How to Use MT-Bench and Chatbot Arena to Build a Reliable LLM Judge

Jackson Wells
Integrated Marketing

There is an uncomfortable irony in modern AI engineering: teams spend months building sophisticated LLM judges to evaluate their agents, but rarely stop to ask, "Who evaluates the judge?" You might have a pipeline that automatically grades your RAG retrieval accuracy, but if that judge is silently biased or hallucinating its own scores, your entire quality signal is noise.
MT-Bench and Chatbot Arena emerged from the University of California, Berkeley (LMSYS Org) to solve this exact problem. While most of the industry knows them simply as leaderboards for comparing models like GPTs against Claude, their deeper contribution is a rigorous methodology for validating the reliability of LLM-as-a-judge systems.
The foundational research by Zheng et al. established that strong LLM judges (such as GPT-4) can achieve over 80% agreement with human experts, matching the agreement rate among humans.
However, that reliability ceiling is conditional.
It requires specific calibration techniques, bias mitigation, and architectural choices. This guide explains how to apply the MT-Bench and Chatbot Arena methodologies to benchmark your own judges, detect biases that corrupt evaluation, and calibrate your infrastructure for production reliability.
TL;DR:
MT-Bench’s 80-question multi-turn design reveals judge reliability gaps invisible to single-turn evaluation — especially critical for production agents handling multi-step conversations
Chatbot Arena’s Elo-based pairwise methodology provides statistically robust reliability scores that pointwise scoring consistently misses
Before calibrating, establish inter-judge agreement baselines using Cohen’s Kappa — judges scoring below 0.6 Kappa are unreliable, regardless of average accuracy
Position, verbosity, and self-enhancement biases silently corrupt scores at scale; reference-guided evaluation drops judge failure rates from 70% to 15% on complex tasks
Multi-judge consensus using 3–5 specialized models outperforms single large frontier judges in consistency while reducing evaluation costs

What Is MT-Bench?
MT-Bench is a standardized evaluation framework developed at UC Berkeley that uses 80 expert-crafted questions across eight capability categories to assess LLM performance on open-ended, multi-turn tasks.
Unlike traditional benchmarks that test narrow, deterministic knowledge, MT-Bench specifically measures conversational ability, instruction-following across context shifts, and the kind of reasoning that only surfaces when an AI must maintain coherence across multiple exchanges.
For AI teams building production systems, MT-Bench’s deeper value lies not in the scores it produces but in the methodology it establishes. It provides a rigorous, reproducible instrument for stress-testing evaluation systems, including your own LLM judge, against the conditions where judges most commonly fail.
The 80-Question Multi-Turn Design
MT-Bench’s 80 questions span eight categories:
Writing
Roleplay
Extraction
Reasoning
Mathematics
Coding
STEM
Social sciences
Each question involves at least two conversational turns — a deliberate design choice, not a convenience. The second turn typically reframes, extends, or challenges the first response, forcing evaluation of whether the model and the judge can maintain context coherence under shifting demands.
Why does the two-turn structure matter for benchmarking your judge?
Single-turn evaluation masks a specific and common failure mode: judges who score individual responses accurately but lose scoring consistency when context from previous turns becomes relevant.
A judge might correctly evaluate whether a coding solution works in isolation, then assign inconsistent quality scores when the second turn asks for optimization, because tracking what was already established requires different reasoning than evaluating from scratch.
Production agents overwhelmingly operate in multi-turn environments. Customer service workflows, document analysis pipelines, and agentic task execution all involve context that accumulates across steps.
An evaluation framework that only stress-tests single-turn performance gives you a reliability picture that simply doesn’t map to how your system actually behaves.
Two Evaluation Modes and When to Use Each
MT-Bench operates in two modes:
Pairwise comparison
Pointwise scoring
Pairwise comparison presents the judge with two responses to the same prompt and asks which is better, producing a relative quality judgment. Pointwise scoring asks the judge to rate a single response on an absolute scale, typically 1 to 10.
The research makes a clear case for when each mode serves you.
Pairwise comparison yields more stable, reliable judgments because relative quality is easier for a model to assess than absolute calibration. Pointwise scoring is prone to scale drift; the judge’s internal understanding of what ‘6 out of 10’ means can shift depending on the examples it has seen recently, the phrasing of adjacent prompts, and subtle context effects.
In practice: use pairwise comparison for A/B testing agent configurations, comparing prompt versions, or validating that a new model version outperforms its predecessor.
