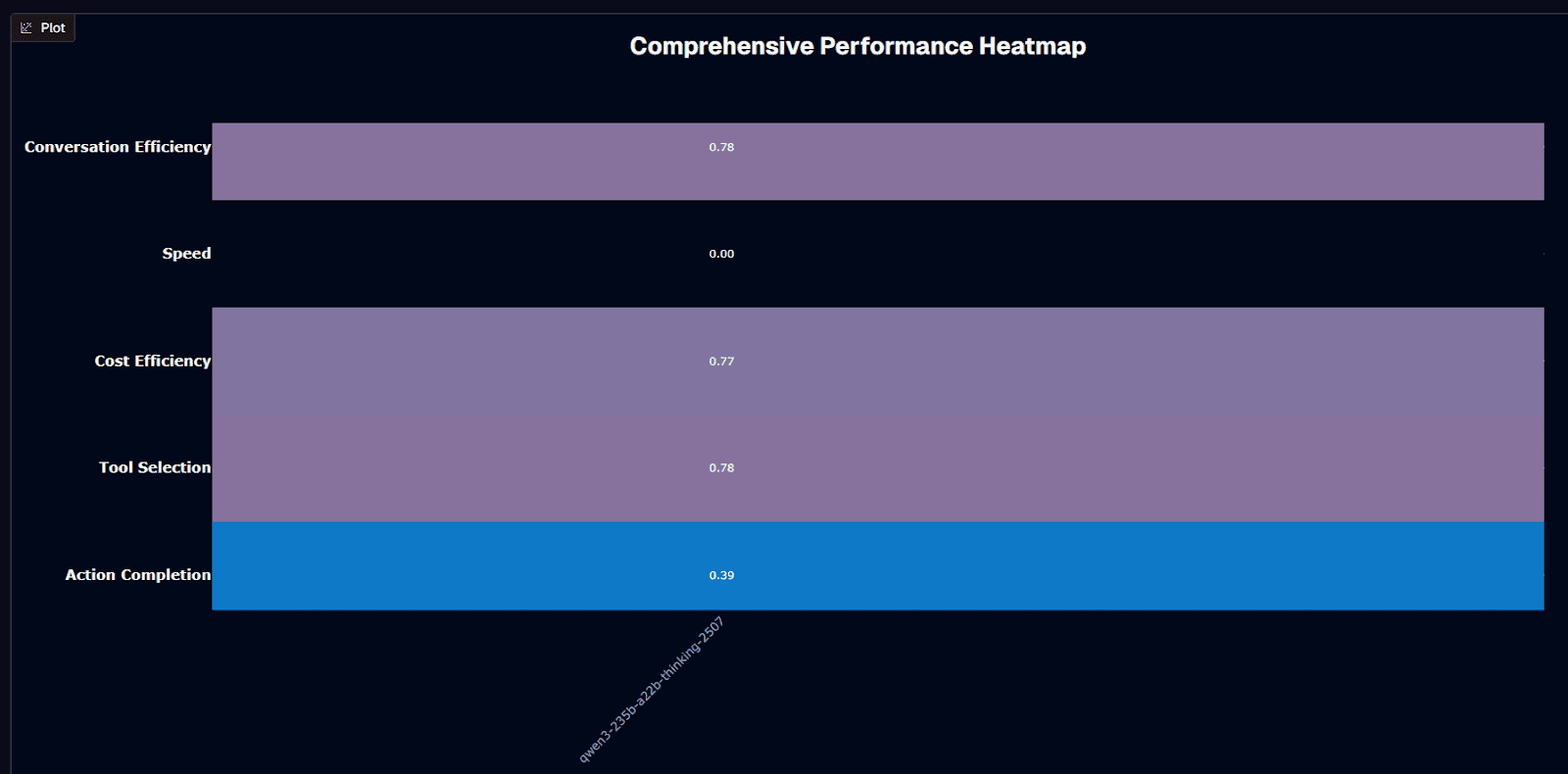
Qwen3-235B-A22B-Thinking-2507 delivers its strongest performance in conversation efficiency and tool selection, both scoring 0.78. Cost efficiency follows closely at 0.77, confirming the Mixture-of-Experts architecture works as intended. Action completion lands at 0.39, while speed sits at 0.00—an intentional design choice, not a bug.
The matching 0.78 scores on conversation efficiency and tool selection mean your agent frameworks maintain context across turns and route to the correct APIs reliably. That's critical for orchestration-heavy deployments where choosing the wrong function derails entire workflows.
The 0.77 cost efficiency reflects the MoE design doing its job: only 22 billion of the 235 billion parameters activate per token, keeping your GPU bill closer to a mid-tier model while delivering frontier-level reasoning.
Speed at 0.00 tells a different story. This "thinking-only" variant explicitly trades latency for reasoning depth, embedding structured chains of thought into every response. You gain transparency and auditability at the cost of extra seconds—an intentional architectural decision for workloads where correctness outweighs speed.
Your deployment decision crystallizes here: when deep reasoning, transparent thinking, or complex multi-step analysis drive your architecture—compliance checks, algorithm design, scientific calculations—this model fits. When sub-second responses matter more than exhaustive logic chains, consider faster alternatives for your latency-sensitive workflows.
Background research
The Mixture-of-Experts backbone routes each prompt through the most relevant parameter subset, conserving GPU cycles without capping output quality. The context window spans 262,144 input tokens with up to 81,960 output tokens—enough for complete reports, multi-step derivations, or full policy drafts in one shot.
