7 Best Prompt Engineering Platforms for Enterprise AI Teams

Jackson Wells
Integrated Marketing

Your production LLM application burns through API costs with unoptimized token usage. Without systematic optimization, token costs scale linearly—representing significant savings opportunity at enterprise scale. Meanwhile, your team faces consistency issues across different prompt versions running in production.
Gartner forecasts $14.2 billion in generative AI spending for 2025—a 148.3% year-over-year increase creating massive pressure on VP-level leaders to demonstrate ROI. Prompt engineering platforms solve these challenges by providing systematic version control, automated evaluation frameworks, and production observability that transforms LLM development from chaotic experimentation into disciplined engineering practice.
This analysis evaluates eight enterprise-grade platforms based on verified market signals, technical capabilities, and documented ROI metrics.
TLDR
Prompt engineering platforms provide version control, automated evaluation, and production monitoring for LLM applications—transforming chaotic experimentation into systematic practice
Enterprise implementations demonstrate significant cost savings through optimized token usage and systematic testing frameworks
Galileo leads with the industry's Agent Observability Platform featuring proprietary Luna-2 models (97% cost reduction, 21x faster than GPT-4o) and runtime intervention capabilities
What is a prompt engineering and optimization platform?

A prompt engineering and optimization platform is systematic infrastructure for developing, testing, versioning, and monitoring the prompts that control LLM behavior. You get visibility into what's actually happening when prompts execute: input variations, model responses, evaluation scores, token consumption, latency measurements, and production performance data.
Core capabilities include prompt versioning with Git-like change tracking, automated evaluation against quality metrics, A/B testing for comparing variations, and production observability that surfaces failures before customers report them.
These platforms understand LLM-specific challenges that traditional monitoring tools miss: non-deterministic outputs, context window management, multi-turn conversation tracking, and token-level cost attribution.
They answer "is this prompt producing reliable, cost-effective, safe outputs at scale?" with comprehensive evaluation across response quality, safety metrics, agentic performance, and RAG system capabilities. For VP-level decision makers, these platforms transform LLM deployments from high-risk experiments into managed capabilities with predictable cost structures and audit trails that satisfy compliance requirements.
Galileo
Galileo provides the industry's leading Agent Observability Platform with real-time evaluation, automated failure detection, and runtime protection designed to make AI agents reliable.
The platform features proprietary Luna-2 evaluation models that deliver F1 scores of 0.95 at just $0.02 per million tokens, representing 97% cost reduction compared to GPT-4 evaluation workflows, while operating at 152 milliseconds average latency—21x faster than GPT-4o's 3,200ms evaluation performance. This economic efficiency enables comprehensive evaluation that would be prohibitively expensive using frontier models.
The multi-headed architecture enables hundreds of metrics on shared infrastructure with agent-specific capabilities, including tool selection quality metrics, flow adherence tracking, and unsafe action detection. Continuous Learning via Human Feedback (CLHF) enables rapid metric customization with just 2-5 examples, transforming weeks of manual evaluator development into minutes of configuration.
