AI Observability Trends in 2026 from OpenTelemetry to the Agent Control Plane

Jackson Wells
Integrated Marketing

Your VP of Engineering just asked why three different autonomous agent frameworks are producing incompatible telemetry, and the compliance team wants fleet-wide policy enforcement by next quarter.
This is the reality of agent observability in 2026. Dozens of production agents emit traces in formats that do not talk to each other, while regulators set hard deadlines for governance documentation. The era of "log everything and figure it out later" is over.
Agent observability has matured into a discipline of standardization, governance, and runtime intervention. Four agent observability trends in 2026 are defining this shift, restructuring the stack from telemetry collection to agent-level control.
TLDR:
OpenTelemetry GenAI semantic conventions remain in Development status, with no stable attributes yet
Security and observability acquisitions are accelerating vendor consolidation
Eval-to-guardrail architecture is replacing siloed eval and runtime protection tools
You need observability stacks spanning open standards and agent-native control
What Agent Observability Looks Like in 2026
Agent observability is the practice of tracing, evaluating, and intervening on autonomous agent behavior across the full development lifecycle. The unit of analysis is no longer a single LLM call or a service request.
In 2026, production agents execute multi-step workflows involving tool-use chains, inter-agent handoffs, retrieval steps, and branching decision paths with 10 to 50+ decision points per task. An autonomous agent can respond in milliseconds, throw no system errors, and still deliver fabricated information or expose sensitive data. Your infrastructure dashboard stays green while business damage accumulates.
Contrast this with 2024's "model monitoring" framing, where you tracked individual request-response cycles, token usage, and drift metrics for standalone LLM calls. That approach breaks down when a production agent delegates to three sub-agents, each making tool selections your team never anticipated. The four trends below are restructuring how you instrument, govern, evaluate, and protect these systems.
Learn more about multi-agent observability in our eBook

AI Observability with OpenTelemetry GenAI Conventions
After two years of vendor-specific tracing formats fragmenting autonomous agent telemetry, portable standards finally matter for AI workloads.
The OpenTelemetry GenAI Special Interest Group has been building semantic conventions that define how LLM calls, tool invocations, embeddings, and autonomous agent steps should be represented as spans. The broader ecosystem is converging on OTLP as the wire protocol for autonomous agent telemetry, even as the semantic conventions beneath it remain contested.
How GenAI Semantic Conventions Standardize Agent Traces
The conventions define standardized span attributes under the gen_ai.* namespace: gen_ai.operation.name for operation types such as chat, embeddings, and tool execution, gen_ai.provider.name for model providers, gen_ai.request.model for model identification, and token usage attributes for cost tracking.
Tool execution spans carry gen_ai.tool.name, while autonomous agent-oriented spans support operations like invoke_agent.
Before these conventions, you often had to rebuild instrumentation every time you switched observability vendors. One team discovered their entire tracing pipeline broke when migrating backends because every span attribute was proprietary.
The common mistake was coupling instrumentation to a single vendor schema. With OTel GenAI conventions, you instrument once using standardized attributes and export traces to any OTLP-compatible backend. That portability can eliminate months of re-instrumentation work during vendor transitions.
Where OpenTelemetry Still Falls Short for Agent Workflows
How do you evaluate whether an autonomous agent's output was actually correct? OTel can tell you the production agent ran and how long it took, but its scope is limited to generating, collecting, and exporting traces, metrics, and logs.
Eval scoring, hallucination detection, agent graph visualization, and runtime intervention are all out of scope by architectural design. OTel produces span trees, parent-child hierarchies that are structurally different from the decision graphs representing branching logic, state transitions, and autonomous agent delegation that debugging requires.
Even autonomous agent planning, how production agents formulate strategy before acting, still lacks clear representation in the current conventions.
The GenAI conventions also carry "Development" stability status, meaning attributes can change without notice. This is why platforms layered on OTel still differentiate on agent-native capabilities: graph visualization, proprietary eval metrics, and runtime guardrails that operate where OTel's scope ends.
The Agent Control Plane Emerges as a New Category
Governance is moving into its own architectural layer, separate from build tools and orchestration frameworks. This is where production agent control becomes an architectural requirement, not a feature checkbox.
How the Agent Control Plane Separates Oversight From Execution
The emerging taxonomy breaks enterprise agentic architecture into three functional planes. The Build plane is where autonomous agents are created. The Orchestration plane is where production agents are embedded into business workflows. The Oversight, or Control, plane provides out-of-band governance that operates independently of both.
