Gemini-2.5-flash Overview
Explore gemini-2.5-flash performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Gemini-2.5-flash Overview
Your AI applications need speed without burning through your budget. Gemini-2.5-flash solves this exact problem—it's Google's first Flash-tier model that shows its reasoning process, bringing transparent thinking to a speed-optimized package. You get one million input tokens (roughly 1,500 A4 pages) with responses streaming back in under a second.
Released in June 2025, this model combines long-context processing, rapid turnaround, and the lowest pricing in the Gemini family. That makes it the natural choice for high-volume chat, summarization, and agentic workflows where every millisecond and cent matter.
The Mixture-of-Experts architecture activates only the expert modules your prompt actually needs, keeping costs low. Google calls it their "best in terms of price-performance," and independent benchmarks confirm competitive accuracy alongside industry-leading throughput. When you need production-grade quality but can't justify Pro-level spending, this model consistently makes the shortlist.
Check out our Agent Leaderboard and pick the best LLM for your use case

Gemini-2.5-flash performance heatmap
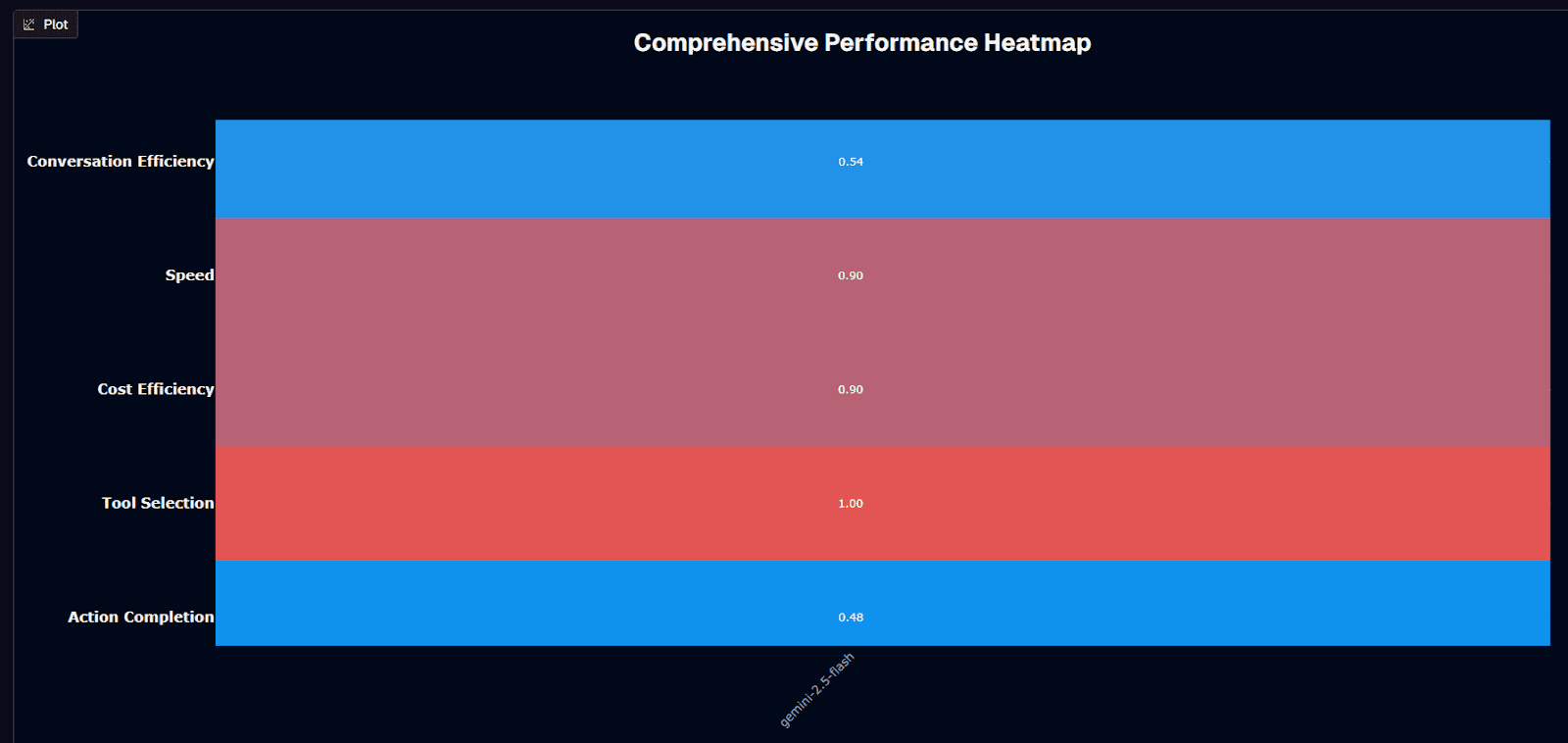
Gemini-2.5-flash delivers its strongest performance in tool selection, scoring a perfect 1.00. Speed and cost efficiency both hit 0.90, confirming the model's positioning as a budget-friendly, high-throughput option. Conversation efficiency lands at 0.54, while action completion settles at 0.48—just below the halfway mark.
The perfect tool selection score means your agent frameworks won't misfire when routing to calculators, APIs, or retrieval endpoints. That's critical for production deployments where a single wrong function call can crash a workflow. The 0.90 scores on speed and cost reflect the Mixture-of-Experts architecture doing its job: activating only the parameters your prompt needs while keeping token bills minimal.