Key Features
Comprehensive observability for multi-agent workflows
Proprietary Luna-2 evaluation models with 97% cost reduction vs GPT-4
Automated Insights Engine for instant failure detection
Runtime protection via guardrail metrics
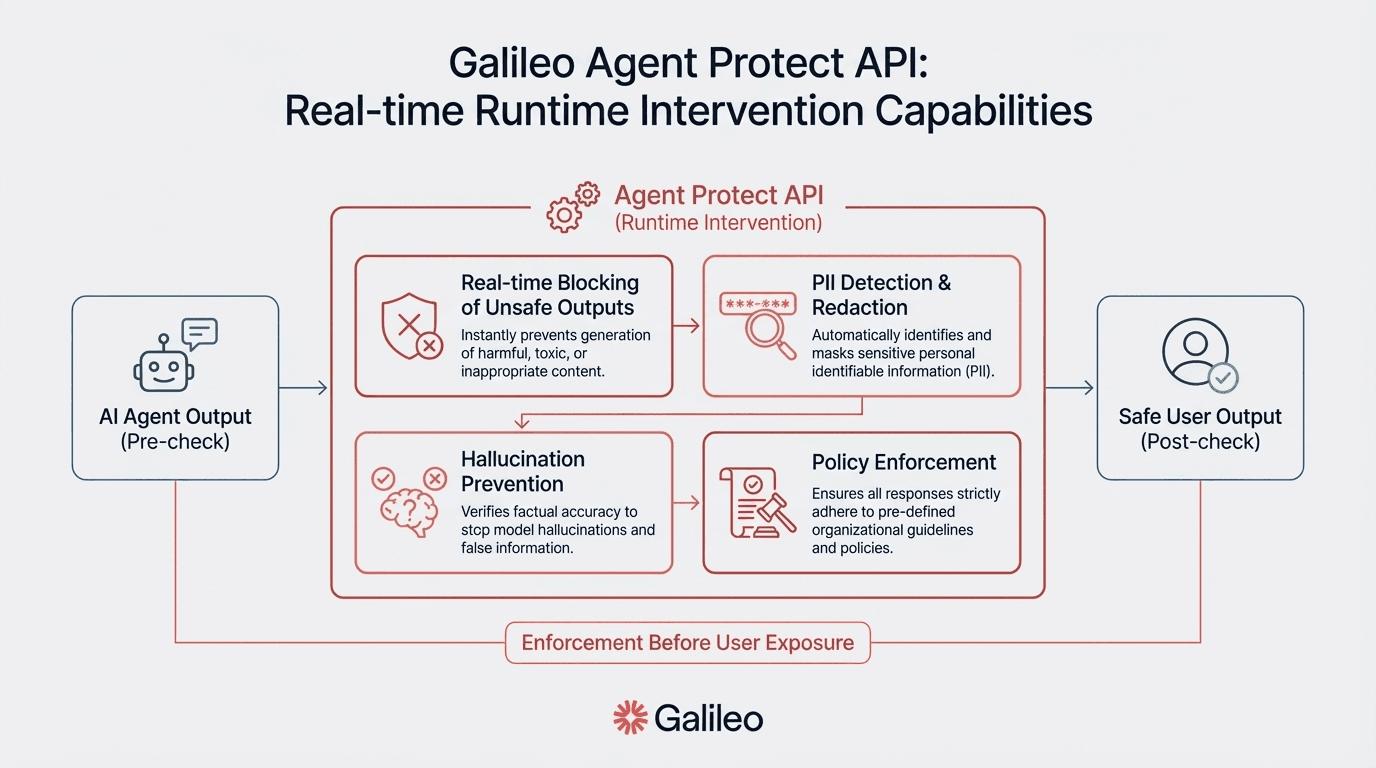
Agent Protect API delivering deterministic override and passthrough actions enabling real-time blocking of unsafe outputs, PII detection and redaction, hallucination prevention through fact-checking, and policy enforcement before actions reach users
Agent Graph visualization showing multi-step decision paths and tool interactions across complex workflows
Multi-agent tracing that tracks how decisions evolve across turns and agents
Processing over 20 million traces daily while supporting 50,000+ live agents on a single platform
Comprehensive framework integrations including LangChain, OpenAI SDK, LlamaIndex, Haystack, AutoGen, and Databricks
Strengths and Weaknesses
Strengths
Industry's only runtime intervention capability through Agent Protect API—capabilities unavailable in competitor platforms offering only passive monitoring
Purpose-built for agents with every feature addressing agent-specific challenges
Agent Insights Engine automatically surfaces failure patterns including tool selection errors, planning breakdowns, and execution loops—reducing debugging time from hours to minutes
Transparent pricing structure starting with a functional free tier (5,000 traces/month, unlimited users) scaling predictably to enterprise deployments
Multi-deployment flexibility including on-premise, hybrid, and cloud configurations
Enterprise security features include SOC 2 Type 2 compliance with flexible deployment options that keep sensitive data within organizational boundaries
Weaknesses
Platform specialization in agent observability may be more than needed for simpler LLM applications
Advanced features require understanding of agent-specific concepts and workflows
Use Cases
Organizations like Twilio use Galileo for autonomous evaluation of AI assistants without ground truth. Magid achieved 100% visibility on all AI inputs and outputs with zero monitoring blind spots. Organizations in regulated industries benefit from audit trail capabilities and runtime guardrails that prevent policy violations before they reach production.