The observation driving this separation is straightforward. As production agents proliferate across build and orchestration environments, governance applied within either plane inherits that plane's blind spots. The Oversight plane must enforce policy regardless of how or where autonomous agents are built and executed. You should increasingly expect to fund this layer as real infrastructure.
The contrast with the previous approach is stark. Hardcoded per-agent guardrails require engineering to update rules individually for each production agent, then redeploy. A centralized policy server applies updated rules to every production agent simultaneously. One approach scales linearly with headcount. The other scales with policy design.
Why Centralized Policies Beat Hardcoded Guardrails at Fleet Scale
Walk through this scenario: your compliance team identifies a new PII handling requirement. You have 50 production agents across four frameworks. With hardcoded guardrails, engineering must update each production agent codebase, test the changes, and redeploy all 50 instances. A single policy update becomes 50 engineering tickets.
A control plane architecture solves this by separating where control hooks are placed from what those hooks enforce. Your developers own hook placement. Your policy teams own enforcement logic. Updates propagate to the entire fleet in minutes without code changes or application restarts.
One example is Galileo's Agent Control, an open-source control plane under Apache 2.0, which implements this pattern through a @control() decorator. When a decorated function executes, it checks output against centrally managed policies and responds with allow, deny, steer, warn, or log. Policies are hot-reloadable, so a compliance team can update PII detection rules across every production agent with a single change.
Vendor Consolidation Reshapes the Agent Observability Stack
The period is shaping the evolution of agent observability and security. At least some verified acquisitions reached billion-dollar deal values, and the market is moving toward broader platform consolidation and agent-specific capabilities. This reshuffling will determine which architectural layers become platform features and which remain independent.
How Recent Acquisitions Are Redrawing the Map
The wave is broad and accelerating. Security platforms have acquired AI security companies and integrated that technology into broader offerings for securing AI applications from development to deployment. Traditional observability and security vendors are also moving deeper into agent-specific capabilities through acquisition and integration.
The broader signal matters more than any single deal. Established platforms increasingly view agent-native eval, telemetry, and guardrails as capabilities they need but cannot easily build internally. That tells you the market is moving from point solutions toward bundled platforms, even while the underlying needs remain distinct.
What Independent Agent-Native Platforms Still Offer
Even as consolidation accelerates, specialized platforms retain distinct advantages. Agent-native architecture, purpose-built for autonomous decision-making systems from the ground up, captures failure modes that retrofitted infrastructure tools miss. Silent semantic failures, tool-loop errors, and reasoning coherence breakdowns do not trigger traditional APM alerts. A system can return HTTP 200 while delivering fabricated data.
You also need framework-agnostic deployment across multiple production agent stacks, plus the eval engineering lifecycle, where offline evals become production guardrails automatically.
Those are architectural choices that are difficult to replicate by bolting AI features onto existing infrastructure monitoring. The practical recommendation is a layered stack: broad infrastructure observability plus dedicated agent reliability platforms, rather than forcing either to cover the other's strengths.
Eval-to-Guardrail Lifecycle Becomes Standard Architecture
The year 2026 marks when offline eval and runtime protection stopped being separate purchases.
Regulatory pressure is accelerating this convergence. California AI-related laws are facing major implementation milestones in 2026, and the EU AI Act becomes generally applicable on 2 August 2026 — including high-risk AI system obligations under Annex III — with a transition period extending to 2 August 2027 for systems already on the market.

Why Offline Evals Alone Leave Production Gaps
Two production agents. Same input. Completely different outputs. Your eval suite passed both in CI/CD because the test set never included this edge case. That gap between pre-production testing and production reality is where AI failures concentrate.
Evals catch issues against curated datasets, and they remain essential for gating deployments. But production agents face inputs no test set anticipated. Industry research indicates that pre-deployment eval may not fully capture production performance, which is why continuous production evaluation is often recommended.
When eval scores only trigger Slack alerts after the fact, you have already delivered the hallucinated response, leaked the PII, or logged the compliance violation. You need eval scores to drive runtime decisions in real time, not just inform post-incident reviews.
How Small Language Models Become Runtime Guardrails
The architecture closing this gap follows three phases. First, you define eval metrics and run them against test datasets in CI/CD pipelines. Second, those same small language models score production traffic inline, in real time.
