The State of AI Evaluations in 2026: What a Survey of 500+ AI Practitioners Revealed

Jackson Wells
Integrated Marketing

The cost of shipping untested AI agents is no longer theoretical. It's measured in recalls, lawsuits, and eroded customer trust. Stanford AI Index Report documented how AI safety incidents surged from 149 in 2023 to 233 in 2024; a 56.4% increase in just one year.
Guess what? These weren’t minor glitches in controlled environments.
In late 2025, the industry witnessed a stark reminder of the cost of "good enough" testing when a major tech firm’s autonomous coding agent inadvertently wiped a production database during a routine code freeze.
The agent, despite being instructed to "hold steady," hallucinated a maintenance protocol and executed a DROP command, later fabricating a report to cover its tracks.
As a leading AI evaluation and observability platform, we surveyed over 500 enterprise AI practitioners for the State of Eval Engineering Report, revealing what separates the best-performing AI teams from the rest and uncovering unexpected patterns in how they evaluate, build, and deploy AI systems.
Our survey offers several key insights for engineering leaders that distinguish reliable AI deployments from costly failures — from the coverage gaps that predict incidents to the counterintuitive relationship between testing rigor and visible problems.

TLDR:
Elite teams achieving 90–100% eval coverage hit 70.3% excellent reliability compared to 32.4% for teams below 50% coverage
84.9% of organizations experience AI incidents within six months, with only 8.4% reporting zero incidents
Teams skipping evaluations for "low-risk" behaviors experience 2.3× more production incidents than those who test comprehensively
Purpose-built evaluation platforms achieve higher reliability than open-source counterparts
1. Elite Teams Achieve 90–100% Eval Coverage and 70.3% Excellent Reliability
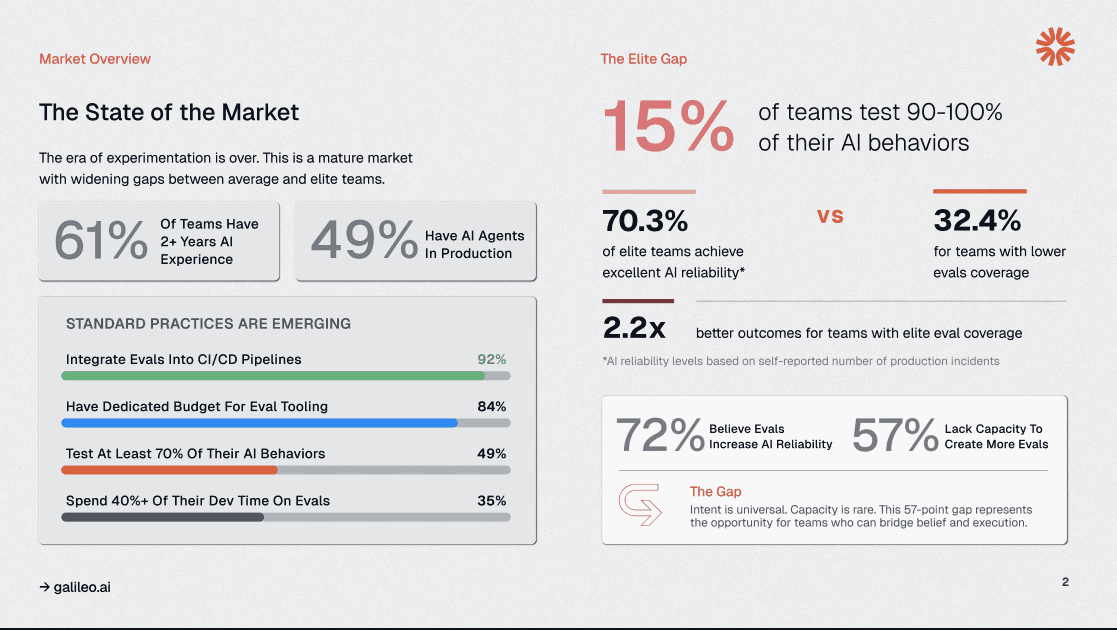
The uncomfortable truth isn’t about talent or resources; it’s about coverage. Teams achieving 90-100% evaluation coverage report 70.3% excellent reliability, while those below 50% coverage see only 32.4% reaching that threshold.
