Qwen2.5 72B Instruct Overview
Explore Qwen2.5 72B Instruct's performance benchmarks, industry-specific capabilities, and evaluation metrics to determine if it's the right AI model for your application's requirements.

Qwen2.5 72B Instruct Overview
Alibaba Cloud's Qwen2.5-72B-Instruct enters the stage as the first fully open-source model that can actually go toe-to-toe with proprietary options for agent deployments. It sits at #7 on our agent leaderboard.
At $0.036 per average session—less than one-quarter what comparable proprietary models cost—this 72.7 billion parameter system forces you to rethink what "cost-effective" really means in your enterprise AI strategy.
Our analysis puts Qwen2.5-72B-Instruct under the microscope across five business domains and agent-specific metrics, revealing patterns that challenge what most of us assumed about open-source versus proprietary AI systems.
Check out our Agent Leaderboard and pick the best LLM for your use case

Qwen2.5 72B Instruct performance heatmap
Qwen2.5-72B-Instruct is the instruction-tuned version of Alibaba Cloud's September 2024 release, built specifically for conversation and agent workflows. The model builds on the Qwen2.5 architecture with major improvements in instruction following, structured output generation, and system prompt handling.
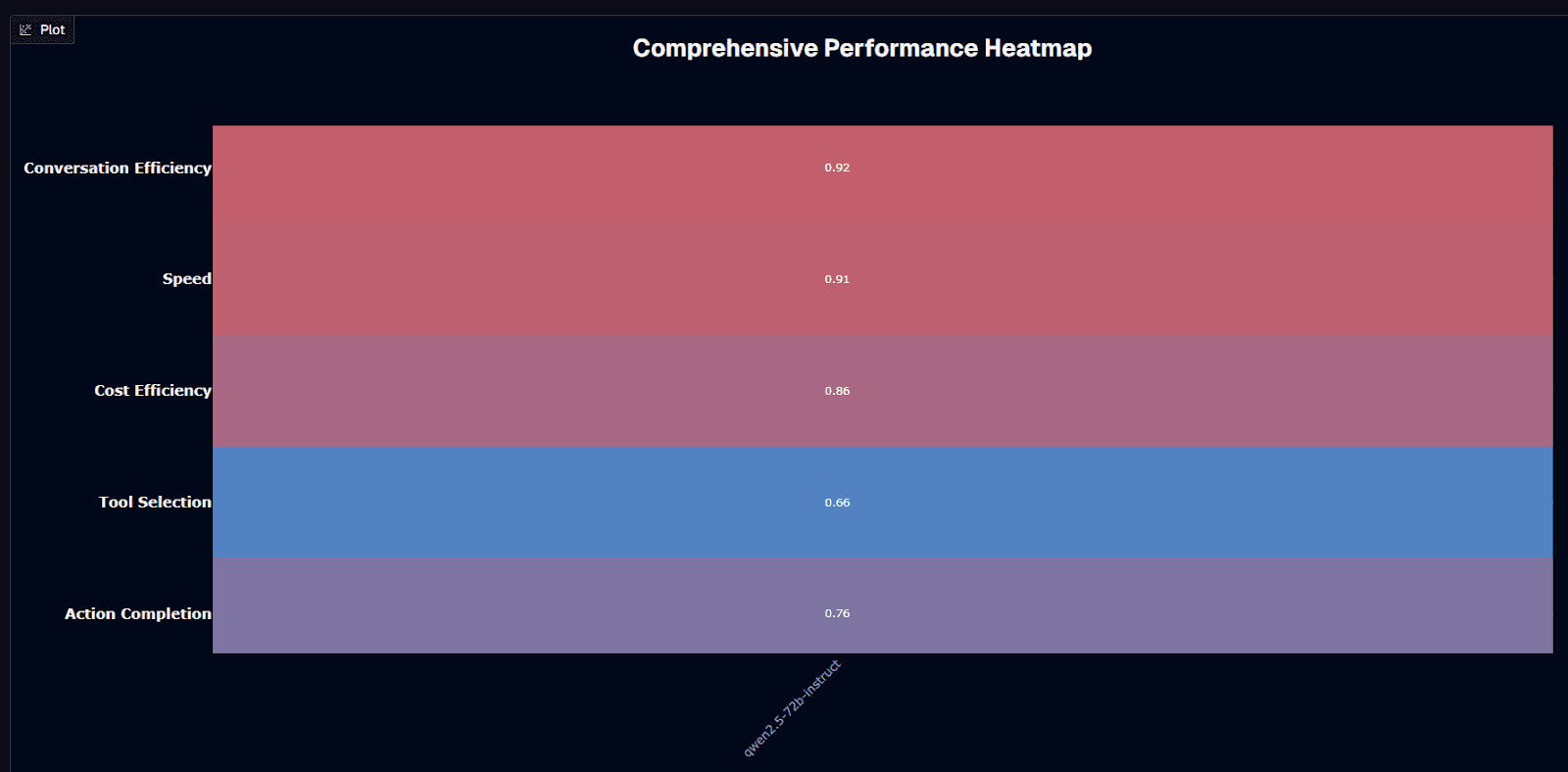
The comprehensive performance heatmap reveals Qwen2.5-72B-Instruct's strength profile across normalized dimensions.
Conversation efficiency (0.92) and Speed (0.91) show exceptional performance—the model completes your tasks rapidly with minimal iterative exchanges.
Cost efficiency (0.86) reflects the substantial economic advantages of open-source deployment for your organization.
Action completion (0.76 normalized) and tool selection (0.66 normalized) represent relative weaknesses compared to the model's efficiency metrics. These lower scores reflect mid-tier absolute performance (0.510 action completion, 0.800 tool selection) that falls short of frontier capabilities but remains functional for many of your production applications.
The heatmap pattern—strong efficiency, moderate capability—characterizes Qwen2.5-72B-Instruct as an economically optimized model rather than a capability-maximized one.
You should evaluate whether your use cases prioritize deployment economics and operational efficiency (Qwen2.5-72B-Instruct's strengths) or absolute task success rates (where proprietary alternatives lead).
Background research
Released under the Qwen Research License (non-commercial use), the model gives you deployment options you simply can't get with proprietary alternatives.
Its 128,000-token context window and support for 29+ languages make it a global-scale solution for your organization, while specialized training incorporating knowledge from Qwen2.5-Coder and Qwen2.5-Math expert models delivers domain-specific capabilities without needing explicit fine-tuning.
