Why Is Your LLM-as-a-Judge Inconsistent? 7 Reasons Teams Get It Wrong

Jackson Wells
Integrated Marketing

You know the engineering experience: you build an LLM-based judge, it looks brilliant on day one, the scores seem perfectly reasonable, and you ship it with confidence. Then, a few weeks later, the exact same production trace receives a 91 on Monday and a 64 on Wednesday.
Nothing in your application code changed. The user's prompt didn't change. The judge did.
According to our latest industry data, 93% of teams using LLM-as-a-judge report major reliability issues, primarily due to consistency failures. This is not a niche edge case; it is the default enterprise experience.
However, the solution is not to abandon the methodology. Our research proves that teams that avoid AI-based evaluation entirely hit a reliability ceiling they cannot break through. LLM-as-a-judge is not inherently broken. The problem lies entirely in how teams implement, architect, and maintain it.
By diagnosing the root causes of these failures, engineering leaders can transition from noisy, unpredictable evaluation pipelines to deterministic quality gates. Here are the seven specific, diagnosable mistakes that explain why most judges fail in production, and what elite teams do differently.
TL;DR:
Most teams ask judges for 0–100 scores when binary yes/no questions deliver dramatically more consistency
A single judge call is insufficient — one opinion from a probabilistic system isn't evidence
Judge prompts built at launch drift in production without continuous autotuning from real false positive learnings
Over-reliance on large general-purpose models creates cost spirals that force damaging coverage compromises
Evaluating individual behaviors in isolation misses compound failures where small errors cascade into critical incidents

1. Asking for Scores When You Should Ask for Verdicts
The most common structural mistake teams make is prompting their judges to return numeric scores on a 0-100 scale or a 1-10 rating. They want granular data, but they sacrifice reliability to get it.
LLMs lack natural numeric calibration.
What exactly is the difference between an 8 and a 9?
The answer depends entirely on the day, the underlying model version, and the probabilistic token sampling of that specific API call.
Galileo's ChainPoll research demonstrated the fix clearly: binary yes/no questions produce dramatically more consistent judgments. Instead of "rate this response 0–100 for clinical accuracy," ask "Does this response contain any clinically inaccurate statements?"
The judge answers yes or no. That answer is reproducible in ways that numeric scores never are. ChainPoll achieved 23% accuracy improvement over single-shot GPT-4 baselines — not through a better model, but through better question design.
Picture a team averaging judge scores across 10,000 daily evaluations. If the model’s internal baseline drifts by just 8 points over a week, trend analysis becomes meaningless. Is the application quality actually improving, or is the judge simply recalibrating its own internal scale?
To fix this, decompose subjective quality into specific, binary questions: "Does this response contain a hallucinated fact? Yes/No." "Does this response directly answer the user's primary question? Yes/No." Even with better questions, however, one answer is rarely enough.
2. Trusting a Single Judge Opinion
Another critical failure point is running a single evaluation call and treating the resulting output as ground truth. Engineers are trained to treat software as deterministic — a function runs once and returns the absolute truth.
But LLMs are inherently probabilistic.
Token sampling introduces natural variation that makes single-call judgments fundamentally unreliable. The exact same trace can receive a "Pass" on a Tuesday and a "Fail" on a Wednesday.
Elite teams solve this using the jury principle.
Multiple judges voting by majority consensus dramatically outperforms single calls. Using three to five smaller judges actually costs less than routing a single call to an expensive reasoning model, all while achieving significantly higher accuracy.
Envision a team gating their deployments on single-judge scores. A borderline code change passes the CI/CD pipeline in the morning because the judge rolled the probabilistic dice favorably, but fails an hour later on a retry.
The CI/CD gate becomes a source of noise rather than a signal. By using odd-numbered panels, teams filter out individual sampling variance. Majority voting prevents stalemates and surfaces genuine quality signals.
The fix doesn't require expensive models or complex architecture. Run three judges. Require two out of three to agree before making a quality decision. That simple change transforms a noisy signal into a reliable one — the same insight that made ChainPoll one of the most cited early papers on LLM evaluation methodology.
Consensus helps filter noise, but it only works if judges consistently ask the right questions over time.
3. Building a Judge Once and Never Updating It
Many teams treat their judge prompts as static artifacts; they are meticulously crafted during the development phase, deployed at launch, and then largely forgotten. This is a recipe for silent failure. Production data drifts, user behavior evolves, and edge cases emerge that were never represented in the original training examples.
