Nova Pro v1
Explore Nova Pro v1 performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Nova Pro v1
You need an LLM that balances capability with cost. Nova Pro v1 hits that target as Amazon's proprietary, closed-weight workhorse offered through Bedrock and select third-party gateways. This fully multimodal system processes both text and images while costing far less than frontier models and maintaining low latency.
Nova represents a model family, not a single system. Premier leads at the top, Lite and Micro handle budget deployments, while Pro occupies the middle ground with the best combination of accuracy, speed, and cost.
Performance metrics matter when your agents make dozens of calls per task. Head-to-head RAG testing showed Nova Pro answering questions faster and more cost-effectively than competing models with matching accuracy. Summarization tasks demonstrated substantial cost savings per request while maintaining output quality.
Context capacity provides real flexibility. Nova Pro accepts up to 300,000 tokens, handling entire contract folders or multi-year chat histories in a single prompt. This scale pairs with strong agentic features: reliable function calling, long-range planning, and competitive scores on Berkeley's tool-use benchmarks. The combination fits orchestration-heavy workflows perfectly.
Multimodal intelligence opens document-heavy applications. Nova Pro achieves strong performance on TextVQA and excels at financial statement analysis. Vision skills combined with fast, affordable inference create a model built for production agents, not just demonstrations.
Check out our Agent Leaderboard and pick the best LLM for your use case

Nova Pro v1 performance heatmap
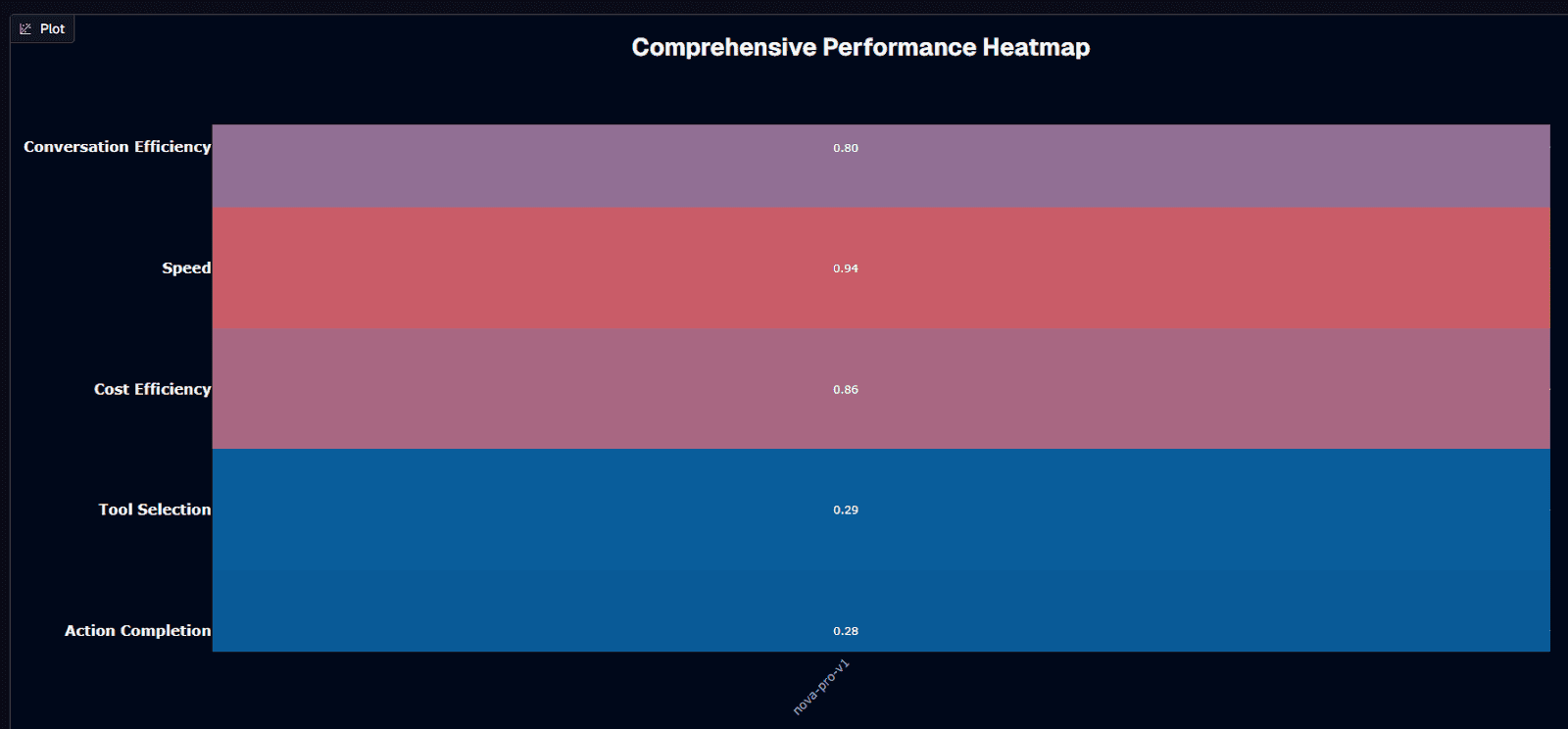
Nova Pro v1 delivers its strongest performance in speed, scoring 0.94—among the fastest models in its capability tier. Cost efficiency follows closely at 0.86, confirming the model's positioning as a budget-friendly option for high-volume deployments. Conversation efficiency lands at a solid 0.80, meaning your agents extract useful information with fewer exchanges. Tool selection (0.29) and action completion (0.28) sit well below the halfway mark.
The 0.94 speed score reflects Amazon's design philosophy: the entire Nova family prioritizes fast inference. Independent RAG benchmarks measured Nova Pro responding 21.97% faster than GPT-4o at matching accuracy levels. The 0.86 cost efficiency stems from token pricing that runs 65–85% below premium alternatives—savings that compound rapidly across thousands of daily requests.
