Your Evals Are Wrong 20% of the Time. Now They Improve Every Time You Look.

Introducing Galileo Autotune: the fastest path from "this eval looks wrong" to "let’s ship!"
The dirty secret of LLM-as-judge evals
Every team shipping AI applications today uses LLM-as-judge evaluators. Context adherence. Instruction following. Tone. Toxicity. The evals run automatically, the scores populate, and everyone moves on.
Except the scores are wrong more often than anyone admits.
Apply a generic eval prompt to a new domain, and you'll find disagreements with human judgment on 20–30% of cases. Not because the metric is broken. It doesn't know your edge cases, your definitions, your standards. A context-adherence metric that works beautifully on a general Q&A feed missed the paraphrase of your strict refund policy. A tone metric built for customer support might penalize the terse responses that engineers actually want.
This isn't a hypothetical. Most eval practitioners talk of a fully manual calibration process in their how-to guides: have humans score 100–200 examples, compare to scorer outputs, calculate correlation, and refine the prompt. That’s not engineering. It’s a 2010s data science loop.
Dropbox recently published something even more revealing. When they needed to adapt their relevance judge to a new model, manual prompt iteration took one to two weeks. Every model change meant starting the tuning cycle over.
This is the reality: most teams either invest weeks of data science effort per metric, or they ship evals they don't fully trust. Neither option scales.
Why manual eval tuning breaks
The manual loop looks simple on paper. You spot a wrong score. You open the eval prompt. You edit the rubric or add an example. You re-run the eval. You check if it helped.
In practice, this cycle has three compounding problems.
It requires the wrong people. The person who knows the domain best (the subject matter expert, the policy lead, the clinician) can see that the eval is wrong. But they can't fix it. Editing an LLM-as-judge prompt requires prompt engineering skill that most domain experts don't have and shouldn't need. So the fix gets routed to a data scientist or ML engineer who has to reconstruct the domain reasoning secondhand.
