5 Tools to Evaluate and Monitor Multi-Agent AI Systems

Your production agent just called the wrong API multiple times overnight. The logs show successful completions, but customer data is corrupted. This scenario—successful logs masking coordination failures—represents one of six primary failure modes documented by academic research.
Without proper evals infrastructure, you lack the fundamental visibility needed to debug failures, validate agent behavior, or ensure compliance with governance requirements.
TLDR:
Multi-agent systems fail at 41-86.7% rates according to ArXiv studies without proper evals infrastructure
Coordination overhead consumes 4-15x more tokens than single-agent systems
Quality issues represent the number one barrier to production deployment
Purpose-built platforms measure Tool Selection Accuracy and Agent Adherence
Leading platforms combine observability, runtime protection, and automated root cause analysis
What are multi-agent AI evaluation platforms?

Multi-agent AI evaluation platforms are specialized observability systems designed to monitor and improve autonomous agent reasoning, reliability, and performance. These platforms instrument the decision-making layer—capturing agent reasoning, tool selection, and inter-agent communication patterns.
Academic research from the Cooperative AI Foundation documents six primary failure modes: miscoordination, conflict, collusion, scheming, hallucinations, and bias—failure types that demand purpose-built instrumentation. For engineering leaders, these platforms deliver actionable insights, automated root cause identification, and quantifiable metrics demonstrating whether multi-agent systems improve or degrade over time.
1 . Galileo
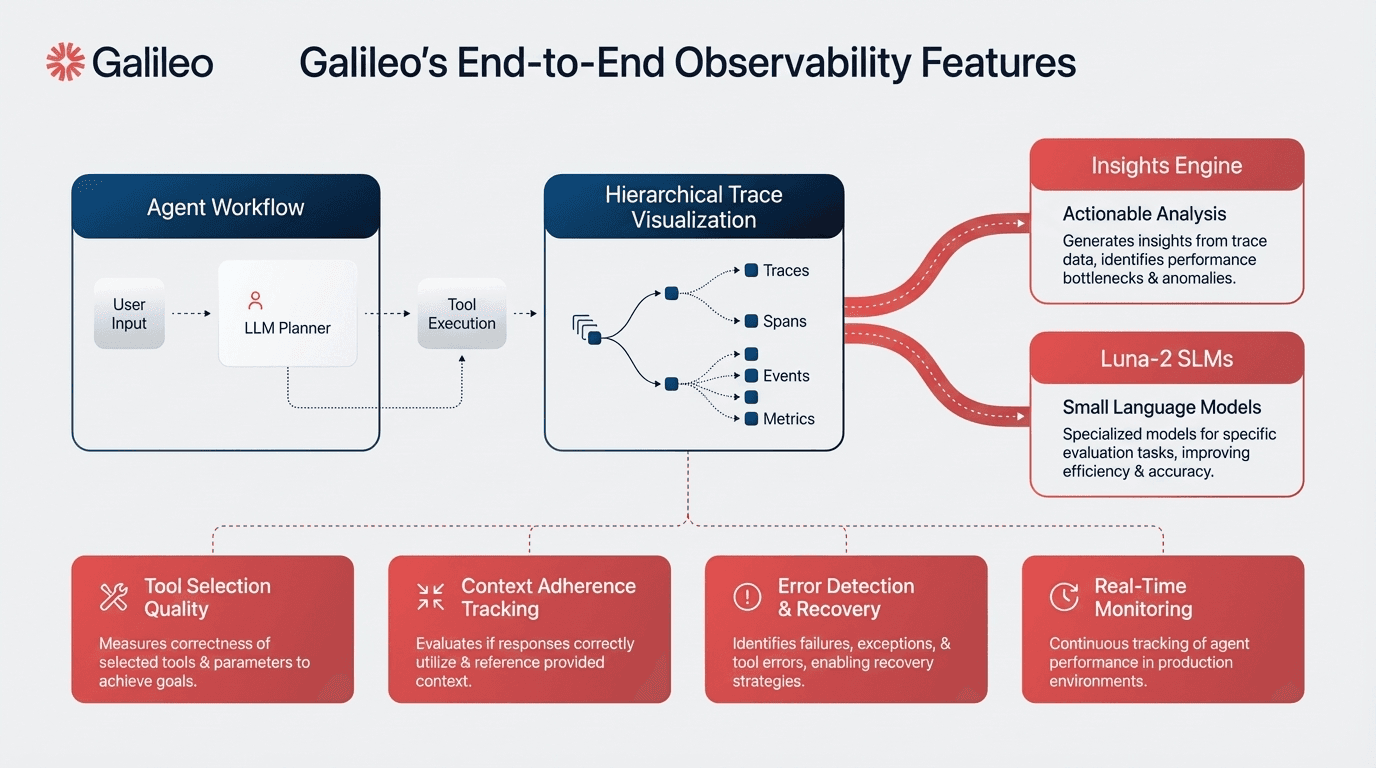
Galileo provides a comprehensive agent observability platform specifically built for multi-agent systems, combining real-time evals, automated failure detection, and runtime protection.
