7 Best Agent Evaluation Tools to Monitor Autonomous AI

Your production agent just called the wrong API 847 times overnight. Customer data is corrupted. You can't trace why agent decisions diverged. Your team spends 60% of their time debugging agents instead of building capabilities.
With Gartner predicting 40% of agentic AI projects will be canceled by 2027 and only 5% of enterprise AI pilots reaching production, evaluation infrastructure determines whether you capture the $2.6-4.4 trillion annual value McKinsey projects from agentic AI.
TLDR:
Agent frameworks measure multi-step behavior, tool orchestration, and trajectory analysis that traditional monitoring misses
Leading platforms provide real-time observability, automated failure detection, and runtime protection across the complete agent lifecycle
Enterprise deployments require SOC 2 compliance, comprehensive audit trails, and integration with existing security infrastructure
Investment benchmark: AI-ready companies allocate ~15% of IT budgets to tech debt remediation and governance
What is an agent evaluation framework?
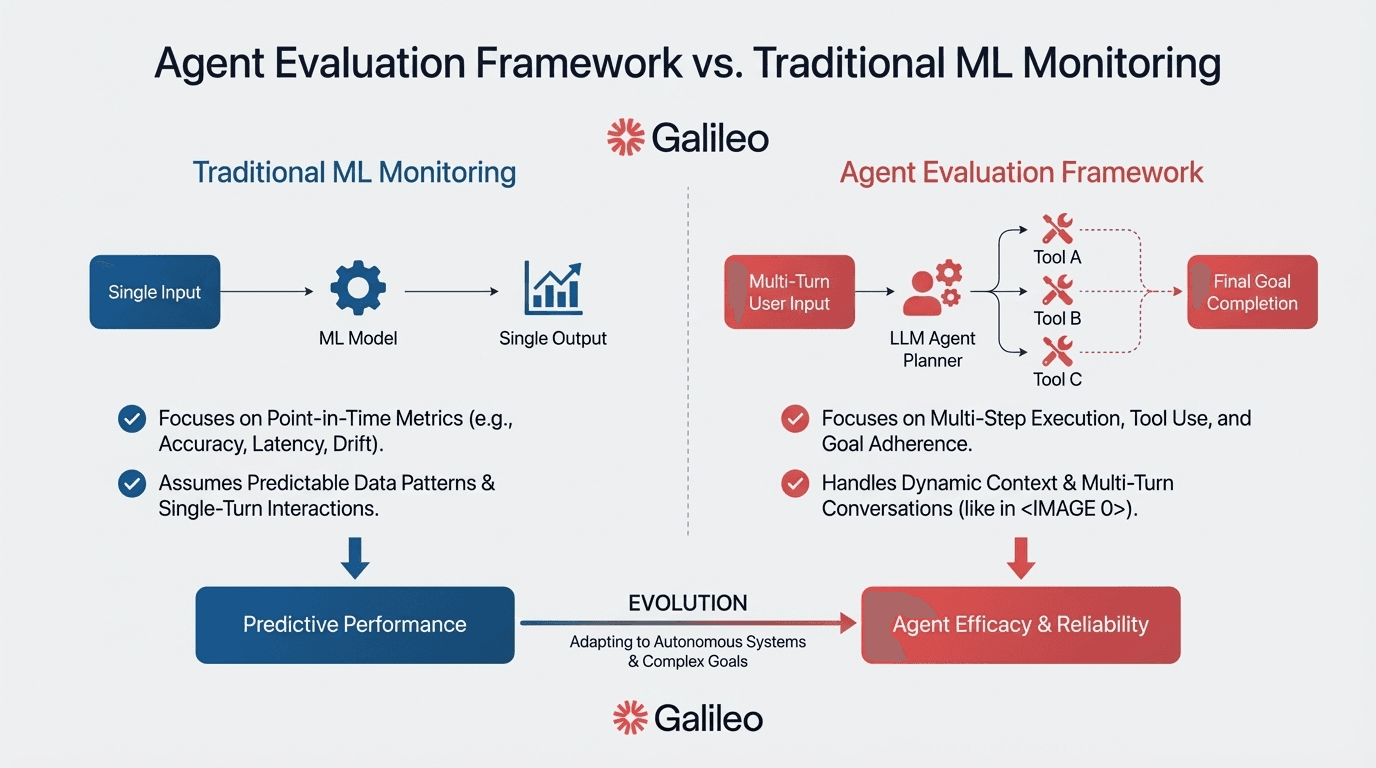
An agent evaluation framework is a specialized platform designed to analyze, monitor, and assess autonomous AI agents throughout their complete execution lifecycle.