It's slow and fragile. Each edit-run-check cycle takes hours. A single metric might need dozens of iterations to converge. And fixes interact: correcting one edge case can introduce regressions on another. Researchers at Berkeley have documented this dynamic as "criteria drift," where the act of grading outputs changes how you define quality, creating a loop that never fully stabilizes. Teams that cap their few-shot examples at a fixed number (15 is common) discover that newer corrections push out older ones, causing mistakes they already fixed to reappear.
It doesn't compound. Without a structured system for collecting and synthesizing feedback, each improvement is isolated. There's no flywheel. The metric doesn't get smarter over time. It just gets patched.
Introducing Galileo Autotune
Autotune closes the loop, automatically.
The workflow is three steps.
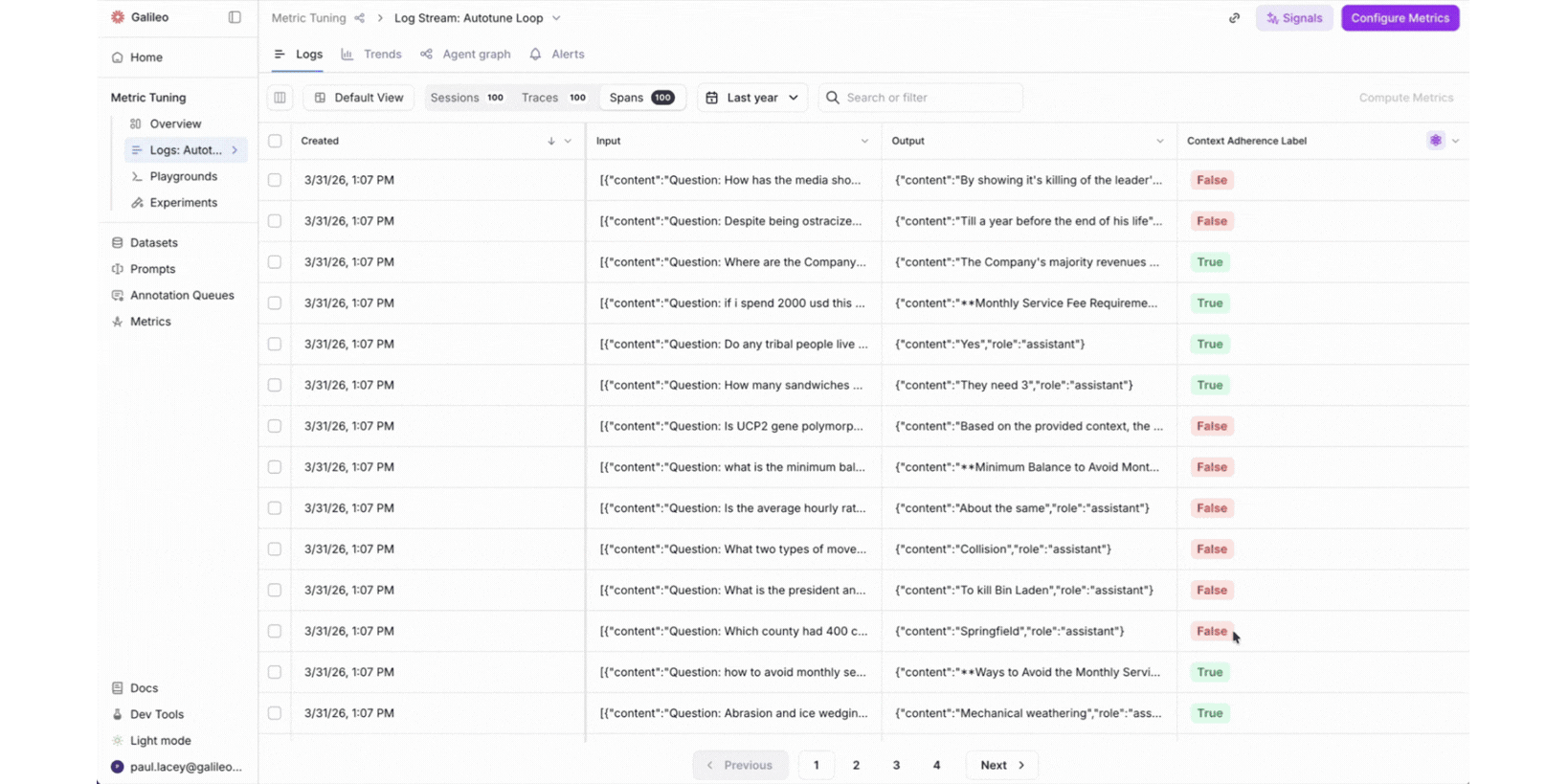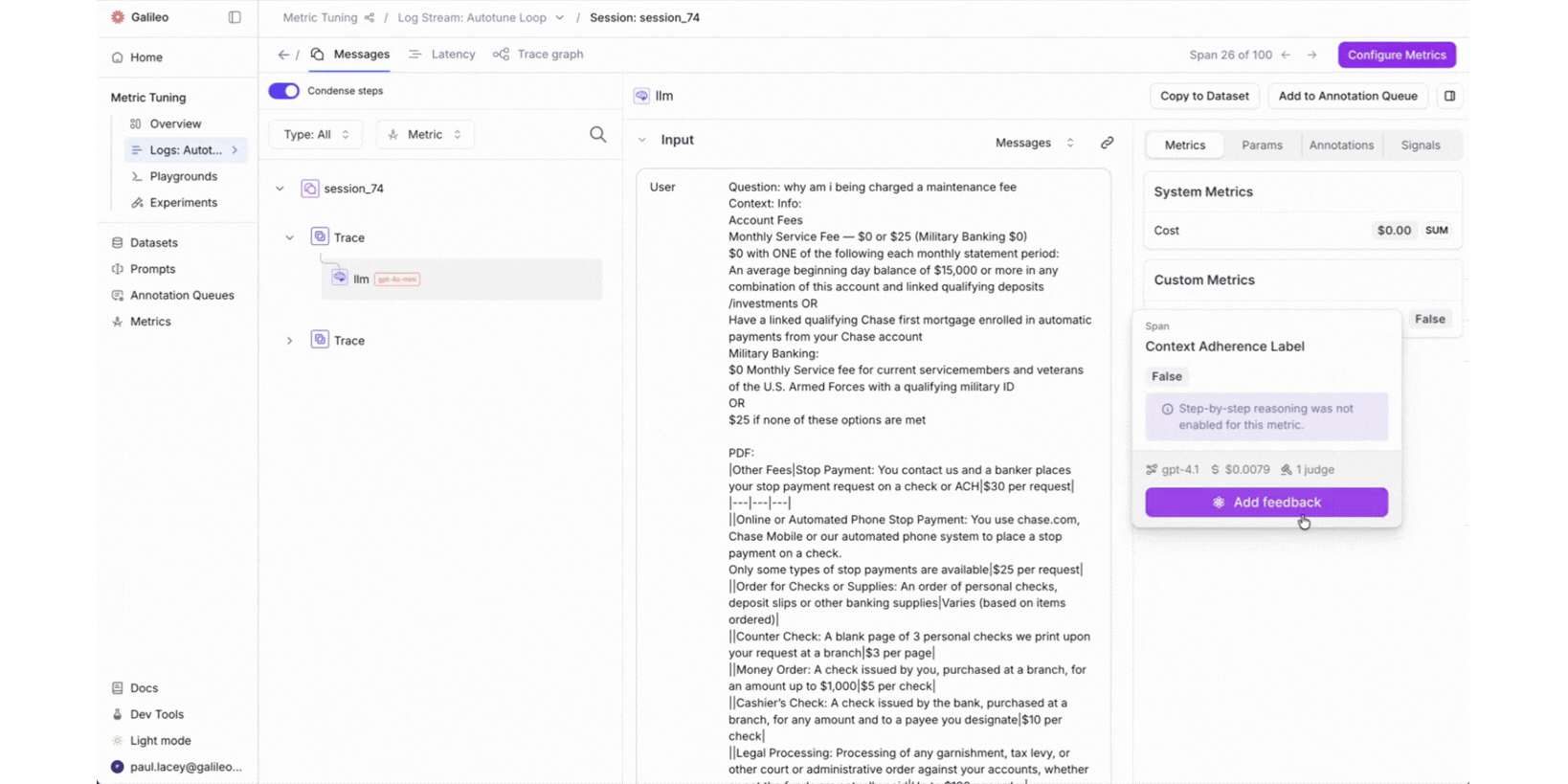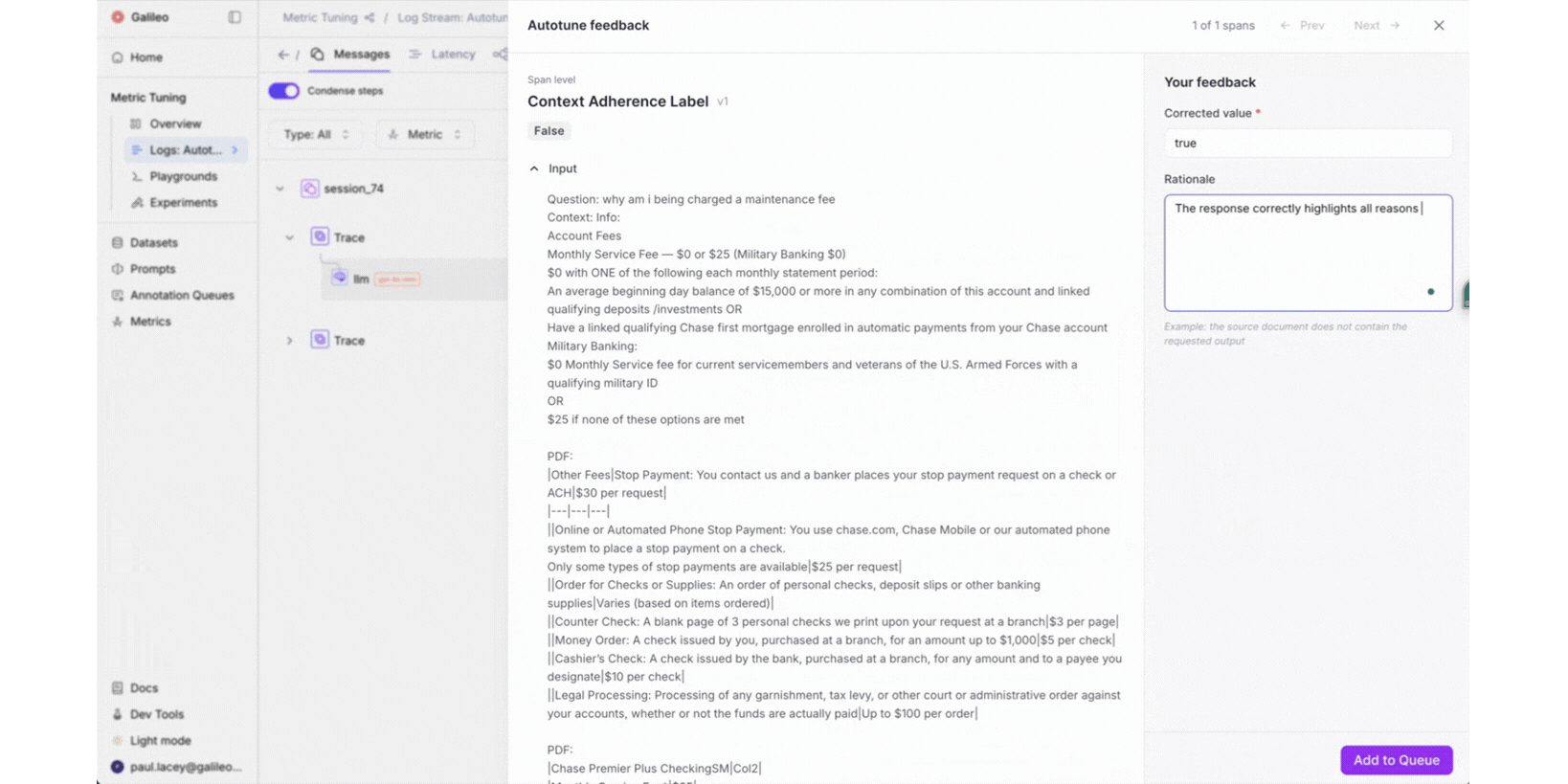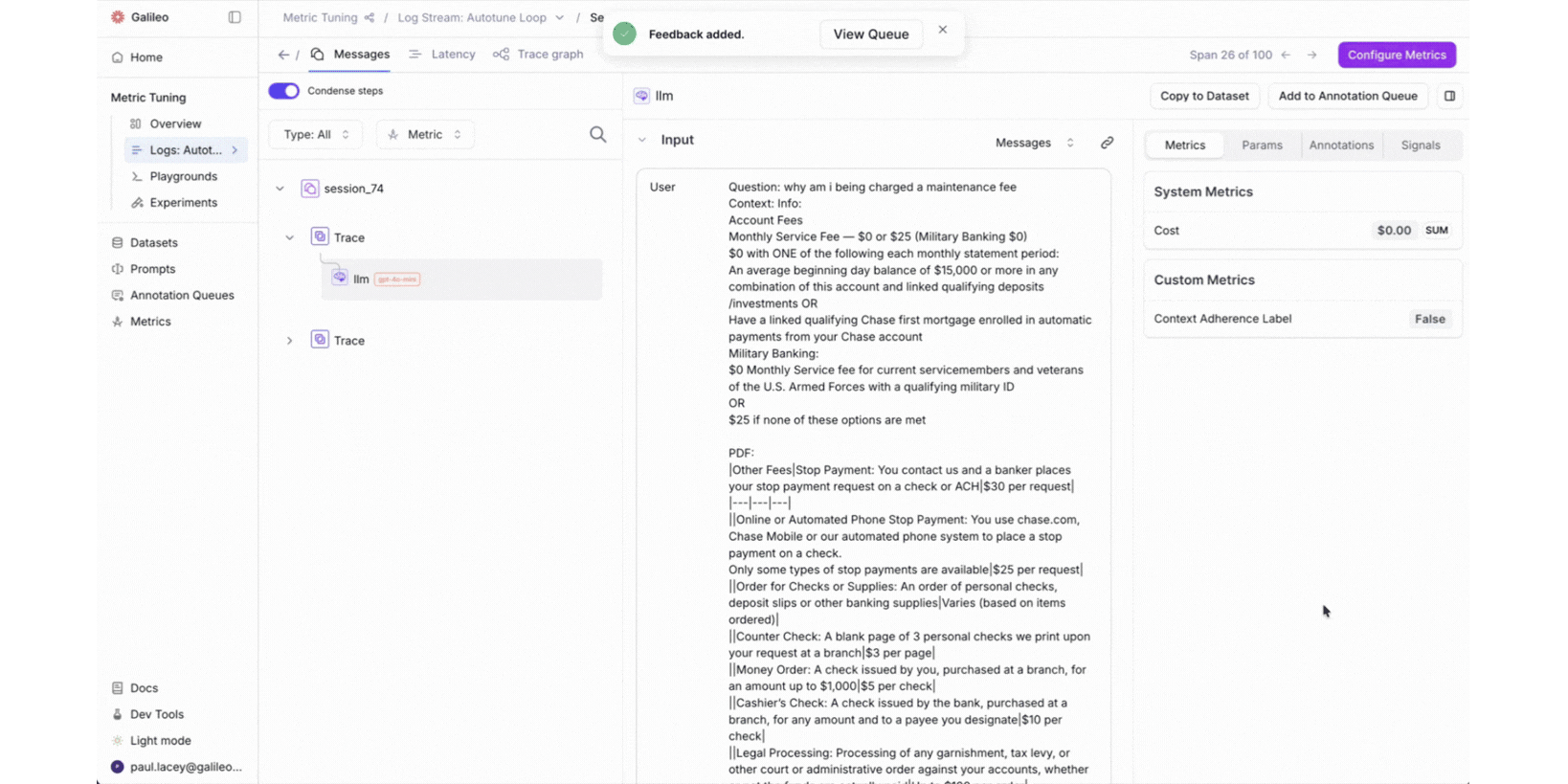
Spot and correct. When a reviewer finds an eval score they disagree with, they correct it right on the trace. They provide the value the metric should have produced and explain their reasoning in natural language. No context-switching to a separate tool. No filing a ticket. The person closest to the domain makes the call.
Autotune rewrites. Galileo aggregates all submitted feedback and rewrites the evaluation prompt: not just the few-shot examples, but the actual rubric, the instructions, the scoring criteria. Our internal research showed that prompt rewriting significantly outperforms few-shot injection alone. The system synthesizes all corrections holistically, so earlier feedback is never lost. This approach builds on a growing body of research showing that iterative, feedback-driven refinement of LLM evaluators can dramatically improve alignment with human judgment.
Test and publish. Before anything goes live, teams review the exact changes Autotune made to the prompt. They run the updated metric against test data in the eval workbench. They publish only when satisfied. If needed, they can recompute historical results with the improved metric.
