The 2026 Caching Playbook for Agents: Bigger Prompts, Smaller Bills.

"I pulled 167 production agent sessions from one machine and counted tokens. The harness loading the most context per turn paid the smallest bill. The one loading the least paid 3× more. Caching broke every prompt-optimization rule we used to follow."
I was sanity-checking eval cost projections for a customer last month and pulled my own agent session logs as a reality check. The numbers stopped fitting my mental model almost immediately.
The harness that loaded the most context per turn was the cheapest one I ran. Not by a little. By 3×.
So I pulled logs from two more harnesses on the same machine, ran the same script, and got the same shape. Claude Code averaged 67,600 tokens on the median turn at 2 cents per turn. The OpenClaw operator agent averaged 18,500 tokens at 6 cents per turn. Same agent class. Same kind of work. The bigger prompt was the cheaper prompt.
This is the part of agent economics that flipped in 2024, and most of us haven't recalibrated for it. I'd been writing agents the way most engineers were taught. Trim the prompt. Prune the history. Keep tokens low. Smaller is cheaper. That instinct used to be right. It isn't anymore.
What I measured
Three workloads, all from real production sessions on a single dev machine over the same week of work. Pulled from ~/.claude/projects/, /Users/airlock/.codex/sessions/, and the OpenClaw operator session log. Heartbeat sessions and cron-handler chatter removed, so the numbers reflect real human-driven work. The right-most column is per-turn cost computed at Sonnet 4.6 rates.
Harness | n | p50 turns | Fresh / turn | Total / turn | Cached | $ / turn |
|---|---|---|---|---|---|---|
Claude Code
| 17 | 36 | 296 | 67.6K | 92.7% | $0.02 |
Codex atomic ticket
| 37 | 19 | 4.4K | 43.5K | 89.6% | $0.03 |
OpenClaw operator
| 113 | 13 | 13.3K | 18.5K | 23.8% | $0.06 |
167 real sessions, parsed from local session logs. Cost / turn computed at Sonnet 4.6 rates ($3 input, $15 output, $0.30 cache read).
Read the table top to bottom and the bill numbers run in the wrong direction. The biggest prompts ship for two cents a turn. The smallest ones ship for six. The whole inversion lives in one column: cache hit rate. Claude Code reads 92.7% of its prompt from cache. OpenClaw reads 23.8%. The discount lives there.
Stop pruning. Start pinning. The prompt that gets reused at the cache rate is worth more than the prompt that's small. |
Why this is true
Prompt caching landed in 2024 and changed the per-call math. Anthropic, OpenAI, and Google now let you pin a prompt prefix in their infrastructure and reuse it on subsequent calls at roughly 10% of the input rate. The prefix has to match exactly. It has to be marked cacheable. Get those two things right and every byte beyond the first call is close to free.
That broke the prompt-optimization advice every engineer was carrying around. Before caching, every token in the prompt cost the same on every call, so the rules were obvious. Keep the prompt small. Swap in only what you need. Never repeat yourself. After caching, those rules are wrong. The new ones: front-load everything that's stable, pin it, append only the fresh delta. The cache makes the prefix a sunk cost.
Here's what the difference looks like in the prompt sent on a median turn.