Qwen2.5-72B-Instruct's development includes several architectural and training innovations:
Transformer Architecture with RoPE and SwiGLU: Enhanced positional encoding through Rotary Position Embeddings (RoPE) and improved activation functions via SwiGLU enable better long-context understanding and more efficient computation
18 Trillion Token Training Dataset: Massive-scale pre-training on diverse multilingual data provides foundational knowledge spanning 29+ languages, with particular depth in Chinese and English
Expert Model Knowledge Transfer: Integration of specialized insights from Qwen2.5-Coder and Qwen2.5-Math expert models during training enhances coding and mathematical reasoning without requiring separate fine-tuning
Instruction-Tuning and Alignment: Extensive post-training optimizes instruction following, structured output generation (especially JSON), and resilience to diverse system prompts for robust chatbot and agent applications
Open Weights and Community Ecosystem: Unlike proprietary alternatives, Qwen2.5-72B-Instruct provides transparent model weights and comprehensive documentation, enabling custom deployments, fine-tuning, and research applications
Is Qwen2.5 72B Instruct suitable for your use case?
Use Qwen2.5-72B-Instruct if you need:
Maximum cost efficiency: At $0.036 per average session, Qwen2.5-72B-Instruct delivers agent capabilities at roughly 23% the cost of comparable proprietary models, making your high-volume deployments possible without breaking the bank
On-premise or custom deployment: Open weights and permissive licensing (for non-commercial use) let you deploy within your own infrastructure, meeting data sovereignty and security requirements that cloud-only models simply can't address
Healthcare domain applications: Strong specialization (0.610 action completion) makes this model particularly good for your medical documentation, patient communication, and clinical workflow automation
Rapid response times: 34.7-second average duration is the fastest execution in the competitive set, vital for your user-facing applications, where waiting means losing users
Efficient conversation patterns: Averages 2.6 turns per session, finishing your tasks with fewer back-and-forths than higher-ranked but slower alternatives
JSON and structured output generation: Enhanced training specifically for structured data handling makes this model excel at your API integration, database operations, and workflow orchestration, requiring formatted responses
Avoid Qwen2.5-72B-Instruct if you:
Work primarily in investment or banking domains: Poor performance in Investment (0.420) and below-average Banking scores (0.480) show domain knowledge gaps that might require significant RAG augmentation or fine-tuning for your financial applications
Require the highest absolute tool selection accuracy: While competitive at 0.800, tool selection quality trails leaders by meaningful margins (12-20 percentage points), potentially increasing your validation workload
Need commercial deployment rights: The Qwen Research License restricts commercial use; you must negotiate separate licensing or look at commercially-licensed alternatives for production deployment
Depend on peak action completion rates: 0.510 action completion puts Qwen2.5-72B-Instruct in mid-tier performance, suggesting your mission-critical autonomous workflows might do better with more capable alternatives despite higher costs
Face strict regulatory compliance requiring proprietary vendor support: Open-source models lack the formal SLAs, liability protections, and dedicated support channels that your regulated industry might need for production AI systems
Qwen2.5 72B Instruct domain performance
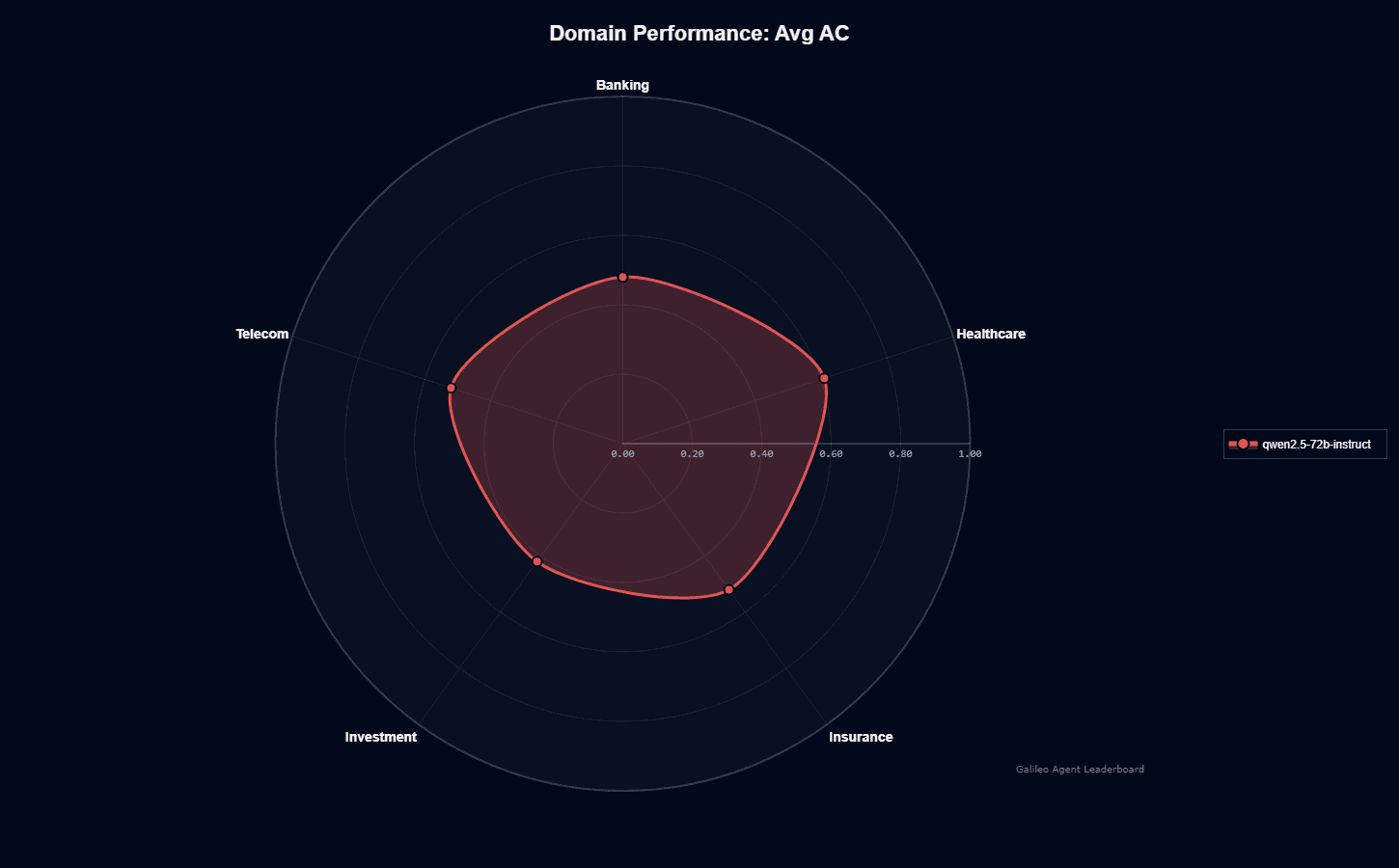
Qwen2.5-72B-Instruct shows uneven domain specialization. Healthcare clearly leads at 0.610 action completion—roughly 20% higher than its next-strongest domains. Insurance and Telecom cluster at 0.520, representing solid mid-tier performance suitable for production deployment with appropriate guardrails.
