7 Best LLMOps Platforms for Scaling Generative AI

Jackson Wells
Integrated Marketing

Your production agent just called the wrong API 847 times overnight. According to S&P Global's 2025 survey, 42% of companies like yours abandoned AI initiatives in 2024-2025, doubling from 17% the previous year. LLMOps platforms address this crisis with observability, evaluation, and governance infrastructure. These tools handle non-deterministic outputs, token economics, and undetectable failures.
TLDR:
LLMOps platforms provide semantic observability beyond infrastructure metrics that miss quality degradation
Purpose-built evaluation frameworks detect hallucinations that caused $67 billion in business losses in 2024
Token-level cost tracking enables 50-90x optimization potential from ByteDance's 50% reduction to a 90x improvement case
Comprehensive compliance certifications (SOC 2, HIPAA, GDPR) are non-negotiable for your enterprise deployment
Galileo's Luna-2 models achieve 97% cost reduction versus GPT-4 alternatives
What is an LLMOps platform?

An LLMOps platform manages the complete lifecycle of large language model applications in production environments. These platforms address generative AI's distinct operational requirements: dynamic context windows, retrieval-augmented generation pipelines, prompt version control, and semantic quality monitoring.
According to Gartner's forecast, worldwide spending on generative AI models will reach $14 billion in 2025. Platforms maintain governance for regulatory compliance and scale from pilot to production.
Traditional monitoring shows 99.9% uptime but misses semantic failures. LLMOps platforms detect context relevance, hallucination rates, and response quality—revealing one prompt template consuming 80% of costs despite handling 20% of traffic.
1. Galileo
Galileo has emerged as the category leader in production-scale LLMOps, processing 20+ million traces daily with infrastructure purpose-built for enterprise generative AI deployments.
The platform's Luna-2 evaluation models represent a breakthrough in evaluation economics, delivering quality assessment at 97% lower cost than GPT-4 while maintaining sub-200ms latency. This economic advantage fundamentally changes the calculus for continuous evaluation—making systematic quality monitoring viable at enterprise scale where traditional LLM pricing would be prohibitively expensive.
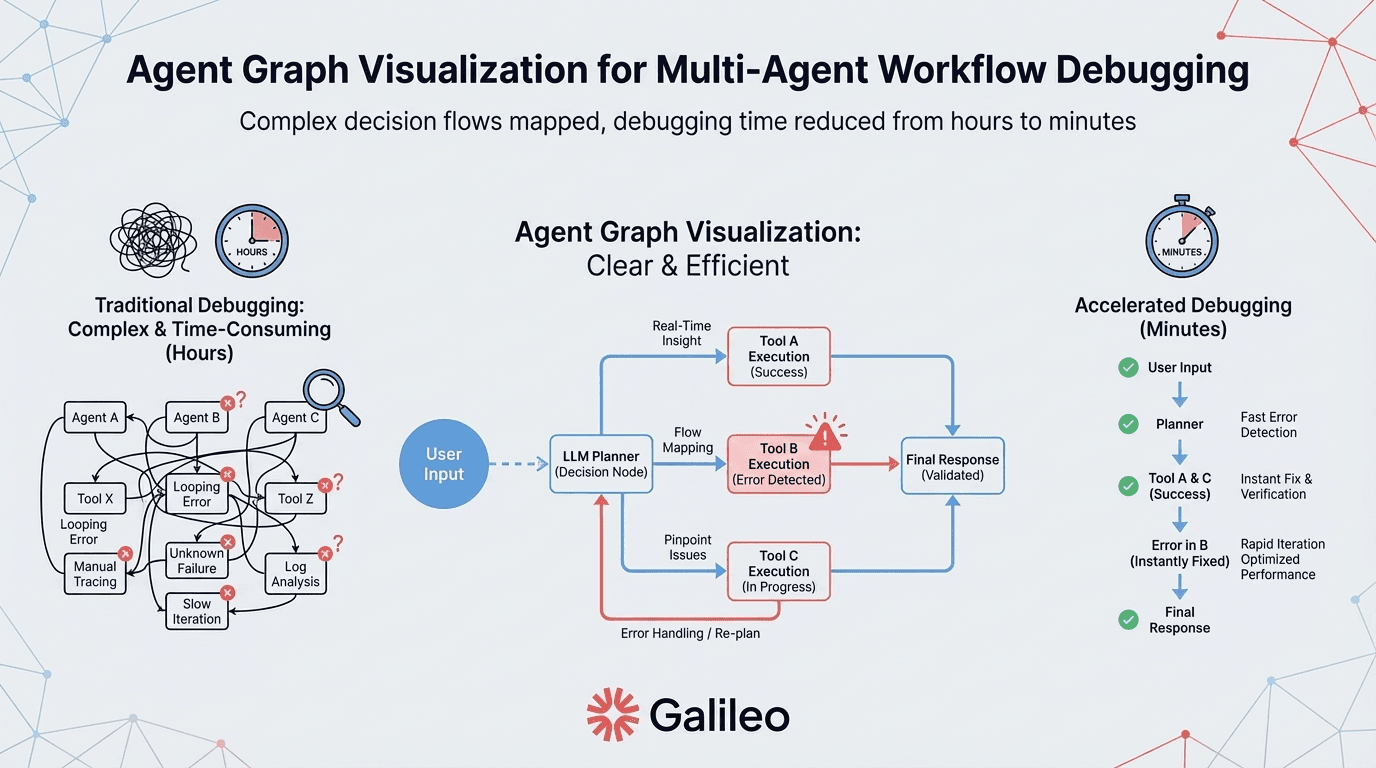
Unlike competitors focused on narrow observability or evaluation, Galileo addresses the complete lifecycle: from Agent Graph visualization that maps multi-agent decision flows to Galileo Signals that automatically clusters failure patterns without manual analysis, surfacing anomalies that would otherwise require hours of log investigation. Runtime protection intercepts harmful outputs at sub-200ms latency, providing real-time guardrails without degrading user experience.