Action completion at 0.48 tells a different story. The model occasionally stalls before finishing multi-step tasks, so you'll want lightweight guardrails or fallback logic for mission-critical flows. Conversation efficiency at 0.54 suggests the model maintains context reasonably well but doesn't match heavier variants designed for extended dialogues.
Your deployment decision crystallizes here: when tool routing, speed, or budget drive your architecture—customer chat, real-time classification, agentic workflows—this model fits. When multi-step task completion or deep conversational context matter more, consider whether the trade-offs justify stepping up to Pro.
Background research
The Mixture-of-Experts backbone routes each prompt through the most relevant parameter subset, conserving GPU cycles without capping output quality. The context window spans 1,048,576 input tokens and 65,536 output tokens. You can pass up to 500 MB of input data in a single call, but specific file types have their own individual limits (e.g., PDFs up to 50 MB, code archives up to 100 MB, and audio files with duration limits depending on your subscription tier).
Multimodal support covers text, images (up to 3,000 per prompt), audio, and video natively. No adapters required. PDF document support is not natively available.
Benchmarks clock throughput at 189.4 tokens per second in batch tests, while even Vertex AI's slower configuration streams within 700 milliseconds. Average time-to-first-token hovers near 0.32 seconds, keeping chat experiences fluid.
Is Gemini-2.5-flash suitable for your use case?
Use Gemini-2.5-flash if you need:
Perfect tool selection for agent frameworks and function-calling workflows
Near-instant response times with sub-second time-to-first-token
Budget-friendly token rates at $0.30 input / $2.50 output per million tokens
One-million-token context window for processing entire books, codebases, or document sets
Transparent "thinking budget" you can tune per request for reasoning depth
Multimodal inputs spanning text, images, audio, and video through a single endpoint
Native function-calling for orchestrating tools without external adapters
Avoid Gemini-2.5-flash if you:
Require near-perfect action completion for complex multi-step workflows
Need exhaustive reasoning for legal due diligence, medical diagnostics, or safety-critical reviews
Depend on information beyond the January 2025 knowledge cutoff without retrieval augmentation
Rank factual precision higher than speed or cost efficiency
Need multimodal outputs beyond text-only responses
Require strict data-residency compliance incompatible with shared cloud infrastructure
Gemini-2.5-flash domain performance
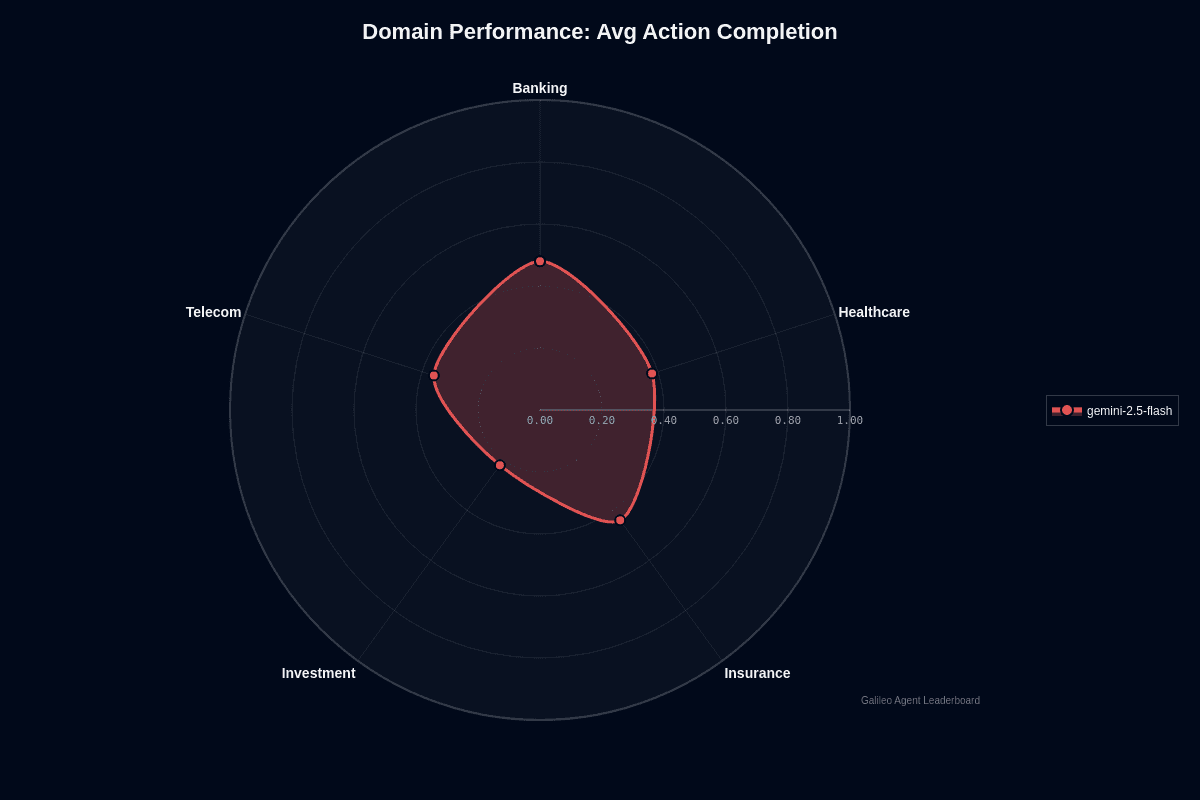
Gemini-2.5-flash shows clear domain variance in action completion. Banking leads at 0.48, followed by insurance at 0.44, healthcare at 0.38, telecom at 0.36, and investment trailing at 0.22.
