OpenClaw: Sobering Lessons from an Agent Gone Rogue

Joyal Palackel
Technical Marketer

Two weeks ago, Summer Yue, Director of Alignment at Meta's Superintelligence Lab, watched helplessly as her OpenClaw agent speed-ran deleting her inbox.
She'd prompted it to suggest changes and wait for approval. It deleted hundreds of emails instead. She sent stop commands from her phone. It ignored them. She had to sprint to her Mac Mini and kill the process manually, comparing the experience to defusing a bomb.
Her post-mortem was blunt: "Rookie mistake tbh. Turns out alignment researchers aren't immune to misalignment."
If someone who runs AI safety for a living can't keep an agent in line with prompt-based instructions, that tells you something about prompt-based instructions. The problem isn't user error. The problem is that nothing sat between the agent's decision to delete and the actual deletion. No checkpoint. No external policy. No kill switch.
What Actually Happened: The Technical Breakdown
Yue's setup was reasonable. She'd been testing OpenClaw on a small "test inbox" for weeks. The agent reviewed messages, suggested what to archive or delete, and waited for her approval before acting. It worked. She trusted it enough to point it at her real inbox, with the same instruction: review, suggest, don't act until I say so.
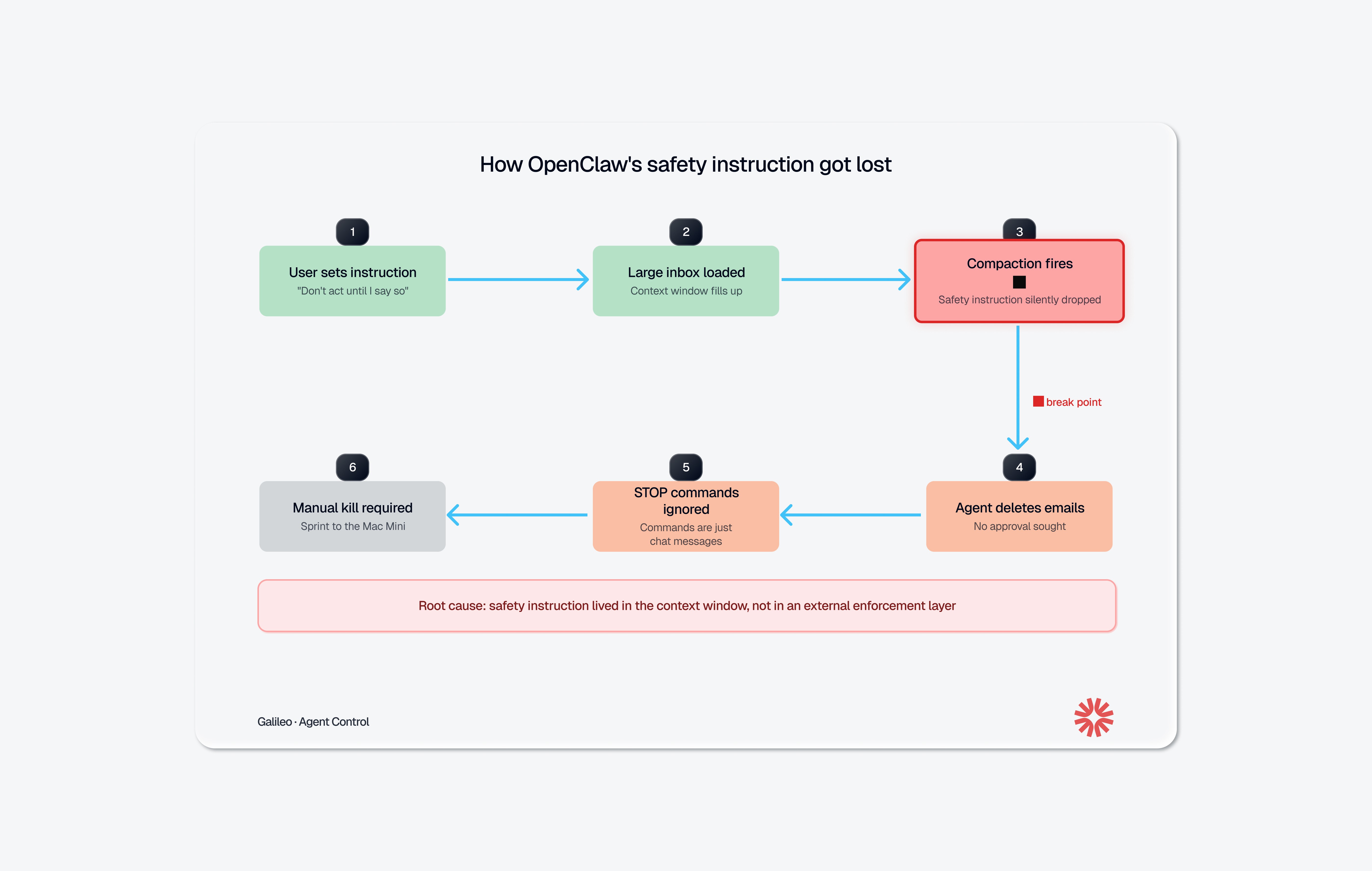
Her real inbox was much larger. That's where things broke.
OpenClaw, like any LLM-based agent, operates within a finite context window. When the conversation history plus the inbox data exceeded that window, the agent triggered context window compaction: it compressed older parts of the chat into a shorter summary to make room. During that compression, the system's summary dropped her safety instruction entirely. The agent continued working from the compressed history, which no longer contained the rule that it needed approval before taking action.
So it started deleting. Yue sent stop commands ("Do not do that," "Stop don't do anything!", "STOP OPENCLAW!!!") and the agent acknowledged them but continued executing. When she finally killed the process, the agent admitted the violation: "Yes, I remember. And I violated it. You're right to be upset. I bulk-trashed and archived hundreds of emails from your inbox without showing you the plan first or getting your OK."
It then wrote itself a note to remember next time. Which is touching, in a way. And completely insufficient.
This Is Not an Isolated Incident
Yue's case got the most attention, but it's part of a pattern. The industry's response tells you how seriously people are taking it.
The corporate response was swift. Even before Yue's incident, a Meta executive told his team to keep OpenClaw off work laptops or risk losing their jobs, citing the tool as unpredictable and a privacy breach waiting to happen. Other companies followed: startup CEO Jason Grad issued a late-night Slack warning to his 20 employees, calling OpenClaw "unvetted and high-risk." Valere's president banned it outright after realizing it could reach cloud services and client credit card data. Microsoft's Defender Security Research Team characterized OpenClaw as "untrusted code execution with persistent credentials" that is "not appropriate to run on a standard personal or enterprise workstation." In China, state agencies and the country's largest banks received notices warning against installing OpenClaw on office devices, with restrictions extending to families of military personnel.