Action completion at 0.28 tells a different story. The model struggles to reliably finish multi-step tasks, particularly when complex reasoning or numerical precision enters the workflow. Tool selection at 0.29 reveals similar challenges—Nova Pro understands function schemas but doesn't always pick the optimal tool for the job.
Your deployment decision crystallizes here: when speed, cost, or conversation throughput drive your architecture—customer chat, document processing, high-volume RAG—Nova Pro delivers exceptional value. When your workflows demand flawless multi-step execution or precise tool orchestration, you'll need robust guardrails or selective routing to higher-tier models.
Background research
Nova Pro operates as a fully multimodal system processing text and images through Amazon Bedrock. The context window spans 300,000 tokens—enough to handle entire contract folders or multi-year chat histories in a single prompt. Token pricing sits at $0.80 per million input tokens and $3.20 per million output tokens, positioning it significantly below flagship models charging $2.50/$10.00 for equivalent volumes.
Multimodal support covers text and images natively, with state-of-the-art scores on TextVQA for document understanding. Video input capabilities exist in the architecture but remain locked in current APIs. No self-hosting or on-premises fine-tuning options are available—API access only.
Benchmarks show strong performance on MT-Bench and Arena-Hard for function calling, with competitive results on Berkeley's tool-use evaluations. Nova Pro sits in Amazon's performance hierarchy between Premier (flagship) and Lite/Micro (budget), delivering strong capabilities without flagship pricing.
Is Nova Pro v1 suitable for your use case?
Use Nova Pro v1 if you need:
Near-instant response times with sub-second time-to-first-token for latency-sensitive agents
Budget-friendly token rates at $0.80 input / $3.20 output per million tokens
300k-token context window for processing entire document sets or extensive chat histories
Strong multimodal document understanding with state-of-the-art TextVQA performance
Reliable function calling for RAG and tool-driven workflows
High conversation efficiency that extracts value with fewer exchanges
Seamless Bedrock integration with IAM-level security
Avoid Nova Pro v1 if you:
Require near-perfect action completion for complex multi-step workflows
Need exhaustive reasoning for advanced mathematics, novel research, or frontier-level analysis
Demand flawless tool selection without guardrails or fallback logic
Require self-hosted deployments or on-premises fine-tuning
Need native video processing without frame extraction workarounds
Build browser automation requiring 90%+ UI reliability (consider Nova Act instead)
Rank absolute accuracy higher than speed or cost efficiency
Nova Pro v1 domain performance
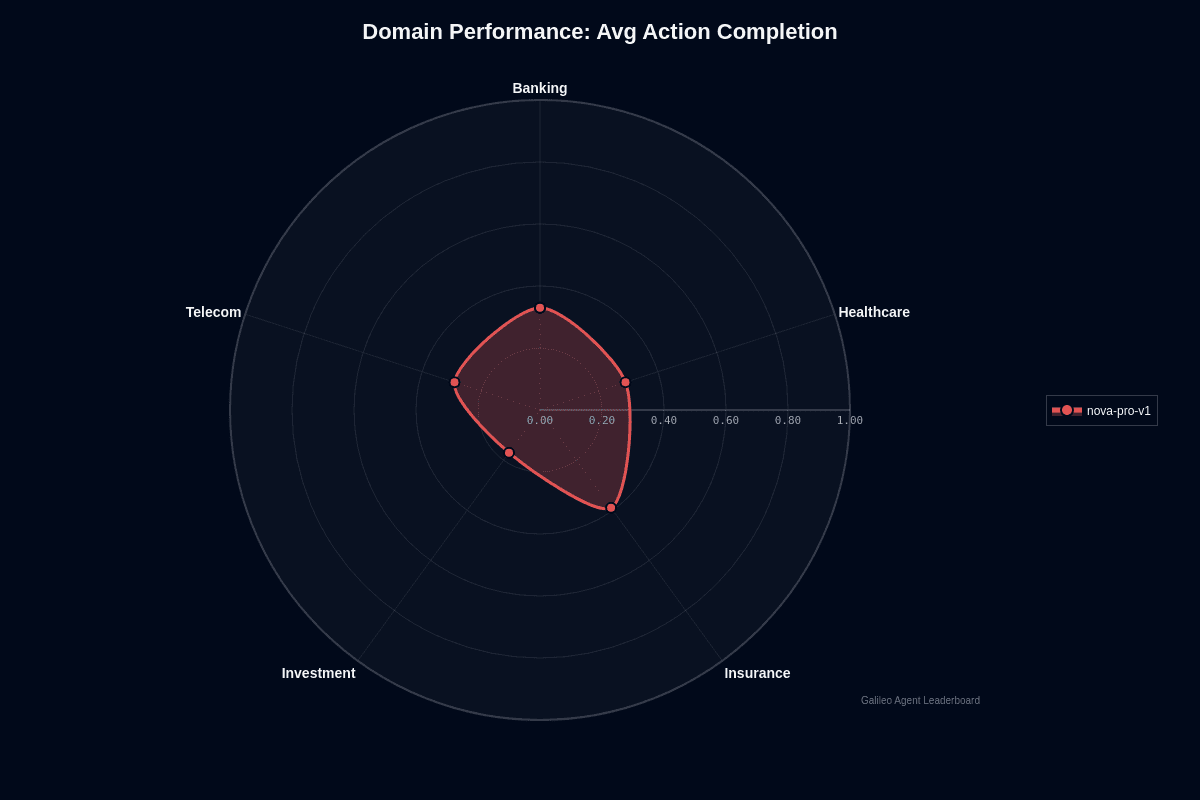
Nova Pro v1 shows clear domain variance in action completion. Insurance leads at 0.39, followed by banking at 0.33, healthcare and telecom both at 0.29, and investment trailing at 0.17.
The radar chart reveals a lopsided shape—insurance pushes outward while investment collapses toward the center. This 22-percentage-point gap between the strongest and weakest domains signals that your deployment strategy should account for vertical-specific performance, not assume uniform results.