On the other hand, use pointwise scoring for absolute quality monitoring, regression testing against defined thresholds, and production dashboards where you need single scores rather than comparative rankings.
The mode mismatch (using pointwise scoring where pairwise would reveal more) is one of the most common and easily corrected evaluation architecture errors.
How MT-Bench Validates Judge Reliability
The original MT-Bench paper’s most important finding for practitioners isn’t the model rankings it produced; it’s the validation methodology it established.
By collecting 3,000 expert votes and measuring agreement between GPT-4 judgments and human preferences, the research demonstrated that strong LLM judges achieve 80% agreement with humans, matching the level of agreement humans have with each other.
What the headline number obscures: that 80% agreement was achieved under specific conditions. The judge received well-structured prompts with explicit criteria. Questions were carefully categorized so the judge was never asked to evaluate domains that required specialized expertise the judge lacked.
Reference answers were provided for categories like math and coding, where ground truth exists. Remove any of these conditions (as most production implementations do) and agreement rates drop substantially.
The practical implication: MT-Bench’s methodology gives you a ceiling to benchmark against, not a floor to assume. If your production judge isn’t achieving anything close to 80% agreement when validated against human preferences on a representative sample of your use cases, the gap reveals exactly where your evaluation infrastructure needs strengthening.

What Is Chatbot Arena?
Chatbot Arena is a crowdsourced evaluation platform developed at UC Berkeley that pits two anonymous LLMs against each other in live conversations, collecting human preference votes to determine which model performed better.
Users interact with both systems simultaneously, then rate their preference without knowing which model produced which response. This eliminates the brand bias that compromises most public model comparisons.
With over 1.5 million pairwise preferences collected for more than 100 models, Chatbot Arena has become one of the most referenced model reliability benchmarks in AI research. But like MT-Bench, its value for production teams extends beyond the leaderboard.
The statistical methodology behind Arena’s Elo scoring system provides a framework for measuring judge reliability that most teams haven’t applied to their own evaluation infrastructure.
How Elo Scoring Works in Practice
Elo scoring (borrowed from competitive chess ranking) treats each pairwise comparison as a match between two opponents. A model that beats a highly-rated opponent gains more points than one that beats a lower-rated one.
Losses cost proportionally based on the gap between ratings. Over thousands of matches, the system converges on ratings that reflect true relative quality rather than the artifacts of any single comparison.
The statistical robustness of Elo scoring comes from its resistance to outliers. Any individual voter may have idiosyncratic preferences, domain blind spots, or fatigue effects. Aggregate those individual judgments across thousands of diverse evaluators, and the noise averages out, leaving a signal that reflects genuine model quality differences.
This is what gives Chatbot Arena scores their credibility—not any individual data point, but the convergence of a large, diverse population.
For production teams, the lesson is that any single evaluation run tells you relatively little. The number that matters is the trend across many evaluations, conducted under varied conditions, with randomized answer positions. That’s the difference between a measurement and a score.
Why Pairwise Beats Pointwise for Calibration
Chatbot Arena never asks evaluators to assign absolute scores. Every judgment is relative: which of these two responses is better? This design choice reflects a fundamental insight about human and model evaluation cognition — relative comparison is more reliable than absolute calibration.
Absolute scores carry a calibration problem that compounds over time.
An evaluator (human or LLM) that rates responses ‘7 out of 10’ in week one might have a subtly different internal reference for ‘7’ by week four, especially after encountering different quality distributions. Pairwise comparison sidesteps this entirely: the question isn’t how good this response is in isolation, but which of these two options serves the user better.
When applying this insight to your judge calibration, pairwise evaluation reveals consistency gaps that pointwise scoring masks. A judge might assign a narrow score distribution (clustering most responses between 6 and 8) that looks stable in aggregate but conceals high variance in which specific responses it ranks above others.
Run the same pairs through the judge multiple times with randomized order and measure agreement. That’s the reliability signal that pointwise scoring can’t give you.
Applying Arena’s Elo Logic to Your Own Judge
You don’t need a crowdsourced platform to apply Arena’s statistical methodology. The core principle: aggregate pairwise comparisons across diverse conditions to produce stable reliability scores, translates directly to internal judge benchmarking.
Run a set of representative agent outputs through your judge in pairwise format, randomizing which response appears in position A versus position B. Run each pair twice with swapped positions.
Calculate agreement rate: how often does the judge give consistent preference rankings regardless of position? Compute inter-judge agreement across multiple judge instances using the same outputs. The resulting Elo-style reliability score tells you whether your judge is consistent enough to trust for production gates.