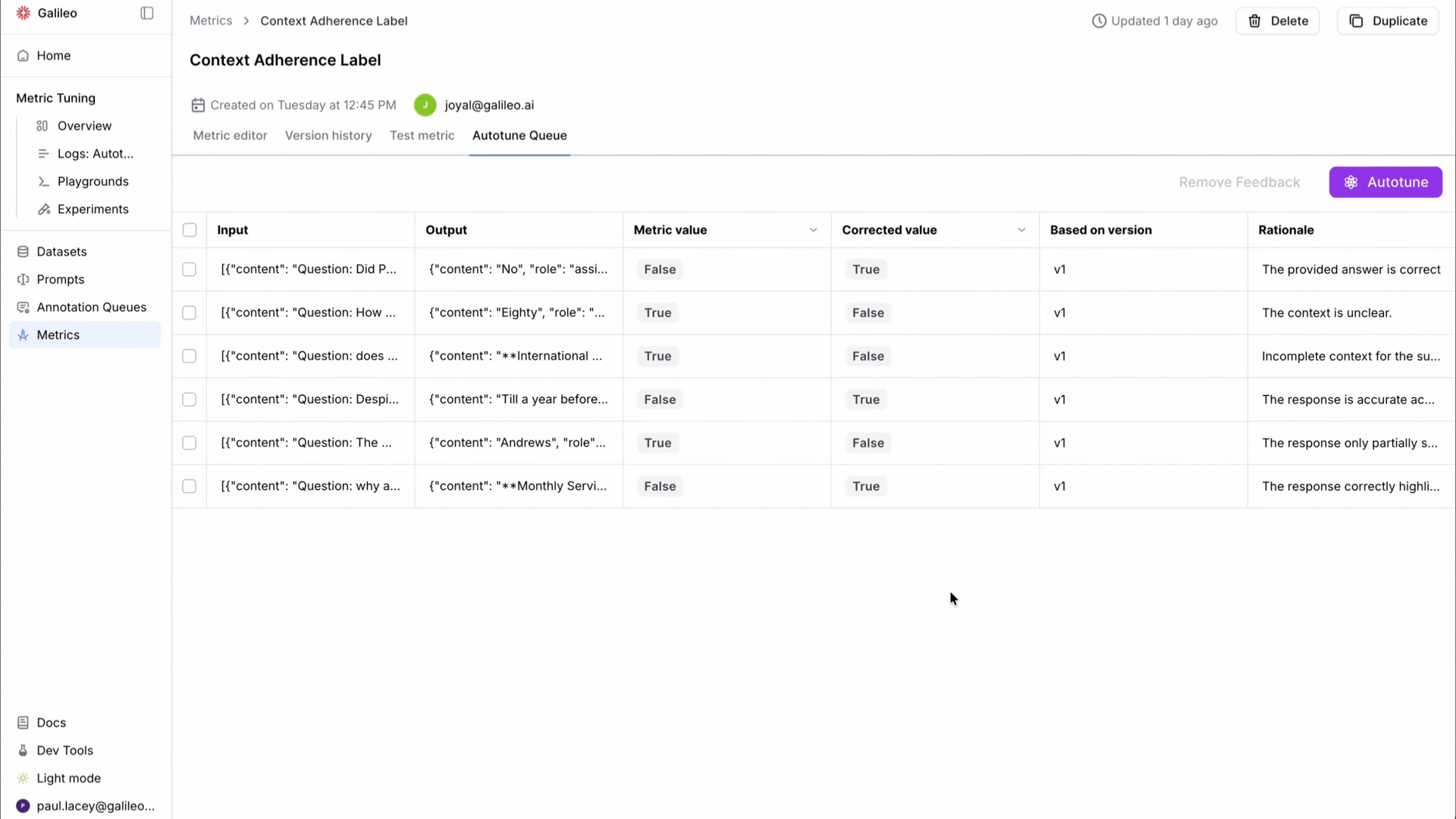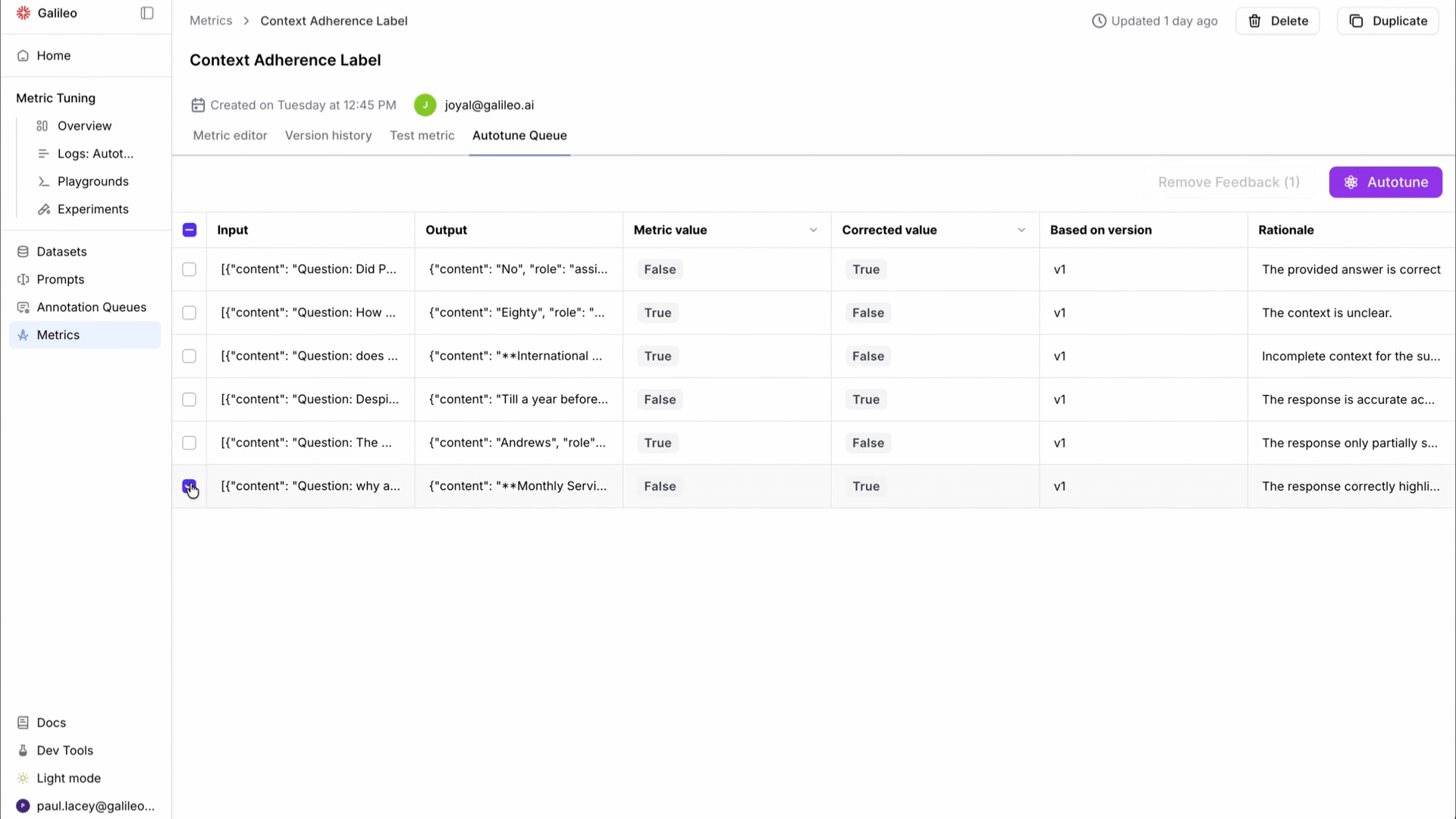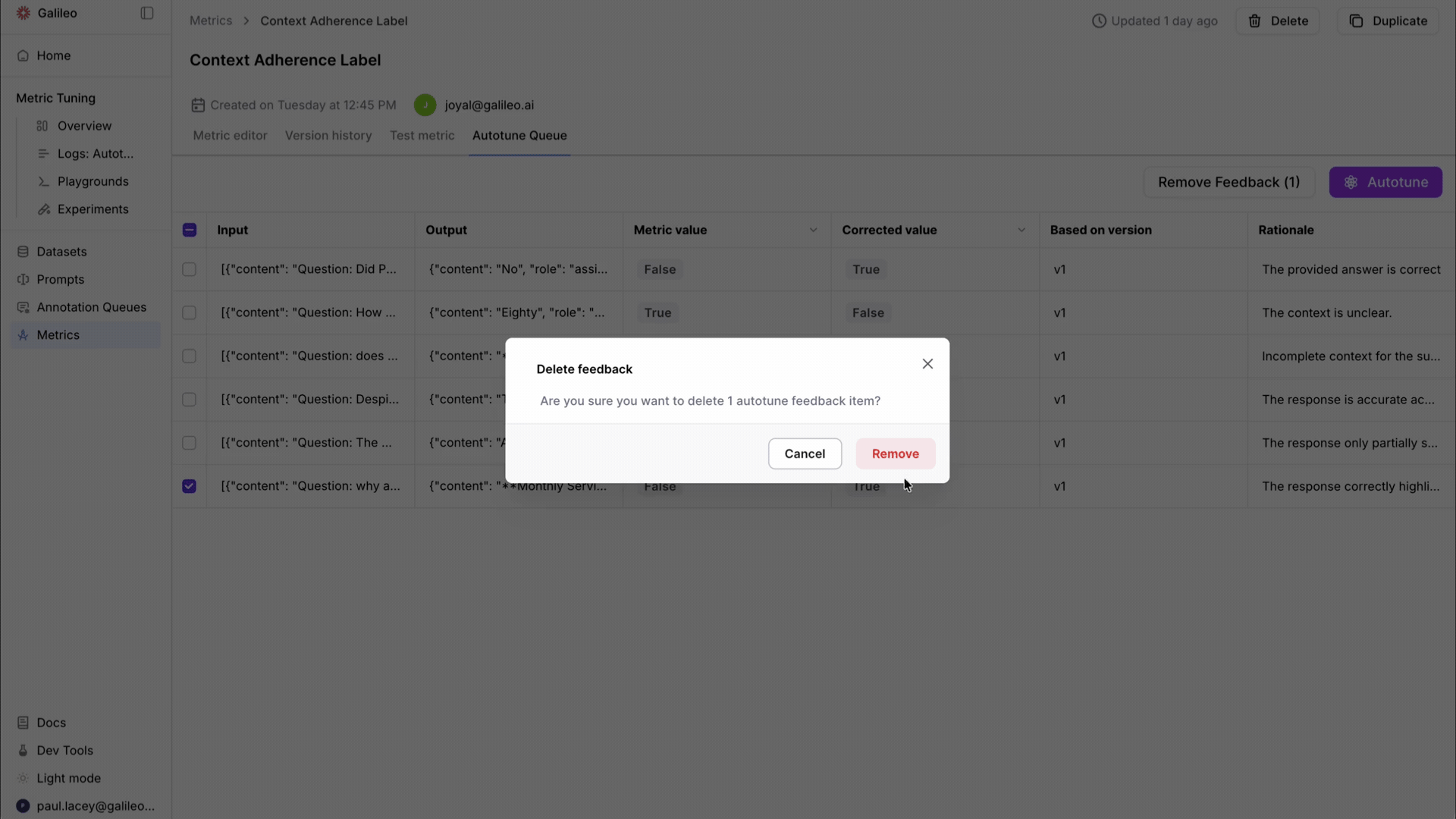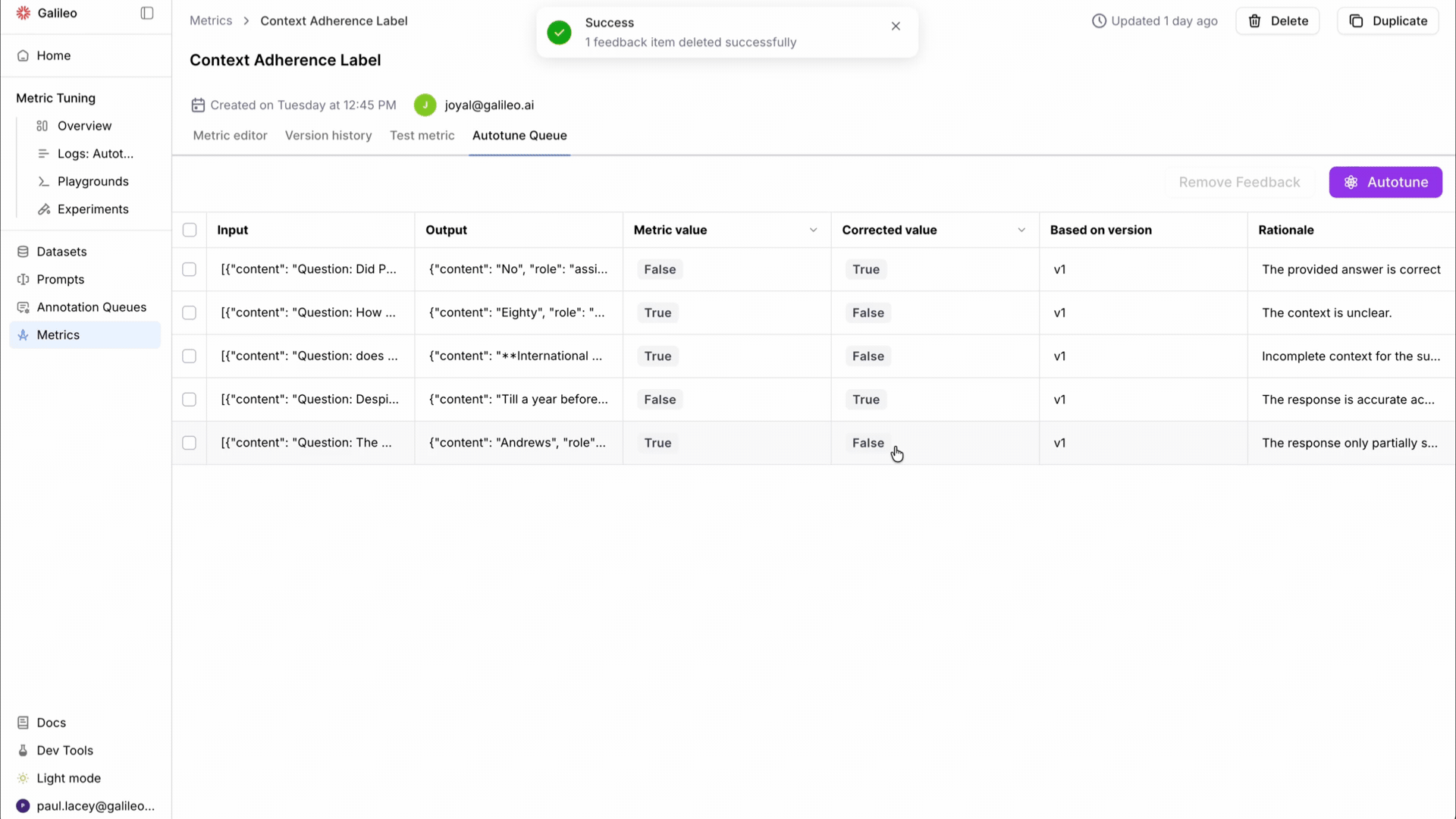
The Autotune Queue gives teams a dedicated surface for managing this entire cycle. Feedback from multiple reviewers flows into a single queue. Admins can review, approve, or reject corrections before they feed into a tuning run. The prompt diff is fully transparent: you see exactly what changed and why.