Insurance's lead makes sense. Nova Pro excels at analyzing financial documents and handles TextVQA-style tasks that blend tables, text, and scanned imagery—exactly what you find in claims packets, policy binders, and loss forms. The 300k-token context window means you can load entire policy schedules, endorsements, and correspondence into one prompt without chunking anything.
Investment's collapse reflects different challenges. Portfolio analytics and real-time market reasoning demand current data feeds and complex numerical modeling—areas where Nova Pro depends on external tool calls or retrieval strategies you must build and maintain. When those pipelines stumble, output quality drops fast.
Banking, healthcare, and telecom occupy the middle ground. Their workflows mix structured documents with transactional lookups: solid territory for Nova Pro's long-context reading, but not as naturally suited as insurance's document-heavy environment.
Nova Pro v1 domain specialization matrix
Action completion
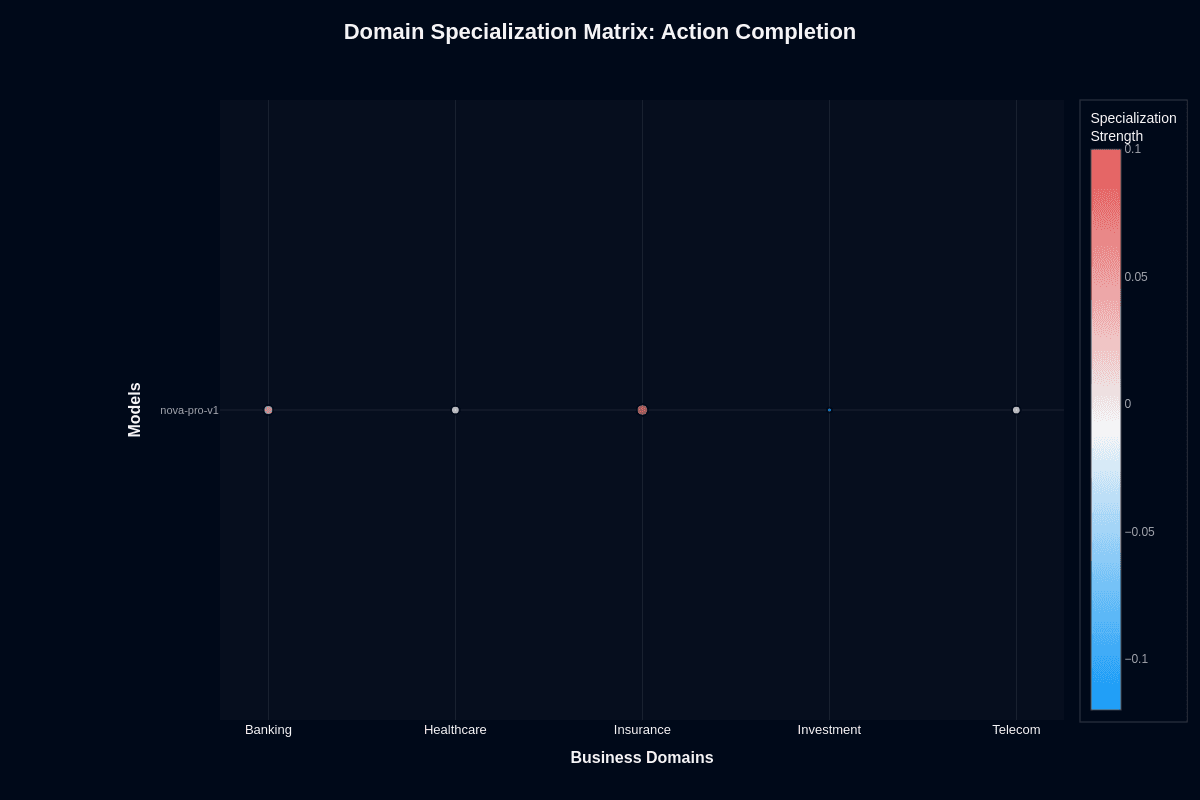
This heatmap reveals where Nova Pro v1 performs better or worse than its overall baseline. Insurance shows positive specialization at +0.10 (coral coloring), indicating the model exceeds its global average in this domain. Banking registers slight positive specialization at +0.05. Healthcare and telecom sit near neutral (white), performing close to baseline expectations.
Investment's blue coloring at -0.10 signals systematic underperformance—the model struggles here more than its overall metrics would predict. This isn't random variance; it's a reproducible pattern reflecting market data's demands for real-time feeds and tight numerical precision.
For product teams, this means domain choice matters meaningfully. You're looking at 20-percentage-point swings between best and worst verticals. Insurance applications can deploy with confidence; investment workflows need validation layers or hybrid approaches routing complex analysis to Premier or specialized calculation engines.