Multimodal support is limited to text processing. The model excels at code generation validated on LiveCodeBench and tops open-source leaderboards on SuperGPQA and HMMT25 for mathematical reasoning. Open-weight licensing means you can self-host on-prem for data residency or spin up cloud endpoints through providers like Fireworks.
Training emphasizes agent workflows with reliable function calling, long-range planning, and structured reasoning. The always-on thinking mode wraps internal reasoning in
<think>blocks, enabling logging, auditing, and parsing for downstream tooling. Support for 100+ languages includes especially strong performance in Mandarin and other East Asian languages.
Is Qwen3-235B-A22B-Thinking-2507 suitable for your use case?
Use Qwen3-235B-A22B-Thinking-2507 if you need:
Multi-step reasoning for complex problems like competition math, scientific analysis, or algorithm design
Native 262K-token context window for processing entire codebases or research papers without retrieval systems
Strong programming capabilities for refactoring and non-trivial code generation
Reliable tool selection and agent orchestration backed by function-call training
Transparent reasoning with explicit
<think>traces you can log, audit, or strip before deliveryFrontier-scale intelligence at mid-tier costs via Mixture-of-Experts architecture
Open weights for on-prem deployment and data residency control
Avoid Qwen3-235B-A22B-Thinking-2507 if you:
Require sub-second response times for latency-sensitive traffic
Need simple chatbot exchanges that lighter models serve more economically
Lack GPU memory and budget for 22B active parameters plus substantial KV cache
Prefer concise answers over verbose reasoning chains that inflate token costs
Build mobile apps or chat widgets requiring compact responses
Demand real-time data beyond the model's knowledge cutoff without retrieval augmentation
Qwen3-235B-A22B-Thinking-2507 domain performance
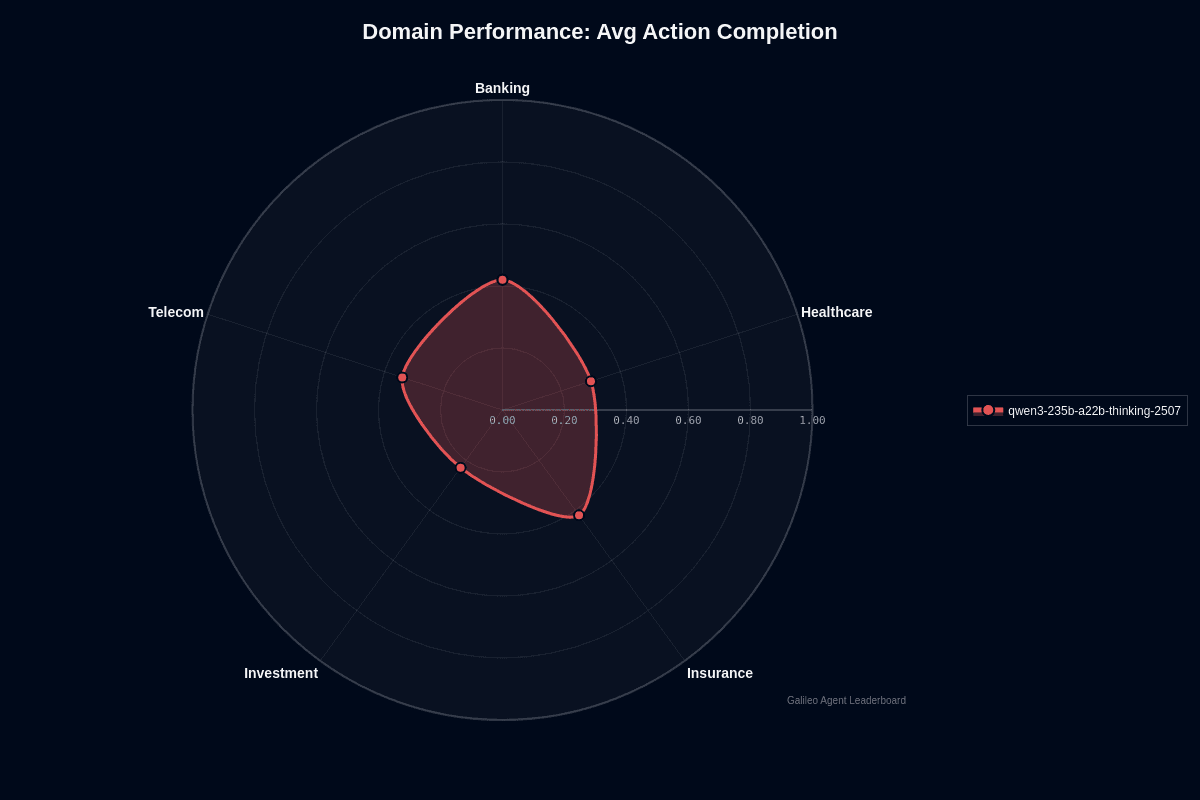
Qwen3-235B-A22B-Thinking-2507 shows clear domain variance in action completion. Banking and insurance both lead at 0.42, telecom follows at 0.34, healthcare drops to 0.30, and investment trails at 0.23.
The radar chart reveals a lopsided shape—banking and insurance push outward while investment collapses toward the center. This 19-percentage-point gap between the strongest and weakest domains signals that your deployment strategy should account for vertical-specific performance, not assume uniform results.
Banking and insurance's shared lead makes sense. These domains rely heavily on structured data reasoning and compliance analysis—exactly where the model's deep thinking capabilities shine. Policy documents, regulatory filings, and transaction verification follow consistent patterns that the extended reasoning chains handle well.