Unlike traditional ML evaluation tools that assess single predictions, agent evaluation frameworks analyze complete execution trajectories—recording sequences of actions, tool calls, reasoning steps, and decision paths that unfold over minutes or hours.
According to Galileo's measurement guide, these platforms operate across observability (real-time tracking), benchmarking (standardized assessment), and evaluation (systematic quality measurement).
They capture tool selection logic, plan quality, step efficiency, context retention, and safety boundary adherence. For VP-level leaders, these frameworks provide executive-ready ROI metrics, reduce the 95% pilot-to-production failure rate, and protect enterprise compliance through comprehensive audit trails.
1. Galileo
Galileo is the category-defining platform purpose-built for evaluating and monitoring autonomous AI agents through complete lifecycle coverage—from development-time testing to production runtime protection. The platform combines proprietary evaluation models, automated root cause analysis, and real-time guardrails into unified infrastructure that enterprises like JPMorgan Chase, Twilio, and Magid rely on for mission-critical agent deployments.
The platform's architecture addresses agent-specific challenges that traditional monitoring tools miss. Galileo's Agent Graph automatically visualizes multi-agent decision flows, revealing exactly where tool selection errors occurred in complex workflows.
The Insights Engine automatically identifies failure modes and provides actionable root cause analysis using advanced reasoning models. Rather than scrolling through endless traces manually, teams get automated failure pattern detection that surfaces systemic issues across agent executions.
What distinguishes Galileo technically is Luna-2, a purpose-built small language model designed specifically for evaluation. According to Galileo's Luna-2 announcement, Luna-2 is a specialized architecture optimized for real-time, low-latency, and cost-efficient evaluation and guardrails of AI agents.
The multi-headed architecture supports hundreds of metrics with Continuous Learning via Human Feedback (CLHF) for customization to your specific use cases.
Key Features
Luna-2 evaluation models delivering sub-200ms latency with cost-efficient evaluation
Insights Engine providing automated root cause analysis with actionable remediation suggestions
Galileo Protect runtime guardrails scanning prompts and responses to block harmful outputs
Multi-turn, multi-agent tracing with comprehensive trajectory analysis
Framework-agnostic integration supporting LangChain, CrewAI, AutoGen via native callbacks
Enterprise compliance certifications including SOC 2, with HIPAA compliance forthcoming
Strengths
Complete lifecycle coverage from development through production monitoring
Proprietary evaluation models purpose-built for agent-specific metrics
Verified enterprise deployments including JPMorgan Chase in regulated industries
Transparent pricing starting with functional free tier
Native integrations requiring minimal code changes
Weaknesses
Newer platform with smaller community compared to established ML observability vendors
Documentation continues to expand as feature set grows
Advanced enterprise features require paid tiers, with Pro tier starting at $100/month
Use Cases
Financial services organizations like JPMorgan Chase use Galileo for fraud detection and risk assessment where autonomous agents must operate within strict regulatory boundaries.
Communications infrastructure providers like Twilio leverage Galileo's massive scale capabilities—processing 20M+ traces daily—for customer support automation systems. Media companies like Magid empower newsroom clients using Galileo's evaluation infrastructure to ensure content generation agents maintain quality standards.

