Galileo vs. Braintrust: The Comprehensive Observability Platform That Goes Beyond Evaluations

Modern AI systems rarely fail in obvious ways; instead, quality erodes quietly as prompts drift, provider APIs hiccup, or cost spikes mask degraded answers. That nuance makes deep observability indispensable long after a model clears offline tests.
When selecting an AI observability platform, you need clear comparisons that go beyond marketing claims. Between Galileo and Braintrust, each vendor takes a fundamentally different approach to evals, agent monitoring, and runtime protection, differences that become apparent only after deployment.
Check out our Agent Leaderboard and pick the best LLM for your use case

Galileo vs. Braintrust at a glance
When you're evaluating these two platforms, the differences become clear fast. Galileo builds a complete reliability stack for complex agents, while Braintrust focuses on evaluation workflows for traditional LLM traces.
The comparison below shows what you'll experience from day one of your enterprise deployment:
Capability | Galileo | Braintrust |
Platform focus | End-to-end GenAI reliability platform that unifies evals, monitoring, and guardrails in a single console | Evaluation-first workflow aimed at scoring and visualizing LLM outputs |
Agent / RAG support | Agent Graph, multi-turn session views, chunk-level RAG metrics | Basic trace visualization; no agent-specific analytics |
Evaluation approach & cost | Runs metrics on Luna-2 SLMs(97% cheaper than GPT-4) | Relies on external LLM judges; costs scale linearly with model choice |
Monitoring depth | Custom dashboards, OpenTelemetry traces, automated failure insights | Fixed dashboards with webhook alerts |
Runtime protection | Real-time guardrails that block unsafe or non-compliant outputs | No native runtime blocking; alerts only after issues surface |
Session-level metrics | Captures end-to-end user journeys for multi-step agents | Lacks consolidated session analytics |
Deployment models | SaaS, private VPC, or fully on-prem for regulated environments | SaaS by default; hybrid option keeps control plane in Braintrust cloud |
These core differences shape everything else about how each platform performs in production. Your choice here determines whether you're building for simple workflows or complex agentic systems.
Core functionality, evals & experimentation
AI prototypes rarely survive first contact with production. You need to compare prompt versions, score outputs, and spot regressions long before users complain.
Galileo
A common frustration occurs when judges disagree or miss subtle hallucinations. Galileo tackles this by combining a rich metric catalog, which boosts evaluator accuracy by cross-checking multiple lightweight models before returning a score.
When you need something domain-specific, you can write a natural-language prompt. The platform turns it into a custom metric and stores it for reuse across teams.
The platform also highlights exactly where things went wrong. Token-level error localization pins a hallucination to the specific phrase that triggered it, so you fix the prompt rather than guess. Evaluations run on Luna-2 small language models, which cost up to 97% less than GPT-4, with millisecond-level latency, allowing you to score every agent turn without budget concerns.

Inside the playground, you replay full traces, diff prompts side by side, and iterate in real time. Continuous Learning with Human Feedback then auto-tunes evaluators as you accept or reject outputs, keeping metrics aligned with evolving business goals.
Braintrust
How can you keep experiments organized when dozens of teammates are tweaking prompts at once? Braintrust structures the workflow around tasks, scorers, and judges. You create a task, attach deterministic or LLM-based scorers, and run judges to grade every response—online or offline.
A side-by-side playground makes it easy to compare model variants, while the Loop assistant auto-generates new prompts and test cases so you never start from a blank slate.
Collaboration is baked in. A dedicated human-review interface lets product managers label edge cases without touching code. Their feedback flows straight back into the scorer pipeline.
Braintrust excels in straightforward GenAI flows, but it stops short of the depth you get elsewhere. There's no token-level error identification, and judge accuracy isn't automatically cross-validated.
Still, if your primary need is a clean, evaluation-first interface that plugs into CI pipelines, the platform delivers a fast path from idea to measurable improvement.
Deep Observability for Production Systems
Moving beyond basic evals, production systems require sophisticated monitoring that can identify failure patterns before they escalate into user-facing issues. The approaches diverge significantly here.
Galileo
You've probably watched a single rogue tool call derail an otherwise healthy agent chain. Galileo exposes that failure path instantly through its Agent Graph, a framework-agnostic map that visualizes every branch, decision, and external call in real time, letting you trace causes instead of guessing them.
Built-in timeline and conversation views switch perspective on demand, so you can replay the exact user turn that triggered the cascade.
Once you spot an anomaly, multi-turn session metrics reveal how errors propagate across steps, capturing latency, token usage, and tool success rates for entire dialogues. Likewise, the Insights Engine automatically clusters failures, highlights hallucinations, and flags broken RAG citations at the chunk level—eliminating manual log scrubbing.