Envision a team running this calibration exercise on their content moderation agent and discovering their judge’s pairwise consistency drops from 87% to 61%, specifically on nuanced policy edge cases — responses that are technically compliant but tonally problematic.
That gap, invisible in their aggregate accuracy metrics, was allowing borderline outputs to pass evaluation regularly. Applying Arena’s methodology didn’t just reveal a bias; it identified exactly which evaluation category needed strengthening.
How to Benchmark Your LLM Judge Using MT-Bench and Chatbot Arena Methodology
Now that the frameworks are clear, the challenge is application. You cannot rely on generic benchmarks; you must validate how your specific judge performs on your specific data. Here is the step-by-step methodology for auditing your judge.
Establish Your Inter-Judge Agreement Baseline
Before you trust a score, you must measure the statistical agreement of your judge. This is done using metrics such as Cohen’s Kappa or Krippendorff’s Alpha, which measure agreement while accounting for the probability of chance agreement.
In the Survey on LLM-as-a-Judge (2025), researchers established clear thresholds. A Kappa score below 0.6 indicates your judge is unreliable, effectively guessing. A score between 0.6 and 0.8 represents moderate reliability, suitable for staging.
Only scores above 0.8 are considered production-grade. Be aware of the "Expert Domain Gap": in specialized fields such as healthcare or law, LLM judge agreement with human SMEs often drops to 60-68%, requiring significantly more calibration than in general conversational tasks.
Detect the Biases Silently Corrupting Your Scores
LLM judges are prone to systematic biases that skew results. The Zheng paper identified three primary offenders, with newer research adding nuanced variants:
Position Bias: Judges prefer the first answer in a pairwise comparison, sometimes by a swing of 25%.
Verbosity Bias: Judges confuse length with depth, preferring longer, "chattier" answers even if they contain less correct information.
Self-Enhancement Bias: A judge model tends to favor outputs that resemble its own training data or writing style.
To detect these, run a Position Swap Test: feed the same two answers to your judge, then swap their order. If the judge's decision flips solely based on order, you have a position bias. Use Galileo Signals to run these systematic experiments and visualize the bias distribution across your test set.
Apply Reference-Guided Evaluation to Hard Categories
One of the most powerful findings from MT-Bench is that reference-guided judging (providing the judge with a "Gold Standard" answer to compare against) reduces the failure rate on complex reasoning tasks from 70% to 15%.
For high-stakes categories like "Factual Accuracy" or "Code Correctness," relying on a judge's internal knowledge is risky. You must provide a reference.
Without Reference: Use for "Tone," "Helpfulness," or general "Chat quality."
With Reference: Mandatory for "Math," "Logic," and "Compliance."
Pairwise: Best for "Regression Testing" (A/B comparisons). Maintaining a versioned library of prompts and their corresponding reference answers is not optional admin work; it is the infrastructure required to lower your failure rate.
The production implementation requires maintaining a reference answer library: a curated, human-validated set of responses for your highest-stakes evaluation categories.
Calibrate Your Judge to Human Ground Truth
If your judge disagrees with your human SMEs, the judge might be wrong. Calibration is the process of aligning the two. Recent research from ChainPoll indicates that LLMs perform significantly better on binary (Yes/No) questions than on 1-10 Likert scales.
Reformulate abstract questions ("Rate safety 1-5") into concrete binary sets ("Does this contain PII? Yes/No." "Is the tone aggressive? Yes/No.").
Furthermore, use Continuous Learning via Human Feedback (CLHF). By providing just 2-5 "few-shot" examples of correctly graded responses (anchor examples) in the judge's prompt, you can radically improve alignment without fine-tuning a model from scratch.
Monitor for Judge Drift in Production
Models change. For instance, when OpenAI or Anthropic updates their API, the underlying behavior of your judge can shift. A judge that was perfectly calibrated in Q1 might become overly strict or lenient in Q2 due to an upstream RLHF update.
You must implement Judge Drift Monitoring. Pin your judge model versions (e.g., gpt-4-0613 instead of gpt-4-turbo), but also schedule quarterly recalibration reviews. Track your Kappa score over time using custom dashboards.
If inter-judge agreement declines, it signals that your evaluation infrastructure, not your agent, is degrading.
The monitoring infrastructure mirrors what you’d build for any production system: baseline metrics, alerting thresholds, and regular validation runs. The difference is that the degradation of judge reliability is harder to detect from user signals alone.