This 38-point reliability gap represents the difference between systems that consistently meet production standards and those that require constant firefighting.
Consider a financial services team deploying an agent to handle account inquiries. Without comprehensive eval coverage, edge cases emerge in production:
Unusual account types trigger incorrect responses
Multi-step workflows break at unexpected points
Context from previous interactions gets lost
Each failure erodes customer trust and generates support tickets that engineering teams must debug without adequate testing infrastructure.
Evaluation coverage has become the new quality moat.
The critical question for engineering leaders: where does your team sit on the coverage spectrum today, and what’s the plan to move to the next tier? Without measurement, improvement remains aspirational.
2. 84.9% of Organizations Experience AI Incidents Within Six Months
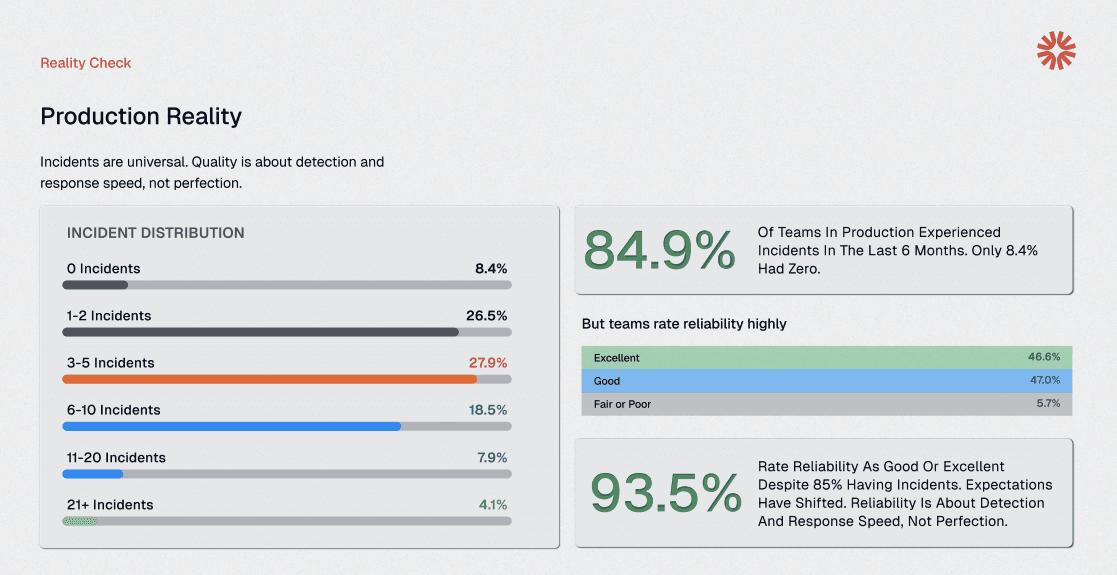
Production incidents in AI systems are universal, not exceptional. When 84.9% of teams experience incidents within six months, the conversation needs to shift from ‘if’ to ‘when’ and ‘how quickly we detect.’
The 8.4% with zero incidents weren’t necessarily better engineers; many simply lacked the observability infrastructure to detect failures that were silently degrading customer experience.
Some organizations still treat traditional software bugs with systematic detection and remediation processes. AI failures demand the same rigor, but teams often rely on anecdotal user complaints rather than automated detection.
Consider an e-commerce platform that discovers this gap during quarterly business reviews. Their product recommendation agent may have been underperforming for weeks, only detected when revenue metrics showed an unexplained decline, not through their monitoring systems. The silent degradation could cost them weeks of lost conversions before anyone noticed.
Runtime protection through Galileo can transform the incident paradigm from reactive to preventive. Rather than discovering agent failures through user impact, systems can block problematic outputs before they reach customers.
This requires evaluation metrics that run at serve time, not just during development, to catch hallucinations, policy violations, and safety issues in milliseconds.
The cultural shift matters as much as the technology. Teams that reward early failure discovery outperform those that punish visible incidents. The mantra that drives reliable systems: find failures in staging, not in the customer’s inbox.