The platform introduced dedicated agentic-specific metrics including Tool Selection Accuracy, Tool Call Quality, and Agent Adherence alongside hierarchical trace visualization mapping multi-agent decision flows from orchestrator to worker agents.
When your routing agent degrades but logs only show successful API calls, traditional monitoring misses the real problem. Galileo's Insights Engine automatically clusters similar failures across agent executions, surfacing patterns in coordination breakdowns.
Key features
Automated failure clustering through the Insights Engine that identifies root causes through intelligent pattern recognition, grouping related failures within minutes
Luna-2 small language model family providing purpose-built assessment capabilities optimized for evaluation tasks with faster inference and lower costs than GPT-4
Evaluation-specific architecture optimizing for consistency across quality dimensions, including context adherence, instruction following, completeness, and chunk attribution
Runtime protection through Galileo Protect with real-time guardrails blocking unsafe outputs before user impact
PII detection and redaction, prompt injection prevention, jailbreak prevention, toxicity filtering, and hallucination detection
Native integration with major frameworks, including OpenAI Agents SDK, LangChain, LlamaIndex, and CrewAI through environment-variable configuration
Strengths and weaknesses
Strengths
Automated failure pattern detection reduces debugging time from hours to minutes
Luna-2 models make continuous evaluation economically viable at the enterprise scale
Hierarchical trace visualization maps complex multi-agent decision flows
Framework-agnostic integration requiring minimal code instrumentation
Weaknesses
Integration complexity varies by framework—LangChain needs only environment variables while CrewAI demands comprehensive instrumentation
Use cases
JPMorgan Chase improved domain-specific query accuracy using Galileo's multi-agent AI governance—eliminating a backlog of 1 million customer utterances without manual review. The MAFA system demonstrates how evaluation platforms enable scale, supporting billions of agent paths and millions of daily queries through systematic AI governance and observability.
2. Arize Phoenix
Phoenix's distributed tracing reveals where agent-to-agent handoffs actually fail through the CLEAR framework: Cost, Latency, Efficacy, Assurance, and Reliability. Why do workflows fail when logs show successful API responses?
Traditional monitoring misses coordination breakdowns. Distributed tracing captures agent-to-agent communication patterns through the CLEAR framework, providing granular visibility into agent interaction quality. This separates Phoenix from infrastructure-focused monitoring tools.
Key features
Distributed tracing capturing agent-to-agent communication patterns with granular visibility into agent interaction quality
CLEAR framework metrics: Cost, Latency, Efficacy, Assurance, and Reliability
Drift detection monitoring that tracks both performance degradation and behavioral changes over time
Alerts when agent decision patterns shift unexpectedly before customer impact occurs
Open architecture enabling custom metric development for organizations with specific coordination measurement requirements
OpenTelemetry compatibility integrating Phoenix into existing observability stacks
Strengths and weaknesses
Strengths
Open-source architecture enables extensive customization while maintaining comprehensive CLEAR framework coordination metrics
Drift detection capabilities catch behavioral changes before customer impact occurs, providing early warning systems for production deployments
OpenTelemetry compatibility connects agent-level metrics with infrastructure performance data
Weaknesses
Custom metric development requires technical expertise beyond simple configuration approaches
Distributed tracing setup involves more complex implementation than environment-variable-based alternatives
Use cases
Teams deploy Phoenix when coordination-specific metrics matter more than general observability—particularly when drift detection can catch degradation before customers experience failures.
Organizations with specific coordination measurement requirements benefit from the open architecture that enables custom metric development aligned with their unique operational needs.
3. LangSmith
How do you gain step-by-step visibility into what your agents are actually doing across complex multi-turn interactions? LangSmith, built by the LangChain team, provides native observability and evaluation infrastructure purpose-built for agent engineering workflows.
The platform makes threads—representing multi-turn agent interactions—a first-class concept, and layers Insights Agent for automatically categorizing agent usage patterns alongside Multi-turn Evals for scoring complete agent conversations rather than individual steps.