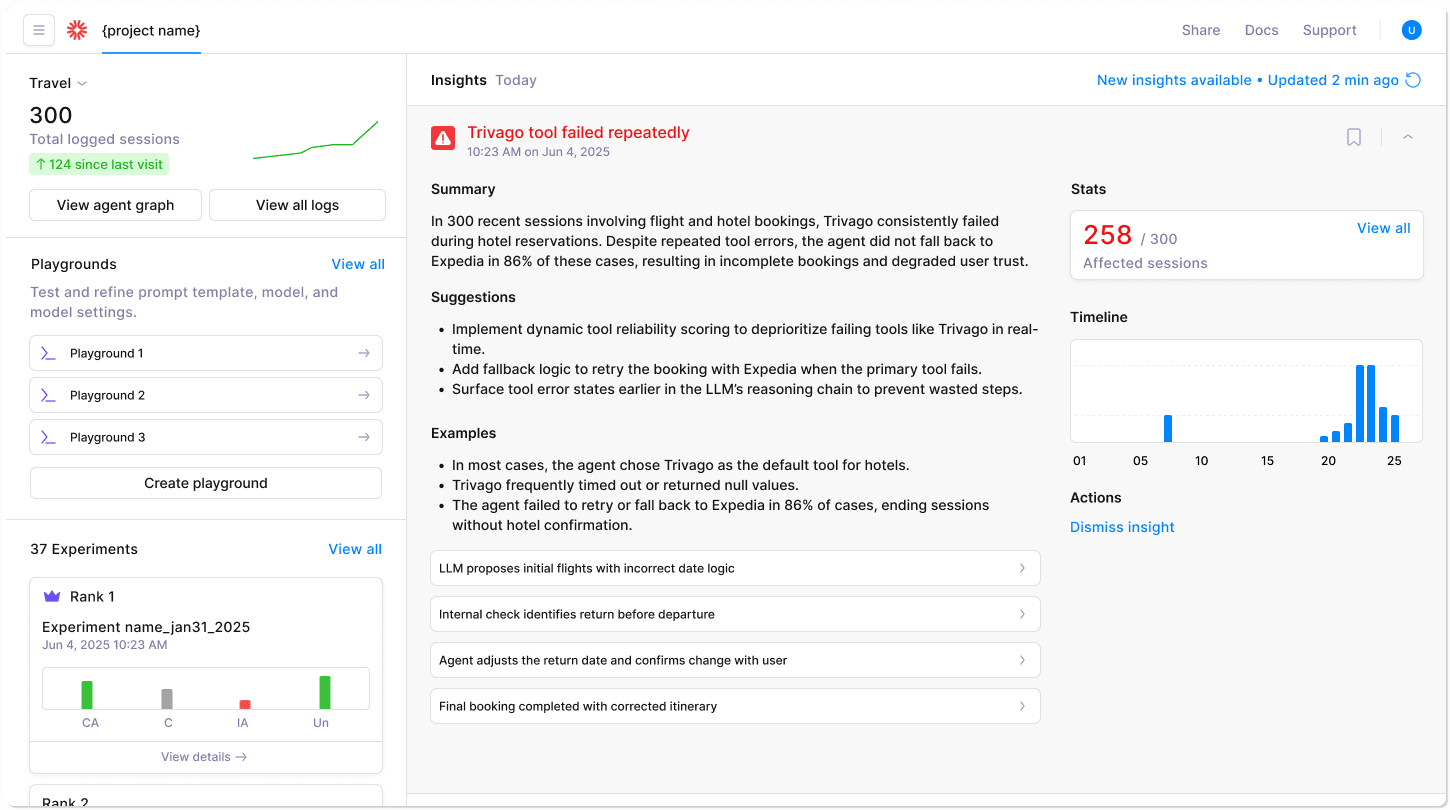
Live logstreams feed customizable dashboards and native alerts. The moment a hallucination slips through, Galileo Protect can block the response before it reaches production, connecting deep observability with real-time protection.
Braintrust
Braintrust caters to simpler traces well. Every model or chain call appears in a clear, chronological visualization, giving you quick insight into latency, cost, and basic output quality. Production monitoring builds directly on the offline evaluation flows you already use, making the transition from staging to live traffic easy.
Dashboards arrive preconfigured and alerts fire through webhooks, making Slack or PagerDuty integrations straightforward. You won't find session-level roll-ups or agent-specific analytics, though.
Document-level explainability is also absent, so investigating a hallucinated citation means jumping back into raw logs. For straightforward chatbots or single-step RAG calls, that trade-off keeps the tool lightweight.
Once your architecture shifts toward multi-agent coordination, the lack of granular metrics and automatic failure clustering leaves you stitching together gaps manually.