Investment's collapse reflects different challenges. Portfolio analytics and real-time market reasoning demand current data feeds and complex numerical modeling that expose the model's tendency to hallucinate without proper retrieval grounding.
Healthcare sits in the middle tier, where biomedical terminology and specialized domain knowledge create friction points that reduce reliability compared to financial services workflows.
Qwen3-235B-A22B-Thinking-2507 domain specialization matrix
Action completion
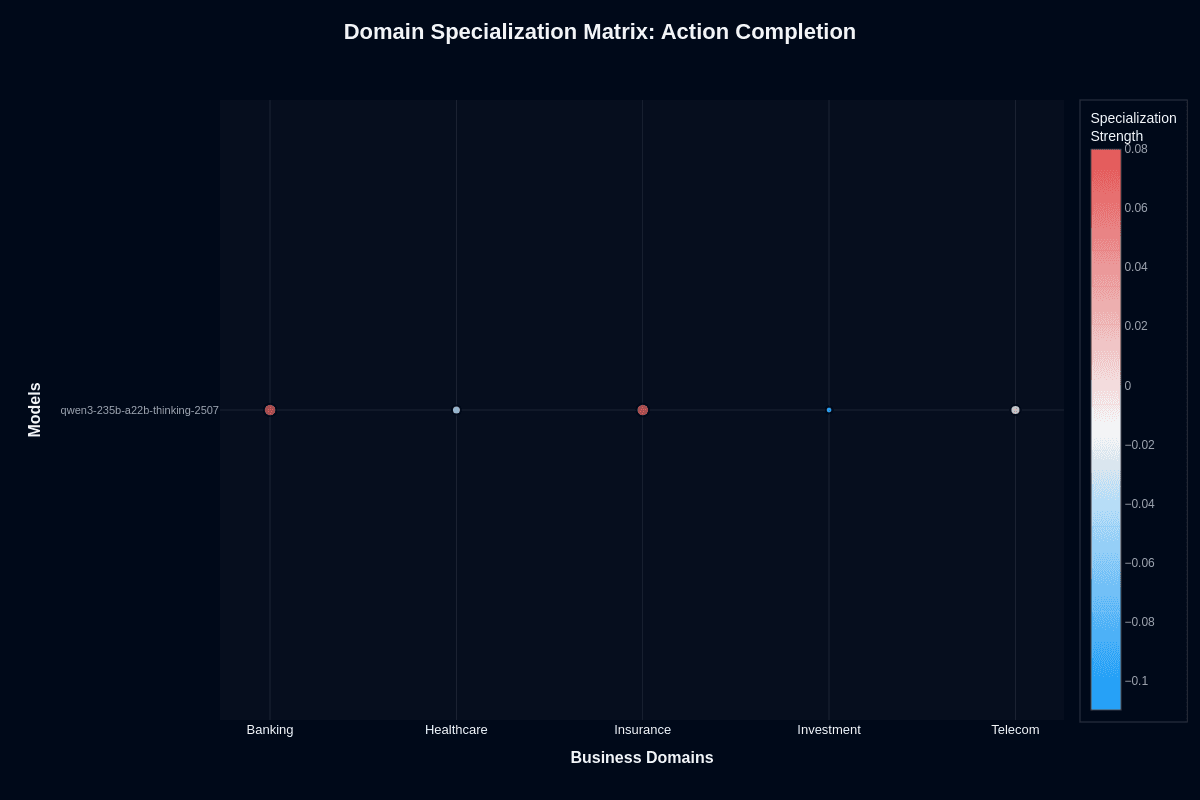
This heatmap reveals where Qwen3-235B-A22B-Thinking-2507 performs better or worse than its overall baseline. Banking shows positive specialization at +0.08 (coral coloring), with insurance close behind at +0.06. Telecom sits near neutral at 0. Healthcare dips slightly to -0.02, while investment drops to -0.10 (blue coloring).
Banking's +0.08 advantage translates to agents that push through complex loan workflows, transaction checks, and regulatory filings without stalling mid-process. Insurance's +0.06 reflects similar strength with policy quotes, claims summarization, and compliance verification.
Investment's -0.10 signals systematic underperformance—your trade recommendation bots are more likely to abandon tasks before completion. This isn't random variance; it's a reproducible pattern reflecting market data's demands for real-time feeds and tight numerical precision. Healthcare's slight negative at -0.02 suggests you'll need robust validation before presenting results to clinicians.