Banking lags at 0.480, showing conceptual understanding gaps in financial services workflows. Investment shows the model's weakest performance at 0.420, revealing significant limitations that would require substantial supplementary systems to overcome.
This 45% performance gap between healthcare and investment domains is among the widest we've seen in any model, pointing to highly specialized training that favors certain verticals.
If you're evaluating domain fit, your healthcare organization can get immediate value from Qwen2.5-72B-Instruct's natural strengths in medical contexts. For insurance and telecom teams, expect reliable baseline performance suitable for customer service, documentation, and operational automation.
Your banking applications will need additional prompt engineering and validation logic to make up for weaker domain knowledge. Investment firms face the steepest integration challenges, likely requiring hybrid architectures combining Qwen2.5-72B-Instruct with specialized financial models or extensive RAG systems.
Qwen2.5 72B Instruct domain specialization matrix
Action completion
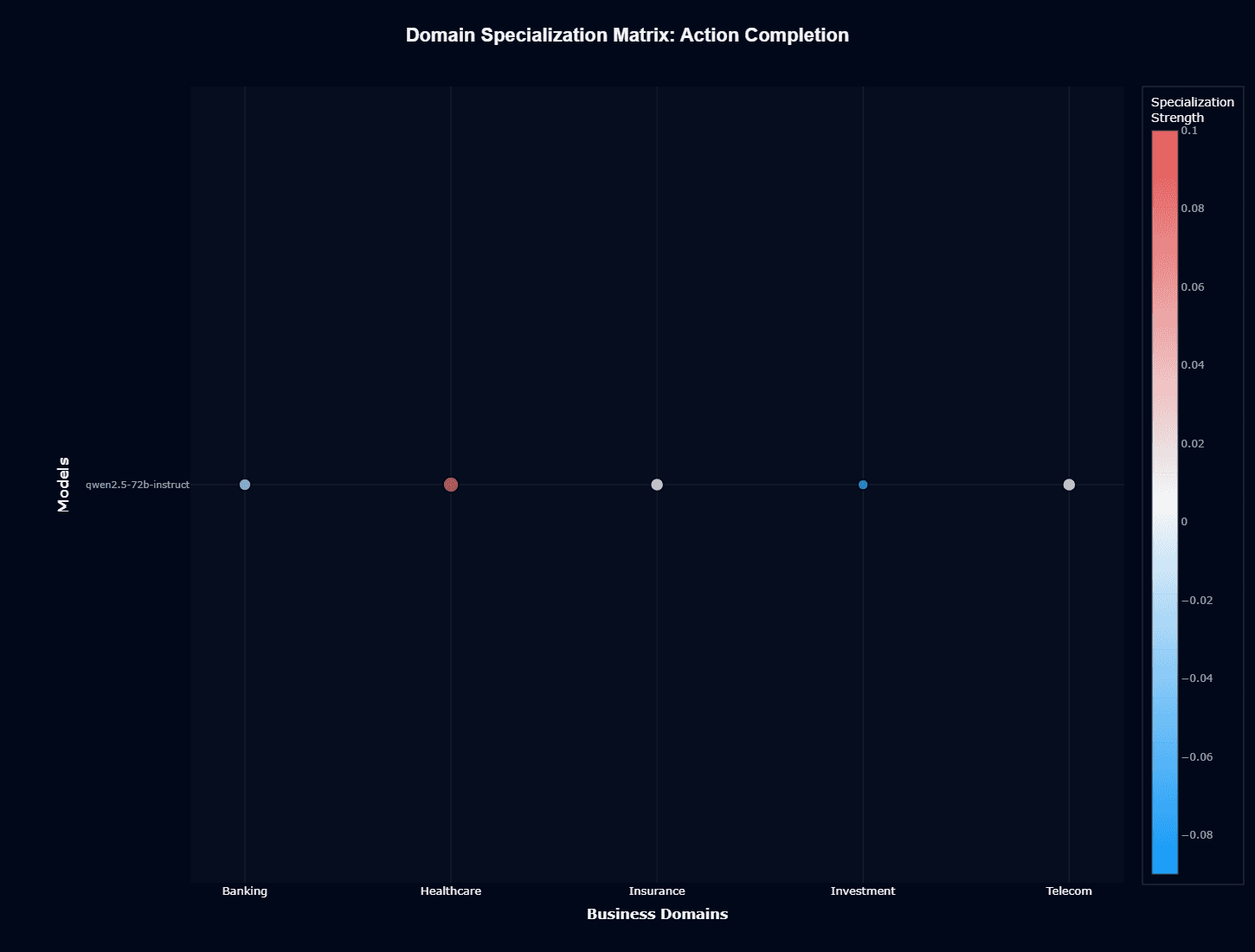
The domain specialization matrix reveals Healthcare as Qwen2.5-72B-Instruct's standout strength, showing positive specialization (red/warm color) that indicates the model performs substantially better than its baseline when completing healthcare-related actions.
This specialization aligns with the absolute performance data, confirming genuine domain expertise rather than just favorable task selection.
Investment demonstrates strong negative specialization (blue/cool color), explaining its 0.420 action completion score—the model actively struggles with financial investment concepts beyond generic weakness.
Banking also shows negative specialization, though less severe than Investment, suggesting foundational financial knowledge exists but remains underdeveloped.
Insurance and Telecom occupy neutral territory, indicating baseline performance without particular advantages or disadvantages. This neutrality makes sense given these domains' reliance on procedural knowledge and documentation patterns that transfer well from general pre-training.
For your development team, Healthcare agents can leverage Qwen2.5-72B-Instruct's natural specialization with minimal additional engineering.
Your Investment and Banking teams should anticipate significant prompt engineering effort, domain-specific fine-tuning, or hybrid architectures combining Qwen2.5-72B-Instruct with financial specialist models.
Insurance and Telecom implementations can proceed with standard integration patterns, neither benefiting from exceptional domain fit nor suffering from problematic gaps.