As practitioners frequently note, the first version of a judge will never give you the best long-term results. A judge calibrated exclusively for launch-day traffic becomes increasingly miscalibrated as application usage matures.
Consider a team whose judge was built when their support agent handled only simple billing queries. Six months later, users are asking complex, multi-step technical questions. The judge was never trained on these new patterns, so it starts scoring these interactions confidently, but completely incorrectly.
The fix requires an autotuning workflow that continuously updates judge prompts based on false positives discovered in production. Including a few-shot set of examples drawn from real disagreements is vital, and goes a long way toward recalibration.
Galileo's Continuous Learning via Human Feedback (CLHF) capability automates this process, detecting when evaluation drift occurs and updating prompts based on production learnings without requiring manual prompt engineering cycles as the application evolves.
By leveraging CLHF, teams can automatically update their evaluation prompts based on real-world production learnings, preventing drift before it corrupts metrics.
Yet, even well-maintained judges will fail at scale if the wrong underlying model powers them.
4. Using the Wrong Model for Evaluation Tasks
A pervasive trap in AI engineering is defaulting to the largest, most capable general-purpose model available as the judge. Teams logically assume that if a frontier model is superior at general reasoning, it will naturally be a superior judge.
This creates significant capability overhead that adds no value to evaluation accuracy but imposes crippling cost, latency, and context-length complexity. Evaluation does not require broad world knowledge; it requires precise, domain-specific judgment.
Purpose-built evaluation models with domain-specific tuning consistently outperform general-purpose giants on assessment tasks.
This over-engineering leads to a predictable cost spiral.
Picture a team evaluating 500,000 daily interactions at frontier model pricing. Their monthly evaluation costs can hit five figures before they have even covered half of their system's behaviors.
This forces them to make dangerous compromises in coverage — the exact opposite of their original goal. By migrating to specialized evaluation models, such as the Luna-2 SLMs, teams can achieve a 97% cost reduction while improving evaluation accuracy.
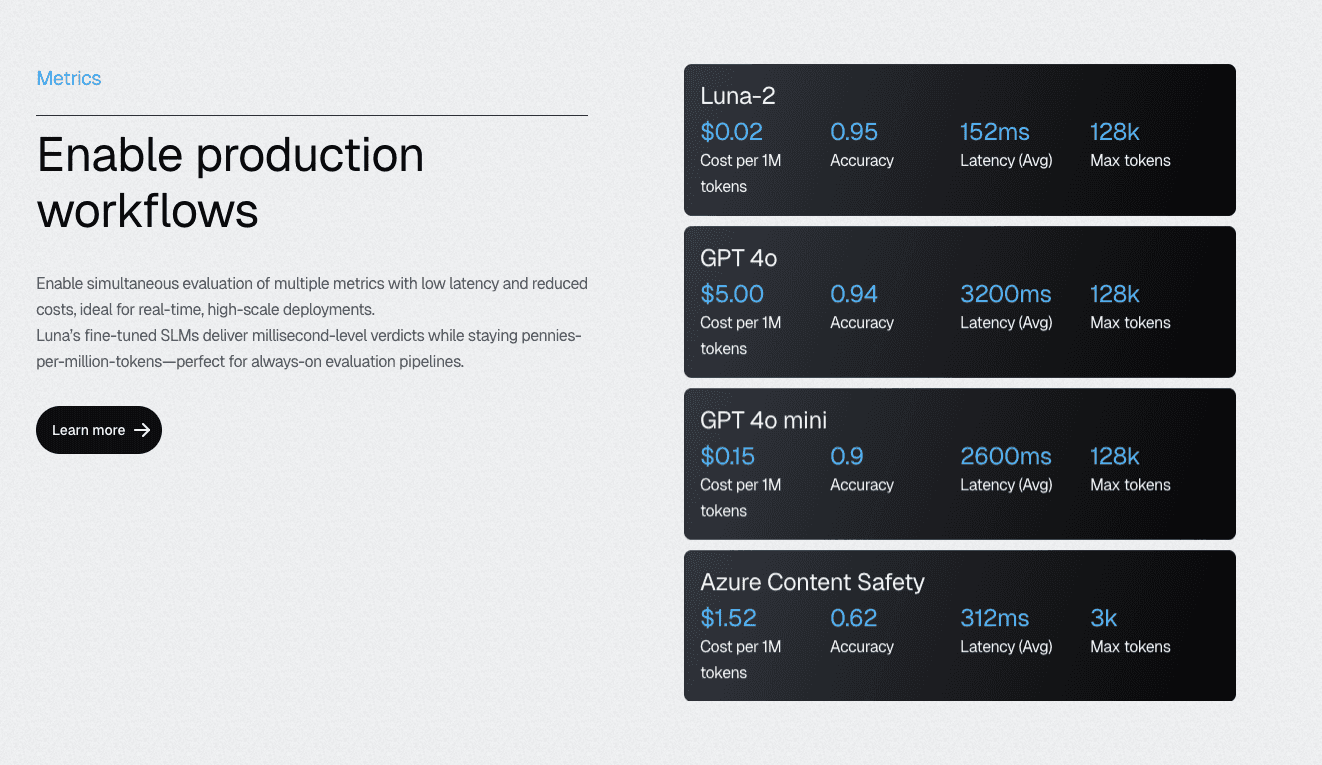
Luna-2 SLMs deliver 97% cost reduction compared to GPT-4 alternatives while maintaining accuracy through specialization. The multi-headed architecture enables the simultaneous execution of 10–20 evaluation metrics on shared infrastructure. Suddenly, comprehensive coverage becomes economically feasible rather than a budget negotiation.