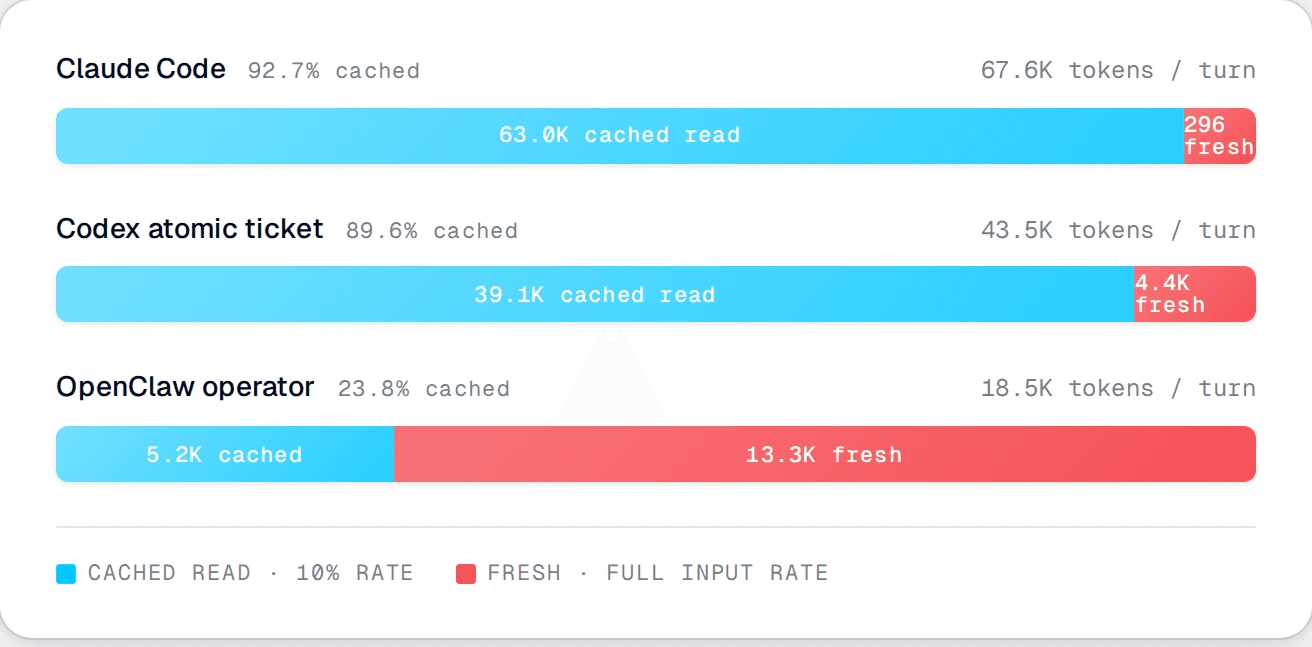
The prompt sent on the median turn. Optimized harnesses load larger prompts but most of them ride at the cached rate.
Claude Code's median turn is 67.6K tokens. Of those, 63K are cached reads paying $0.30 per million. Only 296 tokens are fresh, paying $3 per million. The full bill: about two cents.
OpenClaw's median turn is 18.5K tokens. Of those, only 5.2K are cached. The other 13.3K are fresh, paying full input rate. The bill: about six cents.
The smaller prompt costs more because there's nothing for the cache to amortize. The bigger prompt costs less because almost all of it is the same prefix every call. The math is upside-down from the way most of us were trained to read it.
Watch what happens over three consecutive turns of the same conversation. The cached prefix stays put. Only the fresh delta grows.

One conversation, three consecutive turns. The cached prefix is reused across turns 2 and 3. The fresh delta is the only thing paying full input rate.
How to engineer for cache
Once you internalize that the prefix is a sunk cost, the design rules flip. Here's the working set I use now.
01. Make the prefix stable and big
System instructions, tool definitions, and any reusable context belong at the top of the prompt, and they belong there verbatim, every turn. Don't dynamically reorder tools. Don't slot user-specific content in at random positions. The cache only hits on exact byte-for-byte matches with what was sent before. One stray comma break and you're paying full price again. Treat the prefix like a static asset.
02. Front-load aggressively
If you've been pruning your tool catalog or trimming your few-shot examples to save tokens, stop. Once those tokens are cached they cost close to nothing. Send more examples. More tool definitions. More constraints. More retrieved context. The richer the cached prefix, the better the agent behaves and the more value you get from every subsequent call. Prompt-trimming advice from 2023 now makes your agent both slower at the task and more expensive to run.
03. Append, don't rewrite
When the conversation grows, append new turns to the end of the existing prompt. Don't rebuild the message array from scratch with a summarization step in the middle. Every byte that shifts breaks the cache from that point forward. Compaction is a real escape hatch when the context fills up, but every compaction event is a cache reset. Time them like a database vacuum.
