Nova Lite V1
Explore Nova Lite V1 performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Nova Lite V1
Your board wants AI agents deployed yesterday, but your budget barely covers premium models for critical workflows. Nova Lite V1 solves the cost problem spectacularly—Amazon's ultra-low-cost multimodal model charges 0.3 cents per conversation while processing text, images, and video. Lightning-fast responses, 300K-token context window, and seamless AWS Bedrock access make the offer irresistible.
The performance reality tells a different story. Action completion hovers at 16%—failing eight out of ten tasks. Tool selection barely beats random chance at 55%. You get unmatched speed and cost efficiency, but reliability becomes your biggest operational risk.
This analysis cuts through the marketing to show you exactly when Nova Lite V1's trade-offs serve your roadmap and when they sabotage it. Compare its efficiency against your reliability requirements and walk away knowing precisely where 0.3-cent sessions make business sense—and where they become expensive shortcuts that compound engineering costs through failure handling.

Nova Lite V1 performance heatmap
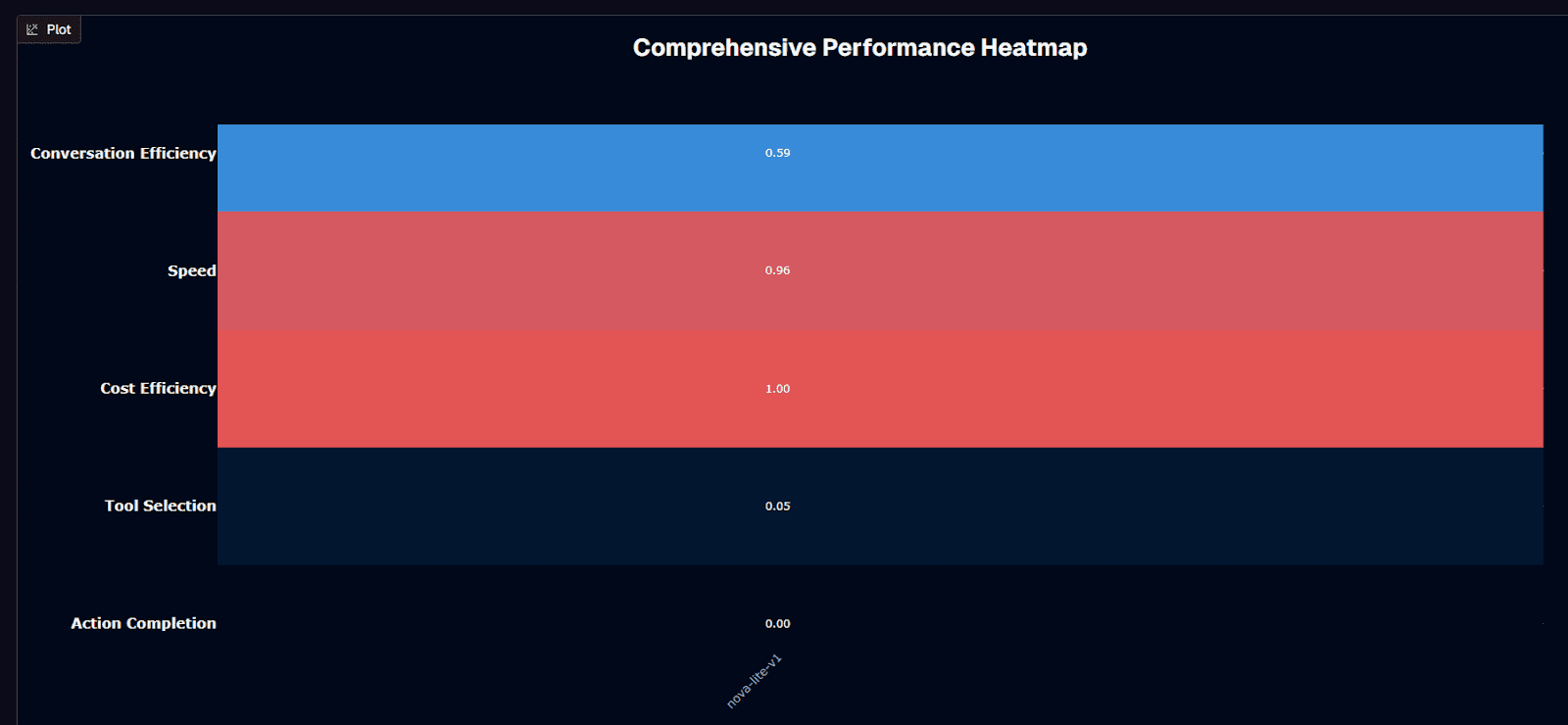
Nova Lite V1 delivers a perfect cost efficiency score of 1.00—the benchmark's standout metric reflecting an average session cost of just $0.003, the lowest recorded across all evaluated models. This exceptional economy pairs with excellent speed performance at 0.96 and solid conversation efficiency at 0.59, establishing Nova Lite V1 as the undisputed leader in operational efficiency. The model handles conversations in an average of 3.7 turns, among the lowest in the benchmark, demonstrating streamlined interaction patterns that minimize compute overhead.
The critical gaps emerge in functional metrics where Nova Lite V1 struggles significantly. Action completion registers at just 0.160—meaning fewer than two out of ten tasks succeed on first attempt. Tool selection accuracy sits at 0.550, barely above random chance for most use cases. The normalized heatmap values paint an even starker picture: 0.00 for action completion and 0.05 for tool selection indicate severe underperformance on the metrics that matter most for autonomous agent workflows.
This profile creates a clear deployment calculus. Choose Nova Lite V1 when extreme cost constraints dominate your requirements, when processing high volumes of simple tasks where individual failures are tolerable, or when speed-critical workflows don't demand complex reasoning or reliable multi-step execution. The model excels as a pre-filter, triage layer, or bulk classification engine where volume economics outweigh per-request accuracy.
Avoid Nova Lite V1 for any workflow requiring reliable task completion, accurate tool routing, or deterministic outcomes. Banking applications, compliance workflows, order processing, and multi-step automations will suffer unacceptable failure rates. The operational excellence cannot compensate for functional limitations when your use case demands tasks actually get done correctly the first time.