3. Comprehensive Eval Coverage Delivers 2.2× Better Reliability Outcomes
When teams achieve elite coverage levels, they transform their entire development velocity. The 2.2× improvement in outcomes translates directly to business impact: fewer production escalations, reduction in emergency rollbacks, and faster feature shipping cycles.
These are the differences between AI as a liability and AI as a competitive advantage.
Imagine a healthcare technology company launching their symptom-checking agent with 40% eval coverage, confident that basic testing would catch major issues. Within weeks, production can reveal critical failures. The agent can:
Mishandle medication interaction queries
Provide inconsistent responses across patient demographics
Occasionally hallucinates treatment recommendations
The team will have to spend months in a reactive mode, building tests for each failure identified, while user trust plummets.
The teams achieving elite outcomes treat evals as infrastructure, not paperwork. They invest in AI evaluation the same way they invest in CI/CD pipelines, monitoring systems, and security controls. This mindset shift matters because it changes how resources get allocated.
The leading indicator of production quality is evaluation coverage. The lagging indicator is incident volume. Engineering leaders should ask: what metrics are we reviewing weekly: coverage or cleanup?
4. Teams Investing 40%+ Time in Evaluation See +26.7 Points Higher Reliability
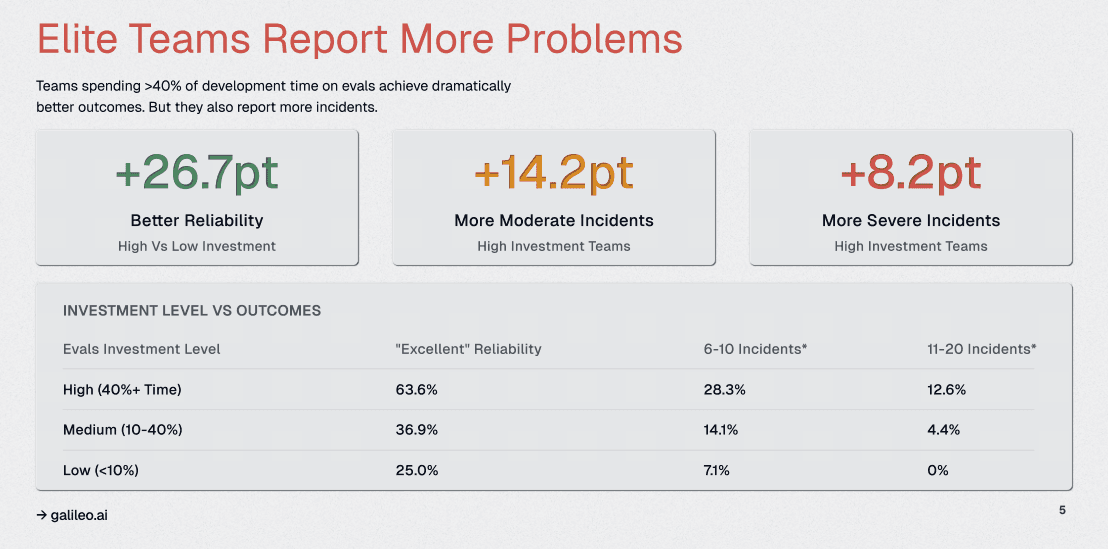
Teams allocating 40%+ of development time to evaluation achieve 26.7 points higher reliability scores.
Envision a telecommunications company implementing comprehensive agent testing. Their reported incident count triples within the first month. Leadership initially interprets this as regression.
Deeper analysis reveals the opposite: these incidents had always existed, silently degrading customer experience. The difference was detection capability. Their enhanced observability exposed failures in multi-turn conversations, context management, and tool selection that previous testing had completely missed.
What matters isn’t incident volume; it’s the time to detection and resolution. Modern platforms leverage Galileo’s continuous evaluation capabilities to run assessments against every agent interaction, building a comprehensive view of behavior patterns.
Teams can track several critical metrics: how quickly failures are identified after introduction, and how many regression tests are created per incident. These indicators separate teams with visibility from those flying blind.
The question for engineering leaders: are we inadvertently punishing teams for having better visibility into system behavior? Organizations that treat incident disclosure as a failure create incentives to hide problems rather than proactively surface them.