Tool selection quality
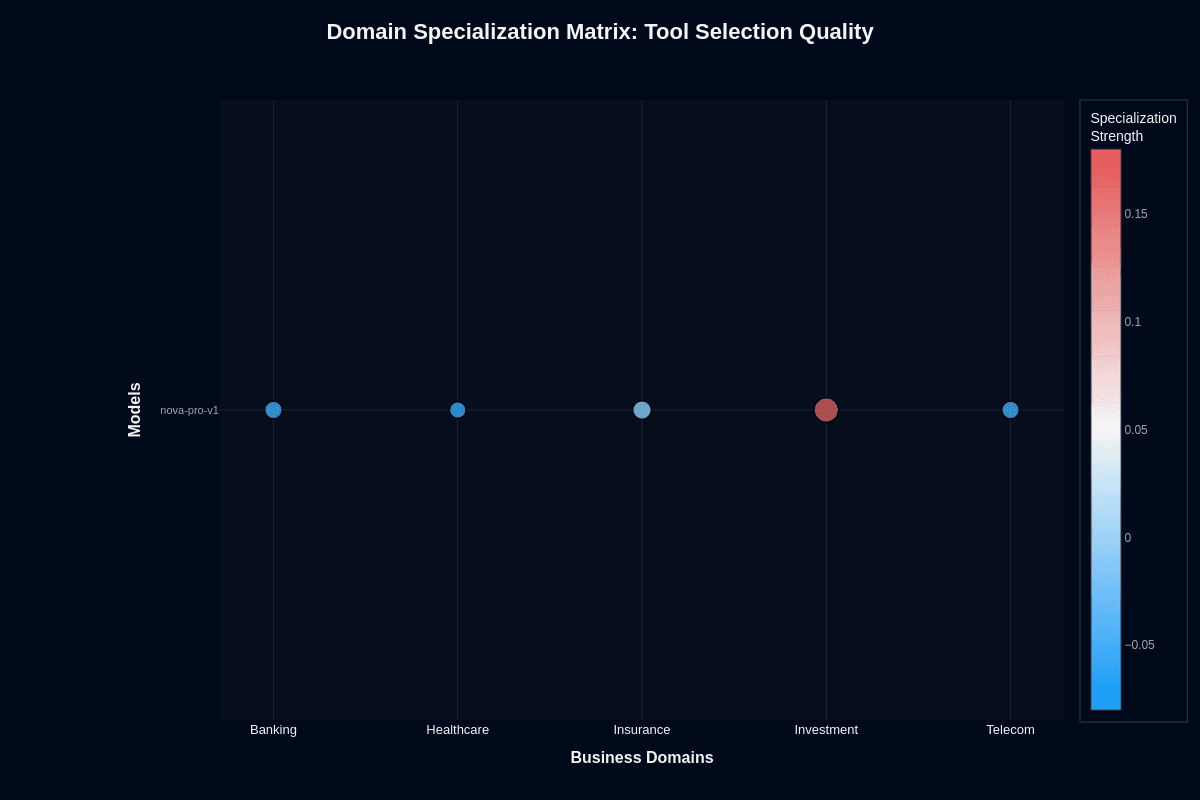
The tool selection heatmap tells a different story entirely. Investment surprises with +0.15 specialization (coral coloring)—the model's strongest domain for tool routing. Healthcare dips slightly to -0.05. Banking, insurance, and telecom all register neutral performance near zero.
This pattern seems counterintuitive given investment's poor action completion, but it reflects architectural reality. Investment tasks often involve clearly defined finance APIs—quote lookups, trade execution, risk assessment endpoints. Models that follow JSON schemas precisely excel at selecting these tools, even when final action accuracy lags. The challenge isn't picking the right API; it's completing the multi-step reasoning that follows.
Healthcare's small deficit stems from domain terminology overlap. Mislabeling "CBC" versus "complete blood count" or confusing similar lab and radiology tools knocks scores down. Tighter tool descriptions and few-shot examples mitigate this gap easily.
Nova Pro v1 performance gap analysis by domain
Action completion
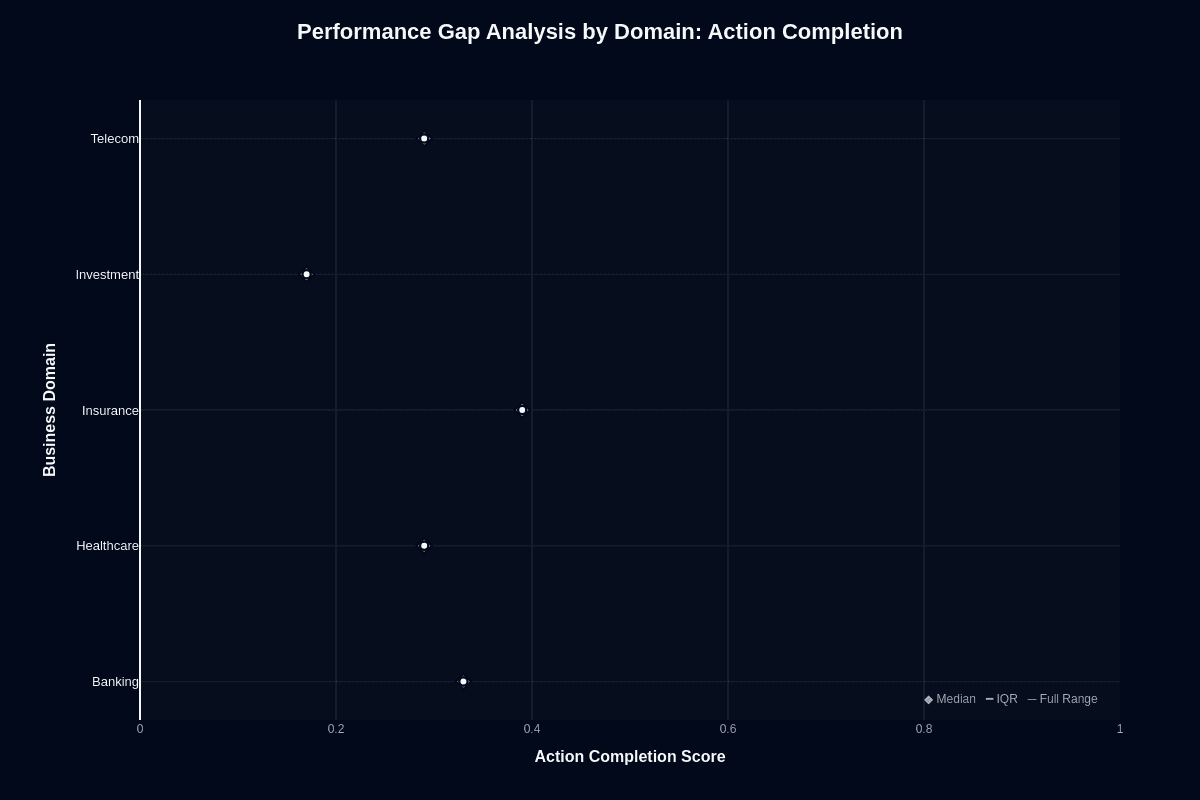
This distribution chart quantifies how much domain choice affects task success. Insurance's median sits near 0.45—the highest among all domains. Banking follows at approximately 0.43, healthcare and telecom cluster around 0.35, and investment trails at roughly 0.23.