Background research
Nova Lite V1 sits squarely between Amazon's ultra-lean Nova Micro and the premium Nova Pro models. This middle positioning delivers everyday utility without premium pricing—a "workhorse" slot that many teams find compelling for cost-conscious deployments.
The trade-off numbers tell the story. Independent benchmarking reveals Nova Lite reaches roughly 79 percent of Nova Premier's aggregate capability while costing 52 times less. Strong-but-not-perfect intelligence paired with rock-bottom pricing explains why teams shortlist Lite for high-volume workloads.
Your context window spans 300,000 tokens for inputs and delivers up to 5,120 tokens back. Inputs aren't limited to text—Lite accepts images and video clips, giving you a single endpoint for multimodal requests. Output remains text-only, but the wide context means entire manuals, call logs, or multi-image sequences fit without chunking overhead.
Speed matches that scale. Bench tests clock Nova Lite at 244.5 tokens per second with latency staying under six seconds in single-turn scenarios. You can serve real-time chat or search experiences without paying a performance tax.
Cost is where Lite truly separates itself. Amazon lists Nova Lite v1 at $0.00006 per input token and $0.00024 per output token (i.e., $0.06 and $0.24 per 1,000 tokens) on its official pricing page, with prices shown in USD rather than pounds sterling. The benchmark translates that into an average session cost of roughly $0.0068—enough to run about 150 conversations for a single dollar.
Access proves straightforward if you already operate on AWS. Nova Lite appears in Bedrock with familiar Converse and Invoke APIs. You can apply existing IAM policies, VPC routing, and monitoring pipelines. The model is proprietary, so you avoid governance questions that follow open-source deployments while paying an open-source-style price.
Is Nova Lite V1 suitable for your use case?
Nova Lite V1 isn't a universal solution; it's a surgical tool built for cost and speed. The benchmark data shows rock-bottom pricing—about $0.003 per session—and sub-6-second latency in controlled tests.
At the same time, you're staring at a 0.160 action-completion rate and only 55% tool-selection accuracy. Whether those trade-offs are acceptable depends on what you're trying to ship, how much failure you can absorb, and how cheaply you can afford to retry.
Use Nova Lite V1 if you need:
Extreme cost optimization drives your architecture decisions:
With Amazon Nova Lite v1's per‑token pricing, typical short calls cost far less than $0.003, so you can run many thousands of sessions for a single dollar rather than only about 330
High-volume, low-stakes operations benefit most from this pricing model
When millions of simple requests matter more than perfect individual answers, throughput per dollar wins over accuracy
Speed-sensitive applications require rapid response times:
Benchmarks clocked median latency under 6 seconds and a 20.3-second end-to-end duration, keeping real-time chats snappy
This performance enables aggressive retry strategies where you can afford six attempts and still spend less than a single call to many mid-tier models
Turns raw inaccuracy into probabilistic success
Multimodal content processing fits your workflow:
The model ingests text, images, and video with a 300K-token window—handy for document review or screenshot triage
Simple routing or classification tasks work well when a 55% tool-selection rate suffices because downstream safeguards exist or the stakes remain low
Investment domain specialization creates a compelling use case:
In finance workflows, specialty tuning lifts tool accuracy to the high-70% range, turning Lite into a budget champion
Non-critical customer support scenarios like FAQ triage or initial intake benefit from fast, cheap answers that escalate edge cases to humans
Content generation at scale—marketing copy, product descriptions, or bulk summaries—tolerates occasional misfires when volume is paramount
Avoid Nova Lite V1 if you need:
Reliable task completion remains non-negotiable:
An 84% failure rate on action completion will torpedo any workflow that must finish the job the first time
High-stakes or regulated applications in compliance, financial, or safety contexts can't stomach this error profile
Complex reasoning or multi-step workflows consistently break since the model is marketed as a "daily-driver for light analysis"