Tool selection quality
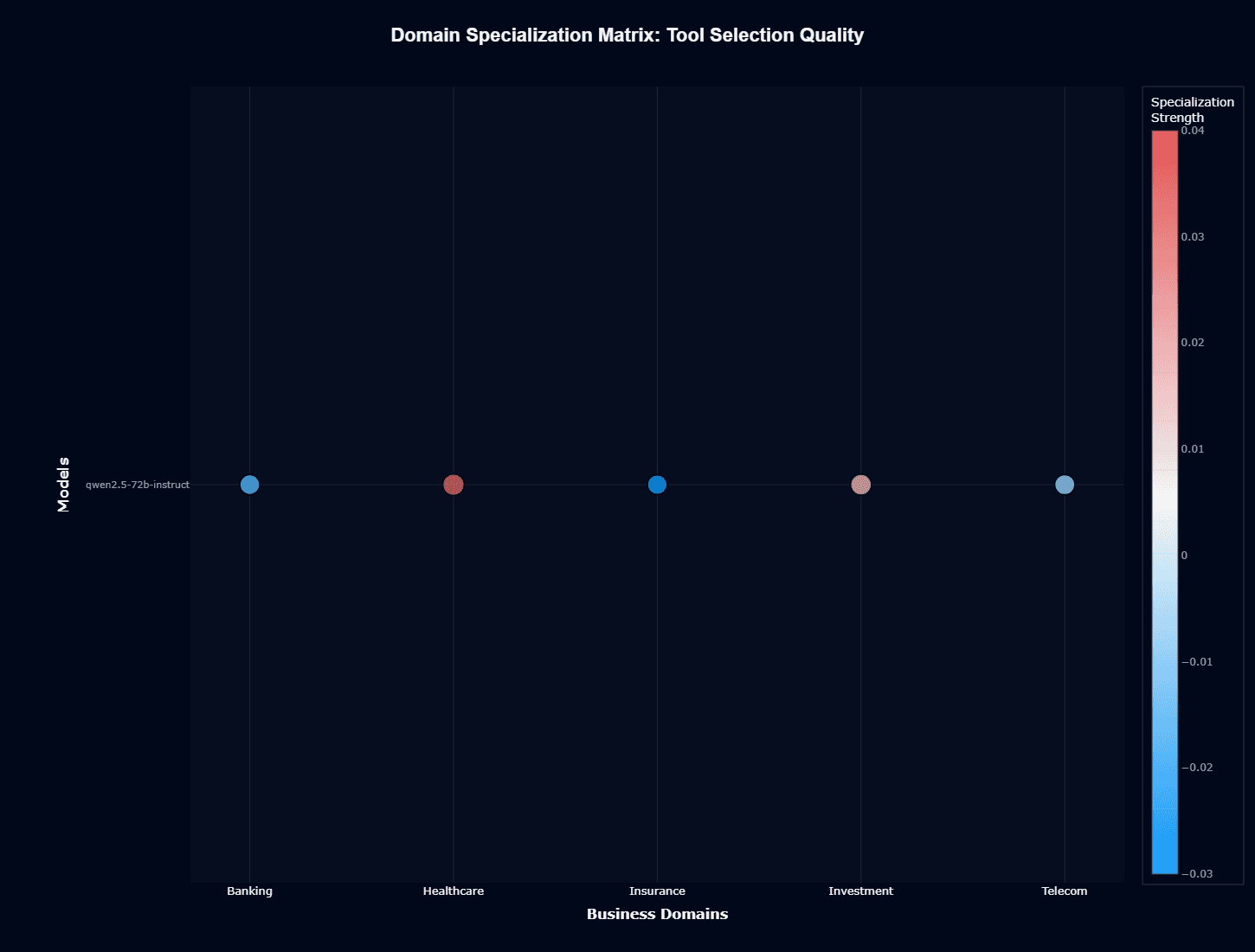
Tool selection quality specialization reveals a different pattern. Healthcare maintains positive specialization (red/warm), indicating the model not only understands medical concepts but also navigates your healthcare-specific tool APIs effectively.
This dual strength—domain knowledge plus technical proficiency—makes Healthcare the optimal target domain for your Qwen2.5-72B-Instruct deployments.
Insurance shows negative specialization (blue/cool) for tool selection despite neutral action completion specialization, suggesting the model grasps insurance concepts adequately but struggles with your insurance industry's specific API conventions and tool patterns.
Banking exhibits similar negative tool selection specialization, indicating technical API navigation challenges even when conceptual understanding exists.
Interestingly, Investment shows slight positive specialization for tool selection despite terrible action completion performance.
This counterintuitive result suggests Qwen2.5-72B-Instruct can identify appropriate financial tools and APIs but lacks the domain knowledge to use them correctly—choosing the right function but providing incorrect parameters or context.
Telecom demonstrates slight negative tool selection specialization, indicating modest challenges with telecommunications-specific APIs despite reasonable action completion.
Qwen2.5 72B Instruct performance gap analysis by domain
Action completion
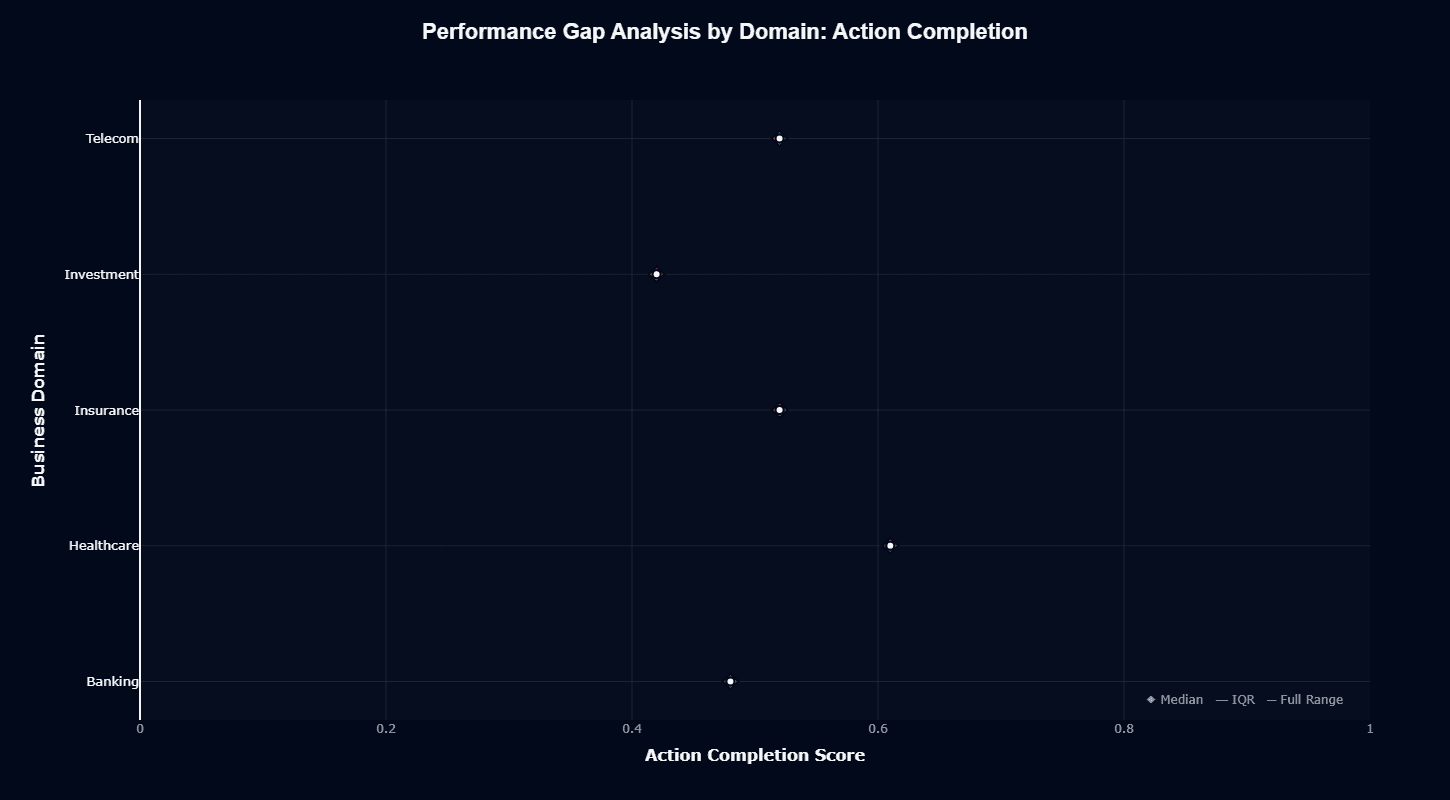
Performance gap analysis reveals relatively tight distributions within most domains, indicating consistent behavior across different tasks within each vertical. Healthcare clusters around 0.61 with narrow variance, demonstrating reliable performance that your team can depend on for production deployments.