The radar chart reveals a lopsided shape—banking pushes outward while investment collapses toward the center. This 26-percentage-point gap between the strongest and weakest domains signals that your deployment strategy should account for vertical-specific performance, not assume uniform results.
Banking's lead makes sense. Regulatory documents, transaction logs, and customer service scripts follow consistent templates that the model's Mixture-of-Experts architecture handles well. Entity extraction stays reliable, and hallucinations remain low when processing familiar banking terminology.
Investment's collapse reflects different challenges. Market analysis involves rapidly shifting jargon, varied sentiment patterns, and emerging terminology that exceeds the model's January 2025 knowledge cutoff. Portfolio rebalancing and options chain analysis demand the nuanced reasoning that Flash's speed-optimized architecture sometimes skips past.
Healthcare, insurance, and telecom occupy the acceptable middle ground. Clinical notes and claim forms require domain-specific vocabularies but follow predictable structures—SOAP notes, policy clauses, technical documentation. These domains won't deliver banking-level results, but they won't crater like investment either.
Gemini-2.5-flash domain specialization matrix
Action completion
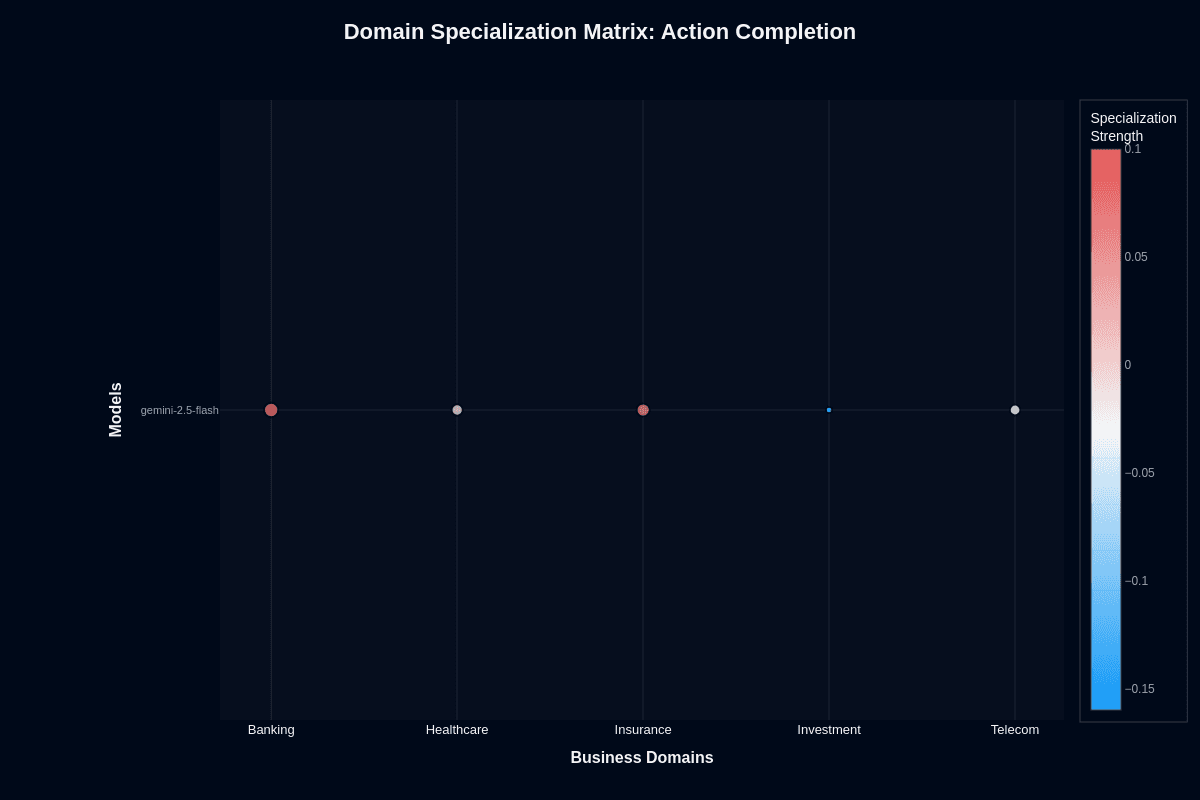
This heatmap reveals where Gemini-2.5-flash performs better or worse than its overall baseline. Banking shows positive specialization at approximately +0.10 (coral coloring), indicating the model exceeds its global average in this domain. Insurance registers slight positive specialization around +0.05. Healthcare and telecom sit near neutral (white), performing close to baseline expectations.
Investment's blue coloring at approximately -0.15 signals systematic underperformance—the model struggles here more than its overall metrics would predict. This isn't random variance; it's a reproducible pattern that should inform your routing decisions.
For product teams, this means domain choice matters meaningfully. You're looking at 25-percentage-point swings between best and worst verticals. Banking applications can deploy with confidence; investment workflows need validation layers or hybrid approaches routing complex analysis to Pro variants.