Your product might still look fine while your evaluation infrastructure has been quietly misleading you for weeks.
The Jury Architecture: Why Multiple Small Judges Beat One Large Judge
The final lesson from these benchmarks is architectural. Relying on a single, massive frontier model (like GPT-4) as a universal judge is often less effective (and always more expensive) than a Panel of Judges (Jury Architecture).
Research confirms that a "Jury" of three to five smaller, specialized models (like Galileo’s Luna-2) often outperforms a single large model. The statistical logic is simple: majority voting across an odd-numbered panel cancels out the stochastic variance and individual bias of any single model.
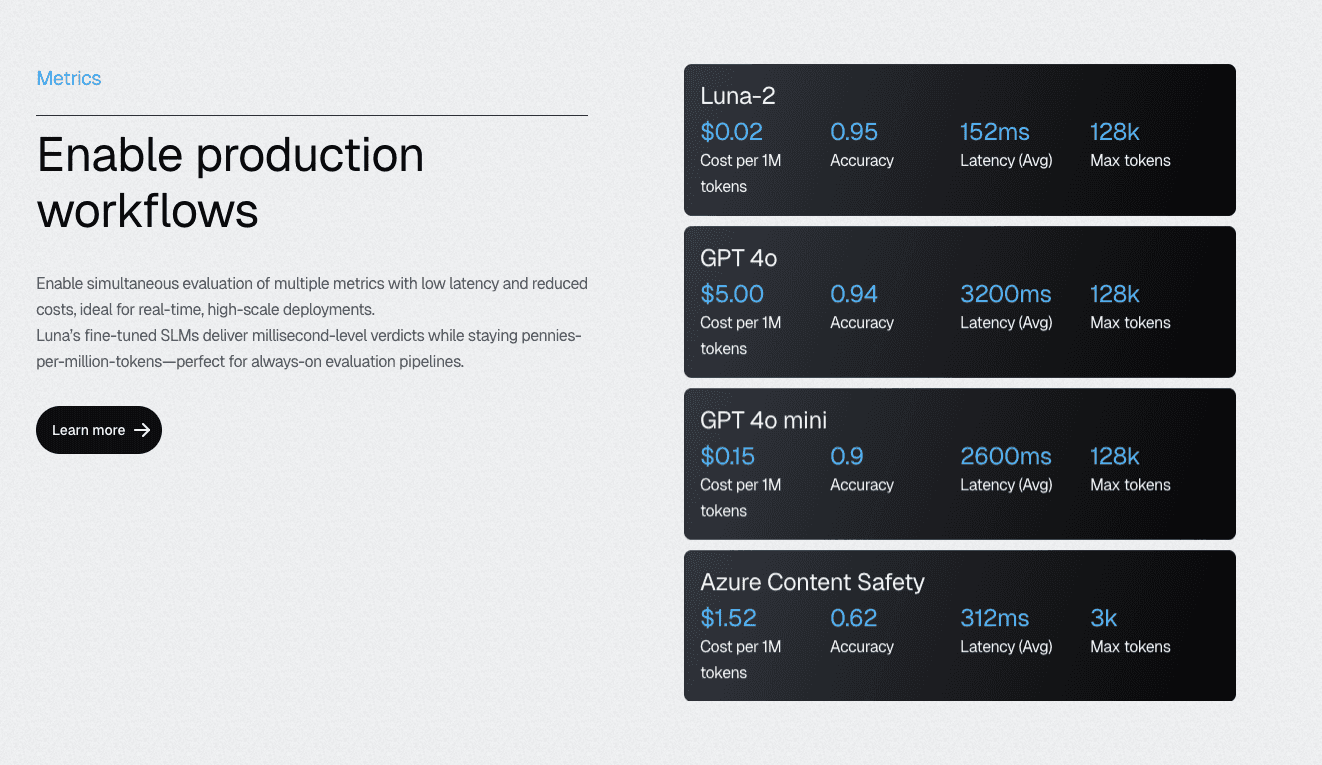
This solves the cost equation. Running a jury of specialized Small Language Models (SLMs) is a fraction of the cost of a single GPT-4 call. For production gates, ensure you set Temperature=0 to minimize inference noise.
Luna-2’s multi-headed architecture enables the production implementation of jury-style evaluation at scale. Running hundreds of metrics on shared infrastructure, with sub-200ms latency even when executing 10-20 metrics simultaneously, makes multi-judge consensus operationally feasible rather than a theoretical ideal that collapses under production load.