The 22-percentage-point gap between insurance's median and investment's median represents the difference between "succeeds nearly half the time" and "fails three-quarters of attempts." These aren't flukes but reproducible patterns visible in the clustering of data points.
For procurement decisions, this chart quantifies risk by vertical. Insurance and banking deployments carry the lowest failure risk. Investment deployments demand guardrails, fallback models, or hybrid routing to Premier for complex analysis. Healthcare and telecom require case-by-case evaluation based on your specific workflow complexity.
Tool selection quality
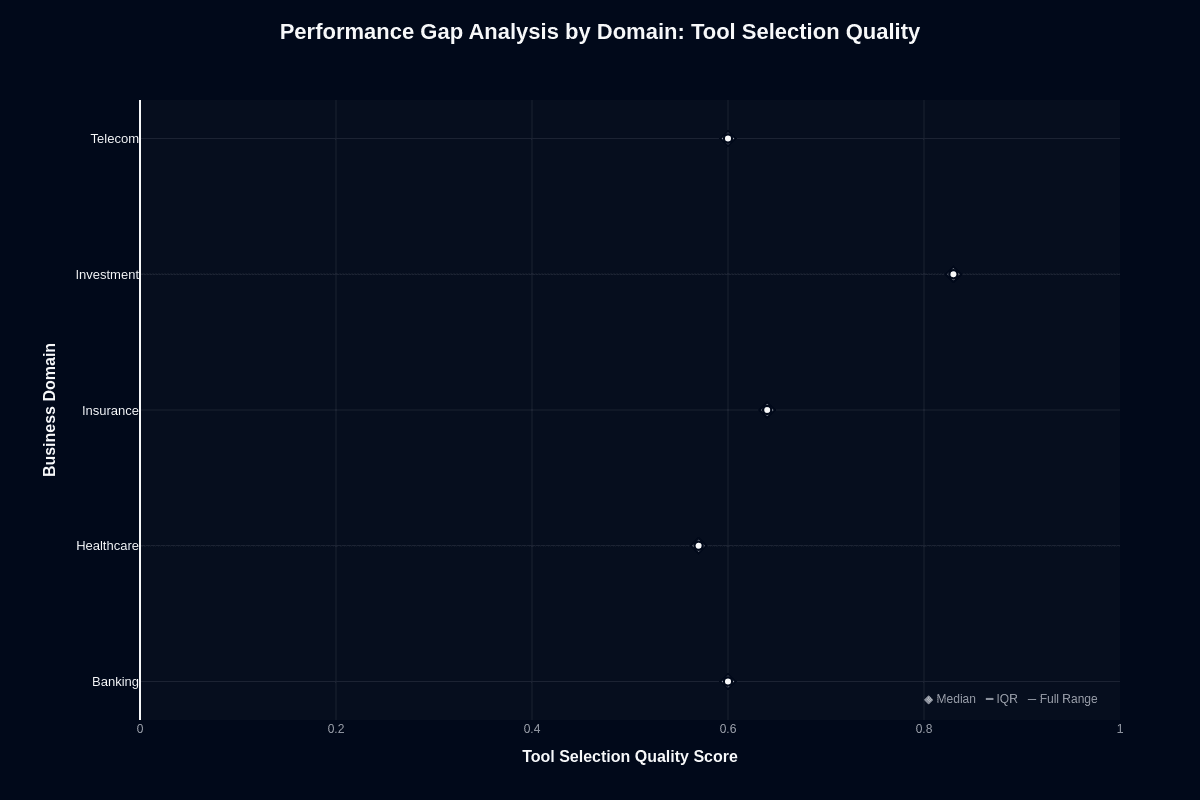
Tool selection quality shows a strikingly different pattern. Investment leads with a median near 0.88—by far the strongest domain. Insurance follows at approximately 0.72, telecom at 0.68, banking at 0.65, and healthcare trails at 0.60.
The compressed gap and generally strong performance across domains indicate Nova Pro's tool-routing capabilities generalize reasonably well. Investment's dominance here confirms the earlier finding: the model excels at selecting well-defined finance APIs even when it struggles to complete the subsequent reasoning chains.
This asymmetry reveals where domain difficulty actually lies. Multi-step workflows, not single-tool calls, separate easy domains from hard ones. Your agent architecture should account for this by handling tool selection with Nova Pro while routing complex execution to specialized services or higher-tier models.
