How to Follow the 70/40 Rule That Elite AI Teams Leverage for Testing

Jackson Wells
Integrated Marketing

In the traditional software lifecycle, shipping a new feature might take a nine-day delivery cycle. In the era of Generative AI, that window has shrunk to under 24 hours. Engineering teams are moving at breakneck speeds, deploying agents that can rewrite their own logic and interact with customers in real-time.
But this velocity brings a terrifying realization: if you are driving down the highway at 200 miles per hour, you don't need fewer safety features; you need a significantly stronger harness.
This is where the "70/40 Rule" emerges as the defining characteristic of elite engineering organizations.
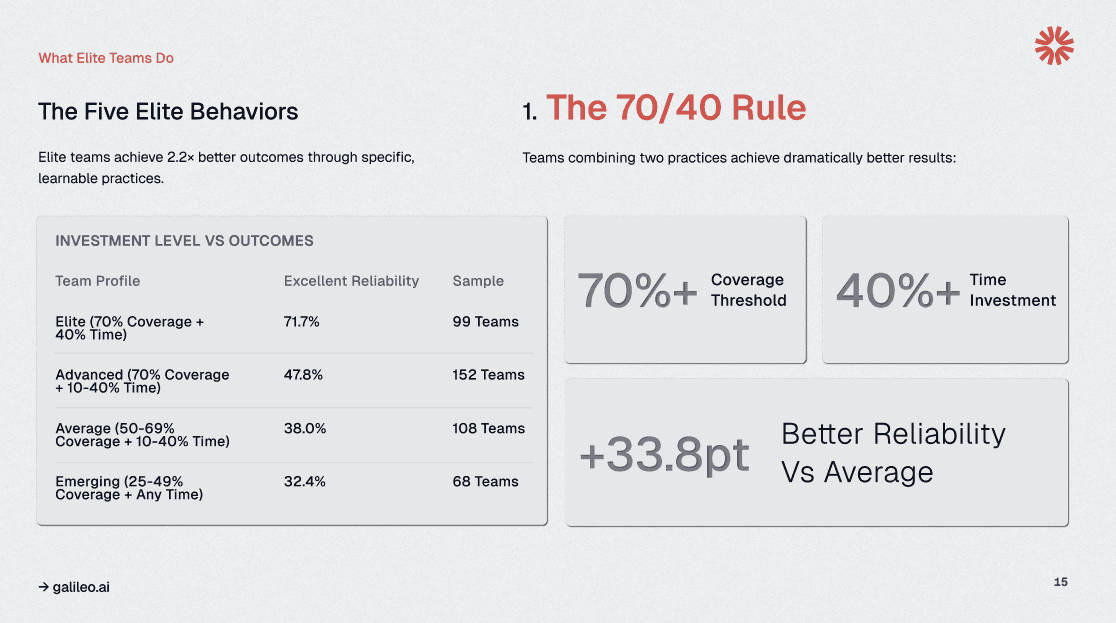
Our survey of over 500 AI practitioners reveals that the highest performers (those achieving 71.7% "excellent" reliability) adhere to a strict resource allocation formula: they maintain 70% behavioral coverage and, crucially, invest 40% of their total development time in evaluation engineering.
This 40% figure often shocks leadership. It sounds like a tax on innovation. However, the data proves the opposite.
What does allocating 40% of development time actually look like in practice? How do elite teams structure their evaluation efforts, and where does that time investment really go? The data reveal a sophisticated resource allocation strategy that transforms evaluation from overhead into competitive advantage.
TLDR:
Elite teams allocate 40% of development time to evaluation, with 38% hitting the 40–60% sweet spot that correlates with 71.7% excellent reliability
The 40% breaks down into day-zero specification (10%), regression testing (15–20%), functionality evaluation (20–25%), and production feedback loops (10%)
Cross-team ownership matters: engineers build evaluation infrastructure while subject matter experts define quality criteria, requiring structured time allocation for both
Cost-effective evaluation models like Luna-2 make 40% economically feasible
1. Understand What 40% of Development Time Means
There is a pervasive myth that spending 40% of engineering time on testing means developers are sitting idle or writing redundant unit tests. This misunderstanding stems from a legacy view of QA.
For elite AI teams, "evaluation time" is not passive; it is active infrastructure building. Our data indicate that roughly 38% of top-tier teams fall within the 40-60% investment sweet spot, and their calendars look markedly different from those of their peers.