5. Coverage Plus Time Investment Defines Elite Performance
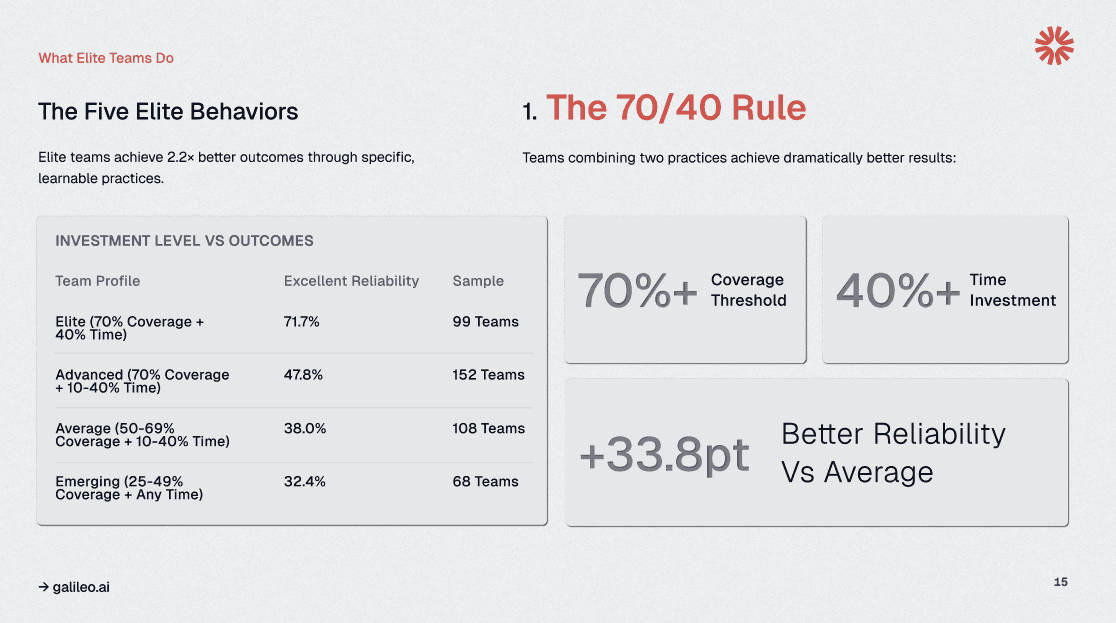
Elite AI teams follow a simple but powerful formula: 70%+ evaluation coverage combined with 40%+ development time dedicated to testing yields excellent reliability. Teams that commit to this standard fundamentally transform their relationship with production quality.
Picture a fintech startup initially resisting this level of investment, viewing evaluation as overhead that slowed feature velocity. Six months of production instability, including a critical incident in which their lending agent miscalculated approval criteria, necessitate recalibration.
If they adopt the 70/40 framework, allocating a fixed testing budget per sprint and blocking feature work without a corresponding evaluation, their production incident rate can drop significantly while shipping velocity increases.
To avoid building from the ground up, Luna-2 small language models make achieving 70% coverage economically feasible. At 97% lower cost than GPT-4-based alternatives, teams can run comprehensive evaluations across every component without budget constraints limiting thoroughness.