Tool selection quality
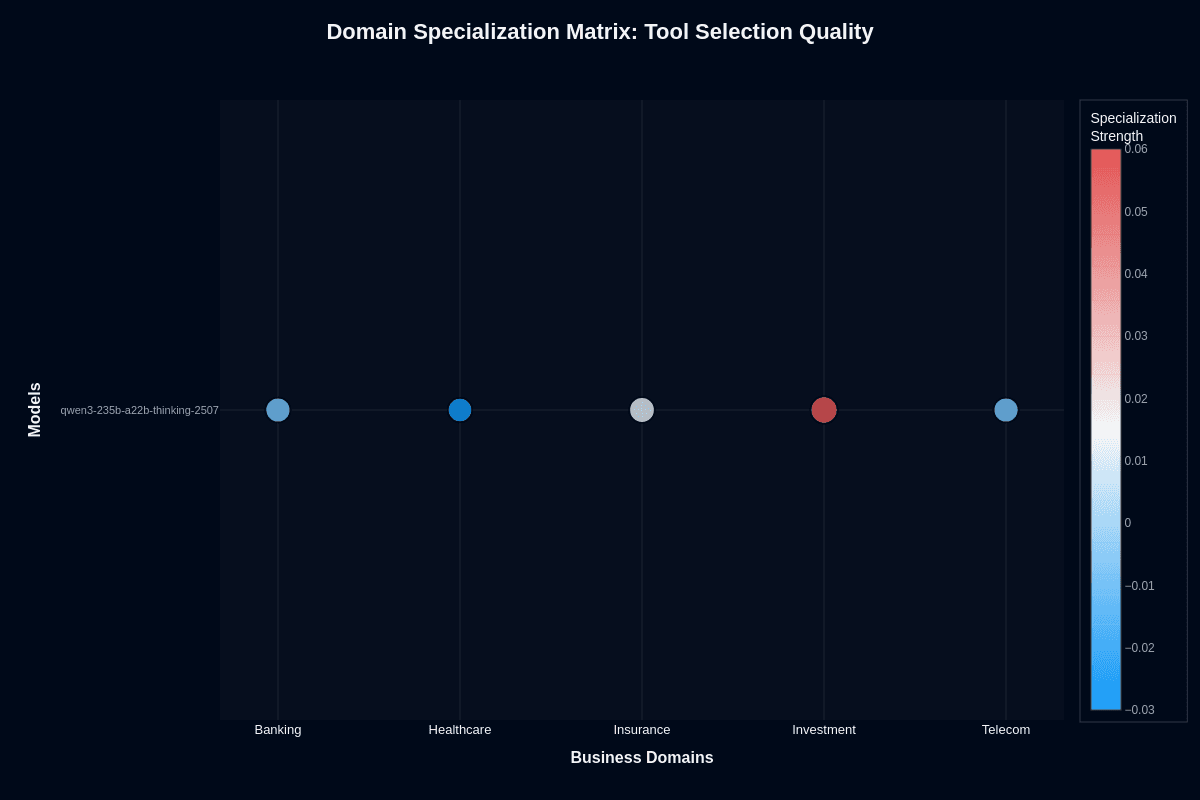
The tool selection heatmap tells a different story. Investment leads with +0.06 specialization (coral coloring)—the model's strongest domain for tool routing. Banking and telecom both register +0.02. Insurance sits neutral at 0, while healthcare dips to -0.03.
Notice the disconnect: investment agents pick the right tools more often than they finish jobs. This reflects the training emphasis on planning and reasoning over execution. Investment tasks often involve clearly defined finance APIs—quote lookups, trade execution, risk assessment endpoints—where precise schema following matters more than completing the subsequent reasoning chain.
Healthcare's -0.03 deficit stems from domain terminology overlap. Mislabeling similar diagnostic tools or confusing lab and radiology endpoints knocks scores down. Tighter tool descriptions and few-shot examples mitigate this gap easily.
Qwen3-235B-A22B-Thinking-2507 performance gap analysis by domain
Action completion
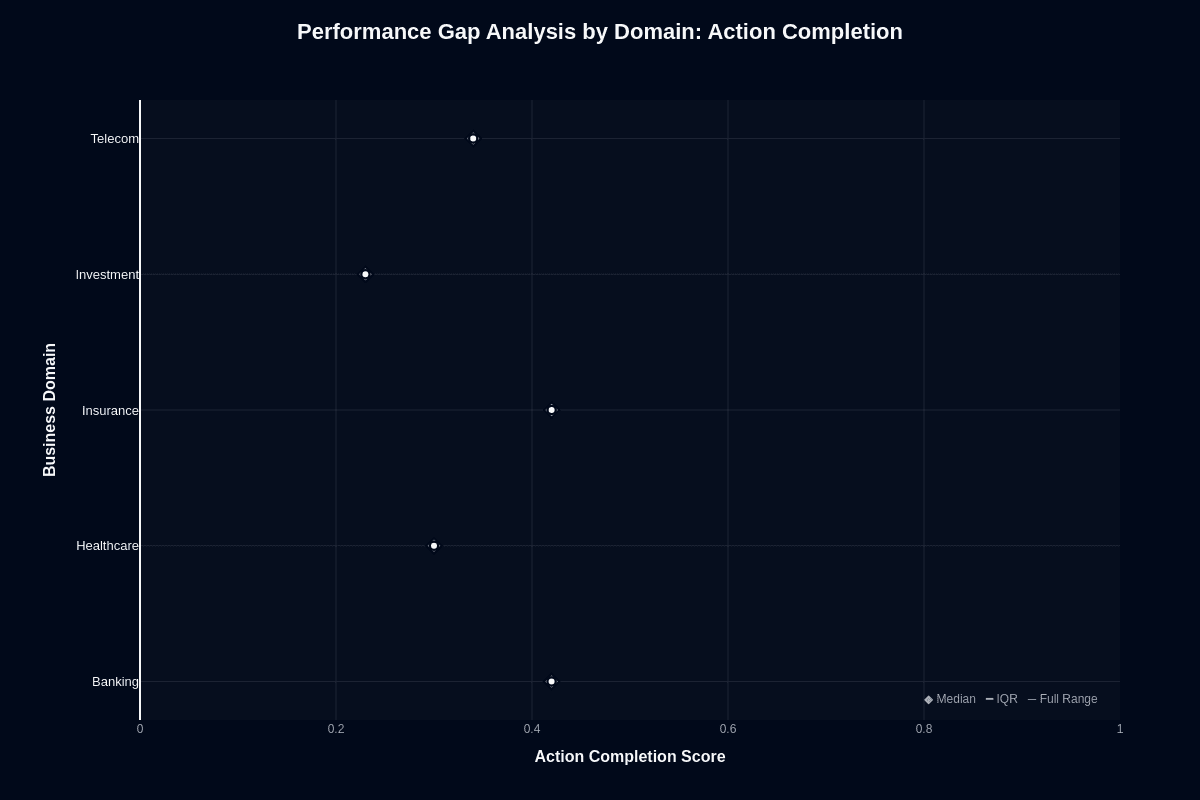
This distribution chart quantifies how much domain choice affects task success. Banking and insurance both hit a median near 0.48—the highest among all domains. Telecom follows at approximately 0.42, healthcare lands at 0.38, and investment trails at roughly 0.28.