LangSmith
LangSmith has received notable market validation, with LangChain raising $125 million at $1.25 billion valuation.
The platform provides deep tracing infrastructure capturing complete execution paths through complex chains and autonomous agents, operating as a framework-agnostic solution that supports applications built with any orchestration layer. LangSmith offers a comprehensive platform spanning the complete development lifecycle from initial experimentation through production monitoring.
Key Features
Deep tracing infrastructure capturing complete execution paths through complex chains and autonomous agents
Framework-agnostic operation supporting applications built with any orchestration layer
Advanced debugging capabilities with detailed trace visualization
Built-in testing frameworks with comprehensive validation
Agent Builder (Beta) for visual agent construction
Strengths and Weaknesses
Strengths
Comprehensive platform spanning the complete development lifecycle from initial experimentation through production monitoring
Enterprise security certifications include SOC 2 Type 2, HIPAA, and GDPR compliance
Flexible deployment options—managed cloud, hybrid, and self-hosted configurations that keep sensitive data within organizational boundaries
Weaknesses
The Agent Builder remains in beta with potential feature limitations
The comprehensive feature set requires significant onboarding investment for teams to realize full value
While a free tier is available, detailed paid tier specifications require direct vendor inquiry, creating budget planning challenges
Use Cases
Organizations building complex LLM applications with multi-step reasoning chains leverage LangSmith's comprehensive observability to debug intricate failure modes. Enterprises requiring security certifications for regulated deployments benefit from verified compliance features and flexible deployment options that maintain data sovereignty. Teams managing production agents at scale use deep tracing to understand decision paths and identify bottlenecks across multi-agent workflows.
Weights & Biases
Weights & Biases extends its established ML experiment tracking platform into generative AI with comprehensive prompt engineering capabilities. Among the eight verified enterprise-grade platforms analyzed, W&B is the only one appearing in Gartner's November 2025 Magic Quadrant for AI Application Development Platforms—providing third-party analyst validation unavailable for competitors. The platform offers a unified experience for teams working across both traditional ML and generative AI domains, featuring the Weave platform that specializes in agentic AI development with prompt management including complete versioning and tracing.
Key Features
Comprehensive experiment tracking across traditional ML and generative AI initiatives
Weave platform specializing in agentic AI development with prompt management including complete versioning and tracing
Collaborative dashboards for team coordination
Extensive integration support with major ML frameworks
Strengths and Weaknesses
Strengths
Unified platform eliminates context switching for teams working across both traditional ML and generative AI domains
Enterprise security options include SOC 2 Type 2 compliance and self-hosted deployment addressing data sovereignty requirements
Reduces implementation friction through extensive framework integrations
Weaknesses
Pricing complexity spans multiple tiers (Free, Pro at $60/month per user, Enterprise custom) with unclear scaling mechanics creating cost uncertainty at enterprise scale
Free tier constraints limit production workload viability
The platform's comprehensive feature breadth requires substantial onboarding investment to realize full value
Use Cases
Organizations maintaining both traditional ML pipelines and LLM applications benefit from the unified platform preventing tool fragmentation. Teams requiring detailed experiment tracking for hyperparameter optimization leverage comprehensive logging infrastructure. Enterprises in regulated industries use self-hosted options while maintaining access to full feature sets including SOC 2 Type 2 and GDPR compliance capabilities. Data science teams coordinating across multiple AI initiatives use collaborative dashboards for unified visibility.
Humanloop
Humanloop focuses specifically on enterprise production deployments with strong emphasis on security and compliance. The platform's architecture supports production deployments with enterprise-grade security features including SOC-2 compliance and self-hosting availability for regulated environments. With a strong security posture and access controls, Humanloop addresses compliance requirements in healthcare, financial services, and government deployments.