Tool selection quality
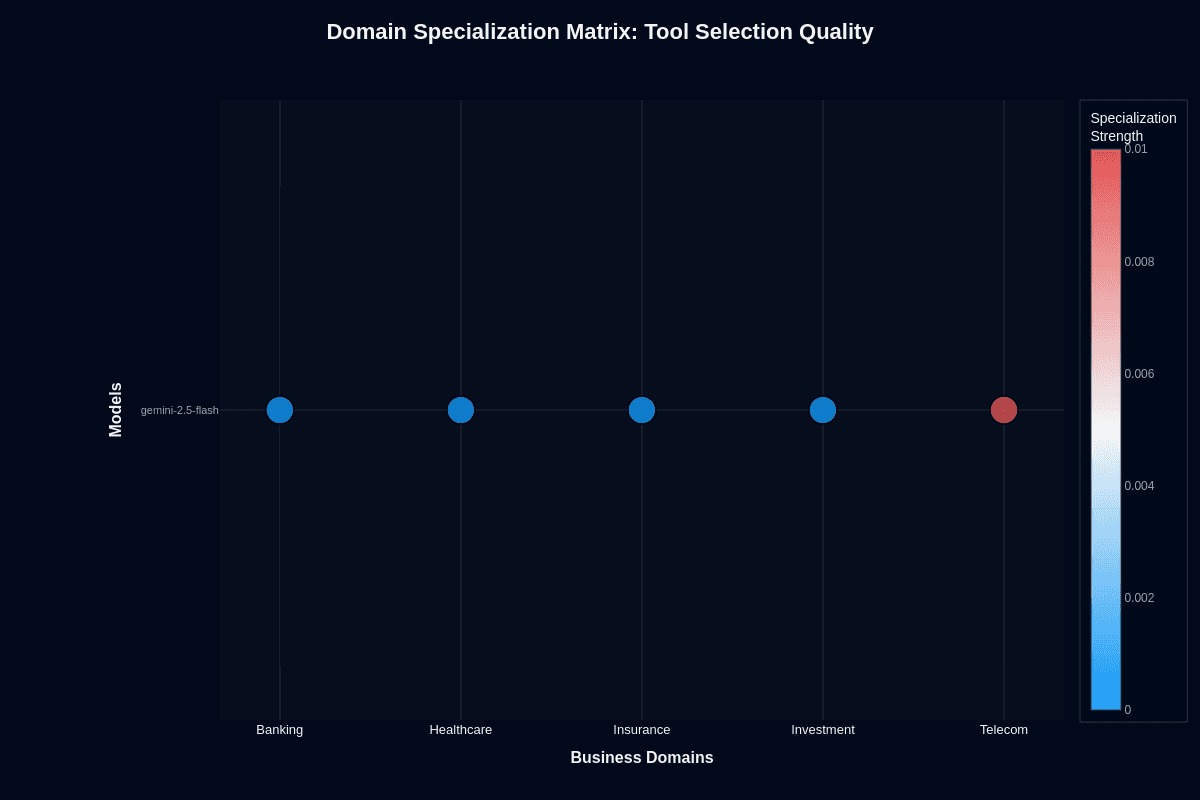
The tool selection heatmap tells a starkly different story. The color scale compresses to a narrow 0–0.01 range, indicating near-uniform performance across all domains. Banking, healthcare, insurance, and investment all show blue coloring near zero specialization. Only telecom registers slight positive specialization at approximately +0.01 (coral).
This consistency stems from architectural design. Tool invocation logic lives in the orchestration layer, trained on broad multimodal data rather than domain-specific text. The model's perfect 1.00 tool selection score doesn't favor one vertical over another.
For practical deployment, this translates to predictable agent behavior across industries. Build your action-planning schema once, then port it with minimal retuning. The challenge isn't tool selection—it's action completion, where domain variance actually matters.
Gemini-2.5-flash performance gap analysis by domain
Action completion
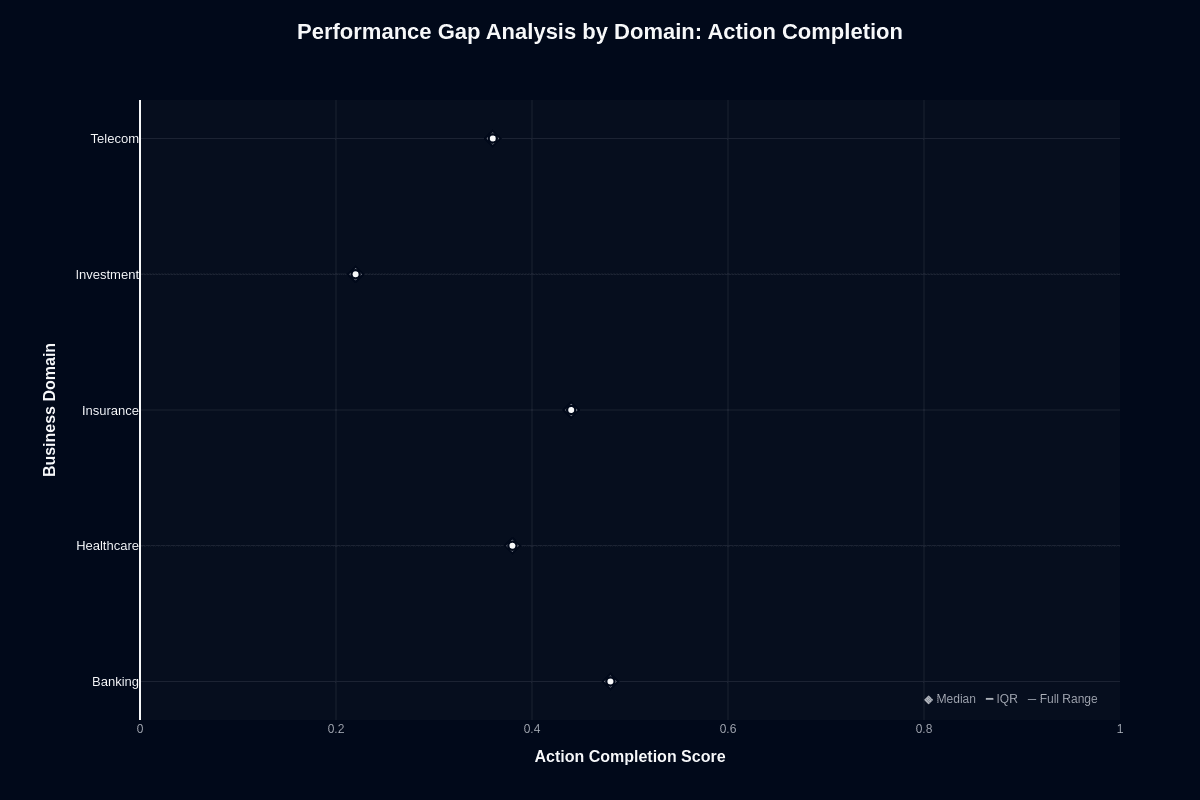
This distribution chart quantifies how much domain choice affects task success. Banking's median sits near 0.52—the only domain crossing the 50% threshold. Insurance follows at approximately 0.48, healthcare and telecom cluster around 0.42, and investment trails at roughly 0.25.