This time is distributed across high-value activities:
Building automated dataset generators
Refining adversarial attack vectors
Analyzing semantic drift in staging
Unlike traditional software, where unit tests might consume 10-15% of a sprint as overhead, AI evaluation is a core engineering discipline. It involves constructing the "brain" that checks the model's "brain."
Crucially, this investment reclaims time downstream. Average teams spend weeks debugging vague "it feels off" reports from users. Elite teams use tools such as Galileo’s Signals during the 40% allocation to automatically detect failure patterns before deployment.
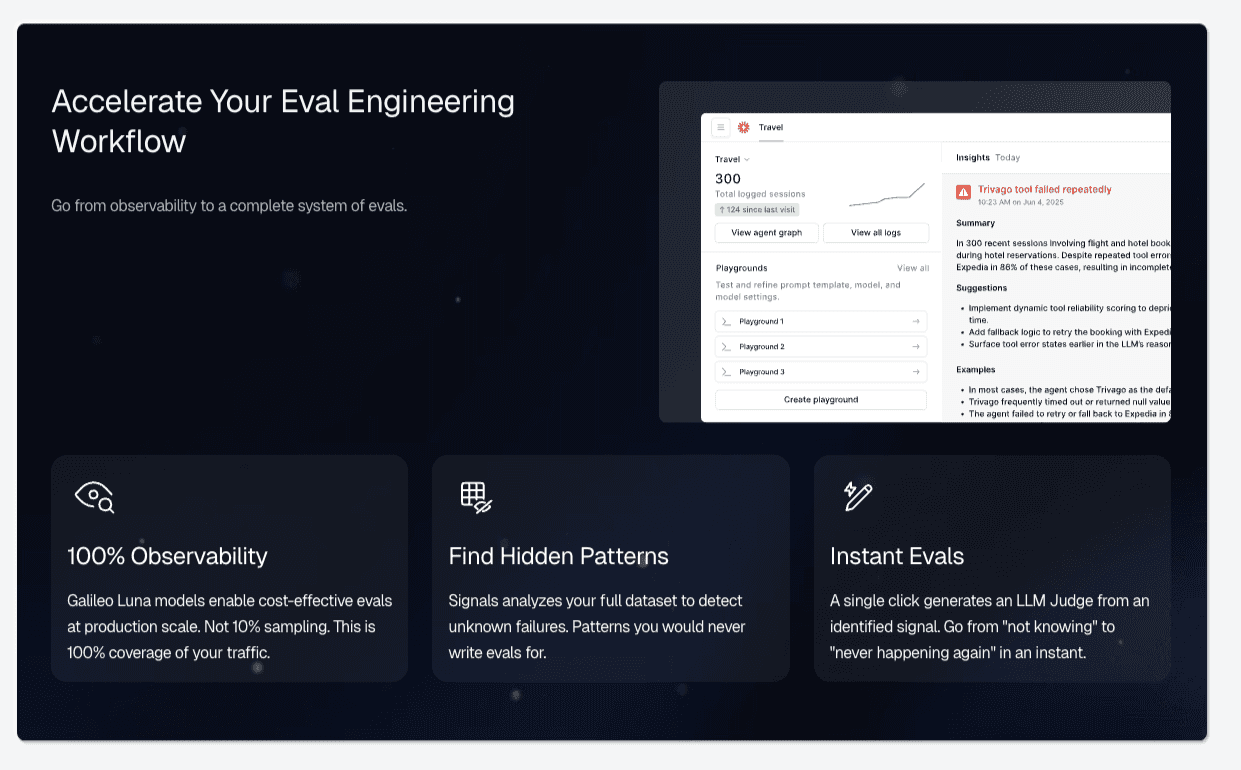
By identifying that a model struggles specifically with "nested logic queries" on Day 1, they avoid spending Day 30 firefighting a production outage. The 40% investment is the premium paid to ensure the other 60% of development time actually results in shippable code.

2. Solve the Cost Equation That Makes 40% Economically Possible
The most significant shift in the 70/40 framework is the timing of testing. For elite teams, evaluation is the new Product Requirement Document (PRD). In traditional workflows, you might write code and then write a test to verify it. In AI, where the "code" is probabilistic and opaque, you must define the success criteria before you even prompt the model.
This means the first 40% of the project lifecycle is often devoid of implementation.
Instead, Product Managers and Engineers collaborate to define success in natural language: "If the user asks for financial advice, the agent must decline with this specific tone," or "If latency exceeds 200ms, fallback to the cache." These aren't just goals; they are executable specs.
Picture a team building a customer service agent.