Key Features
Luna-2 evaluation models: 97% cost reduction versus GPT-4 with sub-200ms latency for real-time quality assessment
Agent Graph visualization: Maps multi-agent decision flows and reasoning chains for complex debugging scenarios
Insights Engine: Automatically clusters failure patterns without manual analysis
Runtime protection: Intercepts harmful outputs at sub-200ms latency
Comprehensive compliance: SOC 2 Type II, HIPAA, GDPR, ISO 27001 certifications
Flexible deployment: Hosted SaaS, VPC installations, and on-premises options
Strengths and Weaknesses
Strengths:
Production-scale observability with 20M+ daily trace capacity
Luna-2's 97% cost reduction enables economically viable continuous evaluation
Comprehensive compliance portfolio eliminates procurement friction for regulated industries
Sub-200ms latency supports real-time monitoring without degrading application performance
Addresses data residency requirements through VPC and on-premises deployment options
Weaknesses:
Evaluation-first architecture requires cultural shift for teams new to systematic quality assessment (though this represents industry best practice rather than platform limitation)
Use Cases
Galileo excels for financial services organizations managing sensitive customer data who leverage the compliance portfolio and VPC deployment options—the fintech case study demonstrates production viability at massive scale with $6.4 trillion under management and 30%+ efficiency gains.
Media organizations requiring 100% visibility on AI-generated content use real-time monitoring to maintain editorial standards, with one entertainment company achieving 100% accuracy across 400+ deployments. Enterprises scaling AI to thousands of employees in customer engagement platforms rely on agent observability for scenarios where AI failures create existential business risk.
2. LangSmith
LangSmith has established itself as the definitive platform for multi-agent workflow observability, addressing the debugging nightmare that occurs when cascading failures through reasoning chains vanish into black boxes with no trace of where decisions went wrong.
Where traditional monitoring fails at agent decision points, LangSmith's end-to-end observability captures token-level granularity across complete reasoning chains. The platform goes beyond pure observability with the Visual Agent Builder providing no-code interfaces for rapid prototyping, while auto-scaling deployment handles long-running agent workloads with multi-LoRA serving.