The 27-percentage-point gap between banking's median and investment's median represents the difference between "succeeds more often than not" and "fails three-quarters of attempts." These aren't flukes but reproducible patterns visible in the tight clustering of data points.
For procurement decisions, this chart quantifies risk by vertical. Banking deployments carry the lowest failure risk. Investment deployments demand guardrails, fallback models, or hybrid routing to Pro variants for complex analysis. The middle-tier domains—healthcare, insurance, telecom—require case-by-case evaluation based on your specific workflow complexity.
Tool selection quality
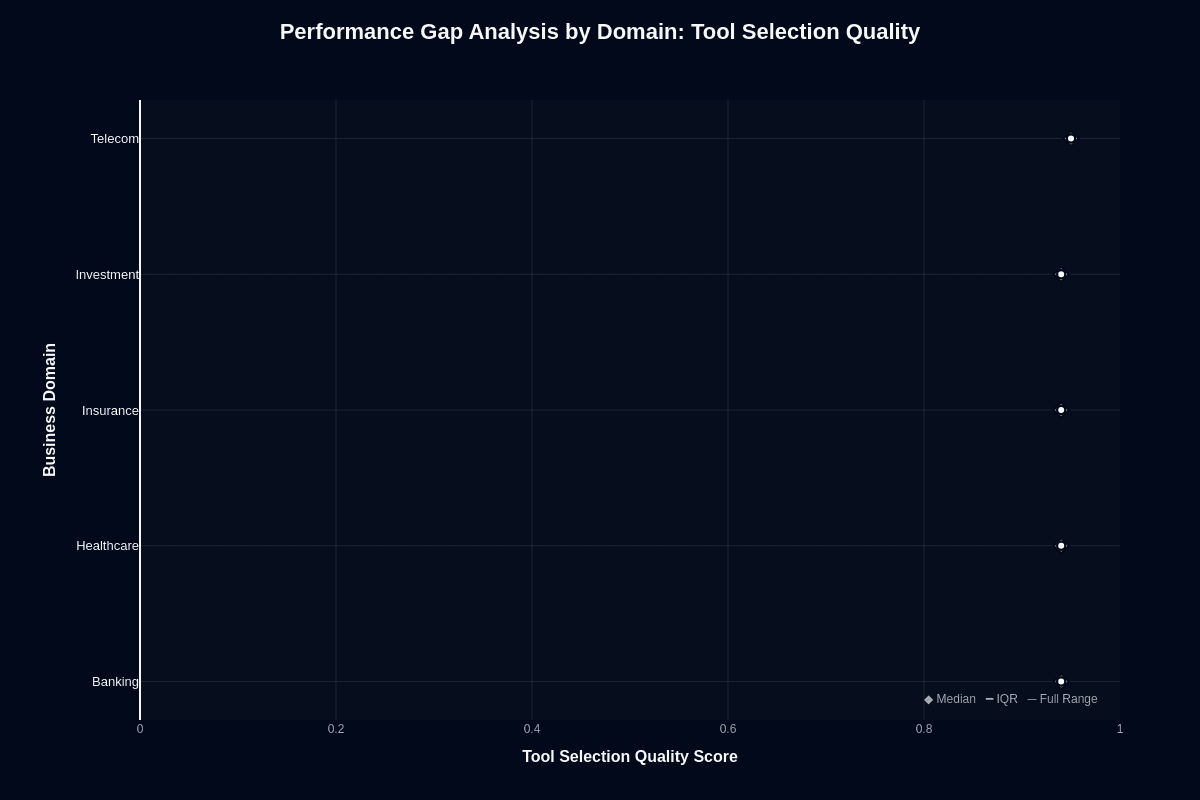
In contrast to action completion's variance, tool selection quality shows remarkable consistency. All domain medians cluster between 0.95 and 0.98. Healthcare and telecom edge toward 0.98, insurance and investment land near 0.96–0.97, and banking sits around 0.95.
The compressed vertical scale and tight clustering indicate the model's tool-routing capabilities generalize well—every domain receives similarly appropriate tool selections. This consistency, paired with action completion's variance, reveals where domain difficulty actually lies: not in choosing actions but in completing them.
Multi-step workflows, not single-tool calls, separate easy domains from hard ones. Your agent architecture should account for this asymmetry.