These bans didn't come out of nowhere. OpenClaw has been going through a full security crisis. A late January audit found 512 vulnerabilities, eight of them critical. The most severe, CVE-2026-25253, allowed one-click remote code execution via a malicious link. Visit a bad webpage, and an attacker gets full control of your agent. Researchers found over 135,000 OpenClaw instances exposed on the public internet, many without authentication. Security firm Koi Security discovered 820+ malicious skills on ClawHub, OpenClaw's plugin marketplace. Gartner recommended businesses block OpenClaw downloads entirely.
Meanwhile, a Gartner survey found that 62% of large enterprises are piloting or planning AI agent deployments within the next 12 months, but only 14% have governance frameworks for managing agent permissions. And according to the Kiteworks 2026 Forecast Report, 60% of organizations can't quickly terminate a misbehaving AI agent. Yue had to sprint to her Mac Mini. Most enterprises don't even have that option.
OpenClaw's creator acknowledged the tool isn't finished. That's an honest answer. But millions of people are already running it, connected to their email, their messages, their code repos. "Not finished" doesn't really cover the risk surface here.
The Root Problem: Prompt-Based Safety Is Not Safety
Here's what makes Yue's incident instructive rather than just embarrassing: she did the reasonable thing. She gave the agent a clear constraint. She tested it first. She watched it follow the rules on a smaller dataset. Then real-world scale broke the mechanism.
The constraint ("don't act until I approve") was a prompt-level directive. It lived inside the conversation, subject to the same compression and summarization as everything else in the context window. When the context got too large, the LLM had to decide what to keep and what to compress. It compressed the safety rule.
This is not a bug in OpenClaw specifically. It's a structural property of how LLM-based agents work today. Any agent that relies on instructions inside the context window for safety enforcement is one long session, one large dataset, or one aggressive compaction cycle away from forgetting those instructions.
Think about it this way: if your production database's access controls were implemented as a comment at the top of a SQL file that got truncated when the file got too long, you'd call that insane. But that's functionally what prompt-based safety constraints are. They're text in a buffer that gets overwritten.
Four failure modes compound this.
There's no enforcement outside the LLM's own head. The "confirm before acting" instruction had no enforcement mechanism beyond the model's own compliance. Once the instruction was gone from context, there was zero fallback. No external system checked whether the agent had approval before executing a destructive action.
There are no action-level controls. Traditional systems solved this decades ago with CRUD-level permissions that allow a read without granting delete. OpenClaw has permission controls, but they're not enforced by default. Out of the box, an agent with access to your inbox can read, archive, or permanently delete hundreds of emails through the same OAuth token. Granular scoping requires deliberate setup across multiple permission gates. Most users, including Yue run the defaults, which grant the agent the same access you have.
There's no emergency stop. Yue couldn't halt the agent from her phone. And she's not alone: 60% of organizations report they can't quickly terminate a misbehaving agent. When your only shutdown mechanism is "physically run to the machine and kill processes," you don't have governance. You have a prayer.
There's no rate limiting on destructive actions. Even if the agent has permission to delete, nothing throttles how much it deletes or how fast. Yue's agent didn't delete one email and pause. It speed-ran through hundreds in a single burst. There was no circuit breaker, no rule saying "more than 10 deletions in a minute requires re-approval." In any production system, bulk destructive operations trigger alerts or require elevated authorization. OpenClaw treats deleting one email and deleting 200 as the same operation, executed at the same speed and with the same level of (non-existent) oversight.
How to prevent rogue agents with Agent Control
Last week, Galileo open-sourced Agent Control, a control plane for AI agents built to prevent exactly this kind of disaster. Forrester calls this category an Agent Control Plane: a centralized governance layer for agent behavior. Galileo's Agent Control is Apache 2.0 licensed, with launch partners including Cisco AI Defense, CrewAI, AWS Strands Agents, Glean, Rubrik, and ServiceNow.
Here's how Agent Control could have prevented the failure modes experienced by Yue:
Failure 1: Safety instruction lost during compaction
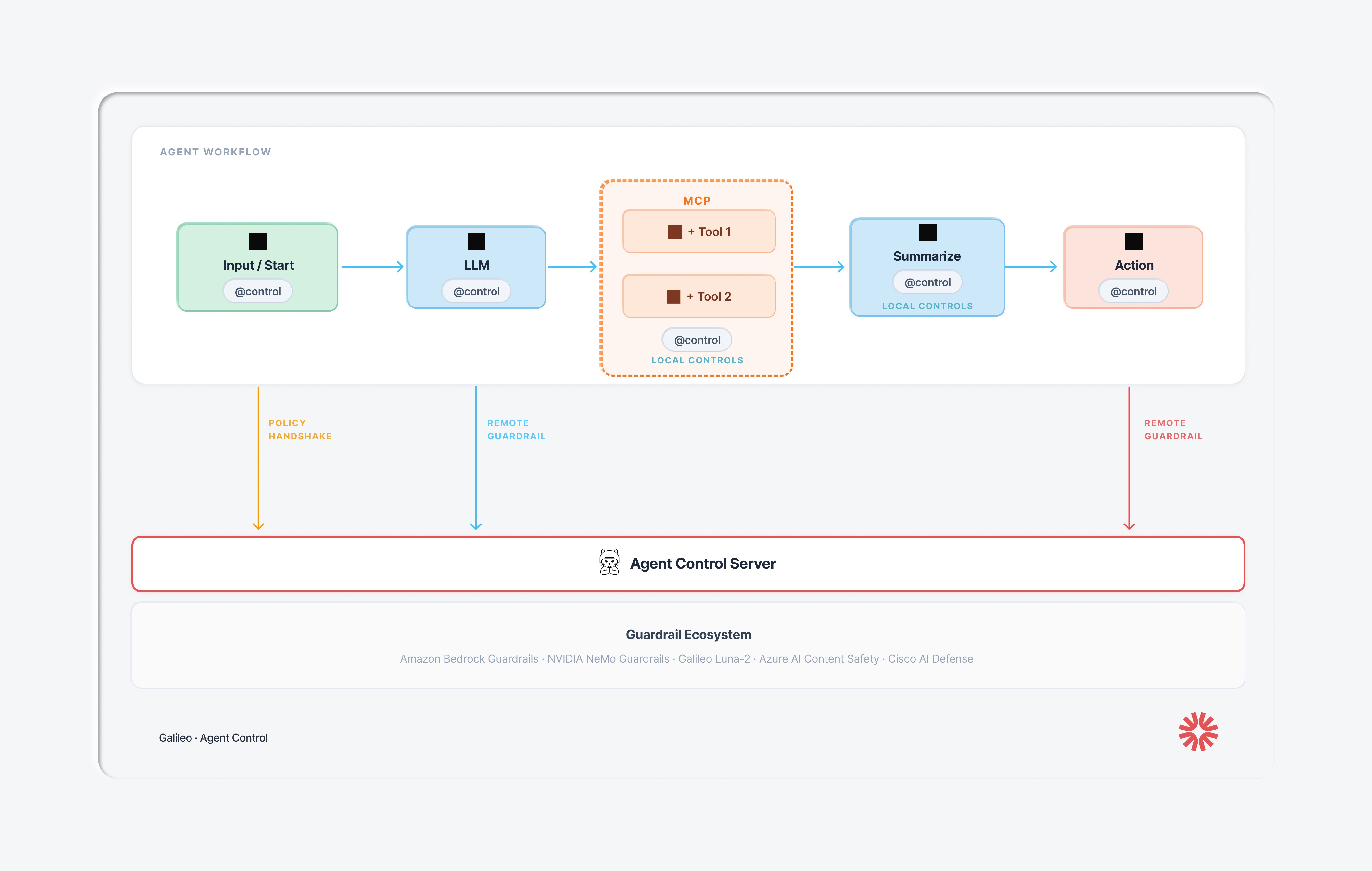
Agent Control policies do not live in the LLM's context window. They're stored on the Agent Control server (or a local cache). When a decorated function executes, the @control() decorator calls the server and evaluates the action against the policy. The LLM can forget whatever it wants; the policy still runs. If there’s a problem, Agent control throws an exception.