Key Features
Integrated evaluation suites for systematic performance validation
Prompt versioning with organizational systems
SDK/API integration supporting existing orchestration layers
Production observability and logging infrastructure
Strengths and Weaknesses
Strengths
Architecture supports production deployments with enterprise-grade security features including SOC-2 compliance
Self-hosting availability for regulated environments
Strong security posture and access controls address compliance requirements in healthcare, financial services, and government deployments
Weaknesses
Limited public user reviews compared to competitors reduce confidence in real-world deployment satisfaction
Pricing opacity with no public enterprise pricing details disclosed creates budget planning challenges for procurement evaluations
Use Cases
Organizations in regulated industries deploying production AI products leverage SOC-2 compliance features and self-hosting availability. Teams requiring systematic LLM evaluation before production release use integrated evaluation frameworks. Enterprises needing on-premise deployment for data sovereignty implement self-hosted architecture while maintaining access to evaluation, versioning, and monitoring capabilities.
Braintrust Data
Braintrust delivers integrated infrastructure spanning prompt engineering, evaluation, and production monitoring. The platform emphasizes unified workflows that integrate evaluations, prompt management, and monitoring without context switching, enabling fast iteration capabilities and quick benchmarking cycles. Developer feedback highlights the streamlined unified workflows as a key advantage, along with transparent pricing that includes a generous free tier.
Key Features
Unified workflows integrating evaluations, prompt management, and monitoring without context switching
Fast iteration capabilities enabling quick benchmarking cycles
Prompt playground with batch testing and AI-powered assistance
Production monitoring with automated alerts
Strengths and Weaknesses
Strengths:
Transparent pricing with generous free tier (1M trace spans, 1 GB processed data, unlimited users) enables extensive evaluation before paid commitment
Developer feedback highlights streamlined unified workflows
Weaknesses
Developer reports identify limited agent-specific features including constrained session-level evaluations and graph debugging capabilities
System prompt inflexibility creates constraints for advanced use cases
Enterprise-only self-hosting limits accessibility
Use Cases
Teams prioritizing rapid iteration cycles use the prompt playground with batch testing and AI-powered assistance. Organizations requiring comprehensive evaluation across accuracy, consistency, and safety metrics leverage the unified evaluation system. Development teams needing production monitoring with automated alerts benefit from integrated observability. Budget-conscious organizations starting AI initiatives use the generous free tier for extensive testing before paid commitment.
Helicone
Helicone takes a distinct architectural approach as an open-source LLM gateway and observability platform focused on production-scale API management. Rather than emphasizing prompt development workflows, Helicone positions itself as infrastructure between applications and LLM providers. The platform's high-performance infrastructure introduces minimal latency overhead while providing sophisticated routing with health-aware strategies and provider failover capabilities.
Key Features
Open-source gateway providing unified routing across providers with real-time monitoring
Granular cost tracking with budget alerting
Rate limiting and intelligent response caching
Health-aware load balancing with provider failover
Strengths and Weaknesses
Strengths
High-performance infrastructure introduces minimal latency overhead
Sophisticated routing enables health-aware strategies with provider failover
Cost optimization through caching addresses token consumption tracking
Open-source transparency provides security validation
Weaknesses
The gateway architecture requires separate cost tracking
May raise latency concerns for risk-averse organizations
Limited UI features reflect infrastructure emphasis over visual development tools
Use Cases
Organizations managing multi-provider LLM strategies use unified routing with intelligent failover. Cost-sensitive deployments leverage response caching and granular cost tracking with budget alerts. High-volume production systems benefit from rate limiting and load balancing capabilities. Teams requiring security validation use open-source transparency for internal audits.
PromptLayer
PromptLayer provides comprehensive logging, versioning, and management infrastructure with focus on team collaboration. The platform offers comprehensive workflow coverage that reduces tool fragmentation, along with flexible team management that addresses enterprise collaboration needs. With transparent pricing, PromptLayer enables straightforward budget planning for organizations at various stages of growth.
Key Features
Comprehensive API request logging with detailed metadata tracking
Version control enabling rollback and comparison
Built-in evaluation capabilities
Team workspaces with collaborative editing
Performance monitoring tools
Strengths and Weaknesses
Strengths
Comprehensive workflow coverage reduces tool fragmentation
Flexible team management addresses enterprise collaboration
Transparent pricing enables straightforward budget planning
Weaknesses
Constrained free tier requires early graduation to paid plans
Per-user pricing at $49/month scales significantly for larger organizations
Use Cases
Teams requiring detailed logging of all LLM interactions use comprehensive metadata tracking. Organizations needing systematic prompt versioning leverage rollback and comparison capabilities.