Insurance and Telecom both show 0.52 medians with similarly compact distributions.
Banking sits at approximately 0.48 with moderate variance, while Investment languishes at 0.42—clearly separated from other domains.
The relatively narrow IQR (interquartile range) indicators across all domains suggest Qwen2.5-72B-Instruct maintains predictable performance characteristics even in weaker domains, avoiding the wild variance that would complicate your evaluation and quality assurance.
This consistency matters significantly for your enterprise deployments. Multi-domain applications can establish universal performance baselines while accounting for predictable domain-specific offsets.
Your quality assurance team benefits from stable distributions that simplify threshold setting and anomaly detection. The model won't suddenly excel or fail catastrophically within a domain—performance remains bounded and predictable.
If you're working in Investment and Banking domains, the compact variance provides both constraint and opportunity.
While absolute performance lags, the predictability enables systematic improvement through targeted techniques like domain-specific RAG, carefully crafted few-shot examples, or task-specific fine-tuning.
Tool selection quality
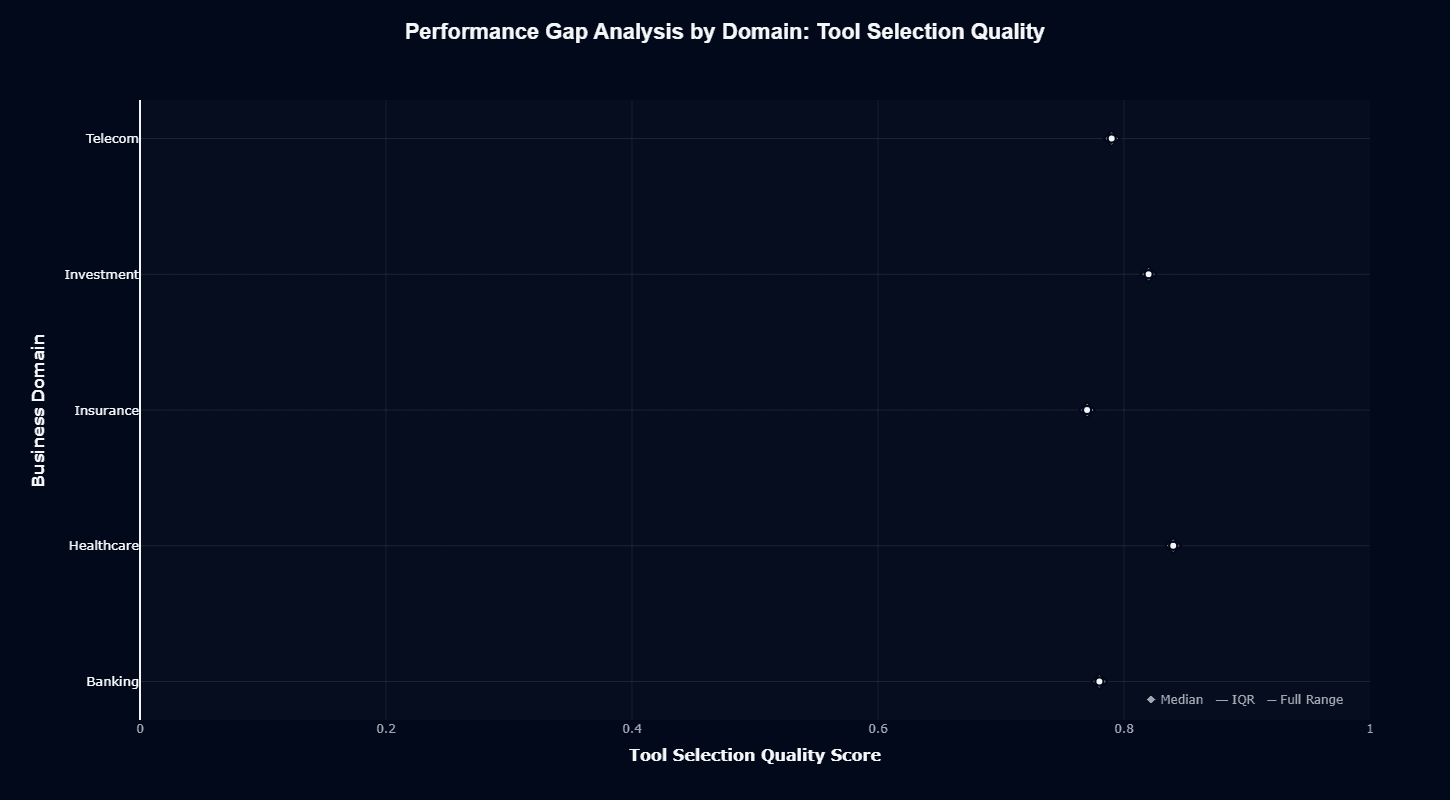
Tool selection quality reveals exceptional performance.
Qwen2.5-72B-Instruct excels at choosing appropriate tools across all domains, even where execution quality varies dramatically. This asymmetry—reliable tool selection paired with uneven execution—suggests the model's function calling reasoning operates independently from domain-specific knowledge application.
For your agentic workflows, this pattern enables targeted optimization strategies. You can trust Qwen2.5-72B-Instruct to invoke correct APIs and functions, then focus improvement efforts on the inputs, parameters, and context provided to those tools rather than second-guessing tool selection itself.
This separation of concerns simplifies your architecture: robust tool selection forms a reliable foundation while domain-specific layers handle execution quality.