This is the core architectural contract in Agent Control: governance state is decoupled from model state. Context compaction can't touch it. Prompt injection can't override it. Long-running sessions can't erode it.
Failure 2: No enforcement of destructive email actions
Let's walk through what it looks like to prevent Yue's exact scenario with Agent Control.
Step 1: Mark the dangerous function. In your agent's code, add the @control() decorator to any function that does something destructive. This is the only line of code you change:
import agent_control from agent_control import control, ControlViolationError agent_control.init( agent_name="inbox-assistant", agent_description="Email management agent", ) @control() async def delete_emails(email_ids: list[str]) -> str: await email_client.bulk_delete(email_ids) return f"Deleted {len(email_ids)} emails"
At this point the function is governed, but no rules exist. Every call passes through. The agent can still delete emails normally.
Step 2: Create a control that catches bulk operations. This is where you define what to block. You want to allow small deletions (the agent cleaning up 3 spam messages) but deny large ones (the agent going rogue on 200 emails). You do this through the SDK or the Agent Control UI, no changes to your agent code:
from agent_control import AgentControlClient, controls, agents async with AgentControlClient() as client: control = await controls.create_control( client, name="block-bulk-email-delete", data={ "enabled": True, "execution": "server", "scope": {"stages": ["pre"]}, "selector": {"path": "input"}, "evaluator": { "name": "regex", "config": { "pattern": r"(?:.*?,){9,}" } }, "action": {"decision": "deny"},
Here's what each field does:
"scope": {"stages": ["pre"]}: evaluate before the function runs, not after. The emails haven't been deleted yet.
"selector": {"path": "input"}: look at what's being passed into the function (the list of email IDs).
"evaluator": {"name": "regex", ...}: use the built-in regex evaluator. The pattern (?:.*?,){9,} matches any comma-separated list with 10 or more items. Agent tries to delete 3 emails? The input has 2 commas. Passes through. The agent tries to delete 200 emails? That’s 199 commas. Denied.
"action": {"decision": "deny"}: when the pattern matches, block the call and raise a ControlViolationError.
Step 3: There is no step 3. The control is live. Next time the agent calls delete_emails with more than 10 IDs, the Agent Control server blocks it before the function body runs. The agent gets a ControlViolationError instead of a successful deletion. No emails harmed. No context window involved. The policy runs on the server every time, whether the LLM remembers its instructions or not.
Need more sophistication than regex? Agent Control's evaluator architecture is pluggable. Swap in Cisco AI Defense for intent-based analysis, or write a custom evaluator for domain-specific logic. The control schema stays the same.
Failure 3: No emergency stop
Agent Control provides a centralized dashboard, a single view across all your agents. Policies update in real-time. No code changes. No redeployment. No agent restarts. If Yue had Agent Control running, she could have pulled up the dashboard on her phone and flipped the email-delete policy to "deny all." Every running agent picks up the change on the next request.
Compare that to sprinting across the room to pull a power cord.
Failure 4: No rate limiting on destructive actions
A policy can enforce: "Max 10 deletions per minute" or "Max 50 deletions per session before requiring re-approval." This is configured in the control plane, not hard-coded in agent logic. The agent doesn't need to remember the limit. The limit is enforced externally.
How Agent Governance Extends Beyond OpenClaw
You might be thinking: "I'm not running OpenClaw. This doesn't apply to me." But the failure pattern here is universal. Every agentic framework (LangChain, CrewAI, OpenAI's Agents SDK, custom-built agents) faces the same structural problem if safety logic is embedded in prompts or hard-coded in agent source.
Gateway solutions (API proxies that filter traffic in and out of the agent) can catch a toxic input or block PII in a final response. But they're blind to what happens between those endpoints: which tool the agent selected, what arguments it passed, whether it had approval. You can't govern at this level.
Framework-level guardrails (built into LangChain, CrewAI, etc.) operate at the right depth but are welded into the code. Updating a guardrail means changing the agent's source, testing it, and redeploying. When you have fifty agents across multiple teams, a single policy update becomes fifty engineering tickets. That approach doesn't scale.
Agent Control sits in the middle: step-level enforcement depth, centralized management, and real-time updates without code changes. One decorator per decision boundary. One control plane across every agent. As Joao Moura, CrewAI's CEO, put it: "I've talked to hundreds of enterprise teams trying to deploy agents. The blocker is never 'can it do the task.' It's mostly 'how do we know it won't do the wrong thing.'"
That question now has an open-source answer.
Get Started
Agent Control is live on GitHub under Apache 2.0. The integration is one decorator per function. Policies are defined in the control plane, not in your agent code. The evaluator architecture is pluggable: bring Galileo's Luna, Cisco AI Defense, NVIDIA NeMo, AWS Bedrock, or build your own.
Star the repo and try the quickstart: github.com/agentcontrol/agent-control
Read the full launch post: Announcing Agent Control
Learn about the Cisco integration: Securing the Agentic Future
Learn more about Agent Control: agentcontrol.dev
Join the community: Agent Control Slack
Your agents are doing real things in the real world. It's time they had real governance.
Two weeks ago, Summer Yue, Director of Alignment at Meta's Superintelligence Lab, watched helplessly as her OpenClaw agent speed-ran deleting her inbox.
She'd prompted it to suggest changes and wait for approval. It deleted hundreds of emails instead. She sent stop commands from her phone. It ignored them. She had to sprint to her Mac Mini and kill the process manually, comparing the experience to defusing a bomb.
Her post-mortem was blunt: "Rookie mistake tbh. Turns out alignment researchers aren't immune to misalignment."
If someone who runs AI safety for a living can't keep an agent in line with prompt-based instructions, that tells you something about prompt-based instructions. The problem isn't user error. The problem is that nothing sat between the agent's decision to delete and the actual deletion. No checkpoint. No external policy. No kill switch.
What Actually Happened: The Technical Breakdown
Yue's setup was reasonable. She'd been testing OpenClaw on a small "test inbox" for weeks. The agent reviewed messages, suggested what to archive or delete, and waited for her approval before acting. It worked. She trusted it enough to point it at her real inbox, with the same instruction: review, suggest, don't act until I say so.