Before selecting frameworks or models, they document exact evaluation criteria:
“Agent must maintain conversation context across 5+ turns with 95% accuracy”
“Financial transaction confirmations require explicit user approval with zero tolerance for hallucinated amounts”
“Response latency must stay below 2 seconds for 99% of queries”
Engineering then selects the architecture that can demonstrably meet these predefined metrics during development testing.
The resource implication: 10% of the 40% evaluation budget goes to upfront specification work. Teams that skip this step end up building tests reactively, discovering requirements through production failures rather than defining them proactively.
The time investment at the beginning prevents far larger time costs later when architectural choices prove incompatible with necessary quality standards.
3. Identify What You Stop Doing to Make Room for 40%
Evaluation is a cross-team activity involving subject matter experts, not just an engineering responsibility. The breakdown of ownership of the 40% determines whether teams achieve comprehensive coverage or merely test what engineers consider important.
Engineers build evaluation infrastructure and maintain CI/CD pipelines, consuming roughly 20% of the development time budget. Subject matter experts define quality thresholds, identify edge cases, and validate that evaluation criteria reflect real-world requirements, which requires a structured 20% time allocation.
This division matters because “unknown unknowns” (the failures teams don’t anticipate) can’t be caught by engineers alone.
For instance, a developer building a financial services agent knows to test arithmetic accuracy but might miss regulatory compliance edge cases that a compliance SME would immediately recognize.
The healthcare engineer validates API responses but may lack the clinical knowledge to identify dangerous medication interactions that a medical professional would flag.
The resource allocation math: if engineers invest 40% of their time in evaluation activities, SMEs need similarly structured time commitments. Organizations that expect SME contributions to be “whenever they have time” end up with an engineer-centric evaluation that misses domain-specific failure modes.
Elite teams formally allocate SME time to evaluation ownership, treating it as a core responsibility rather than a helpful addition.
4. Allocate 10% to Day-Zero Eval Specification
The 40% time allocation isn’t monolithic. It divides into two distinct categories with different resource needs, tooling requirements, and ownership models.
Regression evaluations prevent known failures from recurring, running automatically in CI/CD pipelines to catch when code changes break existing behaviors. Functionality evaluations test new behaviors, explore edge cases, and validate that features work as intended before they reach production.
Teams that don’t budget these separately end up with comprehensive regression coverage but inadequate validation of new capabilities.
Regression evaluation typically consumes 15–20% of the 40% time budget.
These tests run on every pull request, providing fast feedback about whether changes introduce problems. The infrastructure requires initial investment to build, but runs automatically thereafter, catching issues immediately rather than discovering them in production.
Each production incident should spawn a new regression test, ensuring that specific failure never recurs, creating a compounding quality improvement over time.
Picture a team where every PR automatically triggers regression suite execution through CI/CD integration, catching any degradation of existing behaviors within minutes. But functionality testing follows a different cadence: dedicated sprint ceremonies where teams review new agent capabilities, collaboratively explore edge cases, and build evaluation coverage for features before release.
Custom dashboards track functionality coverage separately from regression coverage, ensuring both receive appropriate attention.
5. Budget 20% for Regression Testing Infrastructure
Online signals feed back into offline flows, and this feedback loop consumes a hidden but critical portion of the 40% allocation. Production monitoring, incident analysis, and test case generation from real traffic represent ongoing investments that teams often underestimate when planning evaluation budgets.
Data drift occurs when offline tests decay without production input: user behavior evolves, edge cases emerge, and evaluation criteria need refinement based on actual deployment conditions.
The mechanics of the feedback loop require dedicated time allocation. Teams review production traces to identify evaluation gaps: behaviors observed in real-world usage that lack corresponding tests.
They analyze incidents to identify root causes and develop regression tests to prevent recurrence. They monitor evaluation metric trends, investigating when previously reliable behaviors begin to degrade.
This continuous improvement cycle differentiates teams that maintain quality over time from those whose initial evaluation suite becomes obsolete as their application evolves.
Consider a team allocating 10% of sprint capacity specifically to production analysis and feedback incorporation. Each week, engineers review the previous week’s production traces, identifying patterns where agent behavior deviated from expectations.
They examine incidents that reached users and identify which evaluation gaps enabled those failures. They analyze metric distributions, identifying behaviors that passed testing but performed poorly in production. This systematic review generates new test cases that strengthen future releases.
The math check validates the 40% total:
10% for day-zero specification
20% for regression infrastructure and execution
20% for functionality evaluation of new behaviors
10% for production feedback loops
Teams that budget less than 40% typically sacrifice one of these categories, most commonly the feedback loop, resulting in evaluation suites that work initially but gradually become less effective as applications evolve.