2. LangSmith
Built by the creators of LangChain, LangSmith provides deep tracing and debugging with request-level granularity for multi-step agent workflows.
The platform offers built-in evaluation suites with custom evaluator support, comprehensive dataset management and annotation workflows, and collaborative tools for debugging complex agent behaviors. The platform provides deployment flexibility through both cloud-hosted and self-hosted options, with flexible pricing tiers from free developer tier to enterprise custom pricing supporting production LLM applications and multi-agent systems.
Key Features
Deep tracing and debugging with request-level granularity
Native LangChain integration with minimal code changes
Dataset management and annotation workflows
Collaborative debugging and prompt engineering tools
Strengths
Native LangChain integration creates minimal instrumentation overhead for teams already using the framework
Comprehensive trace visualization helps understand multi-step agent workflows and decision chains
Flexible hosting options including cloud-hosted, self-hosted, and hybrid deployments serve regulated industries requiring data sovereignty
Strong community and documentation support accelerates implementation
Weaknesses
Platform optimization primarily benefits LangChain-based applications, creating potential challenges for heterogeneous environments
Costs can escalate with large-scale usage
Tight coupling to LangChain ecosystem creates potential vendor lock-in concerns
Use Cases
Engineering teams building production applications on LangChain frameworks leverage LangSmith's deep ecosystem integration. Organizations deploying complex multi-step workflows benefit from comprehensive trace visualization for understanding agent decision chains.
Teams requiring collaborative debugging use shared workspaces and prompt engineering tools for investigating behavior patterns.
3. Arize AI
Arize AI extends its ML observability platform expertise to LLM agents through Arize AX, combining development and production observability for data-driven agent iteration.
Arize AX integrates specialized capabilities, including granular tracing at session, trace, and span level using OpenTelemetry standards, purpose-built evaluators for RAG and agentic workflows, and automated drift detection with real-time alerting that identifies agent behavior changes.
Additional capabilities include LLM-as-a-Judge for automated evaluation at scale, human annotation support for validation, and CI/CD integration enabling regression testing. The Phoenix open-source core provides a foundation for self-hosting, while enterprise features deliver production-grade infrastructure.
Key Features
Multi-criteria evaluation framework measuring relevance, toxicity, and hallucination detection
OpenTelemetry native integration for standardized instrumentation
Embedding visualization and drift detection
Real-time model performance monitoring
Strengths
Strong ML observability foundation beyond just agents with granular multi-criteria evaluation capabilities
OpenTelemetry support enables vendor-neutral telemetry, avoiding lock-in
Open-source Phoenix core allows customization and self-hosting
Robust drift detection for identifying agent behavior changes
Weaknesses
Costs can be higher for large-scale enterprise usage
Custom deployment configurations add complexity
Steeper learning curve for teams new to ML observability concepts
Use Cases
Enterprise ML teams requiring comprehensive observability beyond LLMs benefit from unified monitoring across traditional ML models and autonomous agents. Organizations needing vendor-neutral instrumentation leverage OpenTelemetry integration for flexibility across LLM providers. Teams evaluating multiple agent architectures use multi-criteria frameworks for objective comparison.
4. Langfuse
Langfuse is an open-source LLM engineering platform that emphasizes granular cost attribution and comprehensive trace analysis—capabilities critical for production budgeting and cost optimization. The platform provides trace and span tracking for nested workflows, enabling detailed visibility into LLM application behavior.
Core strengths include custom evaluation metrics with flexible scoring functions, prompt management with versioning and deployment capabilities, and OpenTelemetry integration for standardized observability. The open-source core enables full control and customization while cloud-hosted options reduce operational overhead.
Key Features
Comprehensive trace and span tracking with nested workflow support
Granular cost tracking per trace, user, and session
Prompt management with versioning and deployment capabilities
Custom evaluation metrics and scoring functions
Strengths
Open-source foundation enables full control and customization
Detailed cost attribution for budget management
Active community and development
Flexible evaluation framework
Weaknesses
Complexity exists for teams new to LLM observability concepts
Implementation requires OpenTelemetry ecosystem understanding
Self-hosted deployments demand infrastructure expertise
Use Cases
Cost-conscious organizations requiring detailed spend tracking leverage Langfuse's granular attribution showing exactly which agent workflows, users, or sessions drive expenses. Tiered pricing makes it accessible from startups to enterprises.