Nova Pro v1 cost-performance efficiency
Action completion
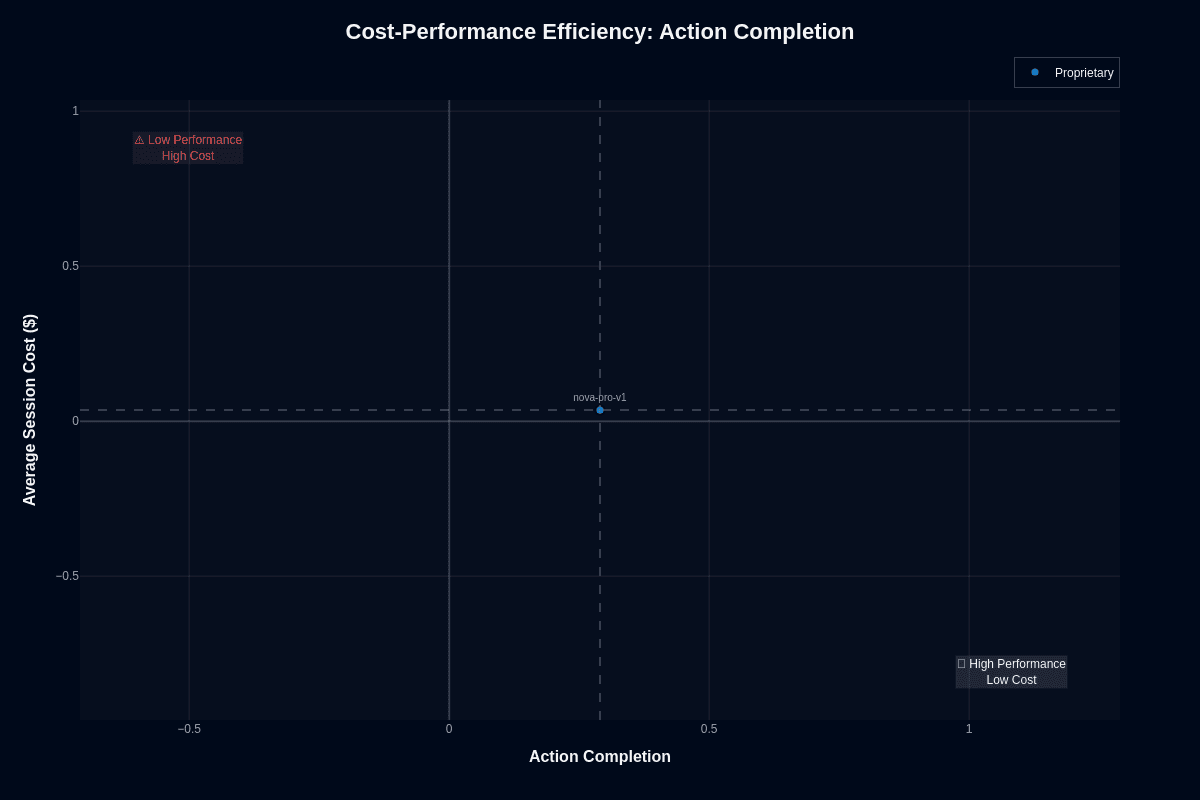
This scatter plot positions Nova Pro v1 at approximately (0.28, $0.04)—in the lower-left area of the chart, approaching but not yet reaching the ideal "High Performance Low Cost" quadrant. The model avoids the "Low Performance High Cost" danger zone in the upper left while maintaining ultra-low cost positioning.
The vertical dashed line at 0.5 action completion emphasizes how far below the model sits from the 50% task success threshold. The horizontal dashed line confirms cost positioning well below premium alternatives.
For developers prioritizing budget over perfection, this positioning makes sense. At roughly $0.04 per complex request, you can afford to run validation layers, retry logic, or ensemble approaches that would be prohibitively expensive with frontier models. High-volume deployments stay within budget because the model's token costs run 65–85% below premium alternatives.
Tool selection quality
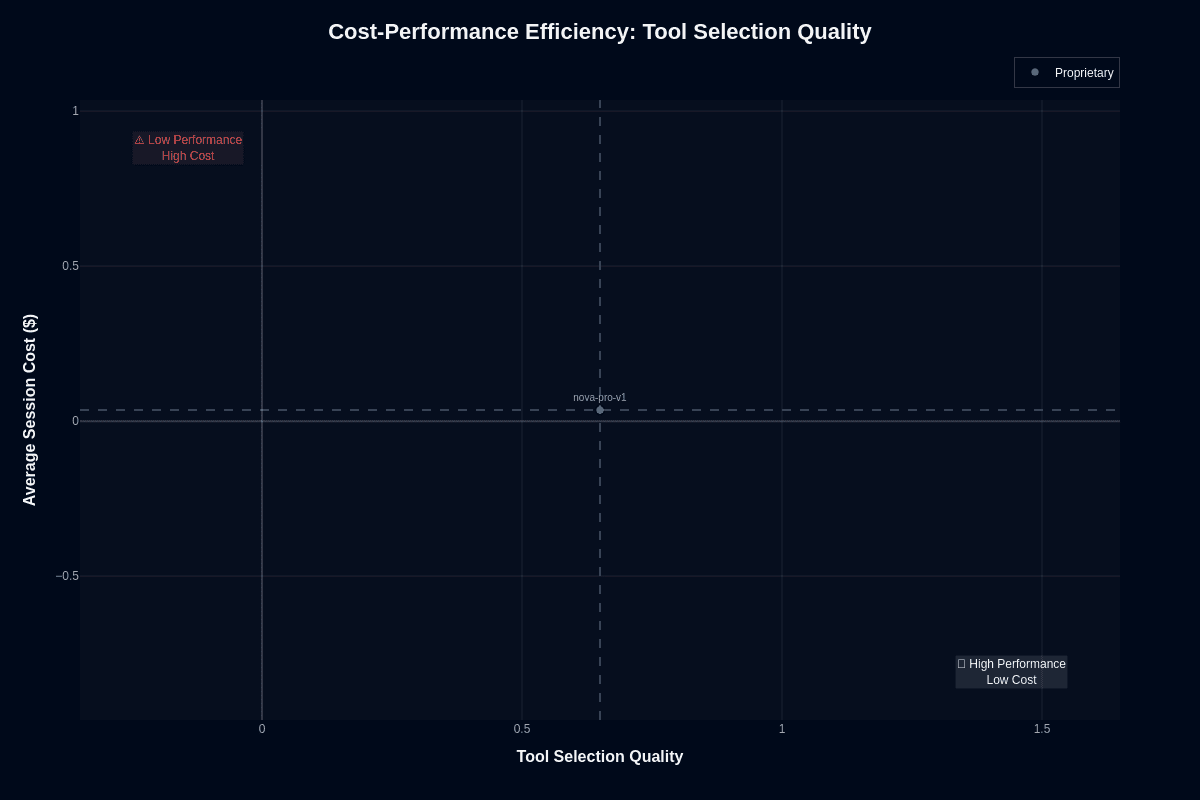
Nova Pro v1's story improves dramatically for tool selection. The model lands at approximately (0.65, $0.04), positioning it solidly in the "High Performance Low Cost" quadrant. Strong tool selection paired with near-minimal session cost represents an attractive outcome for agent infrastructure.