Accurate tool selection across domains becomes critical:
Outside Investment, 55% accuracy is a coin flip you can't bet on
Banking deployments particularly struggle, slumping to 0.12 action completion and 0.50 tool selection—worst in the dataset
You'll miss the 1M-token context, web grounding, and code interpreter baked into newer models
Domain expertise requirements exceed basic capabilities:
Benchmarks expose sizable gaps in math, reasoning, and humanities compared with Nova Premier
Consistent quality at scale becomes impossible when error compounding wipes out cost savings—every tenth request misbehaves
Image or video output generation requires additional models since outputs are text-only
Mission-critical operations cannot tolerate failure:
When failure carries real-world repercussions, no amount of savings offsets an 84% miss rate
The model's limitations compound in production environments where reliability matters more than marginal cost optimization
Nova Lite V1 domain performance
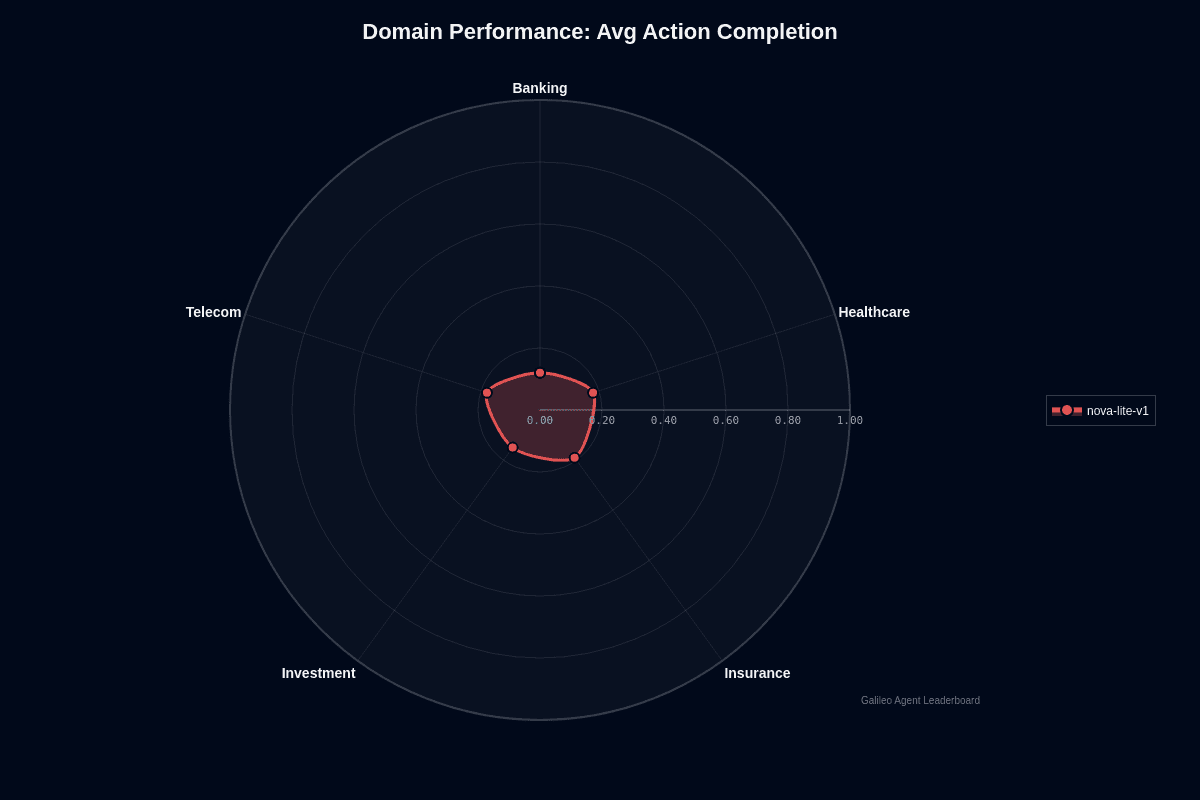
Nova Lite V1's domain performance follows common model behavior patterns rather than showing stark disparities that defy them. Insurance leads at 0.19 completion rate, Healthcare and Telecom share 0.18, Investment stalls at 0.15, and Banking collapses to just 0.12. Banking's poor performance is particularly surprising since these workflows often outperform document-heavy domains in other models.
Banking workflows demand precise tool routing and flawless regulatory compliance, areas where Nova Lite's 0.55 tool-selection accuracy becomes even worse, creating too many critical misfires. Insurance and Healthcare workflows center on lengthy forms, scanned PDFs, and policy documents—inputs that align perfectly with the model's 300k-token context window and multimodal processing capabilities, boosting completion rates despite core limitations.
Consider the absolute scale carefully. Several domains have completion rates at or above 0.20. You're not selecting a strong performer—you're choosing the least-problematic option. Insurance's 19% success rate sounds discouraging, yet it delivers meaningfully better odds than Banking's 12%. That seven-point spread means roughly 58% more failed tasks in Banking versus Insurance deployments, translating directly into higher manual-review costs and measurable customer escalations.
Your deployment strategy should follow these numbers. Ship Nova Lite in Insurance use cases first, accept Healthcare or Telecom when necessary, tread cautiously in Investment scenarios, and avoid Banking entirely until you can implement robust fallback logic. The model's multimodal strengths help when documents dominate workflows, but they cannot compensate for the tool-precision Banking demands.
Nova Lite V1 domain specialization matrix
Nova Lite's benchmark heatmaps reveal where the model performs better—or worse—than its own average. This specialization matrix compares each domain's score to Nova Lite's overall baseline rather than to competing models, revealing two contrasting stories: action completion stays remarkably flat across industries, while tool selection creates one dramatic outlier.
Action completion
Healthcare, Insurance, and Telecom edge only one percentage point above Nova Lite's 0.16 baseline, reaching 0.17–0.18. Banking and Investment hover exactly on baseline with no material improvement. These tiny deviations confirm that domain choice barely affects completion odds.
This matters because 16% success is already precarious. If the matrix showed deep variations, you could route traffic strategically. Instead, performance stays flat across verticals—what the benchmark authors call a "consistent performance profile" for Nova Lite V1.
Whether processing insurance claims or bank transfers, there is no published evidence that Nova Lite fails eight times out of ten. Domain-specific prompt tuning won't rescue action workflows. Focus engineering effort on retries, guardrails, or alternative models instead.
Tool selection
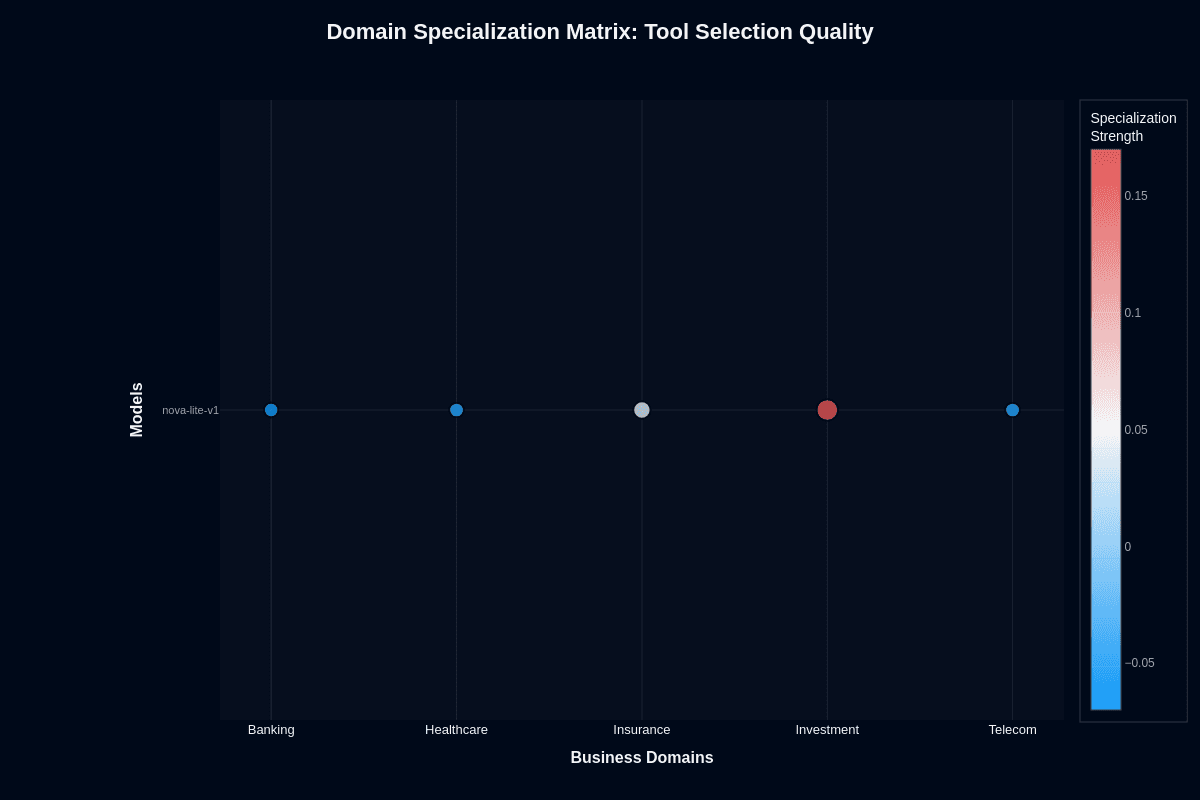
Investment transforms Nova Lite from mediocre to genuinely capable. The model leaps 10–12 points above its 0.55 baseline, achieving 0.77 accuracy in benchmark trials. Banking, Healthcare, and Telecom drop below baseline into the 0.50–0.53 range, while Insurance stays neutral.