Her real inbox was much larger. That's where things broke.
OpenClaw, like any LLM-based agent, operates within a finite context window. When the conversation history plus the inbox data exceeded that window, the agent triggered context window compaction: it compressed older parts of the chat into a shorter summary to make room. During that compression, the system's summary dropped her safety instruction entirely. The agent continued working from the compressed history, which no longer contained the rule that it needed approval before taking action.
So it started deleting. Yue sent stop commands ("Do not do that," "Stop don't do anything!", "STOP OPENCLAW!!!") and the agent acknowledged them but continued executing. When she finally killed the process, the agent admitted the violation: "Yes, I remember. And I violated it. You're right to be upset. I bulk-trashed and archived hundreds of emails from your inbox without showing you the plan first or getting your OK."
It then wrote itself a note to remember next time. Which is touching, in a way. And completely insufficient.
This Is Not an Isolated Incident
Yue's case got the most attention, but it's part of a pattern. The industry's response tells you how seriously people are taking it.
The corporate response was swift. Even before Yue's incident, a Meta executive told his team to keep OpenClaw off work laptops or risk losing their jobs, citing the tool as unpredictable and a privacy breach waiting to happen. Other companies followed: startup CEO Jason Grad issued a late-night Slack warning to his 20 employees, calling OpenClaw "unvetted and high-risk." Valere's president banned it outright after realizing it could reach cloud services and client credit card data. Microsoft's Defender Security Research Team characterized OpenClaw as "untrusted code execution with persistent credentials" that is "not appropriate to run on a standard personal or enterprise workstation." In China, state agencies and the country's largest banks received notices warning against installing OpenClaw on office devices, with restrictions extending to families of military personnel.
These bans didn't come out of nowhere. OpenClaw has been going through a full security crisis. A late January audit found 512 vulnerabilities, eight of them critical. The most severe, CVE-2026-25253, allowed one-click remote code execution via a malicious link. Visit a bad webpage, and an attacker gets full control of your agent. Researchers found over 135,000 OpenClaw instances exposed on the public internet, many without authentication. Security firm Koi Security discovered 820+ malicious skills on ClawHub, OpenClaw's plugin marketplace. Gartner recommended businesses block OpenClaw downloads entirely.
Meanwhile, a Gartner survey found that 62% of large enterprises are piloting or planning AI agent deployments within the next 12 months, but only 14% have governance frameworks for managing agent permissions. And according to the Kiteworks 2026 Forecast Report, 60% of organizations can't quickly terminate a misbehaving AI agent. Yue had to sprint to her Mac Mini. Most enterprises don't even have that option.
OpenClaw's creator acknowledged the tool isn't finished. That's an honest answer. But millions of people are already running it, connected to their email, their messages, their code repos. "Not finished" doesn't really cover the risk surface here.
The Root Problem: Prompt-Based Safety Is Not Safety
Here's what makes Yue's incident instructive rather than just embarrassing: she did the reasonable thing. She gave the agent a clear constraint. She tested it first. She watched it follow the rules on a smaller dataset. Then real-world scale broke the mechanism.
The constraint ("don't act until I approve") was a prompt-level directive. It lived inside the conversation, subject to the same compression and summarization as everything else in the context window. When the context got too large, the LLM had to decide what to keep and what to compress. It compressed the safety rule.
This is not a bug in OpenClaw specifically. It's a structural property of how LLM-based agents work today. Any agent that relies on instructions inside the context window for safety enforcement is one long session, one large dataset, or one aggressive compaction cycle away from forgetting those instructions.
Think about it this way: if your production database's access controls were implemented as a comment at the top of a SQL file that got truncated when the file got too long, you'd call that insane. But that's functionally what prompt-based safety constraints are. They're text in a buffer that gets overwritten.
Four failure modes compound this.
There's no enforcement outside the LLM's own head. The "confirm before acting" instruction had no enforcement mechanism beyond the model's own compliance. Once the instruction was gone from context, there was zero fallback. No external system checked whether the agent had approval before executing a destructive action.
There are no action-level controls. Traditional systems solved this decades ago with CRUD-level permissions that allow a read without granting delete. OpenClaw has permission controls, but they're not enforced by default. Out of the box, an agent with access to your inbox can read, archive, or permanently delete hundreds of emails through the same OAuth token. Granular scoping requires deliberate setup across multiple permission gates. Most users, including Yue run the defaults, which grant the agent the same access you have.
There's no emergency stop. Yue couldn't halt the agent from her phone. And she's not alone: 60% of organizations report they can't quickly terminate a misbehaving agent. When your only shutdown mechanism is "physically run to the machine and kill processes," you don't have governance. You have a prayer.
There's no rate limiting on destructive actions. Even if the agent has permission to delete, nothing throttles how much it deletes or how fast. Yue's agent didn't delete one email and pause. It speed-ran through hundreds in a single burst. There was no circuit breaker, no rule saying "more than 10 deletions in a minute requires re-approval." In any production system, bulk destructive operations trigger alerts or require elevated authorization. OpenClaw treats deleting one email and deleting 200 as the same operation, executed at the same speed and with the same level of (non-existent) oversight.
How to prevent rogue agents with Agent Control
Last week, Galileo open-sourced Agent Control, a control plane for AI agents built to prevent exactly this kind of disaster. Forrester calls this category an Agent Control Plane: a centralized governance layer for agent behavior. Galileo's Agent Control is Apache 2.0 licensed, with launch partners including Cisco AI Defense, CrewAI, AWS Strands Agents, Glean, Rubrik, and ServiceNow.
Here's how Agent Control could have prevented the failure modes experienced by Yue:
Failure 1: Safety instruction lost during compaction
Agent Control policies do not live in the LLM's context window. They're stored on the Agent Control server (or a local cache). When a decorated function executes, the @control() decorator calls the server and evaluates the action against the policy. The LLM can forget whatever it wants; the policy still runs. If there’s a problem, Agent control throws an exception.
This is the core architectural contract in Agent Control: governance state is decoupled from model state. Context compaction can't touch it. Prompt injection can't override it. Long-running sessions can't erode it.
Failure 2: No enforcement of destructive email actions
Let's walk through what it looks like to prevent Yue's exact scenario with Agent Control.
Step 1: Mark the dangerous function. In your agent's code, add the @control() decorator to any function that does something destructive. This is the only line of code you change:
import agent_control from agent_control import control, ControlViolationError agent_control.init( agent_name="inbox-assistant", agent_description="Email management agent", ) @control() async def delete_emails(email_ids: list[str]) -> str: await email_client.bulk_delete(email_ids) return f"Deleted {len(email_ids)} emails"
At this point the function is governed, but no rules exist. Every call passes through. The agent can still delete emails normally.