Qwen2.5 72B Instruct cost-performance efficiency
Action completion
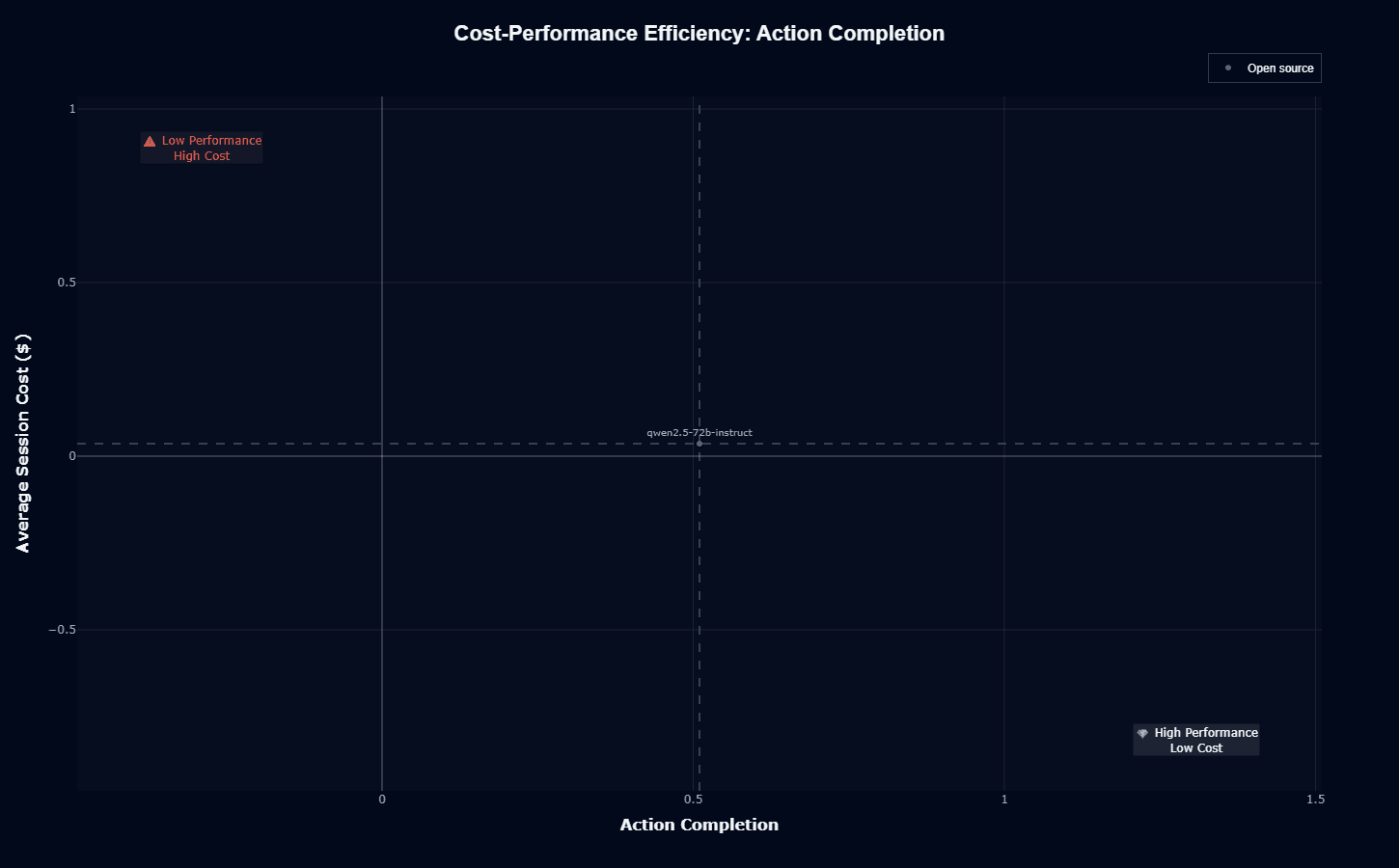
Qwen2.5-72B-Instruct occupies an extraordinary position in cost-performance analysis—essentially zero session cost ($0.036, graphically indistinguishable from zero) combined with competitive 0.51 action completion.
This "open source" positioning (marked with a blue indicator) delivers a value proposition fundamentally different from proprietary alternatives.
At $0.036 per session, Qwen2.5-72B-Instruct enables deployment economics impossible with proprietary models.
Consider processing 10 million agent interactions monthly: your annual cost with Qwen2.5-72B-Instruct would be approximately $360,000, while comparable proprietary solutions at $0.15+ per session would exceed $1.8 million—a 5x cost differential that transforms feasibility calculations for your high-volume applications.
The model sits squarely in the "High Performance, Low Cost" quadrant, though not achieving peak action completion scores. This positioning serves you well if you prioritize deployment scale over marginal accuracy gains.
For use cases where consistent good performance outweighs occasional excellent performance, Qwen2.5-72B-Instruct's economics become compelling.
The open-source designation provides additional economic advantages beyond per-session costs: no vendor lock-in, no price increase risk, complete control over deployment infrastructure, and the ability to fine-tune without per-token charges.
You can optimize prompts, experiment with architectures, and iterate rapidly without accumulating API costs that would throttle innovation in proprietary deployments.
Tool selection quality

Tool selection quality analysis shows Qwen2.5-72B-Instruct achieving 0.80 accuracy at near-zero cost, occupying the "High Performance, Low Cost" quadrant with considerable margin.
While trailing leaders in absolute tool selection quality (12-20 percentage points), the cost differential makes this tradeoff economically rational for many of your applications.
Tool selection errors compound rapidly in multi-step workflows. A single incorrect function invocation derails entire processes, requiring human intervention and dramatically increasing your effective costs.
Qwen2.5-72B-Instruct's 0.80 tool selection quality strikes a pragmatic balance: sufficient accuracy to avoid constant failures while maintaining deployment economics that enable your aggressive experimentation and iteration.
If you're building tool-heavy agents, Qwen2.5-72B-Instruct's position presents a clear value calculation. Enhanced validation logic and error recovery mechanisms can compensate for the ~20-percentage-point tool selection gap compared to premium models, with implementation costs far below the 5x pricing differential.
The model becomes particularly attractive for your development and staging environments where rapid iteration matters more than peak production reliability.
You can deploy hybrid architectures: Qwen2.5-72B-Instruct handles the majority of tool selection at minimal cost, with premium models reserved for high-stakes decisions flagged by confidence scoring or domain context.
This tiered approach optimizes your cost-quality frontier rather than accepting one-size-fits-all tradeoffs.