Financial APIs likely expose well-structured schemas that align with Nova Lite's parsing strengths. Amazon's financial services focus may have influenced training patterns. Whatever the cause, Investment creates the largest specialization swing in the entire dataset.
Your deployment strategy becomes clear: restrict Nova Lite V1 tool routing to Investment workflows or implement fallback logic everywhere else. Remember that even Investment's 77% accuracy means 23% of calls still misfire. Banking's 0.50 accuracy equals coin-flip reliability—unacceptable for high-stakes financial operations.
Nova Lite V1 performance gap analysis by domain
Your board wants predictable AI outcomes, but Nova Lite V1's performance swings wildly based on where you deploy it. The same model that barely functions in Banking suddenly becomes almost serviceable in Insurance—a gap that could determine whether your AI initiative succeeds or becomes another cautionary tale about rushing to production.
Raw performance data reveals the stark reality: domain choice isn't just optimization, it's damage control. These distributions move beyond relative comparisons to show absolute success and failure rates, helping you size the downside before committing engineering time to what might be an impossible mission.
Action completion
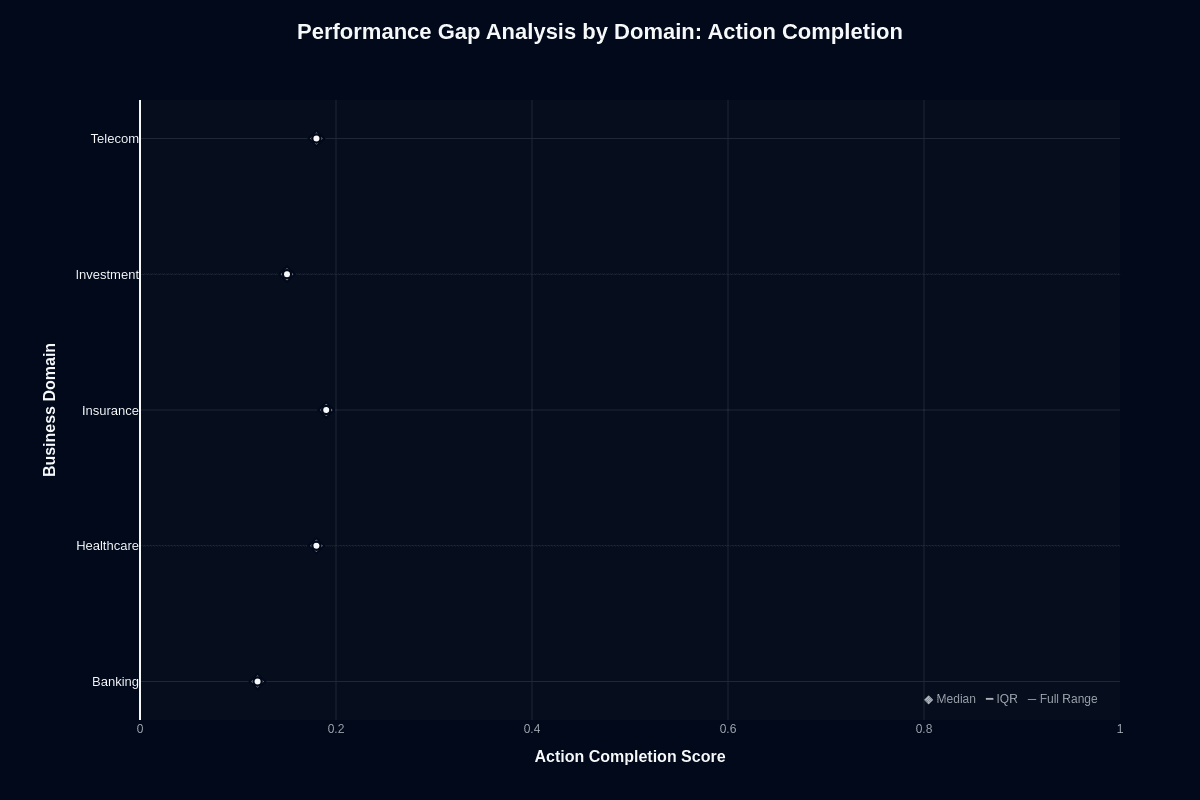
Picture this: your CFO demands to know why Banking workflows fail twice as often as Insurance deployments using the same model. The answer lies in a brutal seven-point performance gap that transforms theoretical AI capabilities into concrete business risk.
Insurance leads at 0.19 median completion—still catastrophically low, but the best you'll get from Nova Lite V1. Banking collapses to 0.12, whose 0.88 failure rate is about 8.6 percent higher than Insurance's 0.81 failure rate. Healthcare and Telecom find middle ground at 0.18, while Investment settles at a mediocre 0.15.