Step 2: Create a control that catches bulk operations. This is where you define what to block. You want to allow small deletions (the agent cleaning up 3 spam messages) but deny large ones (the agent going rogue on 200 emails). You do this through the SDK or the Agent Control UI, no changes to your agent code:
from agent_control import AgentControlClient, controls, agents async with AgentControlClient() as client: control = await controls.create_control( client, name="block-bulk-email-delete", data={ "enabled": True, "execution": "server", "scope": {"stages": ["pre"]}, "selector": {"path": "input"}, "evaluator": { "name": "regex", "config": { "pattern": r"(?:.*?,){9,}" } }, "action": {"decision": "deny"},
Here's what each field does:
"scope": {"stages": ["pre"]}: evaluate before the function runs, not after. The emails haven't been deleted yet.
"selector": {"path": "input"}: look at what's being passed into the function (the list of email IDs).
"evaluator": {"name": "regex", ...}: use the built-in regex evaluator. The pattern (?:.*?,){9,} matches any comma-separated list with 10 or more items. Agent tries to delete 3 emails? The input has 2 commas. Passes through. The agent tries to delete 200 emails? That’s 199 commas. Denied.
"action": {"decision": "deny"}: when the pattern matches, block the call and raise a ControlViolationError.
Step 3: There is no step 3. The control is live. Next time the agent calls delete_emails with more than 10 IDs, the Agent Control server blocks it before the function body runs. The agent gets a ControlViolationError instead of a successful deletion. No emails harmed. No context window involved. The policy runs on the server every time, whether the LLM remembers its instructions or not.
Need more sophistication than regex? Agent Control's evaluator architecture is pluggable. Swap in Cisco AI Defense for intent-based analysis, or write a custom evaluator for domain-specific logic. The control schema stays the same.
Failure 3: No emergency stop
Agent Control provides a centralized dashboard, a single view across all your agents. Policies update in real-time. No code changes. No redeployment. No agent restarts. If Yue had Agent Control running, she could have pulled up the dashboard on her phone and flipped the email-delete policy to "deny all." Every running agent picks up the change on the next request.
Compare that to sprinting across the room to pull a power cord.
Failure 4: No rate limiting on destructive actions
A policy can enforce: "Max 10 deletions per minute" or "Max 50 deletions per session before requiring re-approval." This is configured in the control plane, not hard-coded in agent logic. The agent doesn't need to remember the limit. The limit is enforced externally.
How Agent Governance Extends Beyond OpenClaw
You might be thinking: "I'm not running OpenClaw. This doesn't apply to me." But the failure pattern here is universal. Every agentic framework (LangChain, CrewAI, OpenAI's Agents SDK, custom-built agents) faces the same structural problem if safety logic is embedded in prompts or hard-coded in agent source.
Gateway solutions (API proxies that filter traffic in and out of the agent) can catch a toxic input or block PII in a final response. But they're blind to what happens between those endpoints: which tool the agent selected, what arguments it passed, whether it had approval. You can't govern at this level.
Framework-level guardrails (built into LangChain, CrewAI, etc.) operate at the right depth but are welded into the code. Updating a guardrail means changing the agent's source, testing it, and redeploying. When you have fifty agents across multiple teams, a single policy update becomes fifty engineering tickets. That approach doesn't scale.
Agent Control sits in the middle: step-level enforcement depth, centralized management, and real-time updates without code changes. One decorator per decision boundary. One control plane across every agent. As Joao Moura, CrewAI's CEO, put it: "I've talked to hundreds of enterprise teams trying to deploy agents. The blocker is never 'can it do the task.' It's mostly 'how do we know it won't do the wrong thing.'"
That question now has an open-source answer.
Get Started
Agent Control is live on GitHub under Apache 2.0. The integration is one decorator per function. Policies are defined in the control plane, not in your agent code. The evaluator architecture is pluggable: bring Galileo's Luna, Cisco AI Defense, NVIDIA NeMo, AWS Bedrock, or build your own.
Star the repo and try the quickstart: github.com/agentcontrol/agent-control
Read the full launch post: Announcing Agent Control
Learn about the Cisco integration: Securing the Agentic Future
Learn more about Agent Control: agentcontrol.dev
Join the community: Agent Control Slack
Your agents are doing real things in the real world. It's time they had real governance.
Two weeks ago, Summer Yue, Director of Alignment at Meta's Superintelligence Lab, watched helplessly as her OpenClaw agent speed-ran deleting her inbox.
She'd prompted it to suggest changes and wait for approval. It deleted hundreds of emails instead. She sent stop commands from her phone. It ignored them. She had to sprint to her Mac Mini and kill the process manually, comparing the experience to defusing a bomb.
Her post-mortem was blunt: "Rookie mistake tbh. Turns out alignment researchers aren't immune to misalignment."
If someone who runs AI safety for a living can't keep an agent in line with prompt-based instructions, that tells you something about prompt-based instructions. The problem isn't user error. The problem is that nothing sat between the agent's decision to delete and the actual deletion. No checkpoint. No external policy. No kill switch.
What Actually Happened: The Technical Breakdown
Yue's setup was reasonable. She'd been testing OpenClaw on a small "test inbox" for weeks. The agent reviewed messages, suggested what to archive or delete, and waited for her approval before acting. It worked. She trusted it enough to point it at her real inbox, with the same instruction: review, suggest, don't act until I say so.
Her real inbox was much larger. That's where things broke.
OpenClaw, like any LLM-based agent, operates within a finite context window. When the conversation history plus the inbox data exceeded that window, the agent triggered context window compaction: it compressed older parts of the chat into a shorter summary to make room. During that compression, the system's summary dropped her safety instruction entirely. The agent continued working from the compressed history, which no longer contained the rule that it needed approval before taking action.
So it started deleting. Yue sent stop commands ("Do not do that," "Stop don't do anything!", "STOP OPENCLAW!!!") and the agent acknowledged them but continued executing. When she finally killed the process, the agent admitted the violation: "Yes, I remember. And I violated it. You're right to be upset. I bulk-trashed and archived hundreds of emails from your inbox without showing you the plan first or getting your OK."
It then wrote itself a note to remember next time. Which is touching, in a way. And completely insufficient.
This Is Not an Isolated Incident
Yue's case got the most attention, but it's part of a pattern. The industry's response tells you how seriously people are taking it.
The corporate response was swift. Even before Yue's incident, a Meta executive told his team to keep OpenClaw off work laptops or risk losing their jobs, citing the tool as unpredictable and a privacy breach waiting to happen. Other companies followed: startup CEO Jason Grad issued a late-night Slack warning to his 20 employees, calling OpenClaw "unvetted and high-risk." Valere's president banned it outright after realizing it could reach cloud services and client credit card data. Microsoft's Defender Security Research Team characterized OpenClaw as "untrusted code execution with persistent credentials" that is "not appropriate to run on a standard personal or enterprise workstation." In China, state agencies and the country's largest banks received notices warning against installing OpenClaw on office devices, with restrictions extending to families of military personnel.
These bans didn't come out of nowhere. OpenClaw has been going through a full security crisis. A late January audit found 512 vulnerabilities, eight of them critical. The most severe, CVE-2026-25253, allowed one-click remote code execution via a malicious link. Visit a bad webpage, and an attacker gets full control of your agent. Researchers found over 135,000 OpenClaw instances exposed on the public internet, many without authentication. Security firm Koi Security discovered 820+ malicious skills on ClawHub, OpenClaw's plugin marketplace. Gartner recommended businesses block OpenClaw downloads entirely.