The 20-percentage-point gap between the top domains and investment represents the difference between "succeeds nearly half the time" and "fails three-quarters of attempts." These aren't flukes but reproducible patterns visible in the clustering of data points.
For procurement decisions, this chart quantifies risk by vertical. Banking and insurance deployments carry the lowest failure risk—you can automate transaction checks, policy lookups, and claims summarization with confidence. Investment deployments demand guardrails, fallback models, or hybrid approaches routing complex analysis to specialized calculation engines. Telecom and healthcare require case-by-case evaluation based on your specific workflow complexity.
Tool selection quality

Tool selection quality shows remarkably strong performance across all domains. Investment leads with a median near 0.95, followed by insurance at 0.90, banking and telecom both at 0.88, and healthcare at 0.85.
The compressed gap and consistently high performance indicate the model's tool-routing capabilities generalize exceptionally well. Investment's 0.95 makes it particularly valuable for research assistants orchestrating multiple data vendors and analytics libraries—even when final action completion lags.
This superiority stems from the model's structured planning approach and explicit reasoning blocks. Your agents can confidently select the right SQL query, pricing API, or diagnostic function even in domains where final answers need human verification. Healthcare's slightly lower 0.85 still delivers strong performance but warrants extra safeguards before invoking patient-facing tools.
Qwen3-235B-A22B-Thinking-2507 cost-performance efficiency
Action completion
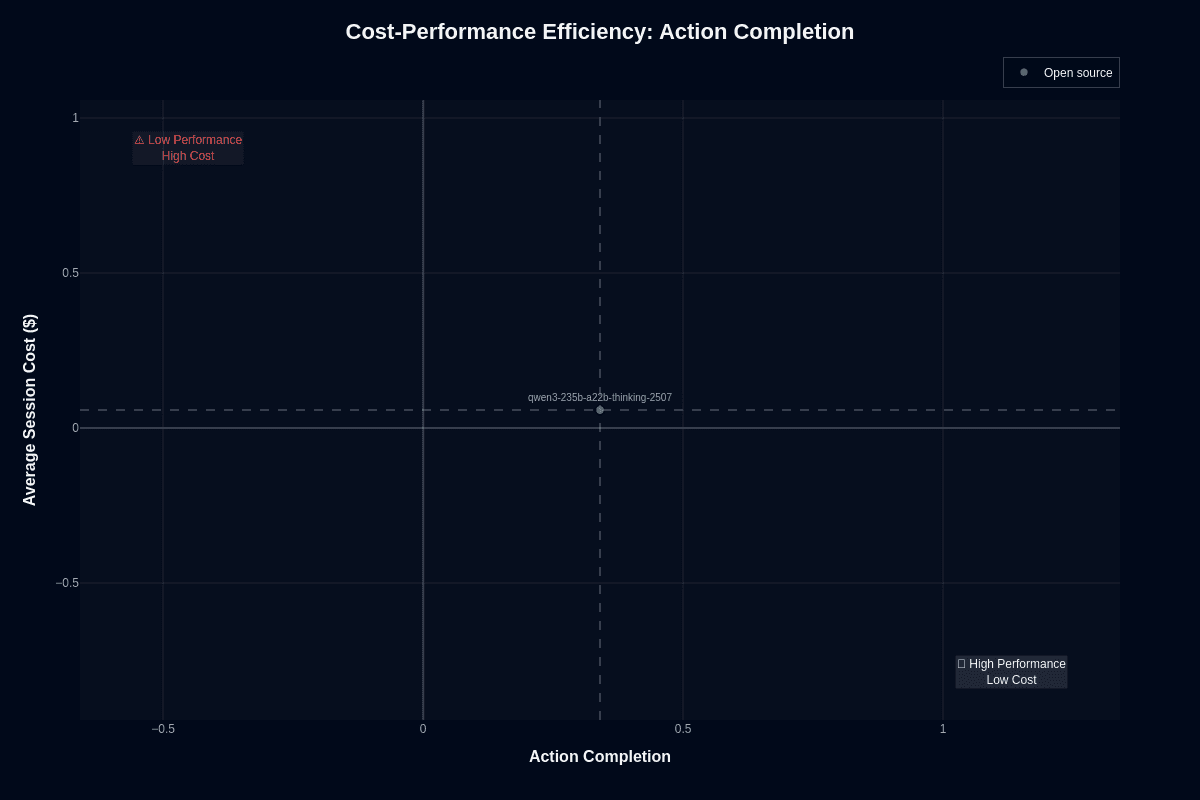
This scatter plot positions Qwen3-235B-A22B-Thinking-2507 at approximately (0.39, $0.06)—approaching the ideal "High Performance Low Cost" quadrant from the left. The model avoids the "Low Performance High Cost" danger zone while maintaining competitive cost positioning.