What changed under the hood
Autotune has been part of the Galileo platform since early 2025 as Continuous Learning via Human Feedback. We've rebuilt the engine with four structural upgrades based on what we learned from customers and from extensive internal research.
From few-shot injection to full prompt rewriting. The original system appended corrected examples to the eval prompt. It worked, but it couldn't change the evaluation rubric itself. The new system rewrites the scoring instructions directly, addressing systemic misalignment rather than individual cases. In our testing, prompt rewriting alone matched or exceeded the accuracy of combined prompt-plus-few-shot approaches. This mirrors what the broader prompt optimization community has found: treating prompts as tunable parameters, not static strings, produces consistently better results.
From the last 15 corrections to unlimited feedback. The original system retained only the 15 most recent corrections. Submit 20 corrections for one type of error, then 20 for another, and the first batch gets silently dropped. We tested this failure mode rigorously. In adversarial conditions, the old system's accuracy oscillated as it "forgot" and "relearned" patterns with each iteration. The new system synthesizes all feedback with no cap and no forgetting.
From invisible feedback to Autotune Queues. Previously, it was difficult to see what feedback had been submitted or to manage it across a team. Autotune Queues surface all corrections in a dedicated interface. Admins can review and approve or reject feedback before it's used, which is critical for teams where multiple reviewers contribute corrections with varying quality.
From blind publish to testing in the flow. Previously, the updated metric went live without a structured validation step. Now, teams review the prompt diff, run the metric against test data, and only publish when they're confident the changes improve performance.
The results
We tested Autotune on real enterprise evaluation datasets where the default metric had meaningful room for improvement.

On an abstention classification eval, the default metric scored an F1 of 0.87. With five annotated corrections and a single Autotune run, F1 jumped to 0.97: a 10-point improvement. On a context adherence eval, the default metric scored 0.67. Autotune lifted it 17-points to 0.84, again with just five examples.
Five examples. Not fifty. Not two hundred. That’s a meaningful number of gaps seen in a single review session. With just a sentence or two of reasoning, the eval performance achieves professional data science results from multiple rounds of manual prompt engineering.
We tested across sample sizes (5, 10, 20, 40, and 48 corrections) and found minimal performance difference beyond the first five. The system converges fast. We also confirmed it works on metrics with and without chain-of-thought reasoning, across boolean, categorical, and percentage output types, and at the span, trace, and session level.
These results aren't isolated. Dropbox published a case study showing that automated judge prompt optimization, using the same conceptual approach, reduced their scoring error by 45% and compressed their model adaptation timeline from one to two weeks down to one to two days. Their VP of Engineering described the impact as "lifting all boats" across their entire stack. A second Dropbox post on LLM-assisted relevance labeling further confirms that small sets of human-labeled examples, combined with automated prompt refinement, can scale human judgment effectively. Autotune is the most integrated, accessible implementation of this approach available today.
Get started
Autotune is available now to all Galileo users. It works on every LLM-powered metric in the platform, preset and custom, across all output types and input levels.
Start by running any eval. When you find a score you disagree with, correct it. Explain your reasoning. That's the only input Autotune needs.
For documentation and a walkthrough, visit the Autotune docs. For a guided demo, book a call with our team. And for a broader look at how evaluation fits into your AI development lifecycle, see our step-by-step LLM evaluation guide.
We built Autotune because we believe the people closest to the domain should control the quality of their evals without prompt engineering. That's how AI systems actually get better: by closing the loop between human expertise and automated evaluation, continuously, at scale.
Your evals are only as good as their fit to your data. Autotune closes the gap.

Paul Lacey