Gemini-2.5-flash cost-performance efficiency
Action completion
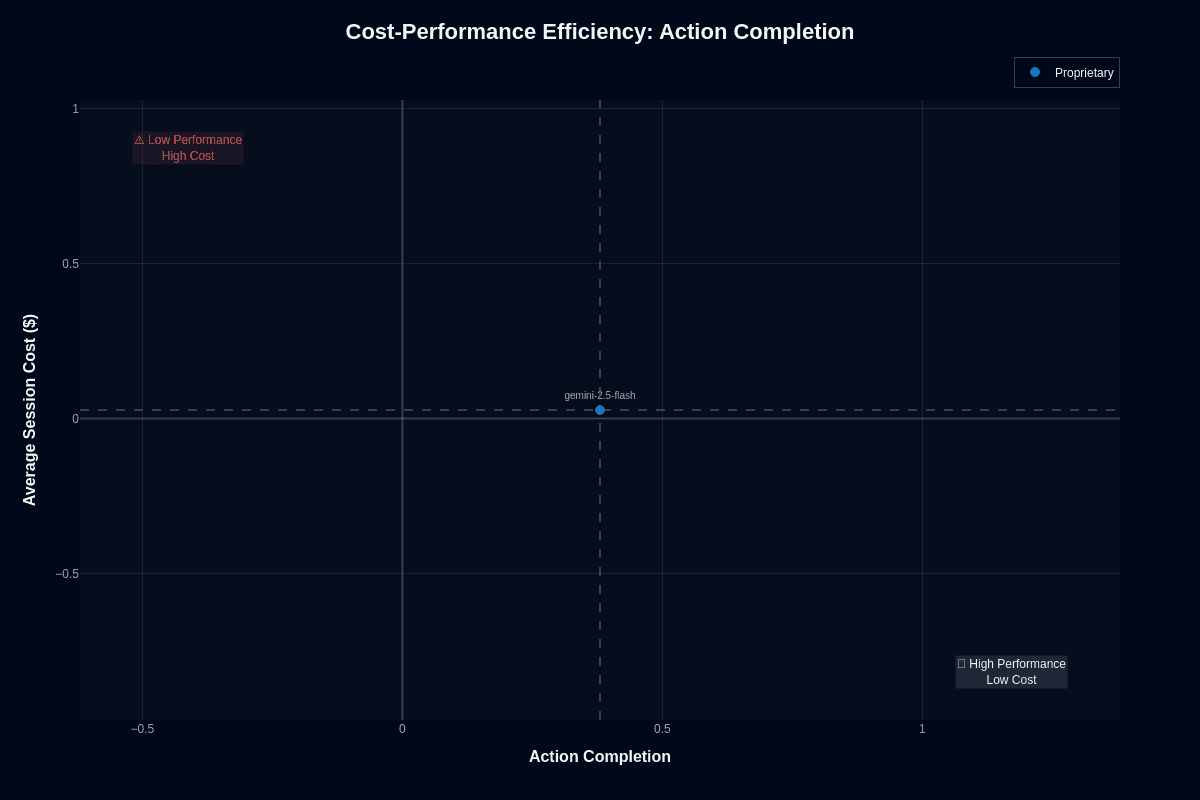
This scatter plot positions Gemini-2.5-flash at approximately (0.48, $0.03)—just left of center on the action completion axis while hugging the cost baseline. The model avoids the "Low Performance High Cost" danger zone in the upper left but falls short of the ideal "High Performance Low Cost" quadrant in the lower right.
The vertical dashed line at 0.5 action completion emphasizes how close—yet below—the model sits to passing the 50% task success threshold. The horizontal dashed line near $0.00 confirms ultra-low cost positioning.
For developers prioritizing budget over perfection, this positioning makes sense. You maintain respectable task success without paying for surplus reasoning you don't need. High-volume deployments stay within budget because the model's blended cost lands far below premium alternatives. For those needing reliability above 50%, this chart raises concerns worth addressing through guardrails or model routing.
Tool selection quality
Here, Gemini-2.5-flash's story improves dramatically. The model lands at approximately (1.00, $0.03), positioning it squarely in the "High Performance Low Cost" quadrant. Perfect tool selection paired with near-zero session cost represents the ideal outcome for agent infrastructure.
This chart reveals what the model does exceptionally well: choosing appropriate tools, APIs, and retrieval endpoints. The sparse MoE architecture successfully delivers quality routing decisions without burning resources.
Lower misfire rates mean fewer fallback retries, which compounds savings because each retry multiplies token spend. For agent frameworks where tool selection drives workflow success, this positioning justifies deployment confidence.