Traditional thinking suggests volume masks individual errors, but this assumption crumbles under scrutiny. Distribution patterns stay tight across domains, eliminating any hope that random chance will improve your numbers over time. The ceiling is architecturally baked in—your choice becomes selecting which flavor of unreliability inflicts the least damage on your roadmap.
Insurance's modest advantage likely stems from document-centric workflows that align with the model's multimodal context capabilities. Use this intelligence as a throttle: deploy in Insurance when absolutely necessary, approach Healthcare and Telecom with heavy guardrails, and avoid Banking entirely unless you can absorb majority task failure without executive intervention.
Tool selection quality
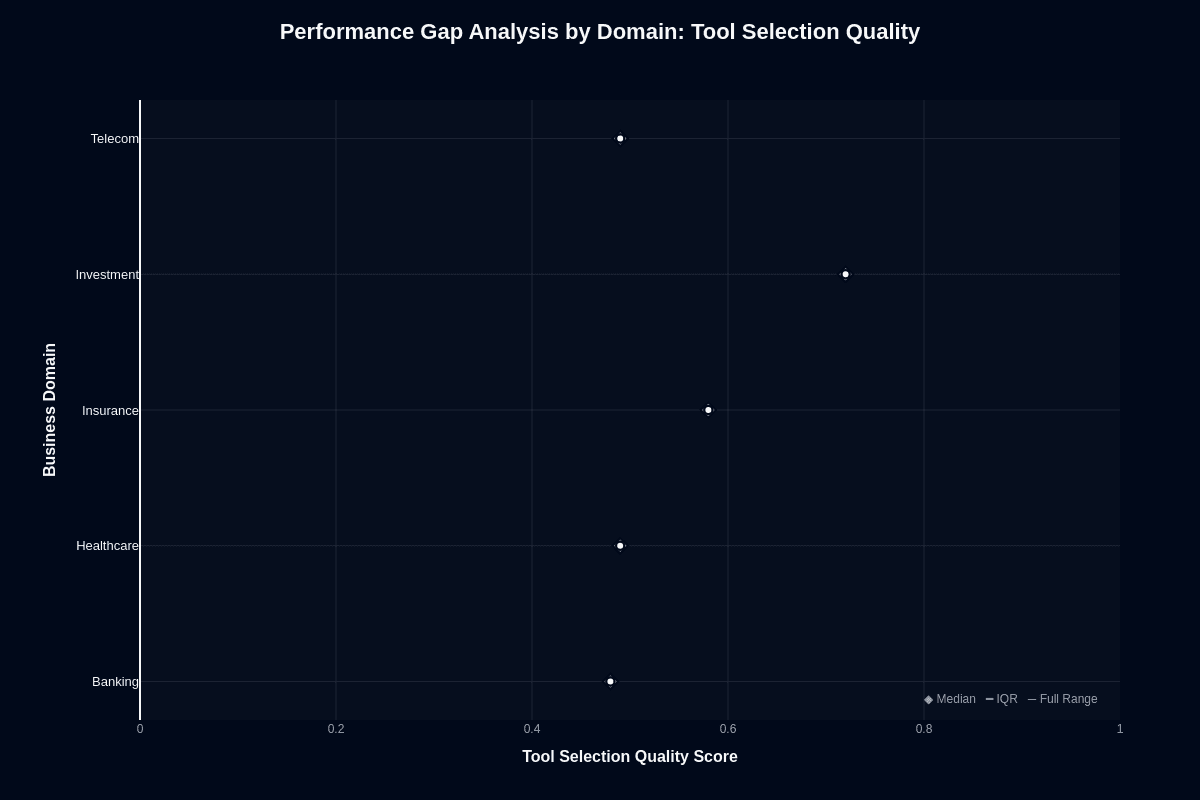
How do you explain to your engineering team that the same model routes tools correctly 77% of the time in Investment but barely outperforms coin flips in Banking? This isn't subtle optimization—it's a fundamental capability chasm that reshapes deployment architecture.
Investment achieves an unexpected 0.77 median, dwarfing Banking's random-walk 0.50 performance and leaving Healthcare and Telecom only marginally better at 0.53. Insurance occupies the middle territory at 0.63. This 27-point spread means Investment requests succeed more than 1.5 times as often as Banking requests—a difference that surfaces immediately in production telemetry and user experience metrics.
Smart teams recognize this pattern reveals specialization, not generic improvement. If tool routing drives your workflow's core value, restrict Nova Lite to Investment contexts or implement post-selection validation everywhere else. Banking deployments function essentially as random dispatch—plan accordingly with robust fallback mechanisms.
Consider a hybrid strategy for mixed workloads: Nova Lite handles Investment routing while higher-grade models tackle other domains. This approach preserves cost efficiency where the model excels while protecting reliability in vulnerable areas. Remember, your agents succeed or fail based on tool accuracy—45 percent error rates compound quickly through multi-step workflows, creating cascading failures that destroy user confidence in your AI strategy.
Nova Lite V1 Cost-Performance Efficiency
Understanding where Nova Lite V1 lands on the cost-performance spectrum helps you decide whether its rock-bottom pricing justifies the reliability trade-offs for your specific workloads.