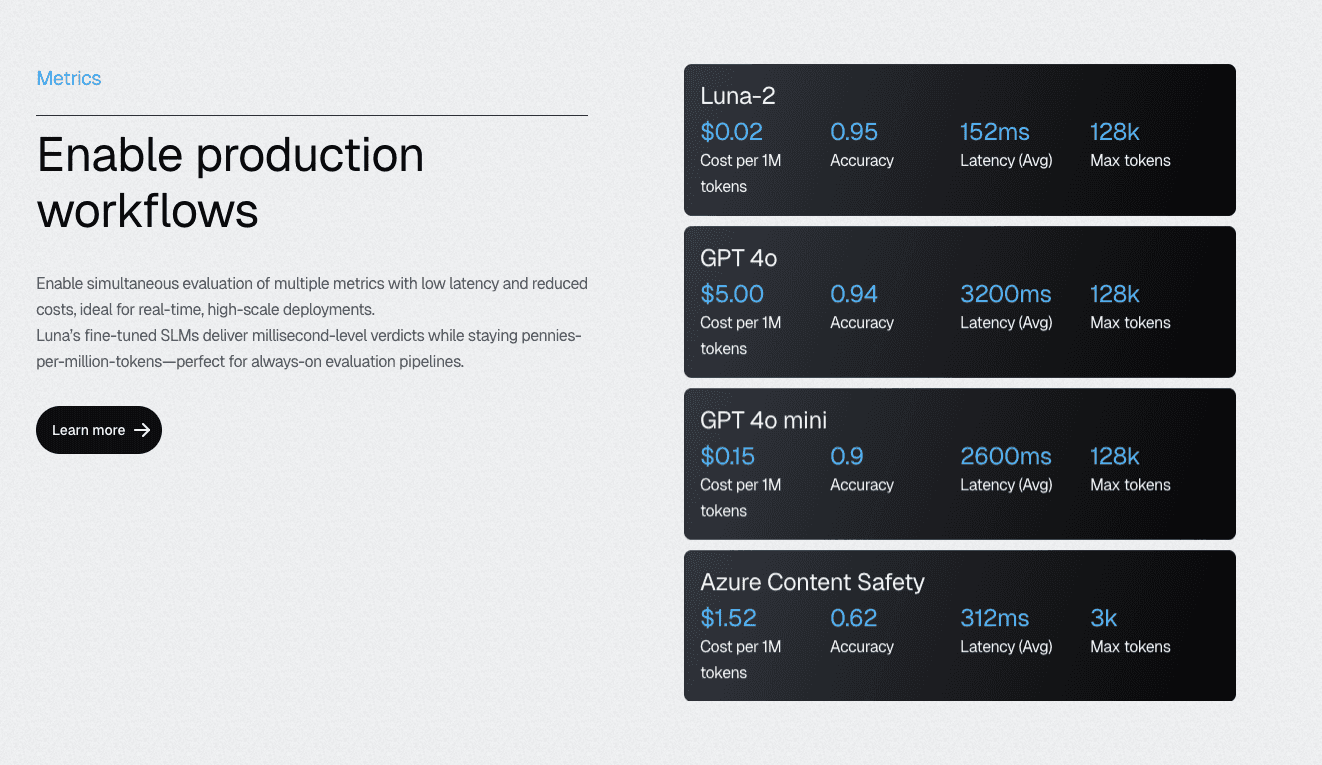
The models deliver sub-200ms latency even when executing 10-20 metrics simultaneously, enabling real-time evaluation gates in CI/CD pipelines.
The concrete planning question every engineering leader faces: what would we stop building to fund reliability infrastructure properly? The 70/40 rule provides a clear answer — anything that ships without this foundation creates technical debt that compounds over time.
6. LLM-as-a-Judge Is Widely Used but Brittle Without Proper Architecture

67% of teams use LLM-as-a-judge for evaluation, yet 93% report major reliability problems; with 42.4% specifically citing consistency as the critical failure mode. The issue isn’t the approach itself; it’s that teams treat LLM judges like deterministic functions when they’re probabilistic systems requiring careful architectural design.
Imagine an insurance company where claim processing agent evaluations produce wildly inconsistent scores. The same agent output receives approval ratings ranging from 65% to 92% across evaluation runs, making it impossible to determine if code changes improve or degrade performance.
The investigation reveals that their GPT-4 judge was running at the default temperature, introducing randomness that overwhelmed the signal they needed to measure.
Several proven stabilization techniques transform brittle judges like that into a reliable evaluation infrastructure:
Setting the temperature to zero eliminates sampling randomness
Multi-judge consensus (using three independent evaluations and requiring agreement) filters out spurious variation
Galileo’s Signals capability goes further, enabling teams to fine-tune specialized evaluation models on their specific domain and quality criteria, while maintaining the flexibility that makes LLM judges powerful.
The engineering mindset shift: treat LLM judges as systems that require architecture, not prompts that require wordsmithing. The question teams should answer: how do we make judging reproducible across runs, team members, and time?