04. Use the longest cache TTL the provider offers
Anthropic offers 5-minute and 1-hour cache TTLs. OpenAI's caching is automatic with shorter implicit windows. If your agent fires bursts of calls within the TTL, you ride the cache. If your agent fires one call every two minutes, you pay cache writes for prefixes that already expired. Architect your batching to fit inside the TTL window. If the batches don't fit, the cache is buying you nothing.
05. Measure cache hit rate, not raw tokens
Token count is the wrong cost metric. Cache hit rate is the right one. Both providers return it per call. Anthropic via cache_read_input_tokens, OpenAI via prompt_tokens_details.cached_tokens. Put it on your dashboards. A 90% hit rate makes a 100K-token prompt feel like a 10K-token one. If your team is still tracking tokens-per-turn as a north-star efficiency metric, the dashboards are misleading you.
None of this is an exotic optimization anymore. It's how Claude Code, Codex, Cursor, and most modern coding agents are built. They send big prompts because big prompts make the agents better, and caching makes big prompts cheap. The agents that aren't doing this look worse on every axis: more expensive, less capable, slower to respond.
The mental model shift
The old mental model treated the prompt like a payload. You paid for what you sent. Optimization meant compression.
The new mental model treats the prompt like a working set. You pay full price once to load it. Then you pay 10% to read from it on every subsequent turn. Optimization means stability, not size. The agent that thrashes its working set every turn pays the most. The agent that pins it and appends the diff pays the least.
If you've ever optimized a hot loop on a CPU, you know the shape. The textbook lesson was to keep your working set in L1 cache and stream the variable data through. That same pattern is now playing out in agent prompts. The hot path moved from “minimize bytes” to “maximize locality.”
Sub-theme: The eval pipeline doesn't get the cache discount
One thing the math above doesn't say out loud. It assumes you're paying for the model that generated the trace. The moment you start evaluating those traces with a separate judge model, the cache discount goes away. Your evaluator calls a different model with a different prompt and a different system header. The provider's cache, the one you spent five tips engineering for, doesn't apply.
The harness that wins on the model bill loses on the eval bill. And the gap grows as context windows get bigger. That's exactly the direction the rest of this post is telling you to grow them.
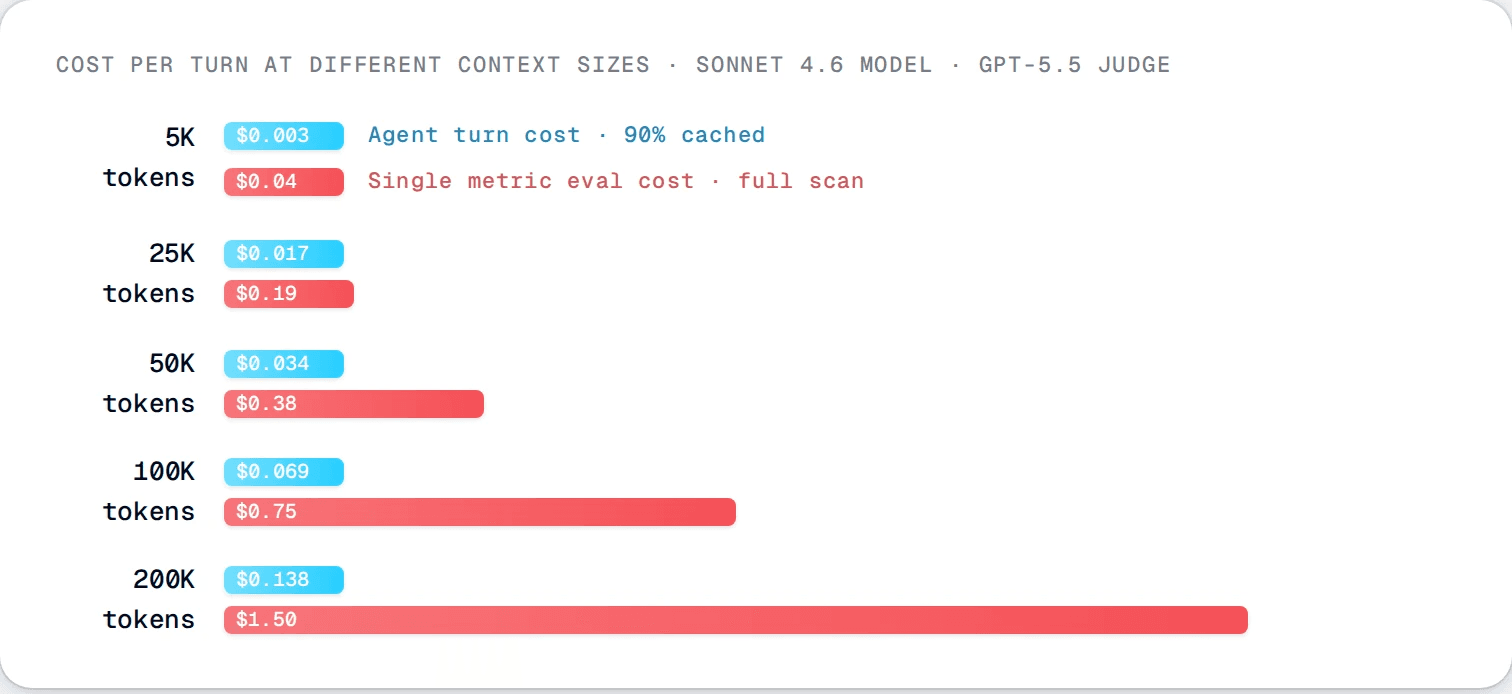
Per-turn cost at five different context window sizes. The model bill grows slowly because cache reads carry most of it. The eval bill grows fast. The evaluator pays full input rate on every byte. At 200K tokens, evaluating one turn costs more than running ten turns of the model itself. Bigger context windows make the evaluator-architecture decision matter more, not less.