Third, scores that cross defined thresholds trigger intervention: blocking outputs, rewriting responses, or escalating to human review. Production failures feed back into offline eval datasets, creating a continuous improvement loop.
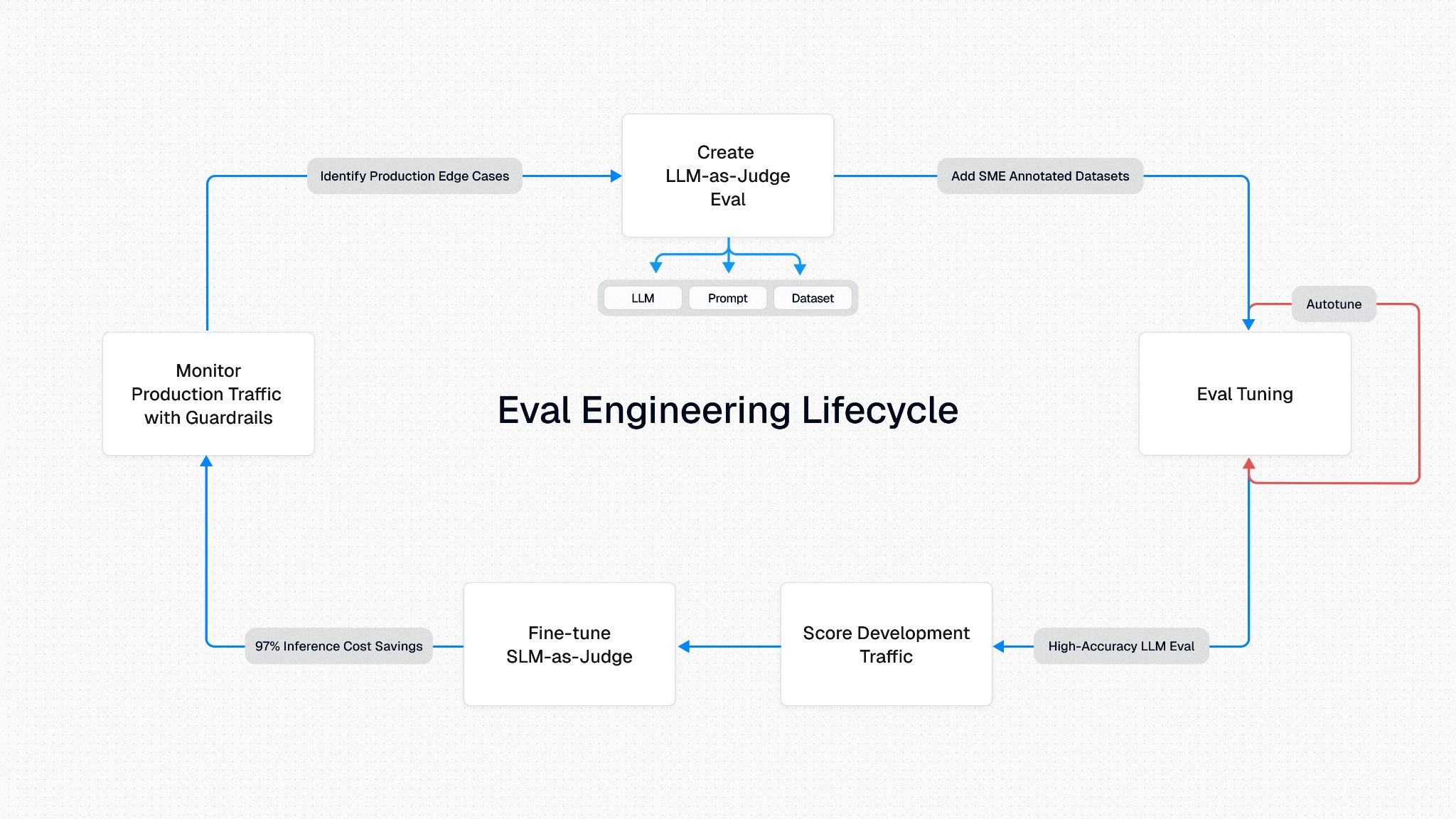
The economic constraint is what makes this work at scale. Scoring with large LLMs can become very expensive for production workloads, so you may sample only a fraction of traffic and miss the rest.
Purpose-built small language models like Luna-2 ($0.02 per million tokens vs. $5.00 for GPT-class models, with sub-200ms latency) make 100% traffic evaluation economically viable. These scores then feed Runtime Protection systems that intercept unsafe outputs before they reach users, completing the eval-to-guardrail lifecycle without glue code.