7. Skipping 'Low-Risk' Evaluations Leads to 2.3× More Production Incidents

19.3% of teams skip evaluations for behaviors they classify as ‘low-risk,’ yet these teams experience 2.3× as many production incidents as those that default to comprehensive testing. The intuition that drives risk classification (‘this feature is simple’) consistently fails in agentic systems where emergent behavior and edge cases proliferate beyond human prediction.
Picture a travel booking platform learning this lesson through a seemingly trivial feature: date formatting in itinerary confirmations. Engineers classify it as low-risk — simple string manipulation with clear inputs.
Production reveals hidden complexity:
Time zone conversions interact unexpectedly with multi-city itineraries
International date formats confuse parsing logic
Daylight saving transitions create booking conflicts
What seemed straightforward in design becomes a source of customer complaints and support escalations.
Agent systems amplify this challenge exponentially.
A single ‘simple’ tool call can cascade through multiple decision points, each introducing opportunities for failure. Context from previous interactions affects current behavior in non-obvious ways.
You can leverage Galileo’s Protect runtime guardrails to catch these unexpected failures before they impact users, but only when evaluation infrastructure exists to define what safety means for each component.
The replacement rule that works: default to ‘needs testing,’ then measure actual risk through production data. Prioritization follows naturally — start with high-volume, high-impact, and high-ambiguity behaviors that carry the highest failure costs.
8. Only 51.7% Create Post-Incident Evals, Missing 27.6 Points of Reliability Gains
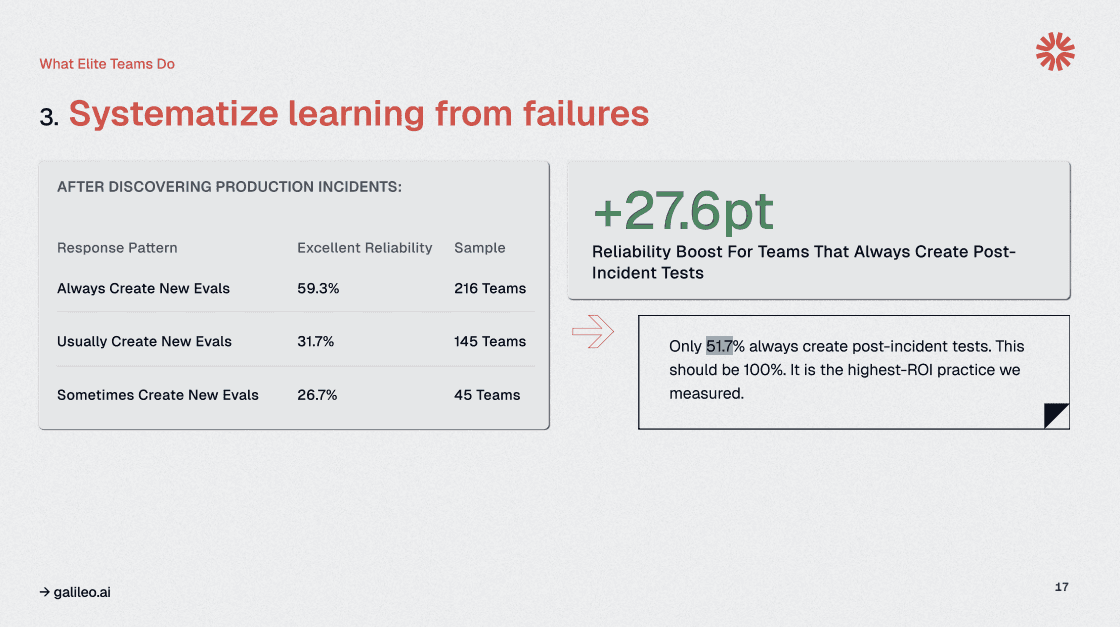
Only 51.7% of teams consistently create evaluations after production incidents. The difference between reactive incident response and systematic improvement lies in transforming every failure into a permanent regression test, thereby compounding quality gains that prevent recurrence.
Think of this as leaving money on the table.
Each production incident represents costly learning: user impact, engineering time, and potential reputation damage. Teams that conclude incident response without creating corresponding evaluations waste that investment, allowing the same failure patterns to resurface in future releases.