Integration and Scalability
Scaling an agent stack is rarely just a hardware question; it hinges on how smoothly you can integrate observability into every request without compromising performance or exceeding budget.
Both platforms promise "one-line" hookups, yet their approaches diverge once traffic spikes or compliance teams appear.
Galileo
Production agent pipelines generate torrents of traces, thousands per minute in busy systems. Galileo meets this challenge with auto-instrumentation that hooks directly into providers like OpenAI, Anthropic, Vertex AI, and AWS without custom glue code.
The serverless backbone scales automatically, eliminating pre-provisioning headaches and midnight paging alerts.
Multi-tier storage keeps hot data fast and cold data cheap, while Luna-2 small language models slash evaluation costs by up to 97% compared to GPT, making always-on metrics financially viable even at enterprise scale.
PII redaction runs at ingestion, so you can stream production traffic from regulated domains without separate scrub jobs. Drop a single SDK call, watch traces flow, and let the platform expand transparently as query volume or new regions come online.
Braintrust
Prefer keeping observability infrastructure closer to your Kubernetes clusters? Braintrust's hybrid model accommodates that preference with Terraform scripts that spin up containerized collectors behind your firewall while a cloud control plane manages updates and query orchestration.
Global CDN routing trims latency for geographically dispersed teams, and asynchronous span processing prevents ingestion backlogs during traffic surges. Intelligent sampling keeps storage bills predictable, but you'll provision judge models yourself.
Since the platform doesn't bundle a cost-optimized evaluator like Galileo's Luna-2 engine, the costs can quickly add up.
Compliance and security
Production multi-agent systems die in committee rooms, not code reviews. When auditors question data handling, legal teams worry about liability exposure, and security leads flag deployment risks, your agents never see real traffic.
Galileo
Regulated industries create a nightmare scenario: every conversation contains potential PII, every tool call generates audit trails, and every response needs real-time policy enforcement.
You get three deployment paths with Galileo—fully SaaS, private VPC, or complete on-premises control—so sensitive healthcare or financial data never crosses boundaries you haven't approved.
SOC 2 compliance comes standard, with enterprise controls like role-based access and encrypted storage protecting logs and traces.
The real differentiator lives in Galileo’s runtime protection. Protect allows you to configure inline guardrails, scoring every agent response under 150 milliseconds and blocking policy violations before they reach users.
Sensitive fields get automatically redacted at the memory level, keeping regulated datasets clean throughout processing. Your security team can embed these same checks across services using dedicated guardrails, while immutable audit trails capture every request for forensic analysis.
High-availability clusters across multiple regions ensure your compliance infrastructure stays resilient even during traffic spikes.
Braintrust
SaaS deployments work fine until your CISO asks hard questions about data residency. Braintrust offers a hybrid approach where processing happens in your VPC while their control plane stays in their cloud. This setup simplifies initial deployment but creates dependencies that limit fully air-gapped scenarios.
You still get SOC 2 Type II certification and GDPR alignment, plus retention policies that automatically purge logs on your schedule—helpful when auditors demand proof of data minimization.
The platform's evals focus means no runtime guardrails exist; unsafe outputs trigger webhook alerts that your code must catch and remediate. On-premises scaling becomes problematic since the orchestration layer remains external, and security teams often reject outbound dependencies during incident response.
These limitations may work for straightforward evaluation workflows, but complex agent deployments requiring real-time policy enforcement and granular network isolation need Galileo's comprehensive protection surface.
Usability and cost of ownership
Even the best observability stack fails if your team can't adopt it quickly or if evals bills spiral out of control. The daily experience and long-term economics vary dramatically between these platforms.
Galileo
You open Galileo's playground and immediately see a full trace, a live diff, and an A/B panel, no tab-hopping required. Need to replay yesterday's incident? One click recreates the entire session, so you can iterate on the prompt, rerun the chain, and watch new metrics register in real time.
Because evaluations run on small language models, latency sits comfortably below 200 ms, and costs are tiny, Luna is up to 97% cheaper than GPT-4 for the same scoring workload.
That price gap means you can layer sentiment, toxicity, and hallucination detectors simultaneously without worrying about API burn. Galileo also skips per-seat licensing, so you avoid the "reviewer surcharge" that creeps into many enterprise tools.
Continuous Learning with Human Feedback adapts those metrics on the fly; when you tweak a rubric, the system backfills scores across historical traces for consistent comparisons. The result is a playground that doubles as a cost-aware control room, keeping both iteration speed and finance teams happy.
Braintrust
Braintrust greets you with a clean side-by-side tester that feels instantly familiar. Type a prompt, compare model variants, then invite teammates into the same view for quick comments. The built-in AI assistant suggests fresh test data, handy when you're staring at a blank dataset.