However, even the most cost-efficient, specialized judges will fail if their prompts lack critical context.
5. Writing Judge Prompts Without Few-Shot Examples
A surprising number of engineering teams build judge prompts that consist solely of a system prompt and a high-level quality description, completely omitting examples of what "good" and "bad" outputs actually look like.
Without grounding examples, LLMs interpret ambiguous quality criteria differently across runs. A directive like "ensure a professional tone" means something entirely different to a judge operating with zero context versus a judge grounded in five domain-specific examples of professional versus unprofessional corporate communication.
Few-shot examples train the model, ensuring the prompt is sufficiently informative for the AI to make a highly specific, repeatable decision.
Envision a healthcare compliance judge evaluating whether agent responses follow strict clinical guidelines. Without examples, the judge relies on its generalized internet training data to interpret "clinical guidelines," completely missing the highly specific protocols of that individual hospital network.
The tactical fix is immediate: provide two to five carefully selected examples for each quality dimension. Crucially, these examples must be drawn from real false positives discovered in production, not hypothetical cases invented by a developer at a whiteboard.
Prioritize examples from real disagreements between the judge and human reviewers — these represent calibration gaps the original prompt didn't address. Resist the temptation to add dozens of examples to address every edge case; context length grows, focus diffuses, and consistency often decreases. Start small and refine from production feedback.
But good prompts with great examples will still fail if you ignore the broader system context.
6. Evaluating Behaviors in Isolation Rather Than System-Wide
As AI architectures shift from simple chat interfaces to complex, agent-based workflows, evaluating individual behaviors in a vacuum becomes a significant liability. The failure mode here is the compound error.
An agent component that scores an isolated 95% accuracy rate can easily trigger a critical incident when its slightly flawed output feeds into a downstream agent.
Small errors cascade.
For example, an LLM might hallucinate the last two digits of a bank account number during a retrieval step. Individually, that output appears reasonable and passes local evaluation. But downstream, another agent uses that fabricated account number to execute a fund transfer. The compound failure is catastrophic, yet neither component's individual evaluation predicted it.
Picture a multi-agent research workflow where each individual step (document retrieval, summarization, and recommendation) scores perfectly. However, the critical context from step one fails to transfer correctly to step three, resulting in a final output that contradicts the source material.
The fix requires moving beyond point-in-time checks. Teams must use multi-turn session tracking and visual mapping, such as Graph Engine, to evaluate system-wide behavior and trace complete decision paths across the entire workflow.
The planning question for engineering teams: does your evaluation infrastructure assess individual agent outputs, or does it track behavior across the complete execution path? Teams that can only answer the first question are flying blind on the failure modes that cause their most severe production incidents.
Even system-wide evaluation fails, however, when teams focus only on budgets rather than outcomes.
7. Conflating Evaluation Cost with Evaluation Quality
The final trap is a financial one: assuming that a cheaper evaluation inherently means a worse evaluation. When teams believe they must use the most expensive models to get accurate judgments, they face a false choice: run a comprehensive evaluation that blows the IT budget, or run an affordable evaluation that leaves massive coverage gaps.
Both paths lead to production incidents.
One fails the balance sheet, the other fails the user. The bitter irony is that teams that spend the most per evaluation (by using frontier models for every interaction) often achieve the lowest total coverage. Spending more per evaluation while evaluating less achieves demonstrably worse reliability outcomes than spending less per evaluation while evaluating your entire system.