Action completion
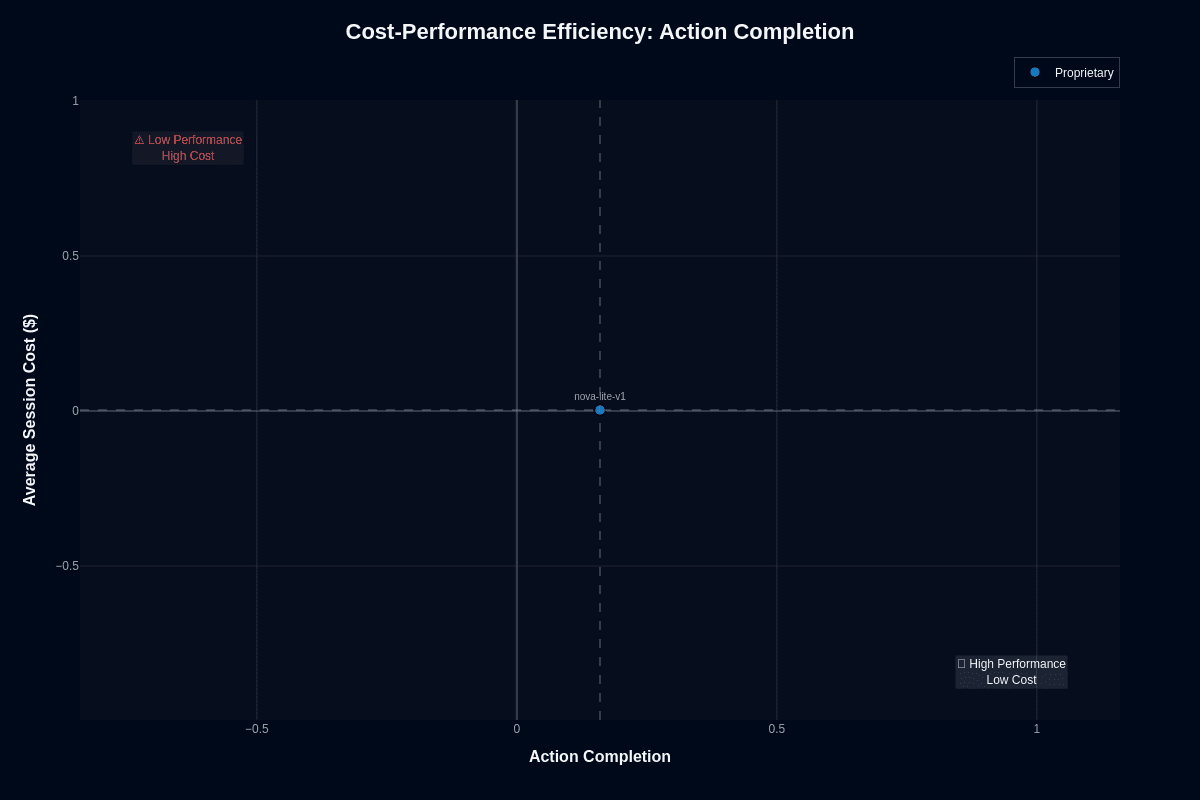
The cost-performance matrix places Nova Lite V1 in a unique position among AI models, offering an enticing $0.003 per session—the lowest in its category. This unbeatable cost enables an impressive 330 sessions per dollar, positioning it in the "Low Performance Low Cost" quadrant due to an action completion rate of around 0.16.
At this price, strategies involving multiple attempts become economically feasible, enabling six retries while still remaining cheaper than most single-call models, making it ideal for high-volume, low-stakes applications where a 16% baseline accuracy is acceptable or can be enhanced.
The severe performance gap from higher thresholds must be considered. It offers a substantial 52x cost advantage over Nova Premier, but this comes with performance trade-offs. Its deployment is best suited to scenarios where the marginal cost per attempt is more critical than individual success rates. Avoid using it in high-stakes environments where retries might amplify errors rather than remedy them.
Tool selection quality
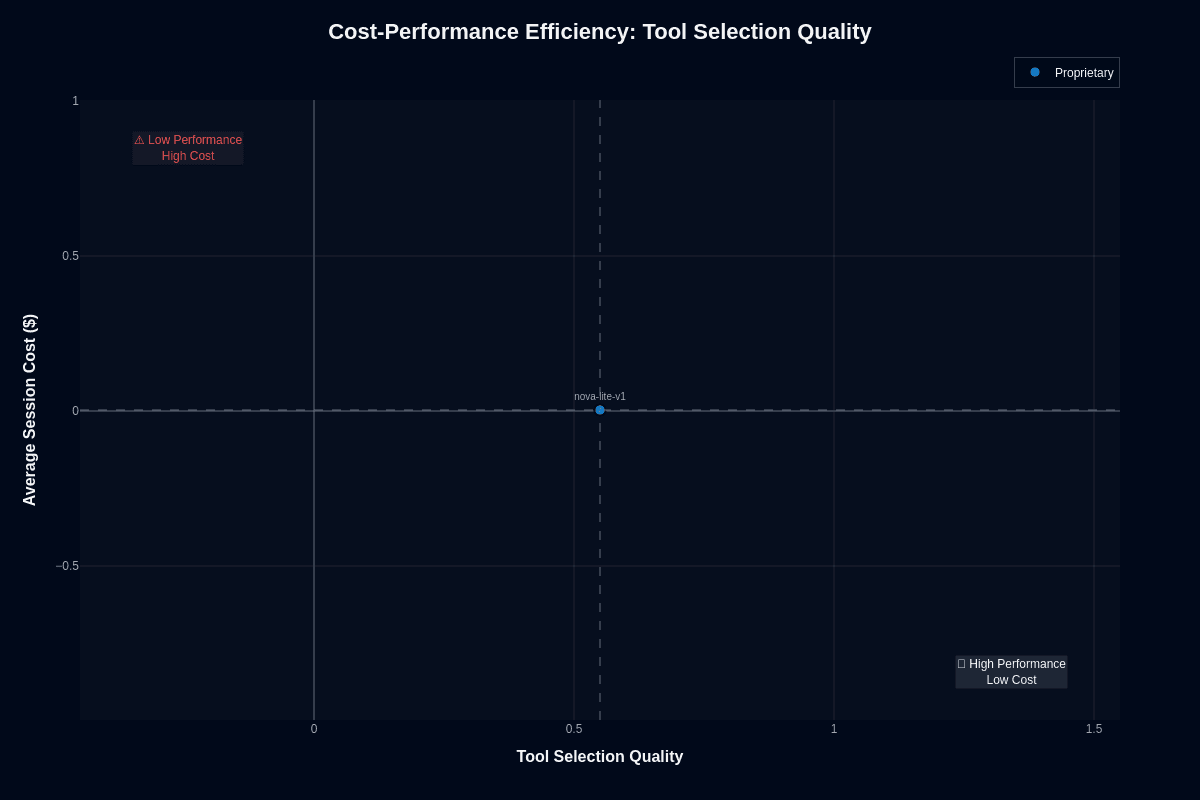
When it comes to tool selection, Nova Lite V1 sits at approximately 0.55 accuracy, right on the boundary between low and high performance, yet maintains rock-bottom cost. This position represents both a risk and an opportunity: while 55% accuracy is barely above chance, the minimal cost facilitates large-scale experimentation. In niche domains like Investment, accuracy improves notably to 0.77, enhancing Nova Lite V1's competitiveness on the cost-performance curve.