Key Features
End-to-end agent observability: Token-level granularity across complete reasoning chains
Visual Agent Builder: No-code interfaces for rapid prototyping
Auto-scaling deployment: Handles long-running agent workloads with multi-LoRA serving
Prompt testing and versioning: Integrates evaluation frameworks including RAGAS and hallucination detection
Token-level cost attribution: Intelligent model routing for optimization
Comprehensive compliance: SOC 2 Type II, HIPAA, GDPR, CCPA, ISO 27001
Flexible deployment: Fully managed GCP infrastructure with regional options (US and EU) plus self-hosted and hybrid configurations
Strengths and Weaknesses
Strengths:
Purpose-built tracing for multi-step agent reasoning chains provides visibility traditional APM tools cannot match
1,000+ LangChain ecosystem integrations reduce implementation friction through pre-built connectors
Enterprise compliance certifications with flexible deployment options address regulated industry requirements
Transparent pricing structure enables accurate budget forecasting
Weaknesses:
Agent workflow specialization may introduce unnecessary complexity for simpler use cases not requiring multi-step reasoning
Strong LangChain ecosystem ties may create perceived lock-in concerns (though framework-agnostic capabilities mitigate this limitation)
Use Cases
AI agents and copilots requiring multi-step reasoning benefit from comprehensive request tracing capturing decision flows. Customer support automation involving retrieval, reasoning, and action execution gains end-to-end observability revealing failure points. Cross-functional teams implementing agent-based applications across business units leverage the visual Agent Builder for rapid development.
3. Weights & Biases
Weights & Biases represents the natural evolution path for organizations already standardized on W&B for traditional ML who are now extending into generative AI. The platform evolved from ML experiment tracking into comprehensive AI lifecycle management through Weave, offering a unified infrastructure that eliminates tool fragmentation across traditional ML and LLM workloads.
The comprehensive security infrastructure—including ISO 27001, ISO 27017, ISO 27018, SOC 2, and HIPAA certifications—provides confidence for regulated industries considering the extension to generative AI.
Key Features
Weave for LLMs: Iterating, evaluating, and monitoring LLM calls and agent workflows
Guardrails monitoring: Tracks safety, bias, and LLM-specific quality metrics
Comprehensive security: ISO 27001, ISO 27017, ISO 27018, SOC 2, and HIPAA certifications
Multi-cloud deployment: Compatibility across AWS, Azure, GCP with on-premises options
Mature experiment tracking: Years of ML production experience
Transparent pricing: Pro tier starting at $60/month
Strengths and Weaknesses
Strengths:
Enterprise-grade maturity with comprehensive compliance certifications provides confidence for regulated industries
Natural extension path for existing W&B infrastructure offers implementation efficiency through familiar interfaces and workflows
Unified infrastructure across traditional ML and LLM workloads eliminates tool fragmentation
Weaknesses:
LLM-specific capabilities represent newer additions to the mature ML platform, with Weave toolset relatively new compared to core platform maturity
General ML platform focus may include unnecessary features for LLM-only teams (though this provides future flexibility if requirements expand)
Use Cases
Organizations managing both traditional ML and LLM workloads deploy W&B for unified infrastructure, avoiding the complexity of multiple tooling ecosystems. Companies with existing W&B installations gain implementation efficiency by extending to generative AI rather than introducing new tooling and retraining teams.
4. MLflow on Databricks
MLflow on Databricks represents the strategic choice for organizations already invested in the Databricks ecosystem who face the critical decision of building custom LLM infrastructure versus extending existing ML capabilities.
The open-source foundation prevents vendor lock-in while managed MLflow on Databricks delivers enterprise capabilities including Unity Catalog for governance and multi-cloud deployment across AWS, Azure, and GCP. MLflow's GenAI module provides evaluation capabilities through built-in and custom LLM judges, dataset management for evaluation datasets, and production monitoring tracking latency, token usage, and quality metrics.
Key Features
GenAI module: Evaluation capabilities through built-in and custom LLM judges
Dataset management: Purpose-built for evaluation datasets
Production monitoring: Tracking latency, token usage, and quality metrics
Open-source foundation: Vendor lock-in mitigation with extensive community resources
Unity Catalog integration: Enterprise governance when deployed on Databricks infrastructure
Multi-cloud deployment: AWS, Azure, GCP support
Strengths and Weaknesses
Strengths:
Open-source foundation provides vendor lock-in mitigation with extensive community resources and transparency into platform evolution
Built-in LLM judges enable specialized evaluation capabilities without requiring external dependencies
Unity Catalog integration provides enterprise governance when deployed on Databricks infrastructure
Weaknesses:
MLflow primarily serves ML lifecycle management with GenAI as add-on module rather than purpose-built LLM infrastructure
Requires significant setup versus LLM-native platforms, particularly for teams without deep MLOps expertise
Full enterprise deployment cost requires evaluating Managed MLflow pricing within the broader Databricks ecosystem, creating complexity for total cost of ownership analysis
Use Cases
Organizations prioritizing open-source flexibility and existing Databricks infrastructure gain natural extension into LLM operations through Managed MLflow. Teams standardizing GenAI model evaluation workflows benefit from integrated governance through Unity Catalog.