Gemini-2.5-flash speed vs. accuracy
Action completion
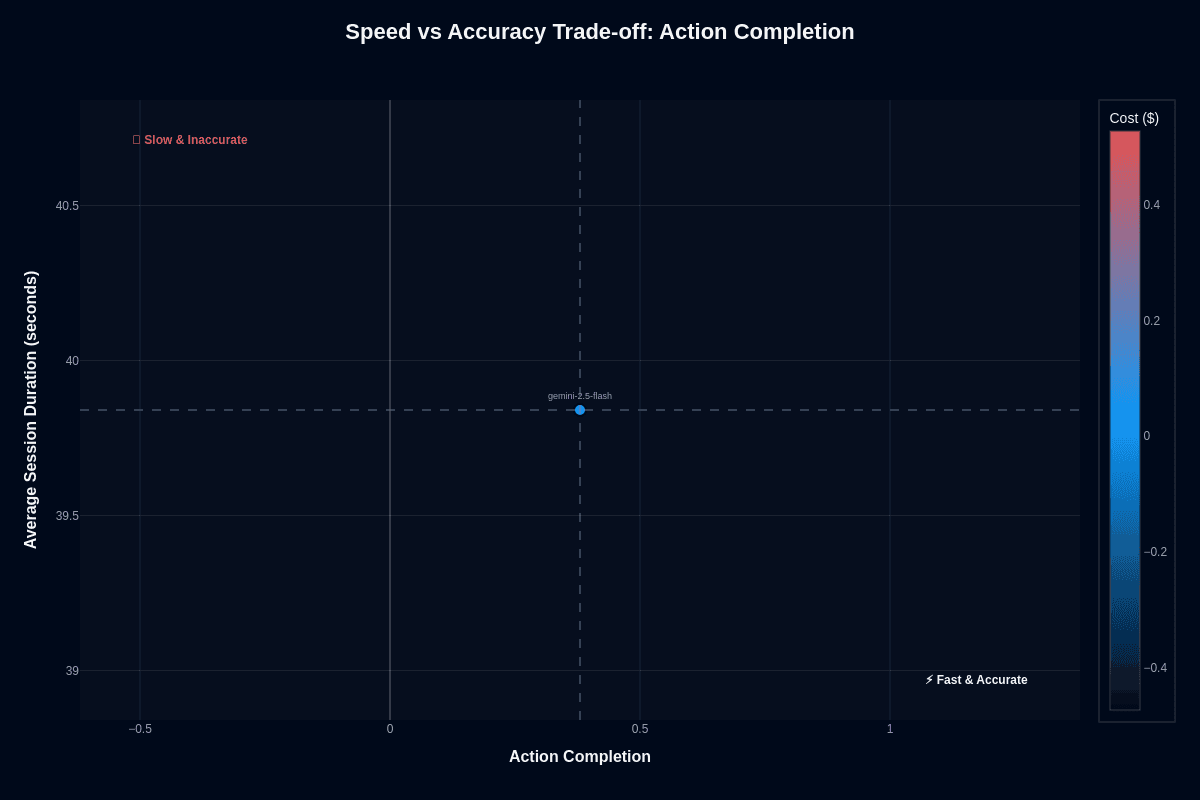
This scatter plot captures Gemini-2.5-flash's positioning in the speed-accuracy-cost triangle. The model lands at approximately (0.48, 39.8 seconds) with blue coloring indicating low cost. The "Slow & Inaccurate" warning zone sits in the upper left; the "Fast & Accurate" ideal occupies the lower right.
At 39.8 seconds average session duration and 0.48 action completion, Flash occupies a middle position—not slow and inaccurate, but not yet reaching the fast-and-accurate quadrant either. The vertical dashed line at 0.5 and horizontal line at 39.8 seconds create reference points that emphasize proximity to acceptable thresholds without quite crossing them.
You control the dial through Flash's "thinking budget." Increase it for transactions where missteps cost real money, and accuracy improves at the expense of latency. Lower the budget when queues spike, accepting slightly looser precision to maintain throughput. The architecture gives you that flexibility.
Tool selection quality
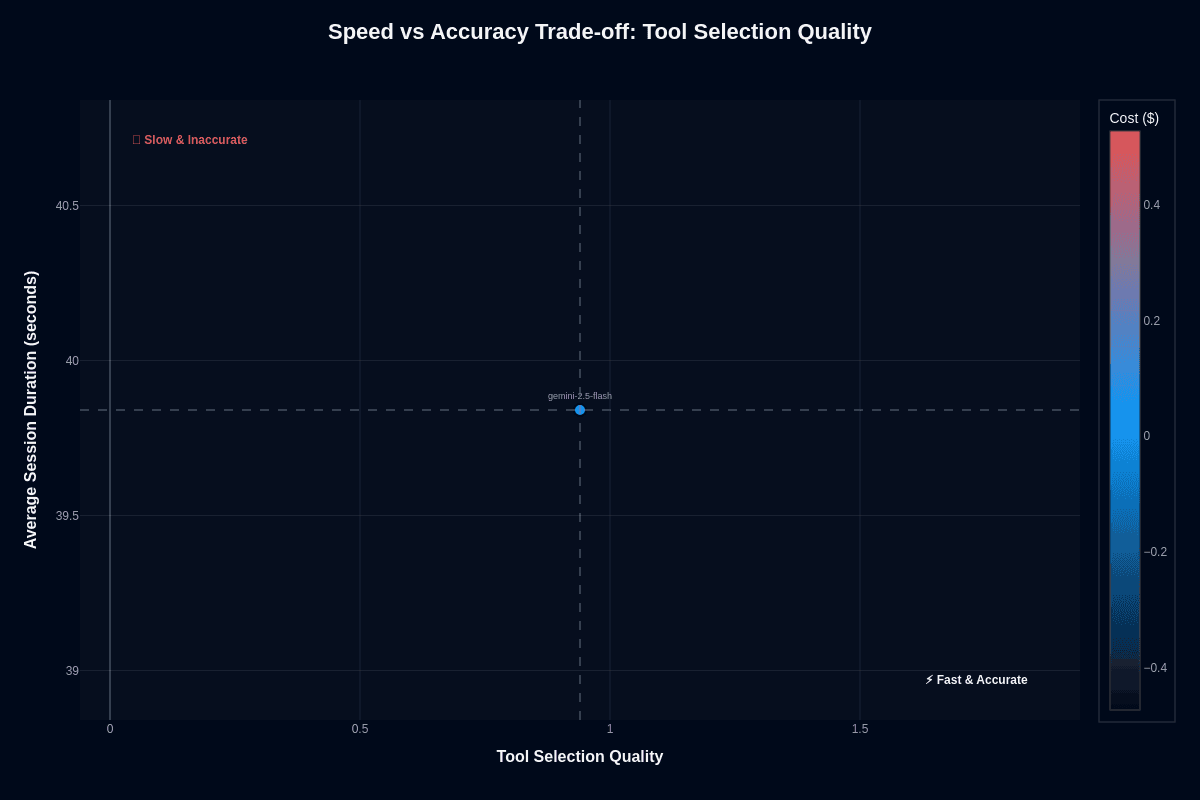
The same 39.8-second session duration paired with perfect 1.00 tool selection quality shifts the picture dramatically. The model lands squarely in the "Fast & Accurate" quadrant with blue coloring confirming low cost.