This chart reveals what the model does well: choosing appropriate tools, APIs, and retrieval endpoints without burning resources. The cost efficiency means you can afford richer prompt context—full OpenAPI specs, detailed tool descriptions, few-shot examples—without breaking budgets.
Fewer malformed calls lead to smoother execution and predictable spend, especially when orchestrating agents that hit multiple APIs per request. For agent frameworks where tool selection drives workflow success, this positioning justifies deployment confidence.
Nova Pro v1 speed vs. accuracy
Action completion
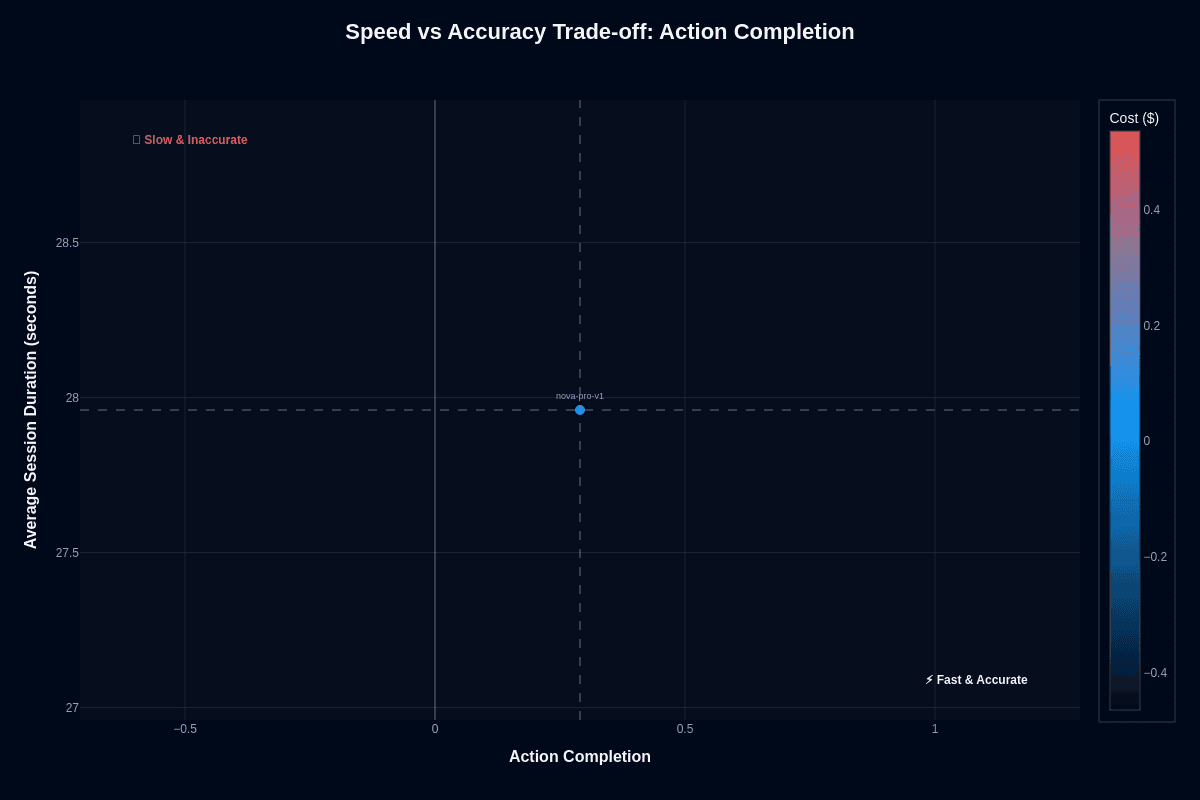
This scatter plot captures Nova Pro v1's positioning in the speed-accuracy-cost triangle. The model lands at approximately (0.28, 27.9 seconds) with blue coloring indicating low cost. The "Slow & Inaccurate" warning zone sits in the upper left; the "Fast & Accurate" ideal occupies the lower right.
At 27.9 seconds average session duration and 0.28 action completion, Nova Pro occupies a position that prioritizes finishing tasks quickly over squeezing out every last percentage point of correctness. The vertical dashed line at 0.5 and the session duration reference create reference points that highlight the distance from ideal thresholds.
The speed advantage pays off in latency-sensitive settings—customer support agents that must resolve tickets before users grow impatient, or monitoring tools that surface anomalies in real time. Independent RAG testing showed Nova Pro answering questions 21.97% faster than GPT-4o at matching accuracy levels. If rapid response matters more than a few extra correct edge cases, Nova Pro's trade-off works in your favor.