5. Arize AI
Arize AI addresses a critical blind spot in production AI systems: failures that never trigger error messages. When retrieval quality declines without alerts and semantic drift occurs within 200 OK responses, these invisible failures require specialized monitoring that traditional APM tools cannot provide.
Arize AI's embedding monitoring enables detection of silent failures in RAG systems through AI-driven cluster search that automatically surfaces anomaly patterns without manual pattern definition. The platform's commitment to open standards through OpenTelemetry-based tracing reduces vendor lock-in while providing framework-agnostic flexibility, positioning Arize as the choice for organizations prioritizing long-term portability alongside deep semantic observability.
Key Features
Embedding monitoring: Detection of silent failures in RAG systems
AI-driven cluster search: Automatically surfaces anomaly patterns
End-to-end LLM-specific observability: OpenTelemetry-based tracing for framework-agnostic flexibility
Prompt management: A/B testing and optimization workflows
Human annotation management: Integrated evaluation workflows
Multi-cloud deployment: Open standards architecture for infrastructure portability
Transparent pricing: $50/month for 50k spans
Strengths and Weaknesses
Strengths:
OpenTelemetry-based tracing provides vendor lock-in mitigation through industry-standard instrumentation
AI-driven cluster search automatically surfaces anomalies without manual pattern definition
Strong evaluation capabilities include RAGAS-style metrics for RAG applications
Transparent pricing enables accurate budget planning
Weaknesses:
Primary focus on observability means you may require additional tooling for complete LLMOps lifecycle coverage including deployment orchestration and model serving infrastructure
Use Cases
Organizations deploy Arize for end-to-end LLM observability including tracing and prompt optimization when traditional monitoring misses quality degradation. RAG applications particularly benefit from embedding monitoring capabilities that detect retrieval quality issues before they impact user experience.
6. WhyLabs
WhyLabs addresses the questions compliance teams are asking that traditional ML platforms cannot answer: Where's prompt injection detection? How do you monitor PII leakage? Does this align with OWASP LLM security standards? WhyLabs answers these with LangKit, an open-source text metrics toolkit providing security-focused monitoring built around emerging governance frameworks.
Key Features
Hybrid SaaS architecture: On-premises containerized agents in your VPC with centralized management
OWASP LLM compliance: Jailbreak detection and security monitoring aligned with standards
MITRE ATLAS alignment: Policy management aligned with security frameworks
Toxicity and PII detection: Real-time monitoring for sensitive content leakage
LangKit: Open-source text metrics toolkit for security-focused monitoring
Policy management: Enforcement of organizational standards
Open-source foundation: Community-maintained codebase for transparency
Strengths and Weaknesses
Strengths:
Regulated industries requiring OWASP-compliant security monitoring with data residency controls benefit from hybrid architecture with customer VPC deployment
Governance-focused observability particularly suited for compliance-heavy industries needing LLM security standards with policy management capabilities
Open-source foundation provides transparency through community-maintained codebase
Weaknesses:
Primary monitoring focus requires additional tooling for full lifecycle management including evaluation frameworks and deployment orchestration
Recent open-source transition introduces infrastructure overhead for self-hosting versus fully managed alternatives
Use Cases
WhyLabs represents the ideal fit for scenarios where security monitoring and data isolation are primary priorities outweighing the need for broader lifecycle management capabilities. Regulated industries such as healthcare and financial services requiring OWASP-compliant security monitoring with strict data residency controls benefit most from the hybrid architecture with customer VPC deployment.