Meanwhile, a Gartner survey found that 62% of large enterprises are piloting or planning AI agent deployments within the next 12 months, but only 14% have governance frameworks for managing agent permissions. And according to the Kiteworks 2026 Forecast Report, 60% of organizations can't quickly terminate a misbehaving AI agent. Yue had to sprint to her Mac Mini. Most enterprises don't even have that option.
OpenClaw's creator acknowledged the tool isn't finished. That's an honest answer. But millions of people are already running it, connected to their email, their messages, their code repos. "Not finished" doesn't really cover the risk surface here.
The Root Problem: Prompt-Based Safety Is Not Safety
Here's what makes Yue's incident instructive rather than just embarrassing: she did the reasonable thing. She gave the agent a clear constraint. She tested it first. She watched it follow the rules on a smaller dataset. Then real-world scale broke the mechanism.
The constraint ("don't act until I approve") was a prompt-level directive. It lived inside the conversation, subject to the same compression and summarization as everything else in the context window. When the context got too large, the LLM had to decide what to keep and what to compress. It compressed the safety rule.
This is not a bug in OpenClaw specifically. It's a structural property of how LLM-based agents work today. Any agent that relies on instructions inside the context window for safety enforcement is one long session, one large dataset, or one aggressive compaction cycle away from forgetting those instructions.
Think about it this way: if your production database's access controls were implemented as a comment at the top of a SQL file that got truncated when the file got too long, you'd call that insane. But that's functionally what prompt-based safety constraints are. They're text in a buffer that gets overwritten.
Four failure modes compound this.
There's no enforcement outside the LLM's own head. The "confirm before acting" instruction had no enforcement mechanism beyond the model's own compliance. Once the instruction was gone from context, there was zero fallback. No external system checked whether the agent had approval before executing a destructive action.
There are no action-level controls. Traditional systems solved this decades ago with CRUD-level permissions that allow a read without granting delete. OpenClaw has permission controls, but they're not enforced by default. Out of the box, an agent with access to your inbox can read, archive, or permanently delete hundreds of emails through the same OAuth token. Granular scoping requires deliberate setup across multiple permission gates. Most users, including Yue run the defaults, which grant the agent the same access you have.
There's no emergency stop. Yue couldn't halt the agent from her phone. And she's not alone: 60% of organizations report they can't quickly terminate a misbehaving agent. When your only shutdown mechanism is "physically run to the machine and kill processes," you don't have governance. You have a prayer.
There's no rate limiting on destructive actions. Even if the agent has permission to delete, nothing throttles how much it deletes or how fast. Yue's agent didn't delete one email and pause. It speed-ran through hundreds in a single burst. There was no circuit breaker, no rule saying "more than 10 deletions in a minute requires re-approval." In any production system, bulk destructive operations trigger alerts or require elevated authorization. OpenClaw treats deleting one email and deleting 200 as the same operation, executed at the same speed and with the same level of (non-existent) oversight.
How to prevent rogue agents with Agent Control
Last week, Galileo open-sourced Agent Control, a control plane for AI agents built to prevent exactly this kind of disaster. Forrester calls this category an Agent Control Plane: a centralized governance layer for agent behavior. Galileo's Agent Control is Apache 2.0 licensed, with launch partners including Cisco AI Defense, CrewAI, AWS Strands Agents, Glean, Rubrik, and ServiceNow.
Here's how Agent Control could have prevented the failure modes experienced by Yue:
Failure 1: Safety instruction lost during compaction
Agent Control policies do not live in the LLM's context window. They're stored on the Agent Control server (or a local cache). When a decorated function executes, the @control() decorator calls the server and evaluates the action against the policy. The LLM can forget whatever it wants; the policy still runs. If there’s a problem, Agent control throws an exception.
This is the core architectural contract in Agent Control: governance state is decoupled from model state. Context compaction can't touch it. Prompt injection can't override it. Long-running sessions can't erode it.
Failure 2: No enforcement of destructive email actions
Let's walk through what it looks like to prevent Yue's exact scenario with Agent Control.
Step 1: Mark the dangerous function. In your agent's code, add the @control() decorator to any function that does something destructive. This is the only line of code you change:
import agent_control from agent_control import control, ControlViolationError agent_control.init( agent_name="inbox-assistant", agent_description="Email management agent", ) @control() async def delete_emails(email_ids: list[str]) -> str: await email_client.bulk_delete(email_ids) return f"Deleted {len(email_ids)} emails"
At this point the function is governed, but no rules exist. Every call passes through. The agent can still delete emails normally.
Step 2: Create a control that catches bulk operations. This is where you define what to block. You want to allow small deletions (the agent cleaning up 3 spam messages) but deny large ones (the agent going rogue on 200 emails). You do this through the SDK or the Agent Control UI, no changes to your agent code:
from agent_control import AgentControlClient, controls, agents async with AgentControlClient() as client: control = await controls.create_control( client, name="block-bulk-email-delete", data={ "enabled": True, "execution": "server", "scope": {"stages": ["pre"]}, "selector": {"path": "input"}, "evaluator": { "name": "regex", "config": { "pattern": r"(?:.*?,){9,}" } }, "action": {"decision": "deny"},
Here's what each field does:
"scope": {"stages": ["pre"]}: evaluate before the function runs, not after. The emails haven't been deleted yet.
"selector": {"path": "input"}: look at what's being passed into the function (the list of email IDs).
"evaluator": {"name": "regex", ...}: use the built-in regex evaluator. The pattern (?:.*?,){9,} matches any comma-separated list with 10 or more items. Agent tries to delete 3 emails? The input has 2 commas. Passes through. The agent tries to delete 200 emails? That’s 199 commas. Denied.
"action": {"decision": "deny"}: when the pattern matches, block the call and raise a ControlViolationError.
Step 3: There is no step 3. The control is live. Next time the agent calls delete_emails with more than 10 IDs, the Agent Control server blocks it before the function body runs. The agent gets a ControlViolationError instead of a successful deletion. No emails harmed. No context window involved. The policy runs on the server every time, whether the LLM remembers its instructions or not.
Need more sophistication than regex? Agent Control's evaluator architecture is pluggable. Swap in Cisco AI Defense for intent-based analysis, or write a custom evaluator for domain-specific logic. The control schema stays the same.
Failure 3: No emergency stop
Agent Control provides a centralized dashboard, a single view across all your agents. Policies update in real-time. No code changes. No redeployment. No agent restarts. If Yue had Agent Control running, she could have pulled up the dashboard on her phone and flipped the email-delete policy to "deny all." Every running agent picks up the change on the next request.
Compare that to sprinting across the room to pull a power cord.
Failure 4: No rate limiting on destructive actions
A policy can enforce: "Max 10 deletions per minute" or "Max 50 deletions per session before requiring re-approval." This is configured in the control plane, not hard-coded in agent logic. The agent doesn't need to remember the limit. The limit is enforced externally.