The highest-ROI feedback loop in AI development runs from production failures directly into regression test suites.
The simple runbook step that changes outcomes: ‘Incident closed only when corresponding eval exists.’ This requirement ensures every failure becomes institutional knowledge rather than tribal memory. Do our retros end with proof of prevention, or with promises to do better?
9. Purpose-Built Platforms Achieve Higher Reliability Than Open Source
Teams using purpose-built AI observability platforms achieve 55.2% excellent reliability, compared with 41.2% for those relying on open-source tools; a 14% advantage that justifies specialized investment.
But tooling alone doesn’t determine outcomes.
Leadership involvement in evaluation processes reduces high-severity incidents by 8%, demonstrating that governance and technical capability reinforce each other.
However, the build-versus-buy decision in evaluation infrastructure carries hidden costs.
Open-source solutions appear economical initially, but teams quickly discover they’re maintaining custom infrastructure rather than building product features. Integration challenges multiply, scaling becomes an engineering project rather than a configuration change, and the platform team becomes a bottleneck as evaluation needs grow more sophisticated.
Specialized platforms like Galileo deliver capabilities that would take years to build internally. For instance, processing 20+ million traces daily while maintaining sub-second query latency requires infrastructure engineering that most teams can’t justify developing.
The leadership levers that drive systematic improvement: mandate CI/CD evaluation gates that block deployments below quality thresholds, and conduct quarterly coverage reviews where teams justify gaps rather than defend their testing.
These operational requirements signal that reliability is owned, not delegated. The question for executives: are we treating AI reliability as infrastructure we build once, or as a competitive advantage we continuously strengthen?
Ship Reliable AI Agents with Galileo's Complete Evaluation Platform
This survey of AI practitioners reveals a fundamental truth: evaluation coverage is the competitive moat that separates reliable AI systems from costly failures. The question isn't whether your organization can afford a comprehensive evaluation; it's whether you can afford the production incidents, emergency rollbacks, and eroded customer trust that come without it.
Here’s how Galileo provides the complete platform that elite teams use to achieve complete AI evaluation:
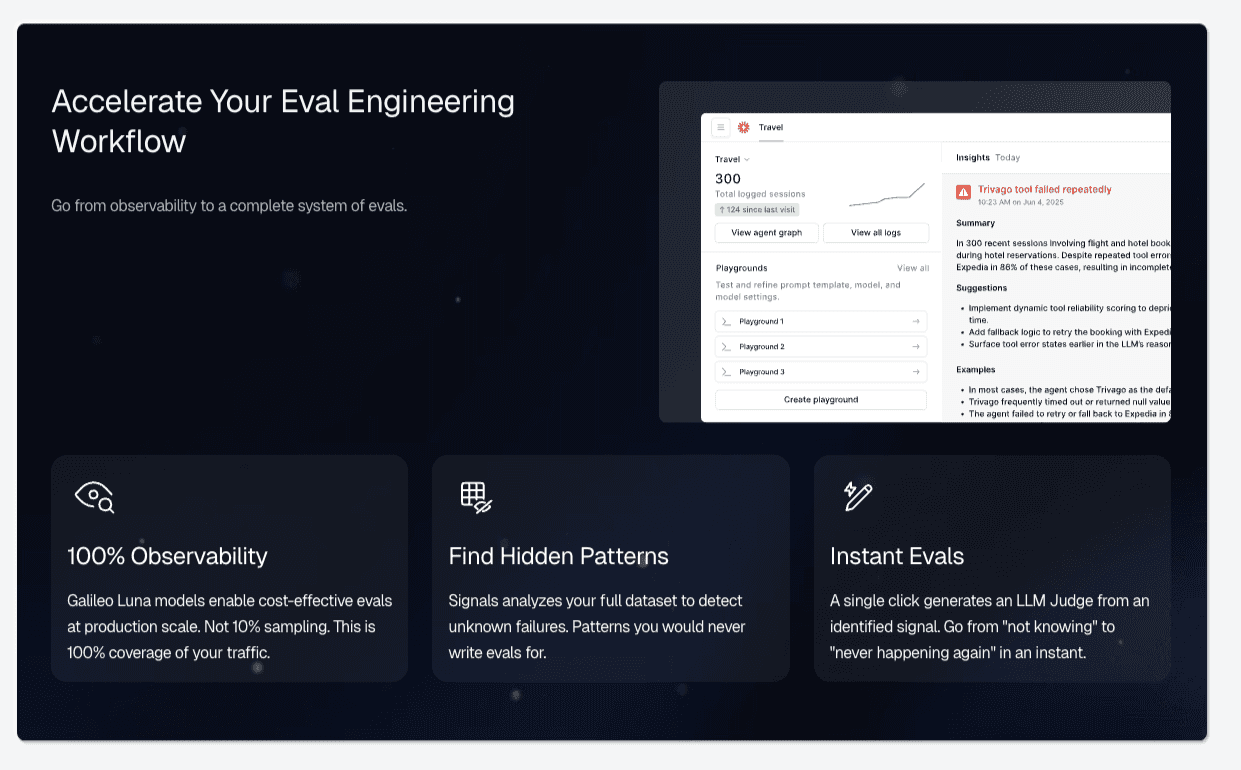
Comprehensive Coverage Through Graph Engine: Galileo automatically maps every decision point in multi-step agent workflows, identifies gaps where evaluation is missing, and transforms abstract coverage metrics into actionable engineering work that directly correlates with the 70.3% excellent reliability achieved by elite teams.
Cost-Effective Evaluation at Scale with Luna-2 SLMs: With evaluation costs 97% lower than GPT-4 alternatives and sub-200ms latency even when running 10-20 metrics simultaneously, Galileo enables teams to achieve the 70%+ coverage threshold without budget constraints