Tool selection quality
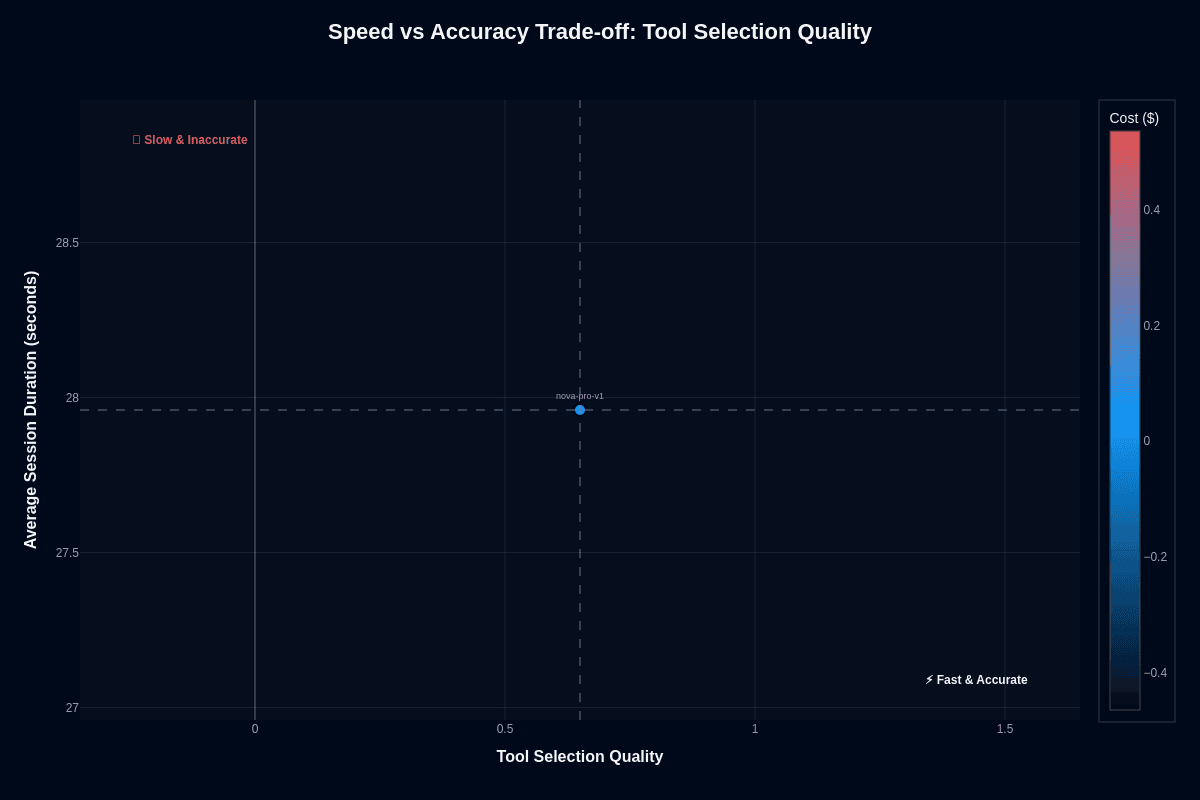
Tool selection accuracy tells a different story. Nova Pro lands at approximately (0.65, 27.9 seconds) with blue coloring confirming low cost—a well-balanced position that sacrifices little precision while retaining quick turnaround.
That balance becomes critical when your agent orchestrates many API calls in sequence—billing lookups, database queries, internal microservices—because each extra second cascades through the chain. Amazon's technical documentation frames the entire Nova family as "designed for fast inference," and you feel that emphasis here.
The model resolves which tool to call, generates a valid payload, and proceeds—all before users notice a delay. If your workflow demands frequent function invocations, Nova Pro keeps cumulative latency low without forcing you up to frontier-level pricing. You get smooth conversations and predictable cloud costs.
Nova Pro v1 pricing and usage costs
Nova Pro follows Bedrock's standard token-based pricing at $0.80 per million input tokens and $3.20 per million output tokens. These rates position Nova Pro significantly below flagship models, with the savings adding up quickly. While premium alternatives charge $2.50/$10.00 for equivalent volumes, Nova Pro delivers substantial cost reduction on typical tasks like summarization.
A retrieval-augmented-generation study across 10 million monthly queries showed Nova Pro cutting costs substantially—saving $68,000 annually—while responding faster than premium competitors.
Consider a customer support scenario: 1,000 daily visitors each sending ten 150-token messages and receiving 100-token replies. Monthly consumption reaches roughly 49.4 million input tokens and 32.9 million output tokens, costing about $145 on Nova Pro versus around $450 for the same premium model workload.
The 300,000-token context window amplifies these savings. You can process entire policy documents or extensive chat histories in single requests rather than fragmenting them across multiple calls. This architectural advantage eliminates the compound costs that plague shorter-context alternatives, creating a cost structure that scales with your production ambitions.
Nova Pro v1 key capabilities and strengths
Speed and economy drive agent success. Nova Pro delivers on both fronts—answering RAG queries substantially faster than competing models while cutting token costs significantly for identical workloads. This speed-economy combination lets you ship responsive agents without budget concerns.
Visual understanding matches the speed advantage. Nova Pro achieves impressive scores on TextVQA and video reasoning benchmarks, then applies this visual intelligence to practical work like invoice processing or chart analysis. Specialized training on financial documents makes it particularly effective for document-heavy workflows. The extensive context window keeps entire contracts, manuals, or conversation histories in memory rather than forcing you to manage retrieval fragments.
Agentic workflows get built-in support. Nova Pro follows JSON tool schemas, orchestrates multi-step plans, and maintains reasoning chains across long sessions—capabilities Amazon designed as core to the Nova family.
First-class Bedrock integration adds IAM-level security, with robust orchestration features and efficiency optimizations; specific claims about autoscaling and significantly reduced input prices are not documented. The result is production-ready intelligence that handles complex tasks, cooperates with external tools, and keeps cloud costs manageable.
Nova Pro v1 limitations and weaknesses
Nova Pro delivers strong price-performance value, but production realities reveal clear trade-offs. Third-party benchmarks show that Nova Pro ranks near the leading edge in math and vision tasks, delivering competitive performance close to premium alternatives. Pure reasoning headroom remains limited compared with elite models.
The proprietary weights mean API-only access—no self-hosting or on-premises fine-tuning options exist. Video input capabilities remain locked away despite strong research results, forcing agents that process footage to rely on frame extraction or external services.
Browser automation workflows face particular challenges. Nova Pro lacks the specialized reinforcement learning that powers Amazon's newer Nova Act service, which achieves 90% reliability on UI automation. Live-web interactions and stable UI clicks will generate more failures, requiring robust guardrails or migration to Nova 2 models with built-in search and code execution.
Production reliability demands careful prompt engineering. Amazon's own engineering teams stress that concise, schema-driven prompts and response caps prevent Nova Pro from drifting off-task or generating costly hallucinations when tools return errors. You'll need to build the planning loop, safety checks, and monitoring layers yourself—no native orchestration or live-data integration comes out of the box.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.