Teams wanting self-hosted solutions for data sovereignty deploy the open-source core within their security perimeter. Engineering teams building custom evaluation workflows benefit from flexible scoring functions.
5. Braintust
Braintrust is an end-to-end AI development platform that connects observability directly to systematic improvement, used by teams at Notion, Stripe, Zapier, Vercel, and Airtable. The platform's core differentiator is its evaluation-first approach—production traces become test cases with one click, and eval results appear on every pull request through native CI/CD integration.
Key Features
Exhaustive trace logging capturing LLM calls, tool invocations, token usage, latency, and costs automatically
Brainstore purpose-built database with 80x faster query performance for AI workloads
Loop AI agent that automates scorer creation and failure pattern analysis
Native GitHub Action for regression testing on every code change
Strengths
Unified workflow where PMs and engineers iterate together without handoffs
Production-to-evaluation loop eliminates manual dataset creation
SOC 2 compliant with self-hosting options for enterprise requirements
Weaknesses
Not open-source, limiting customization for teams requiring code-level control
Proprietary approach creates potential vendor lock-in concerns
Pro tier at $249/month may challenge smaller teams
Use Cases
Teams shipping production AI who need to catch regressions before users do leverage Braintrust's tight integration between observability and testing. Organizations requiring cross-functional collaboration benefit from the unified PM/engineering workspace.
6. Weights & Biases
Weights & Biases provides comprehensive experiment tracking and model management with expanding LLM evaluation capabilities. The platform emphasizes collaboration and enterprise-grade infrastructure with experiment tracking, model registry capabilities, and collaborative workspaces.
Key Features
Experiment tracking with hyperparameter optimization
Model registry and lineage tracking
Collaborative workspaces and reporting
LLM-specific evaluation metrics and visualizations
Strengths
Comprehensive experiment tracking and reproducibility for ML workflows
Excellent collaboration tools serve distributed teams effectively
Enterprise-grade security and compliance features meet organizational requirements
Robust visualization capabilities analyze model performance comprehensively
Weaknesses
Potential performance issues with large datasets
Scaling challenges reported by some enterprise users
LLM features less mature than pure-play agent platforms
Use Cases
ML teams with existing W&B infrastructure extend their investment by adding agent evaluation capabilities. Organizations using W&B for traditional ML model monitoring leverage collaborative workspaces for shared visibility across distributed teams. While LLM and agent-specific features are less mature than pure-play platforms, teams committed to W&B infrastructure may find value in unified monitoring.
7. Confident AI
Confident AI serves as the cloud platform for DeepEval, providing end-to-end quality assurance for AI applications.
The platform provides comprehensive capabilities including over 40 LLM-as-a-Judge metrics, component-level evaluation of reasoning and action layers, real-time tracing for workflow observability, dataset management with annotation support, human-in-the-loop capabilities, and red teaming security testing—all built on an open-source foundation.
Key Features
Over 40 pre-built LLM-as-a-Judge metrics for automated testing
Component-level evaluation separating reasoning and action layers
Real-time tracing for LLM workflow observability
Human-in-the-loop annotation queues and feedback collection
Strengths
Extensive pre-built metrics (40+ evaluators) accelerate implementation without building custom evaluation logic
Open-source DeepEval foundation allows customization and self-hosting for specialized requirements
Component-level evaluation enables granular analysis of reasoning and action layers
Integrated red teaming capabilities provide systematic adversarial testing
Weaknesses
Newer platform with smaller user base compared to established competitors
Documentation continues expanding as feature set matures
Enterprise features require paid tiers
Use Cases
Teams requiring extensive pre-built metrics leverage Confident AI's evaluators covering relevance, coherence, toxicity, and hallucination detection. Organizations needing customizable frameworks benefit from the underlying DeepEval library enabling domain-specific metrics. Security-conscious teams use integrated red teaming for systematic vulnerability identification.