Consider a team running GPT-4 evaluations on just 20% of their production traffic due to strict cost constraints. They are highly confident about that 20%, but completely blind to the other 80%.
The next critical production incident inevitably arises from the uncovered majority — exactly where budget constraints forced them to cut corners. The fix is to optimize the cost per evaluation to enable comprehensive coverage, rather than reducing your evaluation scope to fit an arbitrary budget.
The question shifts from "which behaviors can we afford to test" to "what quality standards should every behavior meet" — a fundamentally different and more productive engineering conversation.
Recognizing these seven mistakes is the diagnosis. Fixing them requires the right infrastructure.
Fix Your LLM Judge with Galileo Comprehensive Evaluation
Each of these seven mistakes is diagnosable and fixable. None requires abandoning LLM-as-a-judge — research shows that abandoning it entirely prevents achieving elite reliability levels.
What changes?
The architecture, the maintenance discipline, and the infrastructure that make a comprehensive, consistent evaluation sustainable at scale.
Here’s how Galileo addresses each failure pattern directly:
Binary Question Frameworks and CLHF Autotuning: Replace numeric-score drift with consistent binary verdicts that automatically improve by reducing production false positives, keeping judges calibrated as applications evolve without manual prompt engineering cycles.
Multi-Headed Luna-2 Architecture for Consensus Evaluation: Jury-style evaluation from multiple specialized models costs less than single frontier model calls while achieving higher consistency — solving the single-judge reliability problem at the infrastructure level.
Continuous Prompt Optimization from Production Learnings: Automatically detects calibration drift and updates judge prompts from real false positives, ensuring evaluation quality improves over time rather than degrading as application usage matures.
Specialized Evaluation Models at 97% Lower Cost Than GPT-4 Alternatives: Make comprehensive coverage economically feasible, eliminating the budget-versus-coverage trade-off that forces teams to evaluate 20% of interactions and hope the other 80% behaves.
Multi-Turn Session Tracking and Graph Engine: Evaluates system-wide behavior across complete agent workflows and tool call sequences — catching compound failures that component-level evaluation was never designed to detect.
Explore how Galileo can help you build an evaluation infrastructure that stays reliable from day one through production at scale.
Frequently asked questions
What is LLM-as-a-Judge evaluation, and why do teams use it?
LLM-as-a-Judge is an evaluation methodology where large language models assess AI outputs based on defined criteria like accuracy, relevance, and helpfulness. Teams adopt it because it scales: human evaluation creates bottlenecks when processing millions of outputs daily. LLM judges provide consistent application of criteria across evaluations, lower inter-rater variability, lower per-evaluation costs than human annotators, and can assess qualitative properties such as helpfulness, tone, and coherence that rule-based metrics like BLEU or ROUGE cannot capture.
How do I reduce position bias in LLM evaluation results?
Position bias, where judges favor responses based on presentation order rather than quality, represents a critical reliability challenge affecting all major LLM judges across 150,000+ evaluation instances. Research on diverse judge models identifies two distinct biases: primacy bias, which favors the first solution presented, and recency bias, which favors the last solution. Mitigation requires randomizing response order across evaluation runs and averaging results across multiple orderings.
What's the difference between single-judge and ensemble evaluation approaches?
Single-judge evaluation uses a single LLM to assess outputs, inheriting all of that model's biases and failure patterns. Ensemble approaches deploy multiple judges in parallel (often from different model families) and aggregate results to reduce individual bias. Academic research and industry best practices converge on ensembles as the minimum viable architecture for production evaluation.
Do I need human evaluators if I'm using LLM-as-a-Judge?
Yes. But strategically rather than comprehensively. Hybrid workflows use automated LLM evaluation for bulk screening while routing edge cases, low-confidence scores, and policy violations to human review. Human evaluators also provide calibration data that keeps LLM judges aligned with ground truth over time. The goal isn't to replace human judgment but to deploy it efficiently where human expertise is most valuable.
How does Galileo's Luna-2 address LLM-as-a-Judge reliability challenges?
Galileo's Luna-2 models are purpose-built small language models for evaluation rather than adapted from general-purpose LLMs. The multi-headed architecture, with lightweight adapters on a shared core, enables simultaneous assessment across multiple metrics, reducing inconsistency from running separate evaluation passes. Sub-200ms latency supports real-time evaluation in production workflows, while a multi-task training methodology optimized for assessment tasks addresses systematic biases documented in academic research.
Jackson Wells