Collaborative development teams use workspaces for coordinated prompt engineering. Growing startups benefit from transparent pricing enabling straightforward budget planning for scaling initiatives.
Choosing the Right Prompt Engineering Platform for Your Enterprise
Prompt engineering platforms have become essential infrastructure for enterprises deploying production LLM applications, providing the version control, automated evaluation, and observability needed to transform chaotic experimentation into disciplined engineering practice.
While each platform offers distinct strengths—from LangSmith's tracing depth to Weights & Biases' unified ML platform—Galileo stands apart as the industry's leading Agent Observability Platform. With proprietary Luna-2 models delivering 97% cost reduction, the industry's only runtime intervention capability through Agent Protect API, and proven scale processing 20M+ traces daily, Galileo provides the comprehensive infrastructure enterprises need for reliable, production-ready AI agents.
Galileo delivers enterprise-grade agent observability infrastructure:
Luna-2 evaluation models: 97% cost reduction compared to GPT-4 evaluations with 21x latency improvement (152ms vs 3,200ms)
Agent Protect API: Industry's only runtime intervention with deterministic override/passthrough actions
Automated Insights Engine: Instant failure detection with actionable root cause analysis for agent workflows
Agent Graph & Multi-Agent Tracing: Deep visibility into tool selection, planning, and multi-turn decision paths
20+ agent-specific metrics: Tool selection quality, flow adherence, RAG systems, and safety
Proven enterprise scale: 20M+ traces daily, 50K+ agents on single platform
Comprehensive framework support: LangChain, OpenAI SDK, LlamaIndex, Haystack, AutoGen integration
Transparent pricing: Functional free tier scaling to enterprise unlimited deployment
Explore how Galileo transforms agent development from chaotic experimentation into systematic production capability with Zero-Error Agents.
Frequently asked questions
What is a prompt engineering and optimization platform?
Prompt engineering platforms provide systematic infrastructure for developing, testing, versioning, and monitoring prompts that control LLM behavior. They collect comprehensive telemetry including prompt variations, model responses, evaluation scores, token consumption, and latency metrics.
Core capabilities include version control, automated testing, A/B experimentation, and production observability that transform LLM development from trial-and-error into disciplined engineering practice with measurable quality and predictable costs.
How do these platforms improve LLM application reliability?
These platforms improve reliability through systematic evaluation frameworks testing prompts against comprehensive quality metrics before production deployment, automated failure detection surfacing degradation patterns, version control preventing inconsistent behavior, and production observability providing real-time alerting when performance degrades.
Your team identifies and resolves problems proactively through continuous monitoring and automated regression testing validating every prompt change against baseline performance benchmarks.
When should enterprises invest in dedicated prompt engineering platforms?
Enterprises should invest when LLM applications transition from experimental projects to production systems affecting customer experience, when prompt management becomes chaotic with multiple variants lacking clear ownership, when debugging time consumes significant engineering capacity, when token costs accumulate without systematic tracking, or when regulatory requirements demand audit trails.
Organizations deploying autonomous agents making sequential decisions require these platforms from inception given multi-step workflow debugging complexity.
How does Galileo differ from competitors in this space?
Galileo distinguishes itself as the industry's leading Agent Observability Platform purpose-built for autonomous systems rather than retrofitted from simpler use cases. The platform provides the industry's only runtime intervention capability through Agent Protect API with deterministic override and passthrough actions that prevent harmful outputs before user impact.
Proprietary Luna-2 evaluation models deliver 97% cost reduction and 21x latency improvement compared to GPT-4o evaluations, while the Insights Engine automatically identifies agent-specific failure patterns including tool selection errors and planning breakdowns. Proven enterprise scale processing 20M+ traces daily with 50K+ agents on single platform demonstrates production readiness unavailable in emerging competitors.
What ROI can enterprises expect from these platforms?
Forrester's Total Economic Impact study documents 333% ROI with $12.02 million net present value from enterprise AI platform implementations. Bain & Company research demonstrates up to 25% total cost savings when combining platform capabilities with process redesign. However, ROI varies significantly based on implementation sophistication—organizations combining prompt optimization with end-to-end process redesign achieve substantially higher returns.
Jackson Wells