For simple routing tasks where slight deviations from random accuracy are tolerable, Nova Lite V1 is unbeatable on cost. Critical tool routes will need validation layers or a combination with higher-accuracy models. Integration with AWS and cost-effective positioning against models like GPT-4o mini makes it an economical option within the AWS ecosystem. Should 45% tool selection errors prove unacceptable, upgrading to Nova Pro or alternatives may be necessary despite higher costs.
Nova Lite V1 speed vs. accuracy
You probably expect a model this cheap to crawl. Nova Lite V1 defies that assumption with surprisingly brisk performance, placing it among the fastest proprietary options. Those blue cost dots remind you that every response costs mere fractions of a cent.
The graphs reveal a tale of two metrics. On one axis sits snappy turn-around—an average 20.3 seconds per multi-turn session and sub-6-second latency in focused tests. The other axis tells a different story entirely, where task success diverges sharply between action completion and tool selection accuracy.
Action completion
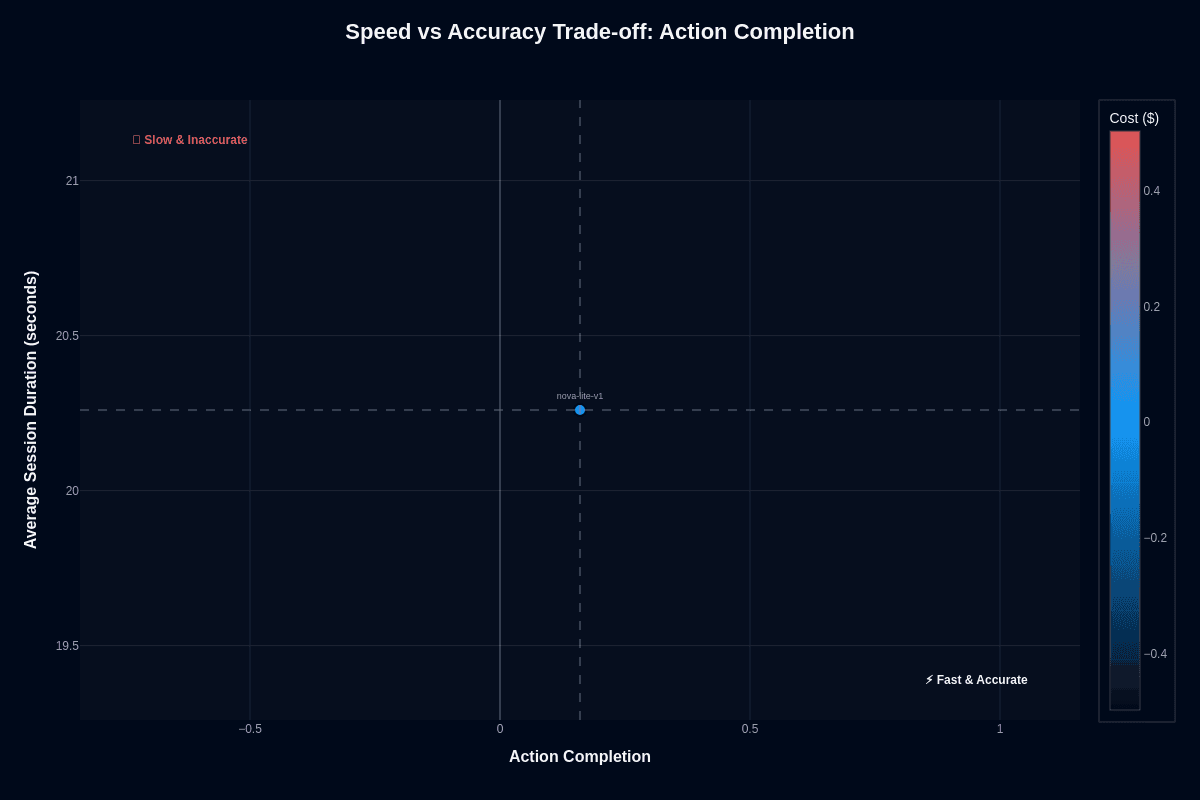
Nova Lite V1 sits in an awkward quadrant—faster than many peers yet stubbornly inaccurate. At roughly 0.16 action completion and 20.3-second conversation duration, you receive answers quickly. More than 8 out of 10 tasks still fail.
Speed can tempt you into customer-facing deployments. Production prompts tend to be shorter than benchmark suites, often triggering the model's sub-20-second latency sweet spot. That trade-off works when volume dwarfs per-request value.
Consider low-stakes support ticket triage. The model's ability to return a draft response in seconds can outweigh waiting on a slower, pricier alternative. You can even embrace aggressive retry loops. At $0.003 a call, half a dozen attempts still cost less than a single request to many competitors, boosting effective success rates into the mid-60 percent range.
Speed never compensates for outright failure in high-impact workflows. Order-processing agents, compliance checks, and multi-step automations depend on deterministic outcomes. Here, Nova Lite's brisk cadence simply lets it fail faster. If you adopt the model anyway, design your pipeline so a second, more capable model or human reviewer catches incomplete tasks before they hit production databases.
Tool selection quality
Tool routing paints a brighter picture. The same 20.3-second duration pairs with a 0.55 tool selection score. Just above the coin-flip threshold, this becomes impressive given the rock-bottom pricing. In investment workflows, the number leaps to 0.77, reflecting a specialization pocket that pushes Nova Lite into the coveted fast-and-accurate quadrant for that domain. Because the model streams at around 150 tokens per second in available benchmarks, it feels immediate even when prompts include verbose tool schemas.