The architecture was designed specifically for the evaluation use case and was not adapted from general inference infrastructure.
The practical guideline for when to use each approach: a single judge for rapid prototyping and development iteration, where speed matters more than precision. Jury architecture for CI/CD evaluation gates, production quality monitoring, and any decision that affects what ships to users.
The cost of a wrong gate decision (shipping a degraded agent configuration) is almost always higher than the marginal cost of running additional judge instances.
Build Production-Grade LLM Judge Infrastructure with Galileo
An LLM judge you can’t benchmark is an LLM judge you can’t trust. The MT-Bench and Chatbot Arena frameworks established that reliable evaluation requires more than a capable model and a well-written prompt; it demands systematic bias detection, statistical reliability measurement, domain calibration, and architectural decisions that hold up under production scale.
Teams that skip these steps don’t just get inaccurate evaluations; they make product decisions guided by systematically misleading signals.
Here’s how Galileo provides the infrastructure elite teams use to build evaluation systems:
Comprehensive Coverage Through Graph View: Galileo automatically maps every decision point in multi-step agent workflows, identifies gaps where evaluation is missing, and transforms abstract coverage metrics into actionable engineering work that directly correlates with the 70.3% excellent reliability achieved by elite teams.
Cost-Effective Evaluation at Scale with Luna-2 SLMs: With evaluation costs 97% lower than GPT-4 alternatives and sub-200ms latency even when running 10-20 metrics simultaneously, Galileo enables teams to achieve the 70%+ coverage threshold without budget constraints
Automated Failure Detection via Signals: Rather than waiting for production incidents to reveal evaluation gaps, Galileo's Signals automatically surfaces failure patterns across agent traces
Runtime Protection: Galileo's industry-leading runtime guardrails catch hallucinations, policy violations, and safety issues in milliseconds at serve time, transforming the incident paradigm from reactive cleanup to preventive blocking
Continuous Improvement with Signals and CLHF: With Galileo, you can fine-tune specialized evaluation models on your domain using Continuous Learning via Human Feedback, achieving the consistency that 93% of teams report missing from standard LLM-as-a-judge approaches
Explore Galileo to see how you can build an LLM judge infrastructure that holds up under the conditions your production agents actually face.
Frequently asked questions
What is LLM-as-a-Judge evaluation, and why do teams use it?
LLM-as-a-Judge is an evaluation methodology where large language models assess AI outputs based on defined criteria like accuracy, relevance, and helpfulness. Teams adopt it because it scales: human evaluation creates bottlenecks when processing millions of outputs daily. LLM judges provide consistent application of criteria across evaluations, lower inter-rater variability, and lower per-evaluation costs than human annotators. They can assess qualitative properties such as helpfulness, tone, and coherence that rule-based metrics like BLEU or ROUGE cannot capture.
How do I reduce position bias in LLM evaluation results?
Position bias, where judges favor responses based on presentation order rather than quality, represents a critical reliability challenge affecting all major LLM judges across 150,000+ evaluation instances. Research on diverse judge models identifies two distinct biases: primacy bias, which favors the first solution presented, and recency bias, which favors the last solution. Mitigation requires randomizing response order across evaluation runs and averaging results across multiple orderings.
What's the difference between single-judge and ensemble evaluation approaches?
Single-judge evaluation uses a single LLM to assess outputs, inheriting all of that model's biases and failure patterns. Ensemble approaches deploy multiple judges in parallel (often from different model families) and aggregate results to reduce individual bias. Academic research and industry best practices converge on ensembles as the minimum viable architecture for production evaluation.
Do I need human evaluators if I'm using LLM-as-a-Judge?
Yes. But strategically rather than comprehensively. Hybrid workflows use automated LLM evaluation for bulk screening while routing edge cases, low-confidence scores, and policy violations to human review. Human evaluators also provide calibration data that keeps LLM judges aligned with ground truth over time. The goal isn't to replace human judgment but to deploy it efficiently where human expertise is most valuable.
How does Galileo's Luna-2 address LLM-as-a-Judge reliability challenges?
Galileo's Luna-2 models are purpose-built Evaluation Foundation Models (EFMs) for evaluation rather than adapted from general-purpose LLMs. The multi-headed architecture, with lightweight adapters on a shared core, enables simultaneous assessment across multiple metrics, reducing inconsistency from running separate evaluation passes. Sub-200ms latency supports real-time evaluation in production workflows, while a multi-task training methodology optimized for assessment tasks addresses systematic biases documented in academic research.
Jackson Wells