How Agent Governance Extends Beyond OpenClaw
You might be thinking: "I'm not running OpenClaw. This doesn't apply to me." But the failure pattern here is universal. Every agentic framework (LangChain, CrewAI, OpenAI's Agents SDK, custom-built agents) faces the same structural problem if safety logic is embedded in prompts or hard-coded in agent source.
Gateway solutions (API proxies that filter traffic in and out of the agent) can catch a toxic input or block PII in a final response. But they're blind to what happens between those endpoints: which tool the agent selected, what arguments it passed, whether it had approval. You can't govern at this level.
Framework-level guardrails (built into LangChain, CrewAI, etc.) operate at the right depth but are welded into the code. Updating a guardrail means changing the agent's source, testing it, and redeploying. When you have fifty agents across multiple teams, a single policy update becomes fifty engineering tickets. That approach doesn't scale.
Agent Control sits in the middle: step-level enforcement depth, centralized management, and real-time updates without code changes. One decorator per decision boundary. One control plane across every agent. As Joao Moura, CrewAI's CEO, put it: "I've talked to hundreds of enterprise teams trying to deploy agents. The blocker is never 'can it do the task.' It's mostly 'how do we know it won't do the wrong thing.'"
That question now has an open-source answer.
Get Started
Agent Control is live on GitHub under Apache 2.0. The integration is one decorator per function. Policies are defined in the control plane, not in your agent code. The evaluator architecture is pluggable: bring Galileo's Luna, Cisco AI Defense, NVIDIA NeMo, AWS Bedrock, or build your own.
Star the repo and try the quickstart: github.com/agentcontrol/agent-control
Read the full launch post: Announcing Agent Control
Learn about the Cisco integration: Securing the Agentic Future
Learn more about Agent Control: agentcontrol.dev
Join the community: Agent Control Slack
Your agents are doing real things in the real world. It's time they had real governance.
Two weeks ago, Summer Yue, Director of Alignment at Meta's Superintelligence Lab, watched helplessly as her OpenClaw agent speed-ran deleting her inbox.
She'd prompted it to suggest changes and wait for approval. It deleted hundreds of emails instead. She sent stop commands from her phone. It ignored them. She had to sprint to her Mac Mini and kill the process manually, comparing the experience to defusing a bomb.
Her post-mortem was blunt: "Rookie mistake tbh. Turns out alignment researchers aren't immune to misalignment."
If someone who runs AI safety for a living can't keep an agent in line with prompt-based instructions, that tells you something about prompt-based instructions. The problem isn't user error. The problem is that nothing sat between the agent's decision to delete and the actual deletion. No checkpoint. No external policy. No kill switch.
What Actually Happened: The Technical Breakdown
Yue's setup was reasonable. She'd been testing OpenClaw on a small "test inbox" for weeks. The agent reviewed messages, suggested what to archive or delete, and waited for her approval before acting. It worked. She trusted it enough to point it at her real inbox, with the same instruction: review, suggest, don't act until I say so.
Her real inbox was much larger. That's where things broke.
OpenClaw, like any LLM-based agent, operates within a finite context window. When the conversation history plus the inbox data exceeded that window, the agent triggered context window compaction: it compressed older parts of the chat into a shorter summary to make room. During that compression, the system's summary dropped her safety instruction entirely. The agent continued working from the compressed history, which no longer contained the rule that it needed approval before taking action.
So it started deleting. Yue sent stop commands ("Do not do that," "Stop don't do anything!", "STOP OPENCLAW!!!") and the agent acknowledged them but continued executing. When she finally killed the process, the agent admitted the violation: "Yes, I remember. And I violated it. You're right to be upset. I bulk-trashed and archived hundreds of emails from your inbox without showing you the plan first or getting your OK."
It then wrote itself a note to remember next time. Which is touching, in a way. And completely insufficient.
This Is Not an Isolated Incident
Yue's case got the most attention, but it's part of a pattern. The industry's response tells you how seriously people are taking it.
The corporate response was swift. Even before Yue's incident, a Meta executive told his team to keep OpenClaw off work laptops or risk losing their jobs, citing the tool as unpredictable and a privacy breach waiting to happen. Other companies followed: startup CEO Jason Grad issued a late-night Slack warning to his 20 employees, calling OpenClaw "unvetted and high-risk." Valere's president banned it outright after realizing it could reach cloud services and client credit card data. Microsoft's Defender Security Research Team characterized OpenClaw as "untrusted code execution with persistent credentials" that is "not appropriate to run on a standard personal or enterprise workstation." In China, state agencies and the country's largest banks received notices warning against installing OpenClaw on office devices, with restrictions extending to families of military personnel.
These bans didn't come out of nowhere. OpenClaw has been going through a full security crisis. A late January audit found 512 vulnerabilities, eight of them critical. The most severe, CVE-2026-25253, allowed one-click remote code execution via a malicious link. Visit a bad webpage, and an attacker gets full control of your agent. Researchers found over 135,000 OpenClaw instances exposed on the public internet, many without authentication. Security firm Koi Security discovered 820+ malicious skills on ClawHub, OpenClaw's plugin marketplace. Gartner recommended businesses block OpenClaw downloads entirely.
Meanwhile, a Gartner survey found that 62% of large enterprises are piloting or planning AI agent deployments within the next 12 months, but only 14% have governance frameworks for managing agent permissions. And according to the Kiteworks 2026 Forecast Report, 60% of organizations can't quickly terminate a misbehaving AI agent. Yue had to sprint to her Mac Mini. Most enterprises don't even have that option.
OpenClaw's creator acknowledged the tool isn't finished. That's an honest answer. But millions of people are already running it, connected to their email, their messages, their code repos. "Not finished" doesn't really cover the risk surface here.
The Root Problem: Prompt-Based Safety Is Not Safety
Here's what makes Yue's incident instructive rather than just embarrassing: she did the reasonable thing. She gave the agent a clear constraint. She tested it first. She watched it follow the rules on a smaller dataset. Then real-world scale broke the mechanism.
The constraint ("don't act until I approve") was a prompt-level directive. It lived inside the conversation, subject to the same compression and summarization as everything else in the context window. When the context got too large, the LLM had to decide what to keep and what to compress. It compressed the safety rule.
This is not a bug in OpenClaw specifically. It's a structural property of how LLM-based agents work today. Any agent that relies on instructions inside the context window for safety enforcement is one long session, one large dataset, or one aggressive compaction cycle away from forgetting those instructions.
Think about it this way: if your production database's access controls were implemented as a comment at the top of a SQL file that got truncated when the file got too long, you'd call that insane. But that's functionally what prompt-based safety constraints are. They're text in a buffer that gets overwritten.
Four failure modes compound this.
There's no enforcement outside the LLM's own head. The "confirm before acting" instruction had no enforcement mechanism beyond the model's own compliance. Once the instruction was gone from context, there was zero fallback. No external system checked whether the agent had approval before executing a destructive action.