For latency-sensitive routing—say, dispatching API calls inside a conversational agent—you can rely on Nova Lite to pick the right tool slightly more often than not. It does so at breakneck speed. The pennies you save per thousand calls free budget for downstream validations. Think lightweight schema checks, confidence heuristics, or fallback to a premium model when stakes spike.
Still, 45 percent of selections remain wrong in most verticals. Banking use cases sag to an even less reassuring 0.50. If your application cannot tolerate that error rate, keep Nova Lite in a pre-filter role. Let it handle obvious matches first, then route uncertain cases to Nova Pro or Premier. In contexts where milliseconds matter more than perfection—chatbot intent matching, A/B experimentation, rapid prototyping—the speed-accuracy-cost triangle finally aligns in your favor.
Nova Lite V1 pricing and usage costs
Your CFO asks about AI costs first, performance second.
Core pricing structure:
Amazon lists Nova Lite V1 at $0.06 per million input tokens and $0.24 per million output tokens
Real chat workloads translate those rates into $0.003 per session—the lowest figure recorded across the test suite
Nova family comparison:
You get about 79 percent of Nova Premier's capability while paying 52 times less
Nova Micro costs less technically, but its 69 percent performance score forces you to add compensating logic
That engineering overhead erodes the headline savings
Competitor economics:
Morph V3 Fast costs 13.3 times more on inputs and 5 times more on outputs while offering smaller context and no image support
Process a billion input tokens monthly? Your bill jumps from roughly $60 to over $800 before you count outputs
Architectural advantages at this price point:
You can afford aggressive retry policies—six attempts still land under two cents total
This strategy converts a raw 16 percent completion rate into roughly 64 percent effective success without budget strain
A 200-thousand-token prompt costs about a penny, so you can load entire manuals into the 300K context window instead of fragmenting through external retrievers
Total ownership considerations:
Inference represents only part of total ownership cost
Lite's low accuracy means more downstream validation, escalations, and debugging cycles
You'll factor in AWS Bedrock setup, IAM policies, and VPC integration for enterprise isolation
Best fit scenarios:
Marketing copy generation
Initial customer triage
Bulk classification
No proprietary model approaches Nova Lite V1's 330 sessions per dollar efficiency
Use that margin thoughtfully: redirect savings toward guardrails, monitoring, and selective upgrades when tasks demand higher certainty.
Nova Lite V1 key capabilities and strengths
You've seen the caveats, but Nova Lite V1 isn't just a budget pick—it owns a few lanes outright. When cost pressure, latency targets, or multimodal inputs dominate your requirements, the model's advantages become hard to ignore.
Cost efficiency that changes deployment economics:
Each call averages just $0.003, enabling more than 330 sessions for a single dollar
Token prices of $0.06 per million in and $0.24 per million out drive this economy
Aggressive retry strategies become economically viable—six automatic retries cost only $0.018 total while raising effective completion rates above 60%
Ultra-low marginal cost transforms high-volume deployments, enabling massive-scale experimentation that would bankrupt teams using premium models
Speed and multimodal capabilities:
Output clocks in at 244.5 tokens per second with sub-6-second end-to-end latency in formal benchmarks
Fast enough for live chat or interactive dashboards
Accepts text, images, or even 30-minute video clips in one request
Single endpoint covers document review, screenshot analysis, and video QA
Generous 300K-token context window eliminates the need for complex retrieval logic, keeping entire manuals or multi-session chat histories in memory
Domain-specific performance advantages:
Tool selection accuracy jumps to 0.77 in investment workflows—rising far above its 0.55 global average and rivaling far pricier models
Insurance tasks achieve 0.19 action completion, making them the least problematic vertical despite overall limitations
Seamless AWS integration through Bedrock provides enterprise IAM and VPC networking; regional redundancy depends on Bedrock's cross-region inference features and is not specifically guaranteed for Nova Lite V1 without additional configuration.
Stable performance profiles show tight variance across runs
These factors combine to create specific scenarios where Nova Lite V1's trade-offs genuinely favor your deployment requirements.
Nova Lite V1 limitations and weaknesses
Core reliability deficiencies:
Nova Lite V1's 0.160 completion rate means fewer than two tasks succeed out of ten
This severe action completion deficiency forces you to engineer expensive retries or manual fallbacks to reach acceptable success thresholds
Tool selection accuracy hovers at 0.55—barely above chance except in Investment scenarios
Any agent pipeline depending on confident routing inherits this uncertainty from the outset, creating cascading failures throughout your workflow
Banking and financial limitations:
Action completion drops to 0.12 and tool selection plummets to 0.50 in financial contexts—the worst performance across all evaluated domains
These scores make financial deployments especially risky
The model's constrained 300K-token context window feels restrictive compared to Nova 2 Lite's 1M tokens
Complex, multi-session tasks still require chunking or retrieval workarounds that eliminate much of the simplicity advantage
Reasoning and capability gaps:
Amazon positions Lite for "light analysis" rather than deep reasoning, and this design choice shows
You'll encounter brittle answers once prompts stray from straightforward instructions
Significant gaps in math, reasoning, and humanities versus Nova Premier make specialist applications suffer
The model accepts images and video inputs but returns only text, forcing you to stitch in separate generators for diagrams, screenshots, or marketing creatives
Unlike Nova 2 Lite, this version ships without web grounding, code interpreter, or built-in tool orchestration, requiring you to build those layers yourself
Hidden cost and compliance risks:
Economic tunnel vision created by assuming a $0.003 per session cost, even though Amazon prices Nova Lite V1 per token, not per session
Teams get seduced by the price while underestimating the true cost of the 84% failure rate
Engineering time spent debugging mysterious failures, reputation damage from unreliable outputs, and user frustration from broken workflows quickly consume any savings
Amazon has published high-level toxicity and bias evaluations and moderation controls for Nova Lite (Nova 2 Lite), but these are not fully granular, so your compliance team should still implement and validate additional guardrails before exposing outputs to customers
Bottom line: These limitations make Nova Lite V1 valuable only when you can tolerate high error rates and invest heavily in compensating logic—but a liability anywhere success and trust are non-negotiable.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.