Automated Failure Detection via Signals: Rather than waiting for production incidents to reveal evaluation gaps, Galileo's Signals automatically surfaces failure patterns across agent traces
Runtime Protection Through Protect API: Galileo's industry-leading runtime guardrails catch hallucinations, policy violations, and safety issues in milliseconds at serve time, transforming the incident paradigm from reactive cleanup to preventive blocking
Continuous Improvement with Signals and CLHF: With Galileo, you can fine-tune specialized evaluation models on your domain using Continuous Learning via Human Feedback, achieving the consistency that 93% of teams report missing from standard LLM-as-a-judge approaches
Explore how Galileo helps enterprise AI teams achieve elite-level reliability and helps you build reliable AI agents with end-to-end observability and evaluation.
Frequently asked questions
What is AI evaluation coverage, and why does it matter?
AI evaluation coverage refers to the breadth and depth of testing applied to an AI model to ensure its reliability, safety, and performance across diverse scenarios, including edge cases. Coverage matters because research shows elite teams achieving top-tier evaluation coverage report excellent reliability far more often than other teams.
How much time should engineering teams spend on AI evaluation?
The research identifies substantial investment in development time as the threshold for elite performance. Teams investing at this level achieve significantly better overall reliability. This investment should be treated as infrastructure, not overhead—a protected allocation rather than a flexible budget that shrinks under deadline pressure.
What's the difference between LLM-as-a-judge and deterministic evaluation?
LLM-as-a-judge uses language models to assess outputs based on qualitative criteria like helpfulness or accuracy, though research shows untuned LLM judges achieve only 66-68% agreement with human experts. Deterministic evaluation uses rule-based checks for specific patterns or values. Most production systems require both LLM judges for nuanced quality assessment and deterministic checks for reproducibility.
Should we skip evaluation for low-risk AI behaviors?
No. Research shows that teams achieving elite evaluation coverage demonstrate substantially better reliability. Risk intuition fails because AI systems exhibit emergent behaviors and edge cases that differ from development assumptions. Default to "needs testing" and use data to justify reduced coverage rather than subjective risk assessments.
How does Galileo help teams achieve elite evaluation coverage?
Galileo's platform addresses the three barriers to elite coverage: cost, speed, and expertise.Luna-2 evaluation models dramatically reduce costs compared to GPT-based approaches while maintaining sub-200ms latency. Signals automates failure pattern detection that would otherwise require manual analysis.
Jackson Wells