Key features
Insights Agent that automatically analyzes production traces to discover and surface common usage patterns, agent behaviors, and failure modes across thousands of interactions
Multi-turn Evals measuring whether agents accomplish user goals across entire conversations, not just individual steps—assessing semantic intent, goal completion, and interaction quality
Environment-variable setup requiring only LANGSMITH_TRACING=true and API credentials for comprehensive trace collection without code instrumentation
Online and offline evaluation modes—offline evals run against datasets for benchmarking and regression testing while online evals run on real production traffic in near real-time
Annotation queues for collecting expert feedback, flagging runs for review, and using human input to improve prompts, evaluators, and datasets
OpenTelemetry compatibility enabling integration with existing observability pipelines, with traces flowing both in and out of LangSmith
Production monitoring dashboards tracking token usage, latency (P50, P99), error rates, cost breakdowns, and feedback scores with configurable alerts via webhooks or PagerDuty
Strengths and weaknesses
Strengths
Native LangChain and LangGraph integration delivers zero-configuration observability with automatic capture of chains, tools, and retriever operations
Insights Agent automates pattern discovery across production traces, answering questions like "What are users asking my agent?" to prioritize improvement efforts
Multi-turn Evals close the gap between individual trace evaluation and holistic conversation quality assessment
Framework-agnostic support through OpenTelemetry means LangSmith works with OpenAI SDK, Anthropic SDK, Vercel AI SDK, LlamaIndex, and custom implementations
Weaknesses
Deepest integration experience requires LangChain or LangGraph—teams using other frameworks get solid observability but lose some framework-specific debugging depth
LangSmith operates as a paid service (Plus and Enterprise tiers) beyond the free developer tier, with pricing scaling per trace volume
Use cases
Teams deploy LangSmith when they need full visibility into multi-turn agent behavior at scale. A leading fintech company handling customer support for tens of millions of active users leveraged LangSmith to rigorously test critical use cases, validate agent performance with LLM evaluations, and iterate on prompts—reducing customer query resolution time by 80%.
4. Braintrust
Generic monitoring tells you an agent responded in 200ms—but did it respond correctly? Braintrust integrates evaluation directly into observability, measuring how well agents perform using customizable metrics rather than just logging what happened. When quality degrades after a prompt change, Braintrust catches it before users complain.
The platform's evaluation-first architecture connects production traces to systematic improvement workflows. Every production failure can be converted into a test case with a single click, closing the feedback loop between testing and production monitoring.
Key features
Loop AI agent that automates the most time-intensive parts of AI development—analyzing prompts, generating better-performing versions, creating evaluation datasets, and building custom scorers tailored to specific use cases
Brainstore, a purpose-built database for AI application logs delivering 80x faster query performance than traditional databases for searching and analyzing agent interactions at enterprise scale
Comprehensive trace capture showing every decision point in multi-step workflows—which tools the agent called, what data it retrieved, step duration, and failure points with nested spans for replaying complex workflows
One-click production trace conversion into evaluation datasets, enabling teams to flow from identifying issues in production logs to creating test cases to running evaluations without context switching
Native CI/CD integration through GitHub Actions and CircleCI, posting eval results directly to pull requests and providing automated quality gates preventing coordination regressions
Framework-agnostic integration supporting 13+ frameworks including LangChain, LlamaIndex, Vercel AI SDK, OpenAI Agents SDK, and CrewAI, plus OpenTelemetry support for custom implementations
SOC 2 Type II compliance with hybrid deployment model for organizations with strict data residency requirements
Strengths and weaknesses
Strengths
Evaluation-first architecture means teams catch regressions before customers see them—production traces automatically become eval datasets, creating a continuous improvement loop
Loop AI agent reduces the tedious work of writing custom scorers and optimizing prompts, generating production-ready evaluation logic from natural language descriptions
Brainstore enables debugging at production scale—teams query, filter, and analyze millions of traces in seconds rather than minutes
Cross-functional collaboration tools enable both engineers and product managers to work in the same interface without handoffs
Weaknesses
Enterprise pricing lacks self-serve options—teams need to contact sales for pricing beyond the free tier (1M trace spans, 10K evaluation scores per month)
Platform depth in evaluation and observability may exceed what teams need if they're looking for simple logging rather than systematic quality improvement
Use cases
Teams adopting Braintrust report transformative improvements in debugging velocity and output quality. One major productivity software company moved from manually tracking failed AI prompts to automated monitoring, going from fixing 3 issues per day to 30. A leading workflow automation platform replaced ad-hoc hallucination detection with systematic dataset management and prompt quality monitoring across millions of monthly AI tasks.
5. LangChain
When managed platforms can't support your specialized coordination logic, you need control over the evaluation infrastructure itself. LangChain's open-source foundation provides that flexibility through supervisor-worker patterns and comprehensive logging.
LangSmith observability requires only environment variable configuration—setting LANGSMITH_TRACING=true and providing API credentials activates comprehensive trace collection without code instrumentation.