Qwen2.5 72B Instruct speed vs. accuracy
Action completion
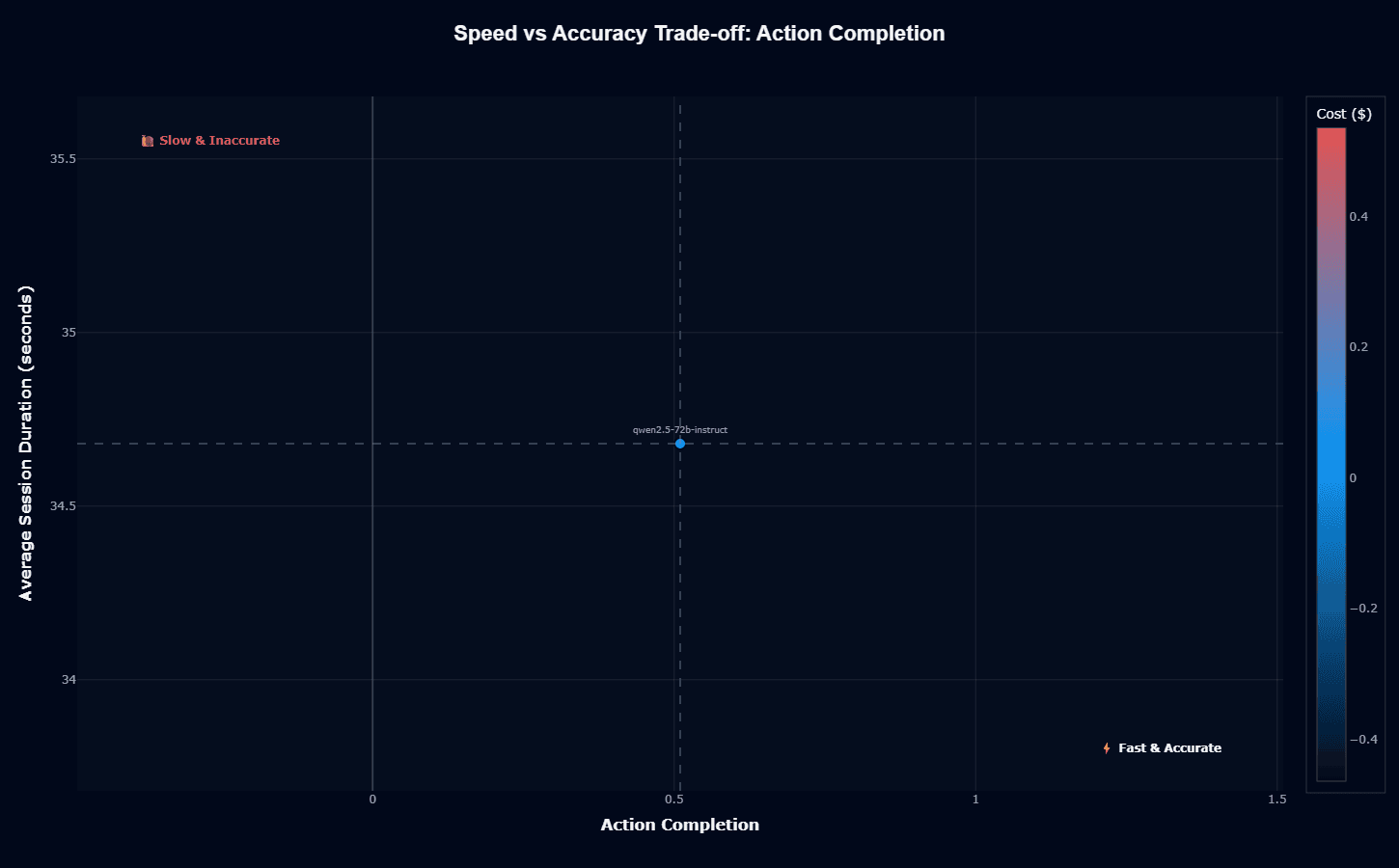
Qwen2.5-72B-Instruct achieves 34.7-second average duration—the fastest execution time in our competitive analysis. Combined with 0.51 action completion, the model occupies a favorable position, balancing response speed against task success rates.
This latency advantage becomes critical for your user-facing applications, where sub-minute response times determine satisfaction.
The speed achievement stems from multiple factors: efficient inference optimization in the Qwen2.5 architecture, aggressive quantization options (Q4_K_M and other compression schemes), and deployment flexibility enabling hardware acceleration unavailable to API-only alternatives.
You can deploy on specialized inference hardware, leverage optimized runtimes like vLLM, and tune generation parameters for your specific latency requirements.
The 34.7-second duration accommodates meaningful reasoning without creating unacceptable wait times. Your users tolerate roughly 30-60 seconds for complex agent tasks, positioning Qwen2.5-72B-Instruct within acceptable bounds while competitors often exceed user patience thresholds.
This speed also enables higher throughput: faster inference means more concurrent sessions per GPU, improving hardware utilization and further reducing your effective per-session costs.
For your production deployments, the speed advantage compounds with cost efficiency. Shorter session durations reduce memory footprint, enable more aggressive batching, and minimize queue depths during traffic spikes.
You can provision fewer inference resources while maintaining acceptable latency percentiles, particularly when combined with Qwen2.5-72B-Instruct's open-source deployment flexibility.
Tool selection quality
Tool selection quality maintains 0.80 accuracy with the same 34.7-second duration, demonstrating that the model's rapid inference doesn't compromise function calling reasoning. This consistency across metrics—achieving both speed and respectable tool selection accuracy—validates Qwen2.5-72B-Instruct's architectural efficiency for your implementation.
The speed versus tool selection quality tradeoff reveals an important characteristic: tool selection reasoning happens early in execution pipelines, typically within the first few seconds of processing.
The remaining duration covers tool execution, response synthesis, and output generation. Qwen2.5-72B-Instruct's 0.80 tool selection quality therefore reflects genuine reasoning capability rather than time-constrained shortcuts.
When optimizing agent performance, note that tool selection quality improvements require architectural changes—better training data, refined prompting strategies, or validation layers—rather than simply allowing longer inference times.
The 34.7-second duration already accommodates thorough tool selection reasoning; extending it further won't meaningfully improve accuracy.
The fast execution combined with competitive tool selection makes Qwen2.5-72B-Instruct particularly suitable for your high-volume, tool-heavy workflows where latency accumulates across multiple agent steps.
Customer service automation, documentation processing, and operational workflows benefit from rapid tool selection that keeps overall interaction times reasonable even when orchestrating multiple sequential tool calls.
Qwen2.5 72B Instruct pricing and usage costs
Qwen2.5-72B-Instruct's pricing fundamentally differs from proprietary alternatives because open weights enable self-hosted deployment. Our $0.036 per average session cost reflects infrastructure expenses for self-hosted deployment rather than per-token API pricing.