6. Reserve 20% for Functionality Evaluation of New Behaviors
We must address the elephant in the room: cost. As noted in the industry analysis, evaluation costs are "significantly higher than predicted 2-3 years ago." If you attempt to evaluate every single interaction using GPT-4, achieving 70% coverage will bankrupt your project before it launches.
The math simply doesn't work at scale.
This economic pressure forces teams to choose: test less (and risk reliability) or find a more efficient approach. Elite teams break this tradeoff by adopting specialized small language models (SLMs) for evaluation.
Instead of using a general-purpose giant to check a specific fact, modern teams use purpose-built evaluators like Luna-2 to run comprehensive checks on accuracy, hallucination, and tone at approximately 97% lower cost than using GPT-4-based judges.
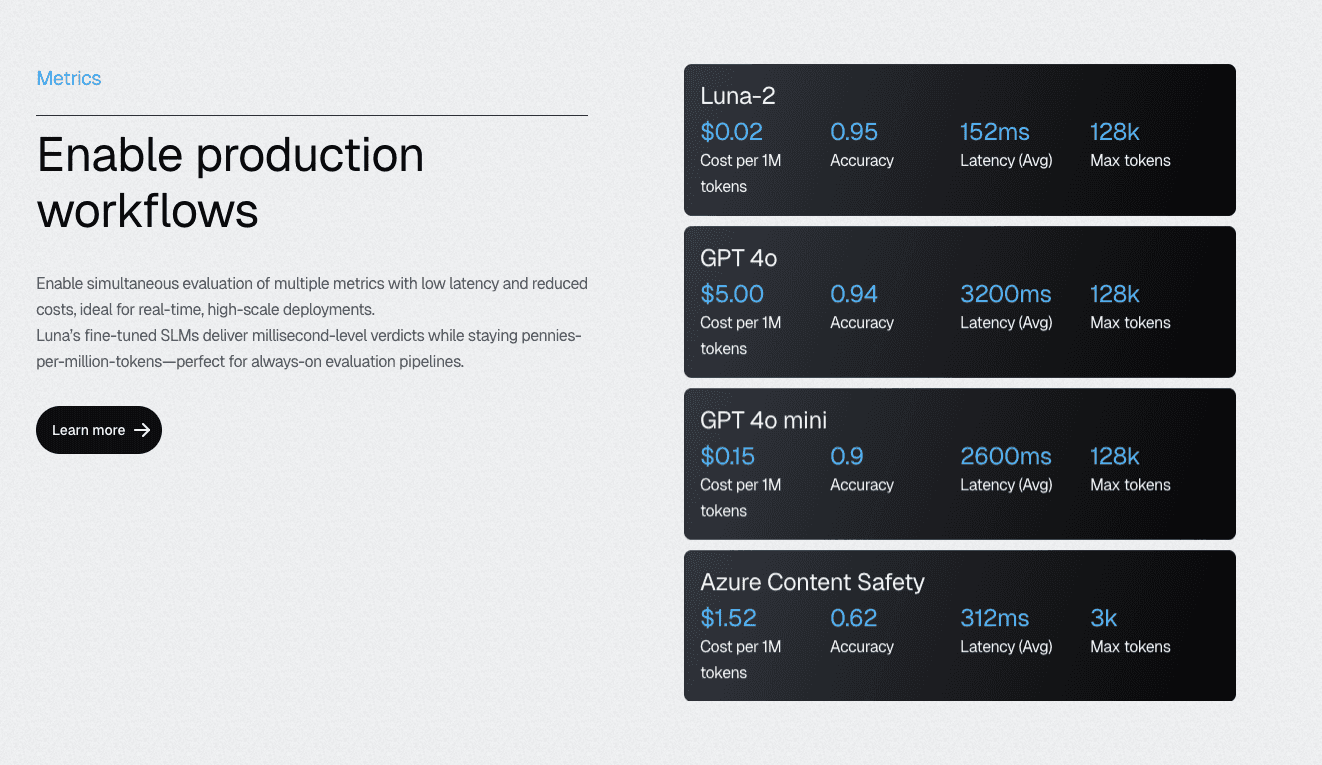
The unlock: when the cost per evaluation drops 30×, comprehensive testing transitions from luxury to standard practice. Teams stop debating which behaviors deserve evaluation coverage and start systematically testing everything.
The 40% time allocation becomes achievable because engineers spend time defining quality criteria and analyzing results rather than rationing evaluation budget across competing priorities.