Costs track every judge call linearly; there's no lightweight evaluator tier, so expanding coverage means larger invoices. Their monitoring dashboards are fixed templates: useful for a high-level pulse, but you'll pipe webhooks into Slack or PagerDuty if you need nuanced alerts.
That do-it-yourself approach extends to budgets; while Braintrust flags cost spikes in production, it leaves optimization strategies to you. For small teams, simplicity outweighs the extra spend, and the interface excels at fast, prompt iteration.
At enterprise scale, the absence of built-in cost controls and metric customization can push total ownership higher than the sticker price initially suggests.
What customers say
Staring at feature checklists only tells you so much. The real test comes when your agents hit production traffic. Customer experiences reveal how these platforms perform under pressure.
Galileo
You'll join over 100 enterprises already relying on Galileo daily, including high-profile adopters like HP, Reddit, and Comcast, who publicly credit the platform for keeping sprawling agent fleets stable at scale.
Galileo customers report significant results:
"The best thing about this platform is that it helps a lot in the evals metrics with precision and I can rely on it, also from the usage I can understand that it is exactly built for the specific needs of the organization and I can say that it's a complete platform for experimentation and can be used for observations as well"
"The platform is helping in deploying the worthy generative ai applications which we worked on efficiently and also most of the time i can say that its cost effective too, the evals part is also making us save significant costs with the help of monitoring etc"
"Galileo makes all the effort that is required in assessing and prototyping much easier. Non-snapshots of the model's performance and bias are incredibly useful since they allow for frequent checkups on the model and the application of generative AI in general."
"Its best data visualization capabilities and the ability to integrate and analyze diverse datasets on a single platform is very helpful. Also, Its UI with customizations is very simple."
Industry leader testimonials

"Evaluations are absolutely essential to delivering safe, reliable, production-grade AI products. Until now, existing evaluation methods, such as human evaluations or using LLMs as a judge, have been very costly and slow. With Luna, Galileo is overcoming enterprise teams' biggest evaluation hurdles – cost, latency, and accuracy. This is a game changer for the industry." - Alex Klug, Head of Product, Data Science & AI at HP
"What Galileo is doing with their Luna-2 small language models is amazing. This is a key step to having total, live in-production evaluations and guard-railing of your AI system." - Industry testimonial
"Galileo's Luna-2 SLMs and evaluation metrics help developers guardrail and understand their LLM-generated data. Combining the capabilities of Galileo and the Elasticsearch vector database empowers developers to build reliable, trustworthy AI systems and agents." - Philipp Krenn, Head of DevRel & Developer Advocacy, Elastic
Braintrust
“Braintrust is really powerful for building AI apps. It's an all-in-one platform with evals tracking, observability, and playground tools for rapid experimentation. Very well-designed and built app that's also very fast to use.” G2 reviewer
Braintrust does not have any more reviews on G2.
Which platform fits your needs?
Your AI system's complexity determines which platform makes sense. Running agent-heavy workflows under strict compliance requirements? Galileo's architecture handles this reality better.
When deciding between Galileo and Braintrust, your choice should be guided by your organization's specific priorities and requirements.
Choose Galileo if:
Your organization operates in a regulated industry requiring robust security alongside a thorough AI assessment
You need deep observability into agent behavior, including Agent Graph visualization, automated failure detection, and multi-turn session analytics
You're building complex multi-agent systems that require real-time monitoring and runtime protection
Your applications involve generative AI that can benefit from evals without ground truth data
You're handling massive data volumes that require significant scalability and cost-optimized low-cost evals
You need comprehensive observability tools with custom dashboards, OpenTelemetry integration, and automated insights that surface failure patterns before they escalate
You require runtime guardrails that block unsafe outputs in production before they reach users
However, teams prioritizing speed over deep runtime control find Braintrust more practical. You can launch their SaaS environment in minutes, test datasets offline, and connect basic monitoring to your existing CI/CD pipeline.
Choose Braintrust if:
Your workflows center on traditional, single-step LLM applications rather than complex multi-agent systems
You prioritize a streamlined evaluation-first interface over comprehensive observability features
Your use cases don't require session-level analytics or agent-specific monitoring capabilities
You're comfortable with fixed dashboard templates and webhook-based alerting rather than customizable observability
Your applications don't need runtime protection or inline guardrails
You prefer a lightweight tool focused primarily on offline experimentation and basic trace visualization
Evaluate your LLMs and agents with Galileo
Moving from reactive debugging to proactive quality assurance requires the right platform—one purpose-built for the complexity of modern multi-agent systems.
Here’s how Galileo's comprehensive observability platform provides a unified solution:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evals: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evals approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Explore how Galileo can help you build reliable LLMs and AI agents that users trust, and transform your testing process from reactive debugging to proactive quality assurance.

Conor Bronsdon