The vertical dashed line at 0.5 action completion emphasizes how close the model sits to the halfway threshold. The $0.06 cost point reflects the Mixture-of-Experts architecture delivering frontier-scale reasoning at mid-tier prices—each token activates only 22 billion of the 235 billion total parameters.
For developers building complex reasoning workflows, this positioning makes sense. You no longer need frontier-model budgets for multi-step tasks like code refactors, policy analyses, or scientific calculations. The MoE design means you tackle hard problems without runaway bills. High-volume deployments stay viable because the architecture keeps per-token costs well below dense alternatives of similar capability.
Tool selection quality
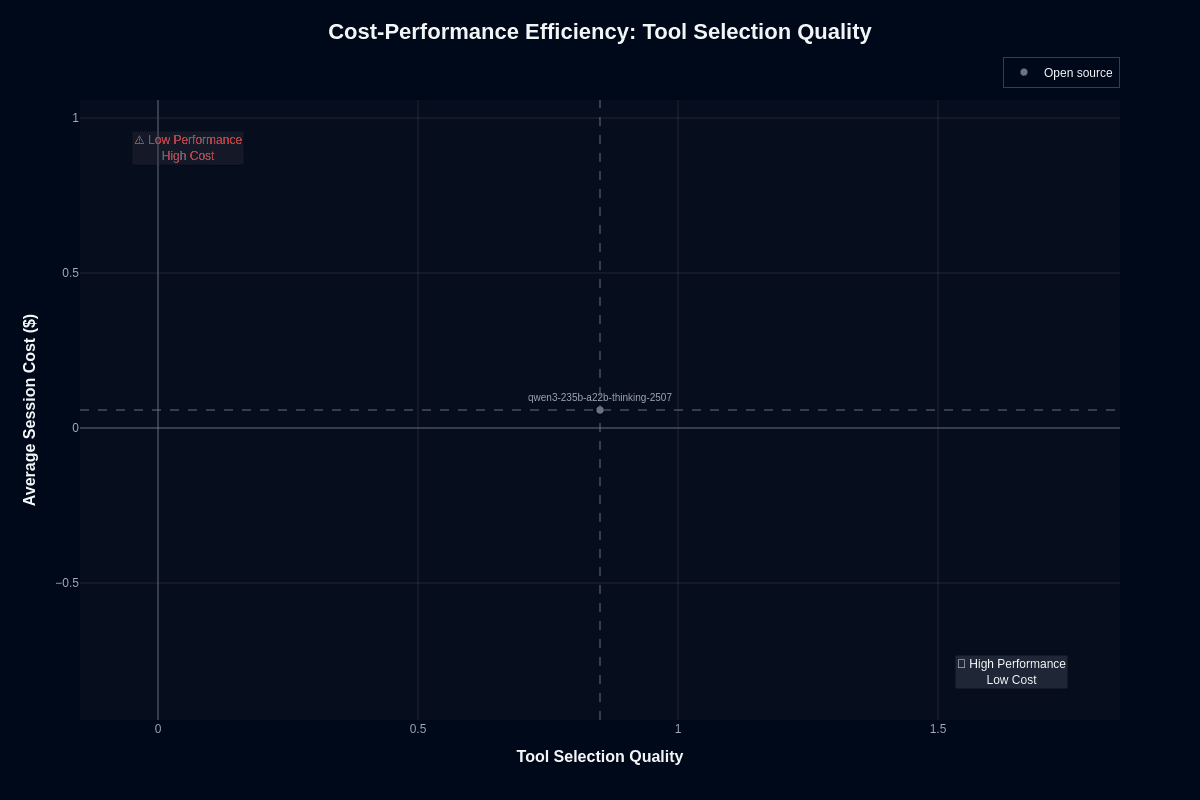
Qwen3-235B-A22B-Thinking-2507's story improves dramatically for tool selection. The model lands at approximately (0.85, $0.06), positioning it squarely in the "High Performance Low Cost" quadrant. Strong tool selection paired with mid-tier session cost represents an attractive outcome for agent infrastructure.
This chart reveals what the model does exceptionally well: choosing appropriate tools, APIs, and function calls without burning resources. Agent workflows that depend on accurate tool invocation get premium precision at budget-friendly rates, allowing orchestration layers to loop and retry without breaking the bank.
The cost efficiency means you can afford richer prompt context—full OpenAPI specs, detailed tool descriptions, comprehensive schema documentation—without exploding budgets. Fewer malformed calls lead to smoother execution and predictable spend.