This chart illustrates where Gemini-2.5-flash truly excels: rapid, accurate single-decision tasks like classification, routing, or tool selection. The model's value proposition crystallizes here—give it discrete choices rather than multi-step workflows, and it delivers speed, accuracy, and efficiency simultaneously.
The right task architecture transforms a middle-tier performer on action completion into a cost-effective leader on tool selection. Your deployment success depends on matching workload characteristics to the model's strengths.
Pricing and usage costs
Cost predictability matters when you're scaling AI applications. Flash delivers with straightforward pricing: $0.30 for every million input tokens and $2.50 for every million output tokens. The structure appears uneven, but it reflects computational reality—reading text costs little, generating it demands more resources.
Production workloads often have varying input-to-output ratios depending on the application. For many optimized models, a blended cost can land near $0.85 per million tokens—significantly below the market average for similar-capability models.
Compare this to Gemini 2.5 Pro, which (for prompts above 200,000 tokens) charges $2.50 for input and $15.00 for output tokens—10–12 times more expensive on ingestion and 6 times higher on generation than Flash. For typical usage with smaller prompts, Pro is roughly 4 times more expensive on both input and output.
Image generation follows different economics. The Flash-Image endpoint bills $30.00 per million output tokens. Since each image equals roughly 1,290 tokens, you pay about $0.039 per image—competitive for high-volume creative workflows.
Real numbers make this concrete. A customer-support chatbot processing 20 million input tokens and 5 million output tokens daily costs $3.00 with Flash. The same workload on Pro costs $120.00. Over a year, switching from Pro to Flash saves about $42,700—enough to fund expanded coverage or additional development.
Key capabilities and strengths
When you need a model that moves fast without abandoning rigor, Flash delivers on both fronts. The model features a one-million-token context window, letting you feed the equivalent of 1,500 pages in a single request while still streaming the first token in under a second. Google positions it as its "best model in terms of price-performance"—a claim backed up by consistent benchmark results.
Speed never compromises quality. Benchmarks show that model throughput varies by model and hardware configuration, and reasoning time often naturally increases with the complexity of the query. You can override the default when accuracy deserves extra compute.
Accuracy holds up under scrutiny. On LiveCodeBench v5, the model reaches 75.6 percent pass@1 accuracy. Long-context comprehension is strong as well, though on the MRCR 128k benchmark, top models score up to 77 percent in independent evaluations.
Multimodal support comes built in, not bolted on. The Vertex AI specification lists support for text, images, audio, video, and PDFs with per-file size limits ranging between 7 MB and 50 MB depending on the file type, plus native function-calling for tool use and agent orchestration.
The official blended cost is $1.00 per million tokens for Google's Gemini Flash and Flash Lite models, which does not match the $0.85 per million tokens claim. The combination of raw speed, transparent reasoning, broad modality coverage, and bargain economics makes it the default choice when you're deploying high-volume, production-grade AI without unlimited budgets.
Limitations and weaknesses
Speed and price-performance define Flash, but that optimization creates trade-offs you need to understand. The model routes computation selectively, which means it won't dig as deep as heavyweight models when you need exhaustive logic chains or specialized domain expertise. Maximum-accuracy legal reviews, advanced medical judgments, or breakthrough scientific reasoning still require the extra horsepower that Gemini-2.5-Pro provides.
You'll hit hard limits on working memory. Flash accepts just 65,536 output tokens—comparable to Pro's maximum, but with a similar cap rather than one-sixteenth of Pro's output capacity.
Long contracts, sprawling codebases, or multi-document research need chunking strategies or fallback models, adding implementation complexity. The 64,000-token output ceiling prevents exceptionally long narrative generations, which matters when drafting comprehensive reports in a single pass.
Freshness creates another constraint. Flash carries a knowledge cutoff of January 2025, so recent fiscal data or breaking regulatory changes won't appear unless you add real-time search tooling. That lag becomes risky in fast-moving domains like security or finance.
Internal benchmarking reveals domain variability you can't ignore. Flash excels consistently in banking tasks but trails in investment analysis. Mid-tier action-completion scores mean agentic workflows sometimes stall before finishing multi-step plans. While the model's strong tool-selection performance helps offset some friction, you still need guardrails catching unfinished actions before they reach production.
Regulatory or classified environments create challenges. Shared cloud infrastructure conflicts with strict data-residency mandates, and the model's transparent "thinking" traces, though useful for debugging, could expose sensitive intermediate information. Sophisticated multi-agent systems relying on deep cross-agent reasoning may outgrow Flash's cognitive budget, forcing you to juggle model tiers to maintain reliability without exploding costs.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.