The 67.6K-token Claude Code turn that costs 2¢ to generate costs about 51¢ per metric to evaluate at frontier judge rates. The 18.5K-token OpenClaw turn that costs 6¢ to generate costs about 14¢ to evaluate. The cheapest agent in your fleet just became the most expensive thing to instrument.
There are three ways out. You can roll a custom evaluator that scans only fresh deltas. It works, but it's real engineering work. You can sample 5% of traffic and accept a 95% blind spot. Cheap, but it defeats the point of evaluating production. Or you can switch the judge to an SLM-based evaluator (we built one called Luna at $0.12 per million) where the cache architecture stops mattering because the per-token rate is small enough that scanning the full context is fine.
The deeper point is that evaluators built before caching landed are not architected for the world caching produced. Most of the eval frameworks shipped pre-2024 still scan full prompts the way the models do, charging frontier rates for the privilege. That's its own post. There's a calculator for the cost math here.
What this changes
If you're currently writing agents and you're not aggressively caching, your costs are higher than they need to be by 3× to 5×. Not because you're picking the wrong model. Because your prompts are the wrong shape.
If you're benchmarking agent providers and you're using “tokens per turn” as your efficiency yardstick, you're measuring the wrong thing. The agent that sends 200K tokens at a 95% hit rate is more efficient than the one sending 20K tokens at a 25% hit rate. By a lot. Cache hit rate dominates token count.
If you're writing eval pipelines and you're scanning the full prompt every turn, you're paying for the cache that someone else got the discount on. There's a cleaner way to do that, and it doesn't involve sampling.
The quiet implication
Caching changed the per-call math in 2024. The next thing it's going to change is what we mean by “small” and “large” agents. The size of an agent's working set isn't a cost anymore. It's a capability budget. The agents that pin 200K tokens of reference material and run fast queries against it are already starting to feel different from the agents that rebuild context every turn. The bills tell the same story before the user does.
The math is what it is. The engineers who recalibrate first build the cheaper, smarter agents.
Methodology
17 Claude Code sessions and 113 OpenClaw operator sessions parsed from local ~/.claude/projects/ and OpenClaw session logs. 37 Codex atomic ticket rollouts parsed from /Users/airlock/.codex/sessions/. Heartbeat and cron-trigger sessions filtered out. Cost figures computed at Claude Sonnet 4.6 rates ($3 input, $15 output, $0.30 cache read). Aggregation script: measure_sessions.py.
Cache pricing references: Anthropic prompt caching, OpenAI prompt caching.

Paul Lacey