Qwen3-235B-A22B-Thinking-2507 speed vs. accuracy
Action completion
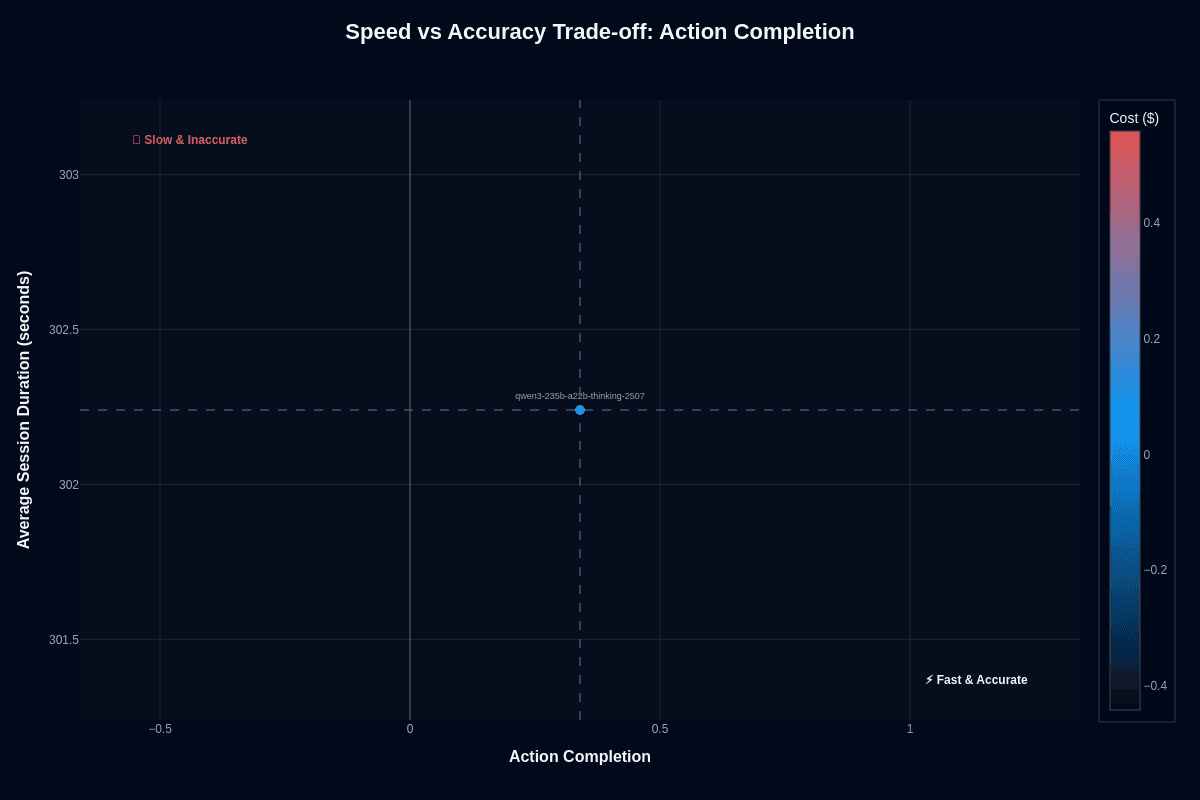
This scatter plot captures Qwen3-235B-A22B-Thinking-2507's positioning in the speed-accuracy-cost triangle. The model lands at approximately (0.34, 302.2 seconds) with blue coloring indicating low cost. The "Slow & Inaccurate" warning zone sits in the upper left; the "Fast & Accurate" ideal occupies the lower right.
At 302.2 seconds average session duration and 0.34 action completion, the model occupies a deliberate position—prioritizing exhaustive reasoning over rapid responses. This isn't a performance failure; it's the architectural intent. A complex action like multi-table SQL migration planning takes five minutes, yet lands closer to the right answer than faster alternatives.
The trade-off pays off for specific workloads. Overnight data audits, compliance checks, and scientific calculations benefit from this latency since correctness outweighs speed. Customer-facing workflows needing sub-second responses struggle here—route simple requests to lighter models and reserve this one for complex escalations where accuracy matters most.
Tool selection quality
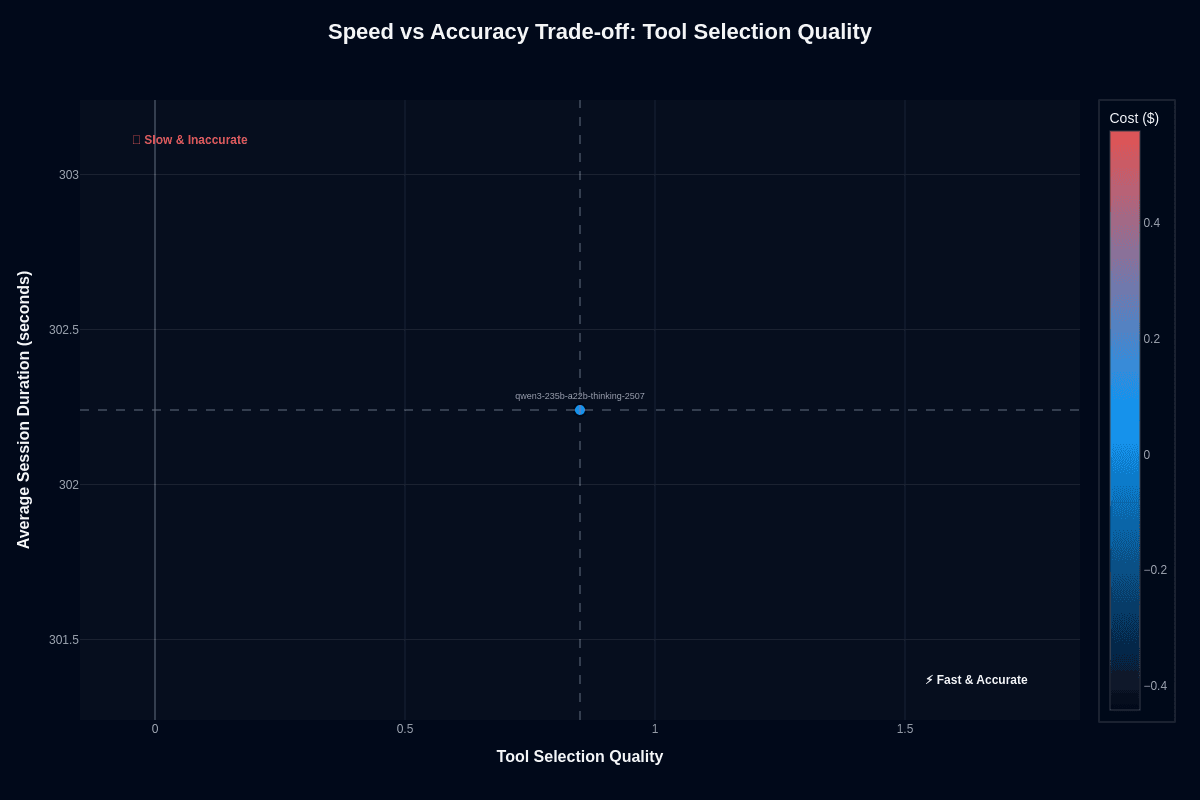
Tool selection accuracy tells a different story. The model lands at approximately (0.85, 302.2 seconds) with blue coloring confirming low cost. Despite the extended session duration, tool selection precision remains exceptionally high.