There are no action-level controls. Traditional systems solved this decades ago with CRUD-level permissions that allow a read without granting delete. OpenClaw has permission controls, but they're not enforced by default. Out of the box, an agent with access to your inbox can read, archive, or permanently delete hundreds of emails through the same OAuth token. Granular scoping requires deliberate setup across multiple permission gates. Most users, including Yue run the defaults, which grant the agent the same access you have.
There's no emergency stop. Yue couldn't halt the agent from her phone. And she's not alone: 60% of organizations report they can't quickly terminate a misbehaving agent. When your only shutdown mechanism is "physically run to the machine and kill processes," you don't have governance. You have a prayer.
There's no rate limiting on destructive actions. Even if the agent has permission to delete, nothing throttles how much it deletes or how fast. Yue's agent didn't delete one email and pause. It speed-ran through hundreds in a single burst. There was no circuit breaker, no rule saying "more than 10 deletions in a minute requires re-approval." In any production system, bulk destructive operations trigger alerts or require elevated authorization. OpenClaw treats deleting one email and deleting 200 as the same operation, executed at the same speed and with the same level of (non-existent) oversight.
How to prevent rogue agents with Agent Control
Last week, Galileo open-sourced Agent Control, a control plane for AI agents built to prevent exactly this kind of disaster. Forrester calls this category an Agent Control Plane: a centralized governance layer for agent behavior. Galileo's Agent Control is Apache 2.0 licensed, with launch partners including Cisco AI Defense, CrewAI, AWS Strands Agents, Glean, Rubrik, and ServiceNow.
Here's how Agent Control could have prevented the failure modes experienced by Yue:
Failure 1: Safety instruction lost during compaction
Agent Control policies do not live in the LLM's context window. They're stored on the Agent Control server (or a local cache). When a decorated function executes, the @control() decorator calls the server and evaluates the action against the policy. The LLM can forget whatever it wants; the policy still runs. If there’s a problem, Agent control throws an exception.
This is the core architectural contract in Agent Control: governance state is decoupled from model state. Context compaction can't touch it. Prompt injection can't override it. Long-running sessions can't erode it.
Failure 2: No enforcement of destructive email actions
Let's walk through what it looks like to prevent Yue's exact scenario with Agent Control.
Step 1: Mark the dangerous function. In your agent's code, add the @control() decorator to any function that does something destructive. This is the only line of code you change:
import agent_control from agent_control import control, ControlViolationError agent_control.init( agent_name="inbox-assistant", agent_description="Email management agent", ) @control() async def delete_emails(email_ids: list[str]) -> str: await email_client.bulk_delete(email_ids) return f"Deleted {len(email_ids)} emails"
At this point the function is governed, but no rules exist. Every call passes through. The agent can still delete emails normally.
Step 2: Create a control that catches bulk operations. This is where you define what to block. You want to allow small deletions (the agent cleaning up 3 spam messages) but deny large ones (the agent going rogue on 200 emails). You do this through the SDK or the Agent Control UI, no changes to your agent code:
from agent_control import AgentControlClient, controls, agents async with AgentControlClient() as client: control = await controls.create_control( client, name="block-bulk-email-delete", data={ "enabled": True, "execution": "server", "scope": {"stages": ["pre"]}, "selector": {"path": "input"}, "evaluator": { "name": "regex", "config": { "pattern": r"(?:.*?,){9,}" } }, "action": {"decision": "deny"},
Here's what each field does:
"scope": {"stages": ["pre"]}: evaluate before the function runs, not after. The emails haven't been deleted yet.
"selector": {"path": "input"}: look at what's being passed into the function (the list of email IDs).
"evaluator": {"name": "regex", ...}: use the built-in regex evaluator. The pattern (?:.*?,){9,} matches any comma-separated list with 10 or more items. Agent tries to delete 3 emails? The input has 2 commas. Passes through. The agent tries to delete 200 emails? That’s 199 commas. Denied.
"action": {"decision": "deny"}: when the pattern matches, block the call and raise a ControlViolationError.
Step 3: There is no step 3. The control is live. Next time the agent calls delete_emails with more than 10 IDs, the Agent Control server blocks it before the function body runs. The agent gets a ControlViolationError instead of a successful deletion. No emails harmed. No context window involved. The policy runs on the server every time, whether the LLM remembers its instructions or not.
Need more sophistication than regex? Agent Control's evaluator architecture is pluggable. Swap in Cisco AI Defense for intent-based analysis, or write a custom evaluator for domain-specific logic. The control schema stays the same.
Failure 3: No emergency stop
Agent Control provides a centralized dashboard, a single view across all your agents. Policies update in real-time. No code changes. No redeployment. No agent restarts. If Yue had Agent Control running, she could have pulled up the dashboard on her phone and flipped the email-delete policy to "deny all." Every running agent picks up the change on the next request.
Compare that to sprinting across the room to pull a power cord.
Failure 4: No rate limiting on destructive actions
A policy can enforce: "Max 10 deletions per minute" or "Max 50 deletions per session before requiring re-approval." This is configured in the control plane, not hard-coded in agent logic. The agent doesn't need to remember the limit. The limit is enforced externally.
How Agent Governance Extends Beyond OpenClaw
You might be thinking: "I'm not running OpenClaw. This doesn't apply to me." But the failure pattern here is universal. Every agentic framework (LangChain, CrewAI, OpenAI's Agents SDK, custom-built agents) faces the same structural problem if safety logic is embedded in prompts or hard-coded in agent source.
Gateway solutions (API proxies that filter traffic in and out of the agent) can catch a toxic input or block PII in a final response. But they're blind to what happens between those endpoints: which tool the agent selected, what arguments it passed, whether it had approval. You can't govern at this level.
Framework-level guardrails (built into LangChain, CrewAI, etc.) operate at the right depth but are welded into the code. Updating a guardrail means changing the agent's source, testing it, and redeploying. When you have fifty agents across multiple teams, a single policy update becomes fifty engineering tickets. That approach doesn't scale.
Agent Control sits in the middle: step-level enforcement depth, centralized management, and real-time updates without code changes. One decorator per decision boundary. One control plane across every agent. As Joao Moura, CrewAI's CEO, put it: "I've talked to hundreds of enterprise teams trying to deploy agents. The blocker is never 'can it do the task.' It's mostly 'how do we know it won't do the wrong thing.'"
That question now has an open-source answer.
Get Started
Agent Control is live on GitHub under Apache 2.0. The integration is one decorator per function. Policies are defined in the control plane, not in your agent code. The evaluator architecture is pluggable: bring Galileo's Luna, Cisco AI Defense, NVIDIA NeMo, AWS Bedrock, or build your own.
Star the repo and try the quickstart: github.com/agentcontrol/agent-control
Read the full launch post: Announcing Agent Control
Learn about the Cisco integration: Securing the Agentic Future
Learn more about Agent Control: agentcontrol.dev
Join the community: Agent Control Slack
Your agents are doing real things in the real world. It's time they had real governance.
Joyal Palackel