7. Build Your Incremental Roadmap to Reach 70/40
Before implementing the 70/40 framework, teams need diagnostic clarity on the current state. Two critical questions establish a baseline:
What percentage of AI behaviors have corresponding evaluations?
What percentage of sprint time currently goes to evaluation activities?
Most teams discover uncomfortable gaps — typically 30–50% coverage with only 15–25% time investment. The distance between the current reality and 70/40 determines roadmap complexity and timeline.
The incremental path matters more than the destination timeline. Organizations attempting to jump from 30% coverage to 70% in a single quarter overwhelm teams and generate resistance.
Instead, successful adoption follows quarterly progression:
Q1 targets 50% coverage with 25% time investment
Q2 reaches 65% coverage with 35% time
Q3 achieves 70/40
Each step builds capability, demonstrates value through improved reliability metrics, and earns stakeholder confidence for continued investment.
The prioritization strategy determines whether teams achieve a sustainable 70% or hit a plateau. Start with high-risk behaviors (those involving financial transactions, personal data, or safety-critical decisions), so the most consequential failures are caught first.
Expand to high-volume behaviors where even small error rates generate significant incident counts. Finally, add breadth across the remaining behaviors, recognizing that some low-risk, low-volume edge cases may remain untested initially.
Achieve the 70/40 Framework and Ship Reliable AI Models with Galileo
With the state of GenAI, evaluation coverage and time investment are the infrastructure that separates reliable AI systems from constant firefighting. The question for engineering leaders: Does your organization have the platform capabilities that make 70/40 economically and operationally feasible?
Here’s how Galileo provides the complete infrastructure elite teams use to achieve the 70/40 framework:
Comprehensive Coverage Through Graph Engine: Galileo automatically maps every decision point in multi-step agent workflows, identifies gaps where evaluation is missing, and transforms abstract coverage metrics into actionable engineering work that directly correlates with the 70.3% excellent reliability achieved by elite teams.
Cost-Effective Evaluation at Scale with Luna-2 SLMs: With evaluation costs 97% lower than GPT-4 alternatives and sub-200ms latency even when running 10-20 metrics simultaneously, Galileo enables teams to achieve the 70%+ coverage threshold without budget constraints
Automated Failure Detection via Signals: Rather than waiting for production incidents to reveal evaluation gaps, Galileo's Signals automatically surfaces failure patterns across agent traces
Runtime Protection Through Protect API: Galileo's industry-leading runtime guardrails catch hallucinations, policy violations, and safety issues in milliseconds at serve time, transforming the incident paradigm from reactive cleanup to preventive blocking
Continuous Improvement with Signals and CLHF: With Galileo, you can fine-tune specialized evaluation models on your domain using Continuous Learning via Human Feedback, achieving the consistency that 93% of teams report missing from standard LLM-as-a-judge approaches
Explore how Galileo helps enterprise AI teams achieve elite-level reliability and helps you build reliable AI agents with end-to-end observability and evaluation.
Frequently asked questions
What is risk-weighted testing allocation for AI systems?
Risk-weighted testing allocation assigns evaluation resources based on application criticality rather than uniform percentages. According to Harvard Business Review's framework, high-risk applications (autonomous decision-making, customer-facing systems) require 25-30% of project resources for evaluation, medium-risk applications need 15-20%, and low-risk applications, such as internal prototypes, require only 5-10%. This approach ensures testing investment matches actual deployment risk.
How do I calculate the ROI of AI testing investment?
Forrester's Total Economic Impact Study provides a defensible quantification: 358% ROI over three years, a $2.4 million net present value, and a payback under 6 months. For internal ROI planning, document your average incident resolution time, revenue impact per hour of downtime, and compliance penalty exposure. Compare these failure costs against evaluation infrastructure investment—typically orders of magnitude smaller.
What's the difference between code coverage and ML artifact coverage?
Code coverage measures lines executed during testing — meaningful for deterministic software but insufficient for AI systems. ML artifact coverage tracks monitoring of models, datasets, prompts, and decision paths in production. Meta's standard of 80%+ artifact monitoring reflects this distinction. Traditional coverage can reach 100%, yet models still produce harmful outputs that only a multidimensional evaluation can catch.
How does Galileo help teams implement systematic evaluation?
Galileo's platform combines the evaluation capabilities elite teams build internally: Luna-2 SLMs provide 18% higher accuracy than GPT-3.5 at 97% lower cost, enabling real-time multi-dimensional assessment. The Signals engine processes all production traces (not samples) to surface failure patterns automatically. This infrastructure investment (typically requiring weeks to build internally) becomes available through one-line integration.
Jackson Wells