The exposed chain of thought allows logging and replay of every decision, making post-mortem debugging less painful than with opaque fast models. Your agents confidently select the right SQL query, pricing API, or diagnostic function—and you can trace exactly why.
Real-time trading bots or live game AI struggle with this latency, but agent workflows calling external calculators, databases, or retrieval systems benefit from the reliability gained. Trim prompt verbosity and batch low-priority requests to squeeze out more throughput without sacrificing the selection precision that anchors your agent's success.
Qwen3-235B-A22B-Thinking-2507 pricing and usage costs
Reasoning models drain budgets fast. Premium closed-source options commonly exceed $6 per million output tokens, making deep analysis prohibitively expensive at scale.
The Mixture-of-Experts architecture changes the equation. Each token activates only 22 billion of its 235 billion parameters, delivering frontier-scale reasoning at roughly 20B model compute costs. This architectural efficiency translates to competitive pricing across major providers.
Fireworks prices the Qwen3-235B model at $6.00 per million input tokens and $12.00 per million output tokens. Even accounting for chain-of-thought verbosity that can generate thousands of tokens per response, the MoE discount keeps total spend well below premium alternatives.
Three strategies maximize cost efficiency when you deploy this reasoning model:
Self-host the open weights when you control suitable GPUs to eliminate per-token fees entirely. Right-size context windows instead of automatically using the full 262K-token capacity for every request. Cap output length or post-process responses to remove internal reasoning before storage and reduce unnecessary token consumption.
These approaches let you access deep reasoning capabilities at per-task costs that would be impossible with dense frontier models.
Qwen3-235B-A22B-Thinking-2507 key capabilities and strengths
Your agents need to process entire contracts, debug complex codebases, and reason through multi-step problems without losing context. This model's 262K-token native context window handles these scenarios without retrieval logic, while its Mixture-of-Experts architecture delivers frontier-level reasoning at roughly the cost of a 20B dense model.
The 235B total parameters with just 22B active per token means you tackle hard problems without runaway bills. This performance shows in the benchmarks—the model tops open-source leaderboards on SuperGPQA, HMMT25, and LiveCodeBench, so you're leaning on proven depth rather than hope when you hand it thorny logic puzzles or algorithm design tasks.
Debugging AI reasoning used to mean guessing what went wrong inside black-box models. The always-on "thinking mode" changes this by enclosing internal reasoning in <think> blocks, giving you transparent chains of thought you can log, audit, and parse for downstream tooling.
Your development workflows benefit from robust coding capabilities that routinely handle multi-file projects, making it a powerful co-pilot for complex engineering tasks. Open-weight licensing keeps governance and cost decisions in your hands—you can self-host on-prem for data residency or spin up cloud endpoints in minutes.
Global teams avoid translation bottlenecks with support for 100+ languages, especially strong performance in Mandarin and other East Asian languages. When you need exhaustive analysis, up to 81,960-token outputs enable complete reports, multi-step derivations, or full policy drafts in one shot—you skip stitching together partial answers.
For agent workflows, fine-tuning for tool use means the model doesn't just think—it decides when to call APIs, spreadsheets, or databases, making orchestration far more reliable than models that treat tools as afterthoughts.
Qwen3-235B-A22B-Thinking-2507 limitations and weaknesses
Your production environment won't forgive the model's heavy compute footprint. Even though only 22 billion parameters fire per token, inference still demands multi-GPU clusters or costly hosted endpoints. Without hardware in the A100/H100 class, the model's size quickly erodes its MoE cost advantage.
The "thinking-only" variant always generates chain-of-thought, so responses arrive seconds—not milliseconds—after each prompt. In latency-sensitive flows you'll watch throughput crumble while token bills rise.
Verbose reasoning creates unexpected operational challenges. The model tends to over-explain when many production tasks need crisp answers, forcing you to post-process, prune, or cap output length to avoid drowning users in unnecessary tokens.
Complex deployment amplifies these issues—MoE routing, 262K context windows, and custom attention kernels introduce configuration pitfalls that trigger CUDA OOMs, KV-cache exhaustion, and fragile scaling without mature MLOps practices.
Domain expertise remains a critical blind spot. Strong general reasoning doesn't guarantee factual accuracy in specialized areas, where the model can invent citations or calculations without retrieval grounding or domain fine-tuning.
Finance, healthcare, and legal workflows require domain-specific constraints the base weights don't include, demanding extra cycles for supervised tuning and policy filters. Training data frozen at the latest available cutoff date means real-time market moves, clinical guidelines, or regulatory changes remain invisible until you integrate RAG or retrain.
Large-context sessions monopolize GPU memory, making concurrent request spikes difficult to serve without traffic shaping or multi-model routing to maintain SLAs.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.