Deployment cost structure:
Serving infrastructure: vLLM, TensorRT-LLM, or similar optimization frameworks
Session capacity: ~150,000 sessions/month per A100 GPU at benchmark workload
Effective cost: $0.012 per session (infrastructure only) to $0.036 accounting for overhead
Quantization options: Q4_K_M reduces memory footprint 60%, enabling multiple instances per GPU
Economic comparison:
Qwen2.5-72B-Instruct's deployment economics shift fixed versus variable cost structures. If your organization processes 1 million agent interactions monthly, you'll face approximately $36,000 in infrastructure costs compared to $150,000+ for comparable proprietary API usage.
Break-even occurs around 50,000 monthly sessions—below this threshold, proprietary APIs prove more economical due to zero upfront infrastructure investment.
However, the open-source model provides economic advantages beyond pure session costs:
No vendor lock-in: Price changes, usage restrictions, and service discontinuation risks eliminated for your organization
Deployment flexibility: On-premise, hybrid cloud, or air-gapped environments are unavailable with API-only alternatives
Fine-tuning economics: Domain-specific optimization costs only compute, not per-token charges
Scaling predictability: Linear cost growth with volume, no surprise API price increases
Licensing considerations:
The Qwen Research License restricts commercial use, requiring separate licensing negotiation for your production deployments. You must account for licensing fees (not publicly disclosed) when calculating the total cost of ownership.
This restriction distinguishes Qwen2.5-72B-Instruct from truly open-source alternatives like Llama 3, which provide commercial-use rights without additional licensing.
For non-commercial applications—research, internal tools, evaluation—Qwen2.5-72B-Instruct provides unrestricted access to frontier capabilities at infrastructure-only costs.
If you're with academic institutions, research organizations, or enterprise innovation labs, you gain full model access without per-query charges that would throttle experimentation in proprietary environments.
Qwen2.5 72B Instruct key capabilities and strengths
Here are Qwen2.5 72B Instruct’s key capabilities and strengths:
Exceptional speed and efficiency: The model completes tasks rapidly without sacrificing reasoning quality, enabling higher throughput and better hardware utilization than slower alternatives.
Outstanding cost efficiency: Qwen2.5-72B-Instruct costs roughly 1/5th what comparable proprietary models do. This economic advantage makes high-volume applications possible that were previously infeasible at API pricing, particularly if you're processing millions of monthly interactions.
Healthcare domain excellence: Your medical documentation, clinical workflow automation, patient communication, and care coordination agents all benefit from natural strength without requiring extensive domain-specific engineering.
Comprehensive multilingual support: Training on 29+ languages with particular depth in Chinese and English enables global deployments serving your diverse user populations. Unlike English-centric alternatives requiring careful prompt engineering for other languages, Qwen2.5-72B-Instruct handles multilingual contexts natively.
Strong conversation efficiency: The model synthesizes information effectively rather than requiring extensive iterative refinement common in less efficient alternatives.
Open weights and deployment flexibility: Unlike proprietary alternatives, Qwen2.5-72B-Instruct provides complete model access, enabling your on-premise deployment, custom fine-tuning, architectural experimentation, and air-gapped environments. You maintain full control over inference infrastructure, data handling, and optimization strategies.
Structured output generation: Enhanced training specifically for JSON and structured data generation makes Qwen2.5-72B-Instruct excel at your API integration, database operations, and workflow orchestration. The model reliably produces well-formed, structured outputs without the formatting failures common in models lacking this specialized training.
Robust tool selection: 0.800 tool selection quality indicates reliable function calling across most contexts. While trailing leaders, this accuracy level prevents the constant tool selection failures that would derail your agentic workflows, providing a solid foundation for multi-step agent architectures.
System prompt resilience: Improved robustness to diverse system prompts enables sophisticated role-play scenarios and flexible agent conditioning without the brittleness that plagues models overfitted to specific prompt formats. Your development team gains freedom to iterate on prompt strategies without triggering unpredictable behavior changes.
Qwen2.5 72B Instruct limitations and weaknesses
While Qwen2.5 72B Instruct excels with some key strengths, there are also limitations and weaknesses to consider:
Mid-tier action completion performance: Your autonomous workflows requiring high task success rates may need additional oversight, validation logic, or hybrid architectures combining Qwen2.5-72B-Instruct with more capable models for critical decisions.
Severe investment domain weakness: If you're in asset management, trading, or investment advisory, anticipate extensive RAG systems, domain-specific fine-tuning, or alternative model selection.
Below-average banking performance: While not as severe as investment limitations, your banking applications still require significant prompt engineering, validation logic, and potentially hybrid architectures to achieve production-quality results.
Commercial licensing restrictions: The Qwen Research License restricts commercial use, requiring separate licensing negotiation. Unlike truly open-source alternatives with permissive licenses, you cannot deploy Qwen2.5-72B-Instruct in production revenue-generating applications without additional agreements.
Deployment complexity: Self-hosting requires infrastructure expertise, GPU availability, serving optimization, and operational overhead absent in API-only alternatives. If you're with a small organization lacking ML infrastructure teams, deployment complexity may outweigh economic advantages, particularly for lower-volume applications
Limited vendor support: Open-source deployment eliminates formal SLAs, dedicated support channels, and liability protections that proprietary vendors provide. If you're in regulated industries, you often require vendor accountability that open-source models cannot satisfy, regardless of technical capabilities or economic advantages.
Inferior absolute performance: Across most metrics, Qwen2.5-72B-Instruct trails both frontier proprietary models and leading open-source alternatives. If your team requires peak performance for mission-critical applications, you should evaluate more capable options despite higher costs or deployment complexity.
Ship reliable AI applications and agents with Galileo
The journey to reliable AI agents requires systematic evaluation across the entire development lifecycle. With the right framework and tools, you can confidently deploy AI applications and agents that deliver consistent value while avoiding costly failures.
Here’s how Galileo provides you with a comprehensive evaluation and monitoring infrastructure:
Automated quality guardrails in CI/CD: Galileo integrates directly into your development workflow, running comprehensive evaluations on every code change and blocking releases that fail quality thresholds
Multi-dimensional response evaluation: With Galileo's Luna-2 evaluation models, you can assess every output across dozens of quality dimensions—correctness, toxicity, bias, adherence—at 97% lower cost than traditional LLM-based evaluation approaches
Real-time runtime protection: Galileo's Agent Protect scans every prompt and response in production, blocking harmful outputs before they reach users while maintaining detailed compliance logs for audit requirements
Intelligent failure detection: Galileo’s Insights Engine automatically clusters similar failures, surfaces root-cause patterns, and recommends fixes, reducing debugging time while building institutional knowledge
Human-in-the-loop optimization: Galileo's Continuous Learning via Human Feedback (CLHF) transforms expert reviews into reusable evaluators, accelerating iteration while maintaining quality standards
Get started with Galileo today and discover how a comprehensive evaluation can elevate your agent development and achieve reliable AI systems that users trust.