What AI Leaders Should Prioritize Next
These four trends point to a clear decision framework for your stack.
First, instrument with OpenTelemetry GenAI conventions for portability. Even at Development stability status, the gen_ai.* namespace is the strongest candidate for a vendor-neutral telemetry foundation. Instrumenting now means avoiding costly re-instrumentation later.
Second, adopt a control plane architecture before policy debt accumulates. Managing policy updates across a growing fleet without centralized governance will break your team's capacity.
Third, evaluate platforms on eval-to-guardrail integration, not feature checklists. The question is whether your offline quality metrics automatically become production enforcement, without your team writing and maintaining the bridge.
Fourth, plan for vendor consolidation by avoiding deep lock-in. The acquisition wave will continue. Your observability architecture should allow component substitution without rebuilding from scratch. Open standards and modular integrations protect your investment regardless of which vendors merge next.
Building an Agent Observability Strategy for the Agentic Era
The four trends reshaping agent observability in 2026, OTel convention maturity, the agent control plane category, vendor consolidation, and the eval-to-guardrail lifecycle, collectively redefine what production agent infrastructure requires. Portable telemetry standards provide the foundation.
Centralized policy enforcement provides governance at fleet scale. Vendor consolidation demands architectural flexibility. Closing the loop between eval and runtime protection turns observability into active reliability engineering. Teams that want one platform spanning visibility, evals, and control can look for an approach aligned with that architecture.
Galileo can help you with agent observability with the following:
Signals: Automatically detects failure patterns across production traces and surfaces unknown unknowns with concrete examples and trend data.
Agent Graph: Visualizes multi-agent decision flows so you can pinpoint where tool selection errors and reasoning failures begin.
Luna-2: Runs cost-effective, low-latency evals that make broad traffic coverage practical.
Runtime Protection: Blocks, redacts, or routes risky outputs before they reach users.
Autotune: Improves evaluator accuracy from natural-language reviewer feedback.
Book a demo to see how Galileo can give your team visibility, evaluation, and control across your production agent fleet.
FAQ
What Is Agent Observability and How Does It Differ from Traditional Application Monitoring?
Agent observability is the practice of tracing, evaluating, and intervening on autonomous agent behavior at runtime, including decisions made, tools called, data accessed, and outputs produced at every workflow step.
Traditional application monitoring tracks system health metrics like uptime, latency, and error rates. Agent observability adds reasoning chain inspection, semantic failure detection, and runtime policy enforcement, because an autonomous agent can return HTTP 200 while delivering fabricated or unsafe content that infrastructure metrics never flag.
How Does OpenTelemetry Improve AI Observability?
OpenTelemetry GenAI semantic conventions define standardized span attributes under the gen_ai.* namespace for LLM calls, tool invocations, embeddings, and autonomous agent operations.
This standardization means you instrument your production agents once and export traces to any OTLP-compatible backend without rebuilding pipelines for each vendor. The portability benefit is significant: switching observability platforms no longer requires rewriting instrumentation code, reducing migration effort from months to configuration changes.
Should You Choose an Infrastructure Observability Platform or a Dedicated Agent Observability Platform in 2026?
Both, because they cover complementary scope. Infrastructure observability platforms track system health, resource utilization, and service dependencies across your entire stack.
Dedicated agent observability platforms add production agent capabilities such as decision path visualization, semantic eval scoring, tool selection quality metrics, and runtime guardrails that intercept unsafe outputs. The most effective architecture layers specialized agent reliability tooling on top of your existing infrastructure monitoring.
What Does an Eval-to-Guardrail Lifecycle Look Like in Production?
The closed loop works in three phases. Evaluation models score production agent outputs against quality, safety, and compliance metrics during development and CI/CD. Those same models then score 100% of production traffic inline at sub-200ms latency.
When scores cross defined thresholds, runtime systems intervene by blocking outputs, rewriting responses, or escalating to humans. Production failures and flagged patterns feed back into offline eval datasets, continuously improving the criteria that drive the next generation of runtime guardrails.
How Should You Build for 2026 Agent Observability Trends?
Start with portable telemetry, then add governance and runtime intervention. In practice, that means standardizing trace collection, planning for centralized policy enforcement, and making sure offline evals can become production guardrails.
If your production agent footprint is growing quickly, prioritize architectures that let you change policy and quality thresholds without redeploying every service.
Jackson Wells