7. Vellum
Vellum bridges the gap between engineers who build with code and product managers who think in workflows—a barrier that slows AI iteration when PMs wait days for engineering cycles just to test prompt variations. The platform's low-code interfaces enable prompt chaining integrating data, APIs, and business logic through visual development environments, democratizing AI development for cross-functional teams.
Key Features
Low-code prompt chaining: Combines data sources, API calls, and business logic through visual interfaces
Real-time monitoring: Evaluation frameworks ensuring production quality
Versioning and logging: Comprehensive tracking for deployed applications
RAG system support: Intent handlers and human-in-the-loop routing
Flexible deployment: Self-hosted, US cloud, and EU cloud options
Transparent pricing: $25/month Pro tier for budget-conscious teams
Strengths and Weaknesses
Strengths:
Low-code interfaces lower technical barriers for cross-functional teams
Strong collaboration features support product managers and engineers working together
Multi-step AI workflow focus includes native RAG support with intent routing and fallback handling
Accessible pricing for small teams and startups
Weaknesses:
Low-code approach may provide less flexibility for highly custom workflows requiring programmatic control
Visual development environments may not suit teams preferring code-first approaches with version control through Git rather than UI-based management
Use Cases
Building complex multi-step AI applications with cross-functional teams benefits from low-code interfaces enabling rapid prototyping without engineering bottlenecks. Organizations with limited LLM infrastructure expertise prioritize deployment speed through accelerated development cycles that visual builders enable.
Building an LLMOps platform strategy
With Gartner forecasting 40% of enterprise applications featuring AI agents by 2026, your operational readiness separates competitive advantage from costly failures. This represents growth from less than 5% in 2025. Implement phased rollouts over 6-12 months with dedicated platform teams and executive sponsorship requiring structured change management.
Galileo delivers production-ready LLMOps infrastructure addressing the complete evaluation, observability, and governance lifecycle:
Luna-2 evaluation models: Achieve real-time quality assessment at 97% lower cost
Agent Graph visualization: Maps multi-agent decision flows reducing debugging time
Comprehensive compliance: SOC 2, HIPAA, GDPR, CCPA, ISO 27001 certifications
Runtime protection: Intercepts harmful outputs at sub-200ms latency
Flexible deployment options: Choose hosted SaaS, VPC, or on-premises installations
Discover how Galileo delivers end-to-end AI reliability: run experiments with pre-built and custom metrics, debug faster with Agent Graph visualization and the Insights Engine, and protect production with Luna-2-powered guardrails at sub-200ms latency.
Frequently asked questions
What is an LLMOps platform and how does it differ from MLOps?
LLMOps platforms manage large language model lifecycles with specialized capabilities MLOps lacks. These include prompt engineering workflows, token-level cost tracking, and semantic quality evaluation. LLMOps addresses generative AI's unique challenges including non-deterministic outputs and dynamic context windows.
When should you adopt dedicated LLMOps platforms versus extending existing MLOps infrastructure?
You should adopt dedicated LLMOps platforms when scaling generative AI applications beyond initial pilots. This includes facing governance requirements for content safety that traditional MLOps cannot address. Platforms are necessary when you require LLM-native capabilities including hallucination detection and semantic observability.
What are the most critical evaluation criteria when selecting an LLMOps platform?
You should prioritize use case alignment first, then security and governance certifications (SOC 2, HIPAA, GDPR). Assessment of operational maturity at Level 3+ is essential. Token-level cost optimization capabilities are infrastructure requirements. Platforms must feature evaluation-first architecture with built-in frameworks.
How does Galileo's Luna-2 evaluation technology work and why does cost matter?
Galileo's Luna-2 models deliver quality assessment at 97% lower cost than GPT-4. Sub-200ms latency enables real-time production monitoring. Cost matters because continuous evaluation of your production traffic becomes prohibitively expensive at traditional LLM pricing. Luna-2's economics enable systematic quality monitoring at enterprise scale.
Should you build custom LLMOps infrastructure or buy a commercial platform?
Research from Forrester reveals 76% of organizations now purchase AI solutions versus 47% in 2024. This represents a 62% increase in buy-over-build preference. Forrester recommends "selectively build where it unlocks competitive advantage and buy where scale and flexibility are priorities." Hidden costs including compliance automation frequently make commercial platforms more economical for your organization.
Jackson Wells