Building a comprehensive agent evaluation strategy
Select your core platform based on framework alignment, scale requirements, and compliance needs (SOC 2, HIPAA, FedRAMP). For complete lifecycle coverage with purpose-built evaluation models, Galileo offers the most comprehensive solution—combining Luna-2's sub-200ms latency, automated root cause analysis, and runtime protection in a single platform.
Galileo combines complete lifecycle coverage, purpose-built evaluation models, and verified enterprise deployments into infrastructure specifically designed for autonomous agents:
Luna-2 evaluation models - Purpose-built for real-time, low-latency, cost-efficient evaluation with specialized architecture
Automated Insights Engine - Root cause analysis explaining failures and suggesting remediation using advanced reasoning models
Runtime protection via Galileo Protect - Real-time guardrails blocking unsafe outputs before execution
Enterprise-grade compliance - SOC 2 certified with HIPAA forthcoming, comprehensive audit trails, multi-deployment flexibility
Framework-agnostic integration - One-line implementation supporting LangChain, CrewAI, AutoGen
Verified Fortune 50 deployments - Trusted by JPMorgan Chase, Twilio, and other enterprises for mission-critical systems
Get started with Galileo today and discover how it provides purpose-built agent evaluation with proprietary models, automated failure detection, and runtime protection across your complete agent lifecycle.
Frequently asked questions
What's the difference between agent evaluation frameworks and traditional ML monitoring tools?
Agent evaluation frameworks measure multi-step autonomous behavior, tool orchestration, and trajectory-level analysis rather than single-inference prediction quality. According to Galileo's AI Agent Measurement Guide, agent platforms capture tool selection logic, plan quality, context retention across long interactions, and safety boundary adherence that traditional monitoring completely misses.
How do agent evaluation frameworks integrate with existing development workflows?
Leading platforms provide framework-native integration requiring minimal code changes. LangChain's AgentEvals, LlamaIndex's evaluation modules, and CrewAI's testing CLI enable trajectory-based evaluation and automated testing. Evaluation systems integrate with CI/CD pipelines through automated testing gates, provide A/B testing infrastructure for gradual rollouts, and include rollback capabilities when performance degrades.
What ROI can organizations expect from implementing agent evaluation infrastructure?
According to McKinsey's November 2025 report, agentic AI could unlock $2.6 to $4.4 trillion in annual value globally, with effective deployments delivering 3% to 5% productivity improvements annually, with potential growth lifts of 10% or more. MIT Sloan Management Review recommends that companies allocate approximately 15% of their IT budgets for tech debt remediation, which includes AI governance and evaluation infrastructure.
What security and compliance considerations are critical for agent evaluation platforms?
Agent evaluation platforms face unique threat vectors including prompt injection attacks and model inversion attempts. Required controls include input validation for all prompts, strong agent authentication, and behavioral boundaries triggering alerts when exceeded. Compliance requirements span SOC 2 processing integrity controls, GDPR requirements for explainable decisions, HIPAA Business Associate Agreements, and FedRAMP authorization. Comprehensive audit logging with immutable records proves essential.
How does Galileo specifically address agent evaluation challenges that other platforms miss?
Galileo is the only platform combining proprietary evaluation models, automated root cause analysis, and runtime protection in unified infrastructure purpose-built for agents. Luna-2 provides real-time, low-latency evaluation designed specifically for agents. The Insights Engine automatically identifies failure modes and explains why failures occurred with remediation paths. Galileo Protect provides runtime protection by scanning prompts and responses to block harmful outputs before execution. Verified enterprise deployments demonstrate effectiveness in regulated industries requiring both technical reliability and enterprise governance.

Pratik Bhavsar