Key features
Environment-variable approach delivering OpenTelemetry-compatible observability infrastructure
Supervisor-worker coordination patterns proven across thousands of implementations
Error handling frameworks capturing failure context in detailed logs
Distributed tracing tracking agent-to-agent communications throughout complex workflows
Rapid instrumentation without significant code modifications
Compatibility with the broader LangChain ecosystem for proprietary coordination patterns
Strengths and weaknesses
Strengths
Open-source foundation avoids vendor lock-in while providing production-tested coordination patterns
Environment-variable setup enables rapid instrumentation without significant code modifications
Extensive ecosystem compatibility for organizations with existing LangChain investments
Weaknesses
LangSmith observability operates as a separate paid service beyond the base open-source framework
Evaluation sophistication depends heavily on team expertise, with less opinionated guidance than managed platforms provide
Use cases
Teams deploy LangChain when building custom agent architectures requiring specialized coordination logic unavailable in managed platforms. The open-source foundation enables organizations to modify instrumentation for proprietary coordination patterns while maintaining compatibility with the broader LangChain ecosystem. Development teams avoiding vendor lock-in choose LangChain's open architecture.
Choose the Right Platform to Prevent Multi-Agent Failures
McKinsey research shows most companies using generative AI report minimal bottom-line impact, largely due to inadequate evaluation infrastructure. While each platform offers unique strengths—Phoenix for drift detection, Maxim for pre-production simulation, LangChain for open-source flexibility—Galileo stands out as the most comprehensive solution. With automated root cause analysis through the Insights Engine, purpose-built Luna-2 evaluation models, and real-time guardrails via Agent Protect, Galileo reduces debugging from hours to minutes while making continuous evaluation economically viable at enterprise scale.
Here’s how Galileo helps evaluate multi-agent AI systems:
Automated root cause analysis — The Insights Engine clusters similar failures across agent executions, identifying coordination breakdowns within minutes instead of hours
Purpose-built evaluation models — Luna-2 delivers faster inference and lower costs than GPT-4, making continuous evaluation economically viable at enterprise scale
Real-time guardrails — Galileo Protect blocks PII leakage, prompt injection, jailbreaks, and hallucinations before they impact users
Hierarchical trace visualization — Maps multi-agent decision flows from orchestrator to worker agents, revealing where handoffs actually fail
Framework-agnostic integration — Native support for OpenAI Agents SDK, LangChain, LlamaIndex, and CrewAI through simple environment-variable configuration
Discover how Galileo can help you transform ambitious blueprints into production-grade agent systems that actually move the business needle.
Frequently Asked Questions
What are multi-agent AI evaluation platforms and how do they differ from traditional monitoring tools?
Multi-agent AI evaluation platforms instrument the decision-making layer by tracking agent reasoning, tool selection, and coordination patterns across performance, quality, cost, and reliability metrics.
Unlike traditional application monitoring tracking infrastructure metrics, these platforms measure agent-specific dimensions including tool selection accuracy and inter-agent communication effectiveness.
When should organizations invest in dedicated multi-agent evaluation platforms?
Organizations should implement evaluation platforms when deploying agents that coordinate autonomously. Gartner research shows over 40% of agentic AI projects will be canceled by 2027 due to lack of proper evaluation infrastructure. Early investment in evaluation infrastructure separates successful implementations from failed projects.
What metrics should engineering leaders track for multi-agent system coordination?
Track metrics across four categories: performance (latency per agent step, task completion rates), coordination quality (handoff success rates, tool selection accuracy), cost (token consumption per agent), and reliability (error clustering patterns, drift detection).
The most critical unsolved challenge remains inter-agent collaboration assessment. While platforms excel at measuring individual agent performance—latency per step, tool selection accuracy, error rates—quantifying coordination quality requires capturing emergent behaviors. Does Agent A's output format match Agent B's expected input structure? Did context loss during handoffs cause downstream failures? Purpose-built platforms instrument these coordination-specific failure modes.
How does Galileo's Luna-2 evaluation model compare to using GPT-4 for agent evaluation?
Luna-2 is purpose-built specifically for evaluation tasks, optimizing for consistency and accuracy in quality assessment. Galileo reports it delivers faster inference with lower latency and lower costs than GPT-4 for evaluation-specific tasks, making continuous evaluation economically viable at enterprise scale.
Can multi-agent evaluation platforms integrate with existing observability tools like Datadog or Splunk?
Yes, most modern platforms support integration through OpenTelemetry-compatible instrumentation. Microsoft advanced industry standards by announcing extensions specifically for multi-agent AI systems. Platforms including Galileo, Arize Phoenix, and CrewAI provide native integrations enabling correlation between agent-level decision metrics and infrastructure